
计算机科学与探索 ›› 2022, Vol. 16 ›› Issue (10): 2377-2386.DOI: 10.3778/j.issn.1673-9418.2203015
石敏, 沈佳林, 易清明, 骆爱文+( )
)
收稿日期:2022-02-11
修回日期:2022-04-15
出版日期:2022-10-01
发布日期:2022-10-14
通讯作者:
+ E-mail: luoaiwen@jnu.edu.cn作者简介:石敏(1977—),女,湖北襄樊人,博士,副教授,主要研究方向为图像多媒体处理、视频编解码等。基金资助:
SHI Min, SHEN Jialin, YI Qingming, LUO Aiwen+()
Received:2022-02-11
Revised:2022-04-15
Online:2022-10-01
Published:2022-10-14
About author:SHI Min, born in 1977, Ph.D., associate professor. Her research interests include image multimedia processing, video codec, etc.Supported by:摘要:
近年来,随着自动驾驶的火热发展,越来越多研究者开始探索图像语义分割网络的轻量化并将其应用于道路交通场景。而目前现存的语义分割网络通常由于参数量庞大难以部署在硬件资源有限的边缘设备,针对这一问题,设计了一个由通道注意力骨干网络(CABb)和空间注意力解码器(SAD)模块构成的双注意力轻量化网络(DALNet),结合“通道-空间”双注意力机制的DALNet在图像上下文语义信息的提取和图像空间信息的恢复上都具有突出的表现。CABb主要由通道注意力瓶颈(CABt)模块组成,CABt模块采用Split策略分离特征通道并行处理多尺度的特征图,引入通道注意力机制进行通道融合,提取多尺度语义信息。SAD模块利用空间注意力机制指导解码器进行双线性插值上采样,恢复分割目标边沿以及细节信息。实验结果表明,DALNet仅凭48万的参数量在城市交通数据集Cityscapes和CamVid最高分别可达到74.1%和70.1%的交并比(mIoU)。DALNet在输入图像分辨率为512×1 024的情况下,基于GTX 1080Ti GPU可以获得74 frame/s的前向推理速度,远超实时语义分割所需的速度要求。
中图分类号:
石敏, 沈佳林, 易清明, 骆爱文. 快速超轻量城市交通场景语义分割[J]. 计算机科学与探索, 2022, 16(10): 2377-2386.
SHI Min, SHEN Jialin, YI Qingming, LUO Aiwen. Rapid and Ultra-lightweight Semantic Segmentation in Urban Traffic Scene[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(10): 2377-2386.

图1 DALNet网络结构
Fig.1 Structure of DALNet
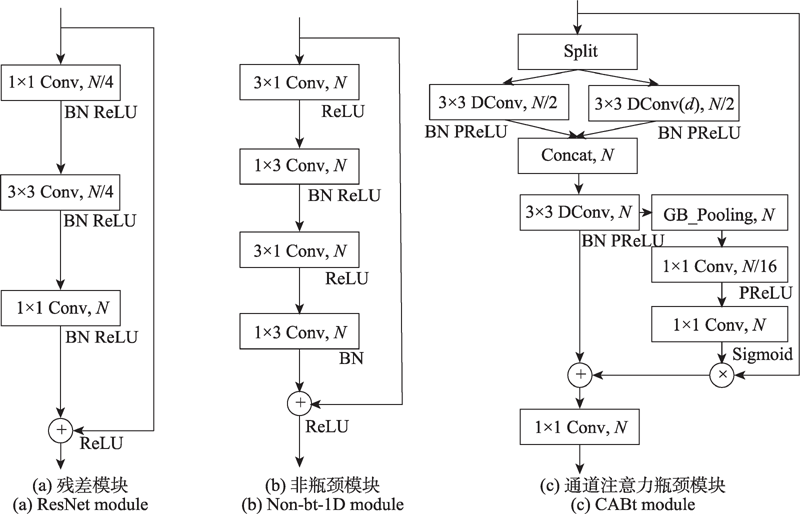
图2 不同瓶颈模块的对比
Fig.2 Comparison of different bottleneck modules

图3 SAD模块
Fig.3 SAD module

图4 DALNet特征热度激活图
Fig.4 DALNet feature heat activation map
| Module | mIoU/% | Speed/(frame/s) | Parameters/106 |
|---|---|---|---|
| Bottleneck[ | 52.5 | 141.6 | 0.36 |
| Non-bt-1D[ | 71.2 | 73.2 | 1.93 |
| CABt | 71.0 | 77.3 | 0.48 |
表1 不同瓶颈模块在Cityscapes验证集的实验结果
Table 1 Experimental results of different bottleneck modules in Cityscapes validation set
| Module | mIoU/% | Speed/(frame/s) | Parameters/106 |
|---|---|---|---|
| Bottleneck[ | 52.5 | 141.6 | 0.36 |
| Non-bt-1D[ | 71.2 | 73.2 | 1.93 |
| CABt | 71.0 | 77.3 | 0.48 |
| Module | SAD | mIoU/% | Speed/(frame/s) | Parameters/106 |
|---|---|---|---|---|
| ResNet[ | 52.5 | 141.6 | 0.36 | |
