
计算机科学与探索 ›› 2022, Vol. 16 ›› Issue (6): 1243-1259.DOI: 10.3778/j.issn.1673-9418.2112035
孙方伟1, 李承阳1,2, 谢永强1,+( ), 李忠博1, 杨才东1, 齐锦1
), 李忠博1, 杨才东1, 齐锦1
收稿日期:2021-12-09
修回日期:2022-03-15
出版日期:2022-06-01
发布日期:2022-06-20
通讯作者:
+ E-mail: xyq_ams@outlook.com作者简介:孙方伟(1996—),男,山东青岛人,硕士研究生,主要研究方向为目标检测、目标跟踪、语义分割。
SUN Fangwei1, LI Chengyang1,2, XIE Yongqiang1,+(), LI Zhongbo1, YANG Caidong1, QI Jin1
Received:2021-12-09
Revised:2022-03-15
Online:2022-06-01
Published:2022-06-20
About author:SUN Fangwei, born in 1996, M.S. candidate. His research interests include object detection, object tracking and semantic segmentation.摘要:
遮挡目标检测长期以来是计算机视觉中的一个难点和研究热点。目前的深度学习基于卷积神经网络,将目标检测任务作为分类任务和回归任务来处理。当目标被遮挡时,遮挡物会混淆目标之间的特征,使得深度网络不能很好地识别和推理,降低检测器在理想场景下的性能。考虑到遮挡在现实中的普遍性,对遮挡目标的有效检测具有重要研究价值。为了进一步促进遮挡目标检测的发展,对基于深度学习的遮挡目标检测算法进行了全面总结,并对已有的遮挡检测算法进行归类、分析、比较。在对目标检测进行简单概述基础上,首先,对遮挡目标检测的相关背景、研究的难点以及遮挡数据集进行了介绍;然后,对遮挡检测优化算法主要按照目标结构、损失函数、非极大值抑制以及部分语义四方面进行归纳分析,在对各种算法之间的联系以及发展脉络进行阐述后,对各种算法性能进行了比较;最后,指出了遮挡目标检测仍面临的困难,并对遮挡目标检测未来的发展方向进行了展望。
中图分类号:
孙方伟, 李承阳, 谢永强, 李忠博, 杨才东, 齐锦. 深度学习应用于遮挡目标检测算法综述[J]. 计算机科学与探索, 2022, 16(6): 1243-1259.
SUN Fangwei, LI Chengyang, XIE Yongqiang, LI Zhongbo, YANG Caidong, QI Jin. Review of Deep Learning Applied to Occluded Object Detection[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(6): 1243-1259.
| 数据集 | 年份 | 图片数量 | 目标类别 | 每张图片 目标个数 | 每张图片遮 挡目标个数 | 各部分占比/% | 使用场景 | ||
|---|---|---|---|---|---|---|---|---|---|
| 训练 | 验证 | 测试 | |||||||
| ImageNet | 2009 | 14 197 122 | 21 841 | — | — | — | — | — | 综合 |
| PASCAL VOC | 2007 | 9 963 | 20 | 2.47 | — | 25.0 | 25.0 | 50.0 | 综合 |
| 2012 | 23 080 | 20 | 2.38 | — | |||||
| MS-COCO | 2014 | 328 000 | 80 | 9.34 | 0.015 | 50.0 | 25.0 | 25.0 | 综合 |
| Open Images | 2018 | 9 178 276 | ~6 000 | 8.00 | — | 98.2 | 1.8 | — | 综合 |
| KITTI | 2012 | 14 999 | 5 | 5.35 | — | — | — | — | 行人、车辆 |
| Caltech数据集 | 2012 | 250 000 | 1 | 0.32 | 0.320 | 50.0 | 50.0 | 行人 | |
| VehicleOcclusion | 2017 | 9 056 | 6 | 1.00 | 1.000 | 50.0 | 50.0 | 车辆 | |
| CityPersons | 2017 | 5 050 | 1 | 6.47 | 0.320 | ~58.9 | ~9.9 | ~31.2 | 行人 |
| CrowdHuman | 2018 | 24 370 | 1 | 22.64 | 2.400 | 61.6 | 17.9 | 20.5 | 行人 |
表1 遮挡目标检测数据集
Table 1 Datasets of occlusion object detection
| 数据集 | 年份 | 图片数量 | 目标类别 | 每张图片 目标个数 | 每张图片遮 挡目标个数 | 各部分占比/% | 使用场景 | ||
