21世纪以来的新兴信息技术对教育深化改革的重大影响
1
2019
... 随着人工智能与大数据技术的广泛应用,教育大数据与教育数据挖掘以其丰富的内涵和实用性为智能教育中相关技术的发展注入了新的动力[1].学习推荐系统是教育数据挖掘领域的重要研究方向,且被广泛地应用于各类智能学习系统[2].在智能学习系统中,学习者利用各类学习资源加入教学活动,学习资源包括课件、多媒体和模拟场景、练习题和测验,甚至适度和生动的讨论话题等.这些学习资源由于内在关系可能组合形成一个复杂的结构[3],如图1所示,在线学习系统中的各类学习资源通常源自互联网或者教师.图中的正方形、六边形、圆形以及五边形分别表示不同种类的学习资源.同类学习资源之间存在知识的前序、后继、同级的层次关系,这种层次关系也可能存在于不同种类的资源间.而即使学习资源的类型不同,也可能具有相同知识、相同来源,属于相同课程,此外,它们之间还可能存在相互引用、扩展知识的关系. ...
Significant influence of emerging information technology on deepening reformation of education in the 21st century
1
2019
... 随着人工智能与大数据技术的广泛应用,教育大数据与教育数据挖掘以其丰富的内涵和实用性为智能教育中相关技术的发展注入了新的动力[1].学习推荐系统是教育数据挖掘领域的重要研究方向,且被广泛地应用于各类智能学习系统[2].在智能学习系统中,学习者利用各类学习资源加入教学活动,学习资源包括课件、多媒体和模拟场景、练习题和测验,甚至适度和生动的讨论话题等.这些学习资源由于内在关系可能组合形成一个复杂的结构[3],如图1所示,在线学习系统中的各类学习资源通常源自互联网或者教师.图中的正方形、六边形、圆形以及五边形分别表示不同种类的学习资源.同类学习资源之间存在知识的前序、后继、同级的层次关系,这种层次关系也可能存在于不同种类的资源间.而即使学习资源的类型不同,也可能具有相同知识、相同来源,属于相同课程,此外,它们之间还可能存在相互引用、扩展知识的关系. ...
教育信息化2.0: 智能教育启程, 智慧教育领航
1
2018
... 随着人工智能与大数据技术的广泛应用,教育大数据与教育数据挖掘以其丰富的内涵和实用性为智能教育中相关技术的发展注入了新的动力[1].学习推荐系统是教育数据挖掘领域的重要研究方向,且被广泛地应用于各类智能学习系统[2].在智能学习系统中,学习者利用各类学习资源加入教学活动,学习资源包括课件、多媒体和模拟场景、练习题和测验,甚至适度和生动的讨论话题等.这些学习资源由于内在关系可能组合形成一个复杂的结构[3],如图1所示,在线学习系统中的各类学习资源通常源自互联网或者教师.图中的正方形、六边形、圆形以及五边形分别表示不同种类的学习资源.同类学习资源之间存在知识的前序、后继、同级的层次关系,这种层次关系也可能存在于不同种类的资源间.而即使学习资源的类型不同,也可能具有相同知识、相同来源,属于相同课程,此外,它们之间还可能存在相互引用、扩展知识的关系. ...
Educational informatization 2.0: starting on a journey of intelligence education guided by smart education
1
2018
... 随着人工智能与大数据技术的广泛应用,教育大数据与教育数据挖掘以其丰富的内涵和实用性为智能教育中相关技术的发展注入了新的动力[1].学习推荐系统是教育数据挖掘领域的重要研究方向,且被广泛地应用于各类智能学习系统[2].在智能学习系统中,学习者利用各类学习资源加入教学活动,学习资源包括课件、多媒体和模拟场景、练习题和测验,甚至适度和生动的讨论话题等.这些学习资源由于内在关系可能组合形成一个复杂的结构[3],如图1所示,在线学习系统中的各类学习资源通常源自互联网或者教师.图中的正方形、六边形、圆形以及五边形分别表示不同种类的学习资源.同类学习资源之间存在知识的前序、后继、同级的层次关系,这种层次关系也可能存在于不同种类的资源间.而即使学习资源的类型不同,也可能具有相同知识、相同来源,属于相同课程,此外,它们之间还可能存在相互引用、扩展知识的关系. ...
Recommender systems in e-learning environments: a survey of the state-of-the-art and possible extensions
1
2015
... 随着人工智能与大数据技术的广泛应用,教育大数据与教育数据挖掘以其丰富的内涵和实用性为智能教育中相关技术的发展注入了新的动力[1].学习推荐系统是教育数据挖掘领域的重要研究方向,且被广泛地应用于各类智能学习系统[2].在智能学习系统中,学习者利用各类学习资源加入教学活动,学习资源包括课件、多媒体和模拟场景、练习题和测验,甚至适度和生动的讨论话题等.这些学习资源由于内在关系可能组合形成一个复杂的结构[3],如图1所示,在线学习系统中的各类学习资源通常源自互联网或者教师.图中的正方形、六边形、圆形以及五边形分别表示不同种类的学习资源.同类学习资源之间存在知识的前序、后继、同级的层次关系,这种层次关系也可能存在于不同种类的资源间.而即使学习资源的类型不同,也可能具有相同知识、相同来源,属于相同课程,此外,它们之间还可能存在相互引用、扩展知识的关系. ...
Implement web learning environment based on data mining
1
2009
... 学习者通过与学习资源的交互达到认知提升的目的,但由于学习资源种类数量繁多且结构复杂,因此有必要在学习系统中嵌入个性化功能,以适应性地跟踪学习者的进展,并提供适合他们需要的学习资源[4].鉴于此,学习推荐系统(learning recommender system,LRS)应运而生.学习是一项具有综合性特征的活动,需要学习者长期持续的认知加工、情感投入乃至意志支撑.因此,与推荐系统在其他领域的应用不同,学习推荐不是为了预测或迎合学习者的潜在行为,而应该通过推荐的内容,辅助学习者在合适的学习进程中以合理的方式发现与其个性化参数相匹配的学习资源,从而保持学习者的积极性,并支持他们有效地完成学习活动[5]. ...
Smart recommendation for an evolving e-learning system: architecture and experiment
1
2003
... 学习者通过与学习资源的交互达到认知提升的目的,但由于学习资源种类数量繁多且结构复杂,因此有必要在学习系统中嵌入个性化功能,以适应性地跟踪学习者的进展,并提供适合他们需要的学习资源[4].鉴于此,学习推荐系统(learning recommender system,LRS)应运而生.学习是一项具有综合性特征的活动,需要学习者长期持续的认知加工、情感投入乃至意志支撑.因此,与推荐系统在其他领域的应用不同,学习推荐不是为了预测或迎合学习者的潜在行为,而应该通过推荐的内容,辅助学习者在合适的学习进程中以合理的方式发现与其个性化参数相匹配的学习资源,从而保持学习者的积极性,并支持他们有效地完成学习活动[5]. ...
Review of ontology-based recommender systems in e-learning
1
2019
... 对于个性化推荐系统而言,首要解决的是用户和推荐对象建模的问题.所谓用户或推荐对象的建模,即通过对用户、推荐对象显式特征的转换或潜在特征的提取,来构成能够体现其独特性或相似性的表示方式.在学习推荐系统中,用户即为学习者,其特征包括学习偏好、学习风格、知识掌握水平、知识背景等[6].学习者表示模块即通过算法将学习者在学习过程中所体现出来的个性化参数值进行有效表示,并尽量使其蕴涵更丰富的个性化语义.学习推荐对象表示模块的作用则是将推荐对象的特征提取出来,并进一步转换推荐对象模型.推荐算法模块通过处理学习者和推荐对象模型,实现推荐.但与其他个性化推荐系统不同的是,学习推荐对象可以是课件、多媒体、练习题等单一学习资源,也可以是由若干有关联的学习资源组合构成的学习路径[7].这是因为在一个完整的课程学习过程中,单一学习资源推荐可能会导致一些问题,首先是忽略了学习者对不同学习资源的偏好,只推荐一种学习资源可能会影响本身不喜欢这类资源的学习者的积极性[8],其次是忽略了学习者在学习过程中的进步和变化,从而丧失了学习推荐的引导作用[9].可见,个性化学习推荐问题在考虑学习资源与学习者个性化特征匹配的基础上,还应考虑对学习者学习效果的影响[10].参考推荐系统[11]对个性化学习推荐系统进行形式化定义:设 是学习者 的个性化参数集合,函数 表示学习者建模过程, 是学习者模型集合; 是所有可以推荐给学习者的对象 的特征集合,函数 表示推荐对象建模过程, 是推荐对象模型集合.设函数 可以用于计算推荐对象对学习者的推荐度,即 , 是一定范围内的全序的非负实数,推荐的目标就是找到推荐度 最大的那些对象 ,如式(1)所示: ...
Learning path personalization and recommendation methods: a survey of the state-of-the-art
3
2020
... 对于个性化推荐系统而言,首要解决的是用户和推荐对象建模的问题.所谓用户或推荐对象的建模,即通过对用户、推荐对象显式特征的转换或潜在特征的提取,来构成能够体现其独特性或相似性的表示方式.在学习推荐系统中,用户即为学习者,其特征包括学习偏好、学习风格、知识掌握水平、知识背景等[6].学习者表示模块即通过算法将学习者在学习过程中所体现出来的个性化参数值进行有效表示,并尽量使其蕴涵更丰富的个性化语义.学习推荐对象表示模块的作用则是将推荐对象的特征提取出来,并进一步转换推荐对象模型.推荐算法模块通过处理学习者和推荐对象模型,实现推荐.但与其他个性化推荐系统不同的是,学习推荐对象可以是课件、多媒体、练习题等单一学习资源,也可以是由若干有关联的学习资源组合构成的学习路径[7].这是因为在一个完整的课程学习过程中,单一学习资源推荐可能会导致一些问题,首先是忽略了学习者对不同学习资源的偏好,只推荐一种学习资源可能会影响本身不喜欢这类资源的学习者的积极性[8],其次是忽略了学习者在学习过程中的进步和变化,从而丧失了学习推荐的引导作用[9].可见,个性化学习推荐问题在考虑学习资源与学习者个性化特征匹配的基础上,还应考虑对学习者学习效果的影响[10].参考推荐系统[11]对个性化学习推荐系统进行形式化定义:设 是学习者 的个性化参数集合,函数 表示学习者建模过程, 是学习者模型集合; 是所有可以推荐给学习者的对象 的特征集合,函数 表示推荐对象建模过程, 是推荐对象模型集合.设函数 可以用于计算推荐对象对学习者的推荐度,即 , 是一定范围内的全序的非负实数,推荐的目标就是找到推荐度 最大的那些对象 ,如式(1)所示: ...
... 学习者建模[12,13]是构建精准、优质、个性化学习推荐系统的先决条件.学习者模型应反映多方面的、动态变化的学习者个性化参数.文献[14]总结了19项学习者个性化参数,并将其归纳为3个类别:“为何学”“学什么”以及“如何学”.其中,“为何学”类别下的参数,是将学习目标和动机视为学习者的个性化差异;“学什么”类别下的参数体现了学习本质内容,即根据学习预期达到的知识点和技能目标等作为学习者的个性化差异;“如何学”类别下包含了更丰富的个性化参数,如学习偏好、学习风格以及面向学习内容所采用教学方法的相关知识背景等,这些参数可用于体现学习者的个体化学习方案差异.对于学习推荐系统而言,可根据应用场景考虑其中一项或多项参数的组合.如在线课程学习中,学习者的目标一般是在限定的时间(三个月或一个学期)内完成学习任务且取得好成绩.为此,学习者只需关注与自己的知识背景、能力水平等参数相匹配,且可以在限定的时间内完成的学习资源;接下来,学习者会在这些学习资源中挑选符合自己学习风格偏好的那些开展学习.因此,文献[7]从学习路径推荐视角,将学习者的个性化参数设置为学习目标、技能学习、知识背景、时间限制以及学习风格五个,每个参数从属的类别如图3所示. ...
... 目前可用于评估个性化学习推荐系统的通用数据集不多,从当前研究的应用场景来看,可以分为用于课程推荐、学习资源推荐以及学习路径推荐三类.课程推荐常用到edX、Coursera、学堂在线(XuetangX)、中国慕课大学(icourse163)等在线课程平台提供的数据集,比如edX数据集可用于评估基于学习风格的课程推荐[112],XuetangX数据集可用于评估基于学习偏好的课程推荐[55],icourse163数据集可用于课程学习中的主题推荐[39].对于学习资源推荐常采用Amazon产品数据集、ASSISTment学习平台数据集等,比如学习书籍推荐使用Amazon的Book- Crossing数据集[53]、e-book数据集[63],练习题推荐使用ASSISTment数据集[42].对于学习路径推荐而言,离线方法并不能提供可靠的结果,因为其假设学习者的行为不会随时间发生变化,研究人员无法获取适用于他们实验的公共数据集[7],所以通常自组织数据集,比如文献[15]和文献[75]均使用了自组织的数据集对提出的推荐方法进行评估. ...
E-learning personalization based on hybrid recommendation strategy and learning style identification
2
2011
... 对于个性化推荐系统而言,首要解决的是用户和推荐对象建模的问题.所谓用户或推荐对象的建模,即通过对用户、推荐对象显式特征的转换或潜在特征的提取,来构成能够体现其独特性或相似性的表示方式.在学习推荐系统中,用户即为学习者,其特征包括学习偏好、学习风格、知识掌握水平、知识背景等[6].学习者表示模块即通过算法将学习者在学习过程中所体现出来的个性化参数值进行有效表示,并尽量使其蕴涵更丰富的个性化语义.学习推荐对象表示模块的作用则是将推荐对象的特征提取出来,并进一步转换推荐对象模型.推荐算法模块通过处理学习者和推荐对象模型,实现推荐.但与其他个性化推荐系统不同的是,学习推荐对象可以是课件、多媒体、练习题等单一学习资源,也可以是由若干有关联的学习资源组合构成的学习路径[7].这是因为在一个完整的课程学习过程中,单一学习资源推荐可能会导致一些问题,首先是忽略了学习者对不同学习资源的偏好,只推荐一种学习资源可能会影响本身不喜欢这类资源的学习者的积极性[8],其次是忽略了学习者在学习过程中的进步和变化,从而丧失了学习推荐的引导作用[9].可见,个性化学习推荐问题在考虑学习资源与学习者个性化特征匹配的基础上,还应考虑对学习者学习效果的影响[10].参考推荐系统[11]对个性化学习推荐系统进行形式化定义:设 是学习者 的个性化参数集合,函数 表示学习者建模过程, 是学习者模型集合; 是所有可以推荐给学习者的对象 的特征集合,函数 表示推荐对象建模过程, 是推荐对象模型集合.设函数 可以用于计算推荐对象对学习者的推荐度,即 , 是一定范围内的全序的非负实数,推荐的目标就是找到推荐度 最大的那些对象 ,如式(1)所示: ...
... 有的方法通过采集学习者在不同系统中体现的个性化参数进行学习者建模,如文献[17]将学习者在多个系统中所表现出的不同学习目标进行组合后形成学习者模型.该方法对学习者的描述是基于其在多个系统中配置文件的前 个标签,并重点描述该学习者在系统中的行为,即其最活跃的个性化特征.还有的研究通过直接调查获取个性化参数的方法进行学习者建模,比如文献[18]所提出的学习推荐模型就直接通过采集学习风格进行学习者建模,还为此开发了一套关于学习风格的在线调查表工具,使用学习风格分类法描述学习者的学习风格特征.文献[8]提出的学习推荐方法同样使用了在线问卷调查的方式收集更丰富的个性化参数,所形成的学习者模型除了学习风格之外,还包括学习者的学习进展.显式学习者建模高效直观,保留了推荐系统所需要的学习者特征,使学习者模型具有良好的可解释性,但在学习者特征缺少的情形下,显式的学习者建模方法往往失效.另一方面,当学习者与学习项目交互矩阵过于稀疏时,采用显式学习者建模方法也难以有效表现学习者与学习资源项目的交互行为特征. ...
Adaptive learning resources sequencing in educational hypermedia systems
1
2005
... 对于个性化推荐系统而言,首要解决的是用户和推荐对象建模的问题.所谓用户或推荐对象的建模,即通过对用户、推荐对象显式特征的转换或潜在特征的提取,来构成能够体现其独特性或相似性的表示方式.在学习推荐系统中,用户即为学习者,其特征包括学习偏好、学习风格、知识掌握水平、知识背景等[6].学习者表示模块即通过算法将学习者在学习过程中所体现出来的个性化参数值进行有效表示,并尽量使其蕴涵更丰富的个性化语义.学习推荐对象表示模块的作用则是将推荐对象的特征提取出来,并进一步转换推荐对象模型.推荐算法模块通过处理学习者和推荐对象模型,实现推荐.但与其他个性化推荐系统不同的是,学习推荐对象可以是课件、多媒体、练习题等单一学习资源,也可以是由若干有关联的学习资源组合构成的学习路径[7].这是因为在一个完整的课程学习过程中,单一学习资源推荐可能会导致一些问题,首先是忽略了学习者对不同学习资源的偏好,只推荐一种学习资源可能会影响本身不喜欢这类资源的学习者的积极性[8],其次是忽略了学习者在学习过程中的进步和变化,从而丧失了学习推荐的引导作用[9].可见,个性化学习推荐问题在考虑学习资源与学习者个性化特征匹配的基础上,还应考虑对学习者学习效果的影响[10].参考推荐系统[11]对个性化学习推荐系统进行形式化定义:设 是学习者 的个性化参数集合,函数 表示学习者建模过程, 是学习者模型集合; 是所有可以推荐给学习者的对象 的特征集合,函数 表示推荐对象建模过程, 是推荐对象模型集合.设函数 可以用于计算推荐对象对学习者的推荐度,即 , 是一定范围内的全序的非负实数,推荐的目标就是找到推荐度 最大的那些对象 ,如式(1)所示: ...
ThoTh Lab: a personalized learning framework for CS hands-on projects (abstract only)
1
2017
... 对于个性化推荐系统而言,首要解决的是用户和推荐对象建模的问题.所谓用户或推荐对象的建模,即通过对用户、推荐对象显式特征的转换或潜在特征的提取,来构成能够体现其独特性或相似性的表示方式.在学习推荐系统中,用户即为学习者,其特征包括学习偏好、学习风格、知识掌握水平、知识背景等[6].学习者表示模块即通过算法将学习者在学习过程中所体现出来的个性化参数值进行有效表示,并尽量使其蕴涵更丰富的个性化语义.学习推荐对象表示模块的作用则是将推荐对象的特征提取出来,并进一步转换推荐对象模型.推荐算法模块通过处理学习者和推荐对象模型,实现推荐.但与其他个性化推荐系统不同的是,学习推荐对象可以是课件、多媒体、练习题等单一学习资源,也可以是由若干有关联的学习资源组合构成的学习路径[7].这是因为在一个完整的课程学习过程中,单一学习资源推荐可能会导致一些问题,首先是忽略了学习者对不同学习资源的偏好,只推荐一种学习资源可能会影响本身不喜欢这类资源的学习者的积极性[8],其次是忽略了学习者在学习过程中的进步和变化,从而丧失了学习推荐的引导作用[9].可见,个性化学习推荐问题在考虑学习资源与学习者个性化特征匹配的基础上,还应考虑对学习者学习效果的影响[10].参考推荐系统[11]对个性化学习推荐系统进行形式化定义:设 是学习者 的个性化参数集合,函数 表示学习者建模过程, 是学习者模型集合; 是所有可以推荐给学习者的对象 的特征集合,函数 表示推荐对象建模过程, 是推荐对象模型集合.设函数 可以用于计算推荐对象对学习者的推荐度,即 , 是一定范围内的全序的非负实数,推荐的目标就是找到推荐度 最大的那些对象 ,如式(1)所示: ...
基于深度学习的推荐系统研究综述
1
2018
... 对于个性化推荐系统而言,首要解决的是用户和推荐对象建模的问题.所谓用户或推荐对象的建模,即通过对用户、推荐对象显式特征的转换或潜在特征的提取,来构成能够体现其独特性或相似性的表示方式.在学习推荐系统中,用户即为学习者,其特征包括学习偏好、学习风格、知识掌握水平、知识背景等[6].学习者表示模块即通过算法将学习者在学习过程中所体现出来的个性化参数值进行有效表示,并尽量使其蕴涵更丰富的个性化语义.学习推荐对象表示模块的作用则是将推荐对象的特征提取出来,并进一步转换推荐对象模型.推荐算法模块通过处理学习者和推荐对象模型,实现推荐.但与其他个性化推荐系统不同的是,学习推荐对象可以是课件、多媒体、练习题等单一学习资源,也可以是由若干有关联的学习资源组合构成的学习路径[7].这是因为在一个完整的课程学习过程中,单一学习资源推荐可能会导致一些问题,首先是忽略了学习者对不同学习资源的偏好,只推荐一种学习资源可能会影响本身不喜欢这类资源的学习者的积极性[8],其次是忽略了学习者在学习过程中的进步和变化,从而丧失了学习推荐的引导作用[9].可见,个性化学习推荐问题在考虑学习资源与学习者个性化特征匹配的基础上,还应考虑对学习者学习效果的影响[10].参考推荐系统[11]对个性化学习推荐系统进行形式化定义:设 是学习者 的个性化参数集合,函数 表示学习者建模过程, 是学习者模型集合; 是所有可以推荐给学习者的对象 的特征集合,函数 表示推荐对象建模过程, 是推荐对象模型集合.设函数 可以用于计算推荐对象对学习者的推荐度,即 , 是一定范围内的全序的非负实数,推荐的目标就是找到推荐度 最大的那些对象 ,如式(1)所示: ...
Survey on deep learning based recommender systems
1
2018
... 对于个性化推荐系统而言,首要解决的是用户和推荐对象建模的问题.所谓用户或推荐对象的建模,即通过对用户、推荐对象显式特征的转换或潜在特征的提取,来构成能够体现其独特性或相似性的表示方式.在学习推荐系统中,用户即为学习者,其特征包括学习偏好、学习风格、知识掌握水平、知识背景等[6].学习者表示模块即通过算法将学习者在学习过程中所体现出来的个性化参数值进行有效表示,并尽量使其蕴涵更丰富的个性化语义.学习推荐对象表示模块的作用则是将推荐对象的特征提取出来,并进一步转换推荐对象模型.推荐算法模块通过处理学习者和推荐对象模型,实现推荐.但与其他个性化推荐系统不同的是,学习推荐对象可以是课件、多媒体、练习题等单一学习资源,也可以是由若干有关联的学习资源组合构成的学习路径[7].这是因为在一个完整的课程学习过程中,单一学习资源推荐可能会导致一些问题,首先是忽略了学习者对不同学习资源的偏好,只推荐一种学习资源可能会影响本身不喜欢这类资源的学习者的积极性[8],其次是忽略了学习者在学习过程中的进步和变化,从而丧失了学习推荐的引导作用[9].可见,个性化学习推荐问题在考虑学习资源与学习者个性化特征匹配的基础上,还应考虑对学习者学习效果的影响[10].参考推荐系统[11]对个性化学习推荐系统进行形式化定义:设 是学习者 的个性化参数集合,函数 表示学习者建模过程, 是学习者模型集合; 是所有可以推荐给学习者的对象 的特征集合,函数 表示推荐对象建模过程, 是推荐对象模型集合.设函数 可以用于计算推荐对象对学习者的推荐度,即 , 是一定范围内的全序的非负实数,推荐的目标就是找到推荐度 最大的那些对象 ,如式(1)所示: ...
Predictive student modeling in educational games with multi-task learning
1
2020
... 学习者建模[12,13]是构建精准、优质、个性化学习推荐系统的先决条件.学习者模型应反映多方面的、动态变化的学习者个性化参数.文献[14]总结了19项学习者个性化参数,并将其归纳为3个类别:“为何学”“学什么”以及“如何学”.其中,“为何学”类别下的参数,是将学习目标和动机视为学习者的个性化差异;“学什么”类别下的参数体现了学习本质内容,即根据学习预期达到的知识点和技能目标等作为学习者的个性化差异;“如何学”类别下包含了更丰富的个性化参数,如学习偏好、学习风格以及面向学习内容所采用教学方法的相关知识背景等,这些参数可用于体现学习者的个体化学习方案差异.对于学习推荐系统而言,可根据应用场景考虑其中一项或多项参数的组合.如在线课程学习中,学习者的目标一般是在限定的时间(三个月或一个学期)内完成学习任务且取得好成绩.为此,学习者只需关注与自己的知识背景、能力水平等参数相匹配,且可以在限定的时间内完成的学习资源;接下来,学习者会在这些学习资源中挑选符合自己学习风格偏好的那些开展学习.因此,文献[7]从学习路径推荐视角,将学习者的个性化参数设置为学习目标、技能学习、知识背景、时间限制以及学习风格五个,每个参数从属的类别如图3所示. ...
Student modeling approaches: a literature review for the last decade
2
2013
... 学习者建模[12,13]是构建精准、优质、个性化学习推荐系统的先决条件.学习者模型应反映多方面的、动态变化的学习者个性化参数.文献[14]总结了19项学习者个性化参数,并将其归纳为3个类别:“为何学”“学什么”以及“如何学”.其中,“为何学”类别下的参数,是将学习目标和动机视为学习者的个性化差异;“学什么”类别下的参数体现了学习本质内容,即根据学习预期达到的知识点和技能目标等作为学习者的个性化差异;“如何学”类别下包含了更丰富的个性化参数,如学习偏好、学习风格以及面向学习内容所采用教学方法的相关知识背景等,这些参数可用于体现学习者的个体化学习方案差异.对于学习推荐系统而言,可根据应用场景考虑其中一项或多项参数的组合.如在线课程学习中,学习者的目标一般是在限定的时间(三个月或一个学期)内完成学习任务且取得好成绩.为此,学习者只需关注与自己的知识背景、能力水平等参数相匹配,且可以在限定的时间内完成的学习资源;接下来,学习者会在这些学习资源中挑选符合自己学习风格偏好的那些开展学习.因此,文献[7]从学习路径推荐视角,将学习者的个性化参数设置为学习目标、技能学习、知识背景、时间限制以及学习风格五个,每个参数从属的类别如图3所示. ...
... 学习者建模应能获取、表示、存储和修改学习者的特征和状态,能通过推理,对学习者进行分类和识别,使系统更充分、更准确地捕获学习者的特征和状态.Chrysafiadi等总结了九种学习者建模方法[13]:覆盖建模(overlay)、原型建模(stereotypes)、摄动建模(perturbation)、机器学习技术建模(machine learning techniques)、基于认知理论建模(cognitive theories)、基于约束的建模(constraint-based)、模糊建模(fuzzy-based)、基于贝叶斯网络建模(Bayesian networks)以及基于本体的建模(ontology-based).可以看出,学习者建模除了要体现学习者的基本属性特征(如年龄、性别等)之外,还需体现学习者的认知状态(或知识掌握状态)、情感状态等,这类状态会随着学习活动的进行而变化.近年来,随着深度学习和特征工程相关研究的发展,学习者建模方法也在发展.本文接下来将结合近几年学习者建模方法的研究进展,并从学习者特征表示的视角将其归纳为显式的学习者建模方法、隐式的学习者建模方法以及语义式的学习者建模方法,如图4所示. ...
Generalized metrics for the analysis of e-learning personalization strategies
2
2015
... 学习者建模[12,13]是构建精准、优质、个性化学习推荐系统的先决条件.学习者模型应反映多方面的、动态变化的学习者个性化参数.文献[14]总结了19项学习者个性化参数,并将其归纳为3个类别:“为何学”“学什么”以及“如何学”.其中,“为何学”类别下的参数,是将学习目标和动机视为学习者的个性化差异;“学什么”类别下的参数体现了学习本质内容,即根据学习预期达到的知识点和技能目标等作为学习者的个性化差异;“如何学”类别下包含了更丰富的个性化参数,如学习偏好、学习风格以及面向学习内容所采用教学方法的相关知识背景等,这些参数可用于体现学习者的个体化学习方案差异.对于学习推荐系统而言,可根据应用场景考虑其中一项或多项参数的组合.如在线课程学习中,学习者的目标一般是在限定的时间(三个月或一个学期)内完成学习任务且取得好成绩.为此,学习者只需关注与自己的知识背景、能力水平等参数相匹配,且可以在限定的时间内完成的学习资源;接下来,学习者会在这些学习资源中挑选符合自己学习风格偏好的那些开展学习.因此,文献[7]从学习路径推荐视角,将学习者的个性化参数设置为学习目标、技能学习、知识背景、时间限制以及学习风格五个,每个参数从属的类别如图3所示. ...
... 随着在线教育和网络技术的蓬勃发展,开放式 学习拓展了学习推荐系统的应用场景[14].在开放式的学习环境下,学习者往往会登录多个在线学习平台、学习管理平台,使用各种各样的学习资源,直接或间接地与其他学习者接触.开放式学习环境网络中的某些学习资源由于来源于不同的系统,相互之间可能存在较大的特征结构差异.为了解决这一问题,文献[80]以分布式MOOC平台为基础,将多个平台各类型学习资源整合至统一平台,其学习资源推荐方法采用了基于Apriori的改进分布式关联规则挖掘算法.文献[33]提出了一种基于分布式在线学习的视频推荐模型,该模型采用去中心化服务供应商协同工作以处理学习视频的大规模上下文数据.有的研究利用了本体在知识表示形式化方面的优势,从组成学习环境网络的异构数据中发现相似学习资源.如文献[74]提出了本体匹配的概念,通过比较不同实体的本体相似性,实现学习资源在各种学习搜索引擎和学习管理系统之间共享.此外,可以将包含多模态学习资源的在线学习平台看作异质信息网络(heterogeneity information networks,HIN)[81,82,83]的一个实例,如图12所示,由学习者、学习资源、教师等实体构成.文献[84]根据网络中实体之间的关系,提取“学习者-学习资源-学习者”“学习者-教师-学习者”等元路径,提出了基于HIN的学习资源推荐方法. ...
A learning path recommendation model based on a multidimensional knowledge graph framework for e-learning
5
2020
... 显式的建模方法是通过提取系统或文档等明显的学习者特征或偏好描述数据,构成能够体现学习者独特性或相似性的表示方式.显式的学习者建模有利于将学习者模型与个性化参数直接对应.由于存在多种学习者个性化参数,在不同的应用需求下,显式学习者建模方法所描述的学习者特征可能也不同.文献[15]从学习者对被推荐对象的偏好出发,认为在学习路径选择上,学习者更关注研究的新颖性、权威性和普及性,并基于此提出了一个学习路径推荐方法,该方法以学习路径中所配置学习资源的新颖度、流行度和权威度3个值的加权平均表示学习者模型.有的显式学习者建模方法直接采用了学习者对学习资源项目评分,如在文献[16]所提出的学习推荐模型中,将所有学习者对所有学习资源项目的评分形成一个矩阵,该矩阵的每一行即为一个学习者的向量表示. ...
... 学习推荐对象建模静态方法是指提取推荐对象显式特征中与学习推荐相关的那些来形成模型.比如直接采集学习推荐对象的文档描述,如文献[15]使用特征关键词集描述学习资源,其中包括:发表时间、引文次数、搜索频率、出版商影响以及作者影响力,然后使用加权关键词矢量方法,通过对推荐对象文档的统计分析得出对象的特征向量.直接提取文档描述虽然简单直观,但是往往难以体现推荐对象的内在差异性.有研究着眼于挖掘更深层次的特征,从推荐对象文本中提取特征,比如从简介、摘要、练习题的题干中提取.文献[53]提出了一个基于卷积神经网络(convolutional neural networks,CNN)的学习资源特征表示生成模型,提取学习资源中的文本信息(例如MOOC平台中的课程介绍、学习资源的摘要等)的特征,生成低维度的隐向量表示,该模型的结构如图9所示. ...
... 近年来基于知识图谱的学习推荐方法受到了关注.文献[75]基于学习过程中已出现知识单元、目标知识单元、知识单元依赖等构建知识图谱,从而形成多个学习路径,然后根据学习者的学习日志判断其学习进度,再向其推荐学习路径.文献[15]构建了一个以学习目标为导向的跨学习领域知识图谱,其中包括了六种语义关系,然后结合学习者的学习目标和学习资源的特征表示推荐学习路径. ...
... Summary and comparison of personalized learning recommendation methods
Table 1 | 文献 | 主要方法/技术 | 推荐策略 | 优势/局限 | 适用场景 |
| [53] | CNN | CR,基于描述文本生成的学习资源表示结合学习者偏好预测评分进行推荐 | 文本描述有利于对学习资源建模提供更丰富的特征信息 | 具有文本描述的学习资料推荐 |
| [62] | Felder-Silverman学习风格量表 | CR,基于满足规则的情况计算学习资源与学习者的相关性分数,再根据分数排序推荐 | 需要人工定义学习资源与学习者学习风格的关联规则 | 学习资料推荐 |
| [63] | Fuzzy decision tree,CNN | CR,从大量数据中识别出学习资源特征,再根据学习者的理解水平进行推荐 | 学习资源数据描述模型的性能影响推荐的效果 | 学习资料推荐 |
| [55] | BPR成对排序 | CF,通过捕获学习者对课程两两之间的偏好排序形成课程有序队列 | 由于负课程均值采样空间较大,这些课程可能不是最优 | 课程推荐 |
| [60] | Weka API的潜在语义分析 | CF,通过关键字注释将学习者与学习资源建立关联 | 使用关键字注释标签对学习者建模,标签本身源自人工设置,可能导致主观偏差 | 学习资料推荐 |
| [61] | 人工免疫系统(AIS)算法 | HR,根据过往课程学习效果对学习者建模,使用AIS聚类融合基于项目的协同过滤获得备选课程的预测矩阵 | 能够融合多种特征到学习者模型,但对冷启动的缓解效果有限 | 课程推荐 |
| [67] | 动态本体映射 | HR,采用相似结构层次的本体映射课程属性与学习者属性,根据匹配度进行推荐 | 可整合来自多个来源的信息,以提高效率和用户满意度 | 课程推荐 |
| [68] | 遗传算法 | HR,整合协同过滤推荐和基于内容推荐,并用遗传算法配置推荐系统的最优参数 | 可整合学习者与课程的多种标准,并得到最优配置结果 | 课程推荐 |
| [69] | 序列模式挖掘 | HR,基于显式特征的学习者模型进行聚类,通过序列模式挖掘完成学习资源的排序及推荐 | 有利于解决信息过载和缺乏多样性的问题 | 课程推荐 |
| [42] | 深度知识追踪、模拟退火算法 | HR,基于知识追踪模型预测学习者答题的准确度生成备选题集,再采用模拟退火算法从候选题集中抽取多样性练习题组成推荐列表 | 以学习者答题准确度为目标,并考虑所推荐练习题的多样性和新颖度 | 练习题推荐 |
| [70] | 多目标粒子群优化算法 | HR,以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐 | 考虑在给定时间规划内的多目标推荐问题 | 学习资料推荐 |
| [39] | 自注意力机制 | SR,将学习者在当前会话中所查看主题的历史记录作为输入序列,计算候选线程得分进行推荐 | 能够在没有太多特征属性情况下捕获学习者当前的选择状态 | 课程讨论线程推荐 |
| [78] | 认知诊断模型、PMF | SR,根据答题会话序列形成的认知诊断模型对学习者建模,再采用PMF预测学生的答题情况,最后根据预测结果进行练习题推荐 | 动态捕获学习者的知识掌握状态 | 练习题推荐 |
| [38] | 深度知识追踪、遗传算法 | SR,基于学习者练习答题会话序列预测学习者知识掌握水平,再通过遗传算法设置试卷各项质量指标,生成推荐试卷 | 同时动态捕获多个学习者的知识掌握状态 | 试卷推荐 |
| [46] | 本体 | KR,使用本体分别对学习者、领域知识和学习行为进行建模 | 未给出具体实现过程 | MOOC课程推荐 |
| [71] | 本体 | KR,基于本体描述所学知识点和学习目标相关性的学习资源推荐方法 | 本体中领域知识和推荐规则制定不能避免人工偏差 | 学习资料推荐 |
| [73] | 本体推理和神经网络 | KR,基于本体模型对学习者和学习资源进行水平层级分类,根据评估反馈向学习者推荐相应水平层级资源 | 能够根据学习者的水平状态动态调节推荐内容 | 课程知识概念相应资源的推荐 |
| [48] | 本体 | KR,通过半自动化方法构建了E-learning行为的标准本体.基于本体规则进行推荐 | 能够融合多种个性化参数的学习者模型 | 课程知识概念和主题的推荐 |
| [74] | 本体、语义相似度 | KR,对学习资源进行分类并基于本体生成语义表示.根据学习资源与学习者目标的语义相似度实现推荐 | 无法确保所推荐知识概念的先后顺序相关性 | 学习中的相关词汇推荐 |
| [75] | 知识图谱 | KR,基于学习过程中出现的知识单元相关要素构建知识图谱,从而形成多个学习路径,然后根据学习者的学习日志判断其学习进度,再向其推荐学习路径 | 学习路径的配置既符合规律又具有灵活性 | 学习路径推荐 |
| [15] | 知识图谱 | KR,构建了一个以学习目标为导向的跨学习领域知识图谱,其中包括了六种语义关系,然后结合学习者 的学习目标和学习资源的特征表示推荐学习路径 | 可扩展、可重用 | 跨领域学习路径推荐 |
注:CR,基于内容;CF,协同过滤;HR,混合推荐;SR,基于会话;KR,基于知识. ...
... 目前可用于评估个性化学习推荐系统的通用数据集不多,从当前研究的应用场景来看,可以分为用于课程推荐、学习资源推荐以及学习路径推荐三类.课程推荐常用到edX、Coursera、学堂在线(XuetangX)、中国慕课大学(icourse163)等在线课程平台提供的数据集,比如edX数据集可用于评估基于学习风格的课程推荐[112],XuetangX数据集可用于评估基于学习偏好的课程推荐[55],icourse163数据集可用于课程学习中的主题推荐[39].对于学习资源推荐常采用Amazon产品数据集、ASSISTment学习平台数据集等,比如学习书籍推荐使用Amazon的Book- Crossing数据集[53]、e-book数据集[63],练习题推荐使用ASSISTment数据集[42].对于学习路径推荐而言,离线方法并不能提供可靠的结果,因为其假设学习者的行为不会随时间发生变化,研究人员无法获取适用于他们实验的公共数据集[7],所以通常自组织数据集,比如文献[15]和文献[75]均使用了自组织的数据集对提出的推荐方法进行评估. ...
Recommender system for learning objects based in the fusion of social signals, interests, and preferences of learner users in ubiquitous e-learning systems
1
2019
... 显式的建模方法是通过提取系统或文档等明显的学习者特征或偏好描述数据,构成能够体现学习者独特性或相似性的表示方式.显式的学习者建模有利于将学习者模型与个性化参数直接对应.由于存在多种学习者个性化参数,在不同的应用需求下,显式学习者建模方法所描述的学习者特征可能也不同.文献[15]从学习者对被推荐对象的偏好出发,认为在学习路径选择上,学习者更关注研究的新颖性、权威性和普及性,并基于此提出了一个学习路径推荐方法,该方法以学习路径中所配置学习资源的新颖度、流行度和权威度3个值的加权平均表示学习者模型.有的显式学习者建模方法直接采用了学习者对学习资源项目评分,如在文献[16]所提出的学习推荐模型中,将所有学习者对所有学习资源项目的评分形成一个矩阵,该矩阵的每一行即为一个学习者的向量表示. ...
Contextualization, user modeling and personalization in the social web: from social tagging via context to cross-system user modeling and personalization
2
2011
... 有的方法通过采集学习者在不同系统中体现的个性化参数进行学习者建模,如文献[17]将学习者在多个系统中所表现出的不同学习目标进行组合后形成学习者模型.该方法对学习者的描述是基于其在多个系统中配置文件的前 个标签,并重点描述该学习者在系统中的行为,即其最活跃的个性化特征.还有的研究通过直接调查获取个性化参数的方法进行学习者建模,比如文献[18]所提出的学习推荐模型就直接通过采集学习风格进行学习者建模,还为此开发了一套关于学习风格的在线调查表工具,使用学习风格分类法描述学习者的学习风格特征.文献[8]提出的学习推荐方法同样使用了在线问卷调查的方式收集更丰富的个性化参数,所形成的学习者模型除了学习风格之外,还包括学习者的学习进展.显式学习者建模高效直观,保留了推荐系统所需要的学习者特征,使学习者模型具有良好的可解释性,但在学习者特征缺少的情形下,显式的学习者建模方法往往失效.另一方面,当学习者与学习项目交互矩阵过于稀疏时,采用显式学习者建模方法也难以有效表现学习者与学习资源项目的交互行为特征. ...
... 相比序列结构而言,图或网络结构更能表现学习环境下的真实情况.在基于图形结构的推荐系统中,数据以图形的形式表示,其中节点是用户、标签或资源,边是它们之间的事务或关系[17].文献[40]根据学习者、学习资源之间的关系为其添加排序标签,即以基于位置关系的排序对学习者进行表示.文献[41]提出将学习者和练习题作为实体,用边表示学习者回答练习,再根据学习者回答练习的正确率确定边的权重.文献[42]在实验部分提到了一种基于知识图谱表示的练习题推荐方法,该方法将学习者和练习题作为实体,并将学生回答练习的结果作为关系.基于知识图谱获得每个实体的低维向量,并进行关系学习,使图的结构和语义信息保持在向量中. ...
Recommendation of educational content to improve student performance: an approach based on learning styles
2
2020
... 有的方法通过采集学习者在不同系统中体现的个性化参数进行学习者建模,如文献[17]将学习者在多个系统中所表现出的不同学习目标进行组合后形成学习者模型.该方法对学习者的描述是基于其在多个系统中配置文件的前 个标签,并重点描述该学习者在系统中的行为,即其最活跃的个性化特征.还有的研究通过直接调查获取个性化参数的方法进行学习者建模,比如文献[18]所提出的学习推荐模型就直接通过采集学习风格进行学习者建模,还为此开发了一套关于学习风格的在线调查表工具,使用学习风格分类法描述学习者的学习风格特征.文献[8]提出的学习推荐方法同样使用了在线问卷调查的方式收集更丰富的个性化参数,所形成的学习者模型除了学习风格之外,还包括学习者的学习进展.显式学习者建模高效直观,保留了推荐系统所需要的学习者特征,使学习者模型具有良好的可解释性,但在学习者特征缺少的情形下,显式的学习者建模方法往往失效.另一方面,当学习者与学习项目交互矩阵过于稀疏时,采用显式学习者建模方法也难以有效表现学习者与学习资源项目的交互行为特征. ...