| √ | 53.4 | 132.4 | 0.36 | |
| ERFNet[ | 70.0 | 41.9 | 2.10 | |
| √ | 71.8 | 70.9 | 1.88 | |
| DALNet | 71.0 | 77.3 | 0.48 | |
| √ | 71.6 | 74.1 | 0.48 |
表2 SAD模块在Cityscapes验证集的实验结果
Table 2 Experimental results of SAD module in Cityscapes validation set
| Module | SAD | mIoU/% | Speed/(frame/s) | Parameters/106 |
|---|---|---|---|---|
| ResNet[ | 52.5 | 141.6 | 0.36 | |
| √ | 53.4 | 132.4 | 0.36 | |
| ERFNet[ | 70.0 | 41.9 | 2.10 | |
| √ | 71.8 | 70.9 | 1.88 | |
| DALNet | 71.0 | 77.3 | 0.48 | |
| √ | 71.6 | 74.1 | 0.48 |
| Method | Input size | mIoU/% | Parameters/ 106 | Speed/ (frame/s) | |
|---|---|---|---|---|---|
| val | test | ||||
| SegNet[ | 360×640 | 57.8 | 56.1 | 29.50 | 38.2 |
| GUN[ | 512×1 024 | 69.6 | 70.4 | — | 33.3 |
| ENet[ | 512×1 024 | 59.0 | 58.3 | 0.36 | 27.4 |
| CGNet[ | 512×1 024 | 63.5 | 64.8 | 0.49 | 65.6 |
| ERFNet[ | 512×1 024 | 70.0 | 68.0 | 2.10 | 41.9 |
| ESNet[ | 512×1 024 | 70.4 | 70.7 | 1.66 | 63.0 |
| EDANet[ | 512×1 024 | 68.1 | 67.3 | 0.68 | 105.5 |
| SQ[19] | 512×1 024 | 59.9 | 59.8 | 16.30 | 25.7 |
| ESPNet[ | 512×1 024 | 60.0 | 60.3 | 0.36 | 146.0 |
| ContextNet[21] | 1 024×2 048 | 67.3 | 66.1 | 0.85 | 57.7 |
| Fast-SCNN[22] | 1 024×2 048 | 68.6 | 68.0 | 1.10 | 67.1 |
| LEDNet[ | 512×1 024 | 70.6 | 69.2 | 0.95 | 59.6 |
| DABNet[ | 512×1 024 | 69.0 | 70.1 | 0.76 | 102.0 |
| DFANet[ | 1 024×1 024 | — | 71.3 | 7.80 | 100.0 |
| Network[ | 448×896 | 74.4 | 73.6 | 6.20 | 51.0* |
| DALNet (ours) | 512×1 024 | 71.6 | 71.1 | 0.48 | 74.1 |
| DALNet (ours) | 1 024×1 024 | 73.5 | 74.1 | 0.48 | 36.5 |
表3 不同模型在Cityscapes数据集上的实验结果
Table 3 Experimental results of different models on Cityscapes dataset
| Method | Input size | mIoU/% | Parameters/ 106 | Speed/ (frame/s) | |
|---|---|---|---|---|---|
| val | test | ||||
| SegNet[ | 360×640 | 57.8 | 56.1 | 29.50 | 38.2 |
| GUN[ | 512×1 024 | 69.6 | 70.4 | — | 33.3 |
| ENet[ | 512×1 024 | 59.0 | 58.3 | 0.36 | 27.4 |
| CGNet[ | 512×1 024 | 63.5 | 64.8 | 0.49 | 65.6 |
| ERFNet[ | 512×1 024 | 70.0 | 68.0 | 2.10 | 41.9 |
| ESNet[ | 512×1 024 | 70.4 | 70.7 | 1.66 | 63.0 |
| EDANet[ | 512×1 024 | 68.1 | 67.3 | 0.68 | 105.5 |
| SQ[19] | 512×1 024 | 59.9 | 59.8 | 16.30 | 25.7 |
