
计算机科学与探索 ›› 2022, Vol. 16 ›› Issue (7): 1570-1582.DOI: 10.3778/j.issn.1673-9418.2012085
潘风蕊1,+( ), 李涛1,2, 邢立冬1, 张好聪1, 吴冠中1
), 李涛1,2, 邢立冬1, 张好聪1, 吴冠中1
收稿日期:2020-12-22
修回日期:2021-02-25
出版日期:2022-07-01
发布日期:2021-03-23
作者简介:潘风蕊(1996—),女,陕西渭南人,硕士研究生,主要研究方向为集成电路系统设计。 基金资助:
PAN Fengrui1,+(), LI Tao1,2, XING Lidong1, ZHANG Haocong1, WU Guanzhong1
Received:2020-12-22
Revised:2021-02-25
Online:2022-07-01
Published:2021-03-23
Supported by:摘要:
传统的可编程处理器虽然高度灵活,但其处理速度及性能不及专用集成电路(ASIC),而图像处理往往是多样、密集且重复的操作,因此处理器要兼顾速度、性能及灵活性。OpenVX是图像图形处理、图计算和深度学习等应用的预处理或者辅助处理开源标准,基于最新的OpenVX 1.3标准中的核心图像处理函数库,设计并实现了一种可编程、可扩展的专用指令集处理器(ASIP)——OpenVX并行处理器。首先分析对比了各种互联网络的拓扑特性,选择了性能比较突出的层次交叉互联网络(HCCM+)作为系统主干,在网络节点处设置处理单元(PE)构成支持动态配置的4×4 PE阵列,结合高效的路由通信方式设计了并行处理器,实现可编程的图像处理。其次所提出的架构适合数据并行计算和新兴的图计算,两种计算模式可单独或混合配置使用,分别将核心视觉函数及图计算模型映射到并行处理器上对两种模式进行验证,对比PE数目不同的情况下图像处理的速度。实验结果表明,并行处理器能够完成对基本核心函数和高复杂度的图计算模型的映射,在数据并行计算和流水线处理两种模式下,可以对图像处理线性加速,调用16个PE对各类函数的平均加速比可达15.037 5。验证环境采用20 nm XCVU440平台芯片,综合实现后频率为125 MHz。
中图分类号:
潘风蕊, 李涛, 邢立冬, 张好聪, 吴冠中. 面向OpenVX核心图像处理函数的并行架构设计[J]. 计算机科学与探索, 2022, 16(7): 1570-1582.
PAN Fengrui, LI Tao, XING Lidong, ZHANG Haocong, WU Guanzhong. Parallel Architecture Design for OpenVX Kernel Image Processing Functions[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(7): 1570-1582.

图1 OpenVX图计算模型
Fig.1 OpenVX graph calculation model

图2 互连网络拓扑结构
Fig.2 Interconnection network topology
| 类型 | Mesh | HCCM | HCCM- | HCCM+ |
|---|---|---|---|---|
| 级数 | | | | |
| 边长 | | | | |
| 节点数 | | | | |