|---|---|---|---|---|---|---|---|---|---|
| 训练 | 验证 | 测试 | |||||||
| ImageNet | 2009 | 14 197 122 | 21 841 | — | — | — | — | — | 综合 |
| PASCAL VOC | 2007 | 9 963 | 20 | 2.47 | — | 25.0 | 25.0 | 50.0 | 综合 |
| 2012 | 23 080 | 20 | 2.38 | — | |||||
| MS-COCO | 2014 | 328 000 | 80 | 9.34 | 0.015 | 50.0 | 25.0 | 25.0 | 综合 |
| Open Images | 2018 | 9 178 276 | ~6 000 | 8.00 | — | 98.2 | 1.8 | — | 综合 |
| KITTI | 2012 | 14 999 | 5 | 5.35 | — | — | — | — | 行人、车辆 |
| Caltech数据集 | 2012 | 250 000 | 1 | 0.32 | 0.320 | 50.0 | 50.0 | 行人 | |
| VehicleOcclusion | 2017 | 9 056 | 6 | 1.00 | 1.000 | 50.0 | 50.0 | 车辆 | |
| CityPersons | 2017 | 5 050 | 1 | 6.47 | 0.320 | ~58.9 | ~9.9 | ~31.2 | 行人 |
| CrowdHuman | 2018 | 24 370 | 1 | 22.64 | 2.400 | 61.6 | 17.9 | 20.5 | 行人 |
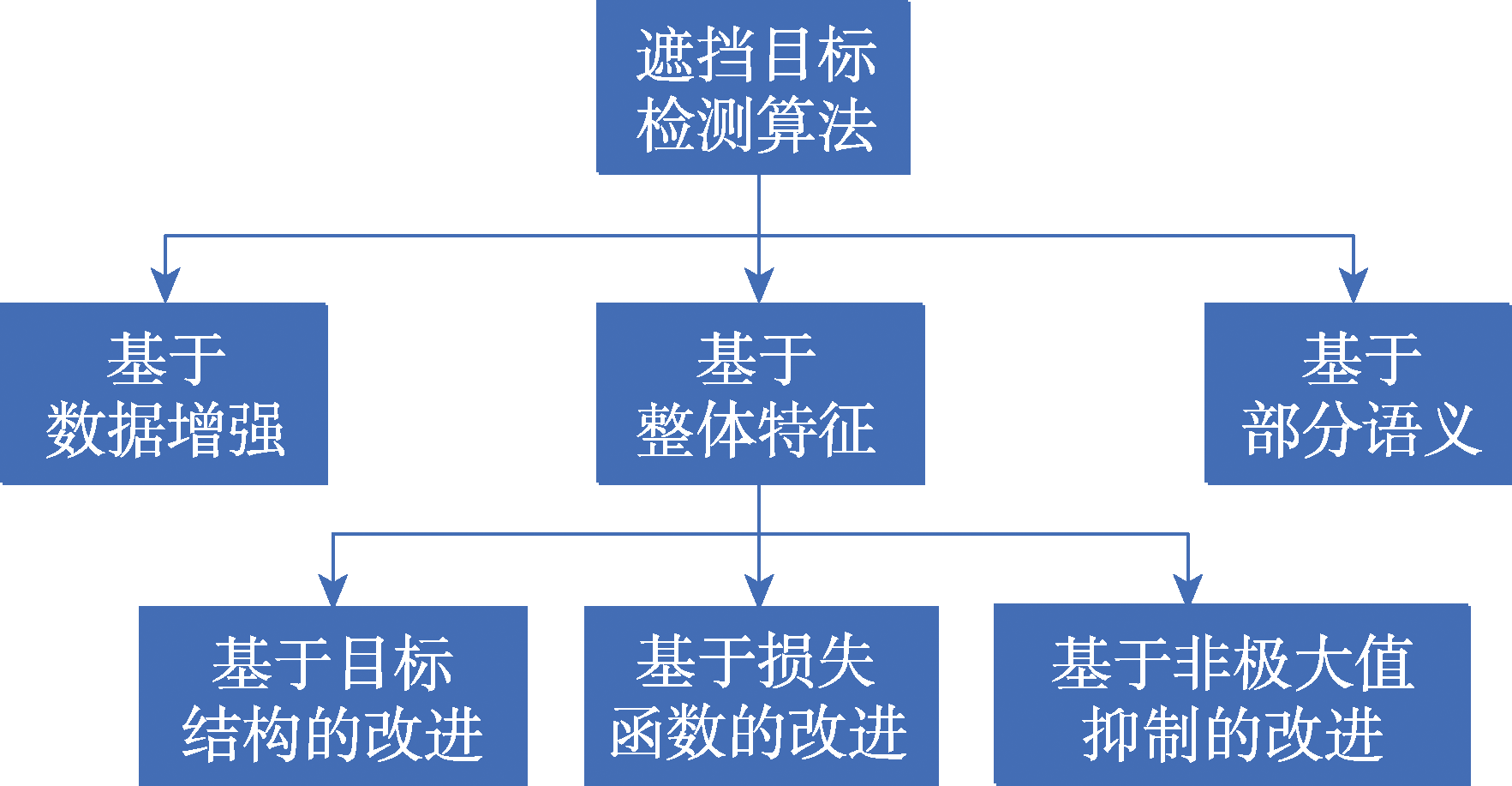
图1 算法分类
Fig.1 Algorithm classification

图2 PORoI和遮挡处理单元结构图
Fig.2 Architecture of PORoI and occlusion process unit

图3 CoupleNet模型结构
Fig.3 Architecture of CoupleNet

图4 JointDet网络结构
Fig.4 Network structure of JointDet

图5 DA-RCNN结构图
Fig.5 Network structure of DA-RCNN

图6 多目标预测总体结构
Fig.6 Architecture of multi-target prediction
| 损失函数 | 函数结构 | 结构说明 |
|---|---|---|
| Repulsion Loss | | 第一部分使得预测框尽可能靠近目标框 第二部分使得预测框尽可能远离周围目标框 第三部分使得预测框尽可能远离周围其他预测框 |
| Aggregation Loss | | 第一部分为回归损失,使得建议框靠近目标框 第二部分使得同一目标的建议框尽可能靠近 |
| GIoU Loss | | 使用交并比GIoU进行损失计算 |
| Rep-GIoU Loss | | GIoU Loss和Repulsion Loss的组合函数 |
| NMS Loss | | 第一部分用来抑制假阳性 第二部分用来避免错误地删除假阴性 |
表2 损失函数结构
Table 2 Architecture of loss function
| 损失函数 | 函数结构 | 结构说明 |
|---|---|---|
| Repulsion Loss | | 第一部分使得预测框尽可能靠近目标框 第二部分使得预测框尽可能远离周围目标框 第三部分使得预测框尽可能远离周围其他预测框 |
| Aggregation Loss | | 第一部分为回归损失,使得建议框靠近目标框 第二部分使得同一目标的建议框尽可能靠近 |
| GIoU Loss | | 使用交并比GIoU进行损失计算 |
| Rep-GIoU Loss | | GIoU Loss和Repulsion Loss的组合函数 |
| NMS Loss | | 第一部分用来抑制假阳性 第二部分用来避免错误地删除假阴性 |
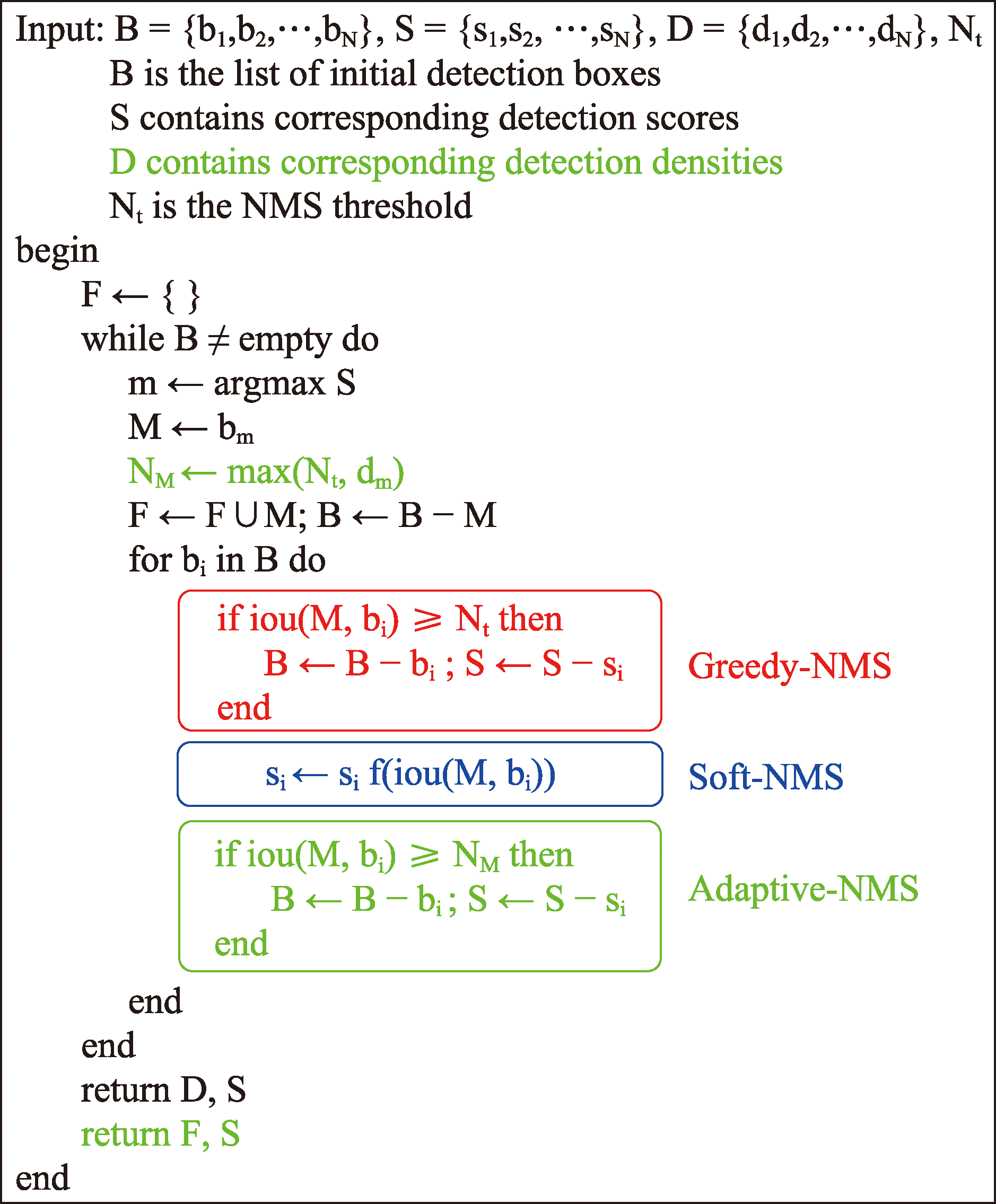
图7 NMS算法的结构
Fig.7 Architecture of NMS
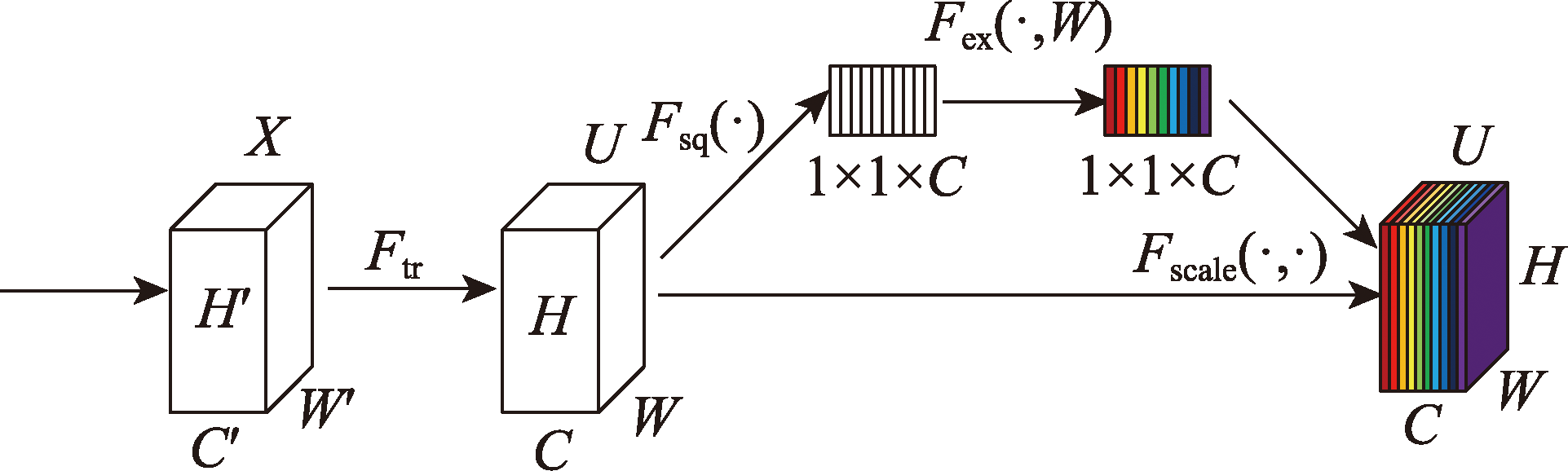
图8 SENet总体结构
Fig.8 Overall architecture of SENet

图9 DeepVoting整体框架
Fig.9 Overall framework of DeepVoting
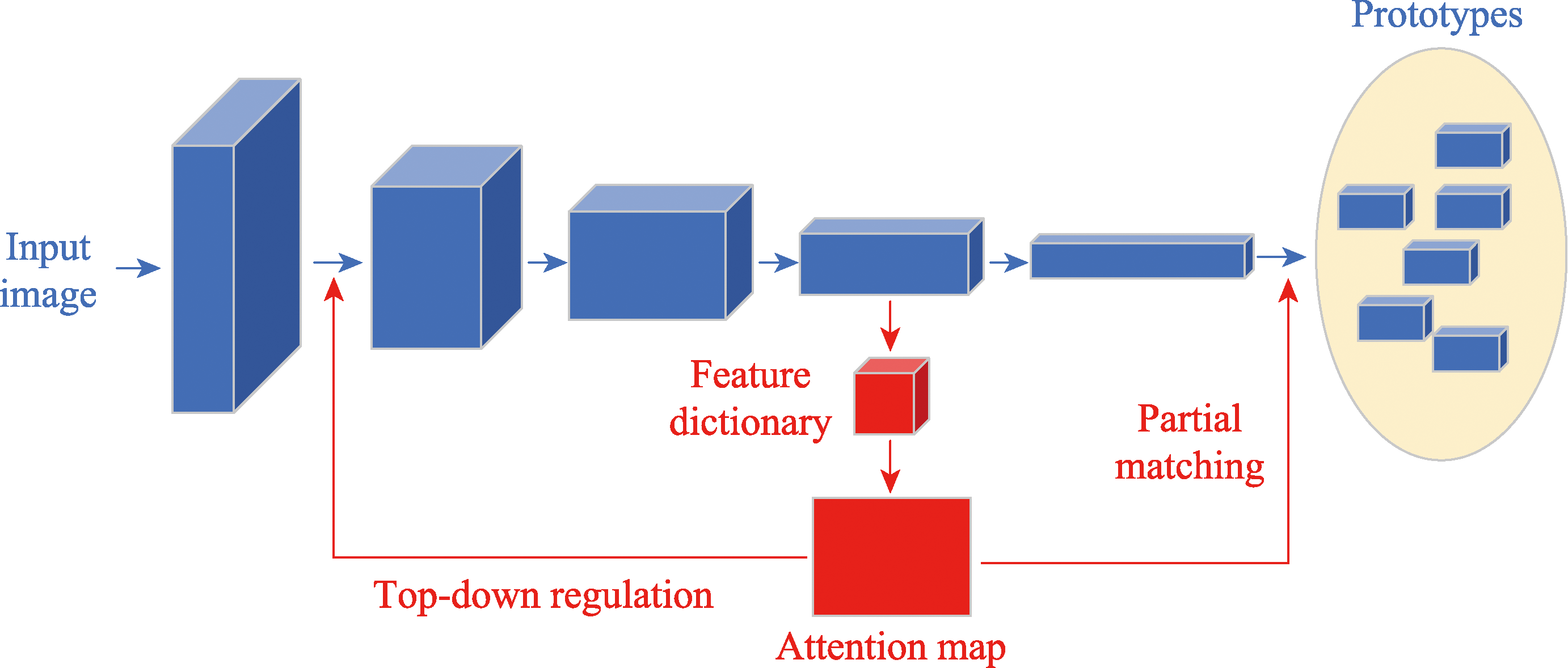
图10 TDAPNet结构图
Fig.10 Overall architecture of TDAPNet
| 算法类型 | 优势 | 局限性 | |
|---|---|---|---|
| 基于数据增强 | 实现简单,可作为另外两种方式的数据预处理手段 | 不符合现实情形,可能导致必要特征的缺失 | |
| 基于 整体 特征 | 基于目标结构 | 利用可见部分,有效降低遮挡物的干扰,特征信息利用率高,分类能力强 | 部件检测器消耗计算资源,数据集要求高,鲁棒性低 |
