
计算机科学与探索 ›› 2022, Vol. 16 ›› Issue (2): 261-279.DOI: 10.3778/j.issn.1673-9418.2107040
王扬, 陈智斌+( ), 吴兆蕊, 高远
), 吴兆蕊, 高远
收稿日期:2021-07-12
修回日期:2021-09-16
出版日期:2022-02-01
发布日期:2021-09-24
通讯作者:
+ E-mail: chenzhibin311@126.com作者简介:王扬(1997—),男,山东烟台人,硕士研究生,主要研究方向为组合最优化、强化学习、深度强化学习等。基金资助:
WANG Yang, CHEN Zhibin+(), WU Zhaorui, GAO Yuan
Received:2021-07-12
Revised:2021-09-16
Online:2022-02-01
Published:2021-09-24
About author:WANG Yang, born in 1997, M.S. candidate. His research interests include combinatorial optimization, reinforcement learning, deep reinforcement learning, etc.Supported by:摘要:
组合最优化问题(COP)的求解方法已经渗透到人工智能、运筹学等众多领域。随着数据规模的不断增大、问题更新速度的变快,运用传统方法求解COP问题在速度、精度、泛化能力等方面受到很大冲击。近年来,强化学习(RL)在无人驾驶、工业自动化等领域的广泛应用,显示出强大的决策力和学习能力,故而诸多研究者尝试使用RL求解COP问题,为求解此类问题提供了一种全新的方法。首先简要梳理常见的COP问题及其RL的基本原理;其次阐述RL求解COP问题的难点,分析RL应用于组合最优化(CO)领域的优势,对RL与COP问题结合的原理进行研究;然后总结近年来采用RL求解COP问题的理论方法和应用研究,对各类代表性研究所解决COP问题的关键要点、算法逻辑、优化效果进行对比分析,以突出RL模型的优越性,并对不同方法的局限性及其使用场景进行归纳总结;最后提出了四个RL求解COP问题的潜在研究方向。
中图分类号:
王扬, 陈智斌, 吴兆蕊, 高远. 强化学习求解组合最优化问题的研究综述[J]. 计算机科学与探索, 2022, 16(2): 261-279.
WANG Yang, CHEN Zhibin, WU Zhaorui, GAO Yuan. Review of Reinforcement Learning for Combinatorial Optimization Problem[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(2): 261-279.

图1 求解COP问题的两种思路
Fig.1 Two approaches to solving COP problem
| 研究方法 | 作者 | 年份 | 研究问题 | 模型和算法 | 优化效果 |
|---|---|---|---|---|---|
| 基于神经组合最优化模型的求解方法 | Bello等人[ | 2016年 | TSP+KP | PN+REINFORCE、A3C、 主动搜索算法 | TSP:优于文献[ KP:达到最优解 |
| Chen等人[ | 2019年 | CVRP+JSP+表达简化 | PN、NeuRewriter框架+ Q-AC | 20-VRP:达到最优解 JSP:优于OR-Tools、DeepRM | |
| Joshi等人[ | 2019年 | TSP | PN+GCN、波束搜索、采样、贪婪搜索 | 20,50,100-TSP:优于文献[ | |
| Li等人[ | 2021年 | CSP | PN+REINFORCE、MHA、自注意力机制 | 优于目前基于深度学习的方法,求解时间快于LS1、LS2算法(20倍) | |
| 基于动态输入的组合最优化模型的求解方法 | Nazari等人[ | 2018年 | TSP+VRP+CVRP+SVRP | REINFORCE+A3C+ Rollout+PN | 优化效果与文献[ |
| Emami等人[ | 2018年 | TSP+Matching+Sorting | RL框架+PN-AC、 SPG算法、AC | TSP:优于文献[ Matching:最优间隙可达0.003% | |
| Kool等人[ | 2018年 | TSP+OP+VRP+PCTSP | Transformer+Attention、 REINFORCE、Rollout | 20,50,100-TSP:优于文献[ 20,50,100-CVRP:接近Gurobi | |
| Oren等人[ | 2021年 | PMSP+CVRP | SOLO框架+MCTS、DQN | 优于OR-Tools、CPLEX,降低了在线求解的时间,减少解空间的搜索范围 | |
| 基于图结构模型的求解方法 | Dai等人[ | 2017年 | MVC+TSP+Max-cut+SCP | S2V-DQN框架+Q-学习、 贪婪算法 | MVC、TSP、Max-cut接近最优解,扩大求解范围,提高模型的泛化能力 |
| Abe等人[ | 2019年 | MVC+MC+Max-cut | CombOpt Zero框架+GNNs、MCTS | 优于文献[ | |
| Mittal等人[ | 2019年 | MF+MVC+MCP | GCOMB框架+GCN、DQN | MF:求解时间相比SOTA算法提高100倍 MVC、MCP:优于文献[ | |
| Drori等人[ | 2020年 | TSP+VRP+MST+SSP | Model-free RL框架、 GNNs+GAT、Attention | TSP:优于文献[ MST、SSP:求解时间快于文献[ | |
| Bresson等人[ | 2021年 | TSP | Transformer+MHA、BFS算法 | 优于Concorde、LKH3,TSP50最优间隙达到0.004%,TSP100最优间隙达到0.39% | |
| 基于强化学习结合传统算法的求解方法 | Deudon等人[ | 2018年 | TSP、VRP | Transformer+LKH3、 REINFORCE、MHA | 20,50,100-TSP:加入2-opt操作后,优于文献[ |