| 边数 | | | | |
| 直径 | | | | |
| 等分宽度 | | | 4 | |
表1 互联网络拓扑性能比较
Table 1 Comparison of network topology performance
| 类型 | Mesh | HCCM | HCCM- | HCCM+ |
|---|---|---|---|---|
| 级数 | | | | |
| 边长 | | | | |
| 节点数 | | | | |
| 边数 | | | | |
| 直径 | | | | |
| 等分宽度 | | | 4 | |

图3 OpenVX并行处理器整体架构
Fig.3 OpenVX parallel processor architecture

图4 PE整体结构
Fig.4 PE architecture
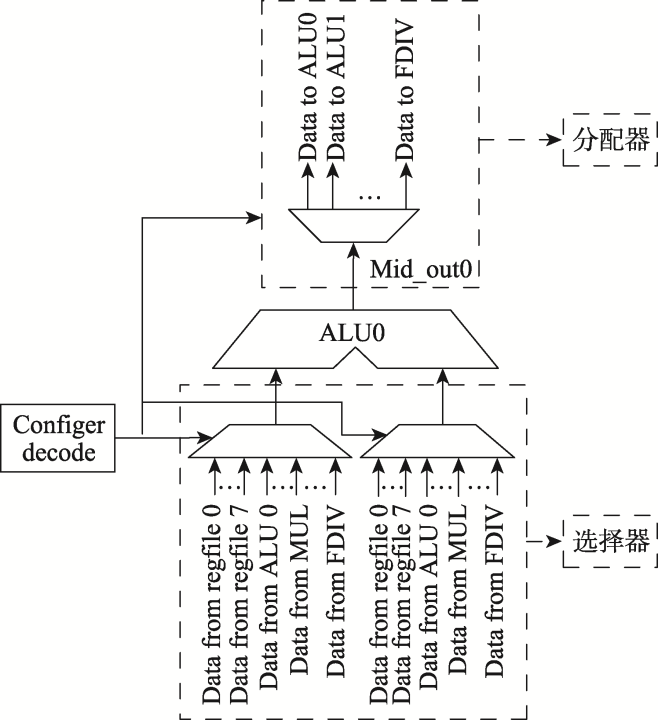
图5 ALU0 I/O数据通路
Fig.5 ALU0 I/O data path
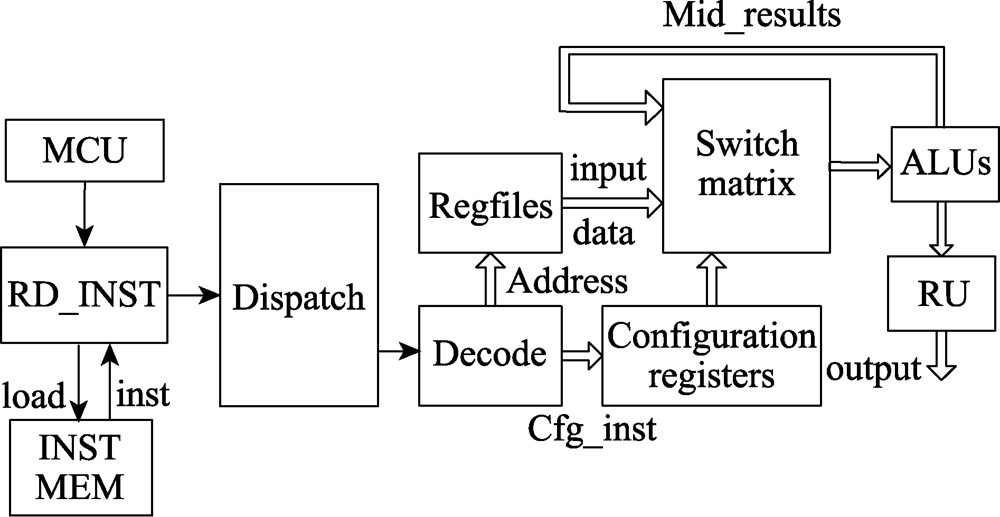
图6 全局控制电路
Fig.6 Global control circuit
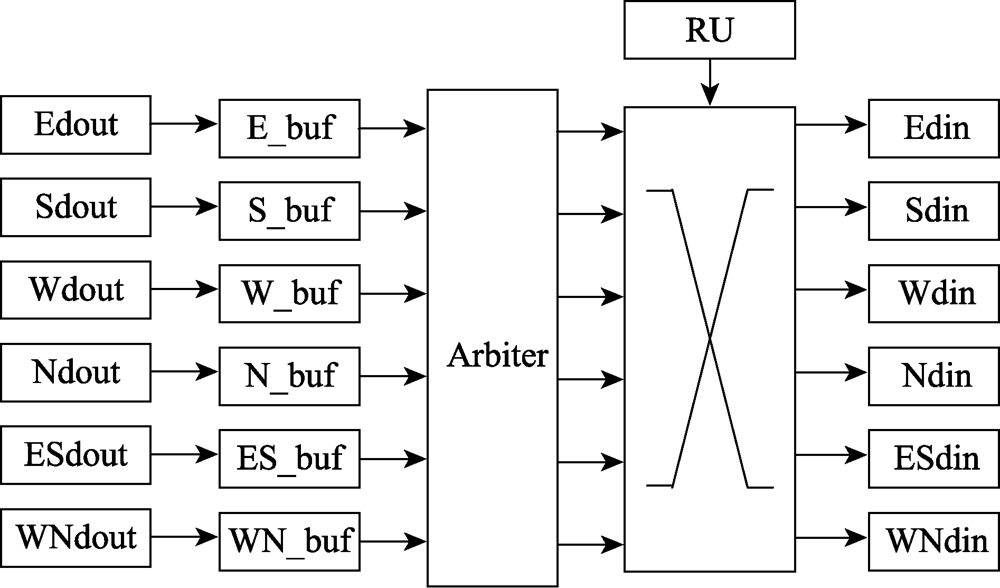
图7 路由结构
Fig.7 Route structure

图8 PE之间数据路由
Fig.8 Data routing between PEs

图9 数据并行计算模式映射
Fig.9 Data parallel computing pattern mapping

图10 数据并行计算模式下图像分块
Fig.10 Image segmentation in data parallel computing mode

图11 形态学滤波执行流程
Fig.11 Morphological filtering execution flow
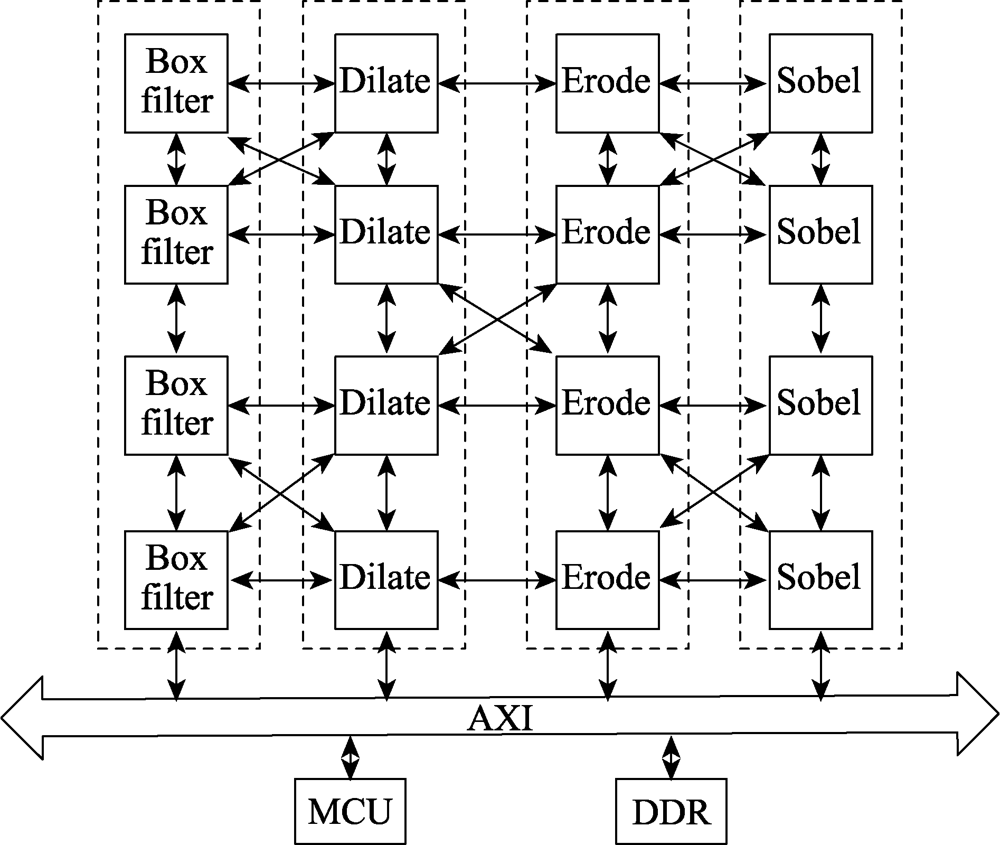
图12 流水线处理模式映射
Fig.12 Pipeline processing pattern mapping
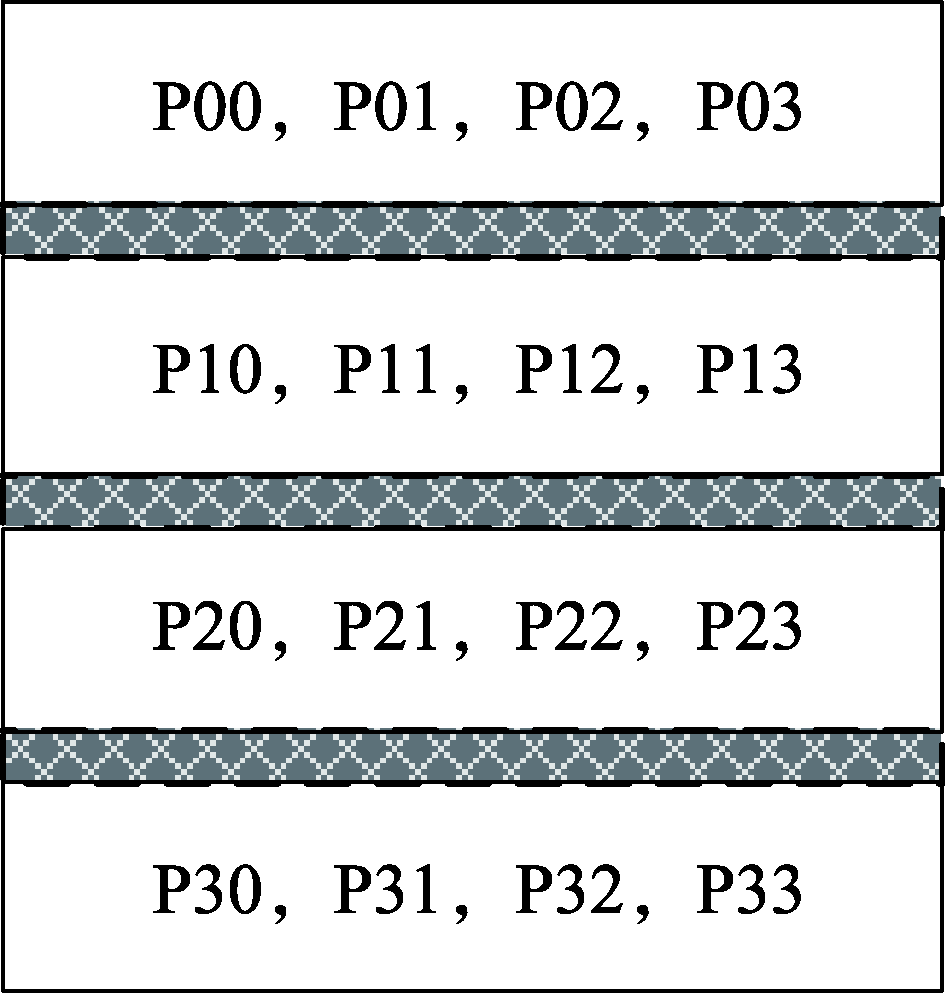
图13 形态学滤波数据分块
Fig.13 Morphological filtering data segmentation

图14 仿真测试平台
Fig.14 Simulation test platform
| 函数类别 | | 1PE | 2PE | 4PE | 8PE | 16PE | |
|---|---|---|---|---|---|---|---|
| Ⅰ | 通道提取 | T/clk | 307 364 | 167 045 | 90 667 | 44 740 | 20 382 |
| | 1.00 | 1.81 | 3.45 | 6.94 | 15.29 | ||
| 颜色转换 | T/clk | 307 375 | 169 820 | 89 094 | 44 290 | 20 103 | |
| | 1.00 | 1.84 | 3.39 | 6.87 | 15.08 | ||
| 位深转换 | T/clk | 307 372 | 171 716 | 90 403 | 44 871 | 20 301 | |
| | 1.00 | 1.79 | 3.40 | 6.85 | 15.14 | ||