| 基于损失函数 | 可解释性,代价小 | 针对遮挡情形的设计难度较高 | |
| 基于非极大值抑制 | 适用范围广 | 不同场景的阈值设定具有差异化 | |
| 基于部分语义 | 鲁棒性高,对遮挡的适应性强 | 分类能力较弱,空间语义信息的获取难度较高 | |
表3 不同类型改进方案的比较
Table 3 Comparison of different types of programmes
| 算法类型 | 优势 | 局限性 | |
|---|---|---|---|
| 基于数据增强 | 实现简单,可作为另外两种方式的数据预处理手段 | 不符合现实情形,可能导致必要特征的缺失 | |
| 基于 整体 特征 | 基于目标结构 | 利用可见部分,有效降低遮挡物的干扰,特征信息利用率高,分类能力强 | 部件检测器消耗计算资源,数据集要求高,鲁棒性低 |
| 基于损失函数 | 可解释性,代价小 | 针对遮挡情形的设计难度较高 | |
| 基于非极大值抑制 | 适用范围广 | 不同场景的阈值设定具有差异化 | |
| 基于部分语义 | 鲁棒性高,对遮挡的适应性强 | 分类能力较弱,空间语义信息的获取难度较高 | |
| 遮挡检测算法 | 提出时间 | 数据集 | AP/% | MR-2/% |
|---|---|---|---|---|
| DeepParts | 2015 | KITTI | 58.7(部分遮挡) | — |
| Caltech | — | 12.9 | ||
| OR-CNN | 2018 | CityPersons | — | 5.9(轻度遮挡) 11.0(一般遮挡) 13.7(部分遮挡) 51.3(严重遮挡) |
| Caltech | — | 4.1 | ||
| CoupleNet | 2017 | PASCAL VOC | 82.7 | — |
| MS-COCO | 34.4 | — | ||
| 文献[52] | 2021 | CityPersons | — | 12.4(一般遮挡) 38.3(部分遮挡) 49.8(严重遮挡) |
| Caltech | — | 4.7(一般遮挡) 40.7(部分遮挡) 34.6(严重遮挡) | ||
| JointDet | 2019 | Caltech | — | 2.9 |
| CrowdHuman | — | 46.5 | ||
| CityPersons | — | 10.2 | ||
| DA-RCNN | 2019 | CrowdHuman | — | 51.8 |
| CrowdDet | 2020 | CrowdHuman | 90.7 | 41.4 |
| CityPersons | 96.1 | 10.7 | ||
| MS-COCO | 38.5 | — | ||
| MFRN | 2021 | CrowdHuman | 90.9 | 40.2 |
| CityPersons | 96.2 | 10.6 | ||
| Repulsion Loss | 2017 | CityPersons | — | 13.2 |
| Caltech | — | 4.0 | ||
| CrowdHuman | — | 54.6 | ||
| NMS Loss | 2021 | CityPersons | — | 10.1 |
| Caltech | — | 5.9 | ||
| Rep-GIoU Loss | 2022 | PASCAL VOC | 82.9 | — |
| FPN+NMS | 2017 | CrowdHuman | 88.1 | 42.9 |
| CityPersons | 95.2 | 11.8 | ||
| FPN+Soft-NMS | 2017 | CrowdHuman | 88.2 | 42.9 |
| CityPersons | 95.3 | 11.8 | ||
| MS-COCO | 38.0 | — | ||
| GossipNet | 2017 | CrowdHuman | 80.4 | 49.4 |
| PETS | 81.4 | — | ||
| MS-COCO | 66.6 | — | ||
| Softer-NMS | 2018 | MS-COCO | 40.4 | — |
| Adaptive-NMS | 2019 | CrowdHuman | 84.7 | 49.7 |
| CityPersons | — | 10.8 | ||
| R2NMS | 2020 | CrowdHuman | 89.3 | 43.4 |
| 文献[72] | 2021 | CityPersons | — | 9.3 |
| Caltech | — | 6.8 | ||
| 文献[74] | 2021 | CityPersons | — | 26.1 |
| Caltech | — | 4.5 | ||
| CrowHuman | — | 45.1 | ||
| 遮挡检测算法 | 提出时间 | 数据集 | AP/% | MR-2/% |
| DeepVoting | 2018 | VehicleSemanticPart | — | 74.0(无遮挡) 58.0(20%~40%) 46.9(40%~60%) 35.2(60%~80%) |
| CompositionalNets[ | 2020 | PASCAL3D+ | 89.5 | — |
