
计算机科学与探索 ›› 2022, Vol. 16 ›› Issue (11): 2487-2504.DOI: 10.3778/j.issn.1673-9418.2204089
胡康1,2, 奚雪峰1,2,3,+( ), 崔志明1,2,3, 周悦尧1,2, 仇亚进1,2
), 崔志明1,2,3, 周悦尧1,2, 仇亚进1,2
收稿日期:2022-04-06
修回日期:2022-05-30
出版日期:2022-11-01
发布日期:2022-11-16
通讯作者:
+ E-mail: xfxi2009@qq.com作者简介:胡康(1998—),男,四川泸州人,硕士研究生,主要研究方向为自然语言处理、文本生成。基金资助:
HU Kang1,2, XI Xuefeng1,2,3,+(), CUI Zhiming1,2,3, ZHOU Yueyao1,2, QIU Yajin1,2
Received:2022-04-06
Revised:2022-05-30
Online:2022-11-01
Published:2022-11-16
About author:HU Kang, born in 1998, M.S. candidate. His research interests include natural language processing and text generation.Supported by:摘要:
文本生成是自然语言处理的热门领域,随着信息收集能力的不断增长,人们收集到越来越多的结构化数据,如表格。如何解决信息过载问题,理解表格含义并描述表格内容是人工智能面临的重要问题,因此有了表格到文本生成任务。表格到文本生成是指语言模型输入表格数据后生成表格的对应文本描述。模型生成的文本描述应该语句流畅,充分表达表格信息且不能偏离表格事实。描述了表格到文本生成任务背景并做出了详细定义,分析了当前任务主要难点并介绍了主流研究方法。表格到文本生成共有两大问题:描述什么,如何描述。梳理了不同研究人员针对这两大问题所提出的解决方法,同时总结了所提出模型的特点、优势以及劣势。对比分析了这些优秀模型在主流数据集上的表现,同时根据模型类型进行归类,并进行横向比较分析。介绍了表格到文本生成领域较为通用的评价方法,总结了不同评价方法的特点、优势以及劣势。最后展望了表格到文本生成任务未来发展趋势。
中图分类号:
胡康, 奚雪峰, 崔志明, 周悦尧, 仇亚进. 深度学习的表格到文本生成研究综述[J]. 计算机科学与探索, 2022, 16(11): 2487-2504.
HU Kang, XI Xuefeng, CUI Zhiming, ZHOU Yueyao, QIU Yajin. Survey of Deep Learning Table-to-Text Generation[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(11): 2487-2504.

图1 Wikibio数据集实例
Fig.1 Example of Wikibio dataset
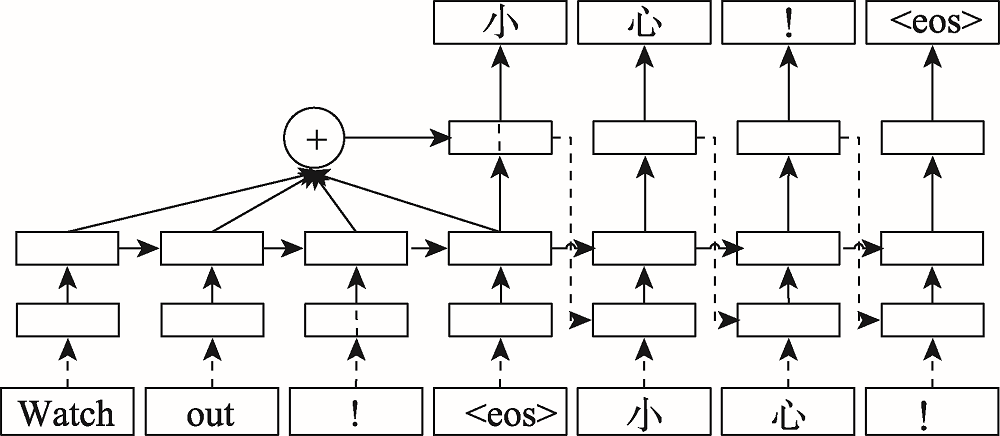
图2 带有注意力机制的序列到序列架构
Fig.2 Sequence-to-sequence architecture with attention mechanism

图3 LSTM结构
Fig.3 LSTM structure
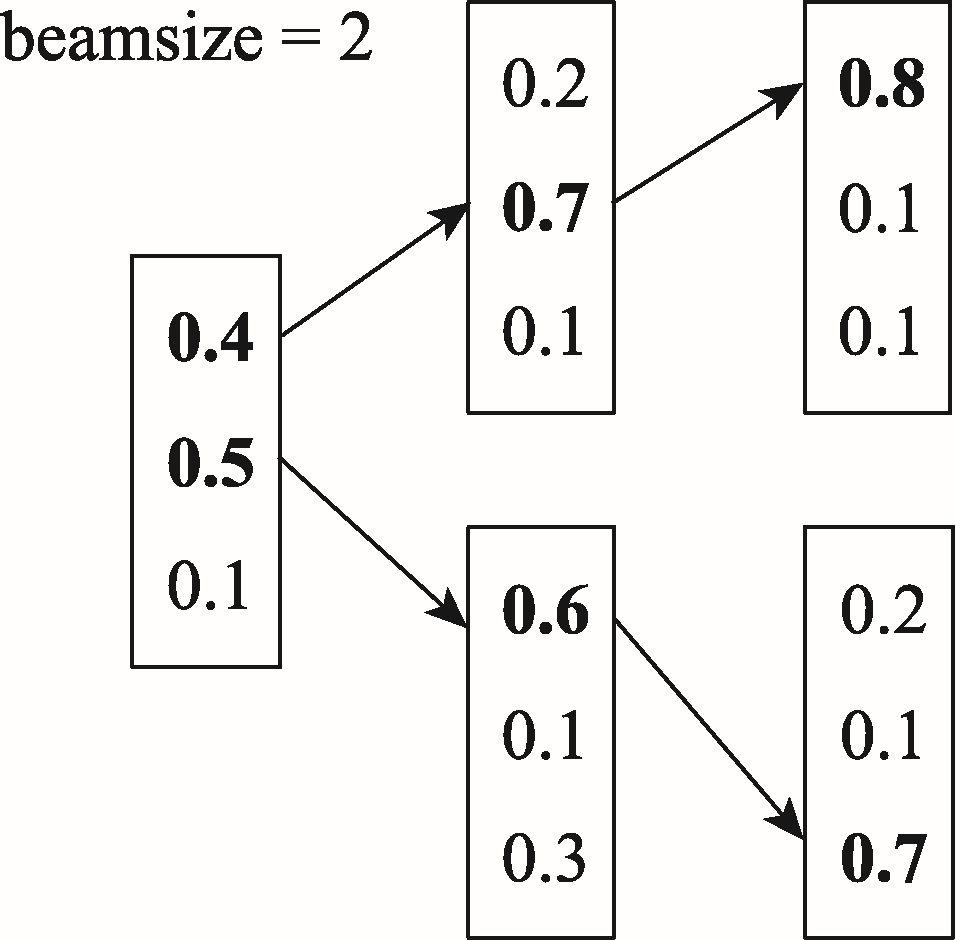
图4 集束搜索示例
Fig.4 Sample diagram of beam search

图5 表格结构感知模型
Fig.5 Table structure perception model
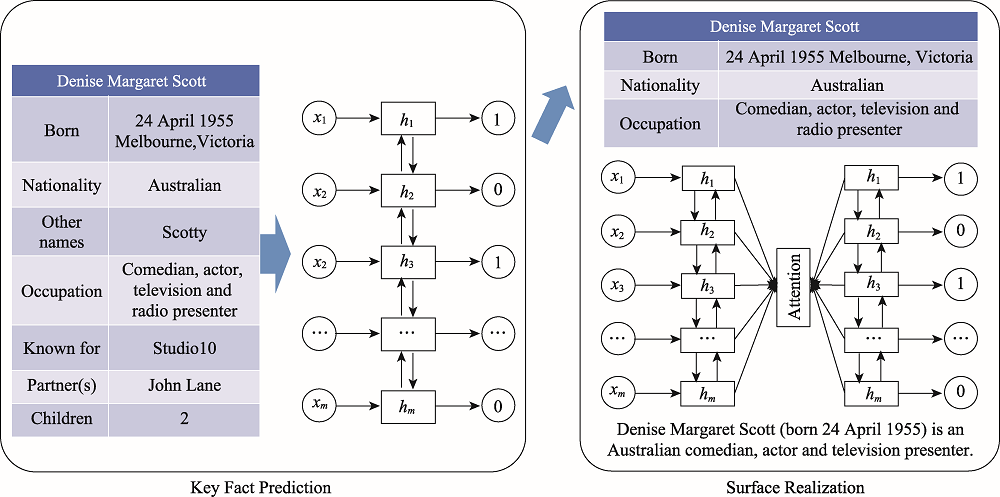
图6 以表格关键事实为中心模型
Fig.6 Model centered on table key facts
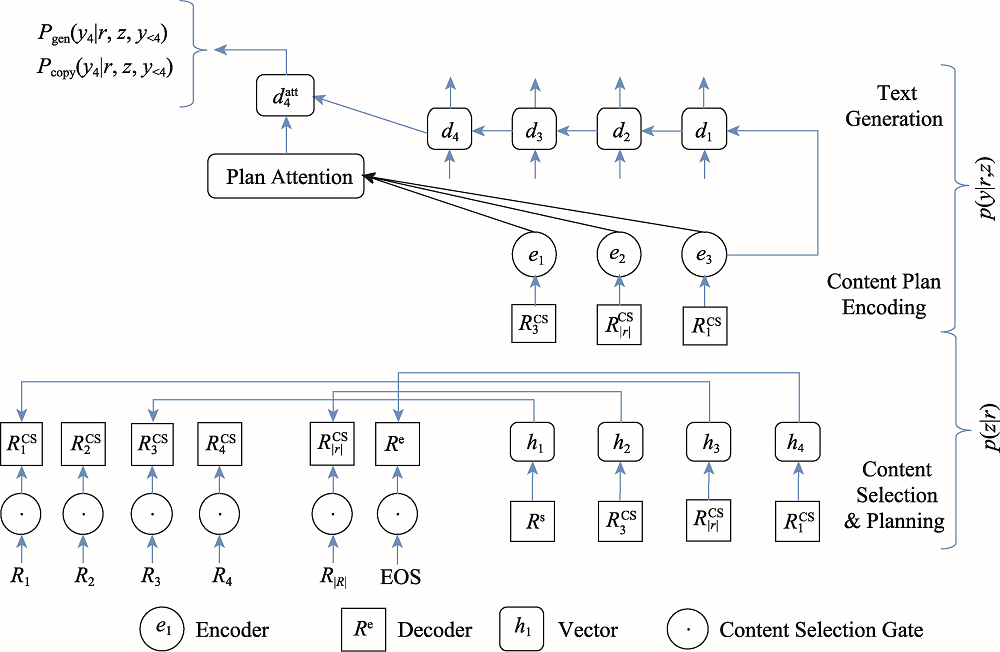
图7 表格内容选择与计划模型
Fig.7 Table content selection and planning model
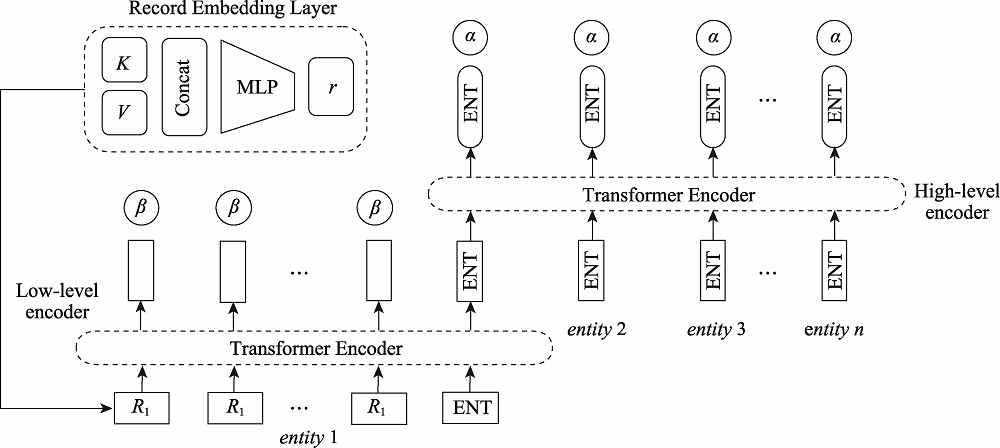
图8 表格内容层次编解码模型
Fig.8 Table content level encoding and decoding model
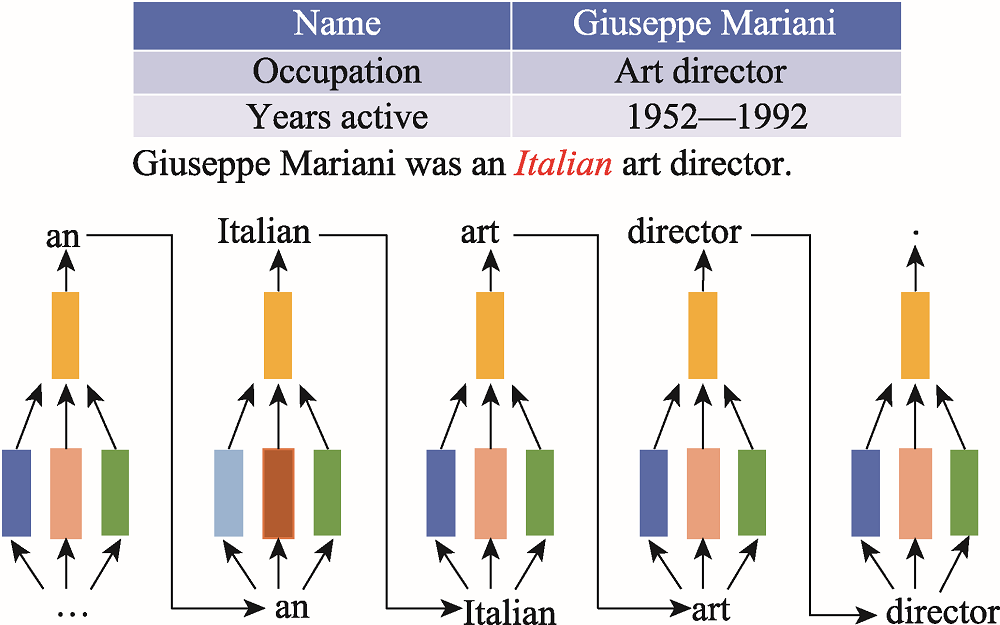
图9 多分支表格信息解码器模型
Fig.9 Multi-branch table information decoder model
| Model | BLEU | RG | CS | CO | |||
|---|---|---|---|---|---|---|---|
| Count | P/% | P/% | R/% | F/% | DLD/% | ||
| Gold Descriptions | 100.00 | 12.84 | 91.77 | 100.00 | 100.00 | 100.00 | 100.00 |
