
计算机科学与探索 ›› 2022, Vol. 16 ›› Issue (4): 791-805.DOI: 10.3778/j.issn.1673-9418.2111028
伏轩仪1, 张銮景2, 梁文科2, 毕方明1,+( ), 房卫东3
), 房卫东3
收稿日期:2021-11-04
修回日期:2022-01-05
出版日期:2022-04-01
发布日期:2022-01-17
通讯作者:
+ E-mail: bifangming@126.com作者简介:伏轩仪(1996—),女,江苏泰兴人,硕士研究生,CCF学生会员,主要研究方向为计算机视觉、边缘计算。
FU Xuanyi1, ZHANG Luanjing2, LIANG Wenke2, BI Fangming1,+(), FANG Weidong3
Received:2021-11-04
Revised:2022-01-05
Online:2022-04-01
Published:2022-01-17
About author:FU Xuanyi, born in 1996, M.S. candidate, student member of CCF. Her research interests include computer vision and edge computing.摘要:
目标检测是计算机视觉领域的基本任务。近年来,基于深度学习的目标检测研究发展十分迅速,锚点(anchor)机制广泛应用于主流目标检测器中。多尺度的锚点是检测器解决尺度问题的有效方法,但锚点策略也存在尺寸固定、模型鲁棒性差等问题。根据优化锚点设置和无锚点(anchor-free)两种不同思路在目标检测中的发展,进一步分类总结检测模型的优缺点。首先回顾anchor策略提出的背景及原理,介绍基于优化anchor设置的目标检测模型,总结anchor机制存在的问题,引出无锚点(anchor-free)系列模型。在基于关键点的anchor-free模型中,按照检测思路分为基于特定位置关键点的检测器和结合中心关键点回归预测的检测器,分类总结算法的优缺点和使用范围,结合COCO数据集上的检测指标进一步对比。最后在总结融合anchor-based和anchor-free的模型基础上探讨两类算法的本质区别,指出未来的研究方向。
中图分类号:
伏轩仪, 张銮景, 梁文科, 毕方明, 房卫东. 锚点机制在目标检测领域的发展综述[J]. 计算机科学与探索, 2022, 16(4): 791-805.
FU Xuanyi, ZHANG Luanjing, LIANG Wenke, BI Fangming, FANG Weidong. Review on Development of Anchor Mechanism in Object Detection[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(4): 791-805.

图1 Faster R-CNN中的锚点示意图
Fig.1 Schematic diagram of anchors in Faster R-CNN

图2 CornerNet检测结构
Fig.2 CornerNet detection framework

图3 左上角点池化数值计算过程
Fig.3 Numerical procedure of top-left corner pooling

图4 改进关键点匹配系列模型检测效果对比
Fig.4 Detection results comparison of key point matching series models

图5 FCOS网络的检测结构
Fig.5 Fully convolutional one-stage object detection framework
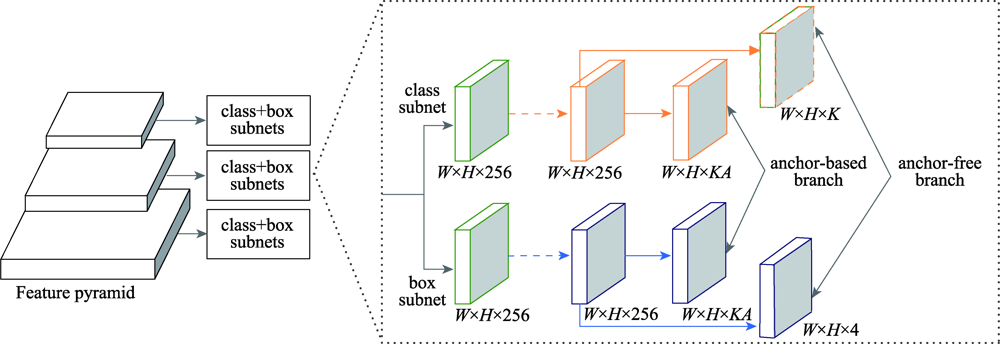
图6 FSAF网络的检测结构
Fig.6 FSAF detection framework

图7 基于标签分配优化的检测模型关系
Fig.7 Relationship between detection models based on label assign optimization
| 模型名称 | 先验形式 | 标签分配 | | |
|---|---|---|---|---|
| scale | spatial | |||
| RetinaNet | anchor | size & IoU | IoU | 36.3 |
| FreeAnchor | anchor | size & IoU | top-k weighting,IoU | 38.7 |
