
计算机科学与探索 ›› 2022, Vol. 16 ›› Issue (9): 2151-2162.DOI: 10.3778/j.issn.1673-9418.2102070
罗逸轩1,2, 刘建华1,2,+( ), 胡任远1,2, 张冬阳1,2, 卜冠南1,2
), 胡任远1,2, 张冬阳1,2, 卜冠南1,2
收稿日期:2021-03-01
修回日期:2021-05-08
出版日期:2022-09-01
发布日期:2021-05-18
通讯作者:
+ E-mail: jhliu@fjnu.edu.cn作者简介:罗逸轩(1996—),男,福建福州人,硕士研究生,CCF会员,主要研究方向为智能计算、强化学习。基金资助:
LUO Yixuan1,2, LIU Jianhua1,2,+(), HU Renyuan1,2, ZHANG Dongyang1,2, BU Guannan1,2
Received:2021-03-01
Revised:2021-05-08
Online:2022-09-01
Published:2021-05-18
About author:LUO Yixuan, born in 1996, M.S. candidate,member of CCF. His research interests include computational intelligence and reinforcement learning.Supported by:摘要:
传统粒子群优化算法(PSO)有着易陷入局部最优、多样性不足和精度低等缺点。近年来,采用强化学习的Q学习思想改进粒子群算法成为一种新的方法,然而目前这种方法存在参数选择偏主观和使用策略单一使其无法解决复杂情况的问题。提出一种融合经验共享策略Q学习的粒子群优化算法(QLPSOES)。该算法将粒子群算法与Q学习方法结合,对每个粒子构建一张Q表,供粒子参数动态选择;同时设计了一种经验共享策略,即粒子通过Q表共享最优粒子的“行为经验”,加速Q表的收敛,增强粒子之间的学习能力,平衡算法的全局和局部搜索能力。另外,采用正交分析法实验,寻找融合Q学习粒子群算法的状态、动作参数和奖励函数等参数的最优组合;最后通过CEC2013中的基准测试函数的实验测试,结果表明,融合经验共享Q学习的粒子群算法的收敛速度和收敛精度相对给出的对比算法均有明显提升,验证了算法具有较优的性能。
中图分类号:
罗逸轩, 刘建华, 胡任远, 张冬阳, 卜冠南. 融合经验共享Q学习的粒子群优化算法[J]. 计算机科学与探索, 2022, 16(9): 2151-2162.
LUO Yixuan, LIU Jianhua, HU Renyuan, ZHANG Dongyang, BU Guannan. Particle Swarm Optimization Combined with Q-learning of Experience Sharing Strategy[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(9): 2151-2162.

图1 Q学习主要组成
Fig.1 Composition of Q-learning
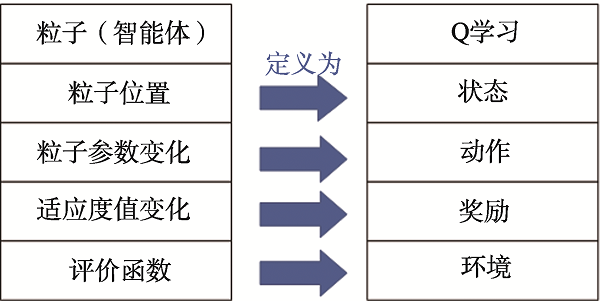
图2 QL与PSO算法的关系
Fig.2 Correspondence between QL and PSO

图3 三维Q表
Fig.3 3-D Q table

图4 决策空间状态
Fig.4 Decision space state
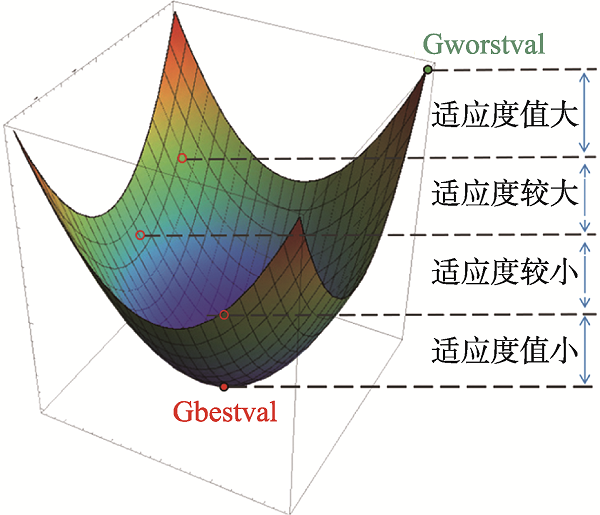
图5 目标空间状态
Fig.5 Objective space state
| 动作名称 | 动作参数 | 收敛速度 | ||
|---|---|---|---|---|
| w | c1 | c2 | ||
| 全局探索 | 大 | 大 | 小 | 慢 |
| 综合搜索 | 中 | 中 | 中 | 中 |
| 局部开发 | 小 | 小 | 大 | 快 |
表1 动作
Table 1 Action
| 动作名称 | 动作参数 | 收敛速度 | ||
|---|---|---|---|---|
| w | c1 | c2 | ||
| 全局探索 | 大 | 大 | 小 | 慢 |
| 综合搜索 | 中 | 中 | 中 | 中 |
| 局部开发 | 小 | 小 | 大 | 快 |
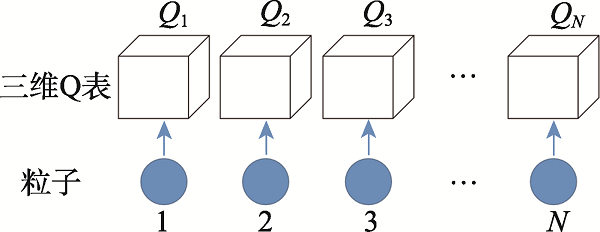
图6 每个粒子均赋予Q表
Fig.6 Q table of each particle

图7 经验共享策略
Fig.7 Experience sharing strategy

图8 QLPSOES算法框架
Fig.8 Framework of QLPSOES
| 编号 | 函数名 | 最优解 |
|---|---|---|
| f1 | Sphere function | -1 400 |
| f2 | Rotated high conditioned elliptic function | -1 300 |
| f3 | Rotated bent cigar function | -1 200 |
| f4 | Rotated discus function | -1 100 |
| f5 | Different powers function | -1 000 |
| f6 | Rotated Rosenbrock's function | -900 |
| f7 | Rotated Schaffer's F7 function | -800 |
| f8 | Rotated Ackley's function | -700 |
| f9 | Rotated Weierstrass function | -600 |
| f10 | Rotated Griewank's function | -500 |
| f11 | Rastrigin's function | -400 |
| f12 | Rotated Rastrigin's function | -300 |