| ESPNet[ | 512×1 024 | 60.0 | 60.3 | 0.36 | 146.0 |
| ContextNet[21] | 1 024×2 048 | 67.3 | 66.1 | 0.85 | 57.7 |
| Fast-SCNN[22] | 1 024×2 048 | 68.6 | 68.0 | 1.10 | 67.1 |
| LEDNet[ | 512×1 024 | 70.6 | 69.2 | 0.95 | 59.6 |
| DABNet[ | 512×1 024 | 69.0 | 70.1 | 0.76 | 102.0 |
| DFANet[ | 1 024×1 024 | — | 71.3 | 7.80 | 100.0 |
| Network[ | 448×896 | 74.4 | 73.6 | 6.20 | 51.0* |
| DALNet (ours) | 512×1 024 | 71.6 | 71.1 | 0.48 | 74.1 |
| DALNet (ours) | 1 024×1 024 | 73.5 | 74.1 | 0.48 | 36.5 |
| Method | Input size | mIoU/% | Parameters/106 | Speed/(frame/s) |
|---|---|---|---|---|
| SegNet[ | 360×480 | 55.6 | 29.50 | 49.8 |
| ENet[ | 360×480 | 51.3 | 0.36 | 105.7 |
| CGNet[ | 360×480 | 65.6 | 0.50 | 112.0 |
| EDANet[ | 360×480 | 66.4 | 0.68 | 232.2 |
| ESPNet[ | 360×480 | 55.6 | 0.36 | 297.6 |
| LEDNet[23] | 360×480 | 66.6 | 0.95 | 109.6 |
| DABNet[24] | 360×480 | 66.4 | 0.76 | — |
| DFANet[ | 720×960 | 64.7 | 7.80 | 120.0 |
| Network[26] | 720×960 | 68.0 | 6.20 | 39.3* |
| SwiftNet[27] | 720×960 | 63.3 | 11.80 | — |
| FPENet[28] | 360×480 | 65.4 | 0.40 | 77.1 |
| DALNet (ours) | 360×480 | 66.1 | 0.47 | 103.4 |
| DALNet (ours) | 720×960 | 70.1 | 0.47 | 54.4 |
表4 不同模型在CamVid测试集的实验结果
Table 4 Experimental results of different models on CamVid test set
| Method | Input size | mIoU/% | Parameters/106 | Speed/(frame/s) |
|---|---|---|---|---|
| SegNet[ | 360×480 | 55.6 | 29.50 | 49.8 |
| ENet[ | 360×480 | 51.3 | 0.36 | 105.7 |
| CGNet[ | 360×480 | 65.6 | 0.50 | 112.0 |
| EDANet[ | 360×480 | 66.4 | 0.68 | 232.2 |
| ESPNet[ | 360×480 | 55.6 | 0.36 | 297.6 |
| LEDNet[23] | 360×480 | 66.6 | 0.95 | 109.6 |
| DABNet[24] | 360×480 | 66.4 | 0.76 | — |
| DFANet[ | 720×960 | 64.7 | 7.80 | 120.0 |
| Network[26] | 720×960 | 68.0 | 6.20 | 39.3* |
| SwiftNet[27] | 720×960 | 63.3 | 11.80 | — |
| FPENet[28] | 360×480 | 65.4 | 0.40 | 77.1 |
| DALNet (ours) | 360×480 | 66.1 | 0.47 | 103.4 |
| DALNet (ours) | 720×960 | 70.1 | 0.47 | 54.4 |