... 学习适用性也是学习推荐系统评估的另一个重要方面,所采取的方式比较灵活,可以通过推荐系统对学习成绩的影响,对学习积极性的影响来进行评估.在文献[105]中,首先将学习者分为三类:第一类通过所提出推荐系统获得推荐;第二类随机获得推荐;第三类没有获得推荐.然后通过比较三类学习者的成绩来开展学习适用性评估.文献[106]通过统计学习者对所推荐文章的阅读、回复和发布频率来评估推荐的适用性.文献[107]将学习者在推荐影响下参与学习活动的频率作为推荐适用性的评估依据.与文献[105]一样,文献[108]和文献[109]也都采用了“推荐前”和“推荐后”的成绩对比来评估学习适用性.其中文献[109]还预设了“适用性等级”,通过成绩提升效果来衡量推荐适用性的级别.此外,文献[108]和文献[109]还通过对学习者在使用推荐系统前后的在线时长、互动频率等进行了比较评估.文献[18]和文献[110]使用Felder-Silverman学习风格指数问卷,通过测量使用推荐系统前后学习风格变化,来评估所提出推荐系统的学习适用性.文献[111]使用“自我-同行”评估方法,应用知识指示事件(know-ledge indicating events,KIE)来评估推荐系统对于学习者知识水平的影响. ...
序列生成对抗网络在推荐系统中的应用
1
2020
... 所谓隐式学习者建模,是指将显式的学习者特征数据或行为数据经过转换计算后得到一种可以描述学习者特征的向量.该向量的组成元素看似不是特征值的直观表示,但能表达学习者特征的语义信息[19,20].由于这种向量通常被称为“隐向量”,本文将这种建模方式称为“隐式学习者建模”.隐式学习者建模是当前学习推荐系统研究的热点,主要包括基于模型的方法、基于会话的方法和基于图的方法. ...
Application of sequence generative adversarial network in recommendation system
1
2020
... 所谓隐式学习者建模,是指将显式的学习者特征数据或行为数据经过转换计算后得到一种可以描述学习者特征的向量.该向量的组成元素看似不是特征值的直观表示,但能表达学习者特征的语义信息[19,20].由于这种向量通常被称为“隐向量”,本文将这种建模方式称为“隐式学习者建模”.隐式学习者建模是当前学习推荐系统研究的热点,主要包括基于模型的方法、基于会话的方法和基于图的方法. ...
改进的哈希学习高效推荐算法
1
2020
... 所谓隐式学习者建模,是指将显式的学习者特征数据或行为数据经过转换计算后得到一种可以描述学习者特征的向量.该向量的组成元素看似不是特征值的直观表示,但能表达学习者特征的语义信息[19,20].由于这种向量通常被称为“隐向量”,本文将这种建模方式称为“隐式学习者建模”.隐式学习者建模是当前学习推荐系统研究的热点,主要包括基于模型的方法、基于会话的方法和基于图的方法. ...
Improved Hashing for efficient recommendation method
1
2020
... 所谓隐式学习者建模,是指将显式的学习者特征数据或行为数据经过转换计算后得到一种可以描述学习者特征的向量.该向量的组成元素看似不是特征值的直观表示,但能表达学习者特征的语义信息[19,20].由于这种向量通常被称为“隐向量”,本文将这种建模方式称为“隐式学习者建模”.隐式学习者建模是当前学习推荐系统研究的热点,主要包括基于模型的方法、基于会话的方法和基于图的方法. ...
Algorithms for non-negative matrix factorization
1
2000
... 矩阵分解(matrix factorization,MF)已经广泛应用于推荐系统中,它基于的假设是:用户偏好受到少量潜在因素的影响,且项目的评分取决于其每个特征因素如何应用于用户偏好[21,22].MF能够把“用户-项目”评分矩阵分解成两个或者多个低维矩阵的乘积实现维数的规约,用低维空间数据研究高维数据的性质,主要包括非负矩阵分解(non-negative matrix factorization,NMF)[23]、广义矩阵分解(generalized matrix factorization,GMF)和概率矩阵分解(probabilistic matrix factorization,PMF).其中NMF方法是把用户对项目的评分矩阵 分解成两个实值非负矩阵 和 ,使得 ,如图5所示. ...
Learning from incomplete ratings using non-negative matrix factorization
1
2006
... 矩阵分解(matrix factorization,MF)已经广泛应用于推荐系统中,它基于的假设是:用户偏好受到少量潜在因素的影响,且项目的评分取决于其每个特征因素如何应用于用户偏好[21,22].MF能够把“用户-项目”评分矩阵分解成两个或者多个低维矩阵的乘积实现维数的规约,用低维空间数据研究高维数据的性质,主要包括非负矩阵分解(non-negative matrix factorization,NMF)[23]、广义矩阵分解(generalized matrix factorization,GMF)和概率矩阵分解(probabilistic matrix factorization,PMF).其中NMF方法是把用户对项目的评分矩阵 分解成两个实值非负矩阵 和 ,使得 ,如图5所示. ...
Learning the parts of objects by non-negative matrix factorization
1
1999
... 矩阵分解(matrix factorization,MF)已经广泛应用于推荐系统中,它基于的假设是:用户偏好受到少量潜在因素的影响,且项目的评分取决于其每个特征因素如何应用于用户偏好[21,22].MF能够把“用户-项目”评分矩阵分解成两个或者多个低维矩阵的乘积实现维数的规约,用低维空间数据研究高维数据的性质,主要包括非负矩阵分解(non-negative matrix factorization,NMF)[23]、广义矩阵分解(generalized matrix factorization,GMF)和概率矩阵分解(probabilistic matrix factorization,PMF).其中NMF方法是把用户对项目的评分矩阵 分解成两个实值非负矩阵 和 ,使得 ,如图5所示. ...
Communication communities in moocs
1
2014
... 采用矩阵分解进行学习者建模,通常先根据交互数据构建值为1/0的矩阵,再将该矩阵分解为两个低维矩阵,其中一个矩阵的行数与学习者人数相同,每行即表示一个学习者的隐特征向量.凡有交互或评分行为的应用场景都可以考虑使用矩阵分解方法.比如在文献[24]中,采用了一个 的矩阵 表示学习者在论坛上的表现,其中每行表示至少在课程的在线论坛上发布一次的学习者n,每一列d表示文中所定义的学习者在论坛中五种行为维度之中的某个类别标签(比如知识构建维度中的一个类别是“观察或意见声明”).如果学习者n发布至少一个帖子分配了d的内容标签,则 的每个条目 为1,否则为0.因此, 是一个值为1/0的矩阵,然后对 采用贝叶斯非负矩阵分解(Bayesian non-negative matrix factorization,BNMF)方法生成学习者隐特征向量.文献[25]根据学习者课程学习记录,构建了“学习者-所选课程”矩阵,再采用PMF方法并假设其条件概率符合高斯分布,将选课矩阵分解为学习者和课程的隐特征向量.文献[26]首先将学习者对学习资源的点击、阅读或使用看作一次“交互”,从而形成一个“学习者-学习资源”交互矩阵.采用GMF方法将其分解为学习者和学习资源的隐特征向量,为了融入学习者与学习资源长时期交互的特征,该模型还结合长短期记忆网络(long short-term memory,LSTM)进一步生成学习者和学习资源的融合隐特征向量,并将两种特征向量进行组合后,共享同一个Sigmoid输出层.在使用过程中,将学习者与学习资源的交互记录作为输入数据,经过模型生成学习者对候选学习资源的交互概率,最后将交互概率最高的前几项学习资源推荐给学习者. ...
Probability matrix factorization algorithm for course recommendation system fusing the influence of nearest neighbor users based on cloud model
1
2018
... 采用矩阵分解进行学习者建模,通常先根据交互数据构建值为1/0的矩阵,再将该矩阵分解为两个低维矩阵,其中一个矩阵的行数与学习者人数相同,每行即表示一个学习者的隐特征向量.凡有交互或评分行为的应用场景都可以考虑使用矩阵分解方法.比如在文献[24]中,采用了一个 的矩阵 表示学习者在论坛上的表现,其中每行表示至少在课程的在线论坛上发布一次的学习者n,每一列d表示文中所定义的学习者在论坛中五种行为维度之中的某个类别标签(比如知识构建维度中的一个类别是“观察或意见声明”).如果学习者n发布至少一个帖子分配了d的内容标签,则 的每个条目 为1,否则为0.因此, 是一个值为1/0的矩阵,然后对 采用贝叶斯非负矩阵分解(Bayesian non-negative matrix factorization,BNMF)方法生成学习者隐特征向量.文献[25]根据学习者课程学习记录,构建了“学习者-所选课程”矩阵,再采用PMF方法并假设其条件概率符合高斯分布,将选课矩阵分解为学习者和课程的隐特征向量.文献[26]首先将学习者对学习资源的点击、阅读或使用看作一次“交互”,从而形成一个“学习者-学习资源”交互矩阵.采用GMF方法将其分解为学习者和学习资源的隐特征向量,为了融入学习者与学习资源长时期交互的特征,该模型还结合长短期记忆网络(long short-term memory,LSTM)进一步生成学习者和学习资源的融合隐特征向量,并将两种特征向量进行组合后,共享同一个Sigmoid输出层.在使用过程中,将学习者与学习资源的交互记录作为输入数据,经过模型生成学习者对候选学习资源的交互概率,最后将交互概率最高的前几项学习资源推荐给学习者. ...
Learning resource recommendation based on generalized matrix factorization and long short-term memory model
1
2019
... 采用矩阵分解进行学习者建模,通常先根据交互数据构建值为1/0的矩阵,再将该矩阵分解为两个低维矩阵,其中一个矩阵的行数与学习者人数相同,每行即表示一个学习者的隐特征向量.凡有交互或评分行为的应用场景都可以考虑使用矩阵分解方法.比如在文献[24]中,采用了一个 的矩阵 表示学习者在论坛上的表现,其中每行表示至少在课程的在线论坛上发布一次的学习者n,每一列d表示文中所定义的学习者在论坛中五种行为维度之中的某个类别标签(比如知识构建维度中的一个类别是“观察或意见声明”).如果学习者n发布至少一个帖子分配了d的内容标签,则 的每个条目 为1,否则为0.因此, 是一个值为1/0的矩阵,然后对 采用贝叶斯非负矩阵分解(Bayesian non-negative matrix factorization,BNMF)方法生成学习者隐特征向量.文献[25]根据学习者课程学习记录,构建了“学习者-所选课程”矩阵,再采用PMF方法并假设其条件概率符合高斯分布,将选课矩阵分解为学习者和课程的隐特征向量.文献[26]首先将学习者对学习资源的点击、阅读或使用看作一次“交互”,从而形成一个“学习者-学习资源”交互矩阵.采用GMF方法将其分解为学习者和学习资源的隐特征向量,为了融入学习者与学习资源长时期交互的特征,该模型还结合长短期记忆网络(long short-term memory,LSTM)进一步生成学习者和学习资源的融合隐特征向量,并将两种特征向量进行组合后,共享同一个Sigmoid输出层.在使用过程中,将学习者与学习资源的交互记录作为输入数据,经过模型生成学习者对候选学习资源的交互概率,最后将交互概率最高的前几项学习资源推荐给学习者. ...
Tutorial on variational autoencoders
1
2016
... 自编码器(auto-encoder)[27]是一个基于多层神经网络的特征抽取生成模型,常被用于图像图片等高维复杂数据处理,基于自编码器的嵌入方法具有特征捕捉方面的优势,近几年来在推荐系统中得到了广泛应用[28,29,30].自编码器由一个编码器(encoder)和一个解码器(decoder)组成,在模型训练时,用户xi特征先由编码器转换为低维的隐编码,再经过解码器还原为新的用户特征 ,而损失函数的构造则根据被还原的特征与输入特征的比较结果进行优化,从而学习输入数据的潜在特征表示.基本自编码器的输出层和输入层具有相同的规模,其结构如图6所示. ...
Collaborative deep learning for recommender systems
1
2015
... 自编码器(auto-encoder)[27]是一个基于多层神经网络的特征抽取生成模型,常被用于图像图片等高维复杂数据处理,基于自编码器的嵌入方法具有特征捕捉方面的优势,近几年来在推荐系统中得到了广泛应用[28,29,30].自编码器由一个编码器(encoder)和一个解码器(decoder)组成,在模型训练时,用户xi特征先由编码器转换为低维的隐编码,再经过解码器还原为新的用户特征 ,而损失函数的构造则根据被还原的特征与输入特征的比较结果进行优化,从而学习输入数据的潜在特征表示.基本自编码器的输出层和输入层具有相同的规模,其结构如图6所示. ...
Collaborative knowledge base embedding for recommender systems
1
2016
... 自编码器(auto-encoder)[27]是一个基于多层神经网络的特征抽取生成模型,常被用于图像图片等高维复杂数据处理,基于自编码器的嵌入方法具有特征捕捉方面的优势,近几年来在推荐系统中得到了广泛应用[28,29,30].自编码器由一个编码器(encoder)和一个解码器(decoder)组成,在模型训练时,用户xi特征先由编码器转换为低维的隐编码,再经过解码器还原为新的用户特征 ,而损失函数的构造则根据被还原的特征与输入特征的比较结果进行优化,从而学习输入数据的潜在特征表示.基本自编码器的输出层和输入层具有相同的规模,其结构如图6所示. ...
Collaborative variational autoencoder for recommender systems
1
2017
... 自编码器(auto-encoder)[27]是一个基于多层神经网络的特征抽取生成模型,常被用于图像图片等高维复杂数据处理,基于自编码器的嵌入方法具有特征捕捉方面的优势,近几年来在推荐系统中得到了广泛应用[28,29,30].自编码器由一个编码器(encoder)和一个解码器(decoder)组成,在模型训练时,用户xi特征先由编码器转换为低维的隐编码,再经过解码器还原为新的用户特征 ,而损失函数的构造则根据被还原的特征与输入特征的比较结果进行优化,从而学习输入数据的潜在特征表示.基本自编码器的输出层和输入层具有相同的规模,其结构如图6所示. ...
Deep exercise recommendation model
1
2019
... 文献[31]提出的练习题推荐系统中,采用了两套结构相同的堆叠降噪自编码器(stacked denoising auto-encoder,SDAE)[32]分别生成学习者隐表示和练习题的隐表示.SDAE是降噪自编码器(denoising auto-encoder,DAE)的变体,DAE的提出是为了防止过拟合,在自编码器输入层的输入数据加入噪音,使学习得到的编码器具有鲁棒性;而SDAE就是将多个DAE堆叠在一起形成一个深层网络结构,并且只在训练时才对输入进行加噪.与矩阵分解不同的是,自编码器能够将学习者多种特征所整合的高维向量进行降维,而矩阵分解则聚焦于表示学习者与学习资源的交互特征. ...
Extracting and composing robust features with denoising autoencoders
1
2008
... 文献[31]提出的练习题推荐系统中,采用了两套结构相同的堆叠降噪自编码器(stacked denoising auto-encoder,SDAE)[32]分别生成学习者隐表示和练习题的隐表示.SDAE是降噪自编码器(denoising auto-encoder,DAE)的变体,DAE的提出是为了防止过拟合,在自编码器输入层的输入数据加入噪音,使学习得到的编码器具有鲁棒性;而SDAE就是将多个DAE堆叠在一起形成一个深层网络结构,并且只在训练时才对输入进行加噪.与矩阵分解不同的是,自编码器能够将学习者多种特征所整合的高维向量进行降维,而矩阵分解则聚焦于表示学习者与学习资源的交互特征. ...
Differentially private online learning for cloud-based video recommendation with multimedia big data in social networks
2
2016
... 学习者所受到的环境影响,难以通过主观调查获得.基于上下文的学习者建模方法能够适当将学习环境的信息融入学习者模型中.比如,有研究提出从社交网络中产生的信息作为特征提取的数据来源,用以更准确捕获学习者的潜在偏好.文献[33]以多媒体为媒介,将学习者看作社交网络中多媒体资源的提供者,基于他/她所学习的多媒体资源描述文本所表达的上下文信息,使用特征袋(bag of features,BOF)算法模型[34]产生学习者的隐特征向量.另外还有研究认为,学习者作为群体中的成员也会受到所在班级环境的影响,文献[35]提出了一种基于班级上下文因素(class contextual factors,CCF)实现个性化学习推荐的方法.该方法所采用的班级上下文因素是学习者对课程知识点的掌握水平,并以此作为学习者的隐特征表示. ...
... 随着在线教育和网络技术的蓬勃发展,开放式 学习拓展了学习推荐系统的应用场景[14].在开放式的学习环境下,学习者往往会登录多个在线学习平台、学习管理平台,使用各种各样的学习资源,直接或间接地与其他学习者接触.开放式学习环境网络中的某些学习资源由于来源于不同的系统,相互之间可能存在较大的特征结构差异.为了解决这一问题,文献[80]以分布式MOOC平台为基础,将多个平台各类型学习资源整合至统一平台,其学习资源推荐方法采用了基于Apriori的改进分布式关联规则挖掘算法.文献[33]提出了一种基于分布式在线学习的视频推荐模型,该模型采用去中心化服务供应商协同工作以处理学习视频的大规模上下文数据.有的研究利用了本体在知识表示形式化方面的优势,从组成学习环境网络的异构数据中发现相似学习资源.如文献[74]提出了本体匹配的概念,通过比较不同实体的本体相似性,实现学习资源在各种学习搜索引擎和学习管理系统之间共享.此外,可以将包含多模态学习资源的在线学习平台看作异质信息网络(heterogeneity information networks,HIN)[81,82,83]的一个实例,如图12所示,由学习者、学习资源、教师等实体构成.文献[84]根据网络中实体之间的关系,提取“学习者-学习资源-学习者”“学习者-教师-学习者”等元路径,提出了基于HIN的学习资源推荐方法. ...
Bag-of-features tagging approach for a better recommendation with social big data
1
2014
... 学习者所受到的环境影响,难以通过主观调查获得.基于上下文的学习者建模方法能够适当将学习环境的信息融入学习者模型中.比如,有研究提出从社交网络中产生的信息作为特征提取的数据来源,用以更准确捕获学习者的潜在偏好.文献[33]以多媒体为媒介,将学习者看作社交网络中多媒体资源的提供者,基于他/她所学习的多媒体资源描述文本所表达的上下文信息,使用特征袋(bag of features,BOF)算法模型[34]产生学习者的隐特征向量.另外还有研究认为,学习者作为群体中的成员也会受到所在班级环境的影响,文献[35]提出了一种基于班级上下文因素(class contextual factors,CCF)实现个性化学习推荐的方法.该方法所采用的班级上下文因素是学习者对课程知识点的掌握水平,并以此作为学习者的隐特征表示. ...
Towards personalized learning through class contextual factors-based exercise recommendation
1
2018
... 学习者所受到的环境影响,难以通过主观调查获得.基于上下文的学习者建模方法能够适当将学习环境的信息融入学习者模型中.比如,有研究提出从社交网络中产生的信息作为特征提取的数据来源,用以更准确捕获学习者的潜在偏好.文献[33]以多媒体为媒介,将学习者看作社交网络中多媒体资源的提供者,基于他/她所学习的多媒体资源描述文本所表达的上下文信息,使用特征袋(bag of features,BOF)算法模型[34]产生学习者的隐特征向量.另外还有研究认为,学习者作为群体中的成员也会受到所在班级环境的影响,文献[35]提出了一种基于班级上下文因素(class contextual factors,CCF)实现个性化学习推荐的方法.该方法所采用的班级上下文因素是学习者对课程知识点的掌握水平,并以此作为学习者的隐特征表示. ...
Session-based recommendations with recurrent neural networks
1
2016
... 基于会话的推荐任务是指给定用户在会话中的上一次互动,预测用户对下一次出现项目感兴趣的可能性.对应的推荐方法采用了用户与项目在一段时间内的交互序列,因此,用于处理序列数据的模型,如循环神经网络(recurrent neural networks,RNN)[36]、Transformer[37]等被广泛使用.文献[38]根据学习者的答题记录,使用基于LSTM(RNN的一种变体)的知识追踪模型(如图7所示)预测学习者正确回答知识点的概率,由于练习题包含一个或多个知识点,可以基于此形成知识点掌握水平概率的向量表示,从而构建学习者模型. ...
Preference-aware mask for session-based recommendation with bidirectional transformer
1
2020
... 基于会话的推荐任务是指给定用户在会话中的上一次互动,预测用户对下一次出现项目感兴趣的可能性.对应的推荐方法采用了用户与项目在一段时间内的交互序列,因此,用于处理序列数据的模型,如循环神经网络(recurrent neural networks,RNN)[36]、Transformer[37]等被广泛使用.文献[38]根据学习者的答题记录,使用基于LSTM(RNN的一种变体)的知识追踪模型(如图7所示)预测学习者正确回答知识点的概率,由于练习题包含一个或多个知识点,可以基于此形成知识点掌握水平概率的向量表示,从而构建学习者模型. ...
Exam paper generation based on performance prediction of student group
3
2020
... 基于会话的推荐任务是指给定用户在会话中的上一次互动,预测用户对下一次出现项目感兴趣的可能性.对应的推荐方法采用了用户与项目在一段时间内的交互序列,因此,用于处理序列数据的模型,如循环神经网络(recurrent neural networks,RNN)[36]、Transformer[37]等被广泛使用.文献[38]根据学习者的答题记录,使用基于LSTM(RNN的一种变体)的知识追踪模型(如图7所示)预测学习者正确回答知识点的概率,由于练习题包含一个或多个知识点,可以基于此形成知识点掌握水平概率的向量表示,从而构建学习者模型. ...
... Summary and comparison of personalized learning recommendation methods
Table 1 | 文献 | 主要方法/技术 | 推荐策略 | 优势/局限 | 适用场景 |
| [53] | CNN | CR,基于描述文本生成的学习资源表示结合学习者偏好预测评分进行推荐 | 文本描述有利于对学习资源建模提供更丰富的特征信息 | 具有文本描述的学习资料推荐 |
| [62] | Felder-Silverman学习风格量表 | CR,基于满足规则的情况计算学习资源与学习者的相关性分数,再根据分数排序推荐 | 需要人工定义学习资源与学习者学习风格的关联规则 | 学习资料推荐 |
| [63] | Fuzzy decision tree,CNN | CR,从大量数据中识别出学习资源特征,再根据学习者的理解水平进行推荐 | 学习资源数据描述模型的性能影响推荐的效果 | 学习资料推荐 |
| [55] | BPR成对排序 | CF,通过捕获学习者对课程两两之间的偏好排序形成课程有序队列 | 由于负课程均值采样空间较大,这些课程可能不是最优 | 课程推荐 |
| [60] | Weka API的潜在语义分析 | CF,通过关键字注释将学习者与学习资源建立关联 | 使用关键字注释标签对学习者建模,标签本身源自人工设置,可能导致主观偏差 | 学习资料推荐 |
| [61] | 人工免疫系统(AIS)算法 | HR,根据过往课程学习效果对学习者建模,使用AIS聚类融合基于项目的协同过滤获得备选课程的预测矩阵 | 能够融合多种特征到学习者模型,但对冷启动的缓解效果有限 | 课程推荐 |
| [67] | 动态本体映射 | HR,采用相似结构层次的本体映射课程属性与学习者属性,根据匹配度进行推荐 | 可整合来自多个来源的信息,以提高效率和用户满意度 | 课程推荐 |
| [68] | 遗传算法 | HR,整合协同过滤推荐和基于内容推荐,并用遗传算法配置推荐系统的最优参数 | 可整合学习者与课程的多种标准,并得到最优配置结果 | 课程推荐 |
| [69] | 序列模式挖掘 | HR,基于显式特征的学习者模型进行聚类,通过序列模式挖掘完成学习资源的排序及推荐 | 有利于解决信息过载和缺乏多样性的问题 | 课程推荐 |
| [42] | 深度知识追踪、模拟退火算法 | HR,基于知识追踪模型预测学习者答题的准确度生成备选题集,再采用模拟退火算法从候选题集中抽取多样性练习题组成推荐列表 | 以学习者答题准确度为目标,并考虑所推荐练习题的多样性和新颖度 | 练习题推荐 |
| [70] | 多目标粒子群优化算法 | HR,以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐 | 考虑在给定时间规划内的多目标推荐问题 | 学习资料推荐 |
| [39] | 自注意力机制 | SR,将学习者在当前会话中所查看主题的历史记录作为输入序列,计算候选线程得分进行推荐 | 能够在没有太多特征属性情况下捕获学习者当前的选择状态 | 课程讨论线程推荐 |
| [78] | 认知诊断模型、PMF | SR,根据答题会话序列形成的认知诊断模型对学习者建模,再采用PMF预测学生的答题情况,最后根据预测结果进行练习题推荐 | 动态捕获学习者的知识掌握状态 | 练习题推荐 |
| [38] | 深度知识追踪、遗传算法 | SR,基于学习者练习答题会话序列预测学习者知识掌握水平,再通过遗传算法设置试卷各项质量指标,生成推荐试卷 | 同时动态捕获多个学习者的知识掌握状态 | 试卷推荐 |
| [46] | 本体 | KR,使用本体分别对学习者、领域知识和学习行为进行建模 | 未给出具体实现过程 | MOOC课程推荐 |
| [71] | 本体 | KR,基于本体描述所学知识点和学习目标相关性的学习资源推荐方法 | 本体中领域知识和推荐规则制定不能避免人工偏差 | 学习资料推荐 |
| [73] | 本体推理和神经网络 | KR,基于本体模型对学习者和学习资源进行水平层级分类,根据评估反馈向学习者推荐相应水平层级资源 | 能够根据学习者的水平状态动态调节推荐内容 | 课程知识概念相应资源的推荐 |
| [48] | 本体 | KR,通过半自动化方法构建了E-learning行为的标准本体.基于本体规则进行推荐 | 能够融合多种个性化参数的学习者模型 | 课程知识概念和主题的推荐 |
| [74] | 本体、语义相似度 | KR,对学习资源进行分类并基于本体生成语义表示.根据学习资源与学习者目标的语义相似度实现推荐 | 无法确保所推荐知识概念的先后顺序相关性 | 学习中的相关词汇推荐 |
| [75] | 知识图谱 | KR,基于学习过程中出现的知识单元相关要素构建知识图谱,从而形成多个学习路径,然后根据学习者的学习日志判断其学习进度,再向其推荐学习路径 | 学习路径的配置既符合规律又具有灵活性 | 学习路径推荐 |
| [15] | 知识图谱 | KR,构建了一个以学习目标为导向的跨学习领域知识图谱,其中包括了六种语义关系,然后结合学习者 的学习目标和学习资源的特征表示推荐学习路径 | 可扩展、可重用 | 跨领域学习路径推荐 |
注:CR,基于内容;CF,协同过滤;HR,混合推荐;SR,基于会话;KR,基于知识. ...
... 推荐系统的核心性能是推荐的准确性,即推荐预测值与真值的接近或误差程度.主要包括推荐预测的精度(accuracy)、召回率(recall)、F1分数、平均绝对误差(mean absolute error,MAE)、均方根误差(root mean square error,RMSE)等.有的研究同时采用多个指标的组合方式,以达到多角度评估的目的.比如文献[60]和文献[93]对所提出的推荐算法分别进行了精度、召回率和F1分数的评估.文献[38]使用了召回率和排序质量的指标(normalized discounted cumulative gain,NDCG),因为NDCG是一个有位置感知的度量标准,它能为推荐项目的排名列表更高位置的项目分配更高的分值,从而测量推荐列表的质量.在实际应用中,也可以对系统的性能进行单个指标上的评估,如文献[94]只采用了F1分数,因为F1分数可以看作精度和召回率的一种调和平均,被认为能够同时兼顾精度和召回率.也有的研究从误差的角度来评估推荐系统性能,比如文献[93]和文献[95]采用了平均误差(MAE),文献[96]和文献[97]则使用均方根误差(RMSE).虽然大部分推荐系统性能评估的指标可以用于学习推荐系统的性能评估,但是对于性能的评估只是学习推荐系统评估的角度之一. ...
STR-SA: session-based thread recommendation for online course forum with self-attention
4
2020
... 近年来,注意力机制(attention mechanism)受到了推荐模型研究的关注,传统的注意力机制是面向源端和目标端的隐变量的计算,从而得到源端输入与目标端输出之间的依赖关系.自注意力机制 (self-attention mechanism)是一种常用的注意力机制,它首先分别在源端和目标端进行,捕捉源端或目标端自身的隐变量之间的依赖关系;然后将源端和目标端的注意力结合,捕捉源端和目标端之间隐变量的依赖关系.因此,自注意力机制不仅可以得到源端与目标端隐变量之间的依赖关系,同时还可以有效获取源端或目标端隐变量之间的依赖关系.文献[39]使用自注意力机制,根据学习者在课程中的浏览点击记录,分别捕获查询、键和值的上下文信息,进一步生成注意力向量,表示会话中的线程.基于自注意力机制的表示生成模型如图8所示. ...
... CBR基于用户和项目的静态特征,而CFR则依赖长期的“用户-项目”交互历史数据,两者都在一定程度上忽略了用户近期状态的变化,这会导致用户当前真实状态被长期平均情况所掩盖.而且,CBR和CFR通常将一个基础交互单元(如评分、点击等)分解为多个“用户-项目”的交互对记录,并将这些记录混合,这样显然不利于保留用户在交互事件中所隐含的“状态转移”.此外,在实际应用场景中,用户信息往往并不完全,并且只有处于正在进行会话中的用户行为更能体现其当前状态.因此,能对有限范围内(一个会话)的行为进行建模是提高推荐质量的有效途径.近年来,基于会话(session-based)的推荐方法[77]成为研究热点.采用基于会话的方法,能捕获用户状态的变化,并将其更好地应用于推荐模型的训练.文献[39]提出了一种基于会话的MOOC课程讨论线程推荐方法,该方法将学习者在当前会话中所查看主题的历史记录作为输入序列,通过模型计算候选线程的推荐得分,最后输出得分最高的前几个线程组成推荐列表.在学习推荐场景下,除了偏好可能会随着学习过程而发生变化之外,学习者的知识掌握状态也在学习过程中不断变化,知识掌握状态是学习发展的核心因素.文献[78]提出了一种基于认知诊断模型预测学习者知识掌握状态的个性化练习题推荐方法,该方法根据学生的答题会话记录所形成的认知诊断模型表示学习者知识掌握状态,再采用PMF预测学生的答题情况,最后根据预测结果进行练习题推荐.文献[42]提出的练习题推荐方法采用深度知识追踪(deep knowledge tracing,DKT)[79]模型捕获学习者知识掌握状态变化,并用知识点掌握概率为学习者建模;采用 LSTM模型预测知识点出现概率并以此对练习题建模.在形成学习者和练习题的表示后,通过匹配、筛选和排序生成练习题推荐列表. ...
... Summary and comparison of personalized learning recommendation methods
Table 1 | 文献 | 主要方法/技术 | 推荐策略 | 优势/局限 | 适用场景 |
| [53] | CNN | CR,基于描述文本生成的学习资源表示结合学习者偏好预测评分进行推荐 | 文本描述有利于对学习资源建模提供更丰富的特征信息 | 具有文本描述的学习资料推荐 |
| [62] | Felder-Silverman学习风格量表 | CR,基于满足规则的情况计算学习资源与学习者的相关性分数,再根据分数排序推荐 | 需要人工定义学习资源与学习者学习风格的关联规则 | 学习资料推荐 |
| [63] | Fuzzy decision tree,CNN | CR,从大量数据中识别出学习资源特征,再根据学习者的理解水平进行推荐 | 学习资源数据描述模型的性能影响推荐的效果 | 学习资料推荐 |
| [55] | BPR成对排序 | CF,通过捕获学习者对课程两两之间的偏好排序形成课程有序队列 | 由于负课程均值采样空间较大,这些课程可能不是最优 | 课程推荐 |
| [60] | Weka API的潜在语义分析 | CF,通过关键字注释将学习者与学习资源建立关联 | 使用关键字注释标签对学习者建模,标签本身源自人工设置,可能导致主观偏差 | 学习资料推荐 |
| [61] | 人工免疫系统(AIS)算法 | HR,根据过往课程学习效果对学习者建模,使用AIS聚类融合基于项目的协同过滤获得备选课程的预测矩阵 | 能够融合多种特征到学习者模型,但对冷启动的缓解效果有限 | 课程推荐 |
| [67] | 动态本体映射 | HR,采用相似结构层次的本体映射课程属性与学习者属性,根据匹配度进行推荐 | 可整合来自多个来源的信息,以提高效率和用户满意度 | 课程推荐 |
| [68] | 遗传算法 | HR,整合协同过滤推荐和基于内容推荐,并用遗传算法配置推荐系统的最优参数 | 可整合学习者与课程的多种标准,并得到最优配置结果 | 课程推荐 |
| [69] | 序列模式挖掘 | HR,基于显式特征的学习者模型进行聚类,通过序列模式挖掘完成学习资源的排序及推荐 | 有利于解决信息过载和缺乏多样性的问题 | 课程推荐 |
| [42] | 深度知识追踪、模拟退火算法 | HR,基于知识追踪模型预测学习者答题的准确度生成备选题集,再采用模拟退火算法从候选题集中抽取多样性练习题组成推荐列表 | 以学习者答题准确度为目标,并考虑所推荐练习题的多样性和新颖度 | 练习题推荐 |
| [70] | 多目标粒子群优化算法 | HR,以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐 | 考虑在给定时间规划内的多目标推荐问题 | 学习资料推荐 |
| [39] | 自注意力机制 | SR,将学习者在当前会话中所查看主题的历史记录作为输入序列,计算候选线程得分进行推荐 | 能够在没有太多特征属性情况下捕获学习者当前的选择状态 | 课程讨论线程推荐 |
| [78] | 认知诊断模型、PMF | SR,根据答题会话序列形成的认知诊断模型对学习者建模,再采用PMF预测学生的答题情况,最后根据预测结果进行练习题推荐 | 动态捕获学习者的知识掌握状态 | 练习题推荐 |
| [38] | 深度知识追踪、遗传算法 | SR,基于学习者练习答题会话序列预测学习者知识掌握水平,再通过遗传算法设置试卷各项质量指标,生成推荐试卷 | 同时动态捕获多个学习者的知识掌握状态 | 试卷推荐 |
| [46] | 本体 | KR,使用本体分别对学习者、领域知识和学习行为进行建模 | 未给出具体实现过程 | MOOC课程推荐 |
| [71] | 本体 | KR,基于本体描述所学知识点和学习目标相关性的学习资源推荐方法 | 本体中领域知识和推荐规则制定不能避免人工偏差 | 学习资料推荐 |
| [73] | 本体推理和神经网络 | KR,基于本体模型对学习者和学习资源进行水平层级分类,根据评估反馈向学习者推荐相应水平层级资源 | 能够根据学习者的水平状态动态调节推荐内容 | 课程知识概念相应资源的推荐 |
| [48] | 本体 | KR,通过半自动化方法构建了E-learning行为的标准本体.基于本体规则进行推荐 | 能够融合多种个性化参数的学习者模型 | 课程知识概念和主题的推荐 |
| [74] | 本体、语义相似度 | KR,对学习资源进行分类并基于本体生成语义表示.根据学习资源与学习者目标的语义相似度实现推荐 | 无法确保所推荐知识概念的先后顺序相关性 | 学习中的相关词汇推荐 |
| [75] | 知识图谱 | KR,基于学习过程中出现的知识单元相关要素构建知识图谱,从而形成多个学习路径,然后根据学习者的学习日志判断其学习进度,再向其推荐学习路径 | 学习路径的配置既符合规律又具有灵活性 | 学习路径推荐 |
| [15] | 知识图谱 | KR,构建了一个以学习目标为导向的跨学习领域知识图谱,其中包括了六种语义关系,然后结合学习者 的学习目标和学习资源的特征表示推荐学习路径 | 可扩展、可重用 | 跨领域学习路径推荐 |
注:CR,基于内容;CF,协同过滤;HR,混合推荐;SR,基于会话;KR,基于知识. ...
... 目前可用于评估个性化学习推荐系统的通用数据集不多,从当前研究的应用场景来看,可以分为用于课程推荐、学习资源推荐以及学习路径推荐三类.课程推荐常用到edX、Coursera、学堂在线(XuetangX)、中国慕课大学(icourse163)等在线课程平台提供的数据集,比如edX数据集可用于评估基于学习风格的课程推荐[112],XuetangX数据集可用于评估基于学习偏好的课程推荐[55],icourse163数据集可用于课程学习中的主题推荐[39].对于学习资源推荐常采用Amazon产品数据集、ASSISTment学习平台数据集等,比如学习书籍推荐使用Amazon的Book- Crossing数据集[53]、e-book数据集[63],练习题推荐使用ASSISTment数据集[42].对于学习路径推荐而言,离线方法并不能提供可靠的结果,因为其假设学习者的行为不会随时间发生变化,研究人员无法获取适用于他们实验的公共数据集[7],所以通常自组织数据集,比如文献[15]和文献[75]均使用了自组织的数据集对提出的推荐方法进行评估. ...
Exploiting semantic information for graph-based recommendations of learning resources
1
2012
... 相比序列结构而言,图或网络结构更能表现学习环境下的真实情况.在基于图形结构的推荐系统中,数据以图形的形式表示,其中节点是用户、标签或资源,边是它们之间的事务或关系[17].文献[40]根据学习者、学习资源之间的关系为其添加排序标签,即以基于位置关系的排序对学习者进行表示.文献[41]提出将学习者和练习题作为实体,用边表示学习者回答练习,再根据学习者回答练习的正确率确定边的权重.文献[42]在实验部分提到了一种基于知识图谱表示的练习题推荐方法,该方法将学习者和练习题作为实体,并将学生回答练习的结果作为关系.基于知识图谱获得每个实体的低维向量,并进行关系学习,使图的结构和语义信息保持在向量中. ...
Utilizing knowledge graph and student testing behavior data for personalized exercise recommendation
1
2018
... 相比序列结构而言,图或网络结构更能表现学习环境下的真实情况.在基于图形结构的推荐系统中,数据以图形的形式表示,其中节点是用户、标签或资源,边是它们之间的事务或关系[17].文献[40]根据学习者、学习资源之间的关系为其添加排序标签,即以基于位置关系的排序对学习者进行表示.文献[41]提出将学习者和练习题作为实体,用边表示学习者回答练习,再根据学习者回答练习的正确率确定边的权重.文献[42]在实验部分提到了一种基于知识图谱表示的练习题推荐方法,该方法将学习者和练习题作为实体,并将学生回答练习的结果作为关系.基于知识图谱获得每个实体的低维向量,并进行关系学习,使图的结构和语义信息保持在向量中. ...
Exercise recommendation based on knowledge concept prediction
7
2020
... 相比序列结构而言,图或网络结构更能表现学习环境下的真实情况.在基于图形结构的推荐系统中,数据以图形的形式表示,其中节点是用户、标签或资源,边是它们之间的事务或关系[17].文献[40]根据学习者、学习资源之间的关系为其添加排序标签,即以基于位置关系的排序对学习者进行表示.文献[41]提出将学习者和练习题作为实体,用边表示学习者回答练习,再根据学习者回答练习的正确率确定边的权重.文献[42]在实验部分提到了一种基于知识图谱表示的练习题推荐方法,该方法将学习者和练习题作为实体,并将学生回答练习的结果作为关系.基于知识图谱获得每个实体的低维向量,并进行关系学习,使图的结构和语义信息保持在向量中. ...
... 混合学习推荐方法(HR)是将多种学习推荐相结合的方法,以达到提高推荐准确度,以及缓解单一推荐方法所可能出现的如矩阵稀疏、冷启动等问题的目的.混合推荐方法最初是将基于内容的推荐方法与协同过滤推荐方法结合,并优化结合策略.如文献[67]提出了一种基于内容推荐和协同过滤推荐的混合方法用于课程推荐,该方法利用本体来克服信息超载问题,即采用相似结构层次的本体来映射课程的属性结构与学习者的特征结构.文献[61]提出了一种采用人工免疫系统算法融合基于内容推荐与协同过滤推荐的课程推荐方法,该方法以学习者的课程学习效果为目标,根据过往课程的学习效果为学习者建模.然后运用免疫网络理论中亲和性与扩展图的概念设计算法,计算学习者与课程的“亲和度”从而实施推荐.对混合学习推荐的研究具有灵活性,可以通过调整其涉及的下级推荐方法,或者优化混合的策略来提升推荐的质量.文献[68]提出了一种采用遗传算法整合多种推荐策略的课程推荐方法,该方法将定制的遗传算法应用于推荐的前置阶段,利用训练数据优化推荐系统的参数配置,然后用该配置构建推荐系统模型.文献[69]提出了一种混合过滤推荐方法,以提高学习推荐的个性化和多样性.该方法首先采用显式学习者建模方法,尽可能丰富学习者的特征描述,然后运用自组织推荐策略进行学习者聚类,最后通过顺序模式挖掘完成学习资源的排序及推荐.文献[42]提出的练习题推荐方法中,融合了基于会话的推荐方法和模拟退火算法,以在保障推荐准确性的同时改善推荐的多样性和新颖度.文献[70]提出了一种基于多目标粒子群优化算法的学习推荐方法,该方法以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐. ...
... CBR基于用户和项目的静态特征,而CFR则依赖长期的“用户-项目”交互历史数据,两者都在一定程度上忽略了用户近期状态的变化,这会导致用户当前真实状态被长期平均情况所掩盖.而且,CBR和CFR通常将一个基础交互单元(如评分、点击等)分解为多个“用户-项目”的交互对记录,并将这些记录混合,这样显然不利于保留用户在交互事件中所隐含的“状态转移”.此外,在实际应用场景中,用户信息往往并不完全,并且只有处于正在进行会话中的用户行为更能体现其当前状态.因此,能对有限范围内(一个会话)的行为进行建模是提高推荐质量的有效途径.近年来,基于会话(session-based)的推荐方法[77]成为研究热点.采用基于会话的方法,能捕获用户状态的变化,并将其更好地应用于推荐模型的训练.文献[39]提出了一种基于会话的MOOC课程讨论线程推荐方法,该方法将学习者在当前会话中所查看主题的历史记录作为输入序列,通过模型计算候选线程的推荐得分,最后输出得分最高的前几个线程组成推荐列表.在学习推荐场景下,除了偏好可能会随着学习过程而发生变化之外,学习者的知识掌握状态也在学习过程中不断变化,知识掌握状态是学习发展的核心因素.文献[78]提出了一种基于认知诊断模型预测学习者知识掌握状态的个性化练习题推荐方法,该方法根据学生的答题会话记录所形成的认知诊断模型表示学习者知识掌握状态,再采用PMF预测学生的答题情况,最后根据预测结果进行练习题推荐.文献[42]提出的练习题推荐方法采用深度知识追踪(deep knowledge tracing,DKT)[79]模型捕获学习者知识掌握状态变化,并用知识点掌握概率为学习者建模;采用 LSTM模型预测知识点出现概率并以此对练习题建模.在形成学习者和练习题的表示后,通过匹配、筛选和排序生成练习题推荐列表. ...