| Ⅱ | 直方图 | T/clk | 614 426 | 372 379 | 187 897 | 94 818 | 41 375 |
| | 1.00 | 1.65 | 3.27 | 6.48 | 14.85 | ||
| 图像积分 | T/clk | 438 723 | 270 816 | 141 068 | 68 981 | 29 643 | |
| | 1.00 | 1.62 | 3.11 | 6.36 | 14.80 | ||
| Ⅲ | 中值滤波 | T/clk | 307 283 | 167 914 | 85 594 | 44 858 | 20 162 |
| | 1.00 | 1.83 | 3.57 | 6.85 | 15.21 | ||
| 图像膨胀 | T/clk | 307 282 | 167 001 | 85 832 | 44 990 | 20 162 | |
| | 1.00 | 1.79 | 3.52 | 7.34 | 15.24 | ||
| 图像腐蚀 | T/clk | 307 282 | 167 001 | 85 832 | 44 924 | 20 162 | |
| | 1.00 | 1.79 | 3.52 | 7.34 | 15.24 | ||
| Sobel | T/clk | 307 285 | 168 837 | 86 074 | 44 924 | 20 256 | |
| | 1.00 | 1.82 | 3.59 | 7.12 | 15.17 | ||
| Ⅳ | Canny | T/clk | 307 314 | 187 386 | 91 735 | 46 775 | 20 750 |
| | 1.00 | 1.64 | 3.35 | 6.57 | 14.81 | ||
| 高斯金字塔 | T/clk | 409 615 | 245 278 | 121 547 | 62 824 | 27 695 | |
| | 1.00 | 1.67 | 3.37 | 6.52 | 14.79 | ||
| Harris Corner | T/clk | 307 309 | 182 922 | 89 856 | 46 917 | 20 722 | |
| | 1.00 | 1.68 | 3.42 | 6.55 | 14.83 | ||
表2 基本核心函数加速比对比
Table 2 Comparison of speedups of basic kernel functions
| 函数类别 | | 1PE | 2PE | 4PE | 8PE | 16PE | |
|---|---|---|---|---|---|---|---|
| Ⅰ | 通道提取 | T/clk | 307 364 | 167 045 | 90 667 | 44 740 | 20 382 |
| | 1.00 | 1.81 | 3.45 | 6.94 | 15.29 | ||
| 颜色转换 | T/clk | 307 375 | 169 820 | 89 094 | 44 290 | 20 103 | |
| | 1.00 | 1.84 | 3.39 | 6.87 | 15.08 | ||
| 位深转换 | T/clk | 307 372 | 171 716 | 90 403 | 44 871 | 20 301 | |
| | 1.00 | 1.79 | 3.40 | 6.85 | 15.14 | ||
| Ⅱ | 直方图 | T/clk | 614 426 | 372 379 | 187 897 | 94 818 | 41 375 |
| | 1.00 | 1.65 | 3.27 | 6.48 | 14.85 | ||
| 图像积分 | T/clk | 438 723 | 270 816 | 141 068 | 68 981 | 29 643 | |
| | 1.00 | 1.62 | 3.11 | 6.36 | 14.80 | ||
| Ⅲ | 中值滤波 | T/clk | 307 283 | 167 914 | 85 594 | 44 858 | 20 162 |
| | 1.00 | 1.83 | 3.57 | 6.85 | 15.21 | ||
| 图像膨胀 | T/clk | 307 282 | 167 001 | 85 832 | 44 990 | 20 162 | |
| | 1.00 | 1.79 | 3.52 | 7.34 | 15.24 | ||
| 图像腐蚀 | T/clk | 307 282 | 167 001 | 85 832 | 44 924 | 20 162 | |
| | 1.00 | 1.79 | 3.52 | 7.34 | 15.24 | ||
| Sobel | T/clk | 307 285 | 168 837 | 86 074 | 44 924 | 20 256 | |
| | 1.00 | 1.82 | 3.59 | 7.12 | 15.17 | ||
| Ⅳ | Canny | T/clk | 307 314 | 187 386 | 91 735 | 46 775 | 20 750 |
| | 1.00 | 1.64 | 3.35 | 6.57 | 14.81 | ||
| 高斯金字塔 | T/clk | 409 615 | 245 278 | 121 547 | 62 824 | 27 695 | |
| | 1.00 | 1.67 | 3.37 | 6.52 | 14.79 | ||
| Harris Corner | T/clk | 307 309 | 182 922 | 89 856 | 46 917 | 20 722 | |
| | 1.00 | 1.68 | 3.42 | 6.55 | 14.83 | ||

图15 不同函数串并比处理权重对比
Fig.15 Weight comparison of different functions serial parallelism ratio

图16 不同函数处理时间对比
Fig.16 Comparison of processing time of different functions

图17 图像处理前后对比
Fig.17 Contrast before and after image processing
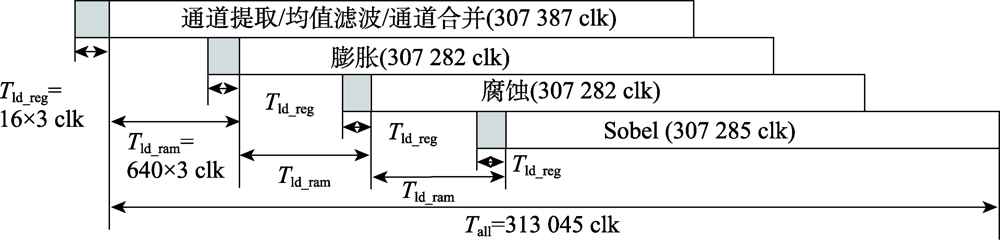
图18 Graph单流水线处理
Fig.18 Graph pipeline processing
| 流水线数目/个 | 处理时间/clk |
|---|---|
| 1 | 313 045 |
| 2 | 220 454 |
| 3 | 132 086 |
| 4 | 92 072 |
表3 不同数目流水线处理时间
Table 3 Processing time of different number of pipelines
