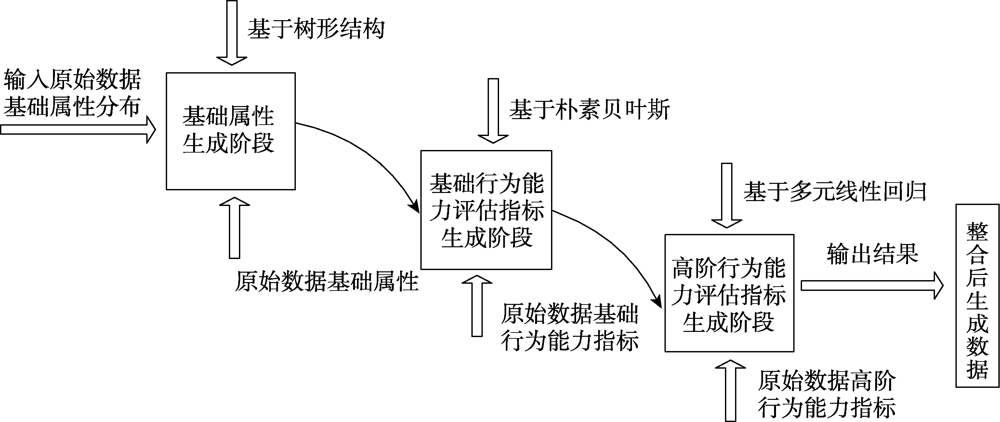
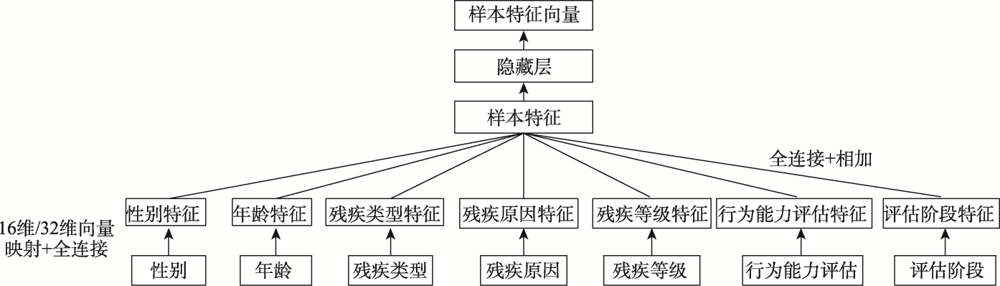
| [1] |
HINTON G E, SALAKHUTDINOV R R. Reducing the dimensionality of data with neural networks[J]. Science, 2006, 313(5786): 504-507.
DOI
URL
|
| [2] |
郭丽丽, 丁世飞. 深度学习研究进展[J]. 计算机科学, 2015, 42(5): 28-33.
|
|
GUO L L, DING S F. Reaserch progress on deep learning[J]. Computer Science, 2015, 42(5): 28-33.
|
| [3] |
刘全, 翟建伟, 章宗长, 等. 深度强化学习综述[J]. 计算机学报, 2018, 41(1): 1-27.
|
|
LIU Q, ZHAI J W, ZHANG Z Z, et al. A survey on deep reinforcement learning[J]. Chinese Journal of Computers, 2018, 41(1): 1-27.
|
| [4] |
刘尚希, 赵福昌, 侯海波. 中国人口老龄化、经济增长与社会化改革[J]. 发展研究, 2020(10): 4-9.
|
|
LIU S X, ZHAO F C, HOU H B. Aging of Chinese population, economic growth and social reform[J]. Development Research, 2020(10): 4-9.
|
| [5] |
LI J, YANG S, WANG X, et al. Tree-structured data regeneration with network coding in distributed storage systems[C]// Proceedings of the 17th International Workshop on Quality of Service, Charleston, Jul 13-15, 2009. Piscataway: IEEE, 2010: 1-9.
|
| [6] |
HUAI M, HUANG L S, YANG W, et al. Privacy-preserving naïve Bayes classification[C]// LNCS 9403: Proceedings of the 8th International Conference on Knowledge Science, Engineering and Management, Chongqing, Oct 28-30, 2015. Cham: Springer, 2015: 627-638.
|
| [7] |
ISLAM M Q, TIKU M L. Multiple linear regression model under nonnormality[J]. Communications in Statistics, 2005, 33(10): 2443-2467.
|
| [8] |
HE H B, GARCIA E A. Learning from imbalanced data[J]. IEEE Transactions on Knowledge and Data Engineering, 2009, 21(9): 1263-1284.
DOI
URL
|
| [9] |
BRANCO P, TORGO L, RIBEIRO R P. A survey of predictive modeling on imbalanced domains[J]. ACM Computing Surveys, 2017, 49(2): 1-50.
|
| [10] |
段萌, 王功鹏, 牛常勇. 基于卷积神经网络的小样本图像识别方法[J]. 计算机工程与设计, 2018, 39(1): 224-229.
|
|
DUAN M, WANG G P, NIU C Y. Method of small sample size image recognition based on convolution neural network[J]. Computer Engineering and Design, 2018, 39(1): 224-229.
|
| [11] |
陈旭, 刘鹏鹤, 孙毓忠, 等. 面向不均衡医学数据集的疾病预测模型研究[J]. 计算机学报, 2019, 42(3): 596-609.
|
|
CHEN X, LIU P H, SUN Y Z, et al. Research on disease prediction models based on imbalanced medical data sets[J]. Chinese Journal of Computers, 2019, 42(3): 596-609.
|
| [12] |
LIU X Y, WU J X, ZHOU Z H. Exploratory undersampling for class-imbalance learning[J]. IEEE Transactions on Systems, Man, and Cybernetics: Part B, 2009, 39(2): 539-550.
DOI
URL
|
| [13] |
LIANG G H, COHN A G. An effective approach for imbalanced classification: unevenly balanced Bagging[C]// Procee-dings of the 27th AAAI Conference on A.pngicial Intelligence, Bellevue, Jul 14-18, 2013. Menlo Park: AAAI, 2013: 1633-1634.
|
| [14] |
RADFORD A, METZ L, CHINTALA S. Unsupervised representation learning with deep convolutional generative adversarial networks[J]. arXiv:1511. 06434, 2015.
|
| [15] |
刘宇飞, 周源, 刘欣, 等. 基于Wasserstein GAN的新一代人工智能小样本数据增强方法——以生物领域癌症分期数据为例[J]. 工程, 2019, 5(1): 156-163.
|
|
LIU Y F, ZHOU Y, LIU X, et al. Wasserstein GAN-based small-sample augmentation for new-generation a.pngicial intelligence: a case study of cancer-staging data in biological[J]. Engineering, 2019, 5(1): 156-163.
DOI
URL
|

 ), 杭少石, 张柏林, 初佃辉
), 杭少石, 张柏林, 初佃辉