| MNIST | 69.4 | — | ||
| TDAPNet | 2019 | PASCAL3D+ | 92.8 | — |
| MNIST | 69.3 | — | ||
| Kortylewski等[ | 2020 | PASCAL3D+ | 95.4 | — |
| Occluded-MS-COCO | 94.4 | — | ||
| Kortylewski等[ | 2021 | PASCAL3D+ | 84.1 | — |
| Occluded-MS-COCO | 95.0 | — | ||
| Wang等[ | 2020 | OccludedVehiclesDetection | 81.4 | — |
| OccludedCOCO | 91.8(0~20%) 83.6(20%~40%) 77.8(40%~60%) 65.4(60%~80%) 59.6(80%~100%) | — |
表4 遮挡检测算法的性能
Table 4 Performance of occlusion detection algorithms
| 遮挡检测算法 | 提出时间 | 数据集 | AP/% | MR-2/% |
|---|---|---|---|---|
| DeepParts | 2015 | KITTI | 58.7(部分遮挡) | — |
| Caltech | — | 12.9 | ||
| OR-CNN | 2018 | CityPersons | — | 5.9(轻度遮挡) 11.0(一般遮挡) 13.7(部分遮挡) 51.3(严重遮挡) |
| Caltech | — | 4.1 | ||
| CoupleNet | 2017 | PASCAL VOC | 82.7 | — |
| MS-COCO | 34.4 | — | ||
| 文献[52] | 2021 | CityPersons | — | 12.4(一般遮挡) 38.3(部分遮挡) 49.8(严重遮挡) |
| Caltech | — | 4.7(一般遮挡) 40.7(部分遮挡) 34.6(严重遮挡) | ||
| JointDet | 2019 | Caltech | — | 2.9 |
| CrowdHuman | — | 46.5 | ||
| CityPersons | — | 10.2 | ||
| DA-RCNN | 2019 | CrowdHuman | — | 51.8 |
| CrowdDet | 2020 | CrowdHuman | 90.7 | 41.4 |
| CityPersons | 96.1 | 10.7 | ||
| MS-COCO | 38.5 | — | ||
| MFRN | 2021 | CrowdHuman | 90.9 | 40.2 |
| CityPersons | 96.2 | 10.6 | ||
| Repulsion Loss | 2017 | CityPersons | — | 13.2 |
| Caltech | — | 4.0 | ||
| CrowdHuman | — | 54.6 | ||
| NMS Loss | 2021 | CityPersons | — | 10.1 |
| Caltech | — | 5.9 | ||
| Rep-GIoU Loss | 2022 | PASCAL VOC | 82.9 | — |
| FPN+NMS | 2017 | CrowdHuman | 88.1 | 42.9 |
| CityPersons | 95.2 | 11.8 | ||
| FPN+Soft-NMS | 2017 | CrowdHuman | 88.2 | 42.9 |
| CityPersons | 95.3 | 11.8 | ||
| MS-COCO | 38.0 | — | ||
| GossipNet | 2017 | CrowdHuman | 80.4 | 49.4 |
| PETS | 81.4 | — | ||
| MS-COCO | 66.6 | — | ||
| Softer-NMS | 2018 | MS-COCO | 40.4 | — |
| Adaptive-NMS | 2019 | CrowdHuman | 84.7 | 49.7 |
| CityPersons | — | 10.8 | ||
| R2NMS | 2020 | CrowdHuman | 89.3 | 43.4 |
| 文献[72] | 2021 | CityPersons | — | 9.3 |
| Caltech | — | 6.8 | ||
| 文献[74] | 2021 | CityPersons | — | 26.1 |
| Caltech | — | 4.5 | ||
| CrowHuman | — | 45.1 | ||
| 遮挡检测算法 | 提出时间 | 数据集 | AP/% | MR-2/% |
| DeepVoting | 2018 | VehicleSemanticPart | — | 74.0(无遮挡) 58.0(20%~40%) 46.9(40%~60%) 35.2(60%~80%) |
| CompositionalNets[ | 2020 | PASCAL3D+ | 89.5 | — |