| Cappart等人[ | 2020年 | TSP+TSPTW+PORT | Transformer+GAT+PPO、BaB-DQN搜索算法 | 优于单个RL算法和CP算法,与Non-linear 求解器优化效果相当 | |
| Gao等人[ | 2020年 | VRP+CVRP+CVRPTW | GAT+AC、PPO、VLNS算法 | VRP:优于多个启发式算法 CVRP:最优间隙为0.58%,扩大求解范围 | |
| Zheng等人[ | 2020年 | TSP、111个TSP数据集 | VSR-LKH3框架+Q-学习、Sarsa、蒙特卡罗 | 结合3个RL算法,优于文献[ | |
| 基于改进强化学习模型的求解方法 | Silva等人[ | 2019年 | VRPTW+UPMS-ST | AMAM+Q-学习、ILS-LA、ILS-Q、VND | 优于其他传统算法和单智能体的优化效果 |
| Ma等人[ | 2019年 | TSP+TSPTW | GPNS+逐层策略优化算法、分层算法、2-opt | 优于OR-Tools和蚁群算法,GPN模型可以有效求解大范围TSP问题 | |
| Lu等人[ | 2020年 | CVRP | Transformer+Attention、 REINFORCE、Rollout | 100-CVRP:优于LKH3,达到目前最优的结果(15.57),求解速度超过OR-Tools | |
| Li等人[ | 2020年 | TSP、MOTSP | DRL-MOA框架+AC | 优于NSGA-Ⅱ、MOEA/D、MOGLS,相比传统算法有更快的求解速度和泛化能力 |
表1 研究方法、求解问题、模型算法的分析与总结
Table 1 Analysis and summary of research methods, solving problems and models
| 研究方法 | 作者 | 年份 | 研究问题 | 模型和算法 | 优化效果 |
|---|---|---|---|---|---|
| 基于神经组合最优化模型的求解方法 | Bello等人[ | 2016年 | TSP+KP | PN+REINFORCE、A3C、 主动搜索算法 | TSP:优于文献[ KP:达到最优解 |
| Chen等人[ | 2019年 | CVRP+JSP+表达简化 | PN、NeuRewriter框架+ Q-AC | 20-VRP:达到最优解 JSP:优于OR-Tools、DeepRM | |
| Joshi等人[ | 2019年 | TSP | PN+GCN、波束搜索、采样、贪婪搜索 | 20,50,100-TSP:优于文献[ | |
| Li等人[ | 2021年 | CSP | PN+REINFORCE、MHA、自注意力机制 | 优于目前基于深度学习的方法,求解时间快于LS1、LS2算法(20倍) | |
| 基于动态输入的组合最优化模型的求解方法 | Nazari等人[ | 2018年 | TSP+VRP+CVRP+SVRP | REINFORCE+A3C+ Rollout+PN | 优化效果与文献[ |
| Emami等人[ | 2018年 | TSP+Matching+Sorting | RL框架+PN-AC、 SPG算法、AC | TSP:优于文献[ Matching:最优间隙可达0.003% | |
| Kool等人[ | 2018年 | TSP+OP+VRP+PCTSP | Transformer+Attention、 REINFORCE、Rollout | 20,50,100-TSP:优于文献[ 20,50,100-CVRP:接近Gurobi | |
| Oren等人[ | 2021年 | PMSP+CVRP | SOLO框架+MCTS、DQN | 优于OR-Tools、CPLEX,降低了在线求解的时间,减少解空间的搜索范围 | |
| 基于图结构模型的求解方法 | Dai等人[ | 2017年 | MVC+TSP+Max-cut+SCP | S2V-DQN框架+Q-学习、 贪婪算法 | MVC、TSP、Max-cut接近最优解,扩大求解范围,提高模型的泛化能力 |
| Abe等人[ | 2019年 | MVC+MC+Max-cut | CombOpt Zero框架+GNNs、MCTS | 优于文献[ | |
| Mittal等人[ | 2019年 | MF+MVC+MCP | GCOMB框架+GCN、DQN | MF:求解时间相比SOTA算法提高100倍 MVC、MCP:优于文献[ | |
| Drori等人[ | 2020年 | TSP+VRP+MST+SSP | Model-free RL框架、 GNNs+GAT、Attention | TSP:优于文献[ MST、SSP:求解时间快于文献[ | |
| Bresson等人[ | 2021年 | TSP | Transformer+MHA、BFS算法 | 优于Concorde、LKH3,TSP50最优间隙达到0.004%,TSP100最优间隙达到0.39% | |
| 基于强化学习结合传统算法的求解方法 | Deudon等人[ | 2018年 | TSP、VRP | Transformer+LKH3、 REINFORCE、MHA | 20,50,100-TSP:加入2-opt操作后,优于文献[ |
| Cappart等人[ | 2020年 | TSP+TSPTW+PORT | Transformer+GAT+PPO、BaB-DQN搜索算法 | 优于单个RL算法和CP算法,与Non-linear 求解器优化效果相当 | |
| Gao等人[ | 2020年 | VRP+CVRP+CVRPTW | GAT+AC、PPO、VLNS算法 | VRP:优于多个启发式算法 CVRP:最优间隙为0.58%,扩大求解范围 | |
| Zheng等人[ | 2020年 | TSP、111个TSP数据集 | VSR-LKH3框架+Q-学习、Sarsa、蒙特卡罗 | 结合3个RL算法,优于文献[ | |
| 基于改进强化学习模型的求解方法 | Silva等人[ | 2019年 | VRPTW+UPMS-ST | AMAM+Q-学习、ILS-LA、ILS-Q、VND | 优于其他传统算法和单智能体的优化效果 |
| Ma等人[ | 2019年 | TSP+TSPTW | GPNS+逐层策略优化算法、分层算法、2-opt | 优于OR-Tools和蚁群算法,GPN模型可以有效求解大范围TSP问题 | |