| ATSS | anchor | size & IoU | top-k,dynamic IoU | 39.3 |
| FCOS | center | range | radius | 38.7 |
| FSAF | anchor & center | loss | IoU & radius | 37.2 |
| AutoAssign | dynamic center | weighting | weighting | 40.5 |
表1 标签分配目标检测模型总结
Table 1 Summary of label assign object detection models
| 模型名称 | 先验形式 | 标签分配 | | |
|---|---|---|---|---|
| scale | spatial | |||
| RetinaNet | anchor | size & IoU | IoU | 36.3 |
| FreeAnchor | anchor | size & IoU | top-k weighting,IoU | 38.7 |
| ATSS | anchor | size & IoU | top-k,dynamic IoU | 39.3 |
| FCOS | center | range | radius | 38.7 |
| FSAF | anchor & center | loss | IoU & radius | 37.2 |
| AutoAssign | dynamic center | weighting | weighting | 40.5 |
| 模型 | 发表会议 | 年份 | 原理 | 优点 | 缺点 | 使用范围 |
|---|---|---|---|---|---|---|
| CornerNet[ | ECCV | 2018 | 检测左上和右下一对角点配对 | 检测思路完全基于关键点;Corner pooling聚焦物体边缘信息 | 本质上仍为矩形包围框;网络对边界敏感,缺乏内部信息 | 目标检测 |
| CornerNet-Lite[ | BMVC | 2020 | 检测左上和右下一对角点配对 | 引入类似人眼扫视的注意力机制;设计轻量化主干网络 | 小物体的误检率高 | 目标检测 |
| ExtremeNet[ | CVPR | 2019 | 检测4个极值点+1个额外的中心点 | 依据几何特征组合关键点 | 枚举法组合关键点效率低 | 目标检测、实例 分割 |
| Objects as Points[ | CVPR | 2019 | 提取目标中心点+回归 | 没有后处理步骤 | 只使用中心点进行回归,可获得的信息少 | 2D/3D目标检测、人体姿态识别 |
| CenterNet2[ | CVPR | 2021 | 将原CenterNet作为两阶段检测模型的第一阶段 | 为两阶段检测器做出概率角度的可解释说明 | — | 目标检测 |
| CenterNet-Triplets[ | ICCV | 2019 | 检测左上和右下一对角点和一个中心关键点 | 结合中心区域检测 | 依赖后处理分组,检测速度慢 | 目标检测 |
| CentripetalNet[ | CVPR | 2020 | 检测角点,结合偏移量进行匹配 | 对相似目标检测效果好 | 中心区域的缩放依赖超参数 | 目标检测、分割 |
| FCOS[ | ICCV | 2019 | 逐像素点分类回归 | 后处理简单增加正样本数量,提高召回率 | 中心度可解释性需要增强 | 目标检测、语义分割、关键点检测 |
| FSAF[ | CVPR | 2019 | 在增加的anchor-free分支上计算focal loss和IoU loss的最小和 | 动态选择最适合目标的特征层 | 与anchor-based分支结合才能取得理想效果 | 小目标检测 |
| ATSS[ | CVPR | 2020 | 根据对象的统计特征自动选择正负样本 | 动态调整IoU阈值 | 自适应过程需要调制超参数 | 目标检测 |
| LSNet[ | CVPR | 2021 | 一个anchor点和多个关键点间的向量确定目标 | 统一多个视觉任务 | 推理速度慢 | 目标检测、实例分割、姿态估计 |
| VFNET[ | CVPR | 2021 | 在FCOS+ATSS的基础上优化包围框的表示 | 变焦损失varifocal loss解决类别不平衡问题 | — | 密集目标检测 |
表2 各类无锚点目标检测模型总结
Table 2 Summary of various anchor-free object detection models