| Conditional Copy | 14.49 | 12.82 | 71.82 | 22.17 | 27.16 | 31.52 | 8.68 |
| NCP+CC | 16.50 | 34.28 | 87.47 | 34.18 | 51.22 | 41.00 | 18.58 |
| Macro | 15.46 | 42.10 | 97.60 | 34.10 | 57.80 | 42.90 | 17.70 |
| STG | 16.15 | 39.05 | 94.43 | 35.77 | 52.05 | 42.40 | 19.38 |
| Three Dimensions Encoder | 16.24 | 32.11 | 91.84 | 35.39 | 48.98 | 41.09 | 20.70 |
| Hierarchical Transformer | 17.50 | 21.17 | 89.46 | 39.47 | 51.64 | 44.70 | 18.90 |
表1 RotoWire实验结果
Table 1 Experiment results of RotoWire
| Model | BLEU | RG | CS | CO | |||
|---|---|---|---|---|---|---|---|
| Count | P/% | P/% | R/% | F/% | DLD/% | ||
| Gold Descriptions | 100.00 | 12.84 | 91.77 | 100.00 | 100.00 | 100.00 | 100.00 |
| Conditional Copy | 14.49 | 12.82 | 71.82 | 22.17 | 27.16 | 31.52 | 8.68 |
| NCP+CC | 16.50 | 34.28 | 87.47 | 34.18 | 51.22 | 41.00 | 18.58 |
| Macro | 15.46 | 42.10 | 97.60 | 34.10 | 57.80 | 42.90 | 17.70 |
| STG | 16.15 | 39.05 | 94.43 | 35.77 | 52.05 | 42.40 | 19.38 |
| Three Dimensions Encoder | 16.24 | 32.11 | 91.84 | 35.39 | 48.98 | 41.09 | 20.70 |
| Hierarchical Transformer | 17.50 | 21.17 | 89.46 | 39.47 | 51.64 | 44.70 | 18.90 |
| Model | BLEU | RG | CS | CO | |||
|---|---|---|---|---|---|---|---|
| Count | DLD/% | ||||||
| Puduppully-plan | 16.50 | 87.47 | 34.28 | 34.18 | 51.22 | 41.00 | 18.58 |
| Puduppully-update | 16.20 | 92.69 | 30.11 | 38.64 | 48.51 | 43.01 | 20.17 |
| Flat | 16.70 | 76.62 | 18.54 | 31.67 | 42.90 | 36.42 | 14.64 |
| Hierarchical Transformer-kv | 17.30 | 89.04 | 21.46 | 38.57 | 51.50 | 44.19 | 18.70 |
| Hierarchical Transformer-k | 17.50 | 89.46 | 21.17 | 39.47 | 51.64 | 44.70 | 18.90 |
| Hierarchical LSTM Encoder | 15.21 | 91.59 | 32.56 | 31.62 | 44.22 | 36.87 | 17.49 |
| Hierarchical CNN Encoder | 14.08 | 90.86 | 30.59 | 30.32 | 40.28 | 34.60 | 15.75 |
| Hierarchical SA Encoder | 15.62 | 90.46 | 29.82 | 34.39 | 45.43 | 39.15 | 19.81 |
| Hierarchical MHSA Encoder | 15.12 | 92.87 | 28.42 | 34.87 | 42.41 | 38.27 | 18.28 |
| Three Dimensions Encoder | 16.24 | 91.84 | 32.11 | 35.39 | 48.98 | 41.09 | 20.70 |
| Three Dimensions Encoder - row-level encoder | 15.32 | 90.19 | 27.90 | 34.70 | 42.53 | 38.22 | 20.02 |
| Three Dimensions Encoder - row | 15.50 | 91.08 | 30.95 | 35.03 | 47.09 | 40.17 | 20.03 |