| Method | Roa | Sid | Bui | Wal | Fen | Pol | TLi | TSi | Veg | Ter | Sky | Ped | Rid | Car | Tru | Bus | Tra | Mot | Bic | Class | Cat |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SegNet[ | 96.4 | 73.2 | 84.0 | 28.4 | 29.0 | 35.7 | 39.8 | 45.1 | 87.0 | 63.8 | 91.8 | 62.8 | 42.8 | 89.3 | 38.1 | 43.1 | 44.1 | 35.8 | 51.9 | 57.0 | 79.1 |
| ENet[ | 96.3 | 74.2 | 75.0 | 32.2 | 33.2 | 43.4 | 34.1 | 44.0 | 88.6 | 61.4 | 90.6 | 65.5 | 38.4 | 90.6 | 36.9 | 50.5 | 48.1 | 38.8 | 55.4 | 58.3 | 80.4 |
| CGNet[ | 95.5 | 78.7 | 88.1 | 40.0 | 43.0 | 54.1 | 59.8 | 63.9 | 89.6 | 67.6 | 92.9 | 74.9 | 54.9 | 90.2 | 44.1 | 59.5 | 25.2 | 47.3 | 60.2 | 64.8 | 85.7 |
| ERFNet[ | 97.2 | 80.0 | 89.5 | 41.6 | 45.3 | 56.4 | 60.5 | 64.6 | 91.4 | 68.7 | 94.2 | 76.1 | 56.4 | 92.4 | 45.7 | 60.6 | 27.0 | 48.7 | 61.8 | 66.3 | 85.2 |
| ESNet[ | 98.1 | 80.4 | 92.4 | 48.3 | 49.2 | 61.5 | 62.5 | 72.3 | 92.5 | 61.5 | 94.4 | 76.6 | 53.2 | 94.4 | 62.5 | 74.3 | 52.4 | 45.5 | 71.4 | 70.7 | 87.4 |
| EDANet[ | 97.8 | 80.6 | 89.5 | 42.0 | 46.0 | 52.3 | 59.8 | 65.0 | 91.4 | 68.7 | 93.6 | 75.7 | 54.3 | 92.4 | 40.9 | 58.7 | 56.0 | 50.2 | 64.0 | 67.3 | 85.8 |
| SQ[19] | 96.9 | 75.4 | 87.9 | 31.6 | 35.7 | 50.9 | 52.0 | 61.7 | 90.9 | 65.8 | 93.0 | 73.8 | 42.6 | 91.5 | 18.8 | 41.2 | 33.3 | 34.0 | 59.9 | 59.8 | 84.3 |
| ESPNet[ | 97.0 | 77.5 | 76.2 | 35.0 | 36.1 | 45.0 | 35.6 | 46.3 | 90.8 | 63.2 | 92.6 | 67.0 | 40.9 | 92.3 | 38.1 | 52.5 | 50.1 | 41.8 | 57.2 | 60.3 | 82.2 |
| LEDNet[ | 98.1 | 79.5 | 91.6 | 47.7 | 49.9 | 62.8 | 61.3 | 72.8 | 92.6 | 61.2 | 94.9 | 76.2 | 53.7 | 90.9 | 64.4 | 64.0 | 52.7 | 44.4 | 71.6 | 70.6 | 87.1 |
| DALNet-512(ours) | 98.0 | 82.8 | 91.1 | 49.5 | 51.0 | 60.0 | 64.0 | 69.7 | 92.4 | 69.3 | 94.7 | 81.1 | 59.4 | 94.0 | 57.1 | 66.8 | 49.2 | 50.8 | 69.0 | 71.1 | 88.2 |
| DALNet-1024(ours) | 98.2 | 83.7 | 91.9 | 54.4 | 53.8 | 62.3 | 67.8 | 72.0 | 92.8 | 70.1 | 95.1 | 82.8 | 63.9 | 94.7 | 62.8 | 75.4 | 60.7 | 55.8 | 70.3 | 74.1 | 89.0 |
表5 Pre-class results of different models on Cityscapes test set 单位:%
Table 5
| Method | Roa | Sid | Bui | Wal | Fen | Pol | TLi | TSi | Veg | Ter | Sky | Ped | Rid | Car | Tru | Bus | Tra | Mot | Bic | Class | Cat |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SegNet[ | 96.4 | 73.2 | 84.0 | 28.4 | 29.0 | 35.7 | 39.8 | 45.1 | 87.0 | 63.8 | 91.8 | 62.8 | 42.8 | 89.3 | 38.1 | 43.1 | 44.1 | 35.8 | 51.9 | 57.0 | 79.1 |