| f13 | Non-continuous rotated Rastrigin's function | -200 |
| f14 | Schwefel's function | -100 |
| f15 | Rotated Schwefel's function | 100 |
| f16 | Rotated Katsuura function | 200 |
| f17 | Lunacek Bi_Rastrigin function | 300 |
| f18 | Rotated Lunacek Bi_Rastrigin function | 400 |
| f19 | Expanded Griewank's plus Rosenbrock's function | 500 |
| f20 | Expanded Scaffer's F6 function | 600 |
| f21 | Composition function 1 (n=5, Rotated) | 700 |
| f22 | Composition function 2 (n=3, Unrotated) | 800 |
| f23 | Composition function 3 (n=3, Rotated) | 900 |
| f24 | Composition function 4 (n=3, Rotated) | 1 000 |
| f25 | Composition function 5 (n=3, Rotated) | 1 100 |
| f26 | Composition function 6 (n=5, Rotated) | 1 200 |
| f27 | Composition function 7 (n=5, Rotated) | 1 300 |
| f28 | Composition function 8 (n=5, Rotated) | 1 400 |
表2 CEC2013测试函数
Table 2 CEC2013 benchmark functions
| 编号 | 函数名 | 最优解 |
|---|---|---|
| f1 | Sphere function | -1 400 |
| f2 | Rotated high conditioned elliptic function | -1 300 |
| f3 | Rotated bent cigar function | -1 200 |
| f4 | Rotated discus function | -1 100 |
| f5 | Different powers function | -1 000 |
| f6 | Rotated Rosenbrock's function | -900 |
| f7 | Rotated Schaffer's F7 function | -800 |
| f8 | Rotated Ackley's function | -700 |
| f9 | Rotated Weierstrass function | -600 |
| f10 | Rotated Griewank's function | -500 |
| f11 | Rastrigin's function | -400 |
| f12 | Rotated Rastrigin's function | -300 |
| f13 | Non-continuous rotated Rastrigin's function | -200 |
| f14 | Schwefel's function | -100 |
| f15 | Rotated Schwefel's function | 100 |
| f16 | Rotated Katsuura function | 200 |
| f17 | Lunacek Bi_Rastrigin function | 300 |
| f18 | Rotated Lunacek Bi_Rastrigin function | 400 |
| f19 | Expanded Griewank's plus Rosenbrock's function | 500 |
| f20 | Expanded Scaffer's F6 function | 600 |
| f21 | Composition function 1 (n=5, Rotated) | 700 |
| f22 | Composition function 2 (n=3, Unrotated) | 800 |
| f23 | Composition function 3 (n=3, Rotated) | 900 |
| f24 | Composition function 4 (n=3, Rotated) | 1 000 |
| f25 | Composition function 5 (n=3, Rotated) | 1 100 |
| f26 | Composition function 6 (n=5, Rotated) | 1 200 |
| f27 | Composition function 7 (n=5, Rotated) | 1 300 |
| f28 | Composition function 8 (n=5, Rotated) | 1 400 |
| 决策空间状态Ⅰ(SⅠ) | 决策空间状态Ⅱ(SⅡ) | 决策空间状态Ⅲ(SⅢ) |
|---|---|---|
| 0<d<0.125∆R | 0<d<0.25∆R | 0<d<(0.25→0.10)∆R |
| 0.125∆R<d<0.250∆R | 0.25∆R<d<0.50∆R | (0.25→0.10)∆R<d<(0.50→0.20)∆R |
| 0.250∆R<d<0.500∆R | 0.50∆R<d<0.75∆R | (0.50→0.20)∆R<d<(0.75→0.30)∆R |
| 0.500∆R <d | 0.75∆R<d | (0.75→0.30)∆R<d |
表3 决策空间状态参数设置
Table 3 Setting of decision space state parameters
| 决策空间状态Ⅰ(SⅠ) | 决策空间状态Ⅱ(SⅡ) | 决策空间状态Ⅲ(SⅢ) |