| Three Dimensions Encoder - column | 15.59 | 91.66 | 28.63 | 34.83 | 43.62 | 38.73 | 19.59 |
| Three Dimensions Encoder - time | 16.10 | 90.94 | 31.43 | 34.62 | 47.74 | 40.13 | 19.81 |
| Three Dimensions Encoder - position embedding | 16.05 | 89.97 | 28.37 | 34.72 | 43.69 | 38.69 | 19.54 |
| Three Dimensions Encoder - record fusion gate | 14.97 | 89.34 | 32.22 | 32.28 | 46.68 | 38.17 | 18.49 |
表2 层次化模型实验结果对比
Table 2 Comparison of experiment results of hierarchical models
| Model | BLEU | RG | CS | CO | |||
|---|---|---|---|---|---|---|---|
| Count | DLD/% | ||||||
| Puduppully-plan | 16.50 | 87.47 | 34.28 | 34.18 | 51.22 | 41.00 | 18.58 |
| Puduppully-update | 16.20 | 92.69 | 30.11 | 38.64 | 48.51 | 43.01 | 20.17 |
| Flat | 16.70 | 76.62 | 18.54 | 31.67 | 42.90 | 36.42 | 14.64 |
| Hierarchical Transformer-kv | 17.30 | 89.04 | 21.46 | 38.57 | 51.50 | 44.19 | 18.70 |
| Hierarchical Transformer-k | 17.50 | 89.46 | 21.17 | 39.47 | 51.64 | 44.70 | 18.90 |
| Hierarchical LSTM Encoder | 15.21 | 91.59 | 32.56 | 31.62 | 44.22 | 36.87 | 17.49 |
| Hierarchical CNN Encoder | 14.08 | 90.86 | 30.59 | 30.32 | 40.28 | 34.60 | 15.75 |
| Hierarchical SA Encoder | 15.62 | 90.46 | 29.82 | 34.39 | 45.43 | 39.15 | 19.81 |
| Hierarchical MHSA Encoder | 15.12 | 92.87 | 28.42 | 34.87 | 42.41 | 38.27 | 18.28 |
| Three Dimensions Encoder | 16.24 | 91.84 | 32.11 | 35.39 | 48.98 | 41.09 | 20.70 |
| Three Dimensions Encoder - row-level encoder | 15.32 | 90.19 | 27.90 | 34.70 | 42.53 | 38.22 | 20.02 |
| Three Dimensions Encoder - row | 15.50 | 91.08 | 30.95 | 35.03 | 47.09 | 40.17 | 20.03 |
| Three Dimensions Encoder - column | 15.59 | 91.66 | 28.63 | 34.83 | 43.62 | 38.73 | 19.59 |
| Three Dimensions Encoder - time | 16.10 | 90.94 | 31.43 | 34.62 | 47.74 | 40.13 | 19.81 |
| Three Dimensions Encoder - position embedding | 16.05 | 89.97 | 28.37 | 34.72 | 43.69 | 38.69 | 19.54 |
| Three Dimensions Encoder - record fusion gate | 14.97 | 89.34 | 32.22 | 32.28 | 46.68 | 38.17 | 18.49 |
| Model | BLEU | RG | CS | CO | |||
|---|---|---|---|---|---|---|---|
| Count | DLD/% | ||||||
| TEMPL | 8.51 | 54.29 | 99.92 | 26.61 | 59.16 | — | 14.41 |
| ED+JC | 13.22 | 22.98 | 76.07 | 27.70 | 33.29 | — | 14.36 |
| ED+CC | 13.31 | 21.94 | 75.08 | 27.96 | 32.71 | — | 15.03 |
