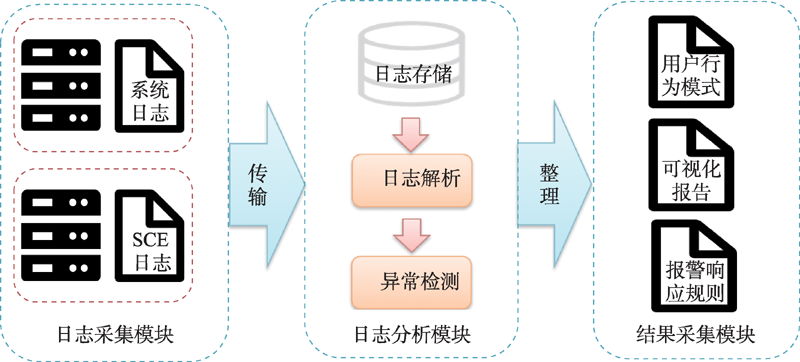
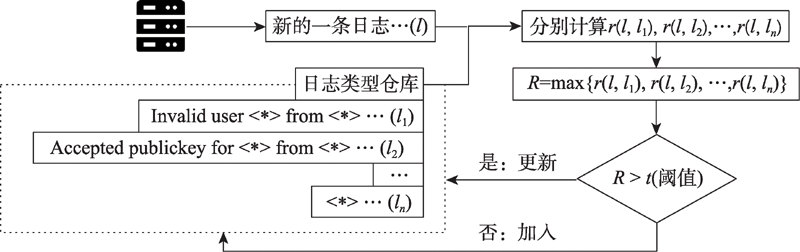
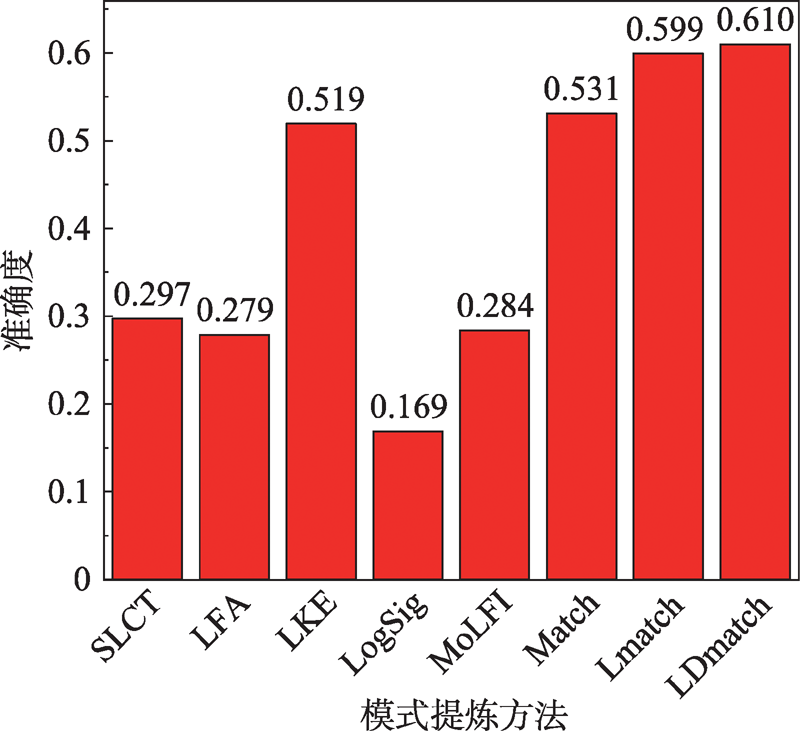
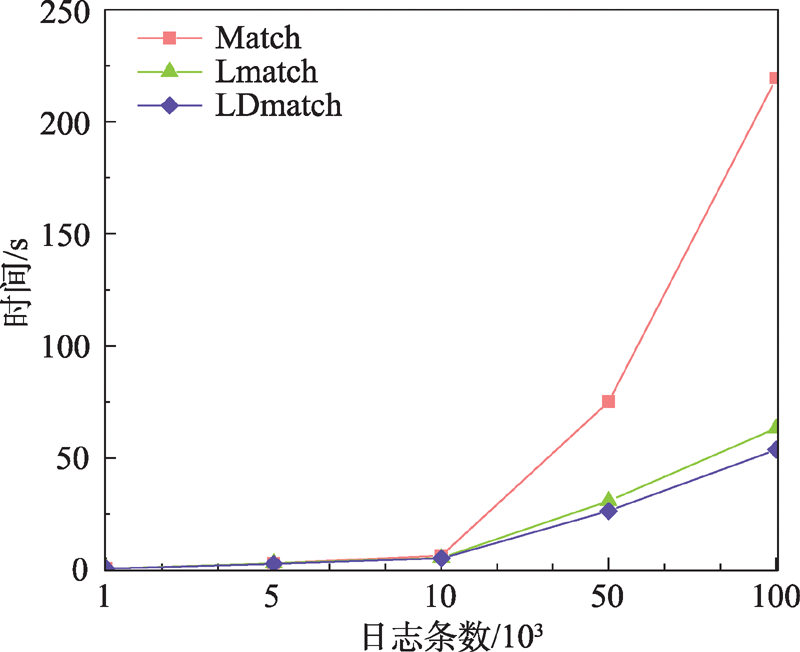
| [1] |
赵一宁, 肖海力. 网格环境日志分析框架LARGE的设计[J]. 科研信息化技术与应用, 2016, 7(3): 3-7.
