
计算机科学与探索 ›› 2022, Vol. 16 ›› Issue (11): 2575-2586.DOI: 10.3778/j.issn.1673-9418.2102001
李青援1, 邓赵红1,2,3,+( ), 罗晓清1, 顾鑫4, 王士同1
), 罗晓清1, 顾鑫4, 王士同1
收稿日期:2021-02-01
修回日期:2021-03-18
出版日期:2022-11-01
发布日期:2021-03-25
通讯作者:
+ E-mail: dengzhaohong@jiangnan.edu.cn作者简介:李青援(1997—),男,山东潍坊人,硕士研究生,主要研究方向为深度学习。基金资助:
LI Qingyuan1, DENG Zhaohong1,2,3,+(), LUO Xiaoqing1, GU Xin4, WANG Shitong1
Received:2021-02-01
Revised:2021-03-18
Online:2022-11-01
Published:2021-03-25
About author:LI Qingyuan, born in 1997, M.S. candidate. His research interest is deep learning.Supported by:摘要:
为了进一步提升SSD算法的性能,解决SSD算法在进行多尺度预测时特征图信息不平衡和小目标识别难的问题,设计了即插即用的模块,充分融合不同尺度特征图包含的信息并建模特征图内的重要性关系,来增强特征图的表示能力。首先,设计了一种新颖的特征融合方法来解决跨尺度特征融合存在的信息差异问题。其次,根据池化金字塔的思想设计了一种深度特征提取模块来提取不同感受野的信息,从而提高模型对不同尺寸目标的检测能力。最后,为了进一步优化特征图,突出特征图对当前任务有效的信息,并建立全局像素点之间的长距离关系和各通道之间的重要性关系,提出了一种轻量级的注意力模块。通过上述机制,修改了SSD模型的架构,有效地提升了SSD算法的检测精度和鲁棒性。在PASCAL VOC数据集上设计了丰富的实验,验证了所提方法的有效性。在PASCAL VOC2007测试集上该方法比SSD算法提高了2.9个百分点的平均精确度(mAP),同时还保留了实时检测的能力。
中图分类号:
李青援, 邓赵红, 罗晓清, 顾鑫, 王士同. 注意力与跨尺度融合的SSD目标检测算法[J]. 计算机科学与探索, 2022, 16(11): 2575-2586.
LI Qingyuan, DENG Zhaohong, LUO Xiaoqing, GU Xin, WANG Shitong. SSD Object Detection Algorithm with Attention and Cross-Scale Fusion[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(11): 2575-2586.
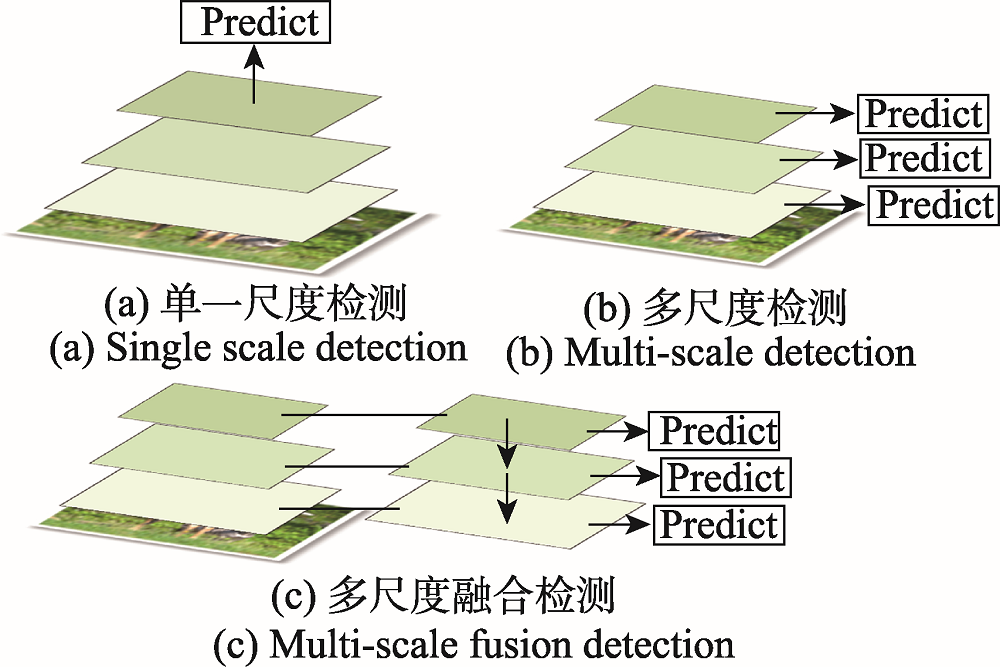
图1 不同类型检测方法
Fig.1 Different types of detection methods
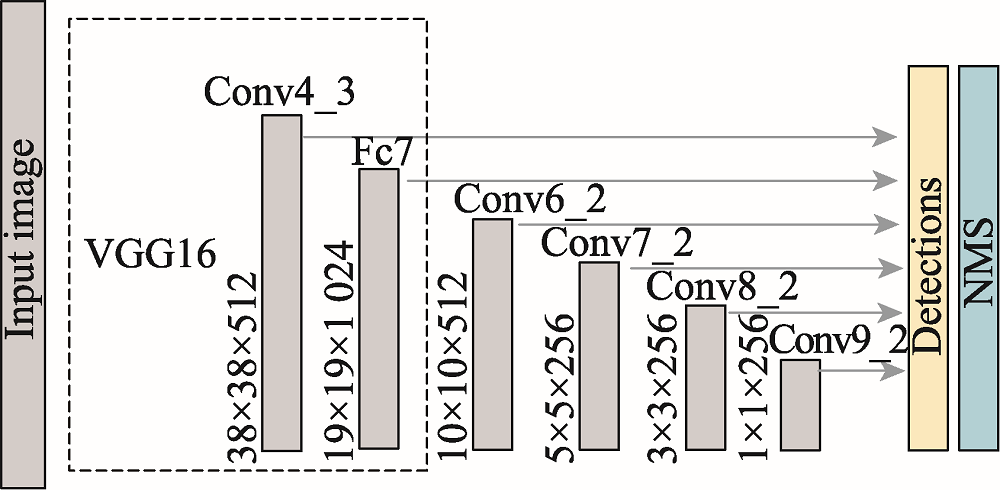
图2 SSD算法整体框架图
Fig.2 Overall framework of SSD
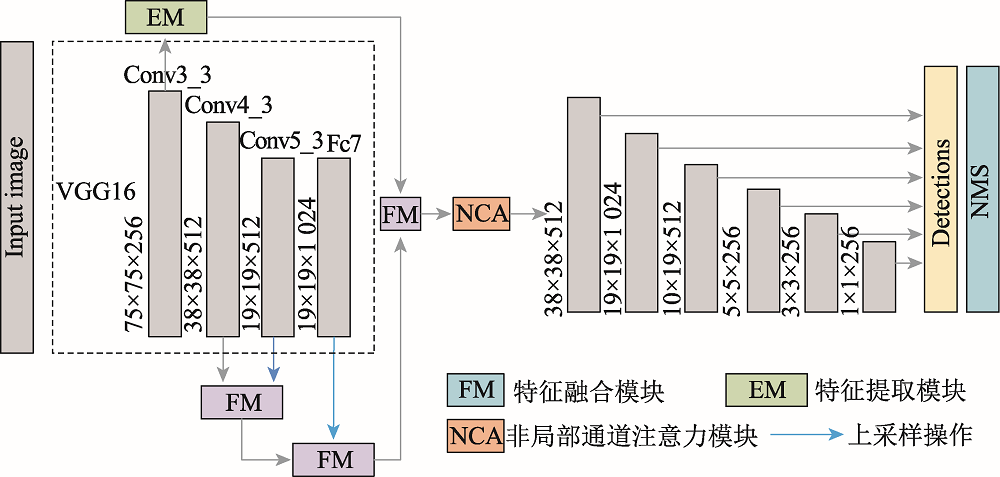
图3 改进的SSD算法整体架构图
Fig.3 Overall framework of improved SSD
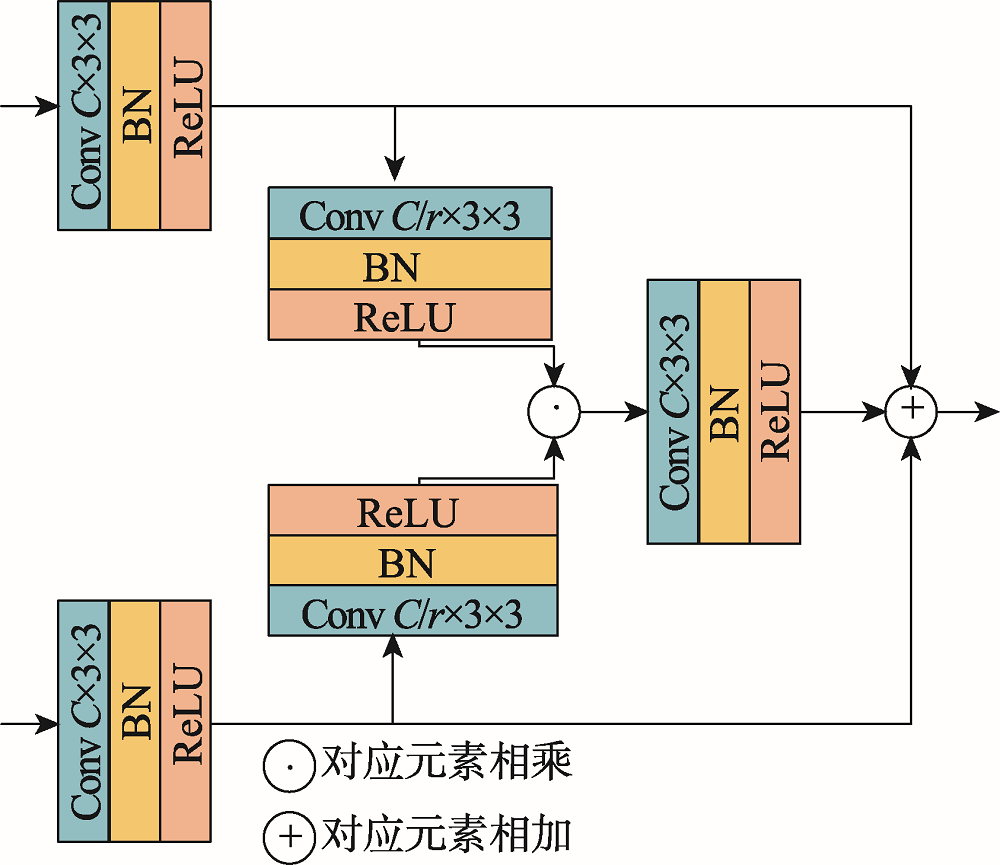
图4 特征融合模块
Fig.4 Feature fusion module
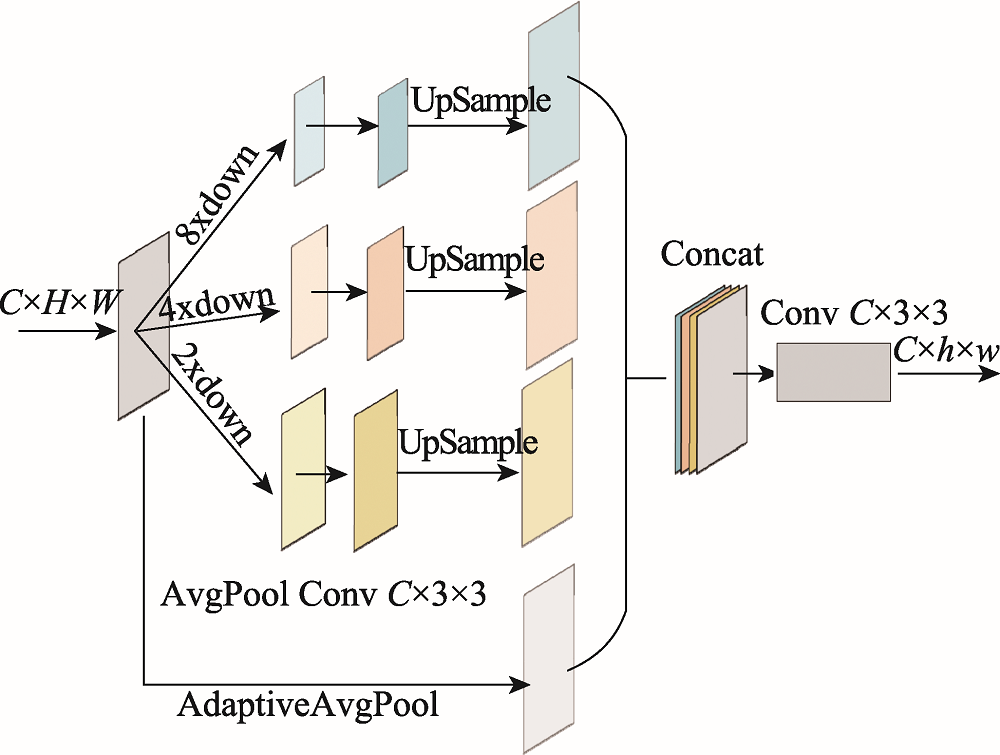
图5 特征提取模块