... Summary and comparison of personalized learning recommendation methods
Table 1 | 文献 | 主要方法/技术 | 推荐策略 | 优势/局限 | 适用场景 |
| [53] | CNN | CR,基于描述文本生成的学习资源表示结合学习者偏好预测评分进行推荐 | 文本描述有利于对学习资源建模提供更丰富的特征信息 | 具有文本描述的学习资料推荐 |
| [62] | Felder-Silverman学习风格量表 | CR,基于满足规则的情况计算学习资源与学习者的相关性分数,再根据分数排序推荐 | 需要人工定义学习资源与学习者学习风格的关联规则 | 学习资料推荐 |
| [63] | Fuzzy decision tree,CNN | CR,从大量数据中识别出学习资源特征,再根据学习者的理解水平进行推荐 | 学习资源数据描述模型的性能影响推荐的效果 | 学习资料推荐 |
| [55] | BPR成对排序 | CF,通过捕获学习者对课程两两之间的偏好排序形成课程有序队列 | 由于负课程均值采样空间较大,这些课程可能不是最优 | 课程推荐 |
| [60] | Weka API的潜在语义分析 | CF,通过关键字注释将学习者与学习资源建立关联 | 使用关键字注释标签对学习者建模,标签本身源自人工设置,可能导致主观偏差 | 学习资料推荐 |
| [61] | 人工免疫系统(AIS)算法 | HR,根据过往课程学习效果对学习者建模,使用AIS聚类融合基于项目的协同过滤获得备选课程的预测矩阵 | 能够融合多种特征到学习者模型,但对冷启动的缓解效果有限 | 课程推荐 |
| [67] | 动态本体映射 | HR,采用相似结构层次的本体映射课程属性与学习者属性,根据匹配度进行推荐 | 可整合来自多个来源的信息,以提高效率和用户满意度 | 课程推荐 |
| [68] | 遗传算法 | HR,整合协同过滤推荐和基于内容推荐,并用遗传算法配置推荐系统的最优参数 | 可整合学习者与课程的多种标准,并得到最优配置结果 | 课程推荐 |
| [69] | 序列模式挖掘 | HR,基于显式特征的学习者模型进行聚类,通过序列模式挖掘完成学习资源的排序及推荐 | 有利于解决信息过载和缺乏多样性的问题 | 课程推荐 |
| [42] | 深度知识追踪、模拟退火算法 | HR,基于知识追踪模型预测学习者答题的准确度生成备选题集,再采用模拟退火算法从候选题集中抽取多样性练习题组成推荐列表 | 以学习者答题准确度为目标,并考虑所推荐练习题的多样性和新颖度 | 练习题推荐 |
| [70] | 多目标粒子群优化算法 | HR,以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐 | 考虑在给定时间规划内的多目标推荐问题 | 学习资料推荐 |
| [39] | 自注意力机制 | SR,将学习者在当前会话中所查看主题的历史记录作为输入序列,计算候选线程得分进行推荐 | 能够在没有太多特征属性情况下捕获学习者当前的选择状态 | 课程讨论线程推荐 |
| [78] | 认知诊断模型、PMF | SR,根据答题会话序列形成的认知诊断模型对学习者建模,再采用PMF预测学生的答题情况,最后根据预测结果进行练习题推荐 | 动态捕获学习者的知识掌握状态 | 练习题推荐 |
| [38] | 深度知识追踪、遗传算法 | SR,基于学习者练习答题会话序列预测学习者知识掌握水平,再通过遗传算法设置试卷各项质量指标,生成推荐试卷 | 同时动态捕获多个学习者的知识掌握状态 | 试卷推荐 |
| [46] | 本体 | KR,使用本体分别对学习者、领域知识和学习行为进行建模 | 未给出具体实现过程 | MOOC课程推荐 |
| [71] | 本体 | KR,基于本体描述所学知识点和学习目标相关性的学习资源推荐方法 | 本体中领域知识和推荐规则制定不能避免人工偏差 | 学习资料推荐 |
| [73] | 本体推理和神经网络 | KR,基于本体模型对学习者和学习资源进行水平层级分类,根据评估反馈向学习者推荐相应水平层级资源 | 能够根据学习者的水平状态动态调节推荐内容 | 课程知识概念相应资源的推荐 |
| [48] | 本体 | KR,通过半自动化方法构建了E-learning行为的标准本体.基于本体规则进行推荐 | 能够融合多种个性化参数的学习者模型 | 课程知识概念和主题的推荐 |
| [74] | 本体、语义相似度 | KR,对学习资源进行分类并基于本体生成语义表示.根据学习资源与学习者目标的语义相似度实现推荐 | 无法确保所推荐知识概念的先后顺序相关性 | 学习中的相关词汇推荐 |
| [75] | 知识图谱 | KR,基于学习过程中出现的知识单元相关要素构建知识图谱,从而形成多个学习路径,然后根据学习者的学习日志判断其学习进度,再向其推荐学习路径 | 学习路径的配置既符合规律又具有灵活性 | 学习路径推荐 |
| [15] | 知识图谱 | KR,构建了一个以学习目标为导向的跨学习领域知识图谱,其中包括了六种语义关系,然后结合学习者 的学习目标和学习资源的特征表示推荐学习路径 | 可扩展、可重用 | 跨领域学习路径推荐 |
注:CR,基于内容;CF,协同过滤;HR,混合推荐;SR,基于会话;KR,基于知识. ...
... 文献[60]对七种推荐的结果进行人工评估,结果表明用户体验的质量与推荐的高精度并不相关.一般而言,用户体验好的推荐内容,除了符合自己偏好外,还要尽量做到不与刚刚看过的内容完全相同或者非常相似,但是一味追求推荐的高精度往往会忽视这一问题.为了解决这一问题,近年来研究人员对推荐的“偶然性”[98,99]开展研究.文献[100]指出,现有大多数的推荐算法基于准确性评估,但难以保障推荐内容能够满足用户需求、偏好的变化,因为单纯准确性可能会导致所推荐内容没有新意.为了获得高的精度评估值,用户可能仅收到那些与他们初始评分高的项目类似的推荐项目(过度专业化).这必然会降低用户体验的满意度[101].因此,用户体验评估的核心指标是推荐的“偶然性”,该指标通常采用新颖度(novelty)和多样性(diversity)等二级指标来衡量.新颖度是指所推荐的项目在用户过往的交互记录中出现得越少越好[102];多样性是指推荐列表中出现的项目越不相似越好,因为用户可能对包含彼此非常相似项目的推荐列表感到不满意[98].新颖而多样的学习资源会在一定程度上激发学习者的学习兴趣,即提高学习资源推荐的新颖度和多样性会对学习者的学习热情产生积极影响[42,53].文献[42]结合练习题的题型、难度、涵盖的知识点等特征,在对练习题推荐精度的基础上,还对推荐的新颖度和多样性进行了评估.对用户体验的评估也常采用人工方法.如文献[103]和文献[104]中,设计了用户体验量表,采用人工打分的方式进行评估,来衡量推荐的感知相关性,此外文献[103]还采用人工打分方式评估了推荐的可用性. ...
... .文献[42]结合练习题的题型、难度、涵盖的知识点等特征,在对练习题推荐精度的基础上,还对推荐的新颖度和多样性进行了评估.对用户体验的评估也常采用人工方法.如文献[103]和文献[104]中,设计了用户体验量表,采用人工打分的方式进行评估,来衡量推荐的感知相关性,此外文献[103]还采用人工打分方式评估了推荐的可用性. ...
... 目前可用于评估个性化学习推荐系统的通用数据集不多,从当前研究的应用场景来看,可以分为用于课程推荐、学习资源推荐以及学习路径推荐三类.课程推荐常用到edX、Coursera、学堂在线(XuetangX)、中国慕课大学(icourse163)等在线课程平台提供的数据集,比如edX数据集可用于评估基于学习风格的课程推荐[112],XuetangX数据集可用于评估基于学习偏好的课程推荐[55],icourse163数据集可用于课程学习中的主题推荐[39].对于学习资源推荐常采用Amazon产品数据集、ASSISTment学习平台数据集等,比如学习书籍推荐使用Amazon的Book- Crossing数据集[53]、e-book数据集[63],练习题推荐使用ASSISTment数据集[42].对于学习路径推荐而言,离线方法并不能提供可靠的结果,因为其假设学习者的行为不会随时间发生变化,研究人员无法获取适用于他们实验的公共数据集[7],所以通常自组织数据集,比如文献[15]和文献[75]均使用了自组织的数据集对提出的推荐方法进行评估. ...
Ontologies in e-learning: review of the literature
3
2015
... 所谓基于知识的学习者建模,是指基于领域知 识背景,通过识别学习者特征实体和其之间的关系,从而形成蕴含语义的网络或图结构,再通过将其实例化形成学习者模型.基于知识的学习者建模通常需要领域专家的参与,难以避免主观偏差,本体技术在该建模方法中被广泛使用[43].本体是基于领域中所涉及的概念、属性和条件,以及它们之间的关系所形成的领域知识表示形式,支持抽象概念和属性的形式表示,并可在需要时进行重用、扩展以及更新知识[44].在学习推荐应用场景下,基于本体的学习者建模方法通常根据学习者的基本属性和学习特征来构建学习者本体.文献[45]提出的基于本体的学习者建模方法,首先使用学习风格指数(index of learning styles,ILS)问卷对学习者的学习风格进行分析,并将有效规则定义为学习风格语义组与学习目标之间存在交集.文献[46]提出了一个基于本体的MOOC学习活动推荐方法.在该推荐方法中,本体被用于建模和表示领域知识、学习者以及学习活动.其中,学习者本体由4个子类构成,即知识水平、学习方式、教学偏好以及学习者基本特征.采用本体技术可以将学习者建模扩展到多模态数据.文献[47]提出一种通过学习者的Facebook帐户提取他/她的社交数据,将个人资料信息、好友列表、喜欢的页面、帖子和群组等进行过滤,寻找那些定义教育兴趣、访问时间偏好、语言媒体偏好等信息,再基于这些信息对学习者本体进行实例化.文献[48]构建了一个基于学习系统领域规则的通用本体,该本体结合了用于建模用户配置文件的概念和属性,以便在学习系统中制定具体、完整和可扩展的用户建模.该方法使学习者模型不断更新,并利用语义规则来分析学生的学习情况,从而更新关于学习者表现的知识. ...
... 学习是一种在教育情境中符合一定心理规律的行为,这是基于知识(knowledge-based)学习推荐方法[71]的研究背景,这种推荐方法将学习者和学习资源的有关知识结合考虑,并应用到推荐过程中,根据学习者在领域知识中的偏好向其推荐学习资源.基于知识的推荐系统需要使用三种类型的知识:即用户的知识、项目的知识以及项目与用户需求之间匹配的知识[72].而这种方法的主要缺点是对领域知识整理的要求离不开人工参与,往往带有主观偏差,而且所构建领域知识的完备性也难以保障.使用本体对学习领域进行建模是基于知识学习推荐中的常用手段.在此过程中,除了可以用本体对学习者和学习资源的知识进行建模[43,48,73]之外,还可以用它来描述学习场景中的要素.比如,文献[43]构建了E-learning环境中的学习行为标准本体.文献[46]使用本体描述了学习者在学习过程中表现的行为,分别对学习者、领域知识和学习行为进行建模.文献[74]设计了一个框架来存储学习资源,对学习资源进行分类并基于本体生成资源表示. ...
... 之外,还可以用它来描述学习场景中的要素.比如,文献[43]构建了E-learning环境中的学习行为标准本体.文献[46]使用本体描述了学习者在学习过程中表现的行为,分别对学习者、领域知识和学习行为进行建模.文献[74]设计了一个框架来存储学习资源,对学习资源进行分类并基于本体生成资源表示. ...
Ontologies in education- state of the art
1
2020
... 所谓基于知识的学习者建模,是指基于领域知 识背景,通过识别学习者特征实体和其之间的关系,从而形成蕴含语义的网络或图结构,再通过将其实例化形成学习者模型.基于知识的学习者建模通常需要领域专家的参与,难以避免主观偏差,本体技术在该建模方法中被广泛使用[43].本体是基于领域中所涉及的概念、属性和条件,以及它们之间的关系所形成的领域知识表示形式,支持抽象概念和属性的形式表示,并可在需要时进行重用、扩展以及更新知识[44].在学习推荐应用场景下,基于本体的学习者建模方法通常根据学习者的基本属性和学习特征来构建学习者本体.文献[45]提出的基于本体的学习者建模方法,首先使用学习风格指数(index of learning styles,ILS)问卷对学习者的学习风格进行分析,并将有效规则定义为学习风格语义组与学习目标之间存在交集.文献[46]提出了一个基于本体的MOOC学习活动推荐方法.在该推荐方法中,本体被用于建模和表示领域知识、学习者以及学习活动.其中,学习者本体由4个子类构成,即知识水平、学习方式、教学偏好以及学习者基本特征.采用本体技术可以将学习者建模扩展到多模态数据.文献[47]提出一种通过学习者的Facebook帐户提取他/她的社交数据,将个人资料信息、好友列表、喜欢的页面、帖子和群组等进行过滤,寻找那些定义教育兴趣、访问时间偏好、语言媒体偏好等信息,再基于这些信息对学习者本体进行实例化.文献[48]构建了一个基于学习系统领域规则的通用本体,该本体结合了用于建模用户配置文件的概念和属性,以便在学习系统中制定具体、完整和可扩展的用户建模.该方法使学习者模型不断更新,并利用语义规则来分析学生的学习情况,从而更新关于学习者表现的知识. ...
LORecommendNet: an ontology-based representation of learning object recommendation
2
2014
... 所谓基于知识的学习者建模,是指基于领域知 识背景,通过识别学习者特征实体和其之间的关系,从而形成蕴含语义的网络或图结构,再通过将其实例化形成学习者模型.基于知识的学习者建模通常需要领域专家的参与,难以避免主观偏差,本体技术在该建模方法中被广泛使用[43].本体是基于领域中所涉及的概念、属性和条件,以及它们之间的关系所形成的领域知识表示形式,支持抽象概念和属性的形式表示,并可在需要时进行重用、扩展以及更新知识[44].在学习推荐应用场景下,基于本体的学习者建模方法通常根据学习者的基本属性和学习特征来构建学习者本体.文献[45]提出的基于本体的学习者建模方法,首先使用学习风格指数(index of learning styles,ILS)问卷对学习者的学习风格进行分析,并将有效规则定义为学习风格语义组与学习目标之间存在交集.文献[46]提出了一个基于本体的MOOC学习活动推荐方法.在该推荐方法中,本体被用于建模和表示领域知识、学习者以及学习活动.其中,学习者本体由4个子类构成,即知识水平、学习方式、教学偏好以及学习者基本特征.采用本体技术可以将学习者建模扩展到多模态数据.文献[47]提出一种通过学习者的Facebook帐户提取他/她的社交数据,将个人资料信息、好友列表、喜欢的页面、帖子和群组等进行过滤,寻找那些定义教育兴趣、访问时间偏好、语言媒体偏好等信息,再基于这些信息对学习者本体进行实例化.文献[48]构建了一个基于学习系统领域规则的通用本体,该本体结合了用于建模用户配置文件的概念和属性,以便在学习系统中制定具体、完整和可扩展的用户建模.该方法使学习者模型不断更新,并利用语义规则来分析学生的学习情况,从而更新关于学习者表现的知识. ...
... 基于知识的学习推荐对象建模方法也通常采用领域本体或知识图谱实现.学习资源本体的构建多采用半自动化或手工方式,同样离不开人工参与,难以避免主观偏差.文献[45]通过专家咨询,采用五种特征构建学习资源本体,即:格式、交互类型、交互级别、语义密度和学习资源类型.文献[57]为了提高学习资源本体构建的效率,采用了领域专家协作标注结合DOGMA[58]的本体构建方法,框架如图10所示.该方法在准备好包含相关知识数据的基础上,先进行清洗和修剪,凸显出实体、属性以及关系,并基于此建构推荐对象本体;在本体构建的过程中,再结合领域专家的协作参与不断完善和优化推荐对象本体. ...
A hybrid knowlegde-based approach for recommending massive learning activities
3
2017
... 所谓基于知识的学习者建模,是指基于领域知 识背景,通过识别学习者特征实体和其之间的关系,从而形成蕴含语义的网络或图结构,再通过将其实例化形成学习者模型.基于知识的学习者建模通常需要领域专家的参与,难以避免主观偏差,本体技术在该建模方法中被广泛使用[43].本体是基于领域中所涉及的概念、属性和条件,以及它们之间的关系所形成的领域知识表示形式,支持抽象概念和属性的形式表示,并可在需要时进行重用、扩展以及更新知识[44].在学习推荐应用场景下,基于本体的学习者建模方法通常根据学习者的基本属性和学习特征来构建学习者本体.文献[45]提出的基于本体的学习者建模方法,首先使用学习风格指数(index of learning styles,ILS)问卷对学习者的学习风格进行分析,并将有效规则定义为学习风格语义组与学习目标之间存在交集.文献[46]提出了一个基于本体的MOOC学习活动推荐方法.在该推荐方法中,本体被用于建模和表示领域知识、学习者以及学习活动.其中,学习者本体由4个子类构成,即知识水平、学习方式、教学偏好以及学习者基本特征.采用本体技术可以将学习者建模扩展到多模态数据.文献[47]提出一种通过学习者的Facebook帐户提取他/她的社交数据,将个人资料信息、好友列表、喜欢的页面、帖子和群组等进行过滤,寻找那些定义教育兴趣、访问时间偏好、语言媒体偏好等信息,再基于这些信息对学习者本体进行实例化.文献[48]构建了一个基于学习系统领域规则的通用本体,该本体结合了用于建模用户配置文件的概念和属性,以便在学习系统中制定具体、完整和可扩展的用户建模.该方法使学习者模型不断更新,并利用语义规则来分析学生的学习情况,从而更新关于学习者表现的知识. ...
... 学习是一种在教育情境中符合一定心理规律的行为,这是基于知识(knowledge-based)学习推荐方法[71]的研究背景,这种推荐方法将学习者和学习资源的有关知识结合考虑,并应用到推荐过程中,根据学习者在领域知识中的偏好向其推荐学习资源.基于知识的推荐系统需要使用三种类型的知识:即用户的知识、项目的知识以及项目与用户需求之间匹配的知识[72].而这种方法的主要缺点是对领域知识整理的要求离不开人工参与,往往带有主观偏差,而且所构建领域知识的完备性也难以保障.使用本体对学习领域进行建模是基于知识学习推荐中的常用手段.在此过程中,除了可以用本体对学习者和学习资源的知识进行建模[43,48,73]之外,还可以用它来描述学习场景中的要素.比如,文献[43]构建了E-learning环境中的学习行为标准本体.文献[46]使用本体描述了学习者在学习过程中表现的行为,分别对学习者、领域知识和学习行为进行建模.文献[74]设计了一个框架来存储学习资源,对学习资源进行分类并基于本体生成资源表示. ...
... Summary and comparison of personalized learning recommendation methods
Table 1 | 文献 | 主要方法/技术 | 推荐策略 | 优势/局限 | 适用场景 |
| [53] | CNN | CR,基于描述文本生成的学习资源表示结合学习者偏好预测评分进行推荐 | 文本描述有利于对学习资源建模提供更丰富的特征信息 | 具有文本描述的学习资料推荐 |
| [62] | Felder-Silverman学习风格量表 | CR,基于满足规则的情况计算学习资源与学习者的相关性分数,再根据分数排序推荐 | 需要人工定义学习资源与学习者学习风格的关联规则 | 学习资料推荐 |
| [63] | Fuzzy decision tree,CNN | CR,从大量数据中识别出学习资源特征,再根据学习者的理解水平进行推荐 | 学习资源数据描述模型的性能影响推荐的效果 | 学习资料推荐 |
| [55] | BPR成对排序 | CF,通过捕获学习者对课程两两之间的偏好排序形成课程有序队列 | 由于负课程均值采样空间较大,这些课程可能不是最优 | 课程推荐 |
| [60] | Weka API的潜在语义分析 | CF,通过关键字注释将学习者与学习资源建立关联 | 使用关键字注释标签对学习者建模,标签本身源自人工设置,可能导致主观偏差 | 学习资料推荐 |
| [61] | 人工免疫系统(AIS)算法 | HR,根据过往课程学习效果对学习者建模,使用AIS聚类融合基于项目的协同过滤获得备选课程的预测矩阵 | 能够融合多种特征到学习者模型,但对冷启动的缓解效果有限 | 课程推荐 |
| [67] | 动态本体映射 | HR,采用相似结构层次的本体映射课程属性与学习者属性,根据匹配度进行推荐 | 可整合来自多个来源的信息,以提高效率和用户满意度 | 课程推荐 |
| [68] | 遗传算法 | HR,整合协同过滤推荐和基于内容推荐,并用遗传算法配置推荐系统的最优参数 | 可整合学习者与课程的多种标准,并得到最优配置结果 | 课程推荐 |
| [69] | 序列模式挖掘 | HR,基于显式特征的学习者模型进行聚类,通过序列模式挖掘完成学习资源的排序及推荐 | 有利于解决信息过载和缺乏多样性的问题 | 课程推荐 |
| [42] | 深度知识追踪、模拟退火算法 | HR,基于知识追踪模型预测学习者答题的准确度生成备选题集,再采用模拟退火算法从候选题集中抽取多样性练习题组成推荐列表 | 以学习者答题准确度为目标,并考虑所推荐练习题的多样性和新颖度 | 练习题推荐 |
| [70] | 多目标粒子群优化算法 | HR,以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐 | 考虑在给定时间规划内的多目标推荐问题 | 学习资料推荐 |
| [39] | 自注意力机制 | SR,将学习者在当前会话中所查看主题的历史记录作为输入序列,计算候选线程得分进行推荐 | 能够在没有太多特征属性情况下捕获学习者当前的选择状态 | 课程讨论线程推荐 |
| [78] | 认知诊断模型、PMF | SR,根据答题会话序列形成的认知诊断模型对学习者建模,再采用PMF预测学生的答题情况,最后根据预测结果进行练习题推荐 | 动态捕获学习者的知识掌握状态 | 练习题推荐 |
| [38] | 深度知识追踪、遗传算法 | SR,基于学习者练习答题会话序列预测学习者知识掌握水平,再通过遗传算法设置试卷各项质量指标,生成推荐试卷 | 同时动态捕获多个学习者的知识掌握状态 | 试卷推荐 |
| [46] | 本体 | KR,使用本体分别对学习者、领域知识和学习行为进行建模 | 未给出具体实现过程 | MOOC课程推荐 |
| [71] | 本体 | KR,基于本体描述所学知识点和学习目标相关性的学习资源推荐方法 | 本体中领域知识和推荐规则制定不能避免人工偏差 | 学习资料推荐 |
| [73] | 本体推理和神经网络 | KR,基于本体模型对学习者和学习资源进行水平层级分类,根据评估反馈向学习者推荐相应水平层级资源 | 能够根据学习者的水平状态动态调节推荐内容 | 课程知识概念相应资源的推荐 |
| [48] | 本体 | KR,通过半自动化方法构建了E-learning行为的标准本体.基于本体规则进行推荐 | 能够融合多种个性化参数的学习者模型 | 课程知识概念和主题的推荐 |
| [74] | 本体、语义相似度 | KR,对学习资源进行分类并基于本体生成语义表示.根据学习资源与学习者目标的语义相似度实现推荐 | 无法确保所推荐知识概念的先后顺序相关性 | 学习中的相关词汇推荐 |
| [75] | 知识图谱 | KR,基于学习过程中出现的知识单元相关要素构建知识图谱,从而形成多个学习路径,然后根据学习者的学习日志判断其学习进度,再向其推荐学习路径 | 学习路径的配置既符合规律又具有灵活性 | 学习路径推荐 |
| [15] | 知识图谱 | KR,构建了一个以学习目标为导向的跨学习领域知识图谱,其中包括了六种语义关系,然后结合学习者 的学习目标和学习资源的特征表示推荐学习路径 | 可扩展、可重用 | 跨领域学习路径推荐 |
注:CR,基于内容;CF,协同过滤;HR,混合推荐;SR,基于会话;KR,基于知识. ...
BROAD-RSI: educational recommender system using social networks interactions and linked data
1
2018
... 所谓基于知识的学习者建模,是指基于领域知 识背景,通过识别学习者特征实体和其之间的关系,从而形成蕴含语义的网络或图结构,再通过将其实例化形成学习者模型.基于知识的学习者建模通常需要领域专家的参与,难以避免主观偏差,本体技术在该建模方法中被广泛使用[43].本体是基于领域中所涉及的概念、属性和条件,以及它们之间的关系所形成的领域知识表示形式,支持抽象概念和属性的形式表示,并可在需要时进行重用、扩展以及更新知识[44].在学习推荐应用场景下,基于本体的学习者建模方法通常根据学习者的基本属性和学习特征来构建学习者本体.文献[45]提出的基于本体的学习者建模方法,首先使用学习风格指数(index of learning styles,ILS)问卷对学习者的学习风格进行分析,并将有效规则定义为学习风格语义组与学习目标之间存在交集.文献[46]提出了一个基于本体的MOOC学习活动推荐方法.在该推荐方法中,本体被用于建模和表示领域知识、学习者以及学习活动.其中,学习者本体由4个子类构成,即知识水平、学习方式、教学偏好以及学习者基本特征.采用本体技术可以将学习者建模扩展到多模态数据.文献[47]提出一种通过学习者的Facebook帐户提取他/她的社交数据,将个人资料信息、好友列表、喜欢的页面、帖子和群组等进行过滤,寻找那些定义教育兴趣、访问时间偏好、语言媒体偏好等信息,再基于这些信息对学习者本体进行实例化.文献[48]构建了一个基于学习系统领域规则的通用本体,该本体结合了用于建模用户配置文件的概念和属性,以便在学习系统中制定具体、完整和可扩展的用户建模.该方法使学习者模型不断更新,并利用语义规则来分析学生的学习情况,从而更新关于学习者表现的知识. ...
An ontology-based approach for user modelling and personalization in e-learning systems
3
2019
... 所谓基于知识的学习者建模,是指基于领域知 识背景,通过识别学习者特征实体和其之间的关系,从而形成蕴含语义的网络或图结构,再通过将其实例化形成学习者模型.基于知识的学习者建模通常需要领域专家的参与,难以避免主观偏差,本体技术在该建模方法中被广泛使用[43].本体是基于领域中所涉及的概念、属性和条件,以及它们之间的关系所形成的领域知识表示形式,支持抽象概念和属性的形式表示,并可在需要时进行重用、扩展以及更新知识[44].在学习推荐应用场景下,基于本体的学习者建模方法通常根据学习者的基本属性和学习特征来构建学习者本体.文献[45]提出的基于本体的学习者建模方法,首先使用学习风格指数(index of learning styles,ILS)问卷对学习者的学习风格进行分析,并将有效规则定义为学习风格语义组与学习目标之间存在交集.文献[46]提出了一个基于本体的MOOC学习活动推荐方法.在该推荐方法中,本体被用于建模和表示领域知识、学习者以及学习活动.其中,学习者本体由4个子类构成,即知识水平、学习方式、教学偏好以及学习者基本特征.采用本体技术可以将学习者建模扩展到多模态数据.文献[47]提出一种通过学习者的Facebook帐户提取他/她的社交数据,将个人资料信息、好友列表、喜欢的页面、帖子和群组等进行过滤,寻找那些定义教育兴趣、访问时间偏好、语言媒体偏好等信息,再基于这些信息对学习者本体进行实例化.文献[48]构建了一个基于学习系统领域规则的通用本体,该本体结合了用于建模用户配置文件的概念和属性,以便在学习系统中制定具体、完整和可扩展的用户建模.该方法使学习者模型不断更新,并利用语义规则来分析学生的学习情况,从而更新关于学习者表现的知识. ...
... 学习是一种在教育情境中符合一定心理规律的行为,这是基于知识(knowledge-based)学习推荐方法[71]的研究背景,这种推荐方法将学习者和学习资源的有关知识结合考虑,并应用到推荐过程中,根据学习者在领域知识中的偏好向其推荐学习资源.基于知识的推荐系统需要使用三种类型的知识:即用户的知识、项目的知识以及项目与用户需求之间匹配的知识[72].而这种方法的主要缺点是对领域知识整理的要求离不开人工参与,往往带有主观偏差,而且所构建领域知识的完备性也难以保障.使用本体对学习领域进行建模是基于知识学习推荐中的常用手段.在此过程中,除了可以用本体对学习者和学习资源的知识进行建模[43,48,73]之外,还可以用它来描述学习场景中的要素.比如,文献[43]构建了E-learning环境中的学习行为标准本体.文献[46]使用本体描述了学习者在学习过程中表现的行为,分别对学习者、领域知识和学习行为进行建模.文献[74]设计了一个框架来存储学习资源,对学习资源进行分类并基于本体生成资源表示. ...
... Summary and comparison of personalized learning recommendation methods
Table 1 | 文献 | 主要方法/技术 | 推荐策略 | 优势/局限 | 适用场景 |
| [53] | CNN | CR,基于描述文本生成的学习资源表示结合学习者偏好预测评分进行推荐 | 文本描述有利于对学习资源建模提供更丰富的特征信息 | 具有文本描述的学习资料推荐 |
| [62] | Felder-Silverman学习风格量表 | CR,基于满足规则的情况计算学习资源与学习者的相关性分数,再根据分数排序推荐 | 需要人工定义学习资源与学习者学习风格的关联规则 | 学习资料推荐 |
| [63] | Fuzzy decision tree,CNN | CR,从大量数据中识别出学习资源特征,再根据学习者的理解水平进行推荐 | 学习资源数据描述模型的性能影响推荐的效果 | 学习资料推荐 |
| [55] | BPR成对排序 | CF,通过捕获学习者对课程两两之间的偏好排序形成课程有序队列 | 由于负课程均值采样空间较大,这些课程可能不是最优 | 课程推荐 |
| [60] | Weka API的潜在语义分析 | CF,通过关键字注释将学习者与学习资源建立关联 | 使用关键字注释标签对学习者建模,标签本身源自人工设置,可能导致主观偏差 | 学习资料推荐 |
| [61] | 人工免疫系统(AIS)算法 | HR,根据过往课程学习效果对学习者建模,使用AIS聚类融合基于项目的协同过滤获得备选课程的预测矩阵 | 能够融合多种特征到学习者模型,但对冷启动的缓解效果有限 | 课程推荐 |
| [67] | 动态本体映射 | HR,采用相似结构层次的本体映射课程属性与学习者属性,根据匹配度进行推荐 | 可整合来自多个来源的信息,以提高效率和用户满意度 | 课程推荐 |
| [68] | 遗传算法 | HR,整合协同过滤推荐和基于内容推荐,并用遗传算法配置推荐系统的最优参数 | 可整合学习者与课程的多种标准,并得到最优配置结果 | 课程推荐 |
| [69] | 序列模式挖掘 | HR,基于显式特征的学习者模型进行聚类,通过序列模式挖掘完成学习资源的排序及推荐 | 有利于解决信息过载和缺乏多样性的问题 | 课程推荐 |
| [42] | 深度知识追踪、模拟退火算法 | HR,基于知识追踪模型预测学习者答题的准确度生成备选题集,再采用模拟退火算法从候选题集中抽取多样性练习题组成推荐列表 | 以学习者答题准确度为目标,并考虑所推荐练习题的多样性和新颖度 | 练习题推荐 |
| [70] | 多目标粒子群优化算法 | HR,以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐 | 考虑在给定时间规划内的多目标推荐问题 | 学习资料推荐 |
| [39] | 自注意力机制 | SR,将学习者在当前会话中所查看主题的历史记录作为输入序列,计算候选线程得分进行推荐 | 能够在没有太多特征属性情况下捕获学习者当前的选择状态 | 课程讨论线程推荐 |
| [78] | 认知诊断模型、PMF | SR,根据答题会话序列形成的认知诊断模型对学习者建模,再采用PMF预测学生的答题情况,最后根据预测结果进行练习题推荐 | 动态捕获学习者的知识掌握状态 | 练习题推荐 |
| [38] | 深度知识追踪、遗传算法 | SR,基于学习者练习答题会话序列预测学习者知识掌握水平,再通过遗传算法设置试卷各项质量指标,生成推荐试卷 | 同时动态捕获多个学习者的知识掌握状态 | 试卷推荐 |
| [46] | 本体 | KR,使用本体分别对学习者、领域知识和学习行为进行建模 | 未给出具体实现过程 | MOOC课程推荐 |
| [71] | 本体 | KR,基于本体描述所学知识点和学习目标相关性的学习资源推荐方法 | 本体中领域知识和推荐规则制定不能避免人工偏差 | 学习资料推荐 |
| [73] | 本体推理和神经网络 | KR,基于本体模型对学习者和学习资源进行水平层级分类,根据评估反馈向学习者推荐相应水平层级资源 | 能够根据学习者的水平状态动态调节推荐内容 | 课程知识概念相应资源的推荐 |
| [48] | 本体 | KR,通过半自动化方法构建了E-learning行为的标准本体.基于本体规则进行推荐 | 能够融合多种个性化参数的学习者模型 | 课程知识概念和主题的推荐 |
| [74] | 本体、语义相似度 | KR,对学习资源进行分类并基于本体生成语义表示.根据学习资源与学习者目标的语义相似度实现推荐 | 无法确保所推荐知识概念的先后顺序相关性 | 学习中的相关词汇推荐 |
| [75] | 知识图谱 | KR,基于学习过程中出现的知识单元相关要素构建知识图谱,从而形成多个学习路径,然后根据学习者的学习日志判断其学习进度,再向其推荐学习路径 | 学习路径的配置既符合规律又具有灵活性 | 学习路径推荐 |
| [15] | 知识图谱 | KR,构建了一个以学习目标为导向的跨学习领域知识图谱,其中包括了六种语义关系,然后结合学习者 的学习目标和学习资源的特征表示推荐学习路径 | 可扩展、可重用 | 跨领域学习路径推荐 |
注:CR,基于内容;CF,协同过滤;HR,混合推荐;SR,基于会话;KR,基于知识. ...
Learning management system adoption: a theory of planned behavior approach
1
2019
... 学习推荐对象主要包括学习资源、好友以及学习路径.其中学习资源是学习活动中所使用的资源,包括习题、课程、教学视频、参考文献、考试卷等,相关推荐的研究较多.按来源不同可将学习资源分为两类:一类源自在线学习平台内部,在平台建设初期导入,并随着平台的运作不断更新和补充;另一类源自在线学习平台外部,学习者可以通过平台提供的链接访问.无论来源于内部或外部,在线学习平台都应对其进行统一标准化管理[49,50],标准化的内容包括资源的类型、所覆盖的知识点、难度、适用阶段、学习时间等.此外,为了提高检索效率,通常在学习资源管理系统中采用自动或半自动的语义化方法[51,52],从而为学习推荐对象的特征描述提供丰富的语义.学习推荐对象建模是学习推荐任务的重要部分,建模之前要考虑以下几个问题: ...
A design of a personalized educational resources management system
1
2015
... 学习推荐对象主要包括学习资源、好友以及学习路径.其中学习资源是学习活动中所使用的资源,包括习题、课程、教学视频、参考文献、考试卷等,相关推荐的研究较多.按来源不同可将学习资源分为两类:一类源自在线学习平台内部,在平台建设初期导入,并随着平台的运作不断更新和补充;另一类源自在线学习平台外部,学习者可以通过平台提供的链接访问.无论来源于内部或外部,在线学习平台都应对其进行统一标准化管理[49,50],标准化的内容包括资源的类型、所覆盖的知识点、难度、适用阶段、学习时间等.此外,为了提高检索效率,通常在学习资源管理系统中采用自动或半自动的语义化方法[51,52],从而为学习推荐对象的特征描述提供丰富的语义.学习推荐对象建模是学习推荐任务的重要部分,建模之前要考虑以下几个问题: ...
Enhancing categorization of learning resources in the dataset of joint educational entities
1
2017
... 学习推荐对象主要包括学习资源、好友以及学习路径.其中学习资源是学习活动中所使用的资源,包括习题、课程、教学视频、参考文献、考试卷等,相关推荐的研究较多.按来源不同可将学习资源分为两类:一类源自在线学习平台内部,在平台建设初期导入,并随着平台的运作不断更新和补充;另一类源自在线学习平台外部,学习者可以通过平台提供的链接访问.无论来源于内部或外部,在线学习平台都应对其进行统一标准化管理[49,50],标准化的内容包括资源的类型、所覆盖的知识点、难度、适用阶段、学习时间等.此外,为了提高检索效率,通常在学习资源管理系统中采用自动或半自动的语义化方法[51,52],从而为学习推荐对象的特征描述提供丰富的语义.学习推荐对象建模是学习推荐任务的重要部分,建模之前要考虑以下几个问题: ...
Resources and semantic-based knowledge models for personalized and self-regulated learning in the web: survey and trends
2
2019
... 学习推荐对象主要包括学习资源、好友以及学习路径.其中学习资源是学习活动中所使用的资源,包括习题、课程、教学视频、参考文献、考试卷等,相关推荐的研究较多.按来源不同可将学习资源分为两类:一类源自在线学习平台内部,在平台建设初期导入,并随着平台的运作不断更新和补充;另一类源自在线学习平台外部,学习者可以通过平台提供的链接访问.无论来源于内部或外部,在线学习平台都应对其进行统一标准化管理[49,50],标准化的内容包括资源的类型、所覆盖的知识点、难度、适用阶段、学习时间等.此外,为了提高检索效率,通常在学习资源管理系统中采用自动或半自动的语义化方法[51,52],从而为学习推荐对象的特征描述提供丰富的语义.学习推荐对象建模是学习推荐任务的重要部分,建模之前要考虑以下几个问题: ...
... 基于知识的学习推荐方法具有灵活性的语义描述域,文献[52]提出一种采用本体综合描述CBR、CFR、HR等推荐算法,并选择性调用相关算法的课程推荐方法,该方法能够根据需求,对已描述的推荐算法进行动态调用.基于知识的学习推荐方法广受关注的主要原因在于:教学是一个有规律的活动,学习行为的目标明确,而且学习资源特征与学习者的需求之间的映射规则易于定制.但是,领域本体或领域知识图谱的构建也是一个需要人工参与,且耗时耗力的过程,所构建本体的合理性和完备性也会影响推荐的效果[71,76].此外,学习者的状态,如情感、知识水平并非一成不变,知识的描述如果没有合理的更新机制,则会导致学习路径固化,反而与“个性化”的初衷相悖. ...
A content-based recommendation algorithm for learning resources
5
2018
... 学习推荐对象建模静态方法是指提取推荐对象显式特征中与学习推荐相关的那些来形成模型.比如直接采集学习推荐对象的文档描述,如文献[15]使用特征关键词集描述学习资源,其中包括:发表时间、引文次数、搜索频率、出版商影响以及作者影响力,然后使用加权关键词矢量方法,通过对推荐对象文档的统计分析得出对象的特征向量.直接提取文档描述虽然简单直观,但是往往难以体现推荐对象的内在差异性.有研究着眼于挖掘更深层次的特征,从推荐对象文本中提取特征,比如从简介、摘要、练习题的题干中提取.文献[53]提出了一个基于卷积神经网络(convolutional neural networks,CNN)的学习资源特征表示生成模型,提取学习资源中的文本信息(例如MOOC平台中的课程介绍、学习资源的摘要等)的特征,生成低维度的隐向量表示,该模型的结构如图9所示. ...
... 基于内容推荐方法(CBR)是通过比较学习资源的属性特征与学习者的偏好,找到与学习者偏好最符合的学习资源.与电子商务中基于内容的推荐有所不同,基于内容的学习推荐可以借鉴学习领域的一些知识背景,比如学习风格模型.文献[62]通过人工定义若干推荐规则将学习资源的特征与学习者的学习风格模型进行关联,基于满足规则的情况计算学习资源与学习者的相关性分数,再根据分数排序推荐.也有研究将学习资源与学习者的知识掌握水平进行关联,如文献[63]提出了一种学习内容推荐方法,该方法首先采用特征选择模型提取学习资源的表示特征,再将表示特征根据学习者理解水平进行分类,从而在大量数据中识别出确切的学习资源内容,然后根据学习者的理解水平进行推荐.除了与学习资源的属性特征直接比较外,现有研究关注于提取学习资源的潜在特征,以及发掘其与学习者的关联.文献[53]提出的推荐方法通过历史学习资源的文本数据(内容本身或内容简介) 结合学习者偏好训练CNN模型.在使用时,该模型可以将输入的学习资源文本信息转换为学习资源的特征,然后结合学习者偏好预测评分进行推荐.基于内容的学习推荐方法离不开学习资源属性特征,一旦缺乏有用的特征数据,该方法的有效性将大为降低. ...