| 模型 | 发表会议 | 年份 | 原理 | 优点 | 缺点 | 使用范围 |
|---|---|---|---|---|---|---|
| CornerNet[ | ECCV | 2018 | 检测左上和右下一对角点配对 | 检测思路完全基于关键点;Corner pooling聚焦物体边缘信息 | 本质上仍为矩形包围框;网络对边界敏感,缺乏内部信息 | 目标检测 |
| CornerNet-Lite[ | BMVC | 2020 | 检测左上和右下一对角点配对 | 引入类似人眼扫视的注意力机制;设计轻量化主干网络 | 小物体的误检率高 | 目标检测 |
| ExtremeNet[ | CVPR | 2019 | 检测4个极值点+1个额外的中心点 | 依据几何特征组合关键点 | 枚举法组合关键点效率低 | 目标检测、实例 分割 |
| Objects as Points[ | CVPR | 2019 | 提取目标中心点+回归 | 没有后处理步骤 | 只使用中心点进行回归,可获得的信息少 | 2D/3D目标检测、人体姿态识别 |
| CenterNet2[ | CVPR | 2021 | 将原CenterNet作为两阶段检测模型的第一阶段 | 为两阶段检测器做出概率角度的可解释说明 | — | 目标检测 |
| CenterNet-Triplets[ | ICCV | 2019 | 检测左上和右下一对角点和一个中心关键点 | 结合中心区域检测 | 依赖后处理分组,检测速度慢 | 目标检测 |
| CentripetalNet[ | CVPR | 2020 | 检测角点,结合偏移量进行匹配 | 对相似目标检测效果好 | 中心区域的缩放依赖超参数 | 目标检测、分割 |
| FCOS[ | ICCV | 2019 | 逐像素点分类回归 | 后处理简单增加正样本数量,提高召回率 | 中心度可解释性需要增强 | 目标检测、语义分割、关键点检测 |
| FSAF[ | CVPR | 2019 | 在增加的anchor-free分支上计算focal loss和IoU loss的最小和 | 动态选择最适合目标的特征层 | 与anchor-based分支结合才能取得理想效果 | 小目标检测 |
| ATSS[ | CVPR | 2020 | 根据对象的统计特征自动选择正负样本 | 动态调整IoU阈值 | 自适应过程需要调制超参数 | 目标检测 |
| LSNet[ | CVPR | 2021 | 一个anchor点和多个关键点间的向量确定目标 | 统一多个视觉任务 | 推理速度慢 | 目标检测、实例分割、姿态估计 |
| VFNET[ | CVPR | 2021 | 在FCOS+ATSS的基础上优化包围框的表示 | 变焦损失varifocal loss解决类别不平衡问题 | — | 密集目标检测 |
| 模型名称 | 主干网络 | 输入图像尺寸 | 处理器配置及实时性指标 | AP/% | AP50/% | AP75/% | APs/% | APm/% | APl/% |
|---|---|---|---|---|---|---|---|---|---|
| SSD[ | ResNet-101 | 300×300 | Titan X 19 frame/s | 31.2 | 50.4 | 33.3 | 10.2 | 34.5 | 49.8 |
| YOLOv3[ | DarkNet-53 | 608×608 | Titan X 45.4 frame/s | 33.0 | 57.9 | 34.4 | 18.3 | 35.4 | 41.9 |
| RetinaNet[ | ResNet-101 | 800×800 | 5 frame/s | 39.1 | 59.1 | 42.3 | 21.8 | 42.7 | 50.2 |
| RefineDet[ | ResNet-101 | 512×512 | Titan X — | 41.8 | 62.9 | 45.7 | 25.6 | 45.1 | 54.1 |
| GFL[ | ResNet-101 | 多尺度 | 2080Ti 10 frame/s | 47.3 | 66.3 | 51.4 | 28.0 | 51.1 | 59.2 |
| EfficientDet[ | EfficientNet-B6[ | 多尺度 | 1080Ti×3 3.8 frame/s | 52.2 | 71.4 | 56.3 | 34.8 | 55.5 | 64.6 |