| NCP+JC | 14.92 | 33.37 | 87.40 | 32.20 | 48.56 | — | 17.98 |
| NCP+CC | 16.19 | 33.88 | 87.51 | 33.52 | 51.21 | — | 18.57 |
| Wiseman | 14.73 | 22.93 | 60.14 | 24.24 | 31.20 | 27.29 | 14.70 |
| Puduppully | 13.96 | 33.06 | 83.17 | 33.06 | 43.59 | 37.60 | 16.97 |
| STG | 16.15 | 39.05 | 94.43 | 35.77 | 52.05 | 42.40 | 19.38 |
| STG+w | 20.84 | 30.25 | 92.00 | 50.75 | 59.03 | 54.58 | 25.75 |
表3 内容选择模型实验结果对比
Table 3 Comparison of experiment results of content selection models
| Model | BLEU | RG | CS | CO | |||
|---|---|---|---|---|---|---|---|
| Count | DLD/% | ||||||
| TEMPL | 8.51 | 54.29 | 99.92 | 26.61 | 59.16 | — | 14.41 |
| ED+JC | 13.22 | 22.98 | 76.07 | 27.70 | 33.29 | — | 14.36 |
| ED+CC | 13.31 | 21.94 | 75.08 | 27.96 | 32.71 | — | 15.03 |
| NCP+JC | 14.92 | 33.37 | 87.40 | 32.20 | 48.56 | — | 17.98 |
| NCP+CC | 16.19 | 33.88 | 87.51 | 33.52 | 51.21 | — | 18.57 |
| Wiseman | 14.73 | 22.93 | 60.14 | 24.24 | 31.20 | 27.29 | 14.70 |
| Puduppully | 13.96 | 33.06 | 83.17 | 33.06 | 43.59 | 37.60 | 16.97 |
| STG | 16.15 | 39.05 | 94.43 | 35.77 | 52.05 | 42.40 | 19.38 |
| STG+w | 20.84 | 30.25 | 92.00 | 50.75 | 59.03 | 54.58 | 25.75 |
| Model | BLEU | ROUGE |
|---|---|---|
| Template | 19.80 | 10.70 |
| Table NLM | 34.70 | 25.80 |
| BAMGO | 42.03 | 39.11 |
| MBD | 41.56 | 25.80 |
| Structure-aware Seq2seq | 44.89 | 41.65 |
表4 Wikibio实验结果
Table 4 Experiment results of Wikibio
| Model | BLEU | ROUGE |
|---|---|---|
| Template | 19.80 | 10.70 |
| Table NLM | 34.70 | 25.80 |
| BAMGO | 42.03 | 39.11 |
| MBD | 41.56 | 25.80 |
| Structure-aware Seq2seq | 44.89 | 41.65 |
| Model | BLEU | PARNET | Halluc rate | Flesch | ||
|---|---|---|---|---|---|---|
| Gold | — | — | — | — | 23.82 | 53.80 |
| Stnd | 41.77 | 79.75 | 45.02 | 55.28 | 4.20 | 58.90 |
| Stnd_filtered | 34.66 | 80.90 | 42.48 | 53.27 | 0.74 | 62.10 |
| Hsmm | 35.17 | 71.72 | 39.84 | 48.32 | 7.98 | 58.60 |
| Hier | 45.14 | 79.80 | 46.02 | 54.65 | 10.10 | 56.20 |
| Hal | 36.50 | 79.00 | 40.50 | 51.70 | — | — |
| MBD | 41.56 | 79.00 | 46.40 | 56.16 | 1.43 | 58.80 |
表5 “幻觉”情况实验结果对比
Table 5 Comparison of experiment results of “hallucination”
| Model | BLEU | PARNET | Halluc rate | Flesch | ||
|---|---|---|---|---|---|---|
| Gold | — | — | — | — | 23.82 | 53.80 |