... Summary and comparison of personalized learning recommendation methods
Table 1 | 文献 | 主要方法/技术 | 推荐策略 | 优势/局限 | 适用场景 |
| [53] | CNN | CR,基于描述文本生成的学习资源表示结合学习者偏好预测评分进行推荐 | 文本描述有利于对学习资源建模提供更丰富的特征信息 | 具有文本描述的学习资料推荐 |
| [62] | Felder-Silverman学习风格量表 | CR,基于满足规则的情况计算学习资源与学习者的相关性分数,再根据分数排序推荐 | 需要人工定义学习资源与学习者学习风格的关联规则 | 学习资料推荐 |
| [63] | Fuzzy decision tree,CNN | CR,从大量数据中识别出学习资源特征,再根据学习者的理解水平进行推荐 | 学习资源数据描述模型的性能影响推荐的效果 | 学习资料推荐 |
| [55] | BPR成对排序 | CF,通过捕获学习者对课程两两之间的偏好排序形成课程有序队列 | 由于负课程均值采样空间较大,这些课程可能不是最优 | 课程推荐 |
| [60] | Weka API的潜在语义分析 | CF,通过关键字注释将学习者与学习资源建立关联 | 使用关键字注释标签对学习者建模,标签本身源自人工设置,可能导致主观偏差 | 学习资料推荐 |
| [61] | 人工免疫系统(AIS)算法 | HR,根据过往课程学习效果对学习者建模,使用AIS聚类融合基于项目的协同过滤获得备选课程的预测矩阵 | 能够融合多种特征到学习者模型,但对冷启动的缓解效果有限 | 课程推荐 |
| [67] | 动态本体映射 | HR,采用相似结构层次的本体映射课程属性与学习者属性,根据匹配度进行推荐 | 可整合来自多个来源的信息,以提高效率和用户满意度 | 课程推荐 |
| [68] | 遗传算法 | HR,整合协同过滤推荐和基于内容推荐,并用遗传算法配置推荐系统的最优参数 | 可整合学习者与课程的多种标准,并得到最优配置结果 | 课程推荐 |
| [69] | 序列模式挖掘 | HR,基于显式特征的学习者模型进行聚类,通过序列模式挖掘完成学习资源的排序及推荐 | 有利于解决信息过载和缺乏多样性的问题 | 课程推荐 |
| [42] | 深度知识追踪、模拟退火算法 | HR,基于知识追踪模型预测学习者答题的准确度生成备选题集,再采用模拟退火算法从候选题集中抽取多样性练习题组成推荐列表 | 以学习者答题准确度为目标,并考虑所推荐练习题的多样性和新颖度 | 练习题推荐 |
| [70] | 多目标粒子群优化算法 | HR,以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐 | 考虑在给定时间规划内的多目标推荐问题 | 学习资料推荐 |
| [39] | 自注意力机制 | SR,将学习者在当前会话中所查看主题的历史记录作为输入序列,计算候选线程得分进行推荐 | 能够在没有太多特征属性情况下捕获学习者当前的选择状态 | 课程讨论线程推荐 |
| [78] | 认知诊断模型、PMF | SR,根据答题会话序列形成的认知诊断模型对学习者建模,再采用PMF预测学生的答题情况,最后根据预测结果进行练习题推荐 | 动态捕获学习者的知识掌握状态 | 练习题推荐 |
| [38] | 深度知识追踪、遗传算法 | SR,基于学习者练习答题会话序列预测学习者知识掌握水平,再通过遗传算法设置试卷各项质量指标,生成推荐试卷 | 同时动态捕获多个学习者的知识掌握状态 | 试卷推荐 |
| [46] | 本体 | KR,使用本体分别对学习者、领域知识和学习行为进行建模 | 未给出具体实现过程 | MOOC课程推荐 |
| [71] | 本体 | KR,基于本体描述所学知识点和学习目标相关性的学习资源推荐方法 | 本体中领域知识和推荐规则制定不能避免人工偏差 | 学习资料推荐 |
| [73] | 本体推理和神经网络 | KR,基于本体模型对学习者和学习资源进行水平层级分类,根据评估反馈向学习者推荐相应水平层级资源 | 能够根据学习者的水平状态动态调节推荐内容 | 课程知识概念相应资源的推荐 |
| [48] | 本体 | KR,通过半自动化方法构建了E-learning行为的标准本体.基于本体规则进行推荐 | 能够融合多种个性化参数的学习者模型 | 课程知识概念和主题的推荐 |
| [74] | 本体、语义相似度 | KR,对学习资源进行分类并基于本体生成语义表示.根据学习资源与学习者目标的语义相似度实现推荐 | 无法确保所推荐知识概念的先后顺序相关性 | 学习中的相关词汇推荐 |
| [75] | 知识图谱 | KR,基于学习过程中出现的知识单元相关要素构建知识图谱,从而形成多个学习路径,然后根据学习者的学习日志判断其学习进度,再向其推荐学习路径 | 学习路径的配置既符合规律又具有灵活性 | 学习路径推荐 |
| [15] | 知识图谱 | KR,构建了一个以学习目标为导向的跨学习领域知识图谱,其中包括了六种语义关系,然后结合学习者 的学习目标和学习资源的特征表示推荐学习路径 | 可扩展、可重用 | 跨领域学习路径推荐 |
注:CR,基于内容;CF,协同过滤;HR,混合推荐;SR,基于会话;KR,基于知识. ...
... 文献[60]对七种推荐的结果进行人工评估,结果表明用户体验的质量与推荐的高精度并不相关.一般而言,用户体验好的推荐内容,除了符合自己偏好外,还要尽量做到不与刚刚看过的内容完全相同或者非常相似,但是一味追求推荐的高精度往往会忽视这一问题.为了解决这一问题,近年来研究人员对推荐的“偶然性”[98,99]开展研究.文献[100]指出,现有大多数的推荐算法基于准确性评估,但难以保障推荐内容能够满足用户需求、偏好的变化,因为单纯准确性可能会导致所推荐内容没有新意.为了获得高的精度评估值,用户可能仅收到那些与他们初始评分高的项目类似的推荐项目(过度专业化).这必然会降低用户体验的满意度[101].因此,用户体验评估的核心指标是推荐的“偶然性”,该指标通常采用新颖度(novelty)和多样性(diversity)等二级指标来衡量.新颖度是指所推荐的项目在用户过往的交互记录中出现得越少越好[102];多样性是指推荐列表中出现的项目越不相似越好,因为用户可能对包含彼此非常相似项目的推荐列表感到不满意[98].新颖而多样的学习资源会在一定程度上激发学习者的学习兴趣,即提高学习资源推荐的新颖度和多样性会对学习者的学习热情产生积极影响[42,53].文献[42]结合练习题的题型、难度、涵盖的知识点等特征,在对练习题推荐精度的基础上,还对推荐的新颖度和多样性进行了评估.对用户体验的评估也常采用人工方法.如文献[103]和文献[104]中,设计了用户体验量表,采用人工打分的方式进行评估,来衡量推荐的感知相关性,此外文献[103]还采用人工打分方式评估了推荐的可用性. ...
... 目前可用于评估个性化学习推荐系统的通用数据集不多,从当前研究的应用场景来看,可以分为用于课程推荐、学习资源推荐以及学习路径推荐三类.课程推荐常用到edX、Coursera、学堂在线(XuetangX)、中国慕课大学(icourse163)等在线课程平台提供的数据集,比如edX数据集可用于评估基于学习风格的课程推荐[112],XuetangX数据集可用于评估基于学习偏好的课程推荐[55],icourse163数据集可用于课程学习中的主题推荐[39].对于学习资源推荐常采用Amazon产品数据集、ASSISTment学习平台数据集等,比如学习书籍推荐使用Amazon的Book- Crossing数据集[53]、e-book数据集[63],练习题推荐使用ASSISTment数据集[42].对于学习路径推荐而言,离线方法并不能提供可靠的结果,因为其假设学习者的行为不会随时间发生变化,研究人员无法获取适用于他们实验的公共数据集[7],所以通常自组织数据集,比如文献[15]和文献[75]均使用了自组织的数据集对提出的推荐方法进行评估. ...
Recommendation system based on rule-space model of two-phase blue-red tree and optimized learning path with multimedia learning and cognitive assessment evaluation
1
2017
... 学习推荐对象建模可以采用“分类”和“交互”两种动态方法实现.“分类”即把推荐对象放入不同类别中,这样可以把同类学习资源推荐给相关的学习者.可以使用基于统计机器学习的分类方法如朴素贝叶斯(Naive-Bayes)、k近邻(k-nearest neighbor,kNN)和支持向量机(support vector machine,SVM)等,也可以使用基于深度学习的方法.推荐对象的类别标签可以预先设置,也可以聚类生成.但是这两种方式都不能完全脱离人工参与,因为由自动聚类产生的标签对学习者来说可能并没有意义.“交互”则利用学习者与推荐对象的交互数据进行建模.文献[54]提出一种基于规则空间(rule-space)模型的推荐方法,该方法根据学习者在学习对象上的学习效果和学习进度等生成诊断表,并进一步将每个课程中学习对象描述为对于学习者的强弱学习状态.文献[55]提出一种基于贝叶斯个性化排序(Bayesian personalized ranking,BPR)算法[56]的MOOC课程推荐模型,该模型沿用了BPR算法的成对排序思想,将一个正样本课程与随机采样的n个负样本课程两两组合成n个“正-负”样本对,然后将它们的编号通过嵌入矩阵转换生成嵌入表示.该方法中还采用了一种可以从成对样本中学习偏好排序的神经网络,用于捕获课程两两之间的偏好排序信息.动态方法利用了“资源-资源”之间的关系、“资源-学习者”之间的动态关系形成推荐对象特征,使对象模型具备了动态性,即能随着推荐对象在系统中随学习过程产生的状态变化而进行调整,有利于更好与不断变化的学习者特征匹配. ...
Improving deep item-based collaborative filtering with Bayesian personalized ranking for MOOC course recommendation
4
2020
... 学习推荐对象建模可以采用“分类”和“交互”两种动态方法实现.“分类”即把推荐对象放入不同类别中,这样可以把同类学习资源推荐给相关的学习者.可以使用基于统计机器学习的分类方法如朴素贝叶斯(Naive-Bayes)、k近邻(k-nearest neighbor,kNN)和支持向量机(support vector machine,SVM)等,也可以使用基于深度学习的方法.推荐对象的类别标签可以预先设置,也可以聚类生成.但是这两种方式都不能完全脱离人工参与,因为由自动聚类产生的标签对学习者来说可能并没有意义.“交互”则利用学习者与推荐对象的交互数据进行建模.文献[54]提出一种基于规则空间(rule-space)模型的推荐方法,该方法根据学习者在学习对象上的学习效果和学习进度等生成诊断表,并进一步将每个课程中学习对象描述为对于学习者的强弱学习状态.文献[55]提出一种基于贝叶斯个性化排序(Bayesian personalized ranking,BPR)算法[56]的MOOC课程推荐模型,该模型沿用了BPR算法的成对排序思想,将一个正样本课程与随机采样的n个负样本课程两两组合成n个“正-负”样本对,然后将它们的编号通过嵌入矩阵转换生成嵌入表示.该方法中还采用了一种可以从成对样本中学习偏好排序的神经网络,用于捕获课程两两之间的偏好排序信息.动态方法利用了“资源-资源”之间的关系、“资源-学习者”之间的动态关系形成推荐对象特征,使对象模型具备了动态性,即能随着推荐对象在系统中随学习过程产生的状态变化而进行调整,有利于更好与不断变化的学习者特征匹配. ...
... 许多个性化学习推荐方法参考了电子商务领域的商品推荐方法.这些方法把学习者看作电子商务平台的用户,把学习资源看作商品,以学习者在学习资源上的打分作为推荐模型的训练标签.常用的方法包括基于内容推荐(content-based recommendation,CBR)[59]、协同过滤推荐(collaborative filtering recommendation,CFR)[55,60]以及混合推荐(hybrid recommendation,HR)[61].此外,基于知识的学习推荐方法,以及基于会话的学习推荐方法也是研究的热点,本章将对这些方法进行介绍. ...
... Summary and comparison of personalized learning recommendation methods
Table 1 | 文献 | 主要方法/技术 | 推荐策略 | 优势/局限 | 适用场景 |
| [53] | CNN | CR,基于描述文本生成的学习资源表示结合学习者偏好预测评分进行推荐 | 文本描述有利于对学习资源建模提供更丰富的特征信息 | 具有文本描述的学习资料推荐 |
| [62] | Felder-Silverman学习风格量表 | CR,基于满足规则的情况计算学习资源与学习者的相关性分数,再根据分数排序推荐 | 需要人工定义学习资源与学习者学习风格的关联规则 | 学习资料推荐 |
| [63] | Fuzzy decision tree,CNN | CR,从大量数据中识别出学习资源特征,再根据学习者的理解水平进行推荐 | 学习资源数据描述模型的性能影响推荐的效果 | 学习资料推荐 |
| [55] | BPR成对排序 | CF,通过捕获学习者对课程两两之间的偏好排序形成课程有序队列 | 由于负课程均值采样空间较大,这些课程可能不是最优 | 课程推荐 |
| [60] | Weka API的潜在语义分析 | CF,通过关键字注释将学习者与学习资源建立关联 | 使用关键字注释标签对学习者建模,标签本身源自人工设置,可能导致主观偏差 | 学习资料推荐 |
| [61] | 人工免疫系统(AIS)算法 | HR,根据过往课程学习效果对学习者建模,使用AIS聚类融合基于项目的协同过滤获得备选课程的预测矩阵 | 能够融合多种特征到学习者模型,但对冷启动的缓解效果有限 | 课程推荐 |
| [67] | 动态本体映射 | HR,采用相似结构层次的本体映射课程属性与学习者属性,根据匹配度进行推荐 | 可整合来自多个来源的信息,以提高效率和用户满意度 | 课程推荐 |
| [68] | 遗传算法 | HR,整合协同过滤推荐和基于内容推荐,并用遗传算法配置推荐系统的最优参数 | 可整合学习者与课程的多种标准,并得到最优配置结果 | 课程推荐 |
| [69] | 序列模式挖掘 | HR,基于显式特征的学习者模型进行聚类,通过序列模式挖掘完成学习资源的排序及推荐 | 有利于解决信息过载和缺乏多样性的问题 | 课程推荐 |
| [42] | 深度知识追踪、模拟退火算法 | HR,基于知识追踪模型预测学习者答题的准确度生成备选题集,再采用模拟退火算法从候选题集中抽取多样性练习题组成推荐列表 | 以学习者答题准确度为目标,并考虑所推荐练习题的多样性和新颖度 | 练习题推荐 |
| [70] | 多目标粒子群优化算法 | HR,以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐 | 考虑在给定时间规划内的多目标推荐问题 | 学习资料推荐 |
| [39] | 自注意力机制 | SR,将学习者在当前会话中所查看主题的历史记录作为输入序列,计算候选线程得分进行推荐 | 能够在没有太多特征属性情况下捕获学习者当前的选择状态 | 课程讨论线程推荐 |
| [78] | 认知诊断模型、PMF | SR,根据答题会话序列形成的认知诊断模型对学习者建模,再采用PMF预测学生的答题情况,最后根据预测结果进行练习题推荐 | 动态捕获学习者的知识掌握状态 | 练习题推荐 |
| [38] | 深度知识追踪、遗传算法 | SR,基于学习者练习答题会话序列预测学习者知识掌握水平,再通过遗传算法设置试卷各项质量指标,生成推荐试卷 | 同时动态捕获多个学习者的知识掌握状态 | 试卷推荐 |
| [46] | 本体 | KR,使用本体分别对学习者、领域知识和学习行为进行建模 | 未给出具体实现过程 | MOOC课程推荐 |
| [71] | 本体 | KR,基于本体描述所学知识点和学习目标相关性的学习资源推荐方法 | 本体中领域知识和推荐规则制定不能避免人工偏差 | 学习资料推荐 |
| [73] | 本体推理和神经网络 | KR,基于本体模型对学习者和学习资源进行水平层级分类,根据评估反馈向学习者推荐相应水平层级资源 | 能够根据学习者的水平状态动态调节推荐内容 | 课程知识概念相应资源的推荐 |
| [48] | 本体 | KR,通过半自动化方法构建了E-learning行为的标准本体.基于本体规则进行推荐 | 能够融合多种个性化参数的学习者模型 | 课程知识概念和主题的推荐 |
| [74] | 本体、语义相似度 | KR,对学习资源进行分类并基于本体生成语义表示.根据学习资源与学习者目标的语义相似度实现推荐 | 无法确保所推荐知识概念的先后顺序相关性 | 学习中的相关词汇推荐 |
| [75] | 知识图谱 | KR,基于学习过程中出现的知识单元相关要素构建知识图谱,从而形成多个学习路径,然后根据学习者的学习日志判断其学习进度,再向其推荐学习路径 | 学习路径的配置既符合规律又具有灵活性 | 学习路径推荐 |
| [15] | 知识图谱 | KR,构建了一个以学习目标为导向的跨学习领域知识图谱,其中包括了六种语义关系,然后结合学习者 的学习目标和学习资源的特征表示推荐学习路径 | 可扩展、可重用 | 跨领域学习路径推荐 |
注:CR,基于内容;CF,协同过滤;HR,混合推荐;SR,基于会话;KR,基于知识. ...
... 目前可用于评估个性化学习推荐系统的通用数据集不多,从当前研究的应用场景来看,可以分为用于课程推荐、学习资源推荐以及学习路径推荐三类.课程推荐常用到edX、Coursera、学堂在线(XuetangX)、中国慕课大学(icourse163)等在线课程平台提供的数据集,比如edX数据集可用于评估基于学习风格的课程推荐[112],XuetangX数据集可用于评估基于学习偏好的课程推荐[55],icourse163数据集可用于课程学习中的主题推荐[39].对于学习资源推荐常采用Amazon产品数据集、ASSISTment学习平台数据集等,比如学习书籍推荐使用Amazon的Book- Crossing数据集[53]、e-book数据集[63],练习题推荐使用ASSISTment数据集[42].对于学习路径推荐而言,离线方法并不能提供可靠的结果,因为其假设学习者的行为不会随时间发生变化,研究人员无法获取适用于他们实验的公共数据集[7],所以通常自组织数据集,比如文献[15]和文献[75]均使用了自组织的数据集对提出的推荐方法进行评估. ...
BPR: Bayesian personalized ranking from implicit feedback
1
2012
... 学习推荐对象建模可以采用“分类”和“交互”两种动态方法实现.“分类”即把推荐对象放入不同类别中,这样可以把同类学习资源推荐给相关的学习者.可以使用基于统计机器学习的分类方法如朴素贝叶斯(Naive-Bayes)、k近邻(k-nearest neighbor,kNN)和支持向量机(support vector machine,SVM)等,也可以使用基于深度学习的方法.推荐对象的类别标签可以预先设置,也可以聚类生成.但是这两种方式都不能完全脱离人工参与,因为由自动聚类产生的标签对学习者来说可能并没有意义.“交互”则利用学习者与推荐对象的交互数据进行建模.文献[54]提出一种基于规则空间(rule-space)模型的推荐方法,该方法根据学习者在学习对象上的学习效果和学习进度等生成诊断表,并进一步将每个课程中学习对象描述为对于学习者的强弱学习状态.文献[55]提出一种基于贝叶斯个性化排序(Bayesian personalized ranking,BPR)算法[56]的MOOC课程推荐模型,该模型沿用了BPR算法的成对排序思想,将一个正样本课程与随机采样的n个负样本课程两两组合成n个“正-负”样本对,然后将它们的编号通过嵌入矩阵转换生成嵌入表示.该方法中还采用了一种可以从成对样本中学习偏好排序的神经网络,用于捕获课程两两之间的偏好排序信息.动态方法利用了“资源-资源”之间的关系、“资源-学习者”之间的动态关系形成推荐对象特征,使对象模型具备了动态性,即能随着推荐对象在系统中随学习过程产生的状态变化而进行调整,有利于更好与不断变化的学习者特征匹配. ...
PC med learner: a personalised and collaborative e-learning materials recommendation system using an ontology based data matching strategy
1
2014
... 基于知识的学习推荐对象建模方法也通常采用领域本体或知识图谱实现.学习资源本体的构建多采用半自动化或手工方式,同样离不开人工参与,难以避免主观偏差.文献[45]通过专家咨询,采用五种特征构建学习资源本体,即:格式、交互类型、交互级别、语义密度和学习资源类型.文献[57]为了提高学习资源本体构建的效率,采用了领域专家协作标注结合DOGMA[58]的本体构建方法,框架如图10所示.该方法在准备好包含相关知识数据的基础上,先进行清洗和修剪,凸显出实体、属性以及关系,并基于此建构推荐对象本体;在本体构建的过程中,再结合领域专家的协作参与不断完善和优化推荐对象本体. ...
An ontology engineering methodology for DOGMA
1
2008
... 基于知识的学习推荐对象建模方法也通常采用领域本体或知识图谱实现.学习资源本体的构建多采用半自动化或手工方式,同样离不开人工参与,难以避免主观偏差.文献[45]通过专家咨询,采用五种特征构建学习资源本体,即:格式、交互类型、交互级别、语义密度和学习资源类型.文献[57]为了提高学习资源本体构建的效率,采用了领域专家协作标注结合DOGMA[58]的本体构建方法,框架如图10所示.该方法在准备好包含相关知识数据的基础上,先进行清洗和修剪,凸显出实体、属性以及关系,并基于此建构推荐对象本体;在本体构建的过程中,再结合领域专家的协作参与不断完善和优化推荐对象本体. ...
Content-based recommendation systems
2
2007
... 许多个性化学习推荐方法参考了电子商务领域的商品推荐方法.这些方法把学习者看作电子商务平台的用户,把学习资源看作商品,以学习者在学习资源上的打分作为推荐模型的训练标签.常用的方法包括基于内容推荐(content-based recommendation,CBR)[59]、协同过滤推荐(collaborative filtering recommendation,CFR)[55,60]以及混合推荐(hybrid recommendation,HR)[61].此外,基于知识的学习推荐方法,以及基于会话的学习推荐方法也是研究的热点,本章将对这些方法进行介绍. ...
... 在学习推荐场景中,该类方法则是基于学习者 对学习资源的评分构建“学习者-学习者”相似度矩阵或“学习资源-学习资源”相似度矩阵,然后根据学习资源项目上的评分找到相似的学习者[59].kNN是协同过滤推荐方法中的常用算法,基于kNN的协同过滤推荐方法根据学习者或项目在相似矩阵中的表示,直接使用所有邻居进行项目之间的相似度计算,在相似矩阵很大的情况下导致了较高的时间复杂度.在推荐应用中,kNN通常采用单个距离度量方法进行相似度的计算,如Cosine[64]、Jaccard[65]、Manhattan[66]等,由于这些指标本身的侧重点不同,可能会对系统的性能产生不同的影响. ...
Tag-based collaborative filtering recommendation in personal learning environments
5
2013
... 许多个性化学习推荐方法参考了电子商务领域的商品推荐方法.这些方法把学习者看作电子商务平台的用户,把学习资源看作商品,以学习者在学习资源上的打分作为推荐模型的训练标签.常用的方法包括基于内容推荐(content-based recommendation,CBR)[59]、协同过滤推荐(collaborative filtering recommendation,CFR)[55,60]以及混合推荐(hybrid recommendation,HR)[61].此外,基于知识的学习推荐方法,以及基于会话的学习推荐方法也是研究的热点,本章将对这些方法进行介绍. ...
... Summary and comparison of personalized learning recommendation methods
Table 1 | 文献 | 主要方法/技术 | 推荐策略 | 优势/局限 | 适用场景 |
| [53] | CNN | CR,基于描述文本生成的学习资源表示结合学习者偏好预测评分进行推荐 | 文本描述有利于对学习资源建模提供更丰富的特征信息 | 具有文本描述的学习资料推荐 |
| [62] | Felder-Silverman学习风格量表 | CR,基于满足规则的情况计算学习资源与学习者的相关性分数,再根据分数排序推荐 | 需要人工定义学习资源与学习者学习风格的关联规则 | 学习资料推荐 |
| [63] | Fuzzy decision tree,CNN | CR,从大量数据中识别出学习资源特征,再根据学习者的理解水平进行推荐 | 学习资源数据描述模型的性能影响推荐的效果 | 学习资料推荐 |
| [55] | BPR成对排序 | CF,通过捕获学习者对课程两两之间的偏好排序形成课程有序队列 | 由于负课程均值采样空间较大,这些课程可能不是最优 | 课程推荐 |
| [60] | Weka API的潜在语义分析 | CF,通过关键字注释将学习者与学习资源建立关联 | 使用关键字注释标签对学习者建模,标签本身源自人工设置,可能导致主观偏差 | 学习资料推荐 |
| [61] | 人工免疫系统(AIS)算法 | HR,根据过往课程学习效果对学习者建模,使用AIS聚类融合基于项目的协同过滤获得备选课程的预测矩阵 | 能够融合多种特征到学习者模型,但对冷启动的缓解效果有限 | 课程推荐 |
| [67] | 动态本体映射 | HR,采用相似结构层次的本体映射课程属性与学习者属性,根据匹配度进行推荐 | 可整合来自多个来源的信息,以提高效率和用户满意度 | 课程推荐 |
| [68] | 遗传算法 | HR,整合协同过滤推荐和基于内容推荐,并用遗传算法配置推荐系统的最优参数 | 可整合学习者与课程的多种标准,并得到最优配置结果 | 课程推荐 |
| [69] | 序列模式挖掘 | HR,基于显式特征的学习者模型进行聚类,通过序列模式挖掘完成学习资源的排序及推荐 | 有利于解决信息过载和缺乏多样性的问题 | 课程推荐 |
| [42] | 深度知识追踪、模拟退火算法 | HR,基于知识追踪模型预测学习者答题的准确度生成备选题集,再采用模拟退火算法从候选题集中抽取多样性练习题组成推荐列表 | 以学习者答题准确度为目标,并考虑所推荐练习题的多样性和新颖度 | 练习题推荐 |
| [70] | 多目标粒子群优化算法 | HR,以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐 | 考虑在给定时间规划内的多目标推荐问题 | 学习资料推荐 |
| [39] | 自注意力机制 | SR,将学习者在当前会话中所查看主题的历史记录作为输入序列,计算候选线程得分进行推荐 | 能够在没有太多特征属性情况下捕获学习者当前的选择状态 | 课程讨论线程推荐 |
| [78] | 认知诊断模型、PMF | SR,根据答题会话序列形成的认知诊断模型对学习者建模,再采用PMF预测学生的答题情况,最后根据预测结果进行练习题推荐 | 动态捕获学习者的知识掌握状态 | 练习题推荐 |
| [38] | 深度知识追踪、遗传算法 | SR,基于学习者练习答题会话序列预测学习者知识掌握水平,再通过遗传算法设置试卷各项质量指标,生成推荐试卷 | 同时动态捕获多个学习者的知识掌握状态 | 试卷推荐 |
| [46] | 本体 | KR,使用本体分别对学习者、领域知识和学习行为进行建模 | 未给出具体实现过程 | MOOC课程推荐 |
| [71] | 本体 | KR,基于本体描述所学知识点和学习目标相关性的学习资源推荐方法 | 本体中领域知识和推荐规则制定不能避免人工偏差 | 学习资料推荐 |
| [73] | 本体推理和神经网络 | KR,基于本体模型对学习者和学习资源进行水平层级分类,根据评估反馈向学习者推荐相应水平层级资源 | 能够根据学习者的水平状态动态调节推荐内容 | 课程知识概念相应资源的推荐 |
| [48] | 本体 | KR,通过半自动化方法构建了E-learning行为的标准本体.基于本体规则进行推荐 | 能够融合多种个性化参数的学习者模型 | 课程知识概念和主题的推荐 |
| [74] | 本体、语义相似度 | KR,对学习资源进行分类并基于本体生成语义表示.根据学习资源与学习者目标的语义相似度实现推荐 | 无法确保所推荐知识概念的先后顺序相关性 | 学习中的相关词汇推荐 |
| [75] | 知识图谱 | KR,基于学习过程中出现的知识单元相关要素构建知识图谱,从而形成多个学习路径,然后根据学习者的学习日志判断其学习进度,再向其推荐学习路径 | 学习路径的配置既符合规律又具有灵活性 | 学习路径推荐 |
| [15] | 知识图谱 | KR,构建了一个以学习目标为导向的跨学习领域知识图谱,其中包括了六种语义关系,然后结合学习者 的学习目标和学习资源的特征表示推荐学习路径 | 可扩展、可重用 | 跨领域学习路径推荐 |
注:CR,基于内容;CF,协同过滤;HR,混合推荐;SR,基于会话;KR,基于知识. ...
... 推荐系统的核心性能是推荐的准确性,即推荐预测值与真值的接近或误差程度.主要包括推荐预测的精度(accuracy)、召回率(recall)、F1分数、平均绝对误差(mean absolute error,MAE)、均方根误差(root mean square error,RMSE)等.有的研究同时采用多个指标的组合方式,以达到多角度评估的目的.比如文献[60]和文献[93]对所提出的推荐算法分别进行了精度、召回率和F1分数的评估.文献[38]使用了召回率和排序质量的指标(normalized discounted cumulative gain,NDCG),因为NDCG是一个有位置感知的度量标准,它能为推荐项目的排名列表更高位置的项目分配更高的分值,从而测量推荐列表的质量.在实际应用中,也可以对系统的性能进行单个指标上的评估,如文献[94]只采用了F1分数,因为F1分数可以看作精度和召回率的一种调和平均,被认为能够同时兼顾精度和召回率.也有的研究从误差的角度来评估推荐系统性能,比如文献[93]和文献[95]采用了平均误差(MAE),文献[96]和文献[97]则使用均方根误差(RMSE).虽然大部分推荐系统性能评估的指标可以用于学习推荐系统的性能评估,但是对于性能的评估只是学习推荐系统评估的角度之一. ...
... 文献[60]对七种推荐的结果进行人工评估,结果表明用户体验的质量与推荐的高精度并不相关.一般而言,用户体验好的推荐内容,除了符合自己偏好外,还要尽量做到不与刚刚看过的内容完全相同或者非常相似,但是一味追求推荐的高精度往往会忽视这一问题.为了解决这一问题,近年来研究人员对推荐的“偶然性”[98,99]开展研究.文献[100]指出,现有大多数的推荐算法基于准确性评估,但难以保障推荐内容能够满足用户需求、偏好的变化,因为单纯准确性可能会导致所推荐内容没有新意.为了获得高的精度评估值,用户可能仅收到那些与他们初始评分高的项目类似的推荐项目(过度专业化).这必然会降低用户体验的满意度[101].因此,用户体验评估的核心指标是推荐的“偶然性”,该指标通常采用新颖度(novelty)和多样性(diversity)等二级指标来衡量.新颖度是指所推荐的项目在用户过往的交互记录中出现得越少越好[102];多样性是指推荐列表中出现的项目越不相似越好,因为用户可能对包含彼此非常相似项目的推荐列表感到不满意[98].新颖而多样的学习资源会在一定程度上激发学习者的学习兴趣,即提高学习资源推荐的新颖度和多样性会对学习者的学习热情产生积极影响[42,53].文献[42]结合练习题的题型、难度、涵盖的知识点等特征,在对练习题推荐精度的基础上,还对推荐的新颖度和多样性进行了评估.对用户体验的评估也常采用人工方法.如文献[103]和文献[104]中,设计了用户体验量表,采用人工打分的方式进行评估,来衡量推荐的感知相关性,此外文献[103]还采用人工打分方式评估了推荐的可用性. ...
... 除此之外,还有不少研究人员使用自主研发平台的数据集,或所在教学机构的数据集来测试推荐性能,以便于进一步对推荐效果进行评估.比如文献[60]从名为PLEM的学习平台获取数据集,用于验证其基于标签的学习资源推荐方法有效性;文献[61]使用了作者所在大学(YZU)在2005—2009年的课程学习数据集;文献[68]使用了作者所在大学(University of Cordoba)计算机相关课程的数据集;文献[67]使用了来自大学课程管理平台UCAS的数据集;文献[73]使用了多所大学的课程学习数据来构成数据集. ...
A hybrid course recommendation system by integrating collaborative filtering and artificial immune systems
4
2016
... 许多个性化学习推荐方法参考了电子商务领域的商品推荐方法.这些方法把学习者看作电子商务平台的用户,把学习资源看作商品,以学习者在学习资源上的打分作为推荐模型的训练标签.常用的方法包括基于内容推荐(content-based recommendation,CBR)[59]、协同过滤推荐(collaborative filtering recommendation,CFR)[55,60]以及混合推荐(hybrid recommendation,HR)[61].此外,基于知识的学习推荐方法,以及基于会话的学习推荐方法也是研究的热点,本章将对这些方法进行介绍. ...
... 混合学习推荐方法(HR)是将多种学习推荐相结合的方法,以达到提高推荐准确度,以及缓解单一推荐方法所可能出现的如矩阵稀疏、冷启动等问题的目的.混合推荐方法最初是将基于内容的推荐方法与协同过滤推荐方法结合,并优化结合策略.如文献[67]提出了一种基于内容推荐和协同过滤推荐的混合方法用于课程推荐,该方法利用本体来克服信息超载问题,即采用相似结构层次的本体来映射课程的属性结构与学习者的特征结构.文献[61]提出了一种采用人工免疫系统算法融合基于内容推荐与协同过滤推荐的课程推荐方法,该方法以学习者的课程学习效果为目标,根据过往课程的学习效果为学习者建模.然后运用免疫网络理论中亲和性与扩展图的概念设计算法,计算学习者与课程的“亲和度”从而实施推荐.对混合学习推荐的研究具有灵活性,可以通过调整其涉及的下级推荐方法,或者优化混合的策略来提升推荐的质量.文献[68]提出了一种采用遗传算法整合多种推荐策略的课程推荐方法,该方法将定制的遗传算法应用于推荐的前置阶段,利用训练数据优化推荐系统的参数配置,然后用该配置构建推荐系统模型.文献[69]提出了一种混合过滤推荐方法,以提高学习推荐的个性化和多样性.该方法首先采用显式学习者建模方法,尽可能丰富学习者的特征描述,然后运用自组织推荐策略进行学习者聚类,最后通过顺序模式挖掘完成学习资源的排序及推荐.文献[42]提出的练习题推荐方法中,融合了基于会话的推荐方法和模拟退火算法,以在保障推荐准确性的同时改善推荐的多样性和新颖度.文献[70]提出了一种基于多目标粒子群优化算法的学习推荐方法,该方法以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐. ...
... Summary and comparison of personalized learning recommendation methods
Table 1 | 文献 | 主要方法/技术 | 推荐策略 | 优势/局限 | 适用场景 |
| [53] | CNN | CR,基于描述文本生成的学习资源表示结合学习者偏好预测评分进行推荐 | 文本描述有利于对学习资源建模提供更丰富的特征信息 | 具有文本描述的学习资料推荐 |
| [62] | Felder-Silverman学习风格量表 | CR,基于满足规则的情况计算学习资源与学习者的相关性分数,再根据分数排序推荐 | 需要人工定义学习资源与学习者学习风格的关联规则 | 学习资料推荐 |
| [63] | Fuzzy decision tree,CNN | CR,从大量数据中识别出学习资源特征,再根据学习者的理解水平进行推荐 | 学习资源数据描述模型的性能影响推荐的效果 | 学习资料推荐 |
| [55] | BPR成对排序 | CF,通过捕获学习者对课程两两之间的偏好排序形成课程有序队列 | 由于负课程均值采样空间较大,这些课程可能不是最优 | 课程推荐 |
| [60] | Weka API的潜在语义分析 | CF,通过关键字注释将学习者与学习资源建立关联 | 使用关键字注释标签对学习者建模,标签本身源自人工设置,可能导致主观偏差 | 学习资料推荐 |
| [61] | 人工免疫系统(AIS)算法 | HR,根据过往课程学习效果对学习者建模,使用AIS聚类融合基于项目的协同过滤获得备选课程的预测矩阵 | 能够融合多种特征到学习者模型,但对冷启动的缓解效果有限 | 课程推荐 |
| [67] | 动态本体映射 | HR,采用相似结构层次的本体映射课程属性与学习者属性,根据匹配度进行推荐 | 可整合来自多个来源的信息,以提高效率和用户满意度 | 课程推荐 |
| [68] | 遗传算法 | HR,整合协同过滤推荐和基于内容推荐,并用遗传算法配置推荐系统的最优参数 | 可整合学习者与课程的多种标准,并得到最优配置结果 | 课程推荐 |
| [69] | 序列模式挖掘 | HR,基于显式特征的学习者模型进行聚类,通过序列模式挖掘完成学习资源的排序及推荐 | 有利于解决信息过载和缺乏多样性的问题 | 课程推荐 |
| [42] | 深度知识追踪、模拟退火算法 | HR,基于知识追踪模型预测学习者答题的准确度生成备选题集,再采用模拟退火算法从候选题集中抽取多样性练习题组成推荐列表 | 以学习者答题准确度为目标,并考虑所推荐练习题的多样性和新颖度 | 练习题推荐 |
| [70] | 多目标粒子群优化算法 | HR,以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐 | 考虑在给定时间规划内的多目标推荐问题 | 学习资料推荐 |
| [39] | 自注意力机制 | SR,将学习者在当前会话中所查看主题的历史记录作为输入序列,计算候选线程得分进行推荐 | 能够在没有太多特征属性情况下捕获学习者当前的选择状态 | 课程讨论线程推荐 |
| [78] | 认知诊断模型、PMF | SR,根据答题会话序列形成的认知诊断模型对学习者建模,再采用PMF预测学生的答题情况,最后根据预测结果进行练习题推荐 | 动态捕获学习者的知识掌握状态 | 练习题推荐 |
| [38] | 深度知识追踪、遗传算法 | SR,基于学习者练习答题会话序列预测学习者知识掌握水平,再通过遗传算法设置试卷各项质量指标,生成推荐试卷 | 同时动态捕获多个学习者的知识掌握状态 | 试卷推荐 |
| [46] | 本体 | KR,使用本体分别对学习者、领域知识和学习行为进行建模 | 未给出具体实现过程 | MOOC课程推荐 |
| [71] | 本体 | KR,基于本体描述所学知识点和学习目标相关性的学习资源推荐方法 | 本体中领域知识和推荐规则制定不能避免人工偏差 | 学习资料推荐 |
| [73] | 本体推理和神经网络 | KR,基于本体模型对学习者和学习资源进行水平层级分类,根据评估反馈向学习者推荐相应水平层级资源 | 能够根据学习者的水平状态动态调节推荐内容 | 课程知识概念相应资源的推荐 |
| [48] | 本体 | KR,通过半自动化方法构建了E-learning行为的标准本体.基于本体规则进行推荐 | 能够融合多种个性化参数的学习者模型 | 课程知识概念和主题的推荐 |
| [74] | 本体、语义相似度 | KR,对学习资源进行分类并基于本体生成语义表示.根据学习资源与学习者目标的语义相似度实现推荐 | 无法确保所推荐知识概念的先后顺序相关性 | 学习中的相关词汇推荐 |
| [75] | 知识图谱 | KR,基于学习过程中出现的知识单元相关要素构建知识图谱,从而形成多个学习路径,然后根据学习者的学习日志判断其学习进度,再向其推荐学习路径 | 学习路径的配置既符合规律又具有灵活性 | 学习路径推荐 |
| [15] | 知识图谱 | KR,构建了一个以学习目标为导向的跨学习领域知识图谱,其中包括了六种语义关系,然后结合学习者 的学习目标和学习资源的特征表示推荐学习路径 | 可扩展、可重用 | 跨领域学习路径推荐 |
注:CR,基于内容;CF,协同过滤;HR,混合推荐;SR,基于会话;KR,基于知识. ...
... 除此之外,还有不少研究人员使用自主研发平台的数据集,或所在教学机构的数据集来测试推荐性能,以便于进一步对推荐效果进行评估.比如文献[60]从名为PLEM的学习平台获取数据集,用于验证其基于标签的学习资源推荐方法有效性;文献[61]使用了作者所在大学(YZU)在2005—2009年的课程学习数据集;文献[68]使用了作者所在大学(University of Cordoba)计算机相关课程的数据集;文献[67]使用了来自大学课程管理平台UCAS的数据集;文献[73]使用了多所大学的课程学习数据来构成数据集. ...
A rule-based approach for adaptive content recommendation in a personalized learning environment: an experimental analysis
2
2019
... 基于内容推荐方法(CBR)是通过比较学习资源的属性特征与学习者的偏好,找到与学习者偏好最符合的学习资源.与电子商务中基于内容的推荐有所不同,基于内容的学习推荐可以借鉴学习领域的一些知识背景,比如学习风格模型.文献[62]通过人工定义若干推荐规则将学习资源的特征与学习者的学习风格模型进行关联,基于满足规则的情况计算学习资源与学习者的相关性分数,再根据分数排序推荐.也有研究将学习资源与学习者的知识掌握水平进行关联,如文献[63]提出了一种学习内容推荐方法,该方法首先采用特征选择模型提取学习资源的表示特征,再将表示特征根据学习者理解水平进行分类,从而在大量数据中识别出确切的学习资源内容,然后根据学习者的理解水平进行推荐.除了与学习资源的属性特征直接比较外,现有研究关注于提取学习资源的潜在特征,以及发掘其与学习者的关联.文献[53]提出的推荐方法通过历史学习资源的文本数据(内容本身或内容简介) 结合学习者偏好训练CNN模型.在使用时,该模型可以将输入的学习资源文本信息转换为学习资源的特征,然后结合学习者偏好预测评分进行推荐.基于内容的学习推荐方法离不开学习资源属性特征,一旦缺乏有用的特征数据,该方法的有效性将大为降低. ...