| ENet[ | 96.3 | 74.2 | 75.0 | 32.2 | 33.2 | 43.4 | 34.1 | 44.0 | 88.6 | 61.4 | 90.6 | 65.5 | 38.4 | 90.6 | 36.9 | 50.5 | 48.1 | 38.8 | 55.4 | 58.3 | 80.4 |
| CGNet[ | 95.5 | 78.7 | 88.1 | 40.0 | 43.0 | 54.1 | 59.8 | 63.9 | 89.6 | 67.6 | 92.9 | 74.9 | 54.9 | 90.2 | 44.1 | 59.5 | 25.2 | 47.3 | 60.2 | 64.8 | 85.7 |
| ERFNet[ | 97.2 | 80.0 | 89.5 | 41.6 | 45.3 | 56.4 | 60.5 | 64.6 | 91.4 | 68.7 | 94.2 | 76.1 | 56.4 | 92.4 | 45.7 | 60.6 | 27.0 | 48.7 | 61.8 | 66.3 | 85.2 |
| ESNet[ | 98.1 | 80.4 | 92.4 | 48.3 | 49.2 | 61.5 | 62.5 | 72.3 | 92.5 | 61.5 | 94.4 | 76.6 | 53.2 | 94.4 | 62.5 | 74.3 | 52.4 | 45.5 | 71.4 | 70.7 | 87.4 |
| EDANet[ | 97.8 | 80.6 | 89.5 | 42.0 | 46.0 | 52.3 | 59.8 | 65.0 | 91.4 | 68.7 | 93.6 | 75.7 | 54.3 | 92.4 | 40.9 | 58.7 | 56.0 | 50.2 | 64.0 | 67.3 | 85.8 |
| SQ[19] | 96.9 | 75.4 | 87.9 | 31.6 | 35.7 | 50.9 | 52.0 | 61.7 | 90.9 | 65.8 | 93.0 | 73.8 | 42.6 | 91.5 | 18.8 | 41.2 | 33.3 | 34.0 | 59.9 | 59.8 | 84.3 |
| ESPNet[ | 97.0 | 77.5 | 76.2 | 35.0 | 36.1 | 45.0 | 35.6 | 46.3 | 90.8 | 63.2 | 92.6 | 67.0 | 40.9 | 92.3 | 38.1 | 52.5 | 50.1 | 41.8 | 57.2 | 60.3 | 82.2 |
| LEDNet[ | 98.1 | 79.5 | 91.6 | 47.7 | 49.9 | 62.8 | 61.3 | 72.8 | 92.6 | 61.2 | 94.9 | 76.2 | 53.7 | 90.9 | 64.4 | 64.0 | 52.7 | 44.4 | 71.6 | 70.6 | 87.1 |
| DALNet-512(ours) | 98.0 | 82.8 | 91.1 | 49.5 | 51.0 | 60.0 | 64.0 | 69.7 | 92.4 | 69.3 | 94.7 | 81.1 | 59.4 | 94.0 | 57.1 | 66.8 | 49.2 | 50.8 | 69.0 | 71.1 | 88.2 |
| DALNet-1024(ours) | 98.2 | 83.7 | 91.9 | 54.4 | 53.8 | 62.3 | 67.8 | 72.0 | 92.8 | 70.1 | 95.1 | 82.8 | 63.9 | 94.7 | 62.8 | 75.4 | 60.7 | 55.8 | 70.3 | 74.1 | 89.0 |

图5 不同模型的分割结果
Fig.5 Segmentation results of different models
| [1] | CHEN L C, ZHU Y, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]// LNCS 11211: Proceedings of the 15th European Conference on Computer Vision, Munich, Sep 8-14, 2018. Cham: Springer, 2018: 833-851. |
| [2] | ZHAO H S, SHI J P, QI X J, et al. Pyramid scene parsing network[C]// Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 6230-6239. |
| [3] |
马书浩, 安居白, 于博. 改进DeepLabv2的实时图像语义分割算法[J]. 计算机工程与应用, 2020, 56(18): 157-164.