| CornerNet[ | Hourglass-104 | 511×511 | TitanX (PASCAL)×10 4.1 frame/s | 42.1 | 57.8 | 45.3 | 20.8 | 44.8 | 56.7 |
| CornerNet-Saccade[ | Hourglass-52 | — | 1080Ti×4 5.2 frame/s | 42.6 | — | — | 25.5 | 44.3 | 58.4 |
| CornerNet-Squeeze[ | Hourglass-52 | — | 1080Ti×4 33 frame/s | 34.4 | — | — | — | — | — |
| ExtremeNet[ | Hourglass-104 | 511×511 | TitanX (PASCAL)×10 3.1 frame/s | 43.7 | 60.5 | 47.0 | 24.1 | 46.9 | 57.9 |
| CenterNet-Points[ | DLA-34 | 512×512 | Titan X 7.8 frame/s | 45.1 | 63.9 | 49.3 | 26.6 | 47.1 | 57.7 |
| CenterNet2[ | Res2Net[ DCN-BiFPN | — | Titan Xp — | 56.4 | 74.0 | 61.6 | 38.7 | 59.7 | 68.6 |
| CenterNet-Triplets[ | Hourglass-104 | 511×511 | Tesla P100 340 ms | 47.0 | 64.5 | 50.7 | 28.9 | 49.9 | 58.9 |
| CentripetalNet[ | Hourglass-104 | — | NVIDIA V100×16 | 48.0 | 65.1 | 51.8 | 29.0 | 50.4 | 59.9 |
| FCOS[ | ResNeXt-101[ | — | — | 44.7 | 64.1 | 48.4 | 27.6 | 47.5 | 55.6 |
| FSAF[ | ResNeXt-101 | 800×800 | Tesla V100×8 362 ms | 44.6 | 65.2 | 48.6 | 29.7 | 47.1 | 54.6 |
| ATSS[ | ResNeXt-101-DCN | — | — | 50.7 | 68.9 | 56.3 | 33.2 | 52.9 | 62.4 |
| LSNet[ | Res2Net-101-DCN | 1 333×800 | Tesla V100×8 6.3 frame/s | 53.5 | 71.1 | 59.2 | 35.2 | 56.4 | 65.8 |
| VFNet[ | Res2Net-101-DCN | 1 333×800 | Tesla V100×8 4.2 frame/s | 55.1 | 73.0 | 60.1 | 37.4 | 58.2 | 67.0 |
表3 各类目标检测模型在COCO数据集上的性能对比
Table 3 Performance comparison of various object detection models on COCO dataset
| 模型名称 | 主干网络 | 输入图像尺寸 | 处理器配置及实时性指标 | AP/% | AP50/% | AP75/% | APs/% | APm/% | APl/% |
|---|---|---|---|---|---|---|---|---|---|
| SSD[ | ResNet-101 | 300×300 | Titan X 19 frame/s | 31.2 | 50.4 | 33.3 | 10.2 | 34.5 | 49.8 |
| YOLOv3[ | DarkNet-53 | 608×608 | Titan X 45.4 frame/s | 33.0 | 57.9 | 34.4 | 18.3 | 35.4 | 41.9 |
| RetinaNet[ | ResNet-101 | 800×800 | 5 frame/s | 39.1 | 59.1 | 42.3 | 21.8 | 42.7 | 50.2 |
| RefineDet[ | ResNet-101 | 512×512 | Titan X — | 41.8 | 62.9 | 45.7 | 25.6 | 45.1 | 54.1 |
| GFL[ | ResNet-101 | 多尺度 | 2080Ti 10 frame/s | 47.3 | 66.3 | 51.4 | 28.0 | 51.1 | 59.2 |