| MNIST | 69.4 | — | ||
| TDAPNet | 2019 | PASCAL3D+ | 92.8 | — |
| MNIST | 69.3 | — | ||
| Kortylewski等[ | 2020 | PASCAL3D+ | 95.4 | — |
| Occluded-MS-COCO | 94.4 | — | ||
| Kortylewski等[ | 2021 | PASCAL3D+ | 84.1 | — |
| Occluded-MS-COCO | 95.0 | — | ||
| Wang等[ | 2020 | OccludedVehiclesDetection | 81.4 | — |
| OccludedCOCO | 91.8(0~20%) 83.6(20%~40%) 77.8(40%~60%) 65.4(60%~80%) 59.6(80%~100%) | — |
| [1] | GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich fea-ture hierarchies for accurate object detection and semantic segmentation[C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, Jun 20-23, 2014. Washington: IEEE Computer Society, 2014: 580-587. |
| [2] | EVERINGHAM M, VAN GOOL L, WILLIAMS C K I, et al. The Pascal visual object classes (VOC) challenge[J]. Inter-national Journal of Computer Vision, 2010, 88(2): 303-338. |
| [3] | LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot MultiBox detector[C]// LNCS 9905: Proceedings of the 14th European Conference on Computer Vision, Amsterdam, Oct 8-16, 2016. Cham: Springer, 2016: 21-37. |
| [4] | REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 779-788. |
| [5] | LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Oct 22-29, 2017. Washington: IEEE Computer Society, 2017: 2999-3007. |
| [6] |
HE K M, ZHANG X Y, REN S Q, et al. Spatial pyramid pooling in deep convolutional networks for visual recogni-tion[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916.
DOI URL |
| [7] | GIRSHICK R. Fast R-CNN[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Dec 13-16, 2015. Washington: IEEE Computer Society, 2015: 1440-1448. |
| [8] | REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]// Advances in Neural Information Processing Systems 28, Dec 7-12, 2015. Red Hook: Curran Associates, 2015: 91-99. |
| [9] | DAI J, LI Y, HE K, et al. R-FCN: object detection via region-based fully convolutional networks[C]// Advances in Neural Information Processing Systems 29, Barcelona, Dec 5-10, 2016. Red Hook: Curran Associates, 2016: 379-387. |
| [10] | HE K M, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Oct 22-29, 2017. Washington: IEEE Computer Society, 2017: 2980-2988. |
| [11] |
RENSINK R A, ENNS J T. Early completion of occluded objects[J]. Vision Research, 1998, 38(15/16): 2489-2505.
DOI URL |
| [12] | CHEN N, LI M L, YUAN H, et al. Survey of pedestrian detection with occlusion[J]. Complex & Intelligent Systems, 2021, 7(1): 577-587. |
| [13] | SALEH K, SZÉNÁSI S, VÁMOSSY Z. Occlusion handling in generic object detection: a review[C]// Proceedings of the 2021 IEEE 19th World Symposium on Applied Machine Intelligence and Informatics, Herl'any, Jan 21-23, 2021. Piscataway: IEEE, 2021. |
| [14] | SHANG M, XIANG D, WANG Z, et al. V2F-Net: explicit decomposition of occluded pedestrian detection[J]. arXiv: 2104.03106, 2021. |
| [15] | ZHANG S S, BENENSON R, OMRAN M, et al. How far are we from solving pedestrian detection?[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 1259-1267. |
| [16] | ZHANG S, WEN L, BIAN X, et al. Occlusion-aware R-CNN: detecting pedestrians in a crowd[C]// LNCS 11207: Proceedings of the 15th European Conference on Computer Vision, Munich, Sep 8-14, 2018. Cham: Springer, 2018: 657-674. |
| [17] |
LIU Y, JING X Y, NIE J H, et al. Context-aware three-dimensional mean-shift with occlusion handling for robust object tracking in RGB-D videos[J]. IEEE Transactions on Multimedia, 2019, 21(3): 664-677.
DOI URL |
| [18] | ONG J, VO B T, VO B N, et al. A Bayesian filter for multi-view 3D multi-object tracking with occlusion handling[J]. arXiv: 2001.04118, 2020. |
| [19] |
ZHAO S C, ZHANG S L, ZHANG L. Towards occlusion handling: object tracking with background estimation[J]. IEEE Transactions on Cybernetics, 2018, 48(7): 2086-2100.
DOI URL |
| [20] |
YANG S, LUO P, LOY C C, et al. Faceness-Net: face detec-tion through deep facial part responses[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(8): 1845-1859.
DOI URL |
| [21] | ZENG D, VELDHUIS R, SPREEUWERS L. A survey of face recognition techniques under occlusion[J]. arXiv: 2006.11366, 2020. |
| [22] | LI A, YUAN Z. SymmNet: a symmetric convolutional neural network for occlusion detection[J]. arXiv: 1807.00959, 2018. |
| [23] | GILROY S, JONES E, GLAVIN M. Overcoming occlusion in the automotive environment—a review[J]. IEEE Transac-tions on Intelligent Transportation Systems, 2021, 22(1): 23-35. |
| [24] | REDDY N D, VO M, NARASIMHAN S G. Occlusion-Net: 2D/3D occluded keypoint localization using graph net-works[C]// Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, Jun 16-20, 2019. Piscataway: IEEE, 2019: 7326-7335. |
| [25] |
YAN S Y, LIU Q S. Inferring occluded features for fast object detection[J]. Signal Processing, 2015, 110: 188-198.
DOI URL |
| [26] | FAWZI A, FROSSARD P. Measuring the effect of nuisance variables on classifiers[C]// Proceedings of the British Machine Vision Conference 2016, York, Sep 19-22, 2016. Durham: BMVA Press, 2016: 137. |
| [27] | LIN T Y, MAIRE M, BELONGIE S J, et al. Microsoft COCO: common objects in context[C]// LNCS 8693: Proceedings of the 13th European Conference on Computer Vision, Zurich, Sep 6-12, 2014. Cham: Springer, 2014: 740-755. |
| [28] | DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database[C]// Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, Jun 20-25, 2009. Washington: IEEE Computer Society, 2009: 248-255. |
| [29] |
KUZNETSOVA A, ROM H, ALLDRIN N, et al. The open images dataset v4[J]. International Journal of Computer Vision, 2020, 128(7): 1956-1981.
DOI URL |
| [30] | GEIGER A, LENZ P, URTASUN R. Are we ready for autonomous driving? The KITTI vision benchmark suite[C]// Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, Jun 16-21, 2012. Washington: IEEE Computer Society, 2012: 3354-3361. |
| [31] | DOLLÁR P, WOJEK C, SCHIELE B, et al. Pedestrian detection: a benchmark[C]// Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, Jun 20-25, 2009. Washington: IEEE Computer Society, 2009: 304-311. |
| [32] | DOLLÁR P, WOJEK C, SCHIELE B, et al. Pedestrian detec-tion: an evaluation of the state of the art[J]. IEEE Transac-tions on Pattern Analysis and Machine Intelligence, 2012, 34(4): 743-761. |
| [33] | ZHANG S S, BENENSON R, SCHIELE B. Citypersons: a diverse dataset for pedestrian detection[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 4457-4465. |
| [34] | WANG J, XIE C, ZHANG Z, et al. Detecting semantic parts on partially occluded objects[J]. arXiv:1707.07819, 2017. |
| [35] | WANG J, ZHANG Z, XIE C, et al. Unsupervised learning of object semantic parts from internal states of CNNs by population encoding[J]. arXiv:1511.06855, 2015. |
| [36] | SHAO S, ZHAO Z, LI B, et al. Crowdhuman: a benchmark for detecting human in a crowd[J]. arXiv: 1805.00123, 2018. |
| [37] | FERRYMAN J, SHAHROKNI A. Pets2009: dataset and challenge[C]// Proceedings of the 2009 12th IEEE Interna-tional Workshop on Performance Evaluation of Tracking and Surveillance, Snowbird, Dec 7-9, 2009. Washington: IEEE Computer Society, 2009: 1-6. |
| [38] | PATINO L, CANE T, VALLEE A, et al. PETS 2016: dataset and challenge[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, Jun 26-Jul 1, 2016. Washington: IEEE Computer Society, 2016: 1-8. |
| [39] | VIGNESH K, YADAV G K, SETHI A. Abnormal event detection on BMTT-PETS 2017 surveillance challenge[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 2161-2168. |
| [40] | EHSANI K, MOTTAGHI R, FARHADI A. SeGAN: seg-menting and generating the invisible[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-22, 2018. Washington: IEEE Computer Society, 2018: 6144-6153. |
| [41] | ADHIKARI B, PELTOMÄKI J, PUURA J, et al. Faster bou-nding box annotation for object detection in indoor scenes[C]// Proceedings of the 7th European Workshop on Visual Information Processing, Tamper, Nov 26-18, 2018. Piscata-way: IEEE, 2018: 1-6. |
| [42] | SINGH A, SHA J, NARAYAN K S, et al. Bigbird: a large-scale 3D database of object instances[C]// Proceedings of the 2014 IEEE International Conference on Robotics and Automation, Hong Kong, China, May 31-Jun 5, 2014. Pis-cataway: IEEE, 2014: 509-516. |
| [43] | WANG X L, SHRIVASTAVA A, GUPTA A. A-Fast-RCNN: hard positive generation via adversary for object detection[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 2606-2615. |
| [44] | GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]// Advances in Neural Infor-mation Processing Systems 27, Montreal, Dec 8-13, 2014. Red Hook: Curran Associates, 2014: 2672-2680. |