| Stnd | 41.77 | 79.75 | 45.02 | 55.28 | 4.20 | 58.90 |
| Stnd_filtered | 34.66 | 80.90 | 42.48 | 53.27 | 0.74 | 62.10 |
| Hsmm | 35.17 | 71.72 | 39.84 | 48.32 | 7.98 | 58.60 |
| Hier | 45.14 | 79.80 | 46.02 | 54.65 | 10.10 | 56.20 |
| Hal | 36.50 | 79.00 | 40.50 | 51.70 | — | — |
| MBD | 41.56 | 79.00 | 46.40 | 56.16 | 1.43 | 58.80 |
| [1] | GARBACEA C, MEI Q. Neural language generation: form-ulation, methods, and evaluation[J]. arXiv:2007.15780, 2020. |
| [2] | YU W, ZHU C, LI Z, et al. A survey of knowledge-enhanced text generation[J]. arXiv:2010.04389, 2020. |
| [3] | PASUPAT P, LIANG P. Compositional semantic parsing on semi-structured tables[C]// Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Lang-uage Processing of the Asian Federation of Natural Langu-age Processing, Beijing, Jul 26-31, 2015. Stroudsburg: ACL, 2015: 1470-1480. |
| [4] | SUN H, MA H, HE X, et al. Table cell search for question answering[C]// Proceedings of the 25th International Confe-rence on World Wide Web, Montréal, Apr 11-15, 2016. New York: ACM, 2016: 771-782. |
| [5] | YIN J, JIANG X, LU Z, et al. Neural generative question answering[C]// Proceedings of the 25th International Joint Conference on Artificial Intelligence, New York, Jul 9-15, 2016. Menlo Park: AAAI, 2016: 2972-2978. |
| [6] | JAUHAR S K, TURNEY P, HOVY E. Tables as semi-structured knowledge for question answering[C]// Proceed-ings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Aug 7-12, 2016. Strouds-burg: ACL, 2016: 474-483. |
| [7] |
KONSTAS I, LAPATA M. A global model for concept-to-text generation[J]. Journal of Artificial Intelligence Research, 2013, 48: 305-346.
DOI URL |
| [8] | LI J, MONROE W, RITTER A, et al. Deep reinforcement learning for dialogue generation[J]. arXiv:1606.01541, 2016. |
| [9] | YAN Z, DUAN N, BAO J, et al. DocChat: an information retrieval approach for chatbot engines using unstructured documents[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Aug 7-12, 2016. Stroudsburg: ACL, 2016: 516-525. |
| [10] | BAO J, TANG D, DUAN N, et al. Table-to-text: describing table region with natural language[J]. arXiv:1805.11234, 2018. |