|---|---|---|
| 0<d<0.125∆R | 0<d<0.25∆R | 0<d<(0.25→0.10)∆R |
| 0.125∆R<d<0.250∆R | 0.25∆R<d<0.50∆R | (0.25→0.10)∆R<d<(0.50→0.20)∆R |
| 0.250∆R<d<0.500∆R | 0.50∆R<d<0.75∆R | (0.50→0.20)∆R<d<(0.75→0.30)∆R |
| 0.500∆R <d | 0.75∆R<d | (0.75→0.30)∆R<d |
| 动作名称 | 动作参数Ⅰ(AⅠ) | 动作参数Ⅱ(AⅡ) | 动作参数Ⅲ(AⅢ) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| c1 | c2 | w | c1 | c2 | w | c1 | c2 | w | |
| 全局探索 | 2.5 | 0.5 | 0.68 | 2.5 | 0.5 | 0.9~0.4 | 2.043 4 | 0.948 7 | 0.729 8 |
| 综合搜索 | 1.5 | 1.5 | 0.68 | 1.5 | 1.5 | 0.9~0.4 | 1.496 0 | 1.496 0 | 0.729 8 |
| 局部开发 | 0.5 | 2.5 | 0.68 | 0.5 | 2.5 | 0.9~0.4 | 0.948 7 | 2.043 4 | 0.729 8 |
表4 动作参数设置
Table 4 Setting of action parameters
| 动作名称 | 动作参数Ⅰ(AⅠ) | 动作参数Ⅱ(AⅡ) | 动作参数Ⅲ(AⅢ) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| c1 | c2 | w | c1 | c2 | w | c1 | c2 | w | |
| 全局探索 | 2.5 | 0.5 | 0.68 | 2.5 | 0.5 | 0.9~0.4 | 2.043 4 | 0.948 7 | 0.729 8 |
| 综合搜索 | 1.5 | 1.5 | 0.68 | 1.5 | 1.5 | 0.9~0.4 | 1.496 0 | 1.496 0 | 0.729 8 |
| 局部开发 | 0.5 | 2.5 | 0.68 | 0.5 | 2.5 | 0.9~0.4 | 0.948 7 | 2.043 4 | 0.729 8 |
| 奖励函数Ⅰ | 奖励函数Ⅱ | 奖励函数Ⅲ |
|---|---|---|
| | | |
表5 奖励函数
Table 5 Reward functions
| 奖励函数Ⅰ | 奖励函数Ⅱ | 奖励函数Ⅲ |
|---|---|---|
| | | |
| 水平 | 因素 | ||
|---|---|---|---|
| 目标状态空间 | 动作参数 | 奖励函数 | |
| 1 | SⅠ | AⅠ | RⅠ |
| 2 | SⅡ | AⅡ | RⅡ |
| 3 | SⅢ | AⅢ | RⅢ |
表6 参数因素水平表
Table 6 Factors and levels of parameters
| 水平 | 因素 | ||
|---|---|---|---|
| 目标状态空间 | 动作参数 | 奖励函数 | |
| 1 | SⅠ | AⅠ | RⅠ |
| 2 | SⅡ | AⅡ | RⅡ |
| 3 | SⅢ | AⅢ | RⅢ |
| 实验号 | 因素1 | 因素2 | 因素3 | rank |
|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 5.21 |
| 2 | 1 | 2 | 2 | 2.25 |
| 3 | 1 | 3 | 3 | 6.86 |
| 4 | 2 | 1 | 2 | 6.14 |
| 5 | 2 | 2 | 3 | 2.14 |
| 6 | 2 | 3 | 1 | 6.36 |
| 7 | 3 | 1 | 3 | 7.29 |
| 8 | 3 | 2 | 1 | 2.07 |
| 9 | 3 | 3 | 2 | 6.68 |
表7 正交方案与实验结果
Table 7 Orthogonal experiment and results
| 实验号 | 因素1 | 因素2 | 因素3 | rank |
|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 5.21 |
| 2 | 1 | 2 | 2 | 2.25 |
| 3 | 1 | 3 | 3 | 6.86 |
| 4 | 2 | 1 | 2 | 6.14 |
| 5 | 2 | 2 | 3 | 2.14 |
| 6 | 2 | 3 | 1 | 6.36 |
| 7 | 3 | 1 | 3 | 7.29 |
| 8 | 3 | 2 | 1 | 2.07 |
| 9 | 3 | 3 | 2 | 6.68 |
| 结果 | S | A | R |
|---|---|---|---|
| k1 | 4.773 3 | 6.213 3 | 4.546 7 |
| k2 | 4.880 0 | 2.153 3 | 5.023 3 |
| k3 | 5.346 7 | 6.633 3 | 5.430 0 |
| 极差R | 0.573 3 | 4.480 0 | 0.883 3 |
| 优水平 | SⅠ | AⅡ | RⅠ |
| 优组合 | SⅠAⅡRⅠ | ||
表8 极差分析表
Table 8 Range analysis
| 结果 | S | A | R |
|---|---|---|---|
| k1 | 4.773 3 | 6.213 3 | 4.546 7 |
| k2 | 4.880 0 | 2.153 3 | 5.023 3 |
| k3 | 5.346 7 | 6.633 3 | 5.430 0 |
| 极差R | 0.573 3 | 4.480 0 | 0.883 3 |
| 优水平 | SⅠ | AⅡ | RⅠ |
| 优组合 | SⅠAⅡRⅠ | ||
| 源 | Ⅲ类平方和 | df | 均方 | F | sig. |