| [45] | DEVRIES T, TAYLOR G W. Improved regularization of convolutional neural networks with cutout[J]. arXiv:1708. 04552, 2017. |
| [46] | HINTON G E, SRIVASTAVA N, KRIZHEVSKY A, et al. Improving neural networks by preventing co-adaptation of feature detectors[J]. arXiv:1207.0580, 2012. |
| [47] | YUN S, HAN D, OH S J, et al. CutMix: regularization strategy to train strong classifiers with localizable features[C]// Proceedings of the 2019 IEEE/CVF International Con-ference on Computer Vision, Seoul, Oct 27-Nov 3, 2019. Piscataway: IEEE, 2019: 6022-6031. |
| [48] | 厍向阳, 李蕊心, 叶鸥. 融合随机擦除和残差注意力网络的行人重识别[J]. 计算机工程与应用, 2022, 58(3): 215-221. |
| SHE X Y, LI R X, YE O. Pedestrian re-identification combining random erasing and residual attention network[J]. Computer Engineering and Applications, 2022, 58(3): 215-221. | |
| [49] | TIAN Y L, LUO P, WANG X G, et al. Deep learning strong parts for pedestrian detection[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision, San-tiago, Dec 11-18, 2015. Washington: IEEE Computer Society, 2015: 1904-1912. |
| [50] | ZHOU C L, YUAN J S. Multi-label learning of part dete-ctors for occluded pedestrian detection[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Oct 22-29, 2017. Washington: IEEE Computer So-ciety, 2017: 3486-3495. |
| [51] | ZHU Y S, ZHAO C Y, WANG J Q, et al. CoupleNet: coupling global structure with local parts for object detec-tion[C]// Proceedings of the 2017 IEEE International Con-ference on Computer Vision, Venice, Oct 22-29, 2017. Wa-shington: IEEE Computer Society, 2017: 4146-4154. |
| [52] | LIU T R, LUO W H, MA L, et al. Coupled network for robust pedestrian detection with gated multi-layer feature extraction and deformable occlusion handling[J]. IEEE Trans-actions on Image Processing, 2021, 30: 754-766. |
| [53] | CHI C, ZHANG S F, XING J L, et al. Relational learning for joint head and human detection[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence, the 32nd Innovative Applications of Artificial Intelligence Conference, the 10th AAAI Symposium on Educational Advances in Artificial Intelligence, New York, Feb 7-12, 2020. Menlo Park: AAAI, 2020: 10647-10654. |
| [54] | ZHANG K, XIONG F, SUN P, et al. Double anchor R-CNN for human detection in a crowd[J]. arXiv: 1909.09998, 2019. |
| [55] | CHU X G, ZHENG A L, ZHANG X Y, et al. Detection in crowded scenes: one proposal, multiple predictions[C]// Pro-ceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 12211-12220. |
| [56] | LIN T Y, DOLLÁR P, GIRSHICK R B, et al. Feature pyramid networks for object detection[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 2117-2125. |
| [57] |
SHAO X T, WANG Q, YANG W, et al. Multi-scale feature pyramid network: a heavily occluded pedestrian detection network based on ResNet[J]. Sensors, 2021, 21(5): 1820.
DOI URL |
| [58] | YU J H, JIANG Y L, WANG Z Y, et al. UnitBox: an advanced object detection network[C]// Proceedings of the 2016 ACM Conference on Multimedia Conference, Amster-dam, Oct 15-19, 2016. New York: ACM, 2016: 516-520. |
| [59] | REZATOFIGHI H, TSOI N, GWAK J Y, et al. Generalized intersection over union: a metric and a loss for bounding box regression[C]// Proceedings of the 2019 IEEE Confer-ence on Computer Vision and Pattern Recognition, Long Beach, Jun 16-20, 2019. Piscataway: IEEE, 2019: 658-666. |
| [60] | ZHENG Z, WANG P, LIU W, et al. Distance-IoU loss: faster and better learning for bounding box regression[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence, the 32nd Innovative Applications of Artificial Intelligence Conference, the 10th AAAI Symposium on Educational Advances in Artificial Intelligence, New York, Feb 7-12, 2020. Menlo Park: AAAI, 2020: 12993-13000. |
| [61] | ZHANG Y F, REN W, ZHANG Z, et al. Focal and efficient IOU loss for accurate bounding box regression[J]. arXiv: 2101.08158, 2021. |
| [62] | WANG X L, XIAO T T, JIANG Y N, et al. Repulsion loss: detecting pedestrians in a crowd[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-22, 2018. Washington: IEEE Computer Society, 2018: 7774-7783. |
| [63] | 阳珊, 王建, 胡莉, 等. 改进RetinaNet的遮挡目标检测算法研究[J]. 计算机工程与应用, 2022, 58(11): 209-214. |
| YANG S, WANG J, HU L, et al. Research on occluded object detection by improved RetinaNet[J]. Computer Engineering and Applications, 2022, 58(11): 209-214. | |
| [64] | LUO Z K, FANG Z, ZHENG S X, et al. NMS-Loss: learning with non-maximum suppression for crowded pedestrian detec-tion[C]// Proceedings of the 2021 International Conference on Multimedia Retrieval, Taipei, China, Aug 21-24, 2021. New York: ACM, 2021: 481-485. |
| [65] | BODLA N, SINGH B, CHELLAPPA R, et al. Soft-NMS-improving object detection with one line of code[C]// Pro-ceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Oct 22-39, 2017. Washington: IEEE Computer Society, 2017: 5561-5569. |
| [66] | HOSANG J H, BENENSON R, SCHIELE B. Learning non-maximum suppression[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 6469-6477. |
| [67] | LIU S T, HUANG D, WANG Y H. Adaptive NMS: refining pedestrian detection in a crowd[C]// Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recogni-tion, Long Beach, Jun 16-20, 2019. Piscataway: IEEE, 2019: 6459-6468. |
| [68] | HE Y H, ZHU C C, WANG J R, et al. Bounding box regres-sion with uncertainty for accurate object detection[C]// Pro-ceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, Jun 16-20, 2019. Piscataway: IEEE, 2019: 2888-2897. |
| [69] | HUANG X, GE Z, JIE Z, et al. NMS by representative region: towards crowded pedestrian detection by proposal pairing[C]// Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 10750-10759. |
| [70] | HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-22, 2018. Washington: IEEE Computer Society, 2018: 7132-7141. |
| [71] | ZHANG S S, YANG J, SCHIELE B. Occluded pedestrian detection through guided attention in CNNs[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-22, 2018. Washington: IEEE Computer Society, 2018: 6995-7003. |
| [72] |
ZHANG S S, CHEN D, YANG J, et al. Guided attention in CNNs for occluded pedestrian detection and re-identification[J]. International Journal of Computer Vision, 2021, 129(6): 1875-1892.