| 流水线数目/个 | 处理时间/clk |
|---|---|
| 1 | 313 045 |
| 2 | 220 454 |
| 3 | 132 086 |
| 4 | 92 072 |
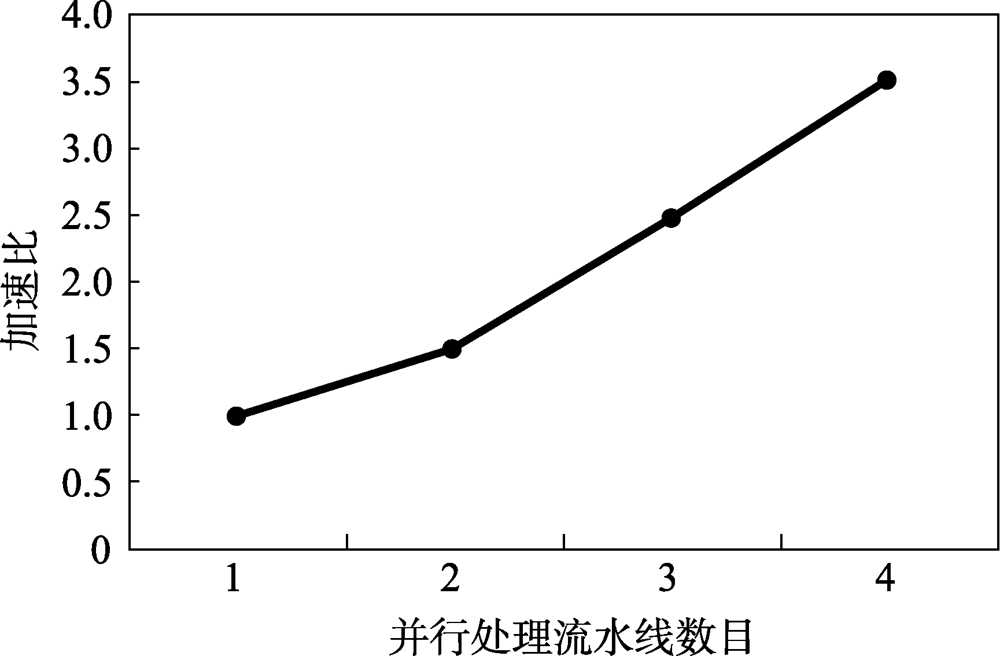
图19 Graph计算模型加速比
Fig.19 Graph execution model acceleration ratio

图20 平均延时对比
Fig.20 Average delay comparison
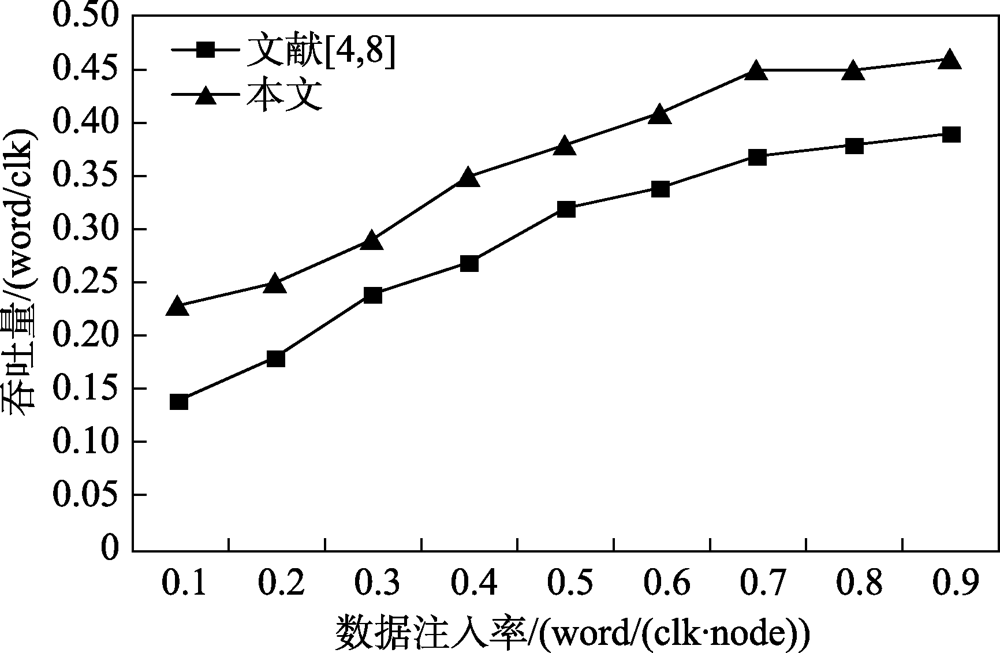
图21 吞吐量对比
Fig.21 Throughput comparison

图22 核心函数加速比对比
Fig.22 Speedup comparison of kernel functions
| 比较项 | FPGA型号 | PE数目 | 处理时间/ms |
|---|---|---|---|
| 本文 | XCVU440-flga2892-2-e | 1 | 2.46 |
| 2 | 1.35 | ||
| 4 | 0.69 | ||
| 8 | 0.36 | ||
| 16 | 0.16 | ||
| 文献[18] | XC3S2000 | — | 0.66 |
| 文献[19] | EP1K30TC144-1 | — | 6.30 |
| 文献[20] | CYCLONEEP1C20 | — | 1.30 |
表4 处理时间对比
Table 4 Comparison of processing time
| 比较项 | FPGA型号 | PE数目 | 处理时间/ms |
|---|---|---|---|
| 本文 | XCVU440-flga2892-2-e | 1 | 2.46 |
| 2 | 1.35 | ||
| 4 | 0.69 | ||
| 8 | 0.36 | ||
| 16 | 0.16 | ||
| 文献[18] | XC3S2000 | — | 0.66 |
| 文献[19] | EP1K30TC144-1 | — | 6.30 |
| 文献[20] | CYCLONEEP1C20 | — | 1.30 |
| 比较项 | LUT(look up table) | FF(filp flop) | Slice | 频率/MHz | 支持处理类型 |
|---|---|---|---|---|---|
| 本文 | 28 768 | 8 704 | 1 596 | 125 | 38 |
| 文献[18] | 1 289 | 1 458 | 1 130 | 105 | 1 |
| 文献[19] | — | — | — | 80 | 1 |
| 文献[20] | 4 096 | — | — | 50 | 1 |
表5 性能对比
Table 5 Performance comparison
| 比较项 | LUT(look up table) | FF(filp flop) | Slice | 频率/MHz | 支持处理类型 |
|---|---|---|---|---|---|
| 本文 | 28 768 | 8 704 | 1 596 | 125 | 38 |
| 文献[18] | 1 289 | 1 458 | 1 130 | 105 | 1 |