| EfficientDet[ | EfficientNet-B6[ | 多尺度 | 1080Ti×3 3.8 frame/s | 52.2 | 71.4 | 56.3 | 34.8 | 55.5 | 64.6 |
| CornerNet[ | Hourglass-104 | 511×511 | TitanX (PASCAL)×10 4.1 frame/s | 42.1 | 57.8 | 45.3 | 20.8 | 44.8 | 56.7 |
| CornerNet-Saccade[ | Hourglass-52 | — | 1080Ti×4 5.2 frame/s | 42.6 | — | — | 25.5 | 44.3 | 58.4 |
| CornerNet-Squeeze[ | Hourglass-52 | — | 1080Ti×4 33 frame/s | 34.4 | — | — | — | — | — |
| ExtremeNet[ | Hourglass-104 | 511×511 | TitanX (PASCAL)×10 3.1 frame/s | 43.7 | 60.5 | 47.0 | 24.1 | 46.9 | 57.9 |
| CenterNet-Points[ | DLA-34 | 512×512 | Titan X 7.8 frame/s | 45.1 | 63.9 | 49.3 | 26.6 | 47.1 | 57.7 |
| CenterNet2[ | Res2Net[ DCN-BiFPN | — | Titan Xp — | 56.4 | 74.0 | 61.6 | 38.7 | 59.7 | 68.6 |
| CenterNet-Triplets[ | Hourglass-104 | 511×511 | Tesla P100 340 ms | 47.0 | 64.5 | 50.7 | 28.9 | 49.9 | 58.9 |
| CentripetalNet[ | Hourglass-104 | — | NVIDIA V100×16 | 48.0 | 65.1 | 51.8 | 29.0 | 50.4 | 59.9 |
| FCOS[ | ResNeXt-101[ | — | — | 44.7 | 64.1 | 48.4 | 27.6 | 47.5 | 55.6 |
| FSAF[ | ResNeXt-101 | 800×800 | Tesla V100×8 362 ms | 44.6 | 65.2 | 48.6 | 29.7 | 47.1 | 54.6 |
| ATSS[ | ResNeXt-101-DCN | — | — | 50.7 | 68.9 | 56.3 | 33.2 | 52.9 | 62.4 |
| LSNet[ | Res2Net-101-DCN | 1 333×800 | Tesla V100×8 6.3 frame/s | 53.5 | 71.1 | 59.2 | 35.2 | 56.4 | 65.8 |
| VFNet[ | Res2Net-101-DCN | 1 333×800 | Tesla V100×8 4.2 frame/s | 55.1 | 73.0 | 60.1 | 37.4 | 58.2 | 67.0 |
| 表征形式 | 方法 | 主干网络 | 旋转一致性 |
|---|---|---|---|
| bounding box | CenterNet[ | Hourglass-104 | 0.833 |
| DLA | 0.851 | ||
| bounding circle | CircleNet | Hourglass-104 | 0.875 |
| DLA | 0.886 |
表4 旋转一致性对比
Table 4 Comparison of rotation consistency results
| 表征形式 | 方法 | 主干网络 | 旋转一致性 |
|---|---|---|---|
| bounding box | CenterNet[ | Hourglass-104 | 0.833 |
| DLA | 0.851 | ||
| bounding circle | CircleNet | Hourglass-104 | 0.875 |
| DLA | 0.886 |
| [1] |
LOWE D G. Distinctive image features from scale-invariant keypoints[J]. International Journal of Computer Vision, 2004, 60(2):91-110.