|---|---|---|---|---|---|
| 修正模型 | 38.461a | 6 | 6.410 | 21.905 | 0.044 |
| 截距 | 225.000 | 1 | 225.000 | 768.880 | 0.001 |
| S | 0.558 | 2 | 0.279 | 0.953 | 0.512 |
| A | 36.730 | 2 | 18.365 | 62.758 | 0.016 |
| R | 1.173 | 2 | 0.586 | 2.004 | 0.333 |
| 误差 | 0.585 | 2 | 0.293 | ||
| 总计 | 264.046 | 9 | |||
| 修正总计 | 39.046 | 8 |
表9 主体间效应的检验(因变量:rank)
Table 9 Test of intersubjective effect (rank)
| 源 | Ⅲ类平方和 | df | 均方 | F | sig. |
|---|---|---|---|---|---|
| 修正模型 | 38.461a | 6 | 6.410 | 21.905 | 0.044 |
| 截距 | 225.000 | 1 | 225.000 | 768.880 | 0.001 |
| S | 0.558 | 2 | 0.279 | 0.953 | 0.512 |
| A | 36.730 | 2 | 18.365 | 62.758 | 0.016 |
| R | 1.173 | 2 | 0.586 | 2.004 | 0.333 |
| 误差 | 0.585 | 2 | 0.293 | ||
| 总计 | 264.046 | 9 | |||
| 修正总计 | 39.046 | 8 |
| 决策空间状态 | 动作参数 | 奖励函数 | ||
|---|---|---|---|---|
| c1 | c2 | w | ||
| 0<d<0.125∆R | 2.5 | 0.5 | 0.9~0.4 | |
| 0.125∆R<d<0.250∆R | 1.5 | 1.5 | 0.9~0.4 | |
| 0.250∆R<d<0.500∆R | 0.5 | 2.5 | 0.9~0.4 | |
| 0.500∆R<d | ||||
表10 QLPSOES参数组合
Table 10 Parameters of QLPSOES
| 决策空间状态 | 动作参数 | 奖励函数 | ||
|---|---|---|---|---|
| c1 | c2 | w | ||
| 0<d<0.125∆R | 2.5 | 0.5 | 0.9~0.4 | |
| 0.125∆R<d<0.250∆R | 1.5 | 1.5 | 0.9~0.4 | |
| 0.250∆R<d<0.500∆R | 0.5 | 2.5 | 0.9~0.4 | |
| 0.500∆R<d | ||||
| 种群数N | 维度D | 迭代次数Miter | 实验次数 |
|---|---|---|---|
| 30 | 30 | 150 000 | 51 |
表11 实验的参数设置
Table 11 Parameter setting for experiment
| 种群数N | 维度D | 迭代次数Miter | 实验次数 |
|---|---|---|---|
| 30 | 30 | 150 000 | 51 |
| 函数 | QLPSOES | QLPSO-1D | QLPSO-2D | QLSOPSO | HPSO | HCPSO |
|---|---|---|---|---|---|---|
| f1 | 9.42E-04 | 2.22E-13 | 2.18E-13 | 9.01E+01 | 2.52E-02 | 1.62E-01 |
| f2 | 1.16E+07 | 1.36E+07 | 1.16E+07 | 1.79E+07 | 3.89E+06 | 1.13E+07 |
| f3 | 3.61E+08 | 5.67E+07 | 5.40E+07 | 7.37E+08 | 4.60E+08 | 3.88E+08 |
| f4 | 2.44E+02 | 7.51E+03 | 6.37E+03 | 1.97E+03 | 5.59E+02 | 1.15E+02 |
| f5 | 1.38E-02 | 1.56E-13 | 1.32E-13 | 1.54E+02 | 7.46E-02 | 2.27E-01 |
| f6 | 1.03E+02 | 8.96E+01 | 8.35E+01 | 1.32E+02 | 6.40E+01 | 9.96E+01 |
| f7 | 4.43E+01 | 3.33E+01 | 3.27E+01 | 3.51E+01 | 7.17E+01 | 4.21E+01 |
| f8 | 2.08E+01 | 2.10E+01 | 2.10E+01 | 2.08E+01 | 2.08E+01 | 2.08E+01 |
| f9 | 2.22E+01 | 2.35E+01 | 2.20E+01 | 2.48E+01 | 2.62E+01 | 2.24E+01 |
| f10 | 6.24E-01 | 1.52E-01 | 1.28E-01 | 5.46E+01 | 1.75E+00 | 1.91E+00 |
| f11 | 4.20E+01 | 4.38E+01 | 4.44E+01 | 5.26E+01 | 6.48E+01 | 8.46E+01 |
| f12 | 8.40E+01 | 6.58E+01 | 5.50E+01 | 9.04E+01 | 8.81E+01 | 8.63E+01 |
| f13 | 1.33E+02 | 1.27E+02 | 1.30E+02 | 1.41E+02 | 1.67E+02 | 1.45E+02 |
| f14 | 1.18E+03 | 1.82E+03 | 1.84E+03 | 3.05E+03 | 1.82E+03 | 2.34E+03 |
| f15 | 3.85E+03 | 6.95E+03 | 5.83E+03 | 4.54E+03 | 3.66E+03 | 5.16E+03 |
| f16 | 1.15E+00 | 2.58E+00 | 2.54E+00 | 1.41E+00 | 1.31E+00 | 1.94E+00 |
| f17 | 1.03E+02 | 8.37E+01 | 8.66E+01 | 1.67E+02 | 1.29E+02 | 1.86E+02 |
| f18 | 1.27E+02 | 2.08E+02 | 1.73E+02 | 1.53E+02 | 1.34E+02 | 1.90E+02 |
| f19 | 7.14E+00 | 4.11E+00 | 4.08E+00 | 1.06E+01 | 9.79E+00 | 1.41E+01 |
| f20 | 1.42E+01 | 1.19E+01 | 1.16E+01 | 1.40E+01 | 1.13E+01 | 1.12E+01 |
| f21 | 2.90E+02 | 2.92E+02 | 3.10E+02 | 3.68E+02 | 3.43E+02 | 3.07E+02 |
| f22 | 1.67E+03 | 1.98E+03 | 1.89E+03 | 3.32E+03 | 2.07E+03 | 2.48E+03 |
| f23 | 3.93E+03 | 6.27E+03 | 5.74E+03 | 4.64E+03 | 3.92E+03 | 5.49E+03 |
| f24 | 2.67E+02 | 2.62E+02 | 2.63E+02 | 2.72E+02 | 2.77E+02 | 2.73E+02 |
| f25 | 2.85E+02 | 2.86E+02 | 2.85E+02 | 2.89E+02 | 2.87E+02 | 2.91E+02 |
| f26 | 2.67E+02 | 3.01E+02 | 2.95E+02 | 2.45E+02 | 2.26E+02 | 2.00E+02 |
| f27 | 8.98E+02 | 8.83E+02 | 9.03E+02 | 9.54E+02 | 9.98E+02 | 9.30E+02 |
| f28 | 3.14E+02 | 3.88E+02 | 3.23E+02 | 8.72E+02 | 4.41E+02 | 4.32E+02 |
表12 函数测试实验结果
Table 12 Experimental results of function test
| 函数 | QLPSOES | QLPSO-1D | QLPSO-2D | QLSOPSO | HPSO | HCPSO |
|---|---|---|---|---|---|---|
| f1 | 9.42E-04 | 2.22E-13 | 2.18E-13 | 9.01E+01 | 2.52E-02 | 1.62E-01 |
| f2 | 1.16E+07 | 1.36E+07 | 1.16E+07 | 1.79E+07 | 3.89E+06 | 1.13E+07 |
| f3 | 3.61E+08 | 5.67E+07 | 5.40E+07 | 7.37E+08 | 4.60E+08 | 3.88E+08 |
| f4 | 2.44E+02 | 7.51E+03 | 6.37E+03 | 1.97E+03 | 5.59E+02 | 1.15E+02 |
| f5 | 1.38E-02 | 1.56E-13 | 1.32E-13 | 1.54E+02 | 7.46E-02 | 2.27E-01 |
| f6 | 1.03E+02 | 8.96E+01 | 8.35E+01 | 1.32E+02 | 6.40E+01 | 9.96E+01 |
| f7 | 4.43E+01 | 3.33E+01 | 3.27E+01 | 3.51E+01 | 7.17E+01 | 4.21E+01 |
| f8 | 2.08E+01 | 2.10E+01 | 2.10E+01 | 2.08E+01 | 2.08E+01 | 2.08E+01 |
| f9 | 2.22E+01 | 2.35E+01 | 2.20E+01 | 2.48E+01 | 2.62E+01 | 2.24E+01 |
| f10 | 6.24E-01 | 1.52E-01 | 1.28E-01 | 5.46E+01 | 1.75E+00 | 1.91E+00 |
| f11 | 4.20E+01 | 4.38E+01 | 4.44E+01 | 5.26E+01 | 6.48E+01 | 8.46E+01 |
| f12 | 8.40E+01 | 6.58E+01 | 5.50E+01 | 9.04E+01 | 8.81E+01 | 8.63E+01 |
| f13 | 1.33E+02 | 1.27E+02 | 1.30E+02 | 1.41E+02 | 1.67E+02 | 1.45E+02 |
| f14 | 1.18E+03 | 1.82E+03 | 1.84E+03 | 3.05E+03 | 1.82E+03 | 2.34E+03 |
| f15 | 3.85E+03 | 6.95E+03 | 5.83E+03 | 4.54E+03 | 3.66E+03 | 5.16E+03 |
| f16 | 1.15E+00 | 2.58E+00 | 2.54E+00 | 1.41E+00 | 1.31E+00 | 1.94E+00 |
| f17 | 1.03E+02 | 8.37E+01 | 8.66E+01 | 1.67E+02 | 1.29E+02 | 1.86E+02 |
| f18 | 1.27E+02 | 2.08E+02 | 1.73E+02 | 1.53E+02 | 1.34E+02 | 1.90E+02 |
| f19 | 7.14E+00 | 4.11E+00 | 4.08E+00 | 1.06E+01 | 9.79E+00 | 1.41E+01 |
| f20 | 1.42E+01 | 1.19E+01 | 1.16E+01 | 1.40E+01 | 1.13E+01 | 1.12E+01 |
| f21 | 2.90E+02 | 2.92E+02 | 3.10E+02 | 3.68E+02 | 3.43E+02 | 3.07E+02 |
| f22 | 1.67E+03 | 1.98E+03 | 1.89E+03 | 3.32E+03 | 2.07E+03 | 2.48E+03 |
| f23 | 3.93E+03 | 6.27E+03 | 5.74E+03 | 4.64E+03 | 3.92E+03 | 5.49E+03 |
| f24 | 2.67E+02 | 2.62E+02 | 2.63E+02 | 2.72E+02 | 2.77E+02 | 2.73E+02 |
| f25 | 2.85E+02 | 2.86E+02 | 2.85E+02 | 2.89E+02 | 2.87E+02 | 2.91E+02 |
| f26 | 2.67E+02 | 3.01E+02 | 2.95E+02 | 2.45E+02 | 2.26E+02 | 2.00E+02 |
| f27 | 8.98E+02 | 8.83E+02 | 9.03E+02 | 9.54E+02 | 9.98E+02 | 9.30E+02 |
| f28 | 3.14E+02 | 3.88E+02 | 3.23E+02 | 8.72E+02 | 4.41E+02 | 4.32E+02 |
| 平均排名 | 算法 | 综合rank | 单峰函数rank | 多峰函数rank | 复杂函数rank | 时间复杂度 |
|---|---|---|---|---|---|---|
| 1 | QLPSOES | 2.55 | 2.9 | 2.77 | 1.94 | O(Max_FEs×N×D) |
| 2 | QLPSO-2D | 2.73 | 2.3 | 2.70 | 3.06 | O(Max_FEs×N2×D) |
| 3 | QLPSO-1D | 3.25 | 3.4 | 3.27 | 3.13 | O(Max_FEs×N2×D) |
| 4 | HCPSO | 3.68 | 3.4 | 3.53 | 4.13 | O(Max_FEs×N×D) |
| 5 | HPSO | 4.05 | 3.4 | 4.30 | 4.00 | O(Max_FEs×N×D) |
| 6 | QLPSOPSO | 4.73 | 5.6 | 4.43 | 4.75 | O(Max_FEs×N×D) |
表13 算法的弗里德曼检测与时间复杂度比较
Table 13 Friedman test and time complexity comparison of algorithms
| 平均排名 | 算法 | 综合rank | 单峰函数rank | 多峰函数rank | 复杂函数rank | 时间复杂度 |
|---|---|---|---|---|---|---|
| 1 | QLPSOES | 2.55 | 2.9 | 2.77 | 1.94 | O(Max_FEs×N×D) |
| 2 | QLPSO-2D | 2.73 | 2.3 | 2.70 | 3.06 | O(Max_FEs×N2×D) |
| 3 | QLPSO-1D | 3.25 | 3.4 | 3.27 | 3.13 | O(Max_FEs×N2×D) |
| 4 | HCPSO | 3.68 | 3.4 | 3.53 | 4.13 | O(Max_FEs×N×D) |
| 5 | HPSO | 4.05 | 3.4 | 4.30 | 4.00 | O(Max_FEs×N×D) |
| 6 | QLPSOPSO | 4.73 | 5.6 | 4.43 | 4.75 | O(Max_FEs×N×D) |
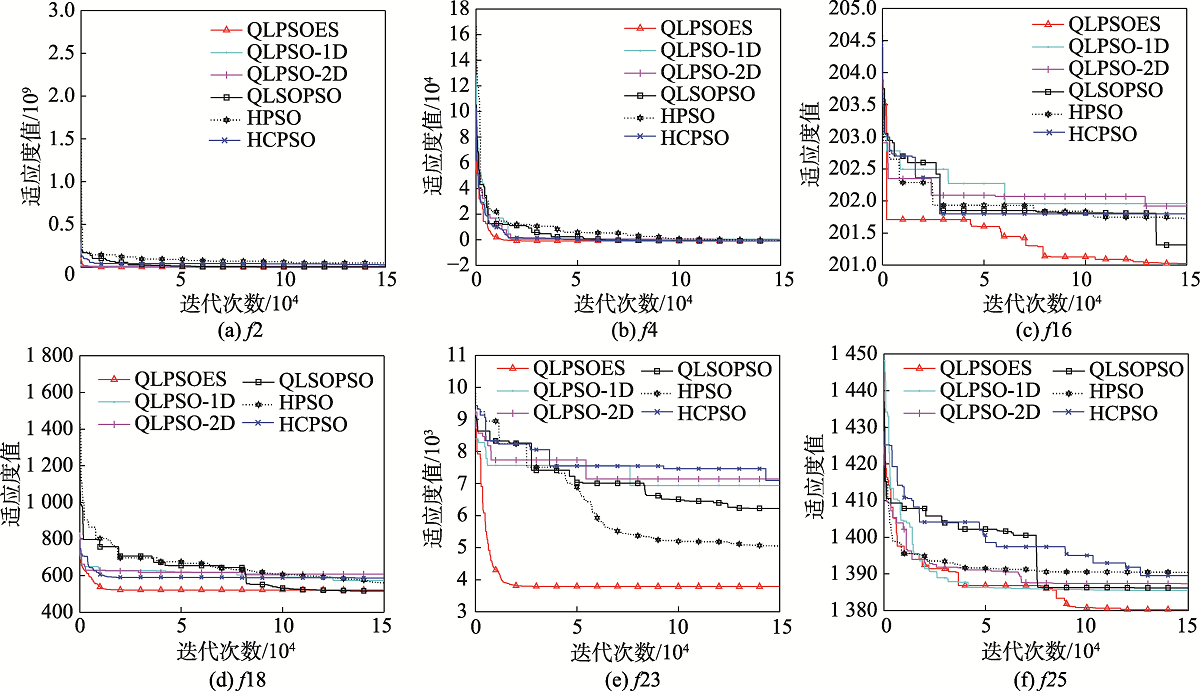
图9 六个测试函数的收敛曲线
Fig.9 Convergence curves of six test functions
| 算法名称 | 单个Q表策略 | 经验共享策略 |
|---|---|---|
| QLPSO-A | √ | × |
| QLPSO-B | × | × |
| QLPSOES | √ | √ |
表14 对比算法的策略设置
Table 14 Strategy setting of algorithms
| 算法名称 | 单个Q表策略 | 经验共享策略 |
|---|---|---|
| QLPSO-A | √ | × |
| QLPSO-B | × | × |
| QLPSOES | √ | √ |
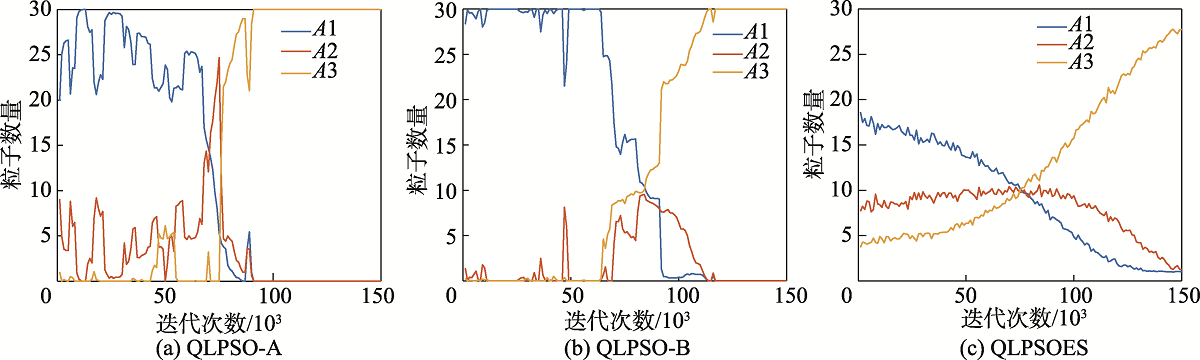
图10 种群动作数量
Fig.10 Number of population actions

图11 位置多样性
Fig.11 Position variety
| [1] | EBERHART R, KENNEDY J. A new optimizer using particle swarm theory[C]// Proceedings of the 6th International Symposium on Micro Machine and Human Science, Nagoya, Oct 4-6, 1995. Piscataway: IEEE, 1995: 39-43. |
| [2] | KENNEDY J, EBERHART R. Particle swarm optimization[C]// Proceedings of the 1995 IEEE International Conference on Neural Network, Perth, Nov 27-Dec 1, 1995. Piscataway: IEEE, 1995: 1942-1948. |
| [3] | EBERHART R, SHI Y. Comparing inertia weights and constriction factors in particle swarm optimization[C]// Proceedings of the 2000 Congress on Evolutionary Computation, La Jolla, Jul 16-19, 2000. Piscataway: IEEE, 2000: 84-88 |
| [4] |
张其文, 尉雅晨. 独立自适应调整参数的粒子群优化算法[J]. 计算机科学与探索, 2020, 14(4): 637-648.