DOI |
|
MA S H, AN J B, YU B. Improved DeepLabv2 real-time image semantic segmentation algorithm[J]. Computer Engineering and Applications, 2020, 56(18): 157-164.
DOI |
|
| [4] |
兰天翔, 向子彧, 刘名果, 等. 融合U-Net及MobileNet-V2的快速语义分割网络[J]. 计算机工程与应用, 2021, 57(17): 175-180.
DOI |
|
LAN T X, XIANG Z Y, LIU M G, et al. Quick semantic segmentation network based on U-Net and MobileNet-V2[J]. Computer Engineering and Applications, 2021, 57(17): 175-180.
DOI |
|
| [5] |
马宇, 张丽果, 杜慧敏, 等. 卷积神经网络的交通标志语义分割[J]. 计算机科学与探索, 2021, 15(6): 1114-1121.
DOI |
|
MA Y, ZHANG L G, DU H M, et al. Traffic sign semantic segmentation based on convolutional neural network[J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(6): 1114-1121.
DOI |
|
| [6] | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[J]. arXiv:1409. 1556, 2014. |
| [7] | HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]// Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 770-778. |
| [8] | CHOLLET F. Xception: deep learning with depthwise separable convolutions[C]// Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 1800-1807. |
| [9] |
BADRINARAYANAN V, KENDALL A, CIPOLLA R. SegNet: a deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2481-2495.
DOI PMID |
| [10] | ZHAO H, QI X, SHEN X, et al. ICNet for real-time semantic segmentation on high-resolution images[C]// LNCS 11207: Proceedings of the 15th European Conference on Computer Vision, Munich, Sep 8-14, 2018. Cham: Springer, 2018: 418- 434. |
| [11] | MAZZINI D. Guided upsampling network for real-time semantic segmentation[J]. arXiv:1807.07466, 2018. |
| [12] | PASZKE A, CHAURASIA A, KIM S, et al. ENet: a deep neural network architecture for real-time semantic segmentation[J]. arXiv:1606.02147, 2016. |
| [13] |
WU T, TANG S, ZHANG R, et al. CGNet: a light-weight context guided network for semantic segmentation[J]. IEEE Transactions on Image Processing, 2021, 30: 1169-1179.
DOI PMID |
| [14] |
ROMERA E, ALVAREZ J M, BERGASA L M, et al. ERFNet: efficient residual factorized convnet for real-time semantic segmentation[J]. IEEE Transactions on Intelligent Transportation Systems, 2017, 19(1): 263-272.