|
|
ZHAO Y N, XIAO H L. The design of LARGE: log anal-yzing framework in grid environment[J]. E-science Techno-logy & Application, 2016, 7(3): 3-7.
|
| [2] |
XU W, HUANG L, FOX A, et al. Detecting large-scale system problems detection by mining console logs[C]// Proceedings of the ACM SIGOPS 22nd Symposium on Operating Systems Principles, Oct 2009. New York: ACM, 2009: 117-132.
|
| [3] |
LOU J G, FU Q, YANG S Q, et al. Mining invariants from console logs for system problem detection[C]// Proceedings of the 2010 USENIX Annual Technical Conference, Boston, Jun 23-25, 2010. Berkeley: USENIX Association, 2010: 231-244.
|
| [4] |
LIN Q W, ZHANG H Y, LOU J G, et al. Log clustering based problem identification for online service systems[C]// Proceedings of the 38th International Conference on Soft-ware Engineering Companion, Austin, May 14-22, 2016. Pisca-taway: IEEE, 2016: 102-111.
|
| [5] |
DU M, LI F F, ZHENG G N, et al. DeepLog: anomaly detection and diagnosis from system logs through deep lear-ning[C]// Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, Oct 30-Nov 3, 2017. New York: ACM, 2017: 1285-1298.
|
| [6] |
ZHAO Y N, XIAO H L. Extracting log patterns from sys-tem logs in LARGE[C]// Proceedings of the 2016 IEEE Inter-national Parallel and Distributed Processing Symposium Workshops, Chicago, May 23-27, 2016. Washington: IEEE Computer Society, 2016: 1645-1652.
|
| [7] |
ZHAO Y N, WANG X D, XIAO H L, et al. Improvement of log pattern extracting algorithm using text similarity[C]// Proceedings of the 2018 IEEE International Parallel and Distributed Processing Symposium Workshops, Vancouver, May 21-25, 2018. Washington: IEEE Computer Society, 2018: 507-514.
|
| [8] |
VAARANDI R. A data clustering algorithm for mining pat-terns from event logs[C]// Proceedings of the 3rd IEEE Work-shop on IP Operations & Management, Kansas City, Oct 3, 2003. Piscataway: IEEE, 2003: 119-126.
|
| [9] |
NAGAPPAN M, VOUK M A. Abstracting log lines to log event types for mining software system logs[C]// Proceedings of the 7th IEEE Working Conference on Mining Software Repositories, Cape Town, May 2-3, 2010. Piscataway: IEEE, 2010: 114-117.
|
| [10] |
FU Q, LOU J G, WANG Y, et al. Execution anomaly detec-tion in distributed systems through unstructured log analysis[C]// Proceedings of the 9th IEEE International Conference on Data Mining, Miami Beach, Dec 6-9, 2009. Piscataway: IEEE, 2009: 149-158.
|
| [11] |
TANG L, LI T, PERNG C S. LogSig: generating system events from raw textual logs[C]// Proceedings of the 20th ACM Conference on Information and Knowledge Management, Oct 2011. New York: ACM, 2011: 785-794.
|
| [12] |
MIZUTANI M. Incremental mining of system log format[C]// Proceedings of the 2013 IEEE International Conference on Services Computing, Santa Clara, Jun 28-Jul 3, 2013. Pis-cataway: IEEE, 2013: 595-602.
|
| [13] |
MESSAOUDI S, PANICHELLA A, BIANCULLI D, et al. A search-based approach for accurate identification of log message formats[C]// Proceedings of the 26th IEEE/ACM International Conference on Program Comprehension, May 2018. New York: ACM, 2018: 167-177.
|
| [14] |
DAI H T, LI H, CHEN C S, et al. Logram: efficient log parsing using n-gram dictionaries[J]. IEEE Transactions on Software Engineering, 2022, 48(3): 879-892.
|
| [15] |
NEDELKOSKI S, BOGATINOVSKI J, ACKER A, et al. Self-supervised log parsing[J]. arXiv:2003.07905, 2020.
|
| [16] |
ZHU J M, HE S L, LIU J Y, et al. Tools and benchmarks for automated log parsing[C]//Proceedings of the 41st Interna-tional Conference on Software Engineering:Software Engi-neering in Practice, Montreal, May 25-31, 2019. Piscataway: IEEE, 2019: 121-130.
|

 ), 肖海力1, 王小宁1, 迟学斌1,2
), 肖海力1, 王小宁1, 迟学斌1,2