| 文献[19] | — | — | — | 80 | 1 |
| 文献[20] | 4 096 | — | — | 50 | 1 |
| [1] | 李雅琪, 冯晓辉, 王哲. 计算机视觉技术的应用进展[J]. 人工智能, 2019(2): 18-27. |
| LI Y Q, FENG X H, WANG Z. Application progress of computer vision technology[J]. A.pngicial Intelligence View, 2019(2): 18-27. | |
| [2] | 山蕊, 李涛, 蒋林, 等. 视觉阵列处理器超越函数加速单元设计[J]. 西安电子科技大学学报(自然科学版), 2018, 45(4): 166-173. |
| SHAN R, LI T, JIANG L, et al. Design of the transcendental function computing unit of the computer vision array pro-cessor[J]. Journal of Xidian University (Natural Science), 2018, 45(4): 166-173. | |
| [3] | GOOSSENS G. 专用指令集处理器设计的架构性研究[J]. 中国集成电路, 2013, 22(10):41-43. |
| GOOSSENS G, Research on architecture of special instruction set processor[J]. China Integrated Circuits, 2013, 22(10):41-43. | |
| [4] | 李涛, 杨婷, 易学渊, 等. 萤火虫2: 一种多态并行机的硬件体系结构[J]. 计算机工程与科学, 2014, 36(2): 191-200. |
| LI T, YANG T, YI X Y, et al. Architecture of a polymorphous parallel computer[J]. Computer Engineering and Science, 2014, 36(2): 191-200. | |
| [5] | 孙建, 李涛, 李雪丹. 基于PAAG的图形图像算法的并行实现[J]. 计算机技术与发展, 2015, 25(11): 61-66. |
| SUN J, LI T, LI X D. Parallel implementation of graphics rendering and image processing algorithm based on PAAG[J]. Computer Technology and Development, 2015, 25(11): 61-66. | |
| [6] | The Khronos OpenVX Working Group. The OpenVX spe-cification[EB/OL]. (2020-09-10)[2020-10-05]. https://www.khronos.org/registry/OpenVX/specs/1.3/html/.OpenVX_Spe-cification_1_3.html. |