DOI |
|
ZHANG Q W, WEI Y C. Particle swarm optimization with independent adaptive parameter adjustment[J]. Journal of Frontiers of Computer Science and Technology, 2020, 14(4): 637-648.
DOI |
|
| [5] |
周文峰, 梁晓磊, 唐可心, 等. 具有拓扑时变和搜索扰动的混合粒子群优化算法[J]. 计算机应用, 2020, 40(7): 1913-1918.
DOI |
| ZHOU W F, LIANG X L, TANG K X, et al. Hybrid particle swarm optimization algorithm with topological time-varying and search disturbance[J]. Journal of Computer Applications, 2020, 40(7): 1913-1918. | |
| [6] | 石松, 陈云. 层次环形拓扑结构的动态粒子群算法[J]. 计算机工程与应用, 2013, 49(8): 1-5. |
| SHI S, CHEN Y. Dynamic particle swarm optimization algorithm with hierarchical ring topology[J]. Computer Engineering and Applications, 2013, 49(8): 1-5. | |
| [7] |
周蓉, 李俊, 王浩. 基于灰狼优化的反向学习粒子群算法[J]. 计算机工程与应用, 2020, 56(7): 48-56.
DOI |
|
ZHOU R, LI J, WANG H. Reverse learning particle swarm optimization based on grey wolf optimization[J]. Computer Engineering and Applications, 2020, 56(7): 48-56.
DOI |
|
| [8] |
朱佳莹, 高茂庭. 融合粒子群与改进蚁群算法的AUV路径规划算法[J]. 计算机工程与应用, 2021, 57(6): 267-273.
DOI |
| ZHU J Y, GAO M T. AUV path planning based on particle swarm optimization and improved ant colony optimization[J]. Computer Engineering and Applications, 2021, 57(6): 267-273. | |
| [9] |
胡晓敏, 王明丰, 张首荣, 等. 用于文本聚类的新型差分进化粒子群算法[J]. 计算机工程与应用, 2021, 57(4): 61-67.
DOI |
| HU X M, WANG M F, ZHANG S R, et al. New differential evolution with particle swarm optimization algorithm for text clustering[J]. Computer Engineering and Applications, 2021, 57(4): 61-67. | |
| [10] | 许胜才, 蔡军, 程昀, 等. 基于拓扑结构与粒子变异改进的粒子群优化算法[J]. 控制与决策, 2019, 34(2): 419-428. |
| XU S C, CAI J, CHENG Y, et al. Modified particle swarm optimization algorithms based on topology and particle mutation[J]. Control and Decision, 2019, 34(2): 419-428. | |
| [11] |
廖玮霖, 程杉, 尚冬冬, 等. 多策略融合的粒子群优化算法[J]. 计算机工程与应用, 2021, 57(1): 69-76.
DOI |
| LIAO W L, CHENG S, SHANG D D, et al. Particle swarm optimization algorithm integrated with multiple-strategies[J]. Computer Engineering and Applications, 2021, 57(1): 69-76. | |
| [12] | PIPERAGKAS G S, GEORGOULAS G, PARSOPOULOS K E, et al. Integrating particle swarm optimization with reinforcement learning in noisy problems[C]// Proceedings of the 14th Annual Conference on Genetic and Evolutionary Computation, Philadelphia, Jul 2012. New York: ACM, 2012: 65-72. |
| [13] | SAMMA H, LIM C P, SALEH J M. A new reinforcement learning-based memetic particle swarm optimizer[J]. Applied Soft Computing, 2016, 43(C): 276-297. |
| [14] | 盛歆漪, 孙俊, 周頔, 等. 一种Q学习的量子粒子群优化方法[J]. 计算机工程与应用, 2014, 50(21): 8-13. |
| SHENG X Y, SUN J, ZHOU D, et al. Quantum-behaved particle swarm optimization method based on Q-learning[J]. Computer Engineering and Applications, 2014, 50(21): 8-13. | |
| [15] |
HSIEH Y Z, SU M C. A Q-learning-based swarm optimization algorithm for economic dispatch problem[J]. Neural Computing and Applications, 2016, 27(8): 2333-2350.
DOI URL |
| [16] |
XU Y, PI D C. A reinforcement learning-based communication topology in particle swarm optimization[J]. Neural Computing and Applications, 2020, 32(14): 10007-10032.
DOI URL |
| [17] | LIU Y X, LU H, CHENG S, et al. An adaptive online parameter control algorithm for particle swarm optimization based on reinforcement learning[C]// Proceedings of the 2019 IEEE Congress on Evolutionary Computation, Wellington, Jun 10-13, 2019. Piscataway: IEEE, 2019: 815-822. |
| [18] | WATKINS C, DAYAN P. Q-learning[J]. Machine Learning, 1992, 8(3/4): 279-292. |
| [19] |
宋威, 华子彧. 融入社会影响力的粒子群优化算法[J]. 计算机科学与探索, 2020, 14(11): 1908-1919.