Fig.5 Feature extraction module
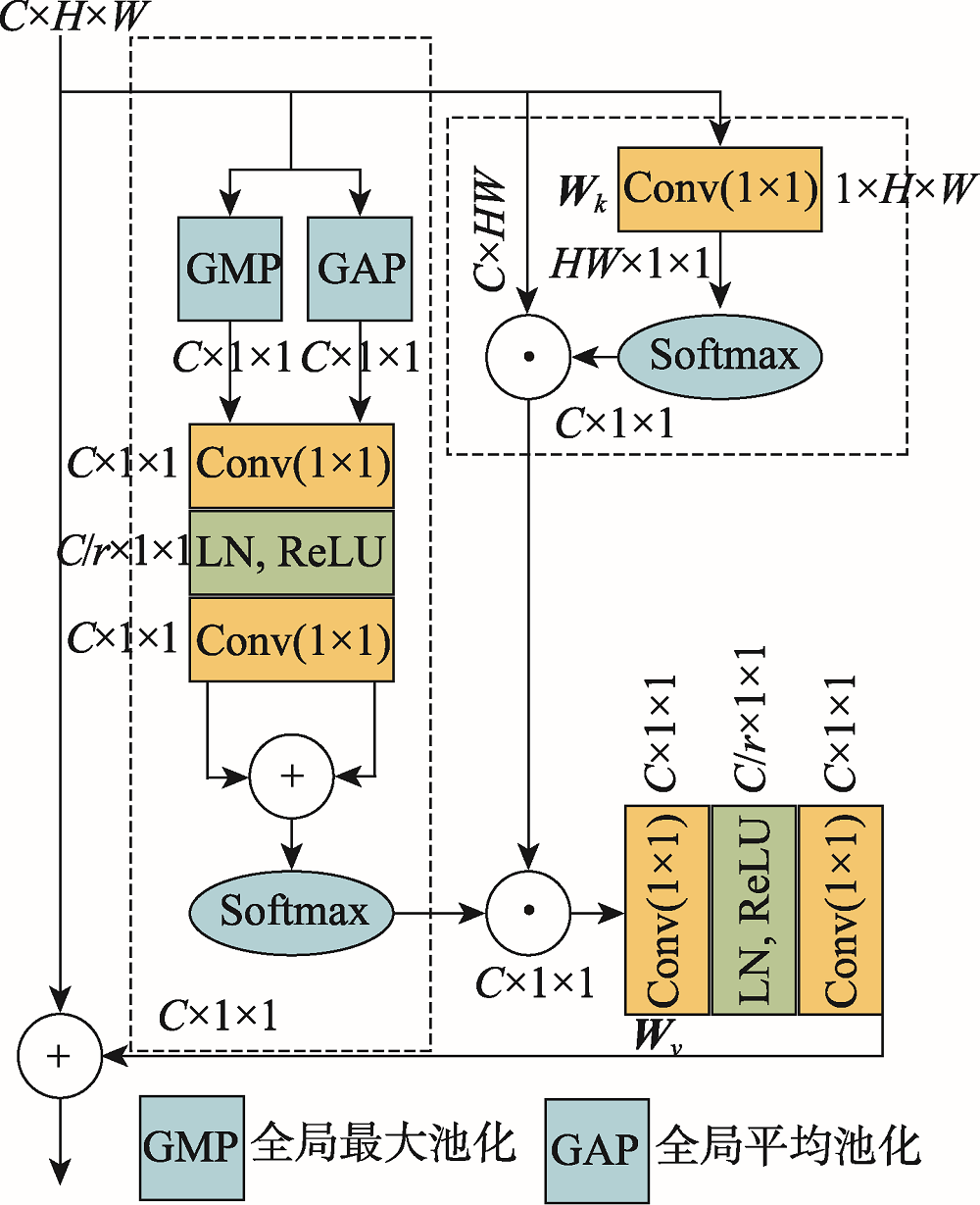
图6 非局部通道注意力机制模块
Fig.6 Non-local channel attentional mechanism module

图7 特征金字塔产生层
Fig.7 Pyramid feature generation layers
| 模型 | mAP | aero | bike | bird | boat | bottle | bus | car | cat | chair | cow | table | dog | horse | mbike | person | plant | sheep | sofa | train | tv |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SSD | 77.5 | 79.5 | 83.9 | 76.0 | 69.6 | 50.5 | 87.0 | 85.7 | 88.1 | 60.3 | 81.5 | 77.0 | 86.1 | 87.5 | 84.0 | 79.4 | 51.7 | 77.9 | 79.5 | 87.6 | 76.8 |
| DSSD | 78.6 | 81.9 | 84.9 | 80.5 | 68.4 | 53.9 | 85.6 | 86.2 | 88.9 | 61.1 | 83.5 | 78.7 | 86.7 | 88.7 | 86.7 | 79.7 | 51.7 | 78.0 | 80.9 | 87.2 | 79.4 |
| ION | 79.2 | 80.2 | 85.2 | 78.8 | 70.9 | 62.6 | 86.6 | 86.9 | 89.8 | 61.7 | 86.9 | 76.5 | 88.4 | 87.5 | 83.4 | 80.5 | 52.4 | 78.1 | 77.2 | 86.9 | 83.5 |
| Ours | 80.4 | 84.9 | 87.0 | 79.5 | 75.5 | 59.5 | 86.7 | 87.4 | 89.0 | 67.5 | 85.0 | 80.0 | 86.6 | 88.0 | 86.2 | 81.9 | 57.1 | 79.1 | 81.1 | 86.3 | 79.7 |
表1 Comparison of detection accuracy of 20 categories on PASCAL VOC2007test dataset 单位:%
Table 1
| 模型 | mAP | aero | bike | bird | boat | bottle | bus | car | cat | chair | cow | table | dog | horse | mbike | person | plant | sheep | sofa | train | tv |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SSD | 77.5 | 79.5 | 83.9 | 76.0 | 69.6 | 50.5 | 87.0 | 85.7 | 88.1 | 60.3 | 81.5 | 77.0 | 86.1 | 87.5 | 84.0 | 79.4 | 51.7 | 77.9 | 79.5 | 87.6 | 76.8 |
| DSSD | 78.6 | 81.9 | 84.9 | 80.5 | 68.4 | 53.9 | 85.6 | 86.2 | 88.9 | 61.1 | 83.5 | 78.7 | 86.7 | 88.7 | 86.7 | 79.7 | 51.7 | 78.0 | 80.9 | 87.2 | 79.4 |