| [7] | 王鹏博. 多态并行机上的OpenVX系统实现[D]. 西安: 西安邮电大学, 2015. WANG P B. Implementation of OpenVX system on poly-morphic parallel computer[D]. Xi’an: Xi’an University of Posts and Telecommunications, 2015. |
| [8] | 李涛, 孙建, 王鹏博. 基于PAAG的OpenVX核心库函数并行化实现[J]. 西安邮电大学学报, 2015, 20(2): 7-10. |
| LI T, SUN J, WANG P B. Parallel implementation of kernels of OpenVX based on PAAG[J]. Journal of Xi’an University of Posts and Telecommunications, 2015, 20(2): 7-10. | |
| [9] | ZAHN F, LAMMEL S, FRÖNING H. On link width scaling for energy-proportional direct interconnection networks[J]. Concurrency and Computation: Practice and Experience, 2019, 31(2): 1-16. |
| [10] | AKL S G. Parallel computation: models and methods[J]. IEEE Concurrency, 1997, 6(4): 79-80. |
| [11] | SHANG J, SHENG D, LIU R, et al. Research on parallel task optimization of high performance computing cluster[C]// Proceedings of the 2020 IEEE International Conference on A.pngicial Intelligence and Information Systems, Dalian, Mar 20-22, 2020. Piscataway: IEEE, 2020: 777-780. |
| [12] | RAO P S, YEDUKONDALU K. Hardware implementation of digital image skeletonization algorithm using FPGA for computer vision applications[J]. Journal of Visual Commu-nication and Image Representation, 2019, 59: 140-149. |
| [13] | 佟倩. 互联网络拓扑结构与鲁棒适变能力研究[D]. 沈阳: 沈阳理工大学, 2018. |
| TONG Q. Research on topology and robust adaptability of interconnected networks[D]. Shenyang: Shenyang University of Technology, 2018. | |
| [14] |