| Lu等人[ | 2020年 | CVRP | Transformer+Attention、 REINFORCE、Rollout | 100-CVRP:优于LKH3,达到目前最优的结果(15.57),求解速度超过OR-Tools | |
| Li等人[ | 2020年 | TSP、MOTSP | DRL-MOA框架+AC | 优于NSGA-Ⅱ、MOEA/D、MOGLS,相比传统算法有更快的求解速度和泛化能力 |

图2 COP解决方案框架
Fig.2 COP solution framework
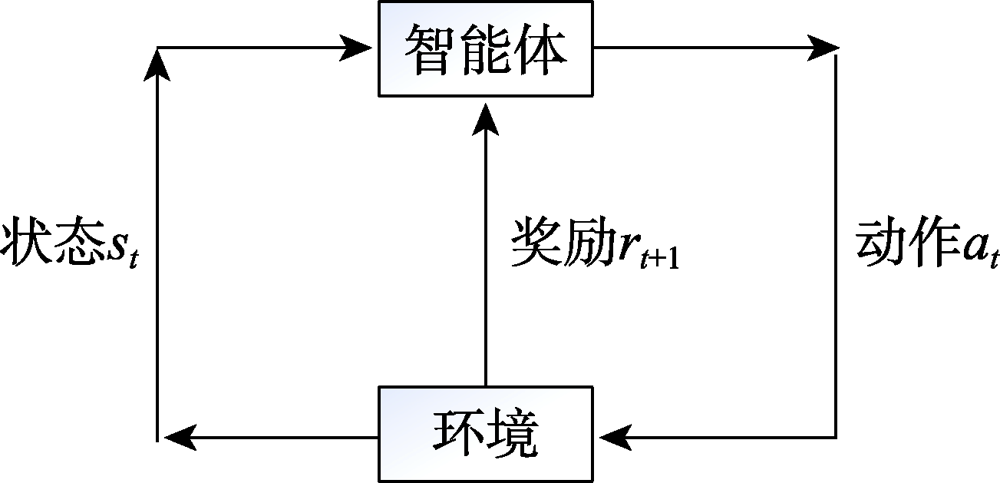
图3 强化学习简要模型
Fig.3 Brief model of reinforcement learning
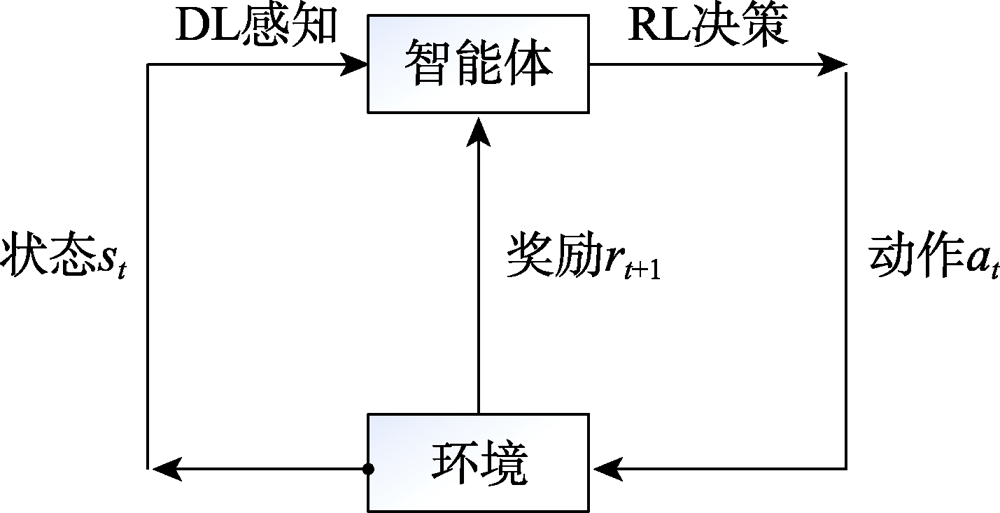
图4 深度强化学习简要模型
Fig.4 Brief model of deep reinforcement learning
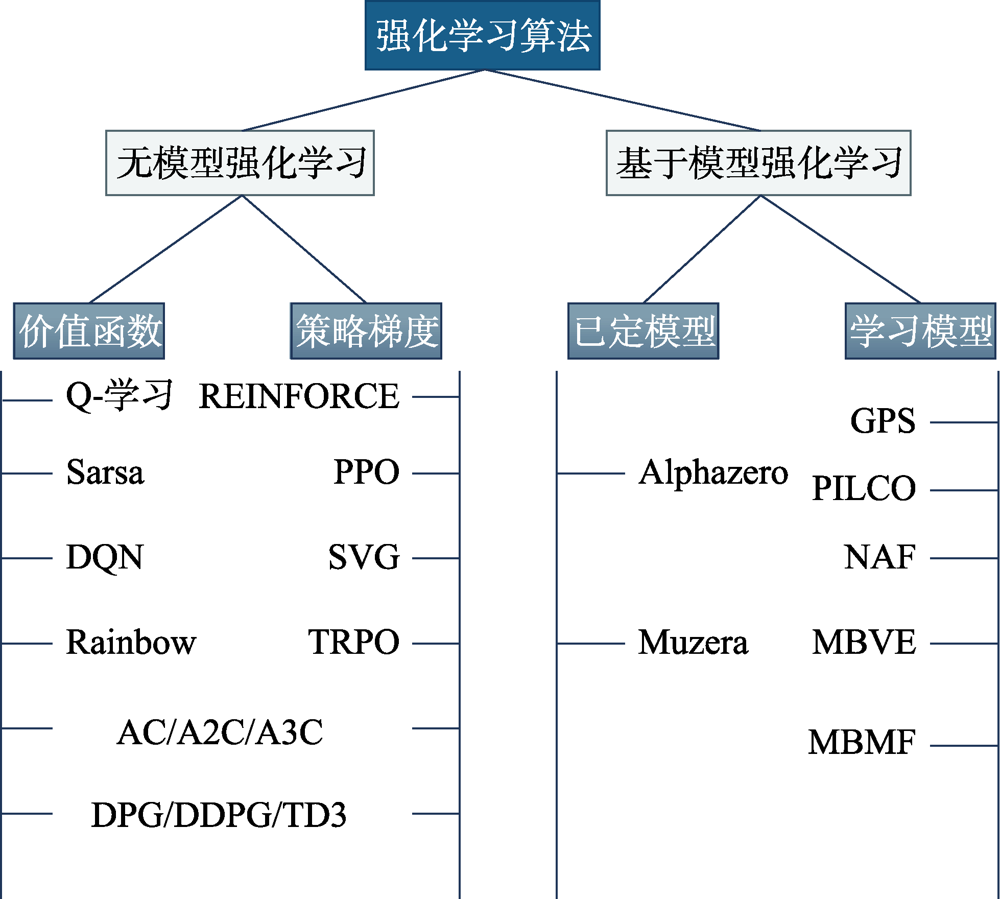
图5 强化学习主流算法
Fig.5 Mainstream reinforcement learning algorithms

图6 Pointer networks模型
Fig.6 Pointer networks model
| 作者 | 模型局限性分析 |
|---|---|
| Bello等人[ | 限于求解100个节点的TSP和200个物品的KP,输出解的质量较差,泛化能力差 |
| Chen等人[ | 限于求解100个节点的VRP,可以处理100 000 工件 |
| Joshi等人[ | 训练限于100个节点TSP的固定图,测试限于500个节点TSP的动态图 |
| Miki等人[ | 数据标签不易获得,依赖图片信息的质量,具有DNN网络的局限性 |
| Li等人[ | 限于求解300个节点的CSP,无法处理动态节点的输入 |
表2 NCO模型的局限性分析
Table 2 Limitation analysis of NCO model
| 作者 | 模型局限性分析 |
|---|---|
| Bello等人[ | 限于求解100个节点的TSP和200个物品的KP,输出解的质量较差,泛化能力差 |
| Chen等人[ | 限于求解100个节点的VRP,可以处理100 000 工件 |
| Joshi等人[ | 训练限于100个节点TSP的固定图,测试限于500个节点TSP的动态图 |
| Miki等人[ | 数据标签不易获得,依赖图片信息的质量,具有DNN网络的局限性 |
| Li等人[ | 限于求解300个节点的CSP,无法处理动态节点的输入 |
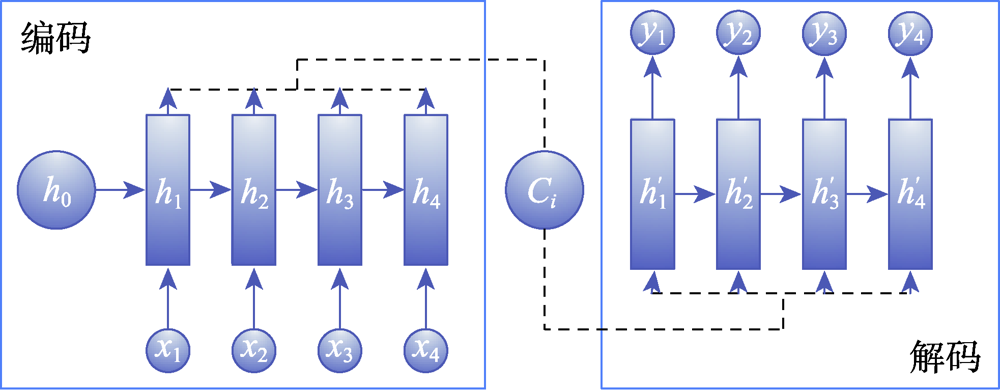
图7 Attention模型示意图
Fig.7 Schematic diagram of Attention model
| 作者 | 模型局限性分析 |
|---|---|
| Nazari等人[ | 限于求解100个节点的TSP和100个节点的VRP和CVRP |
| Kool等人[ | 限于求解100个节点的TSP、CVRP、OP、 SDVRP、PCTSP、SPCTSP,训练模型时间较慢,网络参数过多 |
| Emami等人[ | 限于求解50个节点的sorting、25个节点的MWM、20个节点的TSP,模型泛化能力差 |
| Oren等人[ | 限于求解100个节点的CVRP,求解PMSP限于80个工件集,线下算法收敛性差 |
| Bo等人[ | 限于求解100个节点的VRP,模型训练时间长(250 h) |
表3 动态输入模型的局限性分析
Table 3 Analysis of limitation of dynamic model
| 作者 | 模型局限性分析 |
|---|---|
| Nazari等人[ | 限于求解100个节点的TSP和100个节点的VRP和CVRP |
| Kool等人[ | 限于求解100个节点的TSP、CVRP、OP、 SDVRP、PCTSP、SPCTSP,训练模型时间较慢,网络参数过多 |
| Emami等人[ | 限于求解50个节点的sorting、25个节点的MWM、20个节点的TSP,模型泛化能力差 |
| Oren等人[ | 限于求解100个节点的CVRP,求解PMSP限于80个工件集,线下算法收敛性差 |
| Bo等人[ | 限于求解100个节点的VRP,模型训练时间长(250 h) |
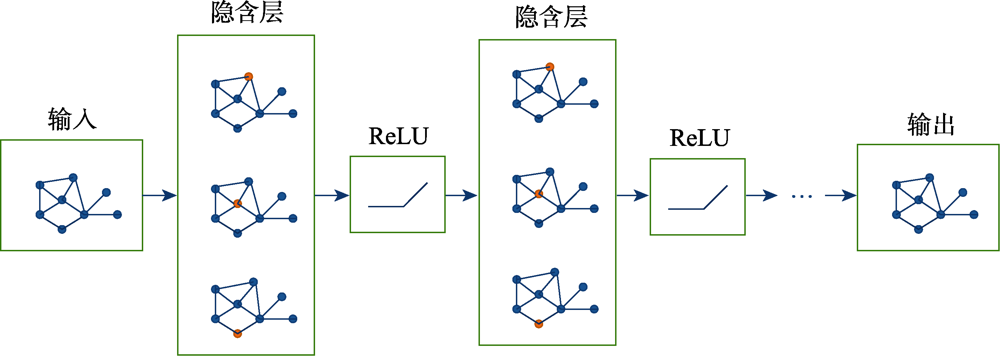
图8 GNNs模型示意图
Fig.8 Schematic diagram of GNNs model
| 作者 | 模型局限性分析 |
|---|---|
| Dai等人[ | 可泛化求解1 200个节点的MVC、Max-cut、TSP,范围增大的过程中,模型收敛性差 |
| Drori等人[ | 训练在100个节点,可泛化求解1 000节点的MST、SSP、TSP |
| Mittal等人[ | 训练在1 000个节点,可泛化求解2 000个节点的MF、MVC、MCP,模型训练时间较慢,完成后求解时间较快 |
| Barrett等人[ | 训练在200个节点,可泛化求解2 000个节点的Max-cut |
| Abe等人[ | 训练在200个节点,可求解任意人造数据集的Max-cut,模型难以反映问题的根本属性 |
| Bresson等人[ | 限于求解100个节点的TSP,无法判别模型构建的合理性 |
表4 图结构模型的局限性分析
Table 4 Limitation analysis of graph structure model
| 作者 | 模型局限性分析 |
|---|---|
| Dai等人[ | 可泛化求解1 200个节点的MVC、Max-cut、TSP,范围增大的过程中,模型收敛性差 |
| Drori等人[ | 训练在100个节点,可泛化求解1 000节点的MST、SSP、TSP |
| Mittal等人[ | 训练在1 000个节点,可泛化求解2 000个节点的MF、MVC、MCP,模型训练时间较慢,完成后求解时间较快 |
| Barrett等人[ | 训练在200个节点,可泛化求解2 000个节点的Max-cut |
| Abe等人[ | 训练在200个节点,可求解任意人造数据集的Max-cut,模型难以反映问题的根本属性 |