... Summary and comparison of personalized learning recommendation methods
Table 1 | 文献 | 主要方法/技术 | 推荐策略 | 优势/局限 | 适用场景 |
| [53] | CNN | CR,基于描述文本生成的学习资源表示结合学习者偏好预测评分进行推荐 | 文本描述有利于对学习资源建模提供更丰富的特征信息 | 具有文本描述的学习资料推荐 |
| [62] | Felder-Silverman学习风格量表 | CR,基于满足规则的情况计算学习资源与学习者的相关性分数,再根据分数排序推荐 | 需要人工定义学习资源与学习者学习风格的关联规则 | 学习资料推荐 |
| [63] | Fuzzy decision tree,CNN | CR,从大量数据中识别出学习资源特征,再根据学习者的理解水平进行推荐 | 学习资源数据描述模型的性能影响推荐的效果 | 学习资料推荐 |
| [55] | BPR成对排序 | CF,通过捕获学习者对课程两两之间的偏好排序形成课程有序队列 | 由于负课程均值采样空间较大,这些课程可能不是最优 | 课程推荐 |
| [60] | Weka API的潜在语义分析 | CF,通过关键字注释将学习者与学习资源建立关联 | 使用关键字注释标签对学习者建模,标签本身源自人工设置,可能导致主观偏差 | 学习资料推荐 |
| [61] | 人工免疫系统(AIS)算法 | HR,根据过往课程学习效果对学习者建模,使用AIS聚类融合基于项目的协同过滤获得备选课程的预测矩阵 | 能够融合多种特征到学习者模型,但对冷启动的缓解效果有限 | 课程推荐 |
| [67] | 动态本体映射 | HR,采用相似结构层次的本体映射课程属性与学习者属性,根据匹配度进行推荐 | 可整合来自多个来源的信息,以提高效率和用户满意度 | 课程推荐 |
| [68] | 遗传算法 | HR,整合协同过滤推荐和基于内容推荐,并用遗传算法配置推荐系统的最优参数 | 可整合学习者与课程的多种标准,并得到最优配置结果 | 课程推荐 |
| [69] | 序列模式挖掘 | HR,基于显式特征的学习者模型进行聚类,通过序列模式挖掘完成学习资源的排序及推荐 | 有利于解决信息过载和缺乏多样性的问题 | 课程推荐 |
| [42] | 深度知识追踪、模拟退火算法 | HR,基于知识追踪模型预测学习者答题的准确度生成备选题集,再采用模拟退火算法从候选题集中抽取多样性练习题组成推荐列表 | 以学习者答题准确度为目标,并考虑所推荐练习题的多样性和新颖度 | 练习题推荐 |
| [70] | 多目标粒子群优化算法 | HR,以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐 | 考虑在给定时间规划内的多目标推荐问题 | 学习资料推荐 |
| [39] | 自注意力机制 | SR,将学习者在当前会话中所查看主题的历史记录作为输入序列,计算候选线程得分进行推荐 | 能够在没有太多特征属性情况下捕获学习者当前的选择状态 | 课程讨论线程推荐 |
| [78] | 认知诊断模型、PMF | SR,根据答题会话序列形成的认知诊断模型对学习者建模,再采用PMF预测学生的答题情况,最后根据预测结果进行练习题推荐 | 动态捕获学习者的知识掌握状态 | 练习题推荐 |
| [38] | 深度知识追踪、遗传算法 | SR,基于学习者练习答题会话序列预测学习者知识掌握水平,再通过遗传算法设置试卷各项质量指标,生成推荐试卷 | 同时动态捕获多个学习者的知识掌握状态 | 试卷推荐 |
| [46] | 本体 | KR,使用本体分别对学习者、领域知识和学习行为进行建模 | 未给出具体实现过程 | MOOC课程推荐 |
| [71] | 本体 | KR,基于本体描述所学知识点和学习目标相关性的学习资源推荐方法 | 本体中领域知识和推荐规则制定不能避免人工偏差 | 学习资料推荐 |
| [73] | 本体推理和神经网络 | KR,基于本体模型对学习者和学习资源进行水平层级分类,根据评估反馈向学习者推荐相应水平层级资源 | 能够根据学习者的水平状态动态调节推荐内容 | 课程知识概念相应资源的推荐 |
| [48] | 本体 | KR,通过半自动化方法构建了E-learning行为的标准本体.基于本体规则进行推荐 | 能够融合多种个性化参数的学习者模型 | 课程知识概念和主题的推荐 |
| [74] | 本体、语义相似度 | KR,对学习资源进行分类并基于本体生成语义表示.根据学习资源与学习者目标的语义相似度实现推荐 | 无法确保所推荐知识概念的先后顺序相关性 | 学习中的相关词汇推荐 |
| [75] | 知识图谱 | KR,基于学习过程中出现的知识单元相关要素构建知识图谱,从而形成多个学习路径,然后根据学习者的学习日志判断其学习进度,再向其推荐学习路径 | 学习路径的配置既符合规律又具有灵活性 | 学习路径推荐 |
| [15] | 知识图谱 | KR,构建了一个以学习目标为导向的跨学习领域知识图谱,其中包括了六种语义关系,然后结合学习者 的学习目标和学习资源的特征表示推荐学习路径 | 可扩展、可重用 | 跨领域学习路径推荐 |
注:CR,基于内容;CF,协同过滤;HR,混合推荐;SR,基于会话;KR,基于知识. ...
A content recommendation system for effective e-learning using embedded feature selection and fuzzy DT based CNN
3
2020
... 基于内容推荐方法(CBR)是通过比较学习资源的属性特征与学习者的偏好,找到与学习者偏好最符合的学习资源.与电子商务中基于内容的推荐有所不同,基于内容的学习推荐可以借鉴学习领域的一些知识背景,比如学习风格模型.文献[62]通过人工定义若干推荐规则将学习资源的特征与学习者的学习风格模型进行关联,基于满足规则的情况计算学习资源与学习者的相关性分数,再根据分数排序推荐.也有研究将学习资源与学习者的知识掌握水平进行关联,如文献[63]提出了一种学习内容推荐方法,该方法首先采用特征选择模型提取学习资源的表示特征,再将表示特征根据学习者理解水平进行分类,从而在大量数据中识别出确切的学习资源内容,然后根据学习者的理解水平进行推荐.除了与学习资源的属性特征直接比较外,现有研究关注于提取学习资源的潜在特征,以及发掘其与学习者的关联.文献[53]提出的推荐方法通过历史学习资源的文本数据(内容本身或内容简介) 结合学习者偏好训练CNN模型.在使用时,该模型可以将输入的学习资源文本信息转换为学习资源的特征,然后结合学习者偏好预测评分进行推荐.基于内容的学习推荐方法离不开学习资源属性特征,一旦缺乏有用的特征数据,该方法的有效性将大为降低. ...
... Summary and comparison of personalized learning recommendation methods
Table 1 | 文献 | 主要方法/技术 | 推荐策略 | 优势/局限 | 适用场景 |
| [53] | CNN | CR,基于描述文本生成的学习资源表示结合学习者偏好预测评分进行推荐 | 文本描述有利于对学习资源建模提供更丰富的特征信息 | 具有文本描述的学习资料推荐 |
| [62] | Felder-Silverman学习风格量表 | CR,基于满足规则的情况计算学习资源与学习者的相关性分数,再根据分数排序推荐 | 需要人工定义学习资源与学习者学习风格的关联规则 | 学习资料推荐 |
| [63] | Fuzzy decision tree,CNN | CR,从大量数据中识别出学习资源特征,再根据学习者的理解水平进行推荐 | 学习资源数据描述模型的性能影响推荐的效果 | 学习资料推荐 |
| [55] | BPR成对排序 | CF,通过捕获学习者对课程两两之间的偏好排序形成课程有序队列 | 由于负课程均值采样空间较大,这些课程可能不是最优 | 课程推荐 |
| [60] | Weka API的潜在语义分析 | CF,通过关键字注释将学习者与学习资源建立关联 | 使用关键字注释标签对学习者建模,标签本身源自人工设置,可能导致主观偏差 | 学习资料推荐 |
| [61] | 人工免疫系统(AIS)算法 | HR,根据过往课程学习效果对学习者建模,使用AIS聚类融合基于项目的协同过滤获得备选课程的预测矩阵 | 能够融合多种特征到学习者模型,但对冷启动的缓解效果有限 | 课程推荐 |
| [67] | 动态本体映射 | HR,采用相似结构层次的本体映射课程属性与学习者属性,根据匹配度进行推荐 | 可整合来自多个来源的信息,以提高效率和用户满意度 | 课程推荐 |
| [68] | 遗传算法 | HR,整合协同过滤推荐和基于内容推荐,并用遗传算法配置推荐系统的最优参数 | 可整合学习者与课程的多种标准,并得到最优配置结果 | 课程推荐 |
| [69] | 序列模式挖掘 | HR,基于显式特征的学习者模型进行聚类,通过序列模式挖掘完成学习资源的排序及推荐 | 有利于解决信息过载和缺乏多样性的问题 | 课程推荐 |
| [42] | 深度知识追踪、模拟退火算法 | HR,基于知识追踪模型预测学习者答题的准确度生成备选题集,再采用模拟退火算法从候选题集中抽取多样性练习题组成推荐列表 | 以学习者答题准确度为目标,并考虑所推荐练习题的多样性和新颖度 | 练习题推荐 |
| [70] | 多目标粒子群优化算法 | HR,以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐 | 考虑在给定时间规划内的多目标推荐问题 | 学习资料推荐 |
| [39] | 自注意力机制 | SR,将学习者在当前会话中所查看主题的历史记录作为输入序列,计算候选线程得分进行推荐 | 能够在没有太多特征属性情况下捕获学习者当前的选择状态 | 课程讨论线程推荐 |
| [78] | 认知诊断模型、PMF | SR,根据答题会话序列形成的认知诊断模型对学习者建模,再采用PMF预测学生的答题情况,最后根据预测结果进行练习题推荐 | 动态捕获学习者的知识掌握状态 | 练习题推荐 |
| [38] | 深度知识追踪、遗传算法 | SR,基于学习者练习答题会话序列预测学习者知识掌握水平,再通过遗传算法设置试卷各项质量指标,生成推荐试卷 | 同时动态捕获多个学习者的知识掌握状态 | 试卷推荐 |
| [46] | 本体 | KR,使用本体分别对学习者、领域知识和学习行为进行建模 | 未给出具体实现过程 | MOOC课程推荐 |
| [71] | 本体 | KR,基于本体描述所学知识点和学习目标相关性的学习资源推荐方法 | 本体中领域知识和推荐规则制定不能避免人工偏差 | 学习资料推荐 |
| [73] | 本体推理和神经网络 | KR,基于本体模型对学习者和学习资源进行水平层级分类,根据评估反馈向学习者推荐相应水平层级资源 | 能够根据学习者的水平状态动态调节推荐内容 | 课程知识概念相应资源的推荐 |
| [48] | 本体 | KR,通过半自动化方法构建了E-learning行为的标准本体.基于本体规则进行推荐 | 能够融合多种个性化参数的学习者模型 | 课程知识概念和主题的推荐 |
| [74] | 本体、语义相似度 | KR,对学习资源进行分类并基于本体生成语义表示.根据学习资源与学习者目标的语义相似度实现推荐 | 无法确保所推荐知识概念的先后顺序相关性 | 学习中的相关词汇推荐 |
| [75] | 知识图谱 | KR,基于学习过程中出现的知识单元相关要素构建知识图谱,从而形成多个学习路径,然后根据学习者的学习日志判断其学习进度,再向其推荐学习路径 | 学习路径的配置既符合规律又具有灵活性 | 学习路径推荐 |
| [15] | 知识图谱 | KR,构建了一个以学习目标为导向的跨学习领域知识图谱,其中包括了六种语义关系,然后结合学习者 的学习目标和学习资源的特征表示推荐学习路径 | 可扩展、可重用 | 跨领域学习路径推荐 |
注:CR,基于内容;CF,协同过滤;HR,混合推荐;SR,基于会话;KR,基于知识. ...
... 目前可用于评估个性化学习推荐系统的通用数据集不多,从当前研究的应用场景来看,可以分为用于课程推荐、学习资源推荐以及学习路径推荐三类.课程推荐常用到edX、Coursera、学堂在线(XuetangX)、中国慕课大学(icourse163)等在线课程平台提供的数据集,比如edX数据集可用于评估基于学习风格的课程推荐[112],XuetangX数据集可用于评估基于学习偏好的课程推荐[55],icourse163数据集可用于课程学习中的主题推荐[39].对于学习资源推荐常采用Amazon产品数据集、ASSISTment学习平台数据集等,比如学习书籍推荐使用Amazon的Book- Crossing数据集[53]、e-book数据集[63],练习题推荐使用ASSISTment数据集[42].对于学习路径推荐而言,离线方法并不能提供可靠的结果,因为其假设学习者的行为不会随时间发生变化,研究人员无法获取适用于他们实验的公共数据集[7],所以通常自组织数据集,比如文献[15]和文献[75]均使用了自组织的数据集对提出的推荐方法进行评估. ...
Matrix factorization meets cosine similarity: addressing sparsity problem in collaborative filtering recommender system
1
2014
... 在学习推荐场景中,该类方法则是基于学习者 对学习资源的评分构建“学习者-学习者”相似度矩阵或“学习资源-学习资源”相似度矩阵,然后根据学习资源项目上的评分找到相似的学习者[59].kNN是协同过滤推荐方法中的常用算法,基于kNN的协同过滤推荐方法根据学习者或项目在相似矩阵中的表示,直接使用所有邻居进行项目之间的相似度计算,在相似矩阵很大的情况下导致了较高的时间复杂度.在推荐应用中,kNN通常采用单个距离度量方法进行相似度的计算,如Cosine[64]、Jaccard[65]、Manhattan[66]等,由于这些指标本身的侧重点不同,可能会对系统的性能产生不同的影响. ...
An efficient recommendation generation using relevant Jaccard similarity
1
2019
... 在学习推荐场景中,该类方法则是基于学习者 对学习资源的评分构建“学习者-学习者”相似度矩阵或“学习资源-学习资源”相似度矩阵,然后根据学习资源项目上的评分找到相似的学习者[59].kNN是协同过滤推荐方法中的常用算法,基于kNN的协同过滤推荐方法根据学习者或项目在相似矩阵中的表示,直接使用所有邻居进行项目之间的相似度计算,在相似矩阵很大的情况下导致了较高的时间复杂度.在推荐应用中,kNN通常采用单个距离度量方法进行相似度的计算,如Cosine[64]、Jaccard[65]、Manhattan[66]等,由于这些指标本身的侧重点不同,可能会对系统的性能产生不同的影响. ...
Product recommendation system by approximate search based on Manhattan distance measurement
1
2012
... 在学习推荐场景中,该类方法则是基于学习者 对学习资源的评分构建“学习者-学习者”相似度矩阵或“学习资源-学习资源”相似度矩阵,然后根据学习资源项目上的评分找到相似的学习者[59].kNN是协同过滤推荐方法中的常用算法,基于kNN的协同过滤推荐方法根据学习者或项目在相似矩阵中的表示,直接使用所有邻居进行项目之间的相似度计算,在相似矩阵很大的情况下导致了较高的时间复杂度.在推荐应用中,kNN通常采用单个距离度量方法进行相似度的计算,如Cosine[64]、Jaccard[65]、Manhattan[66]等,由于这些指标本身的侧重点不同,可能会对系统的性能产生不同的影响. ...
Ontology-based personalized course recommendation framework
3
2019
... 混合学习推荐方法(HR)是将多种学习推荐相结合的方法,以达到提高推荐准确度,以及缓解单一推荐方法所可能出现的如矩阵稀疏、冷启动等问题的目的.混合推荐方法最初是将基于内容的推荐方法与协同过滤推荐方法结合,并优化结合策略.如文献[67]提出了一种基于内容推荐和协同过滤推荐的混合方法用于课程推荐,该方法利用本体来克服信息超载问题,即采用相似结构层次的本体来映射课程的属性结构与学习者的特征结构.文献[61]提出了一种采用人工免疫系统算法融合基于内容推荐与协同过滤推荐的课程推荐方法,该方法以学习者的课程学习效果为目标,根据过往课程的学习效果为学习者建模.然后运用免疫网络理论中亲和性与扩展图的概念设计算法,计算学习者与课程的“亲和度”从而实施推荐.对混合学习推荐的研究具有灵活性,可以通过调整其涉及的下级推荐方法,或者优化混合的策略来提升推荐的质量.文献[68]提出了一种采用遗传算法整合多种推荐策略的课程推荐方法,该方法将定制的遗传算法应用于推荐的前置阶段,利用训练数据优化推荐系统的参数配置,然后用该配置构建推荐系统模型.文献[69]提出了一种混合过滤推荐方法,以提高学习推荐的个性化和多样性.该方法首先采用显式学习者建模方法,尽可能丰富学习者的特征描述,然后运用自组织推荐策略进行学习者聚类,最后通过顺序模式挖掘完成学习资源的排序及推荐.文献[42]提出的练习题推荐方法中,融合了基于会话的推荐方法和模拟退火算法,以在保障推荐准确性的同时改善推荐的多样性和新颖度.文献[70]提出了一种基于多目标粒子群优化算法的学习推荐方法,该方法以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐. ...
... Summary and comparison of personalized learning recommendation methods
Table 1 | 文献 | 主要方法/技术 | 推荐策略 | 优势/局限 | 适用场景 |
| [53] | CNN | CR,基于描述文本生成的学习资源表示结合学习者偏好预测评分进行推荐 | 文本描述有利于对学习资源建模提供更丰富的特征信息 | 具有文本描述的学习资料推荐 |
| [62] | Felder-Silverman学习风格量表 | CR,基于满足规则的情况计算学习资源与学习者的相关性分数,再根据分数排序推荐 | 需要人工定义学习资源与学习者学习风格的关联规则 | 学习资料推荐 |
| [63] | Fuzzy decision tree,CNN | CR,从大量数据中识别出学习资源特征,再根据学习者的理解水平进行推荐 | 学习资源数据描述模型的性能影响推荐的效果 | 学习资料推荐 |
| [55] | BPR成对排序 | CF,通过捕获学习者对课程两两之间的偏好排序形成课程有序队列 | 由于负课程均值采样空间较大,这些课程可能不是最优 | 课程推荐 |
| [60] | Weka API的潜在语义分析 | CF,通过关键字注释将学习者与学习资源建立关联 | 使用关键字注释标签对学习者建模,标签本身源自人工设置,可能导致主观偏差 | 学习资料推荐 |
| [61] | 人工免疫系统(AIS)算法 | HR,根据过往课程学习效果对学习者建模,使用AIS聚类融合基于项目的协同过滤获得备选课程的预测矩阵 | 能够融合多种特征到学习者模型,但对冷启动的缓解效果有限 | 课程推荐 |
| [67] | 动态本体映射 | HR,采用相似结构层次的本体映射课程属性与学习者属性,根据匹配度进行推荐 | 可整合来自多个来源的信息,以提高效率和用户满意度 | 课程推荐 |
| [68] | 遗传算法 | HR,整合协同过滤推荐和基于内容推荐,并用遗传算法配置推荐系统的最优参数 | 可整合学习者与课程的多种标准,并得到最优配置结果 | 课程推荐 |
| [69] | 序列模式挖掘 | HR,基于显式特征的学习者模型进行聚类,通过序列模式挖掘完成学习资源的排序及推荐 | 有利于解决信息过载和缺乏多样性的问题 | 课程推荐 |
| [42] | 深度知识追踪、模拟退火算法 | HR,基于知识追踪模型预测学习者答题的准确度生成备选题集,再采用模拟退火算法从候选题集中抽取多样性练习题组成推荐列表 | 以学习者答题准确度为目标,并考虑所推荐练习题的多样性和新颖度 | 练习题推荐 |
| [70] | 多目标粒子群优化算法 | HR,以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐 | 考虑在给定时间规划内的多目标推荐问题 | 学习资料推荐 |
| [39] | 自注意力机制 | SR,将学习者在当前会话中所查看主题的历史记录作为输入序列,计算候选线程得分进行推荐 | 能够在没有太多特征属性情况下捕获学习者当前的选择状态 | 课程讨论线程推荐 |
| [78] | 认知诊断模型、PMF | SR,根据答题会话序列形成的认知诊断模型对学习者建模,再采用PMF预测学生的答题情况,最后根据预测结果进行练习题推荐 | 动态捕获学习者的知识掌握状态 | 练习题推荐 |
| [38] | 深度知识追踪、遗传算法 | SR,基于学习者练习答题会话序列预测学习者知识掌握水平,再通过遗传算法设置试卷各项质量指标,生成推荐试卷 | 同时动态捕获多个学习者的知识掌握状态 | 试卷推荐 |
| [46] | 本体 | KR,使用本体分别对学习者、领域知识和学习行为进行建模 | 未给出具体实现过程 | MOOC课程推荐 |
| [71] | 本体 | KR,基于本体描述所学知识点和学习目标相关性的学习资源推荐方法 | 本体中领域知识和推荐规则制定不能避免人工偏差 | 学习资料推荐 |
| [73] | 本体推理和神经网络 | KR,基于本体模型对学习者和学习资源进行水平层级分类,根据评估反馈向学习者推荐相应水平层级资源 | 能够根据学习者的水平状态动态调节推荐内容 | 课程知识概念相应资源的推荐 |
| [48] | 本体 | KR,通过半自动化方法构建了E-learning行为的标准本体.基于本体规则进行推荐 | 能够融合多种个性化参数的学习者模型 | 课程知识概念和主题的推荐 |
| [74] | 本体、语义相似度 | KR,对学习资源进行分类并基于本体生成语义表示.根据学习资源与学习者目标的语义相似度实现推荐 | 无法确保所推荐知识概念的先后顺序相关性 | 学习中的相关词汇推荐 |
| [75] | 知识图谱 | KR,基于学习过程中出现的知识单元相关要素构建知识图谱,从而形成多个学习路径,然后根据学习者的学习日志判断其学习进度,再向其推荐学习路径 | 学习路径的配置既符合规律又具有灵活性 | 学习路径推荐 |
| [15] | 知识图谱 | KR,构建了一个以学习目标为导向的跨学习领域知识图谱,其中包括了六种语义关系,然后结合学习者 的学习目标和学习资源的特征表示推荐学习路径 | 可扩展、可重用 | 跨领域学习路径推荐 |
注:CR,基于内容;CF,协同过滤;HR,混合推荐;SR,基于会话;KR,基于知识. ...
... 除此之外,还有不少研究人员使用自主研发平台的数据集,或所在教学机构的数据集来测试推荐性能,以便于进一步对推荐效果进行评估.比如文献[60]从名为PLEM的学习平台获取数据集,用于验证其基于标签的学习资源推荐方法有效性;文献[61]使用了作者所在大学(YZU)在2005—2009年的课程学习数据集;文献[68]使用了作者所在大学(University of Cordoba)计算机相关课程的数据集;文献[67]使用了来自大学课程管理平台UCAS的数据集;文献[73]使用了多所大学的课程学习数据来构成数据集. ...
Helping university students to choose elective courses by using a hybrid multi-criteria recommendation system with genetic optimization
3
2020
... 混合学习推荐方法(HR)是将多种学习推荐相结合的方法,以达到提高推荐准确度,以及缓解单一推荐方法所可能出现的如矩阵稀疏、冷启动等问题的目的.混合推荐方法最初是将基于内容的推荐方法与协同过滤推荐方法结合,并优化结合策略.如文献[67]提出了一种基于内容推荐和协同过滤推荐的混合方法用于课程推荐,该方法利用本体来克服信息超载问题,即采用相似结构层次的本体来映射课程的属性结构与学习者的特征结构.文献[61]提出了一种采用人工免疫系统算法融合基于内容推荐与协同过滤推荐的课程推荐方法,该方法以学习者的课程学习效果为目标,根据过往课程的学习效果为学习者建模.然后运用免疫网络理论中亲和性与扩展图的概念设计算法,计算学习者与课程的“亲和度”从而实施推荐.对混合学习推荐的研究具有灵活性,可以通过调整其涉及的下级推荐方法,或者优化混合的策略来提升推荐的质量.文献[68]提出了一种采用遗传算法整合多种推荐策略的课程推荐方法,该方法将定制的遗传算法应用于推荐的前置阶段,利用训练数据优化推荐系统的参数配置,然后用该配置构建推荐系统模型.文献[69]提出了一种混合过滤推荐方法,以提高学习推荐的个性化和多样性.该方法首先采用显式学习者建模方法,尽可能丰富学习者的特征描述,然后运用自组织推荐策略进行学习者聚类,最后通过顺序模式挖掘完成学习资源的排序及推荐.文献[42]提出的练习题推荐方法中,融合了基于会话的推荐方法和模拟退火算法,以在保障推荐准确性的同时改善推荐的多样性和新颖度.文献[70]提出了一种基于多目标粒子群优化算法的学习推荐方法,该方法以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐. ...
... Summary and comparison of personalized learning recommendation methods
Table 1 | 文献 | 主要方法/技术 | 推荐策略 | 优势/局限 | 适用场景 |
| [53] | CNN | CR,基于描述文本生成的学习资源表示结合学习者偏好预测评分进行推荐 | 文本描述有利于对学习资源建模提供更丰富的特征信息 | 具有文本描述的学习资料推荐 |
| [62] | Felder-Silverman学习风格量表 | CR,基于满足规则的情况计算学习资源与学习者的相关性分数,再根据分数排序推荐 | 需要人工定义学习资源与学习者学习风格的关联规则 | 学习资料推荐 |
| [63] | Fuzzy decision tree,CNN | CR,从大量数据中识别出学习资源特征,再根据学习者的理解水平进行推荐 | 学习资源数据描述模型的性能影响推荐的效果 | 学习资料推荐 |
| [55] | BPR成对排序 | CF,通过捕获学习者对课程两两之间的偏好排序形成课程有序队列 | 由于负课程均值采样空间较大,这些课程可能不是最优 | 课程推荐 |
| [60] | Weka API的潜在语义分析 | CF,通过关键字注释将学习者与学习资源建立关联 | 使用关键字注释标签对学习者建模,标签本身源自人工设置,可能导致主观偏差 | 学习资料推荐 |
| [61] | 人工免疫系统(AIS)算法 | HR,根据过往课程学习效果对学习者建模,使用AIS聚类融合基于项目的协同过滤获得备选课程的预测矩阵 | 能够融合多种特征到学习者模型,但对冷启动的缓解效果有限 | 课程推荐 |
| [67] | 动态本体映射 | HR,采用相似结构层次的本体映射课程属性与学习者属性,根据匹配度进行推荐 | 可整合来自多个来源的信息,以提高效率和用户满意度 | 课程推荐 |
| [68] | 遗传算法 | HR,整合协同过滤推荐和基于内容推荐,并用遗传算法配置推荐系统的最优参数 | 可整合学习者与课程的多种标准,并得到最优配置结果 | 课程推荐 |
| [69] | 序列模式挖掘 | HR,基于显式特征的学习者模型进行聚类,通过序列模式挖掘完成学习资源的排序及推荐 | 有利于解决信息过载和缺乏多样性的问题 | 课程推荐 |
| [42] | 深度知识追踪、模拟退火算法 | HR,基于知识追踪模型预测学习者答题的准确度生成备选题集,再采用模拟退火算法从候选题集中抽取多样性练习题组成推荐列表 | 以学习者答题准确度为目标,并考虑所推荐练习题的多样性和新颖度 | 练习题推荐 |
| [70] | 多目标粒子群优化算法 | HR,以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐 | 考虑在给定时间规划内的多目标推荐问题 | 学习资料推荐 |
| [39] | 自注意力机制 | SR,将学习者在当前会话中所查看主题的历史记录作为输入序列,计算候选线程得分进行推荐 | 能够在没有太多特征属性情况下捕获学习者当前的选择状态 | 课程讨论线程推荐 |
| [78] | 认知诊断模型、PMF | SR,根据答题会话序列形成的认知诊断模型对学习者建模,再采用PMF预测学生的答题情况,最后根据预测结果进行练习题推荐 | 动态捕获学习者的知识掌握状态 | 练习题推荐 |
| [38] | 深度知识追踪、遗传算法 | SR,基于学习者练习答题会话序列预测学习者知识掌握水平,再通过遗传算法设置试卷各项质量指标,生成推荐试卷 | 同时动态捕获多个学习者的知识掌握状态 | 试卷推荐 |
| [46] | 本体 | KR,使用本体分别对学习者、领域知识和学习行为进行建模 | 未给出具体实现过程 | MOOC课程推荐 |
| [71] | 本体 | KR,基于本体描述所学知识点和学习目标相关性的学习资源推荐方法 | 本体中领域知识和推荐规则制定不能避免人工偏差 | 学习资料推荐 |
| [73] | 本体推理和神经网络 | KR,基于本体模型对学习者和学习资源进行水平层级分类,根据评估反馈向学习者推荐相应水平层级资源 | 能够根据学习者的水平状态动态调节推荐内容 | 课程知识概念相应资源的推荐 |
| [48] | 本体 | KR,通过半自动化方法构建了E-learning行为的标准本体.基于本体规则进行推荐 | 能够融合多种个性化参数的学习者模型 | 课程知识概念和主题的推荐 |
| [74] | 本体、语义相似度 | KR,对学习资源进行分类并基于本体生成语义表示.根据学习资源与学习者目标的语义相似度实现推荐 | 无法确保所推荐知识概念的先后顺序相关性 | 学习中的相关词汇推荐 |
| [75] | 知识图谱 | KR,基于学习过程中出现的知识单元相关要素构建知识图谱,从而形成多个学习路径,然后根据学习者的学习日志判断其学习进度,再向其推荐学习路径 | 学习路径的配置既符合规律又具有灵活性 | 学习路径推荐 |
| [15] | 知识图谱 | KR,构建了一个以学习目标为导向的跨学习领域知识图谱,其中包括了六种语义关系,然后结合学习者 的学习目标和学习资源的特征表示推荐学习路径 | 可扩展、可重用 | 跨领域学习路径推荐 |
注:CR,基于内容;CF,协同过滤;HR,混合推荐;SR,基于会话;KR,基于知识. ...
... 除此之外,还有不少研究人员使用自主研发平台的数据集,或所在教学机构的数据集来测试推荐性能,以便于进一步对推荐效果进行评估.比如文献[60]从名为PLEM的学习平台获取数据集,用于验证其基于标签的学习资源推荐方法有效性;文献[61]使用了作者所在大学(YZU)在2005—2009年的课程学习数据集;文献[68]使用了作者所在大学(University of Cordoba)计算机相关课程的数据集;文献[67]使用了来自大学课程管理平台UCAS的数据集;文献[73]使用了多所大学的课程学习数据来构成数据集. ...
A hybrid e-learning recommendation approach based on learners’ influence propagation
2
2020
... 混合学习推荐方法(HR)是将多种学习推荐相结合的方法,以达到提高推荐准确度,以及缓解单一推荐方法所可能出现的如矩阵稀疏、冷启动等问题的目的.混合推荐方法最初是将基于内容的推荐方法与协同过滤推荐方法结合,并优化结合策略.如文献[67]提出了一种基于内容推荐和协同过滤推荐的混合方法用于课程推荐,该方法利用本体来克服信息超载问题,即采用相似结构层次的本体来映射课程的属性结构与学习者的特征结构.文献[61]提出了一种采用人工免疫系统算法融合基于内容推荐与协同过滤推荐的课程推荐方法,该方法以学习者的课程学习效果为目标,根据过往课程的学习效果为学习者建模.然后运用免疫网络理论中亲和性与扩展图的概念设计算法,计算学习者与课程的“亲和度”从而实施推荐.对混合学习推荐的研究具有灵活性,可以通过调整其涉及的下级推荐方法,或者优化混合的策略来提升推荐的质量.文献[68]提出了一种采用遗传算法整合多种推荐策略的课程推荐方法,该方法将定制的遗传算法应用于推荐的前置阶段,利用训练数据优化推荐系统的参数配置,然后用该配置构建推荐系统模型.文献[69]提出了一种混合过滤推荐方法,以提高学习推荐的个性化和多样性.该方法首先采用显式学习者建模方法,尽可能丰富学习者的特征描述,然后运用自组织推荐策略进行学习者聚类,最后通过顺序模式挖掘完成学习资源的排序及推荐.文献[42]提出的练习题推荐方法中,融合了基于会话的推荐方法和模拟退火算法,以在保障推荐准确性的同时改善推荐的多样性和新颖度.文献[70]提出了一种基于多目标粒子群优化算法的学习推荐方法,该方法以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐. ...
... Summary and comparison of personalized learning recommendation methods
Table 1 | 文献 | 主要方法/技术 | 推荐策略 | 优势/局限 | 适用场景 |
| [53] | CNN | CR,基于描述文本生成的学习资源表示结合学习者偏好预测评分进行推荐 | 文本描述有利于对学习资源建模提供更丰富的特征信息 | 具有文本描述的学习资料推荐 |
| [62] | Felder-Silverman学习风格量表 | CR,基于满足规则的情况计算学习资源与学习者的相关性分数,再根据分数排序推荐 | 需要人工定义学习资源与学习者学习风格的关联规则 | 学习资料推荐 |
| [63] | Fuzzy decision tree,CNN | CR,从大量数据中识别出学习资源特征,再根据学习者的理解水平进行推荐 | 学习资源数据描述模型的性能影响推荐的效果 | 学习资料推荐 |
| [55] | BPR成对排序 | CF,通过捕获学习者对课程两两之间的偏好排序形成课程有序队列 | 由于负课程均值采样空间较大,这些课程可能不是最优 | 课程推荐 |
| [60] | Weka API的潜在语义分析 | CF,通过关键字注释将学习者与学习资源建立关联 | 使用关键字注释标签对学习者建模,标签本身源自人工设置,可能导致主观偏差 | 学习资料推荐 |
| [61] | 人工免疫系统(AIS)算法 | HR,根据过往课程学习效果对学习者建模,使用AIS聚类融合基于项目的协同过滤获得备选课程的预测矩阵 | 能够融合多种特征到学习者模型,但对冷启动的缓解效果有限 | 课程推荐 |
| [67] | 动态本体映射 | HR,采用相似结构层次的本体映射课程属性与学习者属性,根据匹配度进行推荐 | 可整合来自多个来源的信息,以提高效率和用户满意度 | 课程推荐 |
| [68] | 遗传算法 | HR,整合协同过滤推荐和基于内容推荐,并用遗传算法配置推荐系统的最优参数 | 可整合学习者与课程的多种标准,并得到最优配置结果 | 课程推荐 |
| [69] | 序列模式挖掘 | HR,基于显式特征的学习者模型进行聚类,通过序列模式挖掘完成学习资源的排序及推荐 | 有利于解决信息过载和缺乏多样性的问题 | 课程推荐 |
| [42] | 深度知识追踪、模拟退火算法 | HR,基于知识追踪模型预测学习者答题的准确度生成备选题集,再采用模拟退火算法从候选题集中抽取多样性练习题组成推荐列表 | 以学习者答题准确度为目标,并考虑所推荐练习题的多样性和新颖度 | 练习题推荐 |
| [70] | 多目标粒子群优化算法 | HR,以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐 | 考虑在给定时间规划内的多目标推荐问题 | 学习资料推荐 |
| [39] | 自注意力机制 | SR,将学习者在当前会话中所查看主题的历史记录作为输入序列,计算候选线程得分进行推荐 | 能够在没有太多特征属性情况下捕获学习者当前的选择状态 | 课程讨论线程推荐 |
| [78] | 认知诊断模型、PMF | SR,根据答题会话序列形成的认知诊断模型对学习者建模,再采用PMF预测学生的答题情况,最后根据预测结果进行练习题推荐 | 动态捕获学习者的知识掌握状态 | 练习题推荐 |
| [38] | 深度知识追踪、遗传算法 | SR,基于学习者练习答题会话序列预测学习者知识掌握水平,再通过遗传算法设置试卷各项质量指标,生成推荐试卷 | 同时动态捕获多个学习者的知识掌握状态 | 试卷推荐 |
| [46] | 本体 | KR,使用本体分别对学习者、领域知识和学习行为进行建模 | 未给出具体实现过程 | MOOC课程推荐 |
| [71] | 本体 | KR,基于本体描述所学知识点和学习目标相关性的学习资源推荐方法 | 本体中领域知识和推荐规则制定不能避免人工偏差 | 学习资料推荐 |
| [73] | 本体推理和神经网络 | KR,基于本体模型对学习者和学习资源进行水平层级分类,根据评估反馈向学习者推荐相应水平层级资源 | 能够根据学习者的水平状态动态调节推荐内容 | 课程知识概念相应资源的推荐 |
| [48] | 本体 | KR,通过半自动化方法构建了E-learning行为的标准本体.基于本体规则进行推荐 | 能够融合多种个性化参数的学习者模型 | 课程知识概念和主题的推荐 |
| [74] | 本体、语义相似度 | KR,对学习资源进行分类并基于本体生成语义表示.根据学习资源与学习者目标的语义相似度实现推荐 | 无法确保所推荐知识概念的先后顺序相关性 | 学习中的相关词汇推荐 |
| [75] | 知识图谱 | KR,基于学习过程中出现的知识单元相关要素构建知识图谱,从而形成多个学习路径,然后根据学习者的学习日志判断其学习进度,再向其推荐学习路径 | 学习路径的配置既符合规律又具有灵活性 | 学习路径推荐 |
| [15] | 知识图谱 | KR,构建了一个以学习目标为导向的跨学习领域知识图谱,其中包括了六种语义关系,然后结合学习者 的学习目标和学习资源的特征表示推荐学习路径 | 可扩展、可重用 | 跨领域学习路径推荐 |
注:CR,基于内容;CF,协同过滤;HR,混合推荐;SR,基于会话;KR,基于知识. ...
基于多目标优化策略的在线学习资源推荐方法
2
2019
... 混合学习推荐方法(HR)是将多种学习推荐相结合的方法,以达到提高推荐准确度,以及缓解单一推荐方法所可能出现的如矩阵稀疏、冷启动等问题的目的.混合推荐方法最初是将基于内容的推荐方法与协同过滤推荐方法结合,并优化结合策略.如文献[67]提出了一种基于内容推荐和协同过滤推荐的混合方法用于课程推荐,该方法利用本体来克服信息超载问题,即采用相似结构层次的本体来映射课程的属性结构与学习者的特征结构.文献[61]提出了一种采用人工免疫系统算法融合基于内容推荐与协同过滤推荐的课程推荐方法,该方法以学习者的课程学习效果为目标,根据过往课程的学习效果为学习者建模.然后运用免疫网络理论中亲和性与扩展图的概念设计算法,计算学习者与课程的“亲和度”从而实施推荐.对混合学习推荐的研究具有灵活性,可以通过调整其涉及的下级推荐方法,或者优化混合的策略来提升推荐的质量.文献[68]提出了一种采用遗传算法整合多种推荐策略的课程推荐方法,该方法将定制的遗传算法应用于推荐的前置阶段,利用训练数据优化推荐系统的参数配置,然后用该配置构建推荐系统模型.文献[69]提出了一种混合过滤推荐方法,以提高学习推荐的个性化和多样性.该方法首先采用显式学习者建模方法,尽可能丰富学习者的特征描述,然后运用自组织推荐策略进行学习者聚类,最后通过顺序模式挖掘完成学习资源的排序及推荐.文献[42]提出的练习题推荐方法中,融合了基于会话的推荐方法和模拟退火算法,以在保障推荐准确性的同时改善推荐的多样性和新颖度.文献[70]提出了一种基于多目标粒子群优化算法的学习推荐方法,该方法以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐. ...
... Summary and comparison of personalized learning recommendation methods
Table 1 | 文献 | 主要方法/技术 | 推荐策略 | 优势/局限 | 适用场景 |
| [53] | CNN | CR,基于描述文本生成的学习资源表示结合学习者偏好预测评分进行推荐 | 文本描述有利于对学习资源建模提供更丰富的特征信息 | 具有文本描述的学习资料推荐 |
| [62] | Felder-Silverman学习风格量表 | CR,基于满足规则的情况计算学习资源与学习者的相关性分数,再根据分数排序推荐 | 需要人工定义学习资源与学习者学习风格的关联规则 | 学习资料推荐 |
| [63] | Fuzzy decision tree,CNN | CR,从大量数据中识别出学习资源特征,再根据学习者的理解水平进行推荐 | 学习资源数据描述模型的性能影响推荐的效果 | 学习资料推荐 |
| [55] | BPR成对排序 | CF,通过捕获学习者对课程两两之间的偏好排序形成课程有序队列 | 由于负课程均值采样空间较大,这些课程可能不是最优 | 课程推荐 |
| [60] | Weka API的潜在语义分析 | CF,通过关键字注释将学习者与学习资源建立关联 | 使用关键字注释标签对学习者建模,标签本身源自人工设置,可能导致主观偏差 | 学习资料推荐 |
| [61] | 人工免疫系统(AIS)算法 | HR,根据过往课程学习效果对学习者建模,使用AIS聚类融合基于项目的协同过滤获得备选课程的预测矩阵 | 能够融合多种特征到学习者模型,但对冷启动的缓解效果有限 | 课程推荐 |
| [67] | 动态本体映射 | HR,采用相似结构层次的本体映射课程属性与学习者属性,根据匹配度进行推荐 | 可整合来自多个来源的信息,以提高效率和用户满意度 | 课程推荐 |
| [68] | 遗传算法 | HR,整合协同过滤推荐和基于内容推荐,并用遗传算法配置推荐系统的最优参数 | 可整合学习者与课程的多种标准,并得到最优配置结果 | 课程推荐 |
| [69] | 序列模式挖掘 | HR,基于显式特征的学习者模型进行聚类,通过序列模式挖掘完成学习资源的排序及推荐 | 有利于解决信息过载和缺乏多样性的问题 | 课程推荐 |
| [42] | 深度知识追踪、模拟退火算法 | HR,基于知识追踪模型预测学习者答题的准确度生成备选题集,再采用模拟退火算法从候选题集中抽取多样性练习题组成推荐列表 | 以学习者答题准确度为目标,并考虑所推荐练习题的多样性和新颖度 | 练习题推荐 |
| [70] | 多目标粒子群优化算法 | HR,以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐 | 考虑在给定时间规划内的多目标推荐问题 | 学习资料推荐 |
| [39] | 自注意力机制 | SR,将学习者在当前会话中所查看主题的历史记录作为输入序列,计算候选线程得分进行推荐 | 能够在没有太多特征属性情况下捕获学习者当前的选择状态 | 课程讨论线程推荐 |
| [78] | 认知诊断模型、PMF | SR,根据答题会话序列形成的认知诊断模型对学习者建模,再采用PMF预测学生的答题情况,最后根据预测结果进行练习题推荐 | 动态捕获学习者的知识掌握状态 | 练习题推荐 |
| [38] | 深度知识追踪、遗传算法 | SR,基于学习者练习答题会话序列预测学习者知识掌握水平,再通过遗传算法设置试卷各项质量指标,生成推荐试卷 | 同时动态捕获多个学习者的知识掌握状态 | 试卷推荐 |
| [46] | 本体 | KR,使用本体分别对学习者、领域知识和学习行为进行建模 | 未给出具体实现过程 | MOOC课程推荐 |
| [71] | 本体 | KR,基于本体描述所学知识点和学习目标相关性的学习资源推荐方法 | 本体中领域知识和推荐规则制定不能避免人工偏差 | 学习资料推荐 |
| [73] | 本体推理和神经网络 | KR,基于本体模型对学习者和学习资源进行水平层级分类,根据评估反馈向学习者推荐相应水平层级资源 | 能够根据学习者的水平状态动态调节推荐内容 | 课程知识概念相应资源的推荐 |
| [48] | 本体 | KR,通过半自动化方法构建了E-learning行为的标准本体.基于本体规则进行推荐 | 能够融合多种个性化参数的学习者模型 | 课程知识概念和主题的推荐 |
| [74] | 本体、语义相似度 | KR,对学习资源进行分类并基于本体生成语义表示.根据学习资源与学习者目标的语义相似度实现推荐 | 无法确保所推荐知识概念的先后顺序相关性 | 学习中的相关词汇推荐 |
| [75] | 知识图谱 | KR,基于学习过程中出现的知识单元相关要素构建知识图谱,从而形成多个学习路径,然后根据学习者的学习日志判断其学习进度,再向其推荐学习路径 | 学习路径的配置既符合规律又具有灵活性 | 学习路径推荐 |
| [15] | 知识图谱 | KR,构建了一个以学习目标为导向的跨学习领域知识图谱,其中包括了六种语义关系,然后结合学习者 的学习目标和学习资源的特征表示推荐学习路径 | 可扩展、可重用 | 跨领域学习路径推荐 |
注:CR,基于内容;CF,协同过滤;HR,混合推荐;SR,基于会话;KR,基于知识. ...
Method of online learning resource recommendation based on multi-objective optimization strategy
2
2019
... 混合学习推荐方法(HR)是将多种学习推荐相结合的方法,以达到提高推荐准确度,以及缓解单一推荐方法所可能出现的如矩阵稀疏、冷启动等问题的目的.混合推荐方法最初是将基于内容的推荐方法与协同过滤推荐方法结合,并优化结合策略.如文献[67]提出了一种基于内容推荐和协同过滤推荐的混合方法用于课程推荐,该方法利用本体来克服信息超载问题,即采用相似结构层次的本体来映射课程的属性结构与学习者的特征结构.文献[61]提出了一种采用人工免疫系统算法融合基于内容推荐与协同过滤推荐的课程推荐方法,该方法以学习者的课程学习效果为目标,根据过往课程的学习效果为学习者建模.然后运用免疫网络理论中亲和性与扩展图的概念设计算法,计算学习者与课程的“亲和度”从而实施推荐.对混合学习推荐的研究具有灵活性,可以通过调整其涉及的下级推荐方法,或者优化混合的策略来提升推荐的质量.文献[68]提出了一种采用遗传算法整合多种推荐策略的课程推荐方法,该方法将定制的遗传算法应用于推荐的前置阶段,利用训练数据优化推荐系统的参数配置,然后用该配置构建推荐系统模型.文献[69]提出了一种混合过滤推荐方法,以提高学习推荐的个性化和多样性.该方法首先采用显式学习者建模方法,尽可能丰富学习者的特征描述,然后运用自组织推荐策略进行学习者聚类,最后通过顺序模式挖掘完成学习资源的排序及推荐.文献[42]提出的练习题推荐方法中,融合了基于会话的推荐方法和模拟退火算法,以在保障推荐准确性的同时改善推荐的多样性和新颖度.文献[70]提出了一种基于多目标粒子群优化算法的学习推荐方法,该方法以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐. ...
... Summary and comparison of personalized learning recommendation methods
Table 1 | 文献 | 主要方法/技术 | 推荐策略 | 优势/局限 | 适用场景 |
| [53] | CNN | CR,基于描述文本生成的学习资源表示结合学习者偏好预测评分进行推荐 | 文本描述有利于对学习资源建模提供更丰富的特征信息 | 具有文本描述的学习资料推荐 |
| [62] | Felder-Silverman学习风格量表 | CR,基于满足规则的情况计算学习资源与学习者的相关性分数,再根据分数排序推荐 | 需要人工定义学习资源与学习者学习风格的关联规则 | 学习资料推荐 |
| [63] | Fuzzy decision tree,CNN | CR,从大量数据中识别出学习资源特征,再根据学习者的理解水平进行推荐 | 学习资源数据描述模型的性能影响推荐的效果 | 学习资料推荐 |
| [55] | BPR成对排序 | CF,通过捕获学习者对课程两两之间的偏好排序形成课程有序队列 | 由于负课程均值采样空间较大,这些课程可能不是最优 | 课程推荐 |
| [60] | Weka API的潜在语义分析 | CF,通过关键字注释将学习者与学习资源建立关联 | 使用关键字注释标签对学习者建模,标签本身源自人工设置,可能导致主观偏差 | 学习资料推荐 |
| [61] | 人工免疫系统(AIS)算法 | HR,根据过往课程学习效果对学习者建模,使用AIS聚类融合基于项目的协同过滤获得备选课程的预测矩阵 | 能够融合多种特征到学习者模型,但对冷启动的缓解效果有限 | 课程推荐 |
| [67] | 动态本体映射 | HR,采用相似结构层次的本体映射课程属性与学习者属性,根据匹配度进行推荐 | 可整合来自多个来源的信息,以提高效率和用户满意度 | 课程推荐 |
| [68] | 遗传算法 | HR,整合协同过滤推荐和基于内容推荐,并用遗传算法配置推荐系统的最优参数 | 可整合学习者与课程的多种标准,并得到最优配置结果 | 课程推荐 |
| [69] | 序列模式挖掘 | HR,基于显式特征的学习者模型进行聚类,通过序列模式挖掘完成学习资源的排序及推荐 | 有利于解决信息过载和缺乏多样性的问题 | 课程推荐 |
| [42] | 深度知识追踪、模拟退火算法 | HR,基于知识追踪模型预测学习者答题的准确度生成备选题集,再采用模拟退火算法从候选题集中抽取多样性练习题组成推荐列表 | 以学习者答题准确度为目标,并考虑所推荐练习题的多样性和新颖度 | 练习题推荐 |
| [70] | 多目标粒子群优化算法 | HR,以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐 | 考虑在给定时间规划内的多目标推荐问题 | 学习资料推荐 |
| [39] | 自注意力机制 | SR,将学习者在当前会话中所查看主题的历史记录作为输入序列,计算候选线程得分进行推荐 | 能够在没有太多特征属性情况下捕获学习者当前的选择状态 | 课程讨论线程推荐 |
| [78] | 认知诊断模型、PMF | SR,根据答题会话序列形成的认知诊断模型对学习者建模,再采用PMF预测学生的答题情况,最后根据预测结果进行练习题推荐 | 动态捕获学习者的知识掌握状态 | 练习题推荐 |
| [38] | 深度知识追踪、遗传算法 | SR,基于学习者练习答题会话序列预测学习者知识掌握水平,再通过遗传算法设置试卷各项质量指标,生成推荐试卷 | 同时动态捕获多个学习者的知识掌握状态 | 试卷推荐 |
| [46] | 本体 | KR,使用本体分别对学习者、领域知识和学习行为进行建模 | 未给出具体实现过程 | MOOC课程推荐 |
| [71] | 本体 | KR,基于本体描述所学知识点和学习目标相关性的学习资源推荐方法 | 本体中领域知识和推荐规则制定不能避免人工偏差 | 学习资料推荐 |
| [73] | 本体推理和神经网络 | KR,基于本体模型对学习者和学习资源进行水平层级分类,根据评估反馈向学习者推荐相应水平层级资源 | 能够根据学习者的水平状态动态调节推荐内容 | 课程知识概念相应资源的推荐 |
| [48] | 本体 | KR,通过半自动化方法构建了E-learning行为的标准本体.基于本体规则进行推荐 | 能够融合多种个性化参数的学习者模型 | 课程知识概念和主题的推荐 |
| [74] | 本体、语义相似度 | KR,对学习资源进行分类并基于本体生成语义表示.根据学习资源与学习者目标的语义相似度实现推荐 | 无法确保所推荐知识概念的先后顺序相关性 | 学习中的相关词汇推荐 |
| [75] | 知识图谱 | KR,基于学习过程中出现的知识单元相关要素构建知识图谱,从而形成多个学习路径,然后根据学习者的学习日志判断其学习进度,再向其推荐学习路径 | 学习路径的配置既符合规律又具有灵活性 | 学习路径推荐 |
| [15] | 知识图谱 | KR,构建了一个以学习目标为导向的跨学习领域知识图谱,其中包括了六种语义关系,然后结合学习者 的学习目标和学习资源的特征表示推荐学习路径 | 可扩展、可重用 | 跨领域学习路径推荐 |
注:CR,基于内容;CF,协同过滤;HR,混合推荐;SR,基于会话;KR,基于知识. ...
Knowledge-based recommendation: a review of ontology-based recommender systems for e-learning
3
2018
... 学习是一种在教育情境中符合一定心理规律的行为,这是基于知识(knowledge-based)学习推荐方法[71]的研究背景,这种推荐方法将学习者和学习资源的有关知识结合考虑,并应用到推荐过程中,根据学习者在领域知识中的偏好向其推荐学习资源.基于知识的推荐系统需要使用三种类型的知识:即用户的知识、项目的知识以及项目与用户需求之间匹配的知识[72].而这种方法的主要缺点是对领域知识整理的要求离不开人工参与,往往带有主观偏差,而且所构建领域知识的完备性也难以保障.使用本体对学习领域进行建模是基于知识学习推荐中的常用手段.在此过程中,除了可以用本体对学习者和学习资源的知识进行建模[43,48,73]之外,还可以用它来描述学习场景中的要素.比如,文献[43]构建了E-learning环境中的学习行为标准本体.文献[46]使用本体描述了学习者在学习过程中表现的行为,分别对学习者、领域知识和学习行为进行建模.文献[74]设计了一个框架来存储学习资源,对学习资源进行分类并基于本体生成资源表示. ...
... 基于知识的学习推荐方法具有灵活性的语义描述域,文献[52]提出一种采用本体综合描述CBR、CFR、HR等推荐算法,并选择性调用相关算法的课程推荐方法,该方法能够根据需求,对已描述的推荐算法进行动态调用.基于知识的学习推荐方法广受关注的主要原因在于:教学是一个有规律的活动,学习行为的目标明确,而且学习资源特征与学习者的需求之间的映射规则易于定制.但是,领域本体或领域知识图谱的构建也是一个需要人工参与,且耗时耗力的过程,所构建本体的合理性和完备性也会影响推荐的效果[71,76].此外,学习者的状态,如情感、知识水平并非一成不变,知识的描述如果没有合理的更新机制,则会导致学习路径固化,反而与“个性化”的初衷相悖. ...
... Summary and comparison of personalized learning recommendation methods
Table 1 | 文献 | 主要方法/技术 | 推荐策略 | 优势/局限 | 适用场景 |
| [53] | CNN | CR,基于描述文本生成的学习资源表示结合学习者偏好预测评分进行推荐 | 文本描述有利于对学习资源建模提供更丰富的特征信息 | 具有文本描述的学习资料推荐 |
| [62] | Felder-Silverman学习风格量表 | CR,基于满足规则的情况计算学习资源与学习者的相关性分数,再根据分数排序推荐 | 需要人工定义学习资源与学习者学习风格的关联规则 | 学习资料推荐 |
| [63] | Fuzzy decision tree,CNN | CR,从大量数据中识别出学习资源特征,再根据学习者的理解水平进行推荐 | 学习资源数据描述模型的性能影响推荐的效果 | 学习资料推荐 |
| [55] | BPR成对排序 | CF,通过捕获学习者对课程两两之间的偏好排序形成课程有序队列 | 由于负课程均值采样空间较大,这些课程可能不是最优 | 课程推荐 |
| [60] | Weka API的潜在语义分析 | CF,通过关键字注释将学习者与学习资源建立关联 | 使用关键字注释标签对学习者建模,标签本身源自人工设置,可能导致主观偏差 | 学习资料推荐 |
| [61] | 人工免疫系统(AIS)算法 | HR,根据过往课程学习效果对学习者建模,使用AIS聚类融合基于项目的协同过滤获得备选课程的预测矩阵 | 能够融合多种特征到学习者模型,但对冷启动的缓解效果有限 | 课程推荐 |
| [67] | 动态本体映射 | HR,采用相似结构层次的本体映射课程属性与学习者属性,根据匹配度进行推荐 | 可整合来自多个来源的信息,以提高效率和用户满意度 | 课程推荐 |
| [68] | 遗传算法 | HR,整合协同过滤推荐和基于内容推荐,并用遗传算法配置推荐系统的最优参数 | 可整合学习者与课程的多种标准,并得到最优配置结果 | 课程推荐 |
| [69] | 序列模式挖掘 | HR,基于显式特征的学习者模型进行聚类,通过序列模式挖掘完成学习资源的排序及推荐 | 有利于解决信息过载和缺乏多样性的问题 | 课程推荐 |
| [42] | 深度知识追踪、模拟退火算法 | HR,基于知识追踪模型预测学习者答题的准确度生成备选题集,再采用模拟退火算法从候选题集中抽取多样性练习题组成推荐列表 | 以学习者答题准确度为目标,并考虑所推荐练习题的多样性和新颖度 | 练习题推荐 |
| [70] | 多目标粒子群优化算法 | HR,以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐 | 考虑在给定时间规划内的多目标推荐问题 | 学习资料推荐 |
| [39] | 自注意力机制 | SR,将学习者在当前会话中所查看主题的历史记录作为输入序列,计算候选线程得分进行推荐 | 能够在没有太多特征属性情况下捕获学习者当前的选择状态 | 课程讨论线程推荐 |
| [78] | 认知诊断模型、PMF | SR,根据答题会话序列形成的认知诊断模型对学习者建模,再采用PMF预测学生的答题情况,最后根据预测结果进行练习题推荐 | 动态捕获学习者的知识掌握状态 | 练习题推荐 |
| [38] | 深度知识追踪、遗传算法 | SR,基于学习者练习答题会话序列预测学习者知识掌握水平,再通过遗传算法设置试卷各项质量指标,生成推荐试卷 | 同时动态捕获多个学习者的知识掌握状态 | 试卷推荐 |
| [46] | 本体 | KR,使用本体分别对学习者、领域知识和学习行为进行建模 | 未给出具体实现过程 | MOOC课程推荐 |
| [71] | 本体 | KR,基于本体描述所学知识点和学习目标相关性的学习资源推荐方法 | 本体中领域知识和推荐规则制定不能避免人工偏差 | 学习资料推荐 |
| [73] | 本体推理和神经网络 | KR,基于本体模型对学习者和学习资源进行水平层级分类,根据评估反馈向学习者推荐相应水平层级资源 | 能够根据学习者的水平状态动态调节推荐内容 | 课程知识概念相应资源的推荐 |
| [48] | 本体 | KR,通过半自动化方法构建了E-learning行为的标准本体.基于本体规则进行推荐 | 能够融合多种个性化参数的学习者模型 | 课程知识概念和主题的推荐 |
| [74] | 本体、语义相似度 | KR,对学习资源进行分类并基于本体生成语义表示.根据学习资源与学习者目标的语义相似度实现推荐 | 无法确保所推荐知识概念的先后顺序相关性 | 学习中的相关词汇推荐 |
| [75] | 知识图谱 | KR,基于学习过程中出现的知识单元相关要素构建知识图谱,从而形成多个学习路径,然后根据学习者的学习日志判断其学习进度,再向其推荐学习路径 | 学习路径的配置既符合规律又具有灵活性 | 学习路径推荐 |
| [15] | 知识图谱 | KR,构建了一个以学习目标为导向的跨学习领域知识图谱,其中包括了六种语义关系,然后结合学习者 的学习目标和学习资源的特征表示推荐学习路径 | 可扩展、可重用 | 跨领域学习路径推荐 |
注:CR,基于内容;CF,协同过滤;HR,混合推荐;SR,基于会话;KR,基于知识. ...
RecomMetz: a context-aware knowledge-based mobile recommender system for movie showtimes
1
2015
... 学习是一种在教育情境中符合一定心理规律的行为,这是基于知识(knowledge-based)学习推荐方法[71]的研究背景,这种推荐方法将学习者和学习资源的有关知识结合考虑,并应用到推荐过程中,根据学习者在领域知识中的偏好向其推荐学习资源.基于知识的推荐系统需要使用三种类型的知识:即用户的知识、项目的知识以及项目与用户需求之间匹配的知识[72].而这种方法的主要缺点是对领域知识整理的要求离不开人工参与,往往带有主观偏差,而且所构建领域知识的完备性也难以保障.使用本体对学习领域进行建模是基于知识学习推荐中的常用手段.在此过程中,除了可以用本体对学习者和学习资源的知识进行建模[43,48,73]之外,还可以用它来描述学习场景中的要素.比如,文献[43]构建了E-learning环境中的学习行为标准本体.文献[46]使用本体描述了学习者在学习过程中表现的行为,分别对学习者、领域知识和学习行为进行建模.文献[74]设计了一个框架来存储学习资源,对学习资源进行分类并基于本体生成资源表示. ...
Ontology based e-learning framework: a personalized, adaptive and context aware model
3
2019
... 学习是一种在教育情境中符合一定心理规律的行为,这是基于知识(knowledge-based)学习推荐方法[71]的研究背景,这种推荐方法将学习者和学习资源的有关知识结合考虑,并应用到推荐过程中,根据学习者在领域知识中的偏好向其推荐学习资源.基于知识的推荐系统需要使用三种类型的知识:即用户的知识、项目的知识以及项目与用户需求之间匹配的知识[72].而这种方法的主要缺点是对领域知识整理的要求离不开人工参与,往往带有主观偏差,而且所构建领域知识的完备性也难以保障.使用本体对学习领域进行建模是基于知识学习推荐中的常用手段.在此过程中,除了可以用本体对学习者和学习资源的知识进行建模[43,48,73]之外,还可以用它来描述学习场景中的要素.比如,文献[43]构建了E-learning环境中的学习行为标准本体.文献[46]使用本体描述了学习者在学习过程中表现的行为,分别对学习者、领域知识和学习行为进行建模.文献[74]设计了一个框架来存储学习资源,对学习资源进行分类并基于本体生成资源表示. ...
... Summary and comparison of personalized learning recommendation methods
Table 1 | 文献 | 主要方法/技术 | 推荐策略 | 优势/局限 | 适用场景 |
| [53] | CNN | CR,基于描述文本生成的学习资源表示结合学习者偏好预测评分进行推荐 | 文本描述有利于对学习资源建模提供更丰富的特征信息 | 具有文本描述的学习资料推荐 |
| [62] | Felder-Silverman学习风格量表 | CR,基于满足规则的情况计算学习资源与学习者的相关性分数,再根据分数排序推荐 | 需要人工定义学习资源与学习者学习风格的关联规则 | 学习资料推荐 |
| [63] | Fuzzy decision tree,CNN | CR,从大量数据中识别出学习资源特征,再根据学习者的理解水平进行推荐 | 学习资源数据描述模型的性能影响推荐的效果 | 学习资料推荐 |
| [55] | BPR成对排序 | CF,通过捕获学习者对课程两两之间的偏好排序形成课程有序队列 | 由于负课程均值采样空间较大,这些课程可能不是最优 | 课程推荐 |
| [60] | Weka API的潜在语义分析 | CF,通过关键字注释将学习者与学习资源建立关联 | 使用关键字注释标签对学习者建模,标签本身源自人工设置,可能导致主观偏差 | 学习资料推荐 |
| [61] | 人工免疫系统(AIS)算法 | HR,根据过往课程学习效果对学习者建模,使用AIS聚类融合基于项目的协同过滤获得备选课程的预测矩阵 | 能够融合多种特征到学习者模型,但对冷启动的缓解效果有限 | 课程推荐 |
| [67] | 动态本体映射 | HR,采用相似结构层次的本体映射课程属性与学习者属性,根据匹配度进行推荐 | 可整合来自多个来源的信息,以提高效率和用户满意度 | 课程推荐 |
| [68] | 遗传算法 | HR,整合协同过滤推荐和基于内容推荐,并用遗传算法配置推荐系统的最优参数 | 可整合学习者与课程的多种标准,并得到最优配置结果 | 课程推荐 |
| [69] | 序列模式挖掘 | HR,基于显式特征的学习者模型进行聚类,通过序列模式挖掘完成学习资源的排序及推荐 | 有利于解决信息过载和缺乏多样性的问题 | 课程推荐 |
| [42] | 深度知识追踪、模拟退火算法 | HR,基于知识追踪模型预测学习者答题的准确度生成备选题集,再采用模拟退火算法从候选题集中抽取多样性练习题组成推荐列表 | 以学习者答题准确度为目标,并考虑所推荐练习题的多样性和新颖度 | 练习题推荐 |
| [70] | 多目标粒子群优化算法 | HR,以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐 | 考虑在给定时间规划内的多目标推荐问题 | 学习资料推荐 |
| [39] | 自注意力机制 | SR,将学习者在当前会话中所查看主题的历史记录作为输入序列,计算候选线程得分进行推荐 | 能够在没有太多特征属性情况下捕获学习者当前的选择状态 | 课程讨论线程推荐 |
| [78] | 认知诊断模型、PMF | SR,根据答题会话序列形成的认知诊断模型对学习者建模,再采用PMF预测学生的答题情况,最后根据预测结果进行练习题推荐 | 动态捕获学习者的知识掌握状态 | 练习题推荐 |
| [38] | 深度知识追踪、遗传算法 | SR,基于学习者练习答题会话序列预测学习者知识掌握水平,再通过遗传算法设置试卷各项质量指标,生成推荐试卷 | 同时动态捕获多个学习者的知识掌握状态 | 试卷推荐 |
| [46] | 本体 | KR,使用本体分别对学习者、领域知识和学习行为进行建模 | 未给出具体实现过程 | MOOC课程推荐 |
| [71] | 本体 | KR,基于本体描述所学知识点和学习目标相关性的学习资源推荐方法 | 本体中领域知识和推荐规则制定不能避免人工偏差 | 学习资料推荐 |
| [73] | 本体推理和神经网络 | KR,基于本体模型对学习者和学习资源进行水平层级分类,根据评估反馈向学习者推荐相应水平层级资源 | 能够根据学习者的水平状态动态调节推荐内容 | 课程知识概念相应资源的推荐 |
| [48] | 本体 | KR,通过半自动化方法构建了E-learning行为的标准本体.基于本体规则进行推荐 | 能够融合多种个性化参数的学习者模型 | 课程知识概念和主题的推荐 |
| [74] | 本体、语义相似度 | KR,对学习资源进行分类并基于本体生成语义表示.根据学习资源与学习者目标的语义相似度实现推荐 | 无法确保所推荐知识概念的先后顺序相关性 | 学习中的相关词汇推荐 |
| [75] | 知识图谱 | KR,基于学习过程中出现的知识单元相关要素构建知识图谱,从而形成多个学习路径,然后根据学习者的学习日志判断其学习进度,再向其推荐学习路径 | 学习路径的配置既符合规律又具有灵活性 | 学习路径推荐 |
| [15] | 知识图谱 | KR,构建了一个以学习目标为导向的跨学习领域知识图谱,其中包括了六种语义关系,然后结合学习者 的学习目标和学习资源的特征表示推荐学习路径 | 可扩展、可重用 | 跨领域学习路径推荐 |
注:CR,基于内容;CF,协同过滤;HR,混合推荐;SR,基于会话;KR,基于知识. ...
... 除此之外,还有不少研究人员使用自主研发平台的数据集,或所在教学机构的数据集来测试推荐性能,以便于进一步对推荐效果进行评估.比如文献[60]从名为PLEM的学习平台获取数据集,用于验证其基于标签的学习资源推荐方法有效性;文献[61]使用了作者所在大学(YZU)在2005—2009年的课程学习数据集;文献[68]使用了作者所在大学(University of Cordoba)计算机相关课程的数据集;文献[67]使用了来自大学课程管理平台UCAS的数据集;文献[73]使用了多所大学的课程学习数据来构成数据集. ...
A framework of semantic recommender systems for e-learning
3
2015
... 学习是一种在教育情境中符合一定心理规律的行为,这是基于知识(knowledge-based)学习推荐方法[71]的研究背景,这种推荐方法将学习者和学习资源的有关知识结合考虑,并应用到推荐过程中,根据学习者在领域知识中的偏好向其推荐学习资源.基于知识的推荐系统需要使用三种类型的知识:即用户的知识、项目的知识以及项目与用户需求之间匹配的知识[72].而这种方法的主要缺点是对领域知识整理的要求离不开人工参与,往往带有主观偏差,而且所构建领域知识的完备性也难以保障.使用本体对学习领域进行建模是基于知识学习推荐中的常用手段.在此过程中,除了可以用本体对学习者和学习资源的知识进行建模[43,48,73]之外,还可以用它来描述学习场景中的要素.比如,文献[43]构建了E-learning环境中的学习行为标准本体.文献[46]使用本体描述了学习者在学习过程中表现的行为,分别对学习者、领域知识和学习行为进行建模.文献[74]设计了一个框架来存储学习资源,对学习资源进行分类并基于本体生成资源表示. ...
... Summary and comparison of personalized learning recommendation methods
Table 1 | 文献 | 主要方法/技术 | 推荐策略 | 优势/局限 | 适用场景 |
| [53] | CNN | CR,基于描述文本生成的学习资源表示结合学习者偏好预测评分进行推荐 | 文本描述有利于对学习资源建模提供更丰富的特征信息 | 具有文本描述的学习资料推荐 |
| [62] | Felder-Silverman学习风格量表 | CR,基于满足规则的情况计算学习资源与学习者的相关性分数,再根据分数排序推荐 | 需要人工定义学习资源与学习者学习风格的关联规则 | 学习资料推荐 |
| [63] | Fuzzy decision tree,CNN | CR,从大量数据中识别出学习资源特征,再根据学习者的理解水平进行推荐 | 学习资源数据描述模型的性能影响推荐的效果 | 学习资料推荐 |
| [55] | BPR成对排序 | CF,通过捕获学习者对课程两两之间的偏好排序形成课程有序队列 | 由于负课程均值采样空间较大,这些课程可能不是最优 | 课程推荐 |
| [60] | Weka API的潜在语义分析 | CF,通过关键字注释将学习者与学习资源建立关联 | 使用关键字注释标签对学习者建模,标签本身源自人工设置,可能导致主观偏差 | 学习资料推荐 |
| [61] | 人工免疫系统(AIS)算法 | HR,根据过往课程学习效果对学习者建模,使用AIS聚类融合基于项目的协同过滤获得备选课程的预测矩阵 | 能够融合多种特征到学习者模型,但对冷启动的缓解效果有限 | 课程推荐 |
| [67] | 动态本体映射 | HR,采用相似结构层次的本体映射课程属性与学习者属性,根据匹配度进行推荐 | 可整合来自多个来源的信息,以提高效率和用户满意度 | 课程推荐 |
| [68] | 遗传算法 | HR,整合协同过滤推荐和基于内容推荐,并用遗传算法配置推荐系统的最优参数 | 可整合学习者与课程的多种标准,并得到最优配置结果 | 课程推荐 |
| [69] | 序列模式挖掘 | HR,基于显式特征的学习者模型进行聚类,通过序列模式挖掘完成学习资源的排序及推荐 | 有利于解决信息过载和缺乏多样性的问题 | 课程推荐 |
| [42] | 深度知识追踪、模拟退火算法 | HR,基于知识追踪模型预测学习者答题的准确度生成备选题集,再采用模拟退火算法从候选题集中抽取多样性练习题组成推荐列表 | 以学习者答题准确度为目标,并考虑所推荐练习题的多样性和新颖度 | 练习题推荐 |
| [70] | 多目标粒子群优化算法 | HR,以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐 | 考虑在给定时间规划内的多目标推荐问题 | 学习资料推荐 |
| [39] | 自注意力机制 | SR,将学习者在当前会话中所查看主题的历史记录作为输入序列,计算候选线程得分进行推荐 | 能够在没有太多特征属性情况下捕获学习者当前的选择状态 | 课程讨论线程推荐 |
| [78] | 认知诊断模型、PMF | SR,根据答题会话序列形成的认知诊断模型对学习者建模,再采用PMF预测学生的答题情况,最后根据预测结果进行练习题推荐 | 动态捕获学习者的知识掌握状态 | 练习题推荐 |
| [38] | 深度知识追踪、遗传算法 | SR,基于学习者练习答题会话序列预测学习者知识掌握水平,再通过遗传算法设置试卷各项质量指标,生成推荐试卷 | 同时动态捕获多个学习者的知识掌握状态 | 试卷推荐 |
| [46] | 本体 | KR,使用本体分别对学习者、领域知识和学习行为进行建模 | 未给出具体实现过程 | MOOC课程推荐 |
| [71] | 本体 | KR,基于本体描述所学知识点和学习目标相关性的学习资源推荐方法 | 本体中领域知识和推荐规则制定不能避免人工偏差 | 学习资料推荐 |
| [73] | 本体推理和神经网络 | KR,基于本体模型对学习者和学习资源进行水平层级分类,根据评估反馈向学习者推荐相应水平层级资源 | 能够根据学习者的水平状态动态调节推荐内容 | 课程知识概念相应资源的推荐 |
| [48] | 本体 | KR,通过半自动化方法构建了E-learning行为的标准本体.基于本体规则进行推荐 | 能够融合多种个性化参数的学习者模型 | 课程知识概念和主题的推荐 |
| [74] | 本体、语义相似度 | KR,对学习资源进行分类并基于本体生成语义表示.根据学习资源与学习者目标的语义相似度实现推荐 | 无法确保所推荐知识概念的先后顺序相关性 | 学习中的相关词汇推荐 |
| [75] | 知识图谱 | KR,基于学习过程中出现的知识单元相关要素构建知识图谱,从而形成多个学习路径,然后根据学习者的学习日志判断其学习进度,再向其推荐学习路径 | 学习路径的配置既符合规律又具有灵活性 | 学习路径推荐 |
| [15] | 知识图谱 | KR,构建了一个以学习目标为导向的跨学习领域知识图谱,其中包括了六种语义关系,然后结合学习者 的学习目标和学习资源的特征表示推荐学习路径 | 可扩展、可重用 | 跨领域学习路径推荐 |
注:CR,基于内容;CF,协同过滤;HR,混合推荐;SR,基于会话;KR,基于知识. ...
... 随着在线教育和网络技术的蓬勃发展,开放式 学习拓展了学习推荐系统的应用场景[14].在开放式的学习环境下,学习者往往会登录多个在线学习平台、学习管理平台,使用各种各样的学习资源,直接或间接地与其他学习者接触.开放式学习环境网络中的某些学习资源由于来源于不同的系统,相互之间可能存在较大的特征结构差异.为了解决这一问题,文献[80]以分布式MOOC平台为基础,将多个平台各类型学习资源整合至统一平台,其学习资源推荐方法采用了基于Apriori的改进分布式关联规则挖掘算法.文献[33]提出了一种基于分布式在线学习的视频推荐模型,该模型采用去中心化服务供应商协同工作以处理学习视频的大规模上下文数据.有的研究利用了本体在知识表示形式化方面的优势,从组成学习环境网络的异构数据中发现相似学习资源.如文献[74]提出了本体匹配的概念,通过比较不同实体的本体相似性,实现学习资源在各种学习搜索引擎和学习管理系统之间共享.此外,可以将包含多模态学习资源的在线学习平台看作异质信息网络(heterogeneity information networks,HIN)[81,82,83]的一个实例,如图12所示,由学习者、学习资源、教师等实体构成.文献[84]根据网络中实体之间的关系,提取“学习者-学习资源-学习者”“学习者-教师-学习者”等元路径,提出了基于HIN的学习资源推荐方法. ...
A multi-constraint learning path recommendation algorithm based on knowledge map
3
2018
... 近年来基于知识图谱的学习推荐方法受到了关注.文献[75]基于学习过程中已出现知识单元、目标知识单元、知识单元依赖等构建知识图谱,从而形成多个学习路径,然后根据学习者的学习日志判断其学习进度,再向其推荐学习路径.文献[15]构建了一个以学习目标为导向的跨学习领域知识图谱,其中包括了六种语义关系,然后结合学习者的学习目标和学习资源的特征表示推荐学习路径. ...
... Summary and comparison of personalized learning recommendation methods
Table 1 | 文献 | 主要方法/技术 | 推荐策略 | 优势/局限 | 适用场景 |
| [53] | CNN | CR,基于描述文本生成的学习资源表示结合学习者偏好预测评分进行推荐 | 文本描述有利于对学习资源建模提供更丰富的特征信息 | 具有文本描述的学习资料推荐 |
| [62] | Felder-Silverman学习风格量表 | CR,基于满足规则的情况计算学习资源与学习者的相关性分数,再根据分数排序推荐 | 需要人工定义学习资源与学习者学习风格的关联规则 | 学习资料推荐 |
| [63] | Fuzzy decision tree,CNN | CR,从大量数据中识别出学习资源特征,再根据学习者的理解水平进行推荐 | 学习资源数据描述模型的性能影响推荐的效果 | 学习资料推荐 |
| [55] | BPR成对排序 | CF,通过捕获学习者对课程两两之间的偏好排序形成课程有序队列 | 由于负课程均值采样空间较大,这些课程可能不是最优 | 课程推荐 |
| [60] | Weka API的潜在语义分析 | CF,通过关键字注释将学习者与学习资源建立关联 | 使用关键字注释标签对学习者建模,标签本身源自人工设置,可能导致主观偏差 | 学习资料推荐 |
| [61] | 人工免疫系统(AIS)算法 | HR,根据过往课程学习效果对学习者建模,使用AIS聚类融合基于项目的协同过滤获得备选课程的预测矩阵 | 能够融合多种特征到学习者模型,但对冷启动的缓解效果有限 | 课程推荐 |
| [67] | 动态本体映射 | HR,采用相似结构层次的本体映射课程属性与学习者属性,根据匹配度进行推荐 | 可整合来自多个来源的信息,以提高效率和用户满意度 | 课程推荐 |
| [68] | 遗传算法 | HR,整合协同过滤推荐和基于内容推荐,并用遗传算法配置推荐系统的最优参数 | 可整合学习者与课程的多种标准,并得到最优配置结果 | 课程推荐 |
| [69] | 序列模式挖掘 | HR,基于显式特征的学习者模型进行聚类,通过序列模式挖掘完成学习资源的排序及推荐 | 有利于解决信息过载和缺乏多样性的问题 | 课程推荐 |
| [42] | 深度知识追踪、模拟退火算法 | HR,基于知识追踪模型预测学习者答题的准确度生成备选题集,再采用模拟退火算法从候选题集中抽取多样性练习题组成推荐列表 | 以学习者答题准确度为目标,并考虑所推荐练习题的多样性和新颖度 | 练习题推荐 |
| [70] | 多目标粒子群优化算法 | HR,以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐 | 考虑在给定时间规划内的多目标推荐问题 | 学习资料推荐 |
| [39] | 自注意力机制 | SR,将学习者在当前会话中所查看主题的历史记录作为输入序列,计算候选线程得分进行推荐 | 能够在没有太多特征属性情况下捕获学习者当前的选择状态 | 课程讨论线程推荐 |
| [78] | 认知诊断模型、PMF | SR,根据答题会话序列形成的认知诊断模型对学习者建模,再采用PMF预测学生的答题情况,最后根据预测结果进行练习题推荐 | 动态捕获学习者的知识掌握状态 | 练习题推荐 |
| [38] | 深度知识追踪、遗传算法 | SR,基于学习者练习答题会话序列预测学习者知识掌握水平,再通过遗传算法设置试卷各项质量指标,生成推荐试卷 | 同时动态捕获多个学习者的知识掌握状态 | 试卷推荐 |
| [46] | 本体 | KR,使用本体分别对学习者、领域知识和学习行为进行建模 | 未给出具体实现过程 | MOOC课程推荐 |
| [71] | 本体 | KR,基于本体描述所学知识点和学习目标相关性的学习资源推荐方法 | 本体中领域知识和推荐规则制定不能避免人工偏差 | 学习资料推荐 |
| [73] | 本体推理和神经网络 | KR,基于本体模型对学习者和学习资源进行水平层级分类,根据评估反馈向学习者推荐相应水平层级资源 | 能够根据学习者的水平状态动态调节推荐内容 | 课程知识概念相应资源的推荐 |
| [48] | 本体 | KR,通过半自动化方法构建了E-learning行为的标准本体.基于本体规则进行推荐 | 能够融合多种个性化参数的学习者模型 | 课程知识概念和主题的推荐 |
| [74] | 本体、语义相似度 | KR,对学习资源进行分类并基于本体生成语义表示.根据学习资源与学习者目标的语义相似度实现推荐 | 无法确保所推荐知识概念的先后顺序相关性 | 学习中的相关词汇推荐 |
| [75] | 知识图谱 | KR,基于学习过程中出现的知识单元相关要素构建知识图谱,从而形成多个学习路径,然后根据学习者的学习日志判断其学习进度,再向其推荐学习路径 | 学习路径的配置既符合规律又具有灵活性 | 学习路径推荐 |
| [15] | 知识图谱 | KR,构建了一个以学习目标为导向的跨学习领域知识图谱,其中包括了六种语义关系,然后结合学习者 的学习目标和学习资源的特征表示推荐学习路径 | 可扩展、可重用 | 跨领域学习路径推荐 |
注:CR,基于内容;CF,协同过滤;HR,混合推荐;SR,基于会话;KR,基于知识. ...
... 目前可用于评估个性化学习推荐系统的通用数据集不多,从当前研究的应用场景来看,可以分为用于课程推荐、学习资源推荐以及学习路径推荐三类.课程推荐常用到edX、Coursera、学堂在线(XuetangX)、中国慕课大学(icourse163)等在线课程平台提供的数据集,比如edX数据集可用于评估基于学习风格的课程推荐[112],XuetangX数据集可用于评估基于学习偏好的课程推荐[55],icourse163数据集可用于课程学习中的主题推荐[39].对于学习资源推荐常采用Amazon产品数据集、ASSISTment学习平台数据集等,比如学习书籍推荐使用Amazon的Book- Crossing数据集[53]、e-book数据集[63],练习题推荐使用ASSISTment数据集[42].对于学习路径推荐而言,离线方法并不能提供可靠的结果,因为其假设学习者的行为不会随时间发生变化,研究人员无法获取适用于他们实验的公共数据集[7],所以通常自组织数据集,比如文献[15]和文献[75]均使用了自组织的数据集对提出的推荐方法进行评估. ...
Graph theory based model for learning path recommendation
1
2013
... 基于知识的学习推荐方法具有灵活性的语义描述域,文献[52]提出一种采用本体综合描述CBR、CFR、HR等推荐算法,并选择性调用相关算法的课程推荐方法,该方法能够根据需求,对已描述的推荐算法进行动态调用.基于知识的学习推荐方法广受关注的主要原因在于:教学是一个有规律的活动,学习行为的目标明确,而且学习资源特征与学习者的需求之间的映射规则易于定制.但是,领域本体或领域知识图谱的构建也是一个需要人工参与,且耗时耗力的过程,所构建本体的合理性和完备性也会影响推荐的效果[71,76].此外,学习者的状态,如情感、知识水平并非一成不变,知识的描述如果没有合理的更新机制,则会导致学习路径固化,反而与“个性化”的初衷相悖. ...
A survey on session-based recommender systems
1
2019
... CBR基于用户和项目的静态特征,而CFR则依赖长期的“用户-项目”交互历史数据,两者都在一定程度上忽略了用户近期状态的变化,这会导致用户当前真实状态被长期平均情况所掩盖.而且,CBR和CFR通常将一个基础交互单元(如评分、点击等)分解为多个“用户-项目”的交互对记录,并将这些记录混合,这样显然不利于保留用户在交互事件中所隐含的“状态转移”.此外,在实际应用场景中,用户信息往往并不完全,并且只有处于正在进行会话中的用户行为更能体现其当前状态.因此,能对有限范围内(一个会话)的行为进行建模是提高推荐质量的有效途径.近年来,基于会话(session-based)的推荐方法[77]成为研究热点.采用基于会话的方法,能捕获用户状态的变化,并将其更好地应用于推荐模型的训练.文献[39]提出了一种基于会话的MOOC课程讨论线程推荐方法,该方法将学习者在当前会话中所查看主题的历史记录作为输入序列,通过模型计算候选线程的推荐得分,最后输出得分最高的前几个线程组成推荐列表.在学习推荐场景下,除了偏好可能会随着学习过程而发生变化之外,学习者的知识掌握状态也在学习过程中不断变化,知识掌握状态是学习发展的核心因素.文献[78]提出了一种基于认知诊断模型预测学习者知识掌握状态的个性化练习题推荐方法,该方法根据学生的答题会话记录所形成的认知诊断模型表示学习者知识掌握状态,再采用PMF预测学生的答题情况,最后根据预测结果进行练习题推荐.文献[42]提出的练习题推荐方法采用深度知识追踪(deep knowledge tracing,DKT)[79]模型捕获学习者知识掌握状态变化,并用知识点掌握概率为学习者建模;采用 LSTM模型预测知识点出现概率并以此对练习题建模.在形成学习者和练习题的表示后,通过匹配、筛选和排序生成练习题推荐列表. ...
基于认知诊断的个性化试题推荐方法
2
2017
... CBR基于用户和项目的静态特征,而CFR则依赖长期的“用户-项目”交互历史数据,两者都在一定程度上忽略了用户近期状态的变化,这会导致用户当前真实状态被长期平均情况所掩盖.而且,CBR和CFR通常将一个基础交互单元(如评分、点击等)分解为多个“用户-项目”的交互对记录,并将这些记录混合,这样显然不利于保留用户在交互事件中所隐含的“状态转移”.此外,在实际应用场景中,用户信息往往并不完全,并且只有处于正在进行会话中的用户行为更能体现其当前状态.因此,能对有限范围内(一个会话)的行为进行建模是提高推荐质量的有效途径.近年来,基于会话(session-based)的推荐方法[77]成为研究热点.采用基于会话的方法,能捕获用户状态的变化,并将其更好地应用于推荐模型的训练.文献[39]提出了一种基于会话的MOOC课程讨论线程推荐方法,该方法将学习者在当前会话中所查看主题的历史记录作为输入序列,通过模型计算候选线程的推荐得分,最后输出得分最高的前几个线程组成推荐列表.在学习推荐场景下,除了偏好可能会随着学习过程而发生变化之外,学习者的知识掌握状态也在学习过程中不断变化,知识掌握状态是学习发展的核心因素.文献[78]提出了一种基于认知诊断模型预测学习者知识掌握状态的个性化练习题推荐方法,该方法根据学生的答题会话记录所形成的认知诊断模型表示学习者知识掌握状态,再采用PMF预测学生的答题情况,最后根据预测结果进行练习题推荐.文献[42]提出的练习题推荐方法采用深度知识追踪(deep knowledge tracing,DKT)[79]模型捕获学习者知识掌握状态变化,并用知识点掌握概率为学习者建模;采用 LSTM模型预测知识点出现概率并以此对练习题建模.在形成学习者和练习题的表示后,通过匹配、筛选和排序生成练习题推荐列表. ...