| [11] | REBUFFEL C, SOULIER L, SCOUTHEETEN G, et al. A hierarchical model for data-to-text generation[C]// LNCS 12035: Proceedings of the 42nd European Conference on IR Research, Lisbon, Apr 14-17, 2020. Cham: Springer, 2020: 65-80. |
| [12] | WISEMAN S, SHIEBER S M, RUSH A M. Challenges in data-to-document generation[C]// Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, Jul 6-12, 2002. Stroudsburg: ACL, 2002: 2253-2263. |
| [13] | CHENG J P, DONG L, LAPATA M. Long short-term memory-networks for machine reading[C]// Proceedings of the 2016 Conference on Empirical Methods in Natural Lan-guage Processing, Austin, Nov 1-4, 2016. Stroudsburg: ACL, 2016: 551-561. |
| [14] | GRAVES A. Long short-term memory[M]// Supervised seq-uence labelling with recurrent neural networks. Berlin, Heidelberg: Springer, 2012: 37-45. |
| [15] | BAHDANAU D, CHO K, BENGIO Y. Neural machine translation by jointly learning to align and translate[J]. arXiv:1409.0473, 2014. |
| [16] | LUONG M T, PHAM H, MANNING C D. Effective approaches to attention-based neural machine translation[C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Sep 17-21, 2015. Stroudsburg: ACL, 2015: 1412-1421. |
| [17] | TAI K S, SOCHER R, MANNING C D. Improved sem-antic representations from tree-structured long short-term memory networks[C]// Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing of the Asian Federation of Natural Language Processing, Beijing, Jul 26-31, 2015. Stroudsburg: ACL, 2015: 1556-1566. |
| [18] | SEE A, LIU P J, MANNING C D. Get to the point: summarization with pointer-generator networks[C]// Procee-dings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, Jul 30-Aug 4, 2017. Stroudsburg: ACL, 2017: 1073-1083. |
| [19] | GÜLÇEHRE C, AHN S, NALLAPATI R, et al. Pointing the unknown words[C]// Proceedings of the 54th Annual Meet-ing of the Association for Computational Linguistics, Berlin, Aug 7-12, 2016. Stroudsburg: ACL, 2016: 1-10. |
| [20] | DEB K, KUMAR A. Light beam search based multi-objec-tive optimization using evolutionary algorithms[C]// Proce-edings of the 2007 IEEE Congress on Evolutionary Comput-ation, Singapore, Sep 25-28, 2007. Piscataway: IEEE, 2007: 2125-2132. |
| [21] |
MEISTER C, VIEIRA T, COTTERELL R. Best-first beam search[J]. Transactions of the Association for Computational Linguistics, 2020, 8: 795-809.