| Bresson等人[ | 限于求解100个节点的TSP,无法判别模型构建的合理性 |
| 作者 | 模型局限性分析 |
|---|---|
| Deudon等人[ | 限于求解100个节点的TSP,模型泛化能力和收敛性差,最优解可能是局部最优解 |
| Cappart等人[ | 限于求解100个节点的TSPTW,模型训练时间长,受CP的限制,模型泛化能力差 |
| Gao等人[ | 限于求解400个节点的CVRP、CVRPTW |
| Costa等人[ | 限于求解100个节点的TSP,模型训练时间较慢,求解速度优势不明显 |
| Zheng等人[ | 限于求解TSBLIB上111个对称TSP(达到1 000个节点) |
表5 RL结合传统算法模型的局限性分析
Table 5 Limitation analysis of RL combined with traditional algorithm model
| 作者 | 模型局限性分析 |
|---|---|
| Deudon等人[ | 限于求解100个节点的TSP,模型泛化能力和收敛性差,最优解可能是局部最优解 |
| Cappart等人[ | 限于求解100个节点的TSPTW,模型训练时间长,受CP的限制,模型泛化能力差 |
| Gao等人[ | 限于求解400个节点的CVRP、CVRPTW |
| Costa等人[ | 限于求解100个节点的TSP,模型训练时间较慢,求解速度优势不明显 |
| Zheng等人[ | 限于求解TSBLIB上111个对称TSP(达到1 000个节点) |
| 作者 | 模型局限性分析 |
|---|---|
| Lu等人[ | 限于求解100个节点的VRP,模型泛化能力差,初始解的随机性大,解的收敛性较差 |
| Li等人[ | 求解kroAB100/150/200数据集,限于求解200个节点的混合双目标TSP |
| Silva等人[ | 限于8个智能体协同工作,求解100个节点的CVRP,求解100个工件在25台机器加工,模型泛化能力差 |
| Tassel等人[ | 限于求解30个工件在20台机器加工,模型输出的解会陷入局部最优解,泛化能力差 |
| Ma等人[ | 限于求解1 000个节点的TSP、TSPW,模型训练时间较长 |
| Delarue等人[ | 限于求解78个节点的VRP、CVRP,解的最优性无法保证 |
表6 改进RL模型的局限性分析
Table 6 Limitation analysis of improved RL model
| 作者 | 模型局限性分析 |
|---|---|
| Lu等人[ | 限于求解100个节点的VRP,模型泛化能力差,初始解的随机性大,解的收敛性较差 |
| Li等人[ | 求解kroAB100/150/200数据集,限于求解200个节点的混合双目标TSP |
| Silva等人[ | 限于8个智能体协同工作,求解100个节点的CVRP,求解100个工件在25台机器加工,模型泛化能力差 |
| Tassel等人[ | 限于求解30个工件在20台机器加工,模型输出的解会陷入局部最优解,泛化能力差 |
| Ma等人[ | 限于求解1 000个节点的TSP、TSPW,模型训练时间较长 |
| Delarue等人[ | 限于求解78个节点的VRP、CVRP,解的最优性无法保证 |
| 模型 | 20-TSP | 50-TSP | 100-TSP | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 花费 | 间隙/% | 时间/s | 花费 | 间隙/% | 时间/s | 花费 | 间隙/% | 时间/s | |
| Concorde[ | 3.84 | 0.00 | 60 | 5.70 | 0.00 | 120 | 7.76 | 0.00 | 180 |
| LKH3[ | 3.84 | 0.00 | 18 | 5.70 | 0.00 | 300 | 7.76 | 0.00 | 1 260 |
| Gurobi[ | 3.84 | 0.00 | 7 | 5.70 | 0.00 | 120 | 7.76 | 0.00 | 1 020 |
| OR-Tools[ | 3.85 | 0.37 | 60 | 5.80 | 1.83 | 300 | 7.99 | 2.90 | 1 380 |
| Bello[ | 3.89 | 1.42 | — | 5.95 | 4.46 | — | 8.30 | 6.90 | — |
| Joshi(GS)[ | 3.86 | 0.60 | 6 | 5.87 | 3.10 | 55 | 8.41 | 8.38 | 180 |
| Joshi(BS)[ | 3.84 | 0.01 | 720 | 5.70 | 0.01 | 1 080 | 7.78 | 1.39 | 2 400 |
| Nazari[ | 3.97 | 3.27 | — | 6.08 | 6.25 | — | 8.44 | 7.93 | — |
| Kool(GS)[ | 3.85 | 0.34 | 1 | 5.80 | 1.76 | 2 | 8.12 | 4.53 | 6 |
| Dai[ | 3.89 | 1.42 | — | 5.99 | 5.16 | — | 8.31 | 7.03 | — |
| Bresson[ | 3.84 | 0.00 | 1 | 5.70 | 0.20 | 1 | 7.79 | 0.39 | 1 |
| Deudon[ | 3.84 | 0.09 | 360 | 5.75 | 1.00 | 1 920 | 8.12 | 4.46 | — |
| Costa[ | 3.84 | 0.00 | — | 5.71 | 0.12 | — | 7.83 | 0.87 | — |
表7 不同模型在TSP上的优化效果比较
Table 7 Comparison of optimization effects of different models on TSP
| 模型 | 20-TSP | 50-TSP | 100-TSP | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 花费 | 间隙/% | 时间/s | 花费 | 间隙/% | 时间/s | 花费 | 间隙/% | 时间/s | |
| Concorde[ | 3.84 | 0.00 | 60 | 5.70 | 0.00 | 120 | 7.76 | 0.00 | 180 |
| LKH3[ | 3.84 | 0.00 | 18 | 5.70 | 0.00 | 300 | 7.76 | 0.00 | 1 260 |
| Gurobi[ | 3.84 | 0.00 | 7 | 5.70 | 0.00 | 120 | 7.76 | 0.00 | 1 020 |
| OR-Tools[ | 3.85 | 0.37 | 60 | 5.80 | 1.83 | 300 | 7.99 | 2.90 | 1 380 |
| Bello[ | 3.89 | 1.42 | — | 5.95 | 4.46 | — | 8.30 | 6.90 | — |
| Joshi(GS)[ | 3.86 | 0.60 | 6 | 5.87 | 3.10 | 55 | 8.41 | 8.38 | 180 |
| Joshi(BS)[ | 3.84 | 0.01 | 720 | 5.70 | 0.01 | 1 080 | 7.78 | 1.39 | 2 400 |
| Nazari[ | 3.97 | 3.27 | — | 6.08 | 6.25 | — | 8.44 | 7.93 | — |
| Kool(GS)[ | 3.85 | 0.34 | 1 | 5.80 | 1.76 | 2 | 8.12 | 4.53 | 6 |
| Dai[ | 3.89 | 1.42 | — | 5.99 | 5.16 | — | 8.31 | 7.03 | — |
| Bresson[ | 3.84 | 0.00 | 1 | 5.70 | 0.20 | 1 | 7.79 | 0.39 | 1 |
| Deudon[ | 3.84 | 0.09 | 360 | 5.75 | 1.00 | 1 920 | 8.12 | 4.46 | — |
| Costa[ | 3.84 | 0.00 | — | 5.71 | 0.12 | — | 7.83 | 0.87 | — |
| 模型 | 20-VRP | 50-VRP | 100-VRP | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 花费 | 间隙/% | 时间/s | 花费 | 间隙/% | 时间/s | 花费 | 间隙/% | 时间/s | |
| LKH3[ | 6.12 | 0.00 | 7 200 | 10.38 | 0.00 | 25 200 | 15.65 | 0.00 | 46 800 |
| OR-Tools[ | 6.42 | 4.84 | 120 | 11.22 | 8.12 | 720 | 17.14 | 9.34 | 3 600 |
| Nazari[ | 6.40 | 4.39 | 1 620 | 11.15 | 7.46 | 2 340 | 16.96 | 8.39 | 4 440 |
| Kool(Sampling)[ | 6.25 | 2.49 | 360 | 10.62 | 2.40 | 1 680 | 16.23 | 3.72 | 7 200 |
| Kool(Greedy) [ | 6.40 | 4.97 | 1 | 10.98 | 5.86 | 3 | 16.80 | 7.34 | 8 |
| Bo(Greedy)[ | 6.28 | 2.95 | 1 | 10.78 | 3.85 | 1 | 16.40 | 4.79 | 3 |
| Chen[ | 6.12 | 0.48 | 1 320 | 10.51 | 1.25 | 2 100 | 16.10 | 2.88 | 3 960 |
| Lu[ | 6.12 | — | 720 | 10.35 | — | 1 020 | 15.57 | — | 1 400 |
表8 不同模型在VRP上的优化效果比较
Table 8 Comparison of optimization effects of different models on VRP
| 模型 | 20-VRP | 50-VRP | 100-VRP | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 花费 | 间隙/% | 时间/s | 花费 | 间隙/% | 时间/s | 花费 | 间隙/% | 时间/s | |
| LKH3[ | 6.12 | 0.00 | 7 200 | 10.38 | 0.00 | 25 200 | 15.65 | 0.00 | 46 800 |
| OR-Tools[ | 6.42 | 4.84 | 120 | 11.22 | 8.12 | 720 | 17.14 | 9.34 | 3 600 |
| Nazari[ | 6.40 | 4.39 | 1 620 | 11.15 | 7.46 | 2 340 | 16.96 | 8.39 | 4 440 |
| Kool(Sampling)[ | 6.25 | 2.49 | 360 | 10.62 | 2.40 | 1 680 | 16.23 | 3.72 | 7 200 |
| Kool(Greedy) [ | 6.40 | 4.97 | 1 | 10.98 | 5.86 | 3 | 16.80 | 7.34 | 8 |
| Bo(Greedy)[ | 6.28 | 2.95 | 1 | 10.78 | 3.85 | 1 | 16.40 | 4.79 | 3 |
| Chen[ | 6.12 | 0.48 | 1 320 | 10.51 | 1.25 | 2 100 | 16.10 | 2.88 | 3 960 |
| Lu[ | 6.12 | — | 720 | 10.35 | — | 1 020 | 15.57 | — | 1 400 |
| [1] | COOK W J, CUNNINGHAM W H, PULLEYBLANK W R, et al. Combinatorial optimization[M]. New York: John Wiley & Sons, Inc., 2010. |
| [2] |
SMIRNOV E A, TIMOSHENKO D M, ANDRIANOV S N. Comparison of regularization methods for ImageNet class-ification with deep convolutional neural networks[J]. AASRI Procedia, 2014, 6:89-94.