| ION | 79.2 | 80.2 | 85.2 | 78.8 | 70.9 | 62.6 | 86.6 | 86.9 | 89.8 | 61.7 | 86.9 | 76.5 | 88.4 | 87.5 | 83.4 | 80.5 | 52.4 | 78.1 | 77.2 | 86.9 | 83.5 |
| Ours | 80.4 | 84.9 | 87.0 | 79.5 | 75.5 | 59.5 | 86.7 | 87.4 | 89.0 | 67.5 | 85.0 | 80.0 | 86.6 | 88.0 | 86.2 | 81.9 | 57.1 | 79.1 | 81.1 | 86.3 | 79.7 |
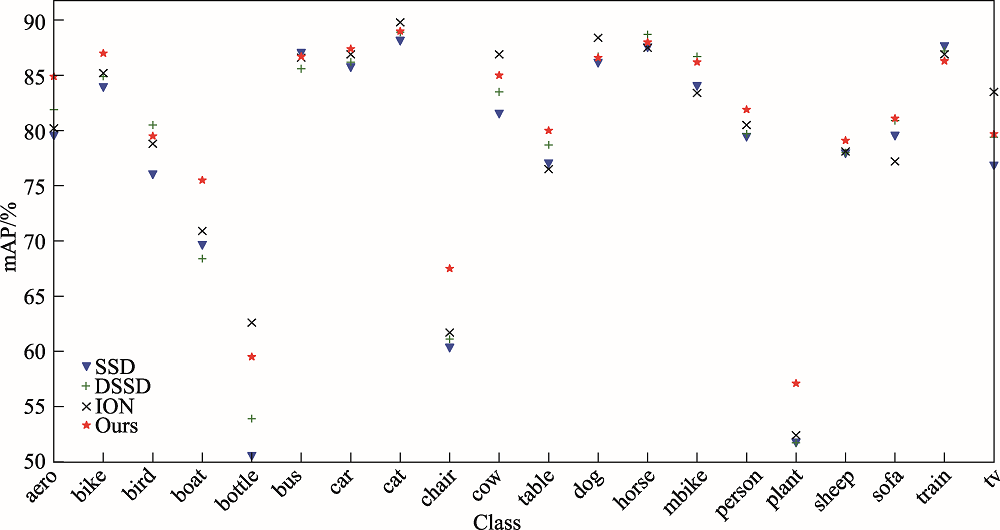
图8 PASCAL VOC 2007test数据集上4种检测算法mAP对比
Fig.8 Comparison of mAP of 4 detection algorithms on PASCAL VOC2007test dataset
| 模型 | mAP | aero | bike | bird | boat | bottle | bus | car | cat | chair | cow | table | dog | horse | mbike | person | plant | sheep | sofa | train | tv |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SSD512 | 76.7 | 88.8 | 84.8 | 77.0 | 61.0 | 56.3 | 82.6 | 82.4 | 92.6 | 58.4 | 80.7 | 61.4 | 90.4 | 87.2 | 86.9 | 85.0 | 53.1 | 81.2 | 65.9 | 86.4 | 72.0 |
| Ours512 | 78.5 | 91.0 | 87.9 | 79.8 | 63.6 | 60.3 | 84.6 | 83.5 | 92.8 | 60.9 | 82.2 | 64.3 | 91.2 | 86.8 | 88.3 | 87.1 | 57.1 | 85.1 | 66.1 | 84.0 | 73.8 |
表2 Comparison of detection accuracy of 20 categories on PASCAL VOC2012test dataset 单位:%
Table 2
| 模型 | mAP | aero | bike | bird | boat | bottle | bus | car | cat | chair | cow | table | dog | horse | mbike | person | plant | sheep | sofa | train | tv |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SSD512 | 76.7 | 88.8 | 84.8 | 77.0 | 61.0 | 56.3 | 82.6 | 82.4 | 92.6 | 58.4 | 80.7 | 61.4 | 90.4 | 87.2 | 86.9 | 85.0 | 53.1 | 81.2 | 65.9 | 86.4 | 72.0 |
| Ours512 | 78.5 | 91.0 | 87.9 | 79.8 | 63.6 | 60.3 | 84.6 | 83.5 | 92.8 | 60.9 | 82.2 | 64.3 | 91.2 | 86.8 | 88.3 | 87.1 | 57.1 | 85.1 | 66.1 | 84.0 | 73.8 |
| 算法 | 网络 | 检测速度/(frame/s) | GPU | 锚框个数 | 输入尺寸 | mAP/% |
|---|---|---|---|---|---|---|
| Faster R-CNN[ | VGG-16 | 7.0 | Tian X | 6 000 | 73.2 | |
| Faster R-CNN[ | ResNet-101 | 2.4 | K40 | 300 | 76.4 | |
| R-FCN[ | ResNet-50 | — | — | 300 | 77.0 | |
| R-FCN[ | ResNet-101 | 5.8 | K40 | 300 | 79.5 | |
| YOLOv2[ | Darknet-19 | 81.0 | Tian X | — | 73.7 | |
| SSD300[ | VGG-16 | 92.0 | 2080Ti | 8 732 | 77.5 | |
| FSSD300[ | VGG-16 | 65.8 | 1080Ti | 8 732 | 78.8 | |
| RefineDet320[ | VGG-16 | 12.9 | K80 | 6 375 | 79.5 | |
| RSSD300[ | VGG-16 | 35.0 | Tian X | 8 732 | 78.5 | |
| DSSD321[ | ResNet-101 | 9.5 | Tian X | 17 080 | 78.6 | |
| ASSD300[ | VGG-16 | 11.8 | K40 | 8 732 | 80.0 | |
| SSD512[ | VGG-16 | 45.0 | 2080Ti | 24 564 | 79.5 | |
| DSSD513[ | ResNet-101 | 5.5 | Tian X | 43 688 | 81.5 | |
| FSSD512[ | VGG-16 | 35.7 | 1080Ti | 24 564 | 80.9 | |
| RSSD512[ | VGG-16 | 16.6 | Tian X | 24 564 | 80.8 | |
| ASSD512 | VGG-16 | 3.4 | K40 | 24 564 | 81.6 | |
| RefineDet512[ | VGG-16 | 5.6 | K80 | 16 320 | 81.2 | |
| Ours300 | VGG-16 | 44.8 | 2080Ti | 8 732 | 80.4 | |
| Ours512 | VGG-16 | 22.5 | 2080Ti | 24 564 | 82.2 |
表3 PASCAL VOC2007test数据集上检测速度和检测精度对比
Table 3 Comparison of detection speed and accuracy on PASCAL VOC2007test dataset
| 算法 | 网络 | 检测速度/(frame/s) | GPU | 锚框个数 | 输入尺寸 | mAP/% |
|---|---|---|---|---|---|---|
| Faster R-CNN[ | VGG-16 | 7.0 | Tian X | 6 000 | 73.2 | |
| Faster R-CNN[ | ResNet-101 | 2.4 | K40 | 300 | 76.4 | |
| R-FCN[ | ResNet-50 | — | — | 300 | 77.0 | |
| R-FCN[ | ResNet-101 | 5.8 | K40 | 300 | 79.5 | |
| YOLOv2[ | Darknet-19 | 81.0 | Tian X | — | 73.7 | |
| SSD300[ | VGG-16 | 92.0 | 2080Ti | 8 732 | 77.5 | |
| FSSD300[ | VGG-16 | 65.8 | 1080Ti | 8 732 | 78.8 | |
| RefineDet320[ | VGG-16 | 12.9 | K80 | 6 375 | 79.5 | |
| RSSD300[ | VGG-16 | 35.0 | Tian X | 8 732 | 78.5 | |
| DSSD321[ | ResNet-101 | 9.5 | Tian X | 17 080 | 78.6 | |
| ASSD300[ | VGG-16 | 11.8 | K40 | 8 732 | 80.0 | |
| SSD512[ | VGG-16 | 45.0 | 2080Ti | 24 564 | 79.5 | |
| DSSD513[ | ResNet-101 | 5.5 | Tian X | 43 688 | 81.5 | |
| FSSD512[ | VGG-16 | 35.7 | 1080Ti | 24 564 | 80.9 | |
| RSSD512[ | VGG-16 | 16.6 | Tian X | 24 564 | 80.8 | |
| ASSD512 | VGG-16 | 3.4 | K40 | 24 564 | 81.6 | |
| RefineDet512[ | VGG-16 | 5.6 | K80 | 16 320 | 81.2 | |
| Ours300 | VGG-16 | 44.8 | 2080Ti | 8 732 | 80.4 | |
| Ours512 | VGG-16 | 22.5 | 2080Ti | 24 564 | 82.2 |

图9 本文与SSD算法检测结果对比
Fig.9 Comparison of detection results between SSD and ours
| 方法 | 检测速度/(frame/s) | mAP/% |
|---|---|---|
| SSD | 92.0 | 77.5 |
| SSD* | 77.0 | 78.1 |
| SSD*+EM | 69.3 | 78.5 |
| SSD*+EM+FM | 46.7 | 79.7 |
| SSD*+EM+FM+NCA | 44.8 | 80.4 |
表4 消融实验对比结果
Table 4 Comparative results of ablation experiments
| 方法 | 检测速度/(frame/s) | mAP/% |
|---|---|---|
| SSD | 92.0 | 77.5 |
| SSD* | 77.0 | 78.1 |
| SSD*+EM | 69.3 | 78.5 |
| SSD*+EM+FM | 46.7 | 79.7 |
| SSD*+EM+FM+NCA | 44.8 | 80.4 |

图10 注意力图可视化
Fig.10 Visualization of attention maps
| [1] | GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, Jun 23-28, 2014. Washington: IEEE Computer Society, 2014: 580- 587. |
| [2] | GIRSHICK R. Fast R-CNN[J]. arXiv:1504.08083, 2015. |
| [3] |
REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
DOI PMID |
| [4] | RAJARAM R N, OHN-BAR E, TRIVEDI M M. RefineNet: iterative refinement for accurate object localization[C]// Proceedings of the 19th IEEE International Conference on Intelligent Transportation Systems, Rio de Janeiro, Nov 1-4, 2016. Piscataway: IEEE, 2016: 1528-1533. |
| [5] | REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 779-788. |
| [6] | REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 6517-6525. |
| [7] | REDMON J, FARHADI A. YOLOv3: an incremental improve-ment[J]. arXiv:1804.02767, 2018. |
| [8] | LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector[C]// LNCS 9905: Proceedings of the 14th European Conference on Computer Vision, Amsterdam, Oct 11-14, 2016. Cham: Springer, 2016: 21-37. |
| [9] | LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Oct 22-29, 2017. Washington: IEEE Computer Society, 2017: 2999-3007. |
| [10] |
FELZENSZWALB P F, GIRSHICK R B, MCALLESTER D A, et al. Object detection with discriminatively trained part- based models[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(9): 1627-1645.
DOI URL |
| [11] | LIN T Y, DOLLAR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 936-944. |
| [12] | LIU S, QI L, QIN H, et al. Path aggregation network for instance segmentation[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition,Salt Lake City, Jun 18-22, 2018. Washington: IEEE Computer Society, 2018: 8759-8768. |
| [13] | ZHAO H, SHI J, QI X, et al. Pyramid scene parsing network[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 6230-6239. |
| [14] |
EVERINGHAM M, ESLAMI S, GOOL L, et al. The PASCAL visual object classes challenge: a retrospective[J]. International Journal of Computer Vision, 2014, 111(1): 98-136.
DOI URL |
| [15] |
LOWE D G. Distinctive image features from scale-invariant keypoints[J]. International Journal of Computer Vision, 2004, 60(2): 91-110.
DOI URL |
| [16] | DALAL N, TRIGGS B. Histograms of oriented gradients for human detection[C]// Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recog-nition, San Diego, Jun 20-26, 2005. Washington: IEEE Computer Society, 2005: 886-893. |
| [17] | FU CY, LIU W, RANGA A, et al. DSSD: deconvolutional single shot detector[J]. arXiv:1701.06659, 2017. |
| [18] | LI Z, ZHOU F. FSSD: feature fusion single shot multibox detector[J]. arXiv:1712.00960, 2017. |
| [19] | SHEN Z, LIU Z, LI J, et al. DSOD: learning deeply supervised object detectors from scratch[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Oct 22-29, 2017. Washington: IEEE Computer Society, 2017: 1937-1945. |
| [20] | HUANG G, LIU Z, WEINBERGER K Q. Densely connected convolutional networks[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 2261-2269. |
| [21] | PANG J, CHEN K, SHI J, et al. Libra R-CNN: towards balanced learning for object detection[C]// Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, Jun 16-20, 2019. Piscataway: IEEE, 2019: 821-830. |
| [22] | BELL S, ZITNICK C L, BALA K, et al. Inside-Outside net: detecting objects in context with skip pooling and recurrent neural networks[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 2874-2883. |
| [23] | KONG T, YAO A, CHEN Y, et al. HyperNet: towards accurate region proposal generation and joint object detection[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 845-853. |
| [24] | HARIHARAN B, ARBELÁEZ P P, GIRSHICK R B, et al. Hypercolumns for object segmentation and fine-grained localization[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, Jun 7-12, 2015. Washington: IEEE Computer Society, 2015: 447-456. |
| [25] |
HU J, SHEN L, ALBANIE S, et al. Squeeze-and-Excitation networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(8): 2011-2023.
DOI PMID |
| [26] | WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C]// LNCS 11211: Proceedings of the 15th European Conference on Computer Vision, Munich, Sep 8-14, 2018. Cham: Springer, 2018: 3-19. |
| [27] | WANG X, GIRSHICK R B, GUPTA A, et al. Non-local neural networks[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-22, 2018. Washington: IEEE Computer Society, 2018: 7794-7803. |
| [28] | CAO Y, XU J, LIN S, et al. GCNet: non-local networks meet squeeze-excitation networks and beyond[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Oct 27-28, 2019. Piscataway: IEEE, 2019: 1971-1980. |
| [29] | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[J]. arXiv:1409. 1556, 2014. |
| [30] | ZHOU B, KHOSLA A, LAPEDRIZA À, et al. Object detectors emerge in deep scene CNNs[J]. arXiv:1412.6856, 2014. |
| [31] | DAI J, LI Y, HE K, et al. R-FCN: object detection via region-based fully convolutional networks[J]. arXiv:1605.06409, 2016. |
| [32] | JEONG J, PARK H, KWAK N. Enhancement of SSD by concatenating feature maps for object detection[J]. arXiv:1705.09587, 2017. |
| [33] | YI J, WU P, METAXAS D. ASSD: attentive single shot multibox detector[J]. Computer Vision and Image Understanding, 2019, 189: 102827. |
| [34] |
SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: visual explanations from deep networks via gradient-based localization[J]. International Journal of Computer Vision, 2020, 128(2): 336-359.
DOI URL |
| [1] | 陈灏然, 彭力, 李文涛, 戴菲菲. 加权网络下的小目标检测算法[J]. 计算机科学与探索, 2022, 16(9): 2143-2150. |
| [2] | 吕晓琦, 纪科, 陈贞翔, 孙润元, 马坤, 邬俊, 李浥东. 结合注意力与循环神经网络的专家推荐算法[J]. 计算机科学与探索, 2022, 16(9): 2068-2077. |
| [3] | 李珍琦, 王晶, 贾子钰, 林友芳. 融合注意力的多维特征图卷积运动想象分类[J]. 计算机科学与探索, 2022, 16(9): 2050-2060. |
| [4] | 张祥平, 刘建勋. 基于深度学习的代码表征及其应用综述[J]. 计算机科学与探索, 2022, 16(9): 2011-2029. |
| [5] | 李冬梅, 罗斯斯, 张小平, 许福. 命名实体识别方法研究综述[J]. 计算机科学与探索, 2022, 16(9): 1954-1968. |
| [6] | 任宁, 付岩, 吴艳霞, 梁鹏举, 韩希. 深度学习应用于目标检测中失衡问题研究综述[J]. 计算机科学与探索, 2022, 16(9): 1933-1953. |
| [7] | 杨才东, 李承阳, 李忠博, 谢永强, 孙方伟, 齐锦. 深度学习的图像超分辨率重建技术综述[J]. 计算机科学与探索, 2022, 16(9): 1990-2010. |
| [8] | 曾凡智, 许露倩, 周燕, 周月霞, 廖俊玮. 面向智慧教育的知识追踪模型研究综述[J]. 计算机科学与探索, 2022, 16(8): 1742-1763. |
| [9] | 安凤平, 李晓薇, 曹翔. 权重初始化-滑动窗口CNN的医学图像分类[J]. 计算机科学与探索, 2022, 16(8): 1885-1897. |
| [10] | 杨知桥, 张莹, 王新杰, 张东波, 王玉. 改进U型网络在视网膜病变检测中的应用研究[J]. 计算机科学与探索, 2022, 16(8): 1877-1884. |
| [11] | 夏鸿斌, 肖奕飞, 刘渊. 融合自注意力机制的长文本生成对抗网络模型[J]. 计算机科学与探索, 2022, 16(7): 1603-1610. |
| [12] | 彭豪, 李晓明. 多尺度选择金字塔网络的小样本目标检测算法[J]. 计算机科学与探索, 2022, 16(7): 1649-1660. |
| [13] | 刘艺, 李蒙蒙, 郑奇斌, 秦伟, 任小广. 视频目标跟踪算法综述[J]. 计算机科学与探索, 2022, 16(7): 1504-1515. |
| [14] | 赵小明, 杨轶娇, 张石清. 面向深度学习的多模态情感识别研究进展[J]. 计算机科学与探索, 2022, 16(7): 1479-1503. |
| [15] | 孙方伟, 李承阳, 谢永强, 李忠博, 杨才东, 齐锦. 深度学习应用于遮挡目标检测算法综述[J]. 计算机科学与探索, 2022, 16(6): 1243-1259. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||