DOI URL |
| [22] | RAY S, DEB NATH A P, RAJ K, et al. The curious case of trusted IC provisioning in untrusted testing facilities[C]// Proceedings of the 2021 Great Lakes Symposium on VLSI, Jun 22-25, 2021. New York: ACM, 2021: 207-212. |
| [23] | KLEIN G, KIM Y, DENG Y T, et al. openNMT: open-source toolkit for neural machine translation[C]// Procee-dings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, Jul 30-Aug 4, 2017. Stroudsburg: ACL: 67-72. |
| [24] | GRAVES A, MOHAMED A R, HINTON G E. Speech recognition with deep recurrent neural networks[C]// Proc-eedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, May 26-31, 2013. Piscataway: IEEE, 2013: 6645-6649. |
| [25] | MENG F D, LU Z D, WANG M X, et al. Encoding source language with convolutional neural network for machine translation[C]// Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Proces-sing of the Asian Federation of Natural Language Processing, Beijing, Jul 26-31, 2015. Stroudsburg: ACL, 2015: 20-30. |
| [26] | GEHRING J, AULI M, GRANGIER D, et al. A convolu-tional encoder model for neural machine translation[C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, Jul 30-Aug 4, 2017. Stroudsburg: ACL, 2017: 123-135. |
| [27] | GU J T, LU Z D, LI H, et al. Incorporating copying mech-anism in sequence-to-sequence learning[C]// Proceedings of the 54th Annual Meeting of the Association for Compu-tational Linguistics, Berlin, Aug 7-12, 2016. Stroudsburg: ACL, 2016: 1631-1640. |
| [28] | VINYALS O, FORTUNATO M, JAITLY N. Pointer net-works[C]// Proceedings of the Annual Conference on Neural Information Processing Systems, Montreal, Dec 7-12, 2015. Red Hook: Curran Associates, 2015: 2692-2700. |
| [29] | HARGREAVES J, VLACHOS A, EMERSON G. Increm-ental beam manipulation for natural language generation[C]// Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics:Main Volume, Apr 19-23, 2021. Stroudsburg: ACL, 2021: 2563-2574. |
| [30] | LIU T, WANG K, SHA L, et al. Table-to-text generation by structure-aware seq2seq learning[J]. arXiv:1711.09724, 2017. |
| [31] | MA S M, YANG P C, LIU T Y, et al. Key fact as Pivot: a two-stage model for low resource table-to-text generation[C]// Proceedings of the 57th Conference of the Association for Computational Linguistics, Florence, Jul 28-Aug 2, 2019. Stroudsburg: ACL, 2019: 2047-2057. |
| [32] | GONG H, FENG X, QIN B, et al. Table-to-text generation with effective hierarchical encoder on three dimensions (row, column and time)[C]// Proceedings of the 2019 Confe-rence on Empirical Methods in Natural Language Proces-sing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, Nov 3-7, 2019. Stroudsburg: ACL, 2019: 3143-3152. |
| [33] | PUDUPPULLY R, LI D, LAPATA M. Data-to-text gener-ation with content selection and planning[C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence, the 31st Innovative Applications of Artificial Intelligence Conf-erence, the 9th AAAI Symposium on Educational Advances in Artificial Intelligence, Honolulu, Jan 27-Feb 1, 2019. Menlo Park: AAAI, 2019: 6908-6915. |
| [34] |
ISO H, UEHARA Y, ISHIGAKI T, et al. Learning to select, track, and generate for data-to-text[J]. Journal of Natural Language Processing, 2020, 27(3): 599-626.