DOI URL |
| [3] | YOGATAMA D, BLUNSOM P, DYER C, et al. Learning to compose words into sentences with reinforcement learning[J]. arXiv:1611.09100, 2016. |
| [4] |
LIPPMANN R P. Review of neural networks for speech recognition[J]. Neural Computation, 2014, 1(1):1-38.
DOI URL |
| [5] | AKSHITA, SMITA. Recommender system: review[J]. Inter-national Journal of Computer Applications, 2013, 71(24):38-42. |
| [6] |
SILVER D, HUANG A, MADDISON C J, et al. Mastering the game of go with deep neural networks and tree search[J]. Nature, 2016, 529(7587):484-489.
DOI URL |
| [7] | 唐振韬, 邵坤, 赵冬斌, 等. 深度强化学习进展: 从AlphaGo到AlphaGo Zero[J]. 控制理论与应用, 2017, 34(12):1529-1546. |
| TANG Z T, SHAO K, ZHAO D B, et al. Recent progress of deep reinforcement learning: from AlphaGo to AlphaGo Zero[J]. Control Theory and Applications, 2017, 34(12):1529-1546. | |
| [8] | HU H Y, ZHANG X D, YAN X W, et al. Solving a new 3D bin packing problem with deep reinforcement learning method[J]. arXiv:1708.05930, 2017. |
| [9] | LIN K X, ZHAO R Y, XU Z, et al. Efficient large-scale fleet management via multi-agent deep reinforcement learn-ing[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, London, Aug 19-23, 2018. New York: ACM, 2018: 1774-1783. |
| [10] | MAO H, SCHWARZKOPF M, VENKATAKRISHNAN S B, et al. Learning scheduling algorithms for data processing clusters[C]//Proceedings of the ACM Special Interest Group on Data Communication, Beijing, Aug 19-23, 2019. New York: ACM, 2019: 270-288. |
| [11] | MIRHOSEINI A, GOLDIE A, YAZGAN M, et al. Chip placement with deep reinforcement learning[J]. arXiv: 2004.10746, 2020. |
| [12] | 刘全, 翟建伟, 章宗长, 等. 深度强化学习综述[J]. 计算机学报, 2018, 41(1):1-27. |
| LIU Q, ZHAI J W, ZHANG Z C, et al. A survey on deep reinforcement learning[J]. Chinese Journal of Computers, 2018, 41(1):1-27. | |
| [13] | 郭田德, 韩丛英, 唐思琦. 组合优化机器学习方法[M]. 北京: 科学出版社, 2019. |
| GUO T D, HAN C Y, TANG S Q. Machine learning methods for combinatorial optimization[M]. Beijing: Science Press, 2019. | |
| [14] | 刘振宏, 蔡茂诚. 组合最优化算法和复杂性[M]. 北京: 清华大学出版社, 1988. |
| LIU Z H, CAI M C. Combinatorial optimization algorithms and complexity[M]. Beijing: Tsinghua University Press, 1988. | |
| [15] | HELSGAUN K. An extension of the Lin-Kernighan-Helsgaun TSP solver for constrained traveling salesman and vehicle routing problems[D]. Roskilde: Roskilde University, 2017. |
| [16] | VAZIRANI V V. Approximation algorithms[M]. Berlin, Hei-delberg: Springer, 2013. |
| [17] |
LAWLER E L, WOOD D E. Branch-and-bound methods: a survey[J]. Operations Research, 1966, 14(4):699-719.
DOI URL |
| [18] | GUTIN G, YEO A. The greedy algorithm for the symmetric TSP[J]. Algorithmic Operations Research, 2007, 2(1):33-36. |
| [19] | KUMAR R, SINGH P K. Pareto evolutionary algorithm hybridized with local search for biobjective TSP[J]. Studies in Computational Intelligence, 2007, 75:361-398. |
| [20] |
HOCHBA D S. Approximation algorithms for NP-hard pro-blems[J]. SIGACT News, 1997, 28(2):40-52.
DOI URL |
| [21] |
KARIMI-MAMAGHAN M, MOHAMMADI M, MEYER P, et al. Machine learning at the service of meta-heuristics for solving combinatorial optimization problems: a state-of-the-art[J]. European Journal of Operational Research, 2021, 296(2):393-748.
DOI URL |
| [22] |
REZOUG A, BADER-EL-DEN M, BOUGHACI D. Guided genetic algorithm for the multidimensional knapsack problem[J]. Memetic Computing, 2018, 10(1):29-42.
DOI URL |
| [23] |
YU B, YANG Z Z, YAO B. An improved ant colony optimi-zation for vehicle routing problem[J]. European Journal of Operational Research, 2009, 196(1):171-176.
DOI URL |
| [24] | DU Z W, YANG Y J, SUN Y X, et al. An improved ant colony optimization algorithm for solving the TSP problem[J]. Applied Mechanics and Materials, 2010, 26- 28:620-624. |
| [25] | 林娟, 杜庆良, 杨辉, 等. 基于粒子群优化算法的并行模拟退火算法[J]. 计算机科学与探索, 2014, 8(7):886-896. |
| LIN J, DU Q L, YANG H, et al. Parallel simulated annealing algorithm based on particle swarm optimization algorithm[J]. Journal of Frontiers of Computer Science and Techno-logy, 2014, 8(7):886-896. | |
| [26] |
HOPFIELD J J, TANK D W. Neural computation of deci-sions in optimization problems[J]. Biological Cybernetics, 1985, 52(3):141-152.
DOI URL |
| [27] |
SMITH K A. Neural networks for combinatorial optimi-zation: a review of more than a decade of research[J]. INFORMS Journal on Computing, 1999, 11(11):15-34.
DOI URL |
| [28] | VINYALS O, FORTUNATO M, JAITLY N. Pointer net-works[J]. arXiv:1506.03134, 2015. |
| [29] | SUTSKEVER I, VINYALS O, LE Q V. Sequence to sequ-ence learning with neural networks[C]//Proceedings of the 27th International Conference on Neural Information Pro-cessing Systems, Montreal, Dec 8-13, 2014. Cambridge: MIT Press, 2014: 3104-3112. |
| [30] | BAHDANAU D, CHO K, BENGIO Y. Neural machine tran-slation by jointly learning to align and translate[J]. arXiv:1409.0473, 2014. |
| [31] | ZHANG W, DIETTERICH T G. A reinforcement learning approach to job-shop scheduling[C]//Proceedings of the 14th International Joint Conference on Artificial Intelligence, Montreal, Aug 20-25, 1995. San Francisco: Morgan Kauf-mann Publishers Inc., 1995: 1114-1120. |
| [32] | BELLO I, PHAM H, LE Q V, et al. Neural combinatorial optimization with reinforcement learning[J]. arXiv:1611. 09940, 2016. |
| [33] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, Dec 4-9, 2017. Red Hook: Curran Associates, 2017: 6000-6010. |
| [34] |
SCARSELLI F, GORI M, TSOI A C, et al. The graph neural network model[J]. IEEE Transactions on Neural Networks, 2008, 20(1):61-80.
DOI URL |
| [35] | NOWAK A, VILLAR S, BANDEIRA A S, et al. A note on learning algorithms for quadratic assignment with graph neural networks[J]. arXiv:1706.07450, 2017. |
| [36] | GASSE M, CHÉTELAT D, FERRONI N, et al. Exact com-binatorial optimization with graph convolutional neural net-works[J]. arXiv:1906.01629, 2019. |
| [37] | LI Z W, CHEN Q F, KOLTUN V. Combinatorial optimiza-tion with graph convolutional networks and guided tree search[J]. arXiv:1810.10659, 2018. |
| [38] | FRANÇOIS A, CAPPART Q, ROUSSEAU L M. How to evaluate machine learning approaches for combinatorial optimization: application to the travelling salesman problem[J]. arXiv:1909.13121, 2019. |
| [39] |
LIBERTO G D, KADIOGLU S, LEO K, et al. DASH: dyn-amic approach for switching heuristics[J]. European Journal of Operational Research, 2016, 248(3):943-953.
DOI URL |
| [40] | HE H, DAUME III H, EISNER J M. Learning to search in branch and bound algorithms[C]//Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, Dec 8-13, 2014. Cambridge: MIT Press, 2014: 3293-3301. |
| [41] |
BENGIO Y, LODI A, PROUVOST A. Machine learning for combinatorial optimization: a methodological tour d’horizon[J]. European Journal of Operational Research, 2021, 290(2):405-421.
DOI URL |
| [42] | SUTTON R, BARTO A. Reinforcement learning: an intro-duction[M]. Cambridge: MIT Press, 1998. |
| [43] | WILLIAMS R J. Simple statistical gradient-following algor-ithms for connectionist reinforcement learning[J]. Machine Learning, 1992, 8(3):229-256. |
| [44] | MNIH V, KAVUKCUOGLU K, SILVER D, et al. Playing Atari with deep reinforcement learning[J]. arXiv:1312.5602, 2013. |
| [45] |
MNIH V, KAVUKCUOGLU K, SILVER D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518:529-533.
DOI URL |
| [46] | LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[J]. arXiv:1509.02971, 2015. |
| [47] | HASSELT H V, GUEZ A, SILVER D. Deep reinforcement learning with double Q-learning[J]. arXiv:1509.06461, 2015. |
| [48] | SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[J]. arXiv:1707.06347, 2017. |
| [49] | HAARNOJA T, ZHOU A, ABBEEL P, et al. Soft actor-critic: off-policy maximum entropy deep reinforcement learning with a stochastic actor[J]. arXiv:1801.01290, 2018. |
| [50] | PATHAK D, AGRAWAL P, EFROS A A, et al. Curiosity-driven exploration by self-supervised prediction[C]//Proceed-ings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 488-489. |
| [51] | LI Y. Deep reinforcement learning: an overview[J]. arXiv:1701.07274, 2017. |
| [52] |
ALIPOUR M M, RAZAVI S N, DERAKHSHI M F, et al. A hybrid algorithm using a genetic algorithm and multiagent reinforcement learning heuristic to solve the traveling sale-sman problem[J]. Neural Computing and Applications, 2018, 30(9):2935-2951.
DOI URL |
| [53] | FAIREE S, KHOMPATRAPORN C, PROM-ON S, et al. Combinatorial artificial bee colony optimization with rein-forcement learning updating for travelling salesman problem[C]//Proceedings of the 2019 16th International Conference on Electrical Engineering/Electronics, Computer, Telecom-munications and Information Technology, Pattaya, Jul 10-13, 2019. Piscataway: IEEE, 2019: 93-96. |
| [54] | HU Y J, YAO Y, LEE W S. A reinforcement learning approach for optimizing multiple traveling salesman problems over graphs[J]. Knowledge-Based Systems, 2020, 204:106244. |
| [55] | YAO F, CAI R Q, WANG H N. Reversible action design for combinatorial optimization with reinforcement learning[J]. arXiv:2102.07210, 2021. |
| [56] | CHRISTOFIDES N. Worst-case analysis of a new heuristic for the travelling salesman problem[D]. Pittsburgh:Carnegie-Mellon University, 1976. |
| [57] | CHEN X Y, TIAN Y D. Learning to perform local rewriting for combinatorial optimization[C]//Proceedings of the 33rd Conference on Advances in Neural Information Processing Systems, Vancouver, Dec 8-14, 2019. Red Hook: Curran Associates, 2019: 6281-6292. |
| [58] | JOSHI C K, LAURENT T, BRESSON X. On learning par-adigms for the travelling salesman problem[J]. arXiv:1910. 07210, 2019. |
| [59] | JOSHI C K, CAPPART Q, ROUSSEAU L M, et al. Learn-ing TSP requires rethinking generalization[J]. arXiv:2006. 07054, 2020. |
| [60] | MIKI S, EBARA H. Solving traveling salesman problem with image-based classification[C]//Proceedings of the 31st IEEE International Conference on Tools with Artificial Intelligence, Portland, Nov 4-6, 2019. Piscataway: IEEE, 2019: 1118-1123. |
| [61] | LI K W, ZHANG T, WANG R, et al. Deep reinforcement learning for combinatorial optimization: covering salesman problems[J]. arXiv:2102.05875, 2021. |
| [62] | NAZARI M, OROOJLOOY A, SNYDER L, et al. Rein-forcement learning for solving the vehicle routing problem[J]. arXiv:1802.04240, 2018. |
| [63] | KOOL W, VAN HOOF H, WELLING M. Attention, learn to solve routing problems[J]. arXiv:1803.08475, 2018. |
| [64] | EMAMI P, RANKA S. Learning permutations with sinkhorn policy gradient[J]. arXiv:1805.07010, 2018. |
| [65] | OREN J, ROSS C, LEFAROV M, et al. SOLO: search on-line, learn offline for combinatorial optimization problems[C]//Proceedings of the 14th International Symposium on Combinatorial Search, Jinan, Jul 26-30, 2021. Menlo Park: AAAI, 2021: 97-105. |
| [66] | BO P, WANG J H, ZHANG Z Z. A deep reinforcement learn-ing algorithm using dynamic attention model for vehicle routing problems[C]//Proceedings of the 2019 International Symposium on Intelligence Computation and Applications, Guangzhou, Nov 16-17, 2019. Cham: Springer, 2019: 636-650. |
| [67] | DAI H, KHALIL E B, ZHANG Y, et al. Learning combina-torial optimization algorithms over graphs[J]. arXiv:1704. 01665, 2017. |
| [68] | DRORI I, KHARKAR A, SICKINGER W R, et al. Learning to solve combinatorial optimization problems on real-world graphs in linear time[C]//Proceedings of the 2020 IEEE International Conference on Machine Learning and Appli-cations, Miami, Dec 14-17, 2020. Piscataway: IEEE, 2020: 19-24. |
| [69] | MITTAL A, DHAWAN A, MEDYA S, et al. Learning heuri-stics over large graphs via deep reinforcement learning[J]. arXiv:1903.03332, 2019. |
| [70] | BARRETT T, CLEMENTS W, FOERSTER J, et al. Explor-atory combinatorial optimization with reinforcement learn-ing[J]. arXiv:1909.04063, 2019. |
| [71] | ABE K, XU Z, SATO I, et al. Solving NP-hard problems on graphs with extended AlphaGo Zero[J]. arXiv:1905.11623, 2019. |
| [72] | ABE K, XU Z, SATO I, et al. Solving NP-hard problems on graphs by reinforcement learning without domain knowledge[J]. arXiv:1905.11623, 2019. |
| [73] | BRESSON X, LAURENT T. The Transformer network for the traveling salesman problem[J]. arXiv:2103.03012, 2021. |
| [74] | DEUDON M, COURNUT P, LACOSTE A, et al. Learning heuristics for the TSP by policy gradient[C]//LNCS 10848: Proceedings of the 15th International Conference on Integr-ation of Constraint Programming, Artificial Intelligence, and Operations Research, Delft, Jun 26-29, 2018. Cham: Springer, 2018: 170-181. |
| [75] | CAPPART Q, MOISAN T, ROUSSEAU L M, et al. Com-bining reinforcement learning and constraint programming for combinatorial optimization[J]. arXiv:2006.01610, 2020. |
| [76] | CAPPART Q, GOUTIERRE E, BERGMAN D, et al. Improv-ing optimization bounds using machine learning: decision diagrams meet deep reinforcement learning[C]//Proceedings of the 33rd AAAI Conference on Artificial Intelligence, the 31st Innovative Applications of Artificial Intelligence Con-ference, the 9th AAAI Symposium on Educational Advances in Artificial Intelligence, Honolulu, Jan 27-Feb 1, 2019. Menlo Park: AAAI, 2019: 1443-1451. |
| [77] | GAO L, CHEN M, CHEN Q, et al. Learn to design the heur-istics for vehicle routing problem[J]. arXiv:2002.08539, 2020. |
| [78] | COSTA P, RHUGGENAATH J, ZHANG Y, et al. Learning 2-opt heuristics for the traveling salesman problem via deep reinforcement learning[J]. arXiv:2004.01608, 2020. |
| [79] | ZHENG J, HE K, ZHOU J, et al. Combining reinforcement learning with Lin-Kernighan-Helsgaun algorithm for the traveling salesman problem[J]. arXiv:2012.04461, 2020. |
| [80] |
HELSGAUN K. An effective implementation of the Lin-Kernighan traveling salesman heuristic[J]. European Journal of Operational Research, 2000, 126(1):106-130.
DOI URL |
| [81] | LU H, ZHANG X W, YANG S. A learning-based iterative method for solving vehicle routing problems[C]// Proceed-ings of the 8th International Conference on Learning Re-presentations, Addis Ababa, May 6-9, 2019: 1-12. |
| [82] |
LI K W, ZHANG T, WANG R. Deep reinforcement learning for multiobjective optimization[J]. IEEE Transactions on Cybernetics, 2020, 51(6):3103-3114.
DOI URL |
| [83] |
SILVA M L, SOUZA S D, SOUZA M F, et al. A reinfor-cement learning-based multi-agent framework applied for solving routing and scheduling problems[J]. Expert Systems with Applications, 2019, 131:148-171.
DOI URL |
| [84] | TASSEL P, GEBSER M, SCHEKOTIHIN K. A scheduling[J]. arXiv:2104.03760, 2021. |
| [85] | MA Q, GE S, HE D, et al. Combinatorial optimization by graph pointer networks and hierarchical reinforcement learn-ing[J]. arXiv:1911.04936, 2019. |
| [86] | DELARUE A, ANDERSON R, TJANDRAATMADJA C. Reinforcement learning with combinatorial actions: an app-lication to vehicle routing[J]. arXiv:2010.12001, 2020. |
| [87] | APPLEGATE D. Concorde: a code for solving traveling sal-esman problems[EB/OL]. [2021-07-12]. https://www.math.uwaterloo.ca/tsp/concorde. |
| [88] | OPTIMIZATION I G. Gurobi optimizer reference manual[EB/OL].(2020-10-27) [2021-07-12]. https://www.gurobi.com. |
| [89] | PERRON L, FURNON V. Google’s OR-tools[EB/OL].(2020-10-06) [2021-07-12]. https://developers.google.com/optimization. |
| [90] |
MAZYAVKINA N, SVIRIDOV S, IVANOV S, et al. Rein-forcement learning for combinatorial optimization: a survey[J]. Computers and Operations Research, 2021, 134:105400.
DOI URL |
| [91] | YANG Y, WHINSTON A. A survey on reinforcement learn-ing for combinatorial optimization[J]. arXiv:2008.12248, 2020. |
| [92] | VESSELINOVA N, STEINERT R, PEREZ-RAMIREZ D F, et al. Learning combinatorial optimization on graphs: a survey with applications to networking[J]. IEEE Access, 2020, 8:120388-120416. |
| [1] | 赵婷婷,孔乐,韩雅杰,任德华,陈亚瑞. 模型化强化学习研究综述[J]. 计算机科学与探索, 2020, 14(6): 918-927. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||