DOI URL |
| [2] | DALAL N, TRIGGS B. Histograms of oriented gradients for human detection[C]// Proceedings of the 2005 IEEE Com-puter Society Conference on Computer Vision and Pattern Recognition, San Diego, Jun 20-25, 2005. Washington: IEEE Computer Society, 2005: 886-893. |
| [3] |
KRIZHEVSKY A, SUTSKEVER I, HINTON G. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6):84-90.
DOI URL |
| [4] | DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database[C]// Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, Jun 20-25, 2009. Washington: IEEE Computer Society, 2009: 248-255. |
| [5] | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[J]. arXiv: 1409. 1556, 2014. |
| [6] | SZEGEDY C, LIU W, JIA Y, et al. Going deeper with con-volutions[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, Jun 7-12, 2015. Washington: IEEE Computer Society, 2015: 1-9. |
| [7] | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Con-ference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Soc-iety, 2016: 770-778. |
| [8] |
JIAO L, ZHANG F, LIU F, et al. A survey of deep learning-based object detection[J]. IEEE Access, 2019, 7:128837-128868.
DOI URL |
| [9] | WU X, SAHOO D, HOI S C H. Recent advances in deep learning for object detection[J]. arXiv: 1908. 03673, 2019. |
| [10] |
LIU L, OUYANG W, WANG X, et al. Deep learning for generic object detection: a survey[J]. International Journal of Computer Vision, 2020, 128(2):261-318.
DOI URL |
| [11] | 聂光涛, 黄华. 光学遥感图像目标检测算法综述[J]. 自动化学报, 2021, 47(8):1729-1749. |
| NIE G T, HUANG H. A survey of object detection in optical remote sensing images[J]. Acta Automatica Sinica, 2021, 47(8):1729-1749. | |
| [12] | REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intell-igence, 2015, 39(6):1137-1149. |
| [13] | HE K, GKIOXARI G, DOLL R P, et al. Mask R-CNN[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Oct 22-29, 2017. Washington: IEEE Computer Society, 2017: 2980-2988. |
| [14] | HUANG L, YANG Y, DENG Y, et al. DenseBox: unifying landmark localization with end to end object detection[J]. arXiv: 1509. 04874, 2015. |
| [15] |
LIN T, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 42(2):318-327.
DOI URL |
| [16] | REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]// Proceed-ings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washing-ton: IEEE Computer Society, 2016: 779-788. |
| [17] | REDMON J, FARHADI A. YOLO9000: better, faster, str-onger[C]// Proceedings of the 2017 IEEE Conference on Com-puter Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 6517-6525. |
| [18] | REDMON J, FARHADI A. YOLOv3: an incremental impr-ovement[J]. arXiv: 1804. 02767, 2018. |
| [19] | DAI J F, LI Y, HE K M, et al. R-FCN: object detection via region-based fully convolutional networks[C]// Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Dec 5-10, 2016. Red Hook: Curran Associates, 2016: 379-387. |
| [20] | LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector[C]// LNCS 9905: Proceedings of the 14th European Conference on Computer Vision, Amsterdam, Oct 11-14, 2016. Cham: Springer, 2016: 21-37. |
| [21] | SZEGEDY C, REED S, ERHAN D, et al. Scalable, high-quality object detection[J]. arXiv: 1412. 1441, 2014. |
| [22] | FU C Y, LIU W, RANGA A, et al. DSSD: deconvolutional single shot detector[J]. arXiv: 1701. 06659, 2017. |
| [23] | YANG X, YAN J, FENG Z, et al. R3Det: refined single-stage detector with feature refinement for rotating object[J]. arXiv: 1908. 05612, 2019. |
| [24] |
YANG X, SUN H, FU K, et al. Automatic ship detection in remote sensing images from Google earth of complex scenes based on multiscale rotation dense feature pyramