
计算机科学与探索 ›› 2022, Vol. 16 ›› Issue (8): 1764-1778.DOI: 10.3778/j.issn.1673-9418.2110049
洪惠群1,2,3, 沈贵萍1,2,+( ), 黄风华1,2,3
), 黄风华1,2,3
收稿日期:2021-10-20
修回日期:2022-04-11
出版日期:2022-08-01
发布日期:2022-08-19
通讯作者:
+E-mail: 992774639@qq.com。作者简介:洪惠群(1984—),女,福建南安人,硕士,讲师,工程师,CCF会员,主要研究方向为图像处理、计算机视觉、表情识别等。基金资助:
HONG Huiqun1,2,3, SHEN Guiping1,2,+(), HUANG Fenghua1,2,3
Received:2021-10-20
Revised:2022-04-11
Online:2022-08-01
Published:2022-08-19
About author:HONG Huiqun, born in 1984, M.S., lecturer, engineer, member of CCF. Her research inte-rests include image processing, computer vision, expression recognition, etc.Supported by:摘要:
面部表情是判断人类情感和人机交互的重要依据,传统机器学习和深度学习的发展,给面部表情识别分析带来了许多机遇与挑战。首先分析了表情识别与情感分析的内在联系与区别,指出表情识别侧重于识别面部的表情及情感。接着总结归纳了基于单模态数据集和传统机器学习方法的表情识别技术及其优缺点,介绍了基于单模态数据集与深度学习方法的表情识别技术,然后指出基于单模态数据的表情识别技术具有一定的局限性,如:数据集在数量和质量上较为不足,识别准确率普遍不高,多停留在实验室研究阶段等。引出基于多模态数据集的表情识别及模态间融合方法,并介绍常用的多模态表情数据集,分析了基于多模态数据集的表情识别技术及模态之间的融合技术,包含特征级融合、决策级融合及混合融合三种方式。最后对表情识别分析技术进行总结与展望:考虑到数据集问题,可构建更多自然环境下的高质量表情数据集,也可结合姿势、脑电波等生理信号构建多模态数据集,利用GAN网络进行数据增强,关注微表情的提取,以及研究多模态融合算法等。
中图分类号:
洪惠群, 沈贵萍, 黄风华. 表情识别技术综述[J]. 计算机科学与探索, 2022, 16(8): 1764-1778.
HONG Huiqun, SHEN Guiping, HUANG Fenghua. Summary of Expression Recognition Technology[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(8): 1764-1778.

图1 单模态人脸表情识别主要步骤
Fig.1 Main steps of unimodal facial expression recognition
| 数据库 | 图像特点 | 标注的表情类别 | 图像/视频数 |
|---|---|---|---|
| TFD[ | A1、B2 | 7类 | 112 234个图像 |
| FER2013[ | A2、B1 | 7类 | 35 887个图像 |
| NVIE[ | A1、B1 | 6类 | 1 830个视频 |
| SFEW [ | A2、B1 | 7类 | 1 766个图像 |
| Multi-PIE[ | A1、B2 | 6类 | 755 370个图像 |
| BU-3DFE[ | A1、B1 | 7类 | 2 500个图像 |
| Oulu-CASIA[ | A1、B1 | 6类 | 2 880个图像 |
| RaFD[ | A1、B1 | 7类 | 1 608个图像 |
| KDEF[ | A1、B1 | 7类 | 4 900个图像 |
| EmotioNet[ | A2、B2 | 23类基本或复合表情 | 100万个图像 |
| RAF-DB[ | A2、B1 | 7类+12复合类 | 29 672个图像 |
| AffectNet[ | A2、B2 | 8类+V-A | 44万个图像 |
| ExpW[ | A2、B2 | 7类 | 91 793个图像 |
| CK+[ | A1、B1 | 8类 | 593个图片 |
| MMI[ | A1、B1 | 7类 | 740个图片、 2 900个视频 |
| JAFFE[ | A1、B1 | 7类 | 213个图片 |
表1 常见的表情识别数据集
Table 1 Common expression recognition datasets
| 数据库 | 图像特点 | 标注的表情类别 | 图像/视频数 |
|---|---|---|---|
| TFD[ | A1、B2 | 7类 | 112 234个图像 |
| FER2013[ | A2、B1 | 7类 | 35 887个图像 |
| NVIE[ | A1、B1 | 6类 | 1 830个视频 |
| SFEW [ | A2、B1 | 7类 | 1 766个图像 |
| Multi-PIE[ | A1、B2 | 6类 | 755 370个图像 |
| BU-3DFE[ | A1、B1 | 7类 | 2 500个图像 |
| Oulu-CASIA[ | A1、B1 | 6类 | 2 880个图像 |
| RaFD[ | A1、B1 | 7类 | 1 608个图像 |
| KDEF[ | A1、B1 | 7类 | 4 900个图像 |
| EmotioNet[ | A2、B2 | 23类基本或复合表情 | 100万个图像 |
| RAF-DB[ | A2、B1 | 7类+12复合类 | 29 672个图像 |
| AffectNet[ | A2、B2 | 8类+V-A | 44万个图像 |
| ExpW[ | A2、B2 | 7类 | 91 793个图像 |
| CK+[ | A1、B1 | 8类 | 593个图片 |
| MMI[ | A1、B1 | 7类 | 740个图片、 2 900个视频 |
| JAFFE[ | A1、B1 | 7类 | 213个图片 |
| 分类 | 主要方法 | 方法描述 | 优点 | 缺点 | |
|---|---|---|---|---|---|
| 基于全局特征提取方法 | 主成分分析法(principal component analysis,PCA)[ | 从原始数据中提取主成分,降低特征维度,力求用较少的特征综合表达原始数据之间的关系 | 提取特征具有全局性 | 计算量大,识别率不高,无法利用训练样本中的类别信息 | |
| 基于纹理特征的提取方法 | 局部二值模式(local binary patterns,LBP)[ | 定义3×3的LBP算子,得到该窗口中心像素点的LBP值,并用这个值来反映该区域的纹理信息 | 具有旋转不变性和灰度不变性等,对光照变化不敏感 | 难以详细描述像素在邻域方向上的灰度值变化,难以满足不同尺寸图像纹理问题 | |
| Gabor变换[ | 通过定义不同的带宽和方向对图像进行多分辨率分析,有效提取图像中的纹理特征 | 对光照变化不敏感,有明显方向选择性和频率选择性 | 当特征维度太大时,难以找到合适的参数变量 | ||
| 基于局部特征提取方法 | 基于几何特征的提取方法[ | 主动形状模型,提取人脸轮廓及眼睛、鼻子、嘴的位置 | 有效地提取人脸面部表情的显著特征 | 当人脸关键识别分类信息丢失时,会导致提取出的特征出现偏差,使得精度下降 | |
| 混合提取方法 | 特定表情的局部二值模式(expression-specific local binary pattern,es-LBP)[ | 提出了es-LBP特征,更好地捕获人脸在重要基点上的局部信息 | es-LBP特征优于传统的LBP特征 | 当图像受到噪声污染比较严重时,准确率下降 | |
| 光流法+图像梯度[ | 在bag-of-words设置中使用OF和IG这种以直方图形式的独特组合,使得所提出的特征在视频中独立于人脸的尺度并跟踪像素的运动,能够捕捉复杂的非刚性运动的面部组件 | 对皮肤色调的变化非常敏感,能克服如面部成分的非刚性运动以及不同肤色和尺度的障碍 | 从视频中每一张图像中提取特征的识别模型,特征的维数变得非常高,导致更高的时间和空间复杂性 | ||
| 几何特征+纹理特征[ | 采用WLD(Weber local descriptor)和HOG(histograms of oriented gradients)结合来表示局部细节 | 能有效提取图像纹理信息,对噪声和光照变化具有很强的鲁棒性,分类的准确率更高和所需时间更少 | 无法自适应权重,解决姿态和光照的变化 | ||
| 局部Gabor+分数次幂多项式核函数PCA[ | 基于局部Gabor滤波组和分数次幂多项式核函数PCA的方法,并利用支持向量机对特征进行分类 | 降低计算复杂度,有效改善光照的影响,获得较好的识别率 | |||
| 光流法[ | 高斯金字塔 Lucas-Kanada光流法 | 将运动图像函数 | 反映人脸表情变化的实际规律,对光照变化不敏感 | 识别模型和算法较为复杂,计算量大 | |
表2 传统表情特征提取方法
Table 2 Traditional expression feature extraction methods
| 分类 | 主要方法 | 方法描述 | 优点 | 缺点 | |
|---|---|---|---|---|---|
| 基于全局特征提取方法 | 主成分分析法(principal component analysis,PCA)[ | 从原始数据中提取主成分,降低特征维度,力求用较少的特征综合表达原始数据之间的关系 | 提取特征具有全局性 | 计算量大,识别率不高,无法利用训练样本中的类别信息 | |
| 基于纹理特征的提取方法 | 局部二值模式(local binary patterns,LBP)[ | 定义3×3的LBP算子,得到该窗口中心像素点的LBP值,并用这个值来反映该区域的纹理信息 | 具有旋转不变性和灰度不变性等,对光照变化不敏感 | 难以详细描述像素在邻域方向上的灰度值变化,难以满足不同尺寸图像纹理问题 | |
| Gabor变换[ | 通过定义不同的带宽和方向对图像进行多分辨率分析,有效提取图像中的纹理特征 | 对光照变化不敏感,有明显方向选择性和频率选择性 | 当特征维度太大时,难以找到合适的参数变量 | ||
| 基于局部特征提取方法 | 基于几何特征的提取方法[ | 主动形状模型,提取人脸轮廓及眼睛、鼻子、嘴的位置 | 有效地提取人脸面部表情的显著特征 | 当人脸关键识别分类信息丢失时,会导致提取出的特征出现偏差,使得精度下降 | |
| 混合提取方法 | 特定表情的局部二值模式(expression-specific local binary pattern,es-LBP)[ | 提出了es-LBP特征,更好地捕获人脸在重要基点上的局部信息 | es-LBP特征优于传统的LBP特征 | 当图像受到噪声污染比较严重时,准确率下降 | |
| 光流法+图像梯度[ | 在bag-of-words设置中使用OF和IG这种以直方图形式的独特组合,使得所提出的特征在视频中独立于人脸的尺度并跟踪像素的运动,能够捕捉复杂的非刚性运动的面部组件 | 对皮肤色调的变化非常敏感,能克服如面部成分的非刚性运动以及不同肤色和尺度的障碍 | 从视频中每一张图像中提取特征的识别模型,特征的维数变得非常高,导致更高的时间和空间复杂性 | ||
| 几何特征+纹理特征[ | 采用WLD(Weber local descriptor)和HOG(histograms of oriented gradients)结合来表示局部细节 | 能有效提取图像纹理信息,对噪声和光照变化具有很强的鲁棒性,分类的准确率更高和所需时间更少 | 无法自适应权重,解决姿态和光照的变化 | ||
| 局部Gabor+分数次幂多项式核函数PCA[ | 基于局部Gabor滤波组和分数次幂多项式核函数PCA的方法,并利用支持向量机对特征进行分类 | 降低计算复杂度,有效改善光照的影响,获得较好的识别率 | |||
| 光流法[ | 高斯金字塔 Lucas-Kanada光流法 | 将运动图像函数 | 反映人脸表情变化的实际规律,对光照变化不敏感 | 识别模型和算法较为复杂,计算量大 | |
| 分类 | 方法描述 | 优点 | 缺点 |
|---|---|---|---|
| 自建网络[ | 构建7层卷积神经网络,用大型人脸数据库预训练后,再用表情数据库微调训练;首次将inception层架构应用到跨多个数据库的表情识别 | 取得比传统方法更好的识别效果 | 由于表情数据库数据量过少,网络容易过拟合 |
| 卷积网络微调[ | FaceNet2ExpNet算法,先利用人脸网络的深层特征作为监督训练卷积层,待其训练完成后,加入随机初始化的全连接层,并从头开始训练 | 相比传统的机器学习方法和基于VGG-16网络方法,识别效果更好 | 仅在CK+、OuluCASIA、TFD和SFEW四个公开表达数据库进行对比 |
| 分阶段微调[ | 迁移了在ImageNet数据集预训练过的卷积神经网络(convolutional neural network,CNN),接着用FER2013数据集对该预训练模型进行微调,最后用目标数据库EmotiW对微调后的模型再进行微调 | 提高识别准确率 | 目标数据库使用的是野外静态人脸表情识别,识别准确率不超过55.6% |
| 多网络融合[ | 采用足够多样的子网络来提取足够多的特征,如:通过视觉分支网络负责图像序列的输入,引入低层到高层的跳转连接来考虑底层特征,通过合适的集合方法来高效融合各种子网络 | 能将面部大动作造成的面部特征变化综合考虑进去,在CK+数据集上效果良好 | 未在更多的数据集上测试 |
| 多通道级联[ | 使用三个并行的多通道卷积网络从不同的面部区域学习融合的全局和局部特征,利用联合嵌入特征学习来探索基于融合区域的特征在嵌入空间中的身份不变和姿态感知的表达表示 | 性能和鲁棒性优于现有的先进方法 | 仍要解决不受约束环境下表情识别准确率问题 |
| 生成对抗网络(generative adversarial network,GAN)[ | 使用反表达式剩余学习,先用cGAN训练生成相应输入人脸图像的中性人脸图像,通过学习留在生成模型中间层的沉练,建立了DeRL方法 | 能缓解身份变异问题,处理自发表达和姿势表达的情况下风格和种族背景的不同 | 网络比较复杂 |
| 基于迁移学习的跨域人脸表情识别[ | 引入稀疏重构思想获取共同投影矩阵并对积,利用两个数据库(BU-4DFE和BP4D+)进行预训练,重构系数矩阵,施加 | 较好区分高兴和惊讶 | 对厌恶和生气区分度不高,同时伤心表情识别率相对较低 |
表3 基于深度学习表情识别方法
Table 3 Expression recognition methods based on deep learning
| 分类 | 方法描述 | 优点 | 缺点 |
|---|---|---|---|
| 自建网络[ | 构建7层卷积神经网络,用大型人脸数据库预训练后,再用表情数据库微调训练;首次将inception层架构应用到跨多个数据库的表情识别 | 取得比传统方法更好的识别效果 | 由于表情数据库数据量过少,网络容易过拟合 |
| 卷积网络微调[ | FaceNet2ExpNet算法,先利用人脸网络的深层特征作为监督训练卷积层,待其训练完成后,加入随机初始化的全连接层,并从头开始训练 | 相比传统的机器学习方法和基于VGG-16网络方法,识别效果更好 | 仅在CK+、OuluCASIA、TFD和SFEW四个公开表达数据库进行对比 |
| 分阶段微调[ | 迁移了在ImageNet数据集预训练过的卷积神经网络(convolutional neural network,CNN),接着用FER2013数据集对该预训练模型进行微调,最后用目标数据库EmotiW对微调后的模型再进行微调 | 提高识别准确率 | 目标数据库使用的是野外静态人脸表情识别,识别准确率不超过55.6% |
| 多网络融合[ | 采用足够多样的子网络来提取足够多的特征,如:通过视觉分支网络负责图像序列的输入,引入低层到高层的跳转连接来考虑底层特征,通过合适的集合方法来高效融合各种子网络 | 能将面部大动作造成的面部特征变化综合考虑进去,在CK+数据集上效果良好 | 未在更多的数据集上测试 |
| 多通道级联[ | 使用三个并行的多通道卷积网络从不同的面部区域学习融合的全局和局部特征,利用联合嵌入特征学习来探索基于融合区域的特征在嵌入空间中的身份不变和姿态感知的表达表示 | 性能和鲁棒性优于现有的先进方法 | 仍要解决不受约束环境下表情识别准确率问题 |
| 生成对抗网络(generative adversarial network,GAN)[ | 使用反表达式剩余学习,先用cGAN训练生成相应输入人脸图像的中性人脸图像,通过学习留在生成模型中间层的沉练,建立了DeRL方法 | 能缓解身份变异问题,处理自发表达和姿势表达的情况下风格和种族背景的不同 | 网络比较复杂 |
| 基于迁移学习的跨域人脸表情识别[ | 引入稀疏重构思想获取共同投影矩阵并对积,利用两个数据库(BU-4DFE和BP4D+)进行预训练,重构系数矩阵,施加 | 较好区分高兴和惊讶 | 对厌恶和生气区分度不高,同时伤心表情识别率相对较低 |
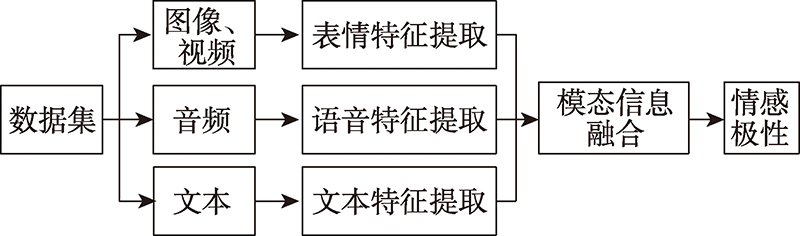
图2 多模态表情识别的框架
Fig.2 Framework of multimodal expression recognition
| 数据模态 | 数据库名称 | 标签类别 | 数据概况 | 数据来源 |
|---|---|---|---|---|
| V、PS | DEAP数据集[ | 消极到积极的9个分数 | 32名男、女测试者 | 实验室采集 |
| V、A、T | CH-SIMS数据集[ | -1(负)、0(中性)或1(正) | 2 281个长度1~10 s视频片段 | 网络视频采集 |
| YouTube数据集[ | 积极、消极、中性3种标签 | 20名女性和27名男性对产品的观点描述, 包含13个积极、22个中性以及12个消极标签的视频序列 | YouTube网采集 | |
| CASIA汉语自然情感视听数据库[ | 6类情绪标签 | 140 min情感片段,由4个专业发音人录制,共9 600句不同发音片段 | 电影、电视剧和脱口秀等采集 | |
| V、A、BM、FM、T等 | IEMOCAP数据集[ | 类别标签+维度标签 | 12 h的视听数据,通过表演激发情感表达 | 实验室采集 |
| A、V | SAVEE数据库[ | 7种情感 | 480段,4名男性演员录音 | 实验室采集 |
| eNTERFACE’05数据集[ | 6种情感标签 | 42个受试者、14个不同国籍、1 260个视频序列 | 实验室采集 | |
| ICT-MMMO数据集[ | 正面、中立和负面3种评论 | 228个正面、23个中立和119个负面的多模态电影评论视频 | YouTube、ExpoTV网采集 | |
| MOSI数据集[ | -3到+3的7类情感 | 不同年龄、不同种族的48名男性、41名女性的2~5 min的电影评论 | YouTube网采集 | |
| CMU-MOSEI数据集[ | 7类情感标签和6类情绪标签 | 含3 228个视频,共计23 453个句子 | YouTube网采集 | |
| T、I、A | NewsRoverSentiment 数据集[ | 3类情感标签 | 929个4~15 s的新闻视频组成 | 新闻视频采集 |
| V、BM、A | AFEW数据库[ | 7类情感标签 | 截取自54部好莱坞电影,含各种头部姿势、遮挡及不同照明共1 809段视频剪辑 | 自然环境下录制 |
| MED数据集[ | 7类情感标签 | 选取自电影、电视剧、直播视频等,共1 839段视频剪辑,719名受试者 | 自然环境下录制 |
表4 多模态情感数据集
Table 4 Multimodal affective datasets
| 数据模态 | 数据库名称 | 标签类别 | 数据概况 | 数据来源 |
|---|---|---|---|---|
| V、PS | DEAP数据集[ | 消极到积极的9个分数 | 32名男、女测试者 | 实验室采集 |
| V、A、T | CH-SIMS数据集[ | -1(负)、0(中性)或1(正) | 2 281个长度1~10 s视频片段 | 网络视频采集 |
| YouTube数据集[ | 积极、消极、中性3种标签 | 20名女性和27名男性对产品的观点描述, 包含13个积极、22个中性以及12个消极标签的视频序列 | YouTube网采集 | |
| CASIA汉语自然情感视听数据库[ | 6类情绪标签 | 140 min情感片段,由4个专业发音人录制,共9 600句不同发音片段 | 电影、电视剧和脱口秀等采集 | |
| V、A、BM、FM、T等 | IEMOCAP数据集[ | 类别标签+维度标签 | 12 h的视听数据,通过表演激发情感表达 | 实验室采集 |
| A、V | SAVEE数据库[ | 7种情感 | 480段,4名男性演员录音 | 实验室采集 |
| eNTERFACE’05数据集[ | 6种情感标签 | 42个受试者、14个不同国籍、1 260个视频序列 | 实验室采集 | |
| ICT-MMMO数据集[ | 正面、中立和负面3种评论 | 228个正面、23个中立和119个负面的多模态电影评论视频 | YouTube、ExpoTV网采集 | |
| MOSI数据集[ | -3到+3的7类情感 | 不同年龄、不同种族的48名男性、41名女性的2~5 min的电影评论 | YouTube网采集 | |
| CMU-MOSEI数据集[ | 7类情感标签和6类情绪标签 | 含3 228个视频,共计23 453个句子 | YouTube网采集 | |
| T、I、A | NewsRoverSentiment 数据集[ | 3类情感标签 | 929个4~15 s的新闻视频组成 | 新闻视频采集 |
| V、BM、A | AFEW数据库[ | 7类情感标签 | 截取自54部好莱坞电影,含各种头部姿势、遮挡及不同照明共1 809段视频剪辑 | 自然环境下录制 |
| MED数据集[ | 7类情感标签 | 选取自电影、电视剧、直播视频等,共1 839段视频剪辑,719名受试者 | 自然环境下录制 |
| 模态 | 表情模态识别方法 | 其他模态识别方法 | 融合方式 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 表情 视频 + 音频 | 局部二值模式提取视频特征,用随机森林模型进行面部情绪识别[ | 采用关联的特征和主成分分析法进行音频特征降维,应用连续混合高斯分布的隐马尔科夫模型进行音频识别 | 基于情绪基调对音视频识别结果进行修正,在不同情绪基调下运用线性相关性分析,进行决策层融合 | 针对单模态间情绪识别结果不一致时,融合后的识别结果不准确的问题进行改进,识别结果的准确率有一定的提升 | 仅在SEMAINE数据库进行验证 |
| 采用VGGNet-19网络进行面部表情特征提取[ | 基于先验知识对音频进行特征提取 | 采用特征直接级联结合PCA降维,并用双向长短时间记忆网络(long short-term memory,LSTM)建模 | 在AViD-Corpus及SEMAINE数据库进行验证,结果有一定改善 | 结果改善不多 | |
| 基于深度学习算法和Gabor变换相结合的面部表情连续情感识别[ | 使用梅尔频率倒谱系数提取语音情感特征,利用迁移学习,使用预训练后的神经网络模型对语音情感状态进行学习 | 考虑模态间的互补性,分析比较了多元线性回归及卡尔曼滤波两种决策层融合算法 | 与单模态比,提升识别准确性 | 无法解决伪表情的识别问题 | |
| 表情 视频 + 脑电 信号 | 使用直方图均衡化进行预处理,再用均匀模式局部二值模式算法提取人脸表情特征,并用于JAFFE数据库进行验证[ | 采用小波阈值去噪进行脑电信号预处理,用分型维数和多尺度熵算法提取脑电信号特征,用支持向量机对DEAP数据库中的脑电信号进行情绪分类 | 通过支持向量机分类器进行情绪分类 | 两个模态分别验证 | 没有在脑电和人脸表情的双模态情绪数据库上进行情绪识别分类 |
| 基于双线性卷积网络(bilinear convolution network,BCN)提取面部表情特征[ | 将脑电信号转换为三组频带图像序列,利用BCN融合图像特征,得到表情脑电信号的多模态情感特征 | 设计了一种三层双向LSTM结构的特征融合网络,融合表情和脑电特征 | 有助于提高情感识别的准确性 | 仅在Matlab上仿真,暂无法在实际环境中应用 | |
| 图像 + 眼动、音频、脑电等 | 采用深度卷积生成对抗网络进行数据增强,采用Faceness-net算法检测人脸,使用提取增强特征图的深度卷积层组成的注意感知动作单元和全连接层单元的双增强胶囊网络,利用压缩函数对人脸表情进行识别[ | 采用多模态传感器采集数据如眼动跟踪器、音频、脑电图、深度相机等,并集成到面部表情识别中 | 特征融合 | 取得较好的结果 | 模型复杂,传感器采集的数据庞大,冗余信息多 |
表5 多模态情感识别
Table 5 Multimodal emotion recognition
| 模态 | 表情模态识别方法 | 其他模态识别方法 | 融合方式 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 表情 视频 + 音频 | 局部二值模式提取视频特征,用随机森林模型进行面部情绪识别[ | 采用关联的特征和主成分分析法进行音频特征降维,应用连续混合高斯分布的隐马尔科夫模型进行音频识别 | 基于情绪基调对音视频识别结果进行修正,在不同情绪基调下运用线性相关性分析,进行决策层融合 | 针对单模态间情绪识别结果不一致时,融合后的识别结果不准确的问题进行改进,识别结果的准确率有一定的提升 | 仅在SEMAINE数据库进行验证 |
| 采用VGGNet-19网络进行面部表情特征提取[ | 基于先验知识对音频进行特征提取 | 采用特征直接级联结合PCA降维,并用双向长短时间记忆网络(long short-term memory,LSTM)建模 | 在AViD-Corpus及SEMAINE数据库进行验证,结果有一定改善 | 结果改善不多 | |
| 基于深度学习算法和Gabor变换相结合的面部表情连续情感识别[ | 使用梅尔频率倒谱系数提取语音情感特征,利用迁移学习,使用预训练后的神经网络模型对语音情感状态进行学习 | 考虑模态间的互补性,分析比较了多元线性回归及卡尔曼滤波两种决策层融合算法 | 与单模态比,提升识别准确性 | 无法解决伪表情的识别问题 | |
| 表情 视频 + 脑电 信号 | 使用直方图均衡化进行预处理,再用均匀模式局部二值模式算法提取人脸表情特征,并用于JAFFE数据库进行验证[ | 采用小波阈值去噪进行脑电信号预处理,用分型维数和多尺度熵算法提取脑电信号特征,用支持向量机对DEAP数据库中的脑电信号进行情绪分类 | 通过支持向量机分类器进行情绪分类 | 两个模态分别验证 | 没有在脑电和人脸表情的双模态情绪数据库上进行情绪识别分类 |
| 基于双线性卷积网络(bilinear convolution network,BCN)提取面部表情特征[ | 将脑电信号转换为三组频带图像序列,利用BCN融合图像特征,得到表情脑电信号的多模态情感特征 | 设计了一种三层双向LSTM结构的特征融合网络,融合表情和脑电特征 | 有助于提高情感识别的准确性 | 仅在Matlab上仿真,暂无法在实际环境中应用 | |
| 图像 + 眼动、音频、脑电等 | 采用深度卷积生成对抗网络进行数据增强,采用Faceness-net算法检测人脸,使用提取增强特征图的深度卷积层组成的注意感知动作单元和全连接层单元的双增强胶囊网络,利用压缩函数对人脸表情进行识别[ | 采用多模态传感器采集数据如眼动跟踪器、音频、脑电图、深度相机等,并集成到面部表情识别中 | 特征融合 | 取得较好的结果 | 模型复杂,传感器采集的数据庞大,冗余信息多 |
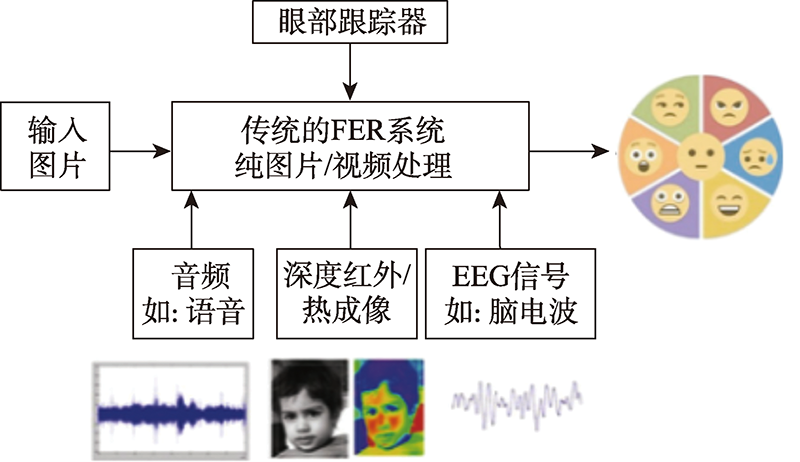
图3 视觉和非视觉传感器集成到面部表情识别
Fig.3 Integration of visual and nonvisual sensors into facial expression recognition
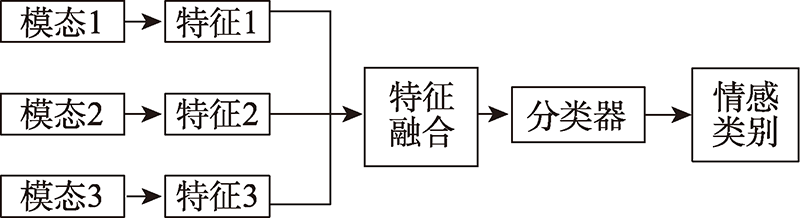
图4 特征级的融合框图
Fig.4 Fusion block diagram of feature level

图5 多模态特征提取
Fig.5 Multimodal feature extraction

图6 提取上下文相关多模态话语特征的层次结构
Fig.6 Hierarchical architecture for extracting context dependent multimodal utterance features

图7 Contextual LSTM网络
Fig.7 Contextual LSTM network
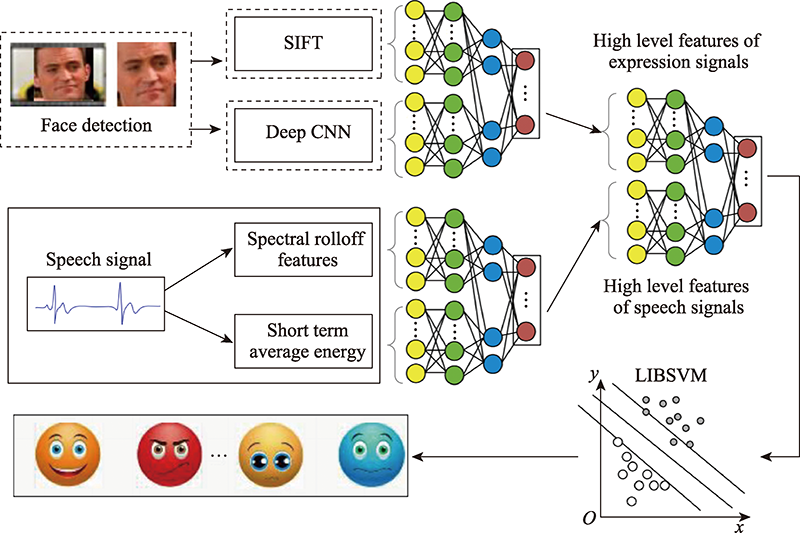
图8 多模态情感识别模型总体架构
Fig.8 Overall architecture of multimodal emotion recognition model
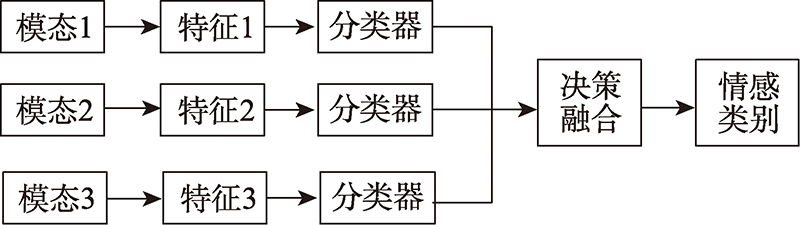
图9 决策级的融合框图
Fig.9 Fusion block diagram of decision level
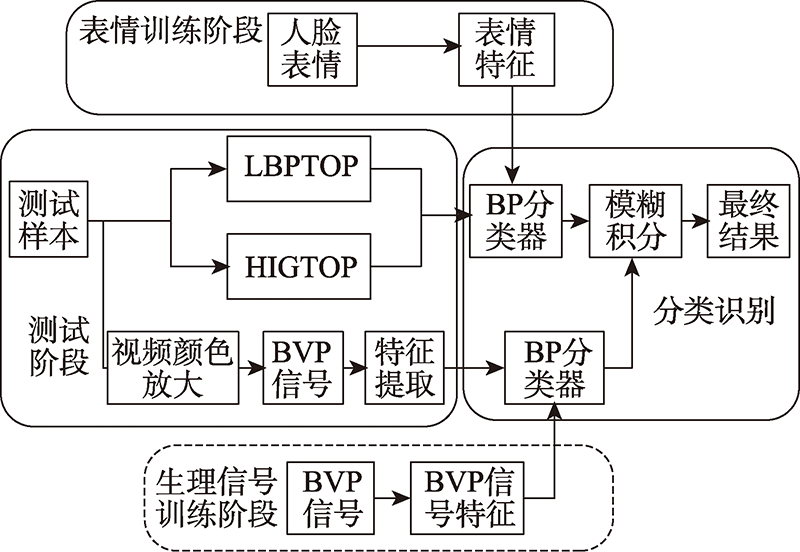
图10 双模态情感识别系统流程图
Fig.10 Flow chart of dual-modality emotion recognition
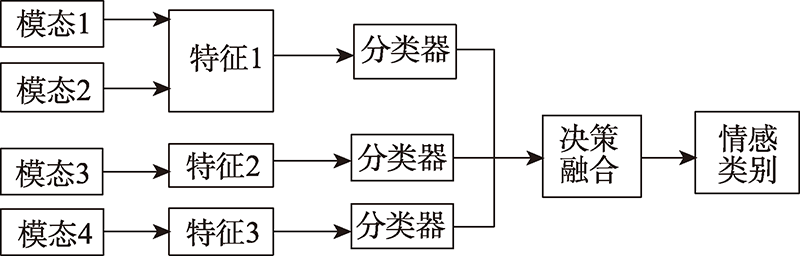
图11 混合融合框图
Fig.11 Hybrid fusion block diagram
| [1] | 蒋斌, 钟瑞, 张秋闻, 等. 采用深度学习方法的非正面表情识别综述[J]. 计算机工程与应用, 2021, 57(8): 48-61. |
| JIANG B, ZHONG R, ZHANG Q W, et al. Survey of non-frontal facial expression recognition by using deep learning methods[J]. Computer Engineering and Applications, 2021, 57(8): 48-61. | |
| [2] | 彭小江, 乔宇. 面部表情分析进展和挑战[J]. 中国图象图形学报, 2020, 25(11): 2337-2348. |
| PENG X J, QIAO Y. Advances and challenges in facial ex-pression analysis[J]. Journal of Image and Graphics, 2020, 25(11): 2337-2348. | |
| [3] | 李珊, 邓伟洪. 深度人脸表情识别研究进展[J]. 中国图象图形学报, 2020, 25(11): 2306-2320. |
| LI S, DENG W H. Deep facial expression recognition: a survey[J]. Journal of Image and Graphics, 2020, 25(11): 2306-2320. | |
| [4] | EKMAN P, ROSENBERG E L. What the face reveals: basic and applied studies of spontaneous expression using the facial action coding system (FACS)[M]. Oxford: Oxford Uni-versity Press, 1997. |
| [5] | 刘颖, 郭莹莹, 房杰, 等. 深度学习跨模态图文检索研究综述[J]. 计算机科学与探索, 2022, 16(3): 489-511. |
| LIU Y, GUO Y Y, FANG J, et al. Survey of research on deep learning image-text cross-modal retrieval[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(3): 489-511. | |
| [6] | 马永杰, 徐小冬, 张茹, 等. 生成式对抗网络及其在图像生成中的研究进展[J]. 计算机科学与探索, 2021, 15(10): 1795-1811. |
| MA Y J, XU X D, ZHANG R, et al. Generative adversarial network and its research progress in image generation[J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(10): 1795-1811. | |
| [7] | 刘颖, 张艺轩, 佘建初, 等. 人脸去遮挡新技术研究综述[J]. 计算机科学与探索, 2021, 15(10): 1773-1794. |
| LIU Y, ZHANG Y X, SHE J C, et al. Review of new face occlusion inpainting technology research[J]. Journal of Fron-tiers of Computer Science and Technology, 2021, 15(10): 1773-1794. | |
| [8] | 莫宏伟, 傅智杰. 基于迁移学习的无监督跨域人脸表情识别[J]. 智能系统学报, 2021, 16(3): 397-406. |
| MO H W, FU Z J. Unsupervised cross-domain expression recognition based on transfer learning[J]. Journal of Intelli-gent Systems, 2021, 16(3): 397-406. | |
| [9] | 刘继明, 张培翔, 刘颖, 等. 多模态的情感分析技术综述[J]. 计算机科学与探索, 2021, 15(7): 1165-1182. |
| LIU J M, ZHANG P X, LIU Y, et al. Summary of multi-modal sentiment analysis technology[J]. Journal of Fron-tiers of Computer Science and Technology, 2021, 15(7): 1165-1182. | |
| [10] | SUSSKIND J M, ANDERSON A K, HINTON G E. The To-ronto face database[D]. Toronto: University of Toronto, 2010. |
| [11] | GOODFELLOW I J, ERHAN D, CARRIER P L, et al. Chal-lenges in representation learning: a report on three machine learning contests[J]. Neural Networks, 2015, 64: 59-63. |
| [12] | WANG S F, LIU Z L, LV S L, et al. A natural visible and infrared facial expression database for expression recogni-tion and emotion inference[J]. IEEE Transactions on Multi-media, 2010, 12(7): 682-691. |
| [13] | DHALL A, GOECKE R, LUCEY S, et al. Static facial expres-sion analysis in tough conditions: data, evaluation protocol and benchmark[C]// Proceedings of the 2011 IEEE Interna-tional Conference on Computer Vision, Barcelona, Nov 6-13, 2011. Washington: IEEE Computer Society, 2011: 2106-2112. |
| [14] | GROSS R, MATTHEWS I, COHN J, et al. Multi-PIE[J]. Image and Vision Computing, 2010, 28(5): 807-813. |
| [15] | YIN L J, WEI X Z, SUN Y, et al. A 3D facial expression database for facial behavior research[C]// Proceedings of the 7th IEEE International Conference on Automatic Face and Gesture Recognition, Southampton, Apr 10-12, 2006. Washington: IEEE Computer Society, 2006: 211-216. |
| [16] | ZHAO G, HUANG X, TAINI M, et al. Facial expression recognition from near-infrared videos[J]. Image and Vision Computing, 2011, 2(9): 607-619. |
| [17] | LANGNER O, DOTSCH R, BIJLSTRA G, et al. Presen-tation and validation of the radboud faces database[J]. Cog-nition and Emotion, 2010, 24(8): 1377-1388. |
| [18] | LUNDQVIST D, FLYKT A, OHMAN A. The karolinska di-rected emotional faces (KDEF)[M/CD]. CD ROM from De-partment of Clinical Neuroscience, Psychology Section, Ka-rolinska Institutet, Sweden, 1998. |
| [19] | BENITEZ-QUIROZ C F, SRINIVASAN R, MARTINEZ A M. EmotioNet: an accurate, real-time algorithm for the au-tomatic annotation of a million facial expressions in the wild[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 5562-5570. |
| [20] | LI S, DENG W H, DU J P. Reliable crowdsourcing and deep locality preserving learning for expression recognition in the wild[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 2584-2593. |
| [21] | LI S, DENG W H. Reliable crowdsourcing and deep locality preserving learning for unconstrained facial expression recog-nition[J]. IEEE Transactions on Image Processing, 2019, 28(1): 356-370. |
| [22] | MOLLAHOSSEINI A, HASANI B, MAHOOR M H. Affect-Net: a database for facial expression, valence, and arousal computing in the wild[J]. IEEE Transactions on Affective Computing, 2019, 10(1): 18-31. |
| [23] | ZHANG Z, LUO P, CHEN C L, et al. From facial expres-sion recognition to interpersonal relation prediction[J]. International Journal of Computer Vision, 2018, 126(5): 550-569. |
| [24] | LUCEY P, COHN J F, KANADE T, et al. The extended Cohn-Kanade dataset (CK+): a complete dataset for action unit and emotion-specified expression[C]// Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, Jun 13-18, 2010. Washington: IEEE Computer Society, 2010: 94-101. |
| [25] | PANTIC M, VALSTAR M F, RADEMAKER R, et al. Web-based database for facial expression analysis[C]// Procee-dings of the 2005 IEEE International Conference on Multi-media and Expo, Amsterdam, Jul 6-9, 2005. Washington: IEEE Computer Society, 2005: 317-321. |
| [26] | VALSTAR M F, PANTIC M. Induced disgust, happiness and surprise: an addition to the MMI facial expression data-base[C]// Proceedings of the 3rd International Workshop on Emo-tion:Corpora for Research on Emotion and Affect, 2010: 65-70. |
| [27] | LYONS M J, AKAMATSU S, KAMACHI M, et al. Coding facial expressions with gabor wavelets[C]// Proceedings of the 3rd International Conference on Face & Gesture Recog-nition, Apr 14-16, 1998. Washington: IEEE Computer So-ciety, 1998: 200-205. |
| [28] | LI S, DENG W H. Deep facial expression recognition: a survey[J]. IEEE Transactions on Affective Computing, 2018. DOI: 10.1109/TAFFC.2020.2981446. |
| [29] | WOLD S, ESBENSEN K, GELADI P. Principal component analysis[J]. Chemometrics and Intelligent Laboratory Systems, 1987, 2: 37-52. |
| [30] | NIU Z G, QIU X H. Facial expression recognition based on weighted principal component analysis and support vector machines[C]// Proceedings of the 3rd International Conference on Advanced Computer Theory and Enginee-ring, Chengdu, Aug 20-22, 2010. Piscataway: IEEE, 2010: 174-178. |
| [31] | ZHU Y N, LI X X, WU G H. Face expression recognition based on equable principal component analysis and linear regression classification[C]// Proceedings of the 3rd Interna-tional Conference on Systems and Informatics, Shanghai, Nov 19-21, 2016. Piscataway: IEEE, 2016: 876-880. |
| [32] | 周书仁, 梁昔明, 朱灿, 等. 基于ICA与HMM的表情识别[J]. 中国图象图形学报, 2008, 13(12): 2321-2328. |
| ZHOU S R, LIANG X M, ZHU C, et al. Facial expression recognition based on independent component analysis and hidden Markov model[J]. Journal of Image and Graphics, 2008, 13(12): 2321-2328. | |
| [33] | OJALA T, PIETIKAINEN M, MAENPAA T. Multiresolu-tion gray-scale and rotation invariant texture classification with local binary patterns[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(7): 971-987. |
| [34] | LIAO S C, ZHU X X, LEI Z, et al. Learning multi-scale block local binary patterns for face recognition[C]// LNCS 4642: Proceedings of the 2007 International Conference on Ad-vances in Biometrics, Seoul, Aug 27-29, 2007. Berlin, Hei-delberg: Springer, 2007: 823-827. |
| [35] | KABIR M H, JABID T, CHAE O. A local directional pat-tern variance (LDPv) based face descriptor for human facial expression recognition[C]// Proceedings of the 7th IEEE International Conference on Advanced Video and Signal Based Surveillance, Boston, Aug 29-Sep 1, 2010. Washing-ton:IEEE Computer Society, 2010: 526-532. |
| [36] | JABID T, KABIR M H, CHAE O. Robust facial expression recognition based on local directional pattern[J]. ETRI Journal, 2010, 32(5): 784-794. |
| [37] | LI H, LI G M. Research on facial expression recognition based on LBP and deep learning[C]// Proceedings of the 2019 International Conference on Robots & Intelligent Sys-tem, Haikou, Jun 15-16, 2019. Piscataway: IEEE, 2019: 94-97. |
| [38] | NAGARAJA S, PRABHAKAR C J, KUMAR P P. Comp-lete local binary pattern for representation of facial expres-sion based on curvelet transform[C]// Proceedings of the 2013 International Conference on Multimedia Processing, Communication and Information Technology, 2013: 48-56. |
| [39] | WU X L, QIU Q C, LIU Z, et al. Hyphae detection in fungal keratitis images with adaptive robust binary pattern[J]. IEEE Access, 2018, 6: 13449-13460. |
| [40] | RUBEL A S, CHOWDHURY A A, KABIR M H. Facial expression recognition using adaptive robust local comp-lete pattern[C]// Proceedings of the 2019 IEEE International Conference on Image Processing, Taipei, China, Sep 22-25, 2019. Piscataway: IEEE, 2019: 41-45. |
| [41] | ZHANG Z Y, MU X M, GAO L. Recognizing facial expres-sions based on Gabor filter selection[C]// Proceedings of the 4th International Congress on Image and Signal Processing, Shanghai, Oct 15-17, 2011. Piscataway: IEEE, 2011: 1544-1548. |
| [42] | BASHYAL S, VENAYAGAMOORTHY G K. Recognition of facial expressions using Gabor wavelets and learning vector quantization[J]. Engineering Applications of Artifi-cial Intelligence, 2008, 21(7): 1056-1064. |
| [43] | ABBOUD B, DAVOINE F, DANG M. Expressive face recognition and synthesis[C]// Proceedings of the 2003 IEEE Conference on Computer Vision and Pattern Recognition, Madison, Jun 16-22, 2003. Washington: IEEE Computer Society, 2003: 54. |
| [44] | 邓洪波, 金连文. 一种基于局部Gabor滤波器组及PCA+LDA的人脸表情识别方法[J]. 中国图象图形学报, 2007, 12(2): 322-329. |
| DENG H B, JIN L W. Facial expression recognition based on local Gabor filter bank and PCA+LDA[J]. Journal of Image and Graphics, 2007, 12(2): 322-329. | |
| [45] | 姚伟, 孙正, 张岩. 面向脸部表情识别的Gabor特征选择方法[J]. 计算机辅助设计与图形学学报, 2008, 22(1): 79-84. |
| YAO W, SUN Z, ZHANG Y. Optimal Gabor feature for facial expression recognition[J]. Journal of Computer-Aided Design & Computer Graphics, 2008, 22(1): 79-84. | |
| [46] | PANTIC M, BARTLETT M S. Face recognition[M]. Vienna: I-Tech Education and Publishing, 2007. |
| [47] | COOTES T F, TAYLOR C J, COOPER D H, et al. Active shape models—their training and application[J]. Computer Vision and Image Understanding, 1995, 61(1): 38-59. |
| [48] | MATTHEWS I, BAKER S. Active appearance models revi-sited[J]. International Journal of Computer Vision, 2004, 60(2): 135-164. |
| [49] | BARMAN A, DUTTA P. Facial expression recognition using distance and shape signature features[J]. Pattern Recogni-tion Letters, 2021, 145: 254-261. |
| [50] | CHAO W L, DING J J, LIU J Z. Facial expression recog-nition based on improved local binary pattern and class-regularized locality preserving projection[J]. Signal Proces-sing, 2015, 117: 1-10. |
| [51] | AGARWAL S, MUKHERJEE D P. Facial expression recogni-tion through adaptive learning of local motion descriptor[J]. Multimedia Tools and Applications, 2017, 76(1): 1073-1099. |
| [52] | WANG X H, JIN C, LIU W, et al. Feature fusion of HOG and WLD for facial expression recognition[C]// Proceedings of the 2013 IEEE/SICE International Symposium on System Integration, Kobe, Dec 15-17, 2013. Piscataway: IEEE, 2013: 227-232. |
| [53] | LIU S S, TIAN Y T. Facial expression recognition method based on Gabor wavelet features and fractional power poly-nomial kernel PCA[C]// LNCS 6064: Proceedings of the 7th International Symposium on Neural Networks, Shanghai, Jun 6-9, 2010. Berlin, Heidelberg: Springer, 2010: 144-151. |
| [54] | 邵虹, 王洋, 王昳昀. 基于AAM和光流法的动态序列表情识别[J]. 计算机工程与设计, 2017, 38(6): 1642-1646. |
| SHAO H, WANG Y, WANG Y J. Dynamic image sequen-ces expression recognition based on active appearance model and optical flow[J]. Computer Engineering and Design, 2017, 38(6): 1642-1646. | |
| [55] | MOLLAHOSSEINI A, CHAN D, MAHOOR M H. Going deeper in facial expression recognition using deep neural networks[C]// Proceedings of the 2016 IEEE Winter Confe-rence on Applications of Computer Vision, Lake Placid, Mar 7-10, 2016. Washington: IEEE Computer Society, 2016: 1-10. |
| [56] | DING H, ZHOU S K, CHELLAPPA R.FaceNet2ExpNet: regularizing a deep face recognition net for expression recognition[C]// Proceedings of the 12th IEEE International Conference on Automatic Face & Gesture Recognition, Wa-shington, May 30-Jun 3, 2017. Washington:IEEE Com-puter Society, 2017: 118-126. |
| [57] | NG H W, NGUYEN V D, VONIKAKIS V, et al. Deep lear-ning for emotion recognition on small datasets using transfer learning[C]// Proceedings of the 2015 ACM International Con-ference on Multimodal Interaction, Seattle, Nov 9-13, 2015. New York: ACM, 2015: 443-449. |
| [58] | VERMA M, KOBORI H, NAKASHIMA Y, et al. Facial expression recognition with skip-connection to leverage low-level features[C]// Proceedings of the 2019 IEEE Inter-national Conference on Image Processing, Taipei, China, Sep 22-25, 2019. Piscataway: IEEE, 2019: 51-55. |
| [59] | LIU Y Y, DAI W, FANG F, et al. Dynamic multi-channel metric network for joint pose-aware and identity-invariant facial expression recognition[J]. Information Sciences, 2021, 578: 195-213. |
| [60] | YANG H Y, CIFTCI U A, YIN L J. Facial expression re-cognition by de-expression residue learning[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-22, 2018. Pisca-taway: IEEE, 2018: 2168-2177. |
| [61] | 张雯婧, 宋鹏, 陈栋梁, 等. 基于稀疏子空间迁移学习的跨域人脸表情识别[J]. 数据采集与处理, 2021, 36(1): 113-121. |
| ZHANG W J, SONG P, CHEN D L, et al. Cross-domain facial expression recognition based on sparse subspace transfer learning[J]. Journal of Data Acquisition & Proces-sing, 2021, 36(1): 113-121. | |
| [62] | KOELSTRA S, MUHL C, SOLEYMANI M, et al. DEAP: a database foremotion analysis using physiological signals[J]. IEEE Transactions on Affective Computing, 2011, 3(1): 18-31. |
| [63] | YU W M, XU H, MENG F Y, et al. CH-SIMS: a Chinese multimodal sentiment analysis dataset with fine-grained annotation of modality[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Jul 5-10, 2020. Stroudsburg: ACL, 2020: 3718-3727. |
| [64] | MORENCY L P, MIHALCEA R, DOSHI P. Towards multi-modal sentiment analysis: harvesting opinions from the web[C]// Proceedings of the 13th International Conference on Multimodal Interfaces, Alicante, Nov 14-18, 2011. New York: ACM, 2011: 169-176. |
| [65] | LI Y, TAO J H, CHAO L L, et al. CHEAVD: a Chinese natural emotional audio-visual database[J]. Journal of Am-bient Intelligence and Humanized Computing, 2017, 8(6): 913-924. |
| [66] | BUSSO C, BULUT M, LEE C, et al. IEMOCAP: interac-tive emotional dyadic motion capture database[J]. Jour-nal of Language Resources and Evaluation, 2008, 42(4): 335-359. |
| [67] | WU M, SU W J, CHEN L F, et al. Two-stage fuzzy fusion based-convolution neural network for dynamic emotion re-cognition[J]. IEEE Transactions on Affective Computing, 2022, 13(2): 805-817. |
| [68] | MARTIN O, KOTSIA I, MACQ B, et al. The eNTERFACE’05 audio-visual emotion database[C]// Proceedings of the 22nd International Conference on Data Engineering Workshops, Atlanta, Apr 3-7, 2006. Washington: IEEE Computer Society, 2006: 8. |
| [69] | WOLLMER M, WENINGER F, KNAUP T, et al. YouTube movie reviews: sentiment analysis in an audio-visual con-text[J]. IEEE Intelligent Systems, 2013, 28(3): 46-53. |
| [70] | ZADEH A, ZELLERS R, PINCUS E, et al. MOSI: multi-modal corpus of sentiment intensity and subjectivity analysis in online opinion videos[J]. arXiv:1606.6259, 2016. |
| [71] | ZADEH A B, LIANG P P, PORIA S, et al. Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph[C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Jul 15-20, 2018. Stroudsburg: ACL, 2018: 2236-2246. |
| [72] | ELLIS J G, JOU B, CHANG S F. Why we watch the news: a dataset for exploring sentiment in broadcast video news[C]// Proceedings of the 16th International Conference on Multimodal Interaction, Istanbul, Nov 12-16, 2014. New York: ACM, 2014: 104-111. |
| [73] | DHALL A, GOECKE R, LUCEY S, et al. Collecting large,richly annotated facial-expression databases from movies[J]. IEEE MultiMedia, 2012, 19(3): 34-41. |
| [74] | 陈静, 王科俊, 赵聪, 等. 真实环境下的多模态情感数据集MED[J]. 中国图象图形学报, 2020, 25(11): 2349-2360. |
| CHEN J, WANG K J, ZHAO C, et al. MED: multimodal emotion dataset in the wild[J]. Journal of Image and Gra-phics, 2020, 25(11): 2349-2360. | |
| [75] | 卫飞高, 张树东, 付晓慧. 基于情绪基调的音视频双模态情绪识别算法[J]. 计算机应用与软件, 2018, 35(8): 238-242. |
| WEI F G, ZHANG S D, FU X H. Audio-visual bimodal emotion recognition based on emotional tone[J]. Computer Applications and Software, 2018, 35(8): 238-242. | |
| [76] | 宋冠军, 张树东, 卫飞高. 音视频双模态情感识别融合框架研究[J]. 计算机工程与应用, 2020, 56(6): 140-146. |
| SONG G J, ZHANG S D, WEI F G. Research on audio-visual dual-modal emotion recognition fusion framework[J]. Computer Engineering and Applications, 2020, 56(6): 140-146. | |
| [77] | 张龙. 基于表情和语音的多模态情感识别及其在机器人服务任务推理中的应用[D]. 济南: 山东大学, 2021. |
| ZHANG L. Multimodal emotion recognition based on face and speech and the application in reasoning of robot service tasks[D]. Jinan: Shandong University, 2021. | |
| [78] | 沈健. 基于脑电和人脸表情的双模态情绪识别系统[D]. 南京: 南京邮电大学, 2020. |
| SHEN J. Bimodal emotion recognition system based on EEG and facial expression[D]. Nanjing: Nanjing University of Posts and Telecommunications, 2020. | |
| [79] | ZHAO Y F, CHEN D Y. Expression EEG multimodal emo-tion recognition method based on the bidirectional LSTM and attention mechanism[J]. Computational and Mathema-tical Methods in Medicine, 2021: 9967592. DOI: 10.1155/2021/9967592. |
| [80] | ULLAH A, WANG J, ANWAR M S, et al. Empirical inves-tigation of multimodal sensors in novel deep facial expres-sion recognition in-the-wild[J]. Journal of Sensors, 2021: 8893661. DOI: 10.1155/2021/8893661. |
| [81] | 何俊, 张彩庆, 李小珍, 等. 面向深度学习的多模态融合技术研究综述[J]. 计算机工程, 2020, 46(5): 1-11. |
| HE J, ZHANG C Q, LI X Z, et al. Survey of research on multimodal fusion technology for deep learning[J]. Computer Engineering, 2020, 46(5): 1-11. | |
| [82] | ZHANG C, YANG Z C, HE X D, et al. Multimodal intelli-gence: representation learning, information fusion, and app-lications[J]. IEEE Journal of Selected Topics in Signal Pro-cessing, 2020, 14(3): 478-493. |
| [83] | NEMATI S, ROHANI R, BASIRI M E, et al. A hybrid latent space data fusion method for multimodal emotion recogni-tion[J]. IEEE Access, 2019, 7: 172948-172964. |
| [84] | 陈炜青. 基于深度学习的多模态情感识别研究[D]. 济南: 山东大学, 2020. |
| CHEN W Q. Research of multi-modal emotion recognition based on deep learning[D]. Jinan: Shandong University, 2020. | |
| [85] | PEREZ-ROSAS V, MIHALCEA R, MORENCY L P. Utte-rance-level multimodal sentiment analysis[C]// Proceedings of the 51st Annual Meeting of the Association for Computa-tional Linguistics, Sofia, Aug 4-9, 2013. Stroudsburg: ACL, 2013: 973-982. |
| [86] | PORIA S, CAMBRIA E, HAZARIKA D, et al. Context-dependent sentiment analysis in user-generated videos[C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, Jul 30-Aug 4, 2017. Stroudsburg:ACL, 2017: 873-883. |
| [87] | NGUYEN D, NGUYEN K, SRIDHARAN S. Deep spatio-temporal feature fusion with compact bilinear pooling for multimodal emotion recognition[J]. Computer Vision and Image Understanding, 2018, 174(15): 33-42. |
| [88] | LIU D, CHEN L X, WANG Z Y, et al. Speech expression multimodal emotion recognition based on deep belief net-work[J]. Grid Computing, 2021, 19(2): 22. |
| [89] | PORIA S, CAMBRIA E, GELBUKH A. Deep convolutional neural network textual features and multiple kernel learning for utterance-level multimodal sentiment analysis[C]// Pro-ceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Sep 17-21, 2015. Stroudsburg: ACL, 2015: 2539-2544. |
| [90] | 任福继, 于曼丽, 胡敏, 等. 融合表情和BVP生理信号的双模态视频情感识别[J]. 中国图象图形学报, 2018, 23(5): 688-697. |
| REN F J, YU M L, HU M, et al. Dual-modality video emo-tion recognition based on facial expression and BVP phy-siological signal[J]. Journal of Image and Graphics, 2018, 23(5): 688-697. | |
| [91] | YUCEL C, ERHAN E, SEYMA C O. Cross-subject multi-modal emotion recognition based on hybrid fusion[J]. IEEE Access, 2020, 8: 168865-168878. |
| [1] | 赵小明, 杨轶娇, 张石清. 面向深度学习的多模态情感识别研究进展[J]. 计算机科学与探索, 2022, 16(7): 1479-1503. |
| [2] | 刘颖, 王哲, 房杰, 朱婷鸽, 李琳娜, 刘继明. 基于图文融合的多模态舆情分析[J]. 计算机科学与探索, 2022, 16(6): 1260-1278. |
| [3] | 包广斌, 李港乐, 王国雄. 面向多模态情感分析的双模态交互注意力[J]. 计算机科学与探索, 2022, 16(4): 909-916. |
| [4] | 刘继明, 张培翔, 刘颖, 张伟东, 房杰. 多模态的情感分析技术综述[J]. 计算机科学与探索, 2021, 15(7): 1165-1182. |
| [5] | 林克正,白婧轩,李昊天,李骜. 深度学习下融合不同模型的小样本表情识别[J]. 计算机科学与探索, 2020, 14(3): 482-492. |
| [6] | 王保加,潘海为,谢晓芹,张志强,冯晓宁. 基于多模态特征的医学图像聚类方法[J]. 计算机科学与探索, 2018, 12(3): 411-422. |
| [7] | 彭瑶,祖辰,张道强. 基于超图的多模态特征选择算法及其应用[J]. 计算机科学与探索, 2018, 12(1): 112-119. |
| [8] | 李海超,李成龙,汤进,罗斌. 热红外与可见光图像融合算法研究[J]. 计算机科学与探索, 2016, 10(3): 407-413. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||