DOI URL |
| [15] | WANG Y, ZHOU Q, XIONG J, et al. ESNet:an efficient symmetric network for real-time semantic segmentation[C]// LNCS 11858: Proceedings of the 2nd Chinese Conference on Pattern Recognition and Computer Vision, Xi’an, Nov 8-11, 2019. Cham: Springer, 2019: 41-52. |
| [16] | LO S Y, HANG H M, CHAN S W, et al. Efficient dense modules of asymmetric convolution for real-time semantic segmentation[C]// Proceedings of the ACM Multimedia Asia, Beijing, Dec 16-18, 2019. New York: ACM, 2019: 1-6. |
| [17] | CORDTS M, OMRAN M, RAMOS S, et al. The cityscapes dataset for semantic urban scene understanding[C]// Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 3213-3223. |
| [18] |
BROSTOW G J, FAUQUEUR J, CIPOLLA R. Semantic object classes in video: a high-definition ground truth database[J]. Pattern Recognition Letters, 2009, 30(2): 88-97.
DOI URL |
| [19] | TREML M, ARJONA-MEDINA J, UNTERTHINER T, et al. Speeding up semantic segmentation for autonomous driving[C]// Proceedings of the 29th Conference on Neural Information Processing Systems. Red Hook: Curran Associates, 2016: 1-7. |
| [20] | MEHTA S, RASTEGARI M, CASPI A, et al. ESPNet: efficient spatial pyramid of dilated convolutions for semantic segmentation[C]// LNCS 11214: Proceedings of the 15th European Conference on Computer Vision, Munich, Sep 8-14, 2018. Cham: Springer, 2018: 561-580. |
| [21] | POUDEL R P, BONDE U, LIWICKI S, et al. ContextNet: exploring context and detail for semantic segmentation in real-time[J]. arXiv:1805.04554, 2018. |
| [22] | POUDEL R P K, LIWICKI S, CIPOLLA R. Fast-SCNN: fast semantic segmentation network[J]. arXiv:1902.04502, 2019. |
| [23] | WANG Y, ZHOU Q, LIU J, et al. LEDNet: a lightweight encoder-decoder network for real-time semantic segmentation[C]// Proceedings of the 29th IEEE International Conference on Image Processing, Taipei, China, Sep 22-25, 2019. Piscataway: IEEE, 2019: 1860-1864. |
| [24] | LI G, YUN I, KIM J, et al. DABNet: depth-wise asymmetric bottleneck for real-time semantic segmentation[J]. arXiv:1907.11357, 2019. |
| [25] | LI H, XIONG P, FAN H, et al. DFANet: deep feature aggregation for real-time semantic segmentation[C]// Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, Jun 16-20, 2019. Piscataway: IEEE, 2019: 9522-9531. |
| [26] |
DONG G, YAN Y, SHEN C, et al. Real-time high-performance semantic image segmentation of urban street scenes[J]. IEEE Transactions on Intelligent Transportation Systems, 2020, 22(6): 3258-3274.
DOI URL |
| [27] | ORSIC M, KRESO I, BEVANDIC P, et al. In defense of pre-trained ImageNet architectures for real-time semantic segmentation of road-driving images[C]// Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, Jun 16-20, 2019. Piscataway: IEEE, 2019: 12607-12616. |
| [28] | LIU M, YIN H. Feature pyramid encoding network for real-time semantic segmentation[J]. arXiv:1909.08599, 2019. |
| [1] | 李运寰, 闻继伟, 彭力. 高帧率的轻量级孪生网络目标跟踪[J]. 计算机科学与探索, 2022, 16(6): 1405-1416. |
| [2] | 李宽宽, 刘立波. 双线性聚合残差注意力的细粒度图像分类模型[J]. 计算机科学与探索, 2022, 16(4): 938-949. |
| [3] | 李杰. 结合注意力和纹理特征增强的行人再识别[J]. 计算机科学与探索, 2022, 16(3): 661-668. |
| [4] | 李文涛, 彭力. 多尺度通道注意力融合网络的小目标检测算法[J]. 计算机科学与探索, 2021, 15(12): 2390-2400. |
| [5] | 孟宪法, 刘方, 李广, 黄萌萌. 卷积神经网络压缩中的知识蒸馏技术综述[J]. 计算机科学与探索, 2021, 15(10): 1812-1829. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||