PUNHANI A, KUMAR P, NITIN N. E-XY: an entropy based XY routing algorithm[J]. International Journal of Grid and Utility Computing, 2019, 10(2): 179-186.
DOI URL |
| [15] | 付涛. 高速图像处理算法研究与实现[D]. 绵阳: 西南科技大学, 2016. |
| FU T. Research and implementation of high speed image processing algorithm[D]. Mianyang: Southwest University of Science and Technology, 2016. | |
| [16] | 李海玲, 张昊. 卷积边界扩展研究与实现[J]. 微型电脑应用, 2018, 34(10): 47-49. |
| LI H L, ZHANG H. Research and implementation of con-volution boundary extension[J]. Microcomputer Applications, 2018, 34(10): 47-49. | |
| [17] |
AL-HAYANNI M A N, XIA F, RAFIEV A, et al. Amdahl’s law in the context of heterogeneous many-core systems—a survey[J]. IET Computers & Digital Techniques, 2020, 14(4): 133-148.
DOI URL |
| [18] | 林源晟. 基于FPGA的图像边缘检测系统设计[D]. 西安: 西安电子科技大学, 2014. LIN Y S. Design of image edge detection system based on FPGA[D]. Xi’an: Xi’an University of Electronic Science and Technology, 2014. |
| [19] | 艾扬利, 杨兵. 基于FPGA的Sobel算子并行计算研究[J]. 现代电子技术, 2005, 28(9): 42-43. |
| AI Y L, YANG B. Study of FPGA-based parallel processing of Sobel operator[J]. Modern Electronic Technology, 2005, 28(9): 42-43. | |
| [20] | 官鑫, 王黎, 高晓蓉, 等. 图像边缘检测Sobel算法的FPGA仿真与实现[J]. 现代电子技术, 2009, 32(8): 109-111. |
| GUAN X, WANG L, GAO X R, et al. Emulation and reali-zation of Sobel edge detection algorithm based on FPGA[J]. Modern Electronic Technology, 2009, 32(8): 109-111. |
| [1] | 张好聪, 李涛, 邢立冬, 潘风蕊. OpenVX特征抽取函数在可编程并行架构的实现[J]. 计算机科学与探索, 2022, 16(7): 1583-1593. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||