... Summary and comparison of personalized learning recommendation methods
Table 1 | 文献 | 主要方法/技术 | 推荐策略 | 优势/局限 | 适用场景 |
| [53] | CNN | CR,基于描述文本生成的学习资源表示结合学习者偏好预测评分进行推荐 | 文本描述有利于对学习资源建模提供更丰富的特征信息 | 具有文本描述的学习资料推荐 |
| [62] | Felder-Silverman学习风格量表 | CR,基于满足规则的情况计算学习资源与学习者的相关性分数,再根据分数排序推荐 | 需要人工定义学习资源与学习者学习风格的关联规则 | 学习资料推荐 |
| [63] | Fuzzy decision tree,CNN | CR,从大量数据中识别出学习资源特征,再根据学习者的理解水平进行推荐 | 学习资源数据描述模型的性能影响推荐的效果 | 学习资料推荐 |
| [55] | BPR成对排序 | CF,通过捕获学习者对课程两两之间的偏好排序形成课程有序队列 | 由于负课程均值采样空间较大,这些课程可能不是最优 | 课程推荐 |
| [60] | Weka API的潜在语义分析 | CF,通过关键字注释将学习者与学习资源建立关联 | 使用关键字注释标签对学习者建模,标签本身源自人工设置,可能导致主观偏差 | 学习资料推荐 |
| [61] | 人工免疫系统(AIS)算法 | HR,根据过往课程学习效果对学习者建模,使用AIS聚类融合基于项目的协同过滤获得备选课程的预测矩阵 | 能够融合多种特征到学习者模型,但对冷启动的缓解效果有限 | 课程推荐 |
| [67] | 动态本体映射 | HR,采用相似结构层次的本体映射课程属性与学习者属性,根据匹配度进行推荐 | 可整合来自多个来源的信息,以提高效率和用户满意度 | 课程推荐 |
| [68] | 遗传算法 | HR,整合协同过滤推荐和基于内容推荐,并用遗传算法配置推荐系统的最优参数 | 可整合学习者与课程的多种标准,并得到最优配置结果 | 课程推荐 |
| [69] | 序列模式挖掘 | HR,基于显式特征的学习者模型进行聚类,通过序列模式挖掘完成学习资源的排序及推荐 | 有利于解决信息过载和缺乏多样性的问题 | 课程推荐 |
| [42] | 深度知识追踪、模拟退火算法 | HR,基于知识追踪模型预测学习者答题的准确度生成备选题集,再采用模拟退火算法从候选题集中抽取多样性练习题组成推荐列表 | 以学习者答题准确度为目标,并考虑所推荐练习题的多样性和新颖度 | 练习题推荐 |
| [70] | 多目标粒子群优化算法 | HR,以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐 | 考虑在给定时间规划内的多目标推荐问题 | 学习资料推荐 |
| [39] | 自注意力机制 | SR,将学习者在当前会话中所查看主题的历史记录作为输入序列,计算候选线程得分进行推荐 | 能够在没有太多特征属性情况下捕获学习者当前的选择状态 | 课程讨论线程推荐 |
| [78] | 认知诊断模型、PMF | SR,根据答题会话序列形成的认知诊断模型对学习者建模,再采用PMF预测学生的答题情况,最后根据预测结果进行练习题推荐 | 动态捕获学习者的知识掌握状态 | 练习题推荐 |
| [38] | 深度知识追踪、遗传算法 | SR,基于学习者练习答题会话序列预测学习者知识掌握水平,再通过遗传算法设置试卷各项质量指标,生成推荐试卷 | 同时动态捕获多个学习者的知识掌握状态 | 试卷推荐 |
| [46] | 本体 | KR,使用本体分别对学习者、领域知识和学习行为进行建模 | 未给出具体实现过程 | MOOC课程推荐 |
| [71] | 本体 | KR,基于本体描述所学知识点和学习目标相关性的学习资源推荐方法 | 本体中领域知识和推荐规则制定不能避免人工偏差 | 学习资料推荐 |
| [73] | 本体推理和神经网络 | KR,基于本体模型对学习者和学习资源进行水平层级分类,根据评估反馈向学习者推荐相应水平层级资源 | 能够根据学习者的水平状态动态调节推荐内容 | 课程知识概念相应资源的推荐 |
| [48] | 本体 | KR,通过半自动化方法构建了E-learning行为的标准本体.基于本体规则进行推荐 | 能够融合多种个性化参数的学习者模型 | 课程知识概念和主题的推荐 |
| [74] | 本体、语义相似度 | KR,对学习资源进行分类并基于本体生成语义表示.根据学习资源与学习者目标的语义相似度实现推荐 | 无法确保所推荐知识概念的先后顺序相关性 | 学习中的相关词汇推荐 |
| [75] | 知识图谱 | KR,基于学习过程中出现的知识单元相关要素构建知识图谱,从而形成多个学习路径,然后根据学习者的学习日志判断其学习进度,再向其推荐学习路径 | 学习路径的配置既符合规律又具有灵活性 | 学习路径推荐 |
| [15] | 知识图谱 | KR,构建了一个以学习目标为导向的跨学习领域知识图谱,其中包括了六种语义关系,然后结合学习者 的学习目标和学习资源的特征表示推荐学习路径 | 可扩展、可重用 | 跨领域学习路径推荐 |
注:CR,基于内容;CF,协同过滤;HR,混合推荐;SR,基于会话;KR,基于知识. ...
Cognitive diagnosis based personalized question recommendation
2
2017
... CBR基于用户和项目的静态特征,而CFR则依赖长期的“用户-项目”交互历史数据,两者都在一定程度上忽略了用户近期状态的变化,这会导致用户当前真实状态被长期平均情况所掩盖.而且,CBR和CFR通常将一个基础交互单元(如评分、点击等)分解为多个“用户-项目”的交互对记录,并将这些记录混合,这样显然不利于保留用户在交互事件中所隐含的“状态转移”.此外,在实际应用场景中,用户信息往往并不完全,并且只有处于正在进行会话中的用户行为更能体现其当前状态.因此,能对有限范围内(一个会话)的行为进行建模是提高推荐质量的有效途径.近年来,基于会话(session-based)的推荐方法[77]成为研究热点.采用基于会话的方法,能捕获用户状态的变化,并将其更好地应用于推荐模型的训练.文献[39]提出了一种基于会话的MOOC课程讨论线程推荐方法,该方法将学习者在当前会话中所查看主题的历史记录作为输入序列,通过模型计算候选线程的推荐得分,最后输出得分最高的前几个线程组成推荐列表.在学习推荐场景下,除了偏好可能会随着学习过程而发生变化之外,学习者的知识掌握状态也在学习过程中不断变化,知识掌握状态是学习发展的核心因素.文献[78]提出了一种基于认知诊断模型预测学习者知识掌握状态的个性化练习题推荐方法,该方法根据学生的答题会话记录所形成的认知诊断模型表示学习者知识掌握状态,再采用PMF预测学生的答题情况,最后根据预测结果进行练习题推荐.文献[42]提出的练习题推荐方法采用深度知识追踪(deep knowledge tracing,DKT)[79]模型捕获学习者知识掌握状态变化,并用知识点掌握概率为学习者建模;采用 LSTM模型预测知识点出现概率并以此对练习题建模.在形成学习者和练习题的表示后,通过匹配、筛选和排序生成练习题推荐列表. ...
... Summary and comparison of personalized learning recommendation methods
Table 1 | 文献 | 主要方法/技术 | 推荐策略 | 优势/局限 | 适用场景 |
| [53] | CNN | CR,基于描述文本生成的学习资源表示结合学习者偏好预测评分进行推荐 | 文本描述有利于对学习资源建模提供更丰富的特征信息 | 具有文本描述的学习资料推荐 |
| [62] | Felder-Silverman学习风格量表 | CR,基于满足规则的情况计算学习资源与学习者的相关性分数,再根据分数排序推荐 | 需要人工定义学习资源与学习者学习风格的关联规则 | 学习资料推荐 |
| [63] | Fuzzy decision tree,CNN | CR,从大量数据中识别出学习资源特征,再根据学习者的理解水平进行推荐 | 学习资源数据描述模型的性能影响推荐的效果 | 学习资料推荐 |
| [55] | BPR成对排序 | CF,通过捕获学习者对课程两两之间的偏好排序形成课程有序队列 | 由于负课程均值采样空间较大,这些课程可能不是最优 | 课程推荐 |
| [60] | Weka API的潜在语义分析 | CF,通过关键字注释将学习者与学习资源建立关联 | 使用关键字注释标签对学习者建模,标签本身源自人工设置,可能导致主观偏差 | 学习资料推荐 |
| [61] | 人工免疫系统(AIS)算法 | HR,根据过往课程学习效果对学习者建模,使用AIS聚类融合基于项目的协同过滤获得备选课程的预测矩阵 | 能够融合多种特征到学习者模型,但对冷启动的缓解效果有限 | 课程推荐 |
| [67] | 动态本体映射 | HR,采用相似结构层次的本体映射课程属性与学习者属性,根据匹配度进行推荐 | 可整合来自多个来源的信息,以提高效率和用户满意度 | 课程推荐 |
| [68] | 遗传算法 | HR,整合协同过滤推荐和基于内容推荐,并用遗传算法配置推荐系统的最优参数 | 可整合学习者与课程的多种标准,并得到最优配置结果 | 课程推荐 |
| [69] | 序列模式挖掘 | HR,基于显式特征的学习者模型进行聚类,通过序列模式挖掘完成学习资源的排序及推荐 | 有利于解决信息过载和缺乏多样性的问题 | 课程推荐 |
| [42] | 深度知识追踪、模拟退火算法 | HR,基于知识追踪模型预测学习者答题的准确度生成备选题集,再采用模拟退火算法从候选题集中抽取多样性练习题组成推荐列表 | 以学习者答题准确度为目标,并考虑所推荐练习题的多样性和新颖度 | 练习题推荐 |
| [70] | 多目标粒子群优化算法 | HR,以学习者规划的时间为约束,以同时满足学习者偏好和学习资源难度最适宜为优化目标进行学习资源推荐 | 考虑在给定时间规划内的多目标推荐问题 | 学习资料推荐 |
| [39] | 自注意力机制 | SR,将学习者在当前会话中所查看主题的历史记录作为输入序列,计算候选线程得分进行推荐 | 能够在没有太多特征属性情况下捕获学习者当前的选择状态 | 课程讨论线程推荐 |
| [78] | 认知诊断模型、PMF | SR,根据答题会话序列形成的认知诊断模型对学习者建模,再采用PMF预测学生的答题情况,最后根据预测结果进行练习题推荐 | 动态捕获学习者的知识掌握状态 | 练习题推荐 |
| [38] | 深度知识追踪、遗传算法 | SR,基于学习者练习答题会话序列预测学习者知识掌握水平,再通过遗传算法设置试卷各项质量指标,生成推荐试卷 | 同时动态捕获多个学习者的知识掌握状态 | 试卷推荐 |
| [46] | 本体 | KR,使用本体分别对学习者、领域知识和学习行为进行建模 | 未给出具体实现过程 | MOOC课程推荐 |
| [71] | 本体 | KR,基于本体描述所学知识点和学习目标相关性的学习资源推荐方法 | 本体中领域知识和推荐规则制定不能避免人工偏差 | 学习资料推荐 |
| [73] | 本体推理和神经网络 | KR,基于本体模型对学习者和学习资源进行水平层级分类,根据评估反馈向学习者推荐相应水平层级资源 | 能够根据学习者的水平状态动态调节推荐内容 | 课程知识概念相应资源的推荐 |
| [48] | 本体 | KR,通过半自动化方法构建了E-learning行为的标准本体.基于本体规则进行推荐 | 能够融合多种个性化参数的学习者模型 | 课程知识概念和主题的推荐 |
| [74] | 本体、语义相似度 | KR,对学习资源进行分类并基于本体生成语义表示.根据学习资源与学习者目标的语义相似度实现推荐 | 无法确保所推荐知识概念的先后顺序相关性 | 学习中的相关词汇推荐 |
| [75] | 知识图谱 | KR,基于学习过程中出现的知识单元相关要素构建知识图谱,从而形成多个学习路径,然后根据学习者的学习日志判断其学习进度,再向其推荐学习路径 | 学习路径的配置既符合规律又具有灵活性 | 学习路径推荐 |
| [15] | 知识图谱 | KR,构建了一个以学习目标为导向的跨学习领域知识图谱,其中包括了六种语义关系,然后结合学习者 的学习目标和学习资源的特征表示推荐学习路径 | 可扩展、可重用 | 跨领域学习路径推荐 |
注:CR,基于内容;CF,协同过滤;HR,混合推荐;SR,基于会话;KR,基于知识. ...
Deep knowledge tracing
2
2015
... CBR基于用户和项目的静态特征,而CFR则依赖长期的“用户-项目”交互历史数据,两者都在一定程度上忽略了用户近期状态的变化,这会导致用户当前真实状态被长期平均情况所掩盖.而且,CBR和CFR通常将一个基础交互单元(如评分、点击等)分解为多个“用户-项目”的交互对记录,并将这些记录混合,这样显然不利于保留用户在交互事件中所隐含的“状态转移”.此外,在实际应用场景中,用户信息往往并不完全,并且只有处于正在进行会话中的用户行为更能体现其当前状态.因此,能对有限范围内(一个会话)的行为进行建模是提高推荐质量的有效途径.近年来,基于会话(session-based)的推荐方法[77]成为研究热点.采用基于会话的方法,能捕获用户状态的变化,并将其更好地应用于推荐模型的训练.文献[39]提出了一种基于会话的MOOC课程讨论线程推荐方法,该方法将学习者在当前会话中所查看主题的历史记录作为输入序列,通过模型计算候选线程的推荐得分,最后输出得分最高的前几个线程组成推荐列表.在学习推荐场景下,除了偏好可能会随着学习过程而发生变化之外,学习者的知识掌握状态也在学习过程中不断变化,知识掌握状态是学习发展的核心因素.文献[78]提出了一种基于认知诊断模型预测学习者知识掌握状态的个性化练习题推荐方法,该方法根据学生的答题会话记录所形成的认知诊断模型表示学习者知识掌握状态,再采用PMF预测学生的答题情况,最后根据预测结果进行练习题推荐.文献[42]提出的练习题推荐方法采用深度知识追踪(deep knowledge tracing,DKT)[79]模型捕获学习者知识掌握状态变化,并用知识点掌握概率为学习者建模;采用 LSTM模型预测知识点出现概率并以此对练习题建模.在形成学习者和练习题的表示后,通过匹配、筛选和排序生成练习题推荐列表. ...
... 冷启动是推荐系统的常见问题[85,86].推荐系统中的冷启动问题又可以分为“项目”冷启动问题和“用户”冷启动问题.在学习推荐系统中,“项目”冷启动是指系统中加入了新的学习资源,而这些学习资源之前并没有被学习者使用或评价过;“用户”冷启动是指系统中加入了新的学习者,这些学习者们在学习系统中没有学习记录,或只有很少的学习记录.这两种冷启动问题均会导致“学习者-学习资源”评分矩阵的稀疏,使协同过滤推荐算法失去精确性.基于LSTM网络的模型能够通过训练从数据中捕获长期和短期的学习行为,从而达到预测较少学习记录的学习者学习行为和效果的目的.文献[86]提出一种基于LSTM模型融合知识关系的全路径学习推荐模型,基于学习者个性特征训练LSTM网络,预测学习路径及其表现,再根据预测结果进行学习路径推荐,从而缓解学习者冷启动问题.面向个性化学习问题,文献[87]提出,在知识追踪模型[79]中引入外部信息能够对冷启动起到有效缓解作用.文献[88]采用具备一致信息传输的跨域推荐方法,通过外部数据缓解冷启动问题.文献[89]建立学习者与课程的关联规则模型,对于新的课程,基于注册信息与学习日志数据,计算新课程与学习者的关联度,并使用频繁模式增长(frequent pattern-growth,FP-growth)算法生成推荐的可视化展示.此外,在推荐方法中融入社交网络信息,也能够缓解冷启动和评分矩阵稀疏问题.文献[90]提出了一种利用社交信息增强深度学习的学习资源推荐方法,并讨论了使用社交信息缓解推荐冷启动问题的优势.文献[91]提出了一种融合社交网络信息的学习推荐方法,该方法基于学习者的社交网络信息发掘社交网络中的学习者之间所具有的潜在相似性,并对学习者聚类,再根据聚类标签进行学习资源和学习好友推荐. ...
MCRS: a course recommendation system for moocs
1
2018
... 随着在线教育和网络技术的蓬勃发展,开放式 学习拓展了学习推荐系统的应用场景[14].在开放式的学习环境下,学习者往往会登录多个在线学习平台、学习管理平台,使用各种各样的学习资源,直接或间接地与其他学习者接触.开放式学习环境网络中的某些学习资源由于来源于不同的系统,相互之间可能存在较大的特征结构差异.为了解决这一问题,文献[80]以分布式MOOC平台为基础,将多个平台各类型学习资源整合至统一平台,其学习资源推荐方法采用了基于Apriori的改进分布式关联规则挖掘算法.文献[33]提出了一种基于分布式在线学习的视频推荐模型,该模型采用去中心化服务供应商协同工作以处理学习视频的大规模上下文数据.有的研究利用了本体在知识表示形式化方面的优势,从组成学习环境网络的异构数据中发现相似学习资源.如文献[74]提出了本体匹配的概念,通过比较不同实体的本体相似性,实现学习资源在各种学习搜索引擎和学习管理系统之间共享.此外,可以将包含多模态学习资源的在线学习平台看作异质信息网络(heterogeneity information networks,HIN)[81,82,83]的一个实例,如图12所示,由学习者、学习资源、教师等实体构成.文献[84]根据网络中实体之间的关系,提取“学习者-学习资源-学习者”“学习者-教师-学习者”等元路径,提出了基于HIN的学习资源推荐方法. ...
Collaborative filtering with entity similarity regularization in heterogeneous information networks
1
2013
... 随着在线教育和网络技术的蓬勃发展,开放式 学习拓展了学习推荐系统的应用场景[14].在开放式的学习环境下,学习者往往会登录多个在线学习平台、学习管理平台,使用各种各样的学习资源,直接或间接地与其他学习者接触.开放式学习环境网络中的某些学习资源由于来源于不同的系统,相互之间可能存在较大的特征结构差异.为了解决这一问题,文献[80]以分布式MOOC平台为基础,将多个平台各类型学习资源整合至统一平台,其学习资源推荐方法采用了基于Apriori的改进分布式关联规则挖掘算法.文献[33]提出了一种基于分布式在线学习的视频推荐模型,该模型采用去中心化服务供应商协同工作以处理学习视频的大规模上下文数据.有的研究利用了本体在知识表示形式化方面的优势,从组成学习环境网络的异构数据中发现相似学习资源.如文献[74]提出了本体匹配的概念,通过比较不同实体的本体相似性,实现学习资源在各种学习搜索引擎和学习管理系统之间共享.此外,可以将包含多模态学习资源的在线学习平台看作异质信息网络(heterogeneity information networks,HIN)[81,82,83]的一个实例,如图12所示,由学习者、学习资源、教师等实体构成.文献[84]根据网络中实体之间的关系,提取“学习者-学习资源-学习者”“学习者-教师-学习者”等元路径,提出了基于HIN的学习资源推荐方法. ...
Meta-learning on heterogeneous information networks for cold-start recommendation
1
2020
... 随着在线教育和网络技术的蓬勃发展,开放式 学习拓展了学习推荐系统的应用场景[14].在开放式的学习环境下,学习者往往会登录多个在线学习平台、学习管理平台,使用各种各样的学习资源,直接或间接地与其他学习者接触.开放式学习环境网络中的某些学习资源由于来源于不同的系统,相互之间可能存在较大的特征结构差异.为了解决这一问题,文献[80]以分布式MOOC平台为基础,将多个平台各类型学习资源整合至统一平台,其学习资源推荐方法采用了基于Apriori的改进分布式关联规则挖掘算法.文献[33]提出了一种基于分布式在线学习的视频推荐模型,该模型采用去中心化服务供应商协同工作以处理学习视频的大规模上下文数据.有的研究利用了本体在知识表示形式化方面的优势,从组成学习环境网络的异构数据中发现相似学习资源.如文献[74]提出了本体匹配的概念,通过比较不同实体的本体相似性,实现学习资源在各种学习搜索引擎和学习管理系统之间共享.此外,可以将包含多模态学习资源的在线学习平台看作异质信息网络(heterogeneity information networks,HIN)[81,82,83]的一个实例,如图12所示,由学习者、学习资源、教师等实体构成.文献[84]根据网络中实体之间的关系,提取“学习者-学习资源-学习者”“学习者-教师-学习者”等元路径,提出了基于HIN的学习资源推荐方法. ...
Recommendation generation using personalized weight of meta-paths in heterogeneous information networks
1
2020
... 随着在线教育和网络技术的蓬勃发展,开放式 学习拓展了学习推荐系统的应用场景[14].在开放式的学习环境下,学习者往往会登录多个在线学习平台、学习管理平台,使用各种各样的学习资源,直接或间接地与其他学习者接触.开放式学习环境网络中的某些学习资源由于来源于不同的系统,相互之间可能存在较大的特征结构差异.为了解决这一问题,文献[80]以分布式MOOC平台为基础,将多个平台各类型学习资源整合至统一平台,其学习资源推荐方法采用了基于Apriori的改进分布式关联规则挖掘算法.文献[33]提出了一种基于分布式在线学习的视频推荐模型,该模型采用去中心化服务供应商协同工作以处理学习视频的大规模上下文数据.有的研究利用了本体在知识表示形式化方面的优势,从组成学习环境网络的异构数据中发现相似学习资源.如文献[74]提出了本体匹配的概念,通过比较不同实体的本体相似性,实现学习资源在各种学习搜索引擎和学习管理系统之间共享.此外,可以将包含多模态学习资源的在线学习平台看作异质信息网络(heterogeneity information networks,HIN)[81,82,83]的一个实例,如图12所示,由学习者、学习资源、教师等实体构成.文献[84]根据网络中实体之间的关系,提取“学习者-学习资源-学习者”“学习者-教师-学习者”等元路径,提出了基于HIN的学习资源推荐方法. ...
一种基于HIN 的学习资源推荐算法研究
1
2019
... 随着在线教育和网络技术的蓬勃发展,开放式 学习拓展了学习推荐系统的应用场景[14].在开放式的学习环境下,学习者往往会登录多个在线学习平台、学习管理平台,使用各种各样的学习资源,直接或间接地与其他学习者接触.开放式学习环境网络中的某些学习资源由于来源于不同的系统,相互之间可能存在较大的特征结构差异.为了解决这一问题,文献[80]以分布式MOOC平台为基础,将多个平台各类型学习资源整合至统一平台,其学习资源推荐方法采用了基于Apriori的改进分布式关联规则挖掘算法.文献[33]提出了一种基于分布式在线学习的视频推荐模型,该模型采用去中心化服务供应商协同工作以处理学习视频的大规模上下文数据.有的研究利用了本体在知识表示形式化方面的优势,从组成学习环境网络的异构数据中发现相似学习资源.如文献[74]提出了本体匹配的概念,通过比较不同实体的本体相似性,实现学习资源在各种学习搜索引擎和学习管理系统之间共享.此外,可以将包含多模态学习资源的在线学习平台看作异质信息网络(heterogeneity information networks,HIN)[81,82,83]的一个实例,如图12所示,由学习者、学习资源、教师等实体构成.文献[84]根据网络中实体之间的关系,提取“学习者-学习资源-学习者”“学习者-教师-学习者”等元路径,提出了基于HIN的学习资源推荐方法. ...
Study on the recommendation algorithm of learning resources based on HIN
1
2019
... 随着在线教育和网络技术的蓬勃发展,开放式 学习拓展了学习推荐系统的应用场景[14].在开放式的学习环境下,学习者往往会登录多个在线学习平台、学习管理平台,使用各种各样的学习资源,直接或间接地与其他学习者接触.开放式学习环境网络中的某些学习资源由于来源于不同的系统,相互之间可能存在较大的特征结构差异.为了解决这一问题,文献[80]以分布式MOOC平台为基础,将多个平台各类型学习资源整合至统一平台,其学习资源推荐方法采用了基于Apriori的改进分布式关联规则挖掘算法.文献[33]提出了一种基于分布式在线学习的视频推荐模型,该模型采用去中心化服务供应商协同工作以处理学习视频的大规模上下文数据.有的研究利用了本体在知识表示形式化方面的优势,从组成学习环境网络的异构数据中发现相似学习资源.如文献[74]提出了本体匹配的概念,通过比较不同实体的本体相似性,实现学习资源在各种学习搜索引擎和学习管理系统之间共享.此外,可以将包含多模态学习资源的在线学习平台看作异质信息网络(heterogeneity information networks,HIN)[81,82,83]的一个实例,如图12所示,由学习者、学习资源、教师等实体构成.文献[84]根据网络中实体之间的关系,提取“学习者-学习资源-学习者”“学习者-教师-学习者”等元路径,提出了基于HIN的学习资源推荐方法. ...
Addressing cold start challenges in recommender systems: towards a new hybrid approach
1
2019
... 冷启动是推荐系统的常见问题[85,86].推荐系统中的冷启动问题又可以分为“项目”冷启动问题和“用户”冷启动问题.在学习推荐系统中,“项目”冷启动是指系统中加入了新的学习资源,而这些学习资源之前并没有被学习者使用或评价过;“用户”冷启动是指系统中加入了新的学习者,这些学习者们在学习系统中没有学习记录,或只有很少的学习记录.这两种冷启动问题均会导致“学习者-学习资源”评分矩阵的稀疏,使协同过滤推荐算法失去精确性.基于LSTM网络的模型能够通过训练从数据中捕获长期和短期的学习行为,从而达到预测较少学习记录的学习者学习行为和效果的目的.文献[86]提出一种基于LSTM模型融合知识关系的全路径学习推荐模型,基于学习者个性特征训练LSTM网络,预测学习路径及其表现,再根据预测结果进行学习路径推荐,从而缓解学习者冷启动问题.面向个性化学习问题,文献[87]提出,在知识追踪模型[79]中引入外部信息能够对冷启动起到有效缓解作用.文献[88]采用具备一致信息传输的跨域推荐方法,通过外部数据缓解冷启动问题.文献[89]建立学习者与课程的关联规则模型,对于新的课程,基于注册信息与学习日志数据,计算新课程与学习者的关联度,并使用频繁模式增长(frequent pattern-growth,FP-growth)算法生成推荐的可视化展示.此外,在推荐方法中融入社交网络信息,也能够缓解冷启动和评分矩阵稀疏问题.文献[90]提出了一种利用社交信息增强深度学习的学习资源推荐方法,并讨论了使用社交信息缓解推荐冷启动问题的优势.文献[91]提出了一种融合社交网络信息的学习推荐方法,该方法基于学习者的社交网络信息发掘社交网络中的学习者之间所具有的潜在相似性,并对学习者聚类,再根据聚类标签进行学习资源和学习好友推荐. ...
Deep learning to address candidate generation and cold start challenges in recommender systems: a research survey
2
... 冷启动是推荐系统的常见问题[85,86].推荐系统中的冷启动问题又可以分为“项目”冷启动问题和“用户”冷启动问题.在学习推荐系统中,“项目”冷启动是指系统中加入了新的学习资源,而这些学习资源之前并没有被学习者使用或评价过;“用户”冷启动是指系统中加入了新的学习者,这些学习者们在学习系统中没有学习记录,或只有很少的学习记录.这两种冷启动问题均会导致“学习者-学习资源”评分矩阵的稀疏,使协同过滤推荐算法失去精确性.基于LSTM网络的模型能够通过训练从数据中捕获长期和短期的学习行为,从而达到预测较少学习记录的学习者学习行为和效果的目的.文献[86]提出一种基于LSTM模型融合知识关系的全路径学习推荐模型,基于学习者个性特征训练LSTM网络,预测学习路径及其表现,再根据预测结果进行学习路径推荐,从而缓解学习者冷启动问题.面向个性化学习问题,文献[87]提出,在知识追踪模型[79]中引入外部信息能够对冷启动起到有效缓解作用.文献[88]采用具备一致信息传输的跨域推荐方法,通过外部数据缓解冷启动问题.文献[89]建立学习者与课程的关联规则模型,对于新的课程,基于注册信息与学习日志数据,计算新课程与学习者的关联度,并使用频繁模式增长(frequent pattern-growth,FP-growth)算法生成推荐的可视化展示.此外,在推荐方法中融入社交网络信息,也能够缓解冷启动和评分矩阵稀疏问题.文献[90]提出了一种利用社交信息增强深度学习的学习资源推荐方法,并讨论了使用社交信息缓解推荐冷启动问题的优势.文献[91]提出了一种融合社交网络信息的学习推荐方法,该方法基于学习者的社交网络信息发掘社交网络中的学习者之间所具有的潜在相似性,并对学习者聚类,再根据聚类标签进行学习资源和学习好友推荐. ...
... .推荐系统中的冷启动问题又可以分为“项目”冷启动问题和“用户”冷启动问题.在学习推荐系统中,“项目”冷启动是指系统中加入了新的学习资源,而这些学习资源之前并没有被学习者使用或评价过;“用户”冷启动是指系统中加入了新的学习者,这些学习者们在学习系统中没有学习记录,或只有很少的学习记录.这两种冷启动问题均会导致“学习者-学习资源”评分矩阵的稀疏,使协同过滤推荐算法失去精确性.基于LSTM网络的模型能够通过训练从数据中捕获长期和短期的学习行为,从而达到预测较少学习记录的学习者学习行为和效果的目的.文献[86]提出一种基于LSTM模型融合知识关系的全路径学习推荐模型,基于学习者个性特征训练LSTM网络,预测学习路径及其表现,再根据预测结果进行学习路径推荐,从而缓解学习者冷启动问题.面向个性化学习问题,文献[87]提出,在知识追踪模型[79]中引入外部信息能够对冷启动起到有效缓解作用.文献[88]采用具备一致信息传输的跨域推荐方法,通过外部数据缓解冷启动问题.文献[89]建立学习者与课程的关联规则模型,对于新的课程,基于注册信息与学习日志数据,计算新课程与学习者的关联度,并使用频繁模式增长(frequent pattern-growth,FP-growth)算法生成推荐的可视化展示.此外,在推荐方法中融入社交网络信息,也能够缓解冷启动和评分矩阵稀疏问题.文献[90]提出了一种利用社交信息增强深度学习的学习资源推荐方法,并讨论了使用社交信息缓解推荐冷启动问题的优势.文献[91]提出了一种融合社交网络信息的学习推荐方法,该方法基于学习者的社交网络信息发掘社交网络中的学习者之间所具有的潜在相似性,并对学习者聚类,再根据聚类标签进行学习资源和学习好友推荐. ...
Cold start know-ledge tracing with attentive neural turing machine
1
2020
... 冷启动是推荐系统的常见问题[85,86].推荐系统中的冷启动问题又可以分为“项目”冷启动问题和“用户”冷启动问题.在学习推荐系统中,“项目”冷启动是指系统中加入了新的学习资源,而这些学习资源之前并没有被学习者使用或评价过;“用户”冷启动是指系统中加入了新的学习者,这些学习者们在学习系统中没有学习记录,或只有很少的学习记录.这两种冷启动问题均会导致“学习者-学习资源”评分矩阵的稀疏,使协同过滤推荐算法失去精确性.基于LSTM网络的模型能够通过训练从数据中捕获长期和短期的学习行为,从而达到预测较少学习记录的学习者学习行为和效果的目的.文献[86]提出一种基于LSTM模型融合知识关系的全路径学习推荐模型,基于学习者个性特征训练LSTM网络,预测学习路径及其表现,再根据预测结果进行学习路径推荐,从而缓解学习者冷启动问题.面向个性化学习问题,文献[87]提出,在知识追踪模型[79]中引入外部信息能够对冷启动起到有效缓解作用.文献[88]采用具备一致信息传输的跨域推荐方法,通过外部数据缓解冷启动问题.文献[89]建立学习者与课程的关联规则模型,对于新的课程,基于注册信息与学习日志数据,计算新课程与学习者的关联度,并使用频繁模式增长(frequent pattern-growth,FP-growth)算法生成推荐的可视化展示.此外,在推荐方法中融入社交网络信息,也能够缓解冷启动和评分矩阵稀疏问题.文献[90]提出了一种利用社交信息增强深度学习的学习资源推荐方法,并讨论了使用社交信息缓解推荐冷启动问题的优势.文献[91]提出了一种融合社交网络信息的学习推荐方法,该方法基于学习者的社交网络信息发掘社交网络中的学习者之间所具有的潜在相似性,并对学习者聚类,再根据聚类标签进行学习资源和学习好友推荐. ...
A cross-domain recommender system with consistent information transfer
1
2017
... 冷启动是推荐系统的常见问题[85,86].推荐系统中的冷启动问题又可以分为“项目”冷启动问题和“用户”冷启动问题.在学习推荐系统中,“项目”冷启动是指系统中加入了新的学习资源,而这些学习资源之前并没有被学习者使用或评价过;“用户”冷启动是指系统中加入了新的学习者,这些学习者们在学习系统中没有学习记录,或只有很少的学习记录.这两种冷启动问题均会导致“学习者-学习资源”评分矩阵的稀疏,使协同过滤推荐算法失去精确性.基于LSTM网络的模型能够通过训练从数据中捕获长期和短期的学习行为,从而达到预测较少学习记录的学习者学习行为和效果的目的.文献[86]提出一种基于LSTM模型融合知识关系的全路径学习推荐模型,基于学习者个性特征训练LSTM网络,预测学习路径及其表现,再根据预测结果进行学习路径推荐,从而缓解学习者冷启动问题.面向个性化学习问题,文献[87]提出,在知识追踪模型[79]中引入外部信息能够对冷启动起到有效缓解作用.文献[88]采用具备一致信息传输的跨域推荐方法,通过外部数据缓解冷启动问题.文献[89]建立学习者与课程的关联规则模型,对于新的课程,基于注册信息与学习日志数据,计算新课程与学习者的关联度,并使用频繁模式增长(frequent pattern-growth,FP-growth)算法生成推荐的可视化展示.此外,在推荐方法中融入社交网络信息,也能够缓解冷启动和评分矩阵稀疏问题.文献[90]提出了一种利用社交信息增强深度学习的学习资源推荐方法,并讨论了使用社交信息缓解推荐冷启动问题的优势.文献[91]提出了一种融合社交网络信息的学习推荐方法,该方法基于学习者的社交网络信息发掘社交网络中的学习者之间所具有的潜在相似性,并对学习者聚类,再根据聚类标签进行学习资源和学习好友推荐. ...
Smart courses recommender system for online learning platform
1
2018
... 冷启动是推荐系统的常见问题[85,86].推荐系统中的冷启动问题又可以分为“项目”冷启动问题和“用户”冷启动问题.在学习推荐系统中,“项目”冷启动是指系统中加入了新的学习资源,而这些学习资源之前并没有被学习者使用或评价过;“用户”冷启动是指系统中加入了新的学习者,这些学习者们在学习系统中没有学习记录,或只有很少的学习记录.这两种冷启动问题均会导致“学习者-学习资源”评分矩阵的稀疏,使协同过滤推荐算法失去精确性.基于LSTM网络的模型能够通过训练从数据中捕获长期和短期的学习行为,从而达到预测较少学习记录的学习者学习行为和效果的目的.文献[86]提出一种基于LSTM模型融合知识关系的全路径学习推荐模型,基于学习者个性特征训练LSTM网络,预测学习路径及其表现,再根据预测结果进行学习路径推荐,从而缓解学习者冷启动问题.面向个性化学习问题,文献[87]提出,在知识追踪模型[79]中引入外部信息能够对冷启动起到有效缓解作用.文献[88]采用具备一致信息传输的跨域推荐方法,通过外部数据缓解冷启动问题.文献[89]建立学习者与课程的关联规则模型,对于新的课程,基于注册信息与学习日志数据,计算新课程与学习者的关联度,并使用频繁模式增长(frequent pattern-growth,FP-growth)算法生成推荐的可视化展示.此外,在推荐方法中融入社交网络信息,也能够缓解冷启动和评分矩阵稀疏问题.文献[90]提出了一种利用社交信息增强深度学习的学习资源推荐方法,并讨论了使用社交信息缓解推荐冷启动问题的优势.文献[91]提出了一种融合社交网络信息的学习推荐方法,该方法基于学习者的社交网络信息发掘社交网络中的学习者之间所具有的潜在相似性,并对学习者聚类,再根据聚类标签进行学习资源和学习好友推荐. ...
Using social networks to enhance a deep learning approach to solve the cold-start problem in recommender systems
1
2020
... 冷启动是推荐系统的常见问题[85,86].推荐系统中的冷启动问题又可以分为“项目”冷启动问题和“用户”冷启动问题.在学习推荐系统中,“项目”冷启动是指系统中加入了新的学习资源,而这些学习资源之前并没有被学习者使用或评价过;“用户”冷启动是指系统中加入了新的学习者,这些学习者们在学习系统中没有学习记录,或只有很少的学习记录.这两种冷启动问题均会导致“学习者-学习资源”评分矩阵的稀疏,使协同过滤推荐算法失去精确性.基于LSTM网络的模型能够通过训练从数据中捕获长期和短期的学习行为,从而达到预测较少学习记录的学习者学习行为和效果的目的.文献[86]提出一种基于LSTM模型融合知识关系的全路径学习推荐模型,基于学习者个性特征训练LSTM网络,预测学习路径及其表现,再根据预测结果进行学习路径推荐,从而缓解学习者冷启动问题.面向个性化学习问题,文献[87]提出,在知识追踪模型[79]中引入外部信息能够对冷启动起到有效缓解作用.文献[88]采用具备一致信息传输的跨域推荐方法,通过外部数据缓解冷启动问题.文献[89]建立学习者与课程的关联规则模型,对于新的课程,基于注册信息与学习日志数据,计算新课程与学习者的关联度,并使用频繁模式增长(frequent pattern-growth,FP-growth)算法生成推荐的可视化展示.此外,在推荐方法中融入社交网络信息,也能够缓解冷启动和评分矩阵稀疏问题.文献[90]提出了一种利用社交信息增强深度学习的学习资源推荐方法,并讨论了使用社交信息缓解推荐冷启动问题的优势.文献[91]提出了一种融合社交网络信息的学习推荐方法,该方法基于学习者的社交网络信息发掘社交网络中的学习者之间所具有的潜在相似性,并对学习者聚类,再根据聚类标签进行学习资源和学习好友推荐. ...
Recommendation in e-learning social networks
1
2011
... 冷启动是推荐系统的常见问题[85,86].推荐系统中的冷启动问题又可以分为“项目”冷启动问题和“用户”冷启动问题.在学习推荐系统中,“项目”冷启动是指系统中加入了新的学习资源,而这些学习资源之前并没有被学习者使用或评价过;“用户”冷启动是指系统中加入了新的学习者,这些学习者们在学习系统中没有学习记录,或只有很少的学习记录.这两种冷启动问题均会导致“学习者-学习资源”评分矩阵的稀疏,使协同过滤推荐算法失去精确性.基于LSTM网络的模型能够通过训练从数据中捕获长期和短期的学习行为,从而达到预测较少学习记录的学习者学习行为和效果的目的.文献[86]提出一种基于LSTM模型融合知识关系的全路径学习推荐模型,基于学习者个性特征训练LSTM网络,预测学习路径及其表现,再根据预测结果进行学习路径推荐,从而缓解学习者冷启动问题.面向个性化学习问题,文献[87]提出,在知识追踪模型[79]中引入外部信息能够对冷启动起到有效缓解作用.文献[88]采用具备一致信息传输的跨域推荐方法,通过外部数据缓解冷启动问题.文献[89]建立学习者与课程的关联规则模型,对于新的课程,基于注册信息与学习日志数据,计算新课程与学习者的关联度,并使用频繁模式增长(frequent pattern-growth,FP-growth)算法生成推荐的可视化展示.此外,在推荐方法中融入社交网络信息,也能够缓解冷启动和评分矩阵稀疏问题.文献[90]提出了一种利用社交信息增强深度学习的学习资源推荐方法,并讨论了使用社交信息缓解推荐冷启动问题的优势.文献[91]提出了一种融合社交网络信息的学习推荐方法,该方法基于学习者的社交网络信息发掘社交网络中的学习者之间所具有的潜在相似性,并对学习者聚类,再根据聚类标签进行学习资源和学习好友推荐. ...
Evaluating recommender systems for technology enhanced learning: a quantitative survey
2
2015
... 学习推荐系统的评估通常围绕系统性能、用户体验和学习适用性三方面进行[92],本章将从这三方面对学习推荐系统的评估方法进行介绍. ...
... 不同方法的评估角度和目的不相同,系统性能评估通常根据推荐系统在测试数据集上的表现来实现,本质上评估的是推荐系统对训练数据的学习能力表现,常使用精度、误差等指标来衡量;用户体验评估在于测量学习者对所推荐学习资源的感受,常通过对新颖度、多样性等指标的测量来评估是否出现推荐的过度专业化,从而弥补单纯准确性评估的不足;学习适用性则注重于所推荐的学习资源是否有利于学习效果和学习质量的提升,常通过学生成绩、学习时长等衡量.性能评估任务能够使用离线数据集完成,用户体验和学习适用性则可能需要加入真实教学场景中的实验.从现有的研究可以看出,对学习推荐系统的评估逐渐倾向于采用多种方法组合互为补充的方式,通过评估方法测量到学习推荐系统的不同效应也越来越丰富和多样化[92],尤其是对用户体验和学习适用性的评估,以及评估中所涉及到的数据隐私问题近年来也越来越受到研究人员的关注. ...
An effective recommendation framework for personal learning environments using a learner preference tree and a GA
2
2013
... 推荐系统的核心性能是推荐的准确性,即推荐预测值与真值的接近或误差程度.主要包括推荐预测的精度(accuracy)、召回率(recall)、F1分数、平均绝对误差(mean absolute error,MAE)、均方根误差(root mean square error,RMSE)等.有的研究同时采用多个指标的组合方式,以达到多角度评估的目的.比如文献[60]和文献[93]对所提出的推荐算法分别进行了精度、召回率和F1分数的评估.文献[38]使用了召回率和排序质量的指标(normalized discounted cumulative gain,NDCG),因为NDCG是一个有位置感知的度量标准,它能为推荐项目的排名列表更高位置的项目分配更高的分值,从而测量推荐列表的质量.在实际应用中,也可以对系统的性能进行单个指标上的评估,如文献[94]只采用了F1分数,因为F1分数可以看作精度和召回率的一种调和平均,被认为能够同时兼顾精度和召回率.也有的研究从误差的角度来评估推荐系统性能,比如文献[93]和文献[95]采用了平均误差(MAE),文献[96]和文献[97]则使用均方根误差(RMSE).虽然大部分推荐系统性能评估的指标可以用于学习推荐系统的性能评估,但是对于性能的评估只是学习推荐系统评估的角度之一. ...