DOI URL |
| [35] | GONG H, SUN Y W, FENG X C, et al. TableGPT: few-shot table-to-text generation with table structure reconstruc-tion and content matching[C]// Proceedings of the 28th International Conference on Computational Linguistics,Barcelona, Dec 8-13, 2020. Praha: International Committee on Computational Linguistics, 2020: 1978-1988. |
| [36] | PAPINENI K, ROUKOS S, WARD T, et al. BLEU: a method for automatic evaluation of machine translation[C]// Procee-dings of the 40th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2002: 311-318. |
| [37] | LIU T Y, LUO F L, XIA Q L, et al. Hierarchical encoder with auxiliary supervision for neural table-to-text generation: learning better representation for tables[C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence, the 31st Innovative Applications of Artificial Intelligence Conf-erence, the 9th AAAI Symposium on Educational Advances in Artificial Intelligence, Honolulu, Jan 27-Feb 1, 2019. Menlo Park: AAAI, 2019: 6786-6793. |
| [38] | VINYALS O, BENGIO S, KUDLUR M. Order matters: sequence to sequence for sets[J]. arXiv:1511.06391, 2015. |
| [39] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the Annual Conference on Neural Information Processing Systems, Long Beach, Dec 4-9, 2017. Red Hook: Curran Associates, 2017: 5998-6008. |
| [40] | CHEN W, WANG H, CHEN J, et al. TabFact: a large-scale dataset for table-based fact verification[J]. arXiv:1909.02164, 2019. |
| [41] | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[J]. arXiv:1810.04805, 2018. |
| [42] | RADFORD A, WU J, CHILD R, et al. Language models are unsupervised multitask learners[J]. OpenAI Blog, 2019, 1(8): 9. |
| [43] | CHEN Z Y, EAVANI H, CHEN W H, et al. Few-shot NLG with pre-trained language model[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Ling-uistics, Jul 5-10, 2020. Stroudsburg: ACL, 2020: 183-190. |
| [44] | LEBRET R, GRANGIER D, AULI M. Neural text gener-ation from structured data with application to the biography domain[C]// Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, Nov 1-4, 2016. Stroudsburg: ACL, 2016: 1203-1213. |
| [45] | PEREZ-BELTRACHINI L, GARDENT C. Analysing data-to-text generation benchmarks[C]// Proceedings of the 10th International Conference on Natural Language Generation, Santiago de Compostela, Sep 4-7, 2017. Stroudsburg: ACL, 2017: 238-242. |
| [46] | DHINGRA B, FARUQUI M, PARIKH A, et al. Handling divergent reference texts when evaluating table-to-text gen-eration[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Jul 28-Aug 2, 2019. Stroudsburg: ACL, 2019: 4884-4895. |
| [47] |
REITER E, BELZ A. An investigation into the validity of some metrics for automatically evaluating natural language generation systems[J]. Computational Linguistics, 2009, 35(4): 529-558.
DOI URL |
| [48] |
REBUFFEL C, ROBERTI M, SOULIER L, et al. Controlling hallucinations at word level in data-to-text generation[J]. Data Mining and Knowledge Discovery, 2022, 36(1): 318-354.
DOI URL |
| [49] | LIN C Y. ROUGE: a package for automatic evaluation of summaries[C]// Proceedings of the Workshop on Text Summ-arization Branches out, Barcelona, Jul 2004. Stroudsburg: ACL, 2004: 74-81. |
| [50] | BRILL E, MOORE R C. An improved error model for noisy channel spelling correction[C]// Proceedings of the 38th Annual Meeting of the Association for Computational Linguistics, Hong Kong, China, Oct 1-8, 2000. Strouds-burg: ACL, 2000: 286-293. |
| [51] |
PUDUPPULLY R, LAPATA M. Data-to-text generation with macro planning[J]. Transactions of the Association for Computational Linguistics, 2021, 9: 510-527.
DOI URL |
| [1] | 李冬梅, 罗斯斯, 张小平, 许福. 命名实体识别方法研究综述[J]. 计算机科学与探索, 2022, 16(9): 1954-1968. |
| [2] | 韩毅, 乔林波, 李东升, 廖湘科. 知识增强型预训练语言模型综述[J]. 计算机科学与探索, 2022, 16(7): 1439-1461. |
| [3] | 夏鸿斌, 肖奕飞, 刘渊. 融合自注意力机制的长文本生成对抗网络模型[J]. 计算机科学与探索, 2022, 16(7): 1603-1610. |
| [4] | 陈共驰, 荣欢, 马廷淮. 面向连贯性强化的无真值依赖文本摘要模型[J]. 计算机科学与探索, 2022, 16(3): 621-636. |
| [5] | 陈德光, 马金林, 马自萍, 周洁. 自然语言处理预训练技术综述[J]. 计算机科学与探索, 2021, 15(8): 1359-1389. |
| [6] | 任建华, 李静, 孟祥福. 上下文感知与层级注意力网络的文档分类方法[J]. 计算机科学与探索, 2021, 15(2): 305-314. |
| [7] | 严春满, 王铖. 卷积神经网络模型发展及应用[J]. 计算机科学与探索, 2021, 15(1): 27-46. |
| [8] | 张秋韵,郭斌,郝少阳,王豪,於志文,景瑶. CrowdDepict:多源群智数据驱动的个性化商品描述生成方法[J]. 计算机科学与探索, 2020, 14(10): 1670-1680. |
| [9] | 唐爽,张灵箫,赵俊峰,谢冰,邹艳珍. 面向多源数据的可扩展主题建模分析框架[J]. 计算机科学与探索, 2019, 13(5): 742-752. |
| [10] | 黄磊,李寿山,王晶晶. 基于认证用户信息的微博用户类型识别方法[J]. 计算机科学与探索, 2015, 9(6): 719-725. |
| [11] | 周宁南,张 孝,孙新云,琚星星,刘奎呈,杜小勇,王 珊. MyBUD自适应分布式存储管理的设计与实现[J]. 计算机科学与探索, 2012, 6(8): 673-683. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||