DOI |
|
SONG W, HUA Z Y. Particle swarm optimization with social influence[J]. Journal of Frontiers of Computer Science and Technology, 2020, 14(11): 1908-1919.
DOI |
|
| [20] |
袁小平, 蒋硕. 基于分层自主学习的改进粒子群优化算法[J]. 计算机应用, 2019, 39(1): 148-153.
DOI |
| YUAN X P, JIANG S. Improved particle swarm optimization algorithm based on hierarchical autonomous learning[J]. Journal of Computer Applications, 2019, 39(1): 148-153. | |
| [21] | LIANG J J, QU B Y, SUGANTHAN P N. Problem definitions and evaluation criteria for the CEC 2013 special session on real-parameter optimization[R]. Singapore: Nanyang Technological University, 2013. |
| [22] | 王东风, 孟丽. 粒子群优化算法的性能分析和参数选择[J]. 自动化学报, 2016, 42(10): 1552-1561. |
| WANG D F, MENG L. Performance analysis and parameter selection of PSO algorithms[J]. Acta Automatica Sinica, 2016, 42(10): 1552-1561. | |
| [23] | SHI Y, EBERHART R C. Empirical study of particle swarm optimization[C]// Proceedings of the 1999 Congress on Evolutionary Computation, Washington, Jul 6-9, 1999. Piscataway: IEEE, 1999: 1945-1950. |
| [24] |
RATNAWEERA A, HALGAMUGE S K, WATSON H C. Self-organizing hierarchical particle swarm optimizer with time-varying acceleration coefficients[J]. IEEE Transactions on Evolutionary Computation, 2004, 8(3): 240-255.
DOI URL |
| [25] | 刘瑞江, 张业旺, 闻崇炜, 等. 正交试验设计和分析方法研究[J]. 实验技术与管理, 2010, 27(9): 52-55. |
| LIU R J, ZHANG Y W, WEN C W, et al. Study on the design and analysis methods of orthogonal experiment[J]. Experimental Technology and Management, 2010, 27(9): 52-55. | |
| [26] | 孟凯露, 尚俊娜, 岳克强. 混合蛙跳算法的最优参数研究[J]. 计算机应用研究, 2019, 36(11): 3321-3324. |
| MENG K L, SHANG J N, YUE K Q. Research on optimal parameters of shuffled frog leaping algorithm[J]. Application Research of Computers, 2019, 36(11): 3321-3324. | |
| [27] | 申元霞, 王国胤, 曾传华. PSO模型种群多样性与学习参数的关系研究[J]. 电子学报, 2011, 39(6): 1238-1244. |
| SHEN Y X, WANG G Y, ZENG C H. Study on the relationship between population diversity and learning parameters in particle swarm optimization[J]. Acta Electronica Sinica, 2011, 39(6): 1238-1244. |
| [1] | 陈共驰, 荣欢, 马廷淮. 面向连贯性强化的无真值依赖文本摘要模型[J]. 计算机科学与探索, 2022, 16(3): 621-636. |
| [2] | 王扬, 陈智斌, 吴兆蕊, 高远. 强化学习求解组合最优化问题的研究综述[J]. 计算机科学与探索, 2022, 16(2): 261-279. |
| [3] | 刘荆欣, 王妍, 韩笑, 夏长清, 宋宝燕. 基于Stackelberg博弈的边缘云资源定价机制研究[J]. 计算机科学与探索, 2022, 16(1): 153-162. |
| [4] | 陈斌, 刘卫国. 基于SAC模型的改进遗传算法求解TSP问题[J]. 计算机科学与探索, 2021, 15(9): 1680-1693. |
| [5] | 李成严, 宋月, 马金涛. 模糊云资源调度问题的RIOPSO算法[J]. 计算机科学与探索, 2021, 15(8): 1534-1545. |
| [6] | 纪伟, 李英梅, 季伟东, 张珑. 粒子置换的双种群综合学习PSO算法[J]. 计算机科学与探索, 2021, 15(4): 766-776. |
| [7] | 严丹,何军,刘红岩,杜小勇. 考虑评级信息的音乐评论文本自动生成[J]. 计算机科学与探索, 2020, 14(8): 1389-1396. |
| [8] | 赵婷婷,孔乐,韩雅杰,任德华,陈亚瑞. 模型化强化学习研究综述[J]. 计算机科学与探索, 2020, 14(6): 918-927. |
| [9] | 张其文,尉雅晨. 独立自适应调整参数的粒子群优化算法[J]. 计算机科学与探索, 2020, 14(4): 637-648. |
| [10] | 程天艺,王亚刚,龙旭,潘晓英. 多层次降维的头颈癌图像特征选择方法[J]. 计算机科学与探索, 2020, 14(4): 669-679. |
| [11] | 刘中强,游晓明,刘升. 启发式强化学习机制的异构双种群蚁群算法[J]. 计算机科学与探索, 2020, 14(3): 460-469. |
| [12] | 杨珉,汪洁. 解决深度探索问题的贝叶斯深度强化学习算法[J]. 计算机科学与探索, 2020, 14(2): 307-316. |
| [13] | 王金杰,李炜. 混合互信息和粒子群算法的多目标特征选择方法[J]. 计算机科学与探索, 2020, 14(1): 83-95. |
| [14] | 王丽娟,丁世飞. 一种粒子群优化的SVM-ELM模型[J]. 计算机科学与探索, 2019, 13(4): 657-665. |
| [15] | 朱芮,马永涛,南亚飞,张云蕾. 融合改进强化学习的认知无线电抗干扰决策算法[J]. 计算机科学与探索, 2019, 13(4): 693-701. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||