... 1分数可以看作精度和召回率的一种调和平均,被认为能够同时兼顾精度和召回率.也有的研究从误差的角度来评估推荐系统性能,比如文献[93]和文献[95]采用了平均误差(MAE),文献[96]和文献[97]则使用均方根误差(RMSE).虽然大部分推荐系统性能评估的指标可以用于学习推荐系统的性能评估,但是对于性能的评估只是学习推荐系统评估的角度之一. ...
Truelearn: a family of Bayesian algorithms to match lifelong learners to open educational resources
2
2020
... 推荐系统的核心性能是推荐的准确性,即推荐预测值与真值的接近或误差程度.主要包括推荐预测的精度(accuracy)、召回率(recall)、F1分数、平均绝对误差(mean absolute error,MAE)、均方根误差(root mean square error,RMSE)等.有的研究同时采用多个指标的组合方式,以达到多角度评估的目的.比如文献[60]和文献[93]对所提出的推荐算法分别进行了精度、召回率和F1分数的评估.文献[38]使用了召回率和排序质量的指标(normalized discounted cumulative gain,NDCG),因为NDCG是一个有位置感知的度量标准,它能为推荐项目的排名列表更高位置的项目分配更高的分值,从而测量推荐列表的质量.在实际应用中,也可以对系统的性能进行单个指标上的评估,如文献[94]只采用了F1分数,因为F1分数可以看作精度和召回率的一种调和平均,被认为能够同时兼顾精度和召回率.也有的研究从误差的角度来评估推荐系统性能,比如文献[93]和文献[95]采用了平均误差(MAE),文献[96]和文献[97]则使用均方根误差(RMSE).虽然大部分推荐系统性能评估的指标可以用于学习推荐系统的性能评估,但是对于性能的评估只是学习推荐系统评估的角度之一. ...
... 学习推荐是人工智能教育的核心研究内容,其 目标是为学习者匹配到最适合的学习资源或路径,这种匹配并非仅仅迎合学习者的兴趣[94],而应该以激发和培养学习动机,提高学习者的学习积极性和持久性,达到提升学习效率为目标.鉴于此,本文从学习推荐系统的通用框架结构出发,将其分解为三个核心问题,即:学习者建模、学习推荐对象建模以及学习推荐方法.具体而言,在学习者建模方面,应根据需求组合多种学习者个性化参数构建学习者模型,并采用能够充分保留学习者特征语义的建模方法.在学习推荐对象建模方面,所提取的特征应与学习者的个性化参数相匹配,不同类型对象的特征表示应该统一,且符合算法模型的输入要求.在学习推荐方法方面,应以学习活动的开展为背景,并围绕学习者与学习资源的交互行为进行设计.学习推荐系统的总体设计思路,不能脱离学习活动的规律,且有必要适时结合人工评估,或真实教学场景下的实验开展用户体验和学习适用性的评价.在未来的研究中,学习推荐系统可能在学习者状态获取和表征,以及学习场景建模等方面产生新的发展. ...
Collaborative recommendation of e-learning resources: an experimental investigation
1
2010
... 推荐系统的核心性能是推荐的准确性,即推荐预测值与真值的接近或误差程度.主要包括推荐预测的精度(accuracy)、召回率(recall)、F1分数、平均绝对误差(mean absolute error,MAE)、均方根误差(root mean square error,RMSE)等.有的研究同时采用多个指标的组合方式,以达到多角度评估的目的.比如文献[60]和文献[93]对所提出的推荐算法分别进行了精度、召回率和F1分数的评估.文献[38]使用了召回率和排序质量的指标(normalized discounted cumulative gain,NDCG),因为NDCG是一个有位置感知的度量标准,它能为推荐项目的排名列表更高位置的项目分配更高的分值,从而测量推荐列表的质量.在实际应用中,也可以对系统的性能进行单个指标上的评估,如文献[94]只采用了F1分数,因为F1分数可以看作精度和召回率的一种调和平均,被认为能够同时兼顾精度和召回率.也有的研究从误差的角度来评估推荐系统性能,比如文献[93]和文献[95]采用了平均误差(MAE),文献[96]和文献[97]则使用均方根误差(RMSE).虽然大部分推荐系统性能评估的指标可以用于学习推荐系统的性能评估,但是对于性能的评估只是学习推荐系统评估的角度之一. ...
Novel and classic metaheuristics for tunning a recommender system for predicting student performance in online campus
1
2018
... 推荐系统的核心性能是推荐的准确性,即推荐预测值与真值的接近或误差程度.主要包括推荐预测的精度(accuracy)、召回率(recall)、F1分数、平均绝对误差(mean absolute error,MAE)、均方根误差(root mean square error,RMSE)等.有的研究同时采用多个指标的组合方式,以达到多角度评估的目的.比如文献[60]和文献[93]对所提出的推荐算法分别进行了精度、召回率和F1分数的评估.文献[38]使用了召回率和排序质量的指标(normalized discounted cumulative gain,NDCG),因为NDCG是一个有位置感知的度量标准,它能为推荐项目的排名列表更高位置的项目分配更高的分值,从而测量推荐列表的质量.在实际应用中,也可以对系统的性能进行单个指标上的评估,如文献[94]只采用了F1分数,因为F1分数可以看作精度和召回率的一种调和平均,被认为能够同时兼顾精度和召回率.也有的研究从误差的角度来评估推荐系统性能,比如文献[93]和文献[95]采用了平均误差(MAE),文献[96]和文献[97]则使用均方根误差(RMSE).虽然大部分推荐系统性能评估的指标可以用于学习推荐系统的性能评估,但是对于性能的评估只是学习推荐系统评估的角度之一. ...
Knowledge modeling via contextualized representations for LSTM-based personalized exercise recommendation
1
2020
... 推荐系统的核心性能是推荐的准确性,即推荐预测值与真值的接近或误差程度.主要包括推荐预测的精度(accuracy)、召回率(recall)、F1分数、平均绝对误差(mean absolute error,MAE)、均方根误差(root mean square error,RMSE)等.有的研究同时采用多个指标的组合方式,以达到多角度评估的目的.比如文献[60]和文献[93]对所提出的推荐算法分别进行了精度、召回率和F1分数的评估.文献[38]使用了召回率和排序质量的指标(normalized discounted cumulative gain,NDCG),因为NDCG是一个有位置感知的度量标准,它能为推荐项目的排名列表更高位置的项目分配更高的分值,从而测量推荐列表的质量.在实际应用中,也可以对系统的性能进行单个指标上的评估,如文献[94]只采用了F1分数,因为F1分数可以看作精度和召回率的一种调和平均,被认为能够同时兼顾精度和召回率.也有的研究从误差的角度来评估推荐系统性能,比如文献[93]和文献[95]采用了平均误差(MAE),文献[96]和文献[97]则使用均方根误差(RMSE).虽然大部分推荐系统性能评估的指标可以用于学习推荐系统的性能评估,但是对于性能的评估只是学习推荐系统评估的角度之一. ...
A survey of serendipity in recommender systems
2
2016
... 文献[60]对七种推荐的结果进行人工评估,结果表明用户体验的质量与推荐的高精度并不相关.一般而言,用户体验好的推荐内容,除了符合自己偏好外,还要尽量做到不与刚刚看过的内容完全相同或者非常相似,但是一味追求推荐的高精度往往会忽视这一问题.为了解决这一问题,近年来研究人员对推荐的“偶然性”[98,99]开展研究.文献[100]指出,现有大多数的推荐算法基于准确性评估,但难以保障推荐内容能够满足用户需求、偏好的变化,因为单纯准确性可能会导致所推荐内容没有新意.为了获得高的精度评估值,用户可能仅收到那些与他们初始评分高的项目类似的推荐项目(过度专业化).这必然会降低用户体验的满意度[101].因此,用户体验评估的核心指标是推荐的“偶然性”,该指标通常采用新颖度(novelty)和多样性(diversity)等二级指标来衡量.新颖度是指所推荐的项目在用户过往的交互记录中出现得越少越好[102];多样性是指推荐列表中出现的项目越不相似越好,因为用户可能对包含彼此非常相似项目的推荐列表感到不满意[98].新颖而多样的学习资源会在一定程度上激发学习者的学习兴趣,即提高学习资源推荐的新颖度和多样性会对学习者的学习热情产生积极影响[42,53].文献[42]结合练习题的题型、难度、涵盖的知识点等特征,在对练习题推荐精度的基础上,还对推荐的新颖度和多样性进行了评估.对用户体验的评估也常采用人工方法.如文献[103]和文献[104]中,设计了用户体验量表,采用人工打分的方式进行评估,来衡量推荐的感知相关性,此外文献[103]还采用人工打分方式评估了推荐的可用性. ...
... [98].新颖而多样的学习资源会在一定程度上激发学习者的学习兴趣,即提高学习资源推荐的新颖度和多样性会对学习者的学习热情产生积极影响[42,53].文献[42]结合练习题的题型、难度、涵盖的知识点等特征,在对练习题推荐精度的基础上,还对推荐的新颖度和多样性进行了评估.对用户体验的评估也常采用人工方法.如文献[103]和文献[104]中,设计了用户体验量表,采用人工打分的方式进行评估,来衡量推荐的感知相关性,此外文献[103]还采用人工打分方式评估了推荐的可用性. ...
Facilitating research through serendipity of recommendations
1
2020
... 文献[60]对七种推荐的结果进行人工评估,结果表明用户体验的质量与推荐的高精度并不相关.一般而言,用户体验好的推荐内容,除了符合自己偏好外,还要尽量做到不与刚刚看过的内容完全相同或者非常相似,但是一味追求推荐的高精度往往会忽视这一问题.为了解决这一问题,近年来研究人员对推荐的“偶然性”[98,99]开展研究.文献[100]指出,现有大多数的推荐算法基于准确性评估,但难以保障推荐内容能够满足用户需求、偏好的变化,因为单纯准确性可能会导致所推荐内容没有新意.为了获得高的精度评估值,用户可能仅收到那些与他们初始评分高的项目类似的推荐项目(过度专业化).这必然会降低用户体验的满意度[101].因此,用户体验评估的核心指标是推荐的“偶然性”,该指标通常采用新颖度(novelty)和多样性(diversity)等二级指标来衡量.新颖度是指所推荐的项目在用户过往的交互记录中出现得越少越好[102];多样性是指推荐列表中出现的项目越不相似越好,因为用户可能对包含彼此非常相似项目的推荐列表感到不满意[98].新颖而多样的学习资源会在一定程度上激发学习者的学习兴趣,即提高学习资源推荐的新颖度和多样性会对学习者的学习热情产生积极影响[42,53].文献[42]结合练习题的题型、难度、涵盖的知识点等特征,在对练习题推荐精度的基础上,还对推荐的新颖度和多样性进行了评估.对用户体验的评估也常采用人工方法.如文献[103]和文献[104]中,设计了用户体验量表,采用人工打分的方式进行评估,来衡量推荐的感知相关性,此外文献[103]还采用人工打分方式评估了推荐的可用性. ...
Challenges of serendipity in recommender systems
1
2016
... 文献[60]对七种推荐的结果进行人工评估,结果表明用户体验的质量与推荐的高精度并不相关.一般而言,用户体验好的推荐内容,除了符合自己偏好外,还要尽量做到不与刚刚看过的内容完全相同或者非常相似,但是一味追求推荐的高精度往往会忽视这一问题.为了解决这一问题,近年来研究人员对推荐的“偶然性”[98,99]开展研究.文献[100]指出,现有大多数的推荐算法基于准确性评估,但难以保障推荐内容能够满足用户需求、偏好的变化,因为单纯准确性可能会导致所推荐内容没有新意.为了获得高的精度评估值,用户可能仅收到那些与他们初始评分高的项目类似的推荐项目(过度专业化).这必然会降低用户体验的满意度[101].因此,用户体验评估的核心指标是推荐的“偶然性”,该指标通常采用新颖度(novelty)和多样性(diversity)等二级指标来衡量.新颖度是指所推荐的项目在用户过往的交互记录中出现得越少越好[102];多样性是指推荐列表中出现的项目越不相似越好,因为用户可能对包含彼此非常相似项目的推荐列表感到不满意[98].新颖而多样的学习资源会在一定程度上激发学习者的学习兴趣,即提高学习资源推荐的新颖度和多样性会对学习者的学习热情产生积极影响[42,53].文献[42]结合练习题的题型、难度、涵盖的知识点等特征,在对练习题推荐精度的基础上,还对推荐的新颖度和多样性进行了评估.对用户体验的评估也常采用人工方法.如文献[103]和文献[104]中,设计了用户体验量表,采用人工打分的方式进行评估,来衡量推荐的感知相关性,此外文献[103]还采用人工打分方式评估了推荐的可用性. ...
Investigating serendipity in recommender systems based on real user feedback
1
2018
... 文献[60]对七种推荐的结果进行人工评估,结果表明用户体验的质量与推荐的高精度并不相关.一般而言,用户体验好的推荐内容,除了符合自己偏好外,还要尽量做到不与刚刚看过的内容完全相同或者非常相似,但是一味追求推荐的高精度往往会忽视这一问题.为了解决这一问题,近年来研究人员对推荐的“偶然性”[98,99]开展研究.文献[100]指出,现有大多数的推荐算法基于准确性评估,但难以保障推荐内容能够满足用户需求、偏好的变化,因为单纯准确性可能会导致所推荐内容没有新意.为了获得高的精度评估值,用户可能仅收到那些与他们初始评分高的项目类似的推荐项目(过度专业化).这必然会降低用户体验的满意度[101].因此,用户体验评估的核心指标是推荐的“偶然性”,该指标通常采用新颖度(novelty)和多样性(diversity)等二级指标来衡量.新颖度是指所推荐的项目在用户过往的交互记录中出现得越少越好[102];多样性是指推荐列表中出现的项目越不相似越好,因为用户可能对包含彼此非常相似项目的推荐列表感到不满意[98].新颖而多样的学习资源会在一定程度上激发学习者的学习兴趣,即提高学习资源推荐的新颖度和多样性会对学习者的学习热情产生积极影响[42,53].文献[42]结合练习题的题型、难度、涵盖的知识点等特征,在对练习题推荐精度的基础上,还对推荐的新颖度和多样性进行了评估.对用户体验的评估也常采用人工方法.如文献[103]和文献[104]中,设计了用户体验量表,采用人工打分的方式进行评估,来衡量推荐的感知相关性,此外文献[103]还采用人工打分方式评估了推荐的可用性. ...
“I like to explore sometimes”: adapting to dynamic user novelty preferences
1
2015
... 文献[60]对七种推荐的结果进行人工评估,结果表明用户体验的质量与推荐的高精度并不相关.一般而言,用户体验好的推荐内容,除了符合自己偏好外,还要尽量做到不与刚刚看过的内容完全相同或者非常相似,但是一味追求推荐的高精度往往会忽视这一问题.为了解决这一问题,近年来研究人员对推荐的“偶然性”[98,99]开展研究.文献[100]指出,现有大多数的推荐算法基于准确性评估,但难以保障推荐内容能够满足用户需求、偏好的变化,因为单纯准确性可能会导致所推荐内容没有新意.为了获得高的精度评估值,用户可能仅收到那些与他们初始评分高的项目类似的推荐项目(过度专业化).这必然会降低用户体验的满意度[101].因此,用户体验评估的核心指标是推荐的“偶然性”,该指标通常采用新颖度(novelty)和多样性(diversity)等二级指标来衡量.新颖度是指所推荐的项目在用户过往的交互记录中出现得越少越好[102];多样性是指推荐列表中出现的项目越不相似越好,因为用户可能对包含彼此非常相似项目的推荐列表感到不满意[98].新颖而多样的学习资源会在一定程度上激发学习者的学习兴趣,即提高学习资源推荐的新颖度和多样性会对学习者的学习热情产生积极影响[42,53].文献[42]结合练习题的题型、难度、涵盖的知识点等特征,在对练习题推荐精度的基础上,还对推荐的新颖度和多样性进行了评估.对用户体验的评估也常采用人工方法.如文献[103]和文献[104]中,设计了用户体验量表,采用人工打分的方式进行评估,来衡量推荐的感知相关性,此外文献[103]还采用人工打分方式评估了推荐的可用性. ...
COCOON CORE: co-author recommendations based on betweenness centrality and interest similarity
2
2014
... 文献[60]对七种推荐的结果进行人工评估,结果表明用户体验的质量与推荐的高精度并不相关.一般而言,用户体验好的推荐内容,除了符合自己偏好外,还要尽量做到不与刚刚看过的内容完全相同或者非常相似,但是一味追求推荐的高精度往往会忽视这一问题.为了解决这一问题,近年来研究人员对推荐的“偶然性”[98,99]开展研究.文献[100]指出,现有大多数的推荐算法基于准确性评估,但难以保障推荐内容能够满足用户需求、偏好的变化,因为单纯准确性可能会导致所推荐内容没有新意.为了获得高的精度评估值,用户可能仅收到那些与他们初始评分高的项目类似的推荐项目(过度专业化).这必然会降低用户体验的满意度[101].因此,用户体验评估的核心指标是推荐的“偶然性”,该指标通常采用新颖度(novelty)和多样性(diversity)等二级指标来衡量.新颖度是指所推荐的项目在用户过往的交互记录中出现得越少越好[102];多样性是指推荐列表中出现的项目越不相似越好,因为用户可能对包含彼此非常相似项目的推荐列表感到不满意[98].新颖而多样的学习资源会在一定程度上激发学习者的学习兴趣,即提高学习资源推荐的新颖度和多样性会对学习者的学习热情产生积极影响[42,53].文献[42]结合练习题的题型、难度、涵盖的知识点等特征,在对练习题推荐精度的基础上,还对推荐的新颖度和多样性进行了评估.对用户体验的评估也常采用人工方法.如文献[103]和文献[104]中,设计了用户体验量表,采用人工打分的方式进行评估,来衡量推荐的感知相关性,此外文献[103]还采用人工打分方式评估了推荐的可用性. ...
... ]中,设计了用户体验量表,采用人工打分的方式进行评估,来衡量推荐的感知相关性,此外文献[103]还采用人工打分方式评估了推荐的可用性. ...
Further thoughts on context aware paper recommendations for education
1
2014
... 文献[60]对七种推荐的结果进行人工评估,结果表明用户体验的质量与推荐的高精度并不相关.一般而言,用户体验好的推荐内容,除了符合自己偏好外,还要尽量做到不与刚刚看过的内容完全相同或者非常相似,但是一味追求推荐的高精度往往会忽视这一问题.为了解决这一问题,近年来研究人员对推荐的“偶然性”[98,99]开展研究.文献[100]指出,现有大多数的推荐算法基于准确性评估,但难以保障推荐内容能够满足用户需求、偏好的变化,因为单纯准确性可能会导致所推荐内容没有新意.为了获得高的精度评估值,用户可能仅收到那些与他们初始评分高的项目类似的推荐项目(过度专业化).这必然会降低用户体验的满意度[101].因此,用户体验评估的核心指标是推荐的“偶然性”,该指标通常采用新颖度(novelty)和多样性(diversity)等二级指标来衡量.新颖度是指所推荐的项目在用户过往的交互记录中出现得越少越好[102];多样性是指推荐列表中出现的项目越不相似越好,因为用户可能对包含彼此非常相似项目的推荐列表感到不满意[98].新颖而多样的学习资源会在一定程度上激发学习者的学习兴趣,即提高学习资源推荐的新颖度和多样性会对学习者的学习热情产生积极影响[42,53].文献[42]结合练习题的题型、难度、涵盖的知识点等特征,在对练习题推荐精度的基础上,还对推荐的新颖度和多样性进行了评估.对用户体验的评估也常采用人工方法.如文献[103]和文献[104]中,设计了用户体验量表,采用人工打分的方式进行评估,来衡量推荐的感知相关性,此外文献[103]还采用人工打分方式评估了推荐的可用性. ...
Exercises recommending for limited time learning
2
2010
... 学习适用性也是学习推荐系统评估的另一个重要方面,所采取的方式比较灵活,可以通过推荐系统对学习成绩的影响,对学习积极性的影响来进行评估.在文献[105]中,首先将学习者分为三类:第一类通过所提出推荐系统获得推荐;第二类随机获得推荐;第三类没有获得推荐.然后通过比较三类学习者的成绩来开展学习适用性评估.文献[106]通过统计学习者对所推荐文章的阅读、回复和发布频率来评估推荐的适用性.文献[107]将学习者在推荐影响下参与学习活动的频率作为推荐适用性的评估依据.与文献[105]一样,文献[108]和文献[109]也都采用了“推荐前”和“推荐后”的成绩对比来评估学习适用性.其中文献[109]还预设了“适用性等级”,通过成绩提升效果来衡量推荐适用性的级别.此外,文献[108]和文献[109]还通过对学习者在使用推荐系统前后的在线时长、互动频率等进行了比较评估.文献[18]和文献[110]使用Felder-Silverman学习风格指数问卷,通过测量使用推荐系统前后学习风格变化,来评估所提出推荐系统的学习适用性.文献[111]使用“自我-同行”评估方法,应用知识指示事件(know-ledge indicating events,KIE)来评估推荐系统对于学习者知识水平的影响. ...
... ]将学习者在推荐影响下参与学习活动的频率作为推荐适用性的评估依据.与文献[105]一样,文献[108]和文献[109]也都采用了“推荐前”和“推荐后”的成绩对比来评估学习适用性.其中文献[109]还预设了“适用性等级”,通过成绩提升效果来衡量推荐适用性的级别.此外,文献[108]和文献[109]还通过对学习者在使用推荐系统前后的在线时长、互动频率等进行了比较评估.文献[18]和文献[110]使用Felder-Silverman学习风格指数问卷,通过测量使用推荐系统前后学习风格变化,来评估所提出推荐系统的学习适用性.文献[111]使用“自我-同行”评估方法,应用知识指示事件(know-ledge indicating events,KIE)来评估推荐系统对于学习者知识水平的影响. ...
Using collaborative filtering to support college students’ use of online forum for English learning
1
2012
... 学习适用性也是学习推荐系统评估的另一个重要方面,所采取的方式比较灵活,可以通过推荐系统对学习成绩的影响,对学习积极性的影响来进行评估.在文献[105]中,首先将学习者分为三类:第一类通过所提出推荐系统获得推荐;第二类随机获得推荐;第三类没有获得推荐.然后通过比较三类学习者的成绩来开展学习适用性评估.文献[106]通过统计学习者对所推荐文章的阅读、回复和发布频率来评估推荐的适用性.文献[107]将学习者在推荐影响下参与学习活动的频率作为推荐适用性的评估依据.与文献[105]一样,文献[108]和文献[109]也都采用了“推荐前”和“推荐后”的成绩对比来评估学习适用性.其中文献[109]还预设了“适用性等级”,通过成绩提升效果来衡量推荐适用性的级别.此外,文献[108]和文献[109]还通过对学习者在使用推荐系统前后的在线时长、互动频率等进行了比较评估.文献[18]和文献[110]使用Felder-Silverman学习风格指数问卷,通过测量使用推荐系统前后学习风格变化,来评估所提出推荐系统的学习适用性.文献[111]使用“自我-同行”评估方法,应用知识指示事件(know-ledge indicating events,KIE)来评估推荐系统对于学习者知识水平的影响. ...
Getting to know your user-unobtrusive user model maintenance within work-integrated learning environments
1
2009
... 学习适用性也是学习推荐系统评估的另一个重要方面,所采取的方式比较灵活,可以通过推荐系统对学习成绩的影响,对学习积极性的影响来进行评估.在文献[105]中,首先将学习者分为三类:第一类通过所提出推荐系统获得推荐;第二类随机获得推荐;第三类没有获得推荐.然后通过比较三类学习者的成绩来开展学习适用性评估.文献[106]通过统计学习者对所推荐文章的阅读、回复和发布频率来评估推荐的适用性.文献[107]将学习者在推荐影响下参与学习活动的频率作为推荐适用性的评估依据.与文献[105]一样,文献[108]和文献[109]也都采用了“推荐前”和“推荐后”的成绩对比来评估学习适用性.其中文献[109]还预设了“适用性等级”,通过成绩提升效果来衡量推荐适用性的级别.此外,文献[108]和文献[109]还通过对学习者在使用推荐系统前后的在线时长、互动频率等进行了比较评估.文献[18]和文献[110]使用Felder-Silverman学习风格指数问卷,通过测量使用推荐系统前后学习风格变化,来评估所提出推荐系统的学习适用性.文献[111]使用“自我-同行”评估方法,应用知识指示事件(know-ledge indicating events,KIE)来评估推荐系统对于学习者知识水平的影响. ...
Extending web-based educational systems with personalised support through user centred designed recommendations along the e-learning life cycle
2
2014
... 学习适用性也是学习推荐系统评估的另一个重要方面,所采取的方式比较灵活,可以通过推荐系统对学习成绩的影响,对学习积极性的影响来进行评估.在文献[105]中,首先将学习者分为三类:第一类通过所提出推荐系统获得推荐;第二类随机获得推荐;第三类没有获得推荐.然后通过比较三类学习者的成绩来开展学习适用性评估.文献[106]通过统计学习者对所推荐文章的阅读、回复和发布频率来评估推荐的适用性.文献[107]将学习者在推荐影响下参与学习活动的频率作为推荐适用性的评估依据.与文献[105]一样,文献[108]和文献[109]也都采用了“推荐前”和“推荐后”的成绩对比来评估学习适用性.其中文献[109]还预设了“适用性等级”,通过成绩提升效果来衡量推荐适用性的级别.此外,文献[108]和文献[109]还通过对学习者在使用推荐系统前后的在线时长、互动频率等进行了比较评估.文献[18]和文献[110]使用Felder-Silverman学习风格指数问卷,通过测量使用推荐系统前后学习风格变化,来评估所提出推荐系统的学习适用性.文献[111]使用“自我-同行”评估方法,应用知识指示事件(know-ledge indicating events,KIE)来评估推荐系统对于学习者知识水平的影响. ...
... ]还预设了“适用性等级”,通过成绩提升效果来衡量推荐适用性的级别.此外,文献[108]和文献[109]还通过对学习者在使用推荐系统前后的在线时长、互动频率等进行了比较评估.文献[18]和文献[110]使用Felder-Silverman学习风格指数问卷,通过测量使用推荐系统前后学习风格变化,来评估所提出推荐系统的学习适用性.文献[111]使用“自我-同行”评估方法,应用知识指示事件(know-ledge indicating events,KIE)来评估推荐系统对于学习者知识水平的影响. ...
Qualitative and quantitative evaluation of an adaptive course in GALE
3
2013
... 学习适用性也是学习推荐系统评估的另一个重要方面,所采取的方式比较灵活,可以通过推荐系统对学习成绩的影响,对学习积极性的影响来进行评估.在文献[105]中,首先将学习者分为三类:第一类通过所提出推荐系统获得推荐;第二类随机获得推荐;第三类没有获得推荐.然后通过比较三类学习者的成绩来开展学习适用性评估.文献[106]通过统计学习者对所推荐文章的阅读、回复和发布频率来评估推荐的适用性.文献[107]将学习者在推荐影响下参与学习活动的频率作为推荐适用性的评估依据.与文献[105]一样,文献[108]和文献[109]也都采用了“推荐前”和“推荐后”的成绩对比来评估学习适用性.其中文献[109]还预设了“适用性等级”,通过成绩提升效果来衡量推荐适用性的级别.此外,文献[108]和文献[109]还通过对学习者在使用推荐系统前后的在线时长、互动频率等进行了比较评估.文献[18]和文献[110]使用Felder-Silverman学习风格指数问卷,通过测量使用推荐系统前后学习风格变化,来评估所提出推荐系统的学习适用性.文献[111]使用“自我-同行”评估方法,应用知识指示事件(know-ledge indicating events,KIE)来评估推荐系统对于学习者知识水平的影响. ...
... ]也都采用了“推荐前”和“推荐后”的成绩对比来评估学习适用性.其中文献[109]还预设了“适用性等级”,通过成绩提升效果来衡量推荐适用性的级别.此外,文献[108]和文献[109]还通过对学习者在使用推荐系统前后的在线时长、互动频率等进行了比较评估.文献[18]和文献[110]使用Felder-Silverman学习风格指数问卷,通过测量使用推荐系统前后学习风格变化,来评估所提出推荐系统的学习适用性.文献[111]使用“自我-同行”评估方法,应用知识指示事件(know-ledge indicating events,KIE)来评估推荐系统对于学习者知识水平的影响. ...
... ]和文献[109]还通过对学习者在使用推荐系统前后的在线时长、互动频率等进行了比较评估.文献[18]和文献[110]使用Felder-Silverman学习风格指数问卷,通过测量使用推荐系统前后学习风格变化,来评估所提出推荐系统的学习适用性.文献[111]使用“自我-同行”评估方法,应用知识指示事件(know-ledge indicating events,KIE)来评估推荐系统对于学习者知识水平的影响. ...
Immediate elaborated feedback personalization in online assessment
1
2008
... 学习适用性也是学习推荐系统评估的另一个重要方面,所采取的方式比较灵活,可以通过推荐系统对学习成绩的影响,对学习积极性的影响来进行评估.在文献[105]中,首先将学习者分为三类:第一类通过所提出推荐系统获得推荐;第二类随机获得推荐;第三类没有获得推荐.然后通过比较三类学习者的成绩来开展学习适用性评估.文献[106]通过统计学习者对所推荐文章的阅读、回复和发布频率来评估推荐的适用性.文献[107]将学习者在推荐影响下参与学习活动的频率作为推荐适用性的评估依据.与文献[105]一样,文献[108]和文献[109]也都采用了“推荐前”和“推荐后”的成绩对比来评估学习适用性.其中文献[109]还预设了“适用性等级”,通过成绩提升效果来衡量推荐适用性的级别.此外,文献[108]和文献[109]还通过对学习者在使用推荐系统前后的在线时长、互动频率等进行了比较评估.文献[18]和文献[110]使用Felder-Silverman学习风格指数问卷,通过测量使用推荐系统前后学习风格变化,来评估所提出推荐系统的学习适用性.文献[111]使用“自我-同行”评估方法,应用知识指示事件(know-ledge indicating events,KIE)来评估推荐系统对于学习者知识水平的影响. ...
Which user interactions predict levels of expertise in work-integrated learning?
1
2013
... 学习适用性也是学习推荐系统评估的另一个重要方面,所采取的方式比较灵活,可以通过推荐系统对学习成绩的影响,对学习积极性的影响来进行评估.在文献[105]中,首先将学习者分为三类:第一类通过所提出推荐系统获得推荐;第二类随机获得推荐;第三类没有获得推荐.然后通过比较三类学习者的成绩来开展学习适用性评估.文献[106]通过统计学习者对所推荐文章的阅读、回复和发布频率来评估推荐的适用性.文献[107]将学习者在推荐影响下参与学习活动的频率作为推荐适用性的评估依据.与文献[105]一样,文献[108]和文献[109]也都采用了“推荐前”和“推荐后”的成绩对比来评估学习适用性.其中文献[109]还预设了“适用性等级”,通过成绩提升效果来衡量推荐适用性的级别.此外,文献[108]和文献[109]还通过对学习者在使用推荐系统前后的在线时长、互动频率等进行了比较评估.文献[18]和文献[110]使用Felder-Silverman学习风格指数问卷,通过测量使用推荐系统前后学习风格变化,来评估所提出推荐系统的学习适用性.文献[111]使用“自我-同行”评估方法,应用知识指示事件(know-ledge indicating events,KIE)来评估推荐系统对于学习者知识水平的影响. ...
MoocRec: learning styles-oriented MOOC recommender and search engine
1
2019
... 目前可用于评估个性化学习推荐系统的通用数据集不多,从当前研究的应用场景来看,可以分为用于课程推荐、学习资源推荐以及学习路径推荐三类.课程推荐常用到edX、Coursera、学堂在线(XuetangX)、中国慕课大学(icourse163)等在线课程平台提供的数据集,比如edX数据集可用于评估基于学习风格的课程推荐[112],XuetangX数据集可用于评估基于学习偏好的课程推荐[55],icourse163数据集可用于课程学习中的主题推荐[39].对于学习资源推荐常采用Amazon产品数据集、ASSISTment学习平台数据集等,比如学习书籍推荐使用Amazon的Book- Crossing数据集[53]、e-book数据集[63],练习题推荐使用ASSISTment数据集[42].对于学习路径推荐而言,离线方法并不能提供可靠的结果,因为其假设学习者的行为不会随时间发生变化,研究人员无法获取适用于他们实验的公共数据集[7],所以通常自组织数据集,比如文献[15]和文献[75]均使用了自组织的数据集对提出的推荐方法进行评估. ...







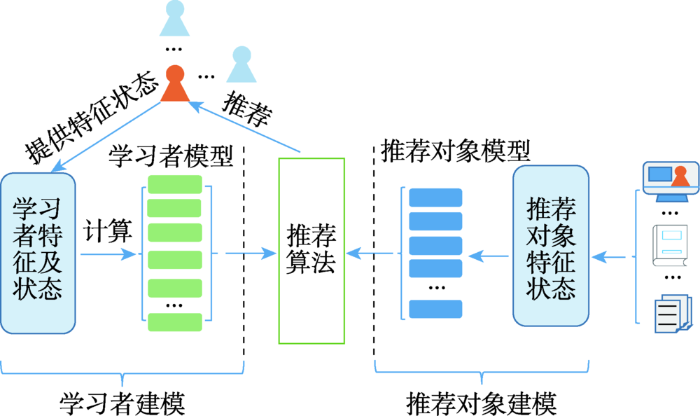
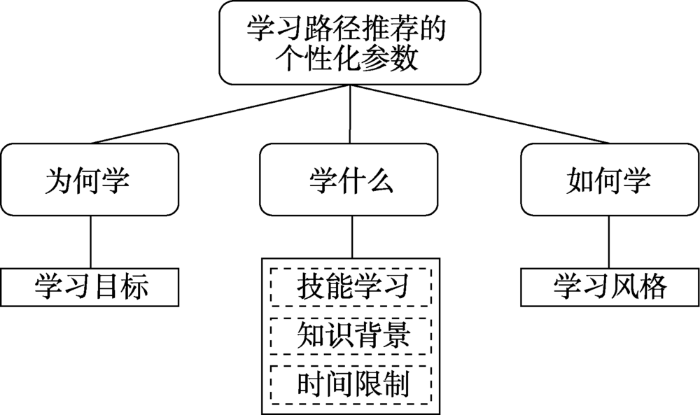
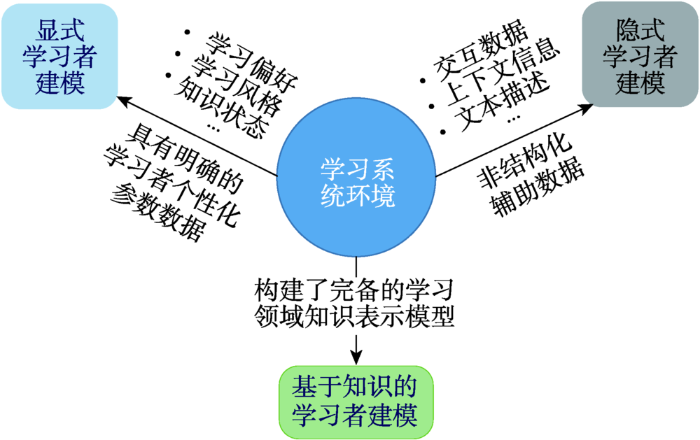
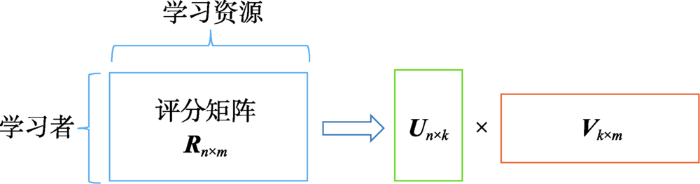
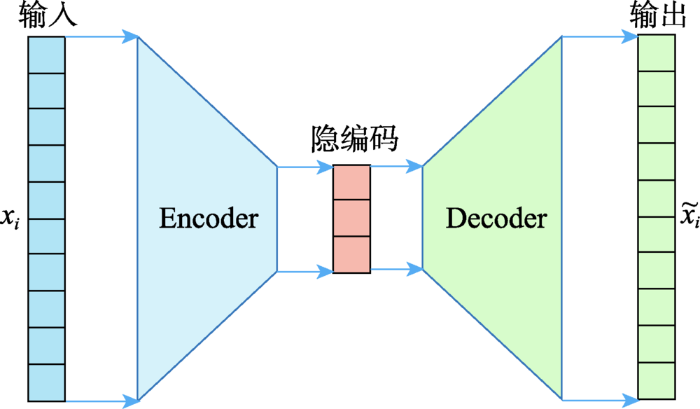
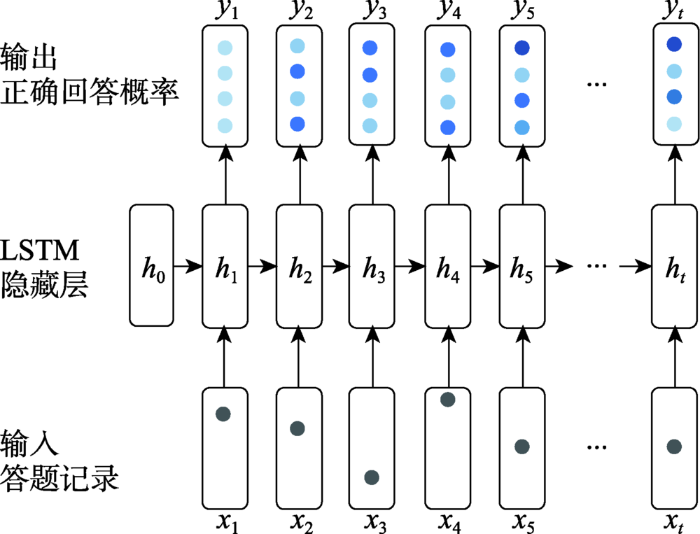
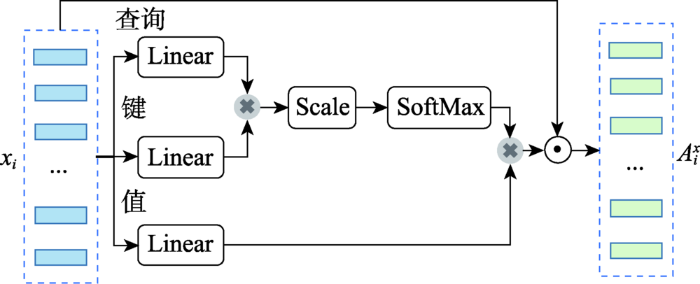
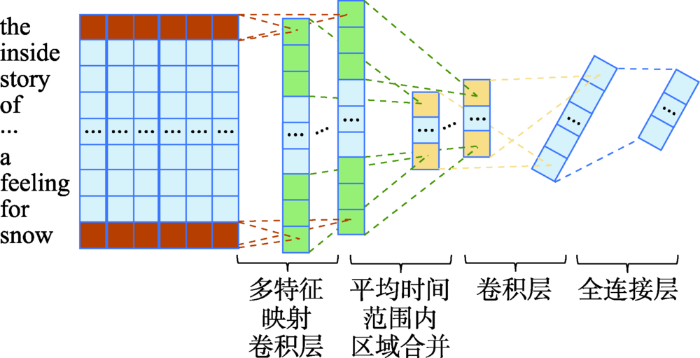
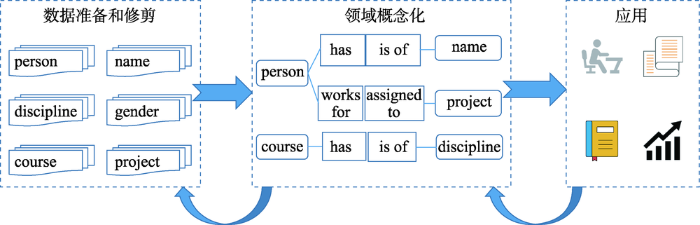
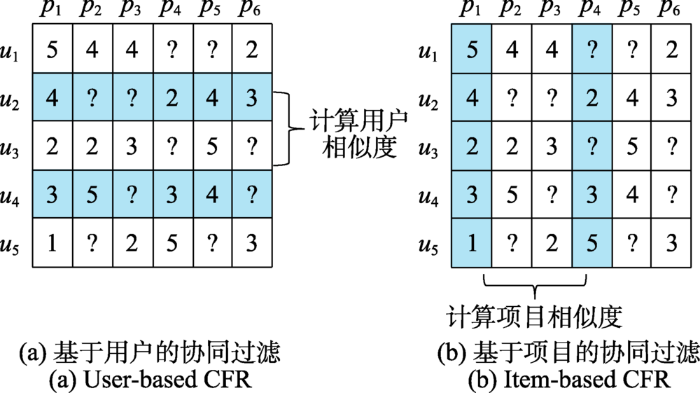
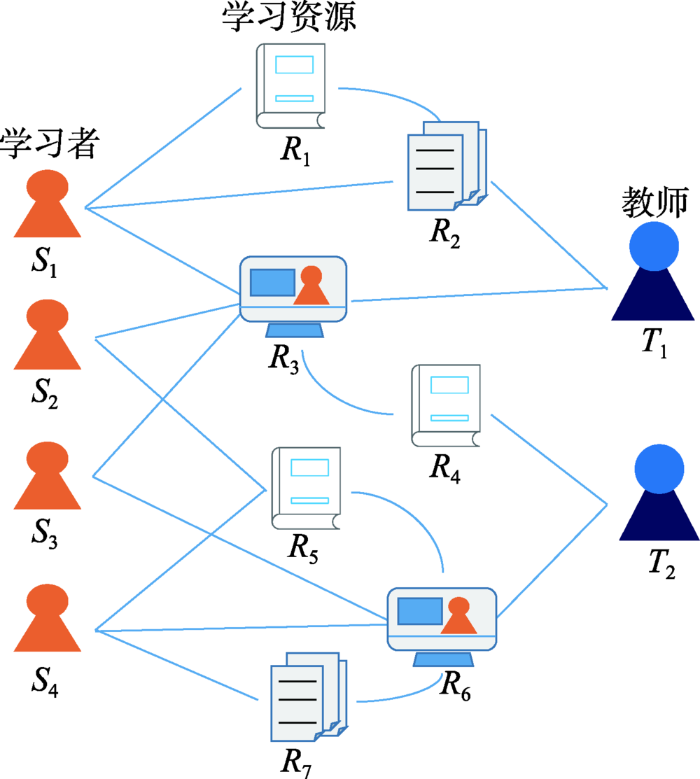

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}