DOI URL |
| [73] | PANG Y W, XIE J, KHAN M H, et al. Mask-guided atten-tion network for occluded pedestrian detection[C]// Procee-dings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Oct 27-Nov 2, 2019. Piscataway: IEEE, 2019: 4966-4974. |
| [74] |
XIE J, PANG Y W, KHAN M H, et al. Mask-guided atten-tion network and occlusion-sensitive hard example mining for occluded pedestrian detection[J]. IEEE Transactions on Image Processing, 2021, 30: 3872-3884.
DOI URL |
| [75] | ZHANG Z S, XIE C H, WANG J Y, et al. DeepVoting: a robust and explainable deep network for semantic part detec-tion under partial occlusion[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recogni-tion, Salt Lake City, Jun 18-22, 2018. Washington: IEEE Computer Society, 2018: 1372-1380. |
| [76] | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[J]. arXiv:1409. 1556, 2014. |
| [77] | KORTYLEWSKI A, LIU Q, WANG H Y, et al. Combining compositional models and deep networks for robust object classification under occlusion[C]// Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision, Snowmass Village, Mar 1-5, 2020. Piscataway: IEEE, 2020: 1322-1330. |
| [78] | XIAO M Q, KORTYLEWSKI A, WU R H, et al. TDAPNet: prototype network with recurrent top-down attention for robust object classification under partial occlusion[J]. arXiv: 1909.03879, 2019. |
| [79] | KORTYLEWSKI A, HE J, LIU Q, et al. Compositional con-volutional neural networks: a deep architecture with innate robustness to partial occlusion[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 8937-8946. |
| [80] |
KORTYLEWSKI A, LIU Q, WANG A T, et al. Compositional convolutional neural networks: a robust and interpretable model for object recognition under occlusion[J]. International Journal of Computer Vision, 2021, 129(3): 736-760.
DOI URL |
| [81] | WANG A T, SUN Y H, KORTYLEWSKI A, et al. Robust object detection under occlusion with context-aware compo-sitionalnets[C]// Proceedings of the 2020 IEEE/CVF Confer-ence on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 12642-12651. |
| [82] | DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image reco-gnition at scale[J]. arXiv: 2010.11929, 2020. |
| [83] | KHAN S, NASEER M, HAYAT M, et al. Transformers in vision: a survey[J]. arXiv: 2101.01169, 2021. |
| [1] | 安凤平, 李晓薇, 曹翔. 权重初始化-滑动窗口CNN的医学图像分类[J]. 计算机科学与探索, 2022, 16(8): 1885-1897. |
| [2] | 曾凡智, 许露倩, 周燕, 周月霞, 廖俊玮. 面向智慧教育的知识追踪模型研究综述[J]. 计算机科学与探索, 2022, 16(8): 1742-1763. |
| [3] | 刘艺, 李蒙蒙, 郑奇斌, 秦伟, 任小广. 视频目标跟踪算法综述[J]. 计算机科学与探索, 2022, 16(7): 1504-1515. |
| [4] | 赵小明, 杨轶娇, 张石清. 面向深度学习的多模态情感识别研究进展[J]. 计算机科学与探索, 2022, 16(7): 1479-1503. |
| [5] | 夏鸿斌, 肖奕飞, 刘渊. 融合自注意力机制的长文本生成对抗网络模型[J]. 计算机科学与探索, 2022, 16(7): 1603-1610. |
| [6] | 刘雅芬, 郑艺峰, 江铃燚, 李国和, 张文杰. 深度半监督学习中伪标签方法综述[J]. 计算机科学与探索, 2022, 16(6): 1279-1290. |
| [7] | 程卫月, 张雪琴, 林克正, 李骜. 融合全局与局部特征的深度卷积神经网络算法[J]. 计算机科学与探索, 2022, 16(5): 1146-1154. |
| [8] | 钟梦圆, 姜麟. 超分辨率图像重建算法综述[J]. 计算机科学与探索, 2022, 16(5): 972-990. |
| [9] | 裴利沈, 赵雪专. 群体行为识别深度学习方法研究综述[J]. 计算机科学与探索, 2022, 16(4): 775-790. |
| [10] | 许嘉, 韦婷婷, 于戈, 黄欣悦, 吕品. 题目难度评估方法研究综述[J]. 计算机科学与探索, 2022, 16(4): 734-759. |
| [11] | 朱伟杰, 陈莹. 双流时间域信息交互的微表情识别卷积网络[J]. 计算机科学与探索, 2022, 16(4): 950-958. |
| [12] | 张全贵, 胡嘉燕, 王丽. 耦合用户公共特征的单类协同过滤推荐算法[J]. 计算机科学与探索, 2022, 16(3): 637-648. |
| [13] | 姜艺, 胥加洁, 柳絮, 朱俊武. 边缘指导图像修复算法研究[J]. 计算机科学与探索, 2022, 16(3): 669-682. |
| [14] | 邬开俊, 黄涛, 王迪聪, 白晨帅, 陶小苗. 视频异常检测技术研究进展[J]. 计算机科学与探索, 2022, 16(3): 529-540. |
| [15] | 刘利平, 孙建, 高世妍. 单图像盲去模糊方法概述[J]. 计算机科学与探索, 2022, 16(3): 552-564. |
| 阅读次数 | ||||||||||||||||||||||||||||||||||||||||||||||||||
|
全文 1183
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||
|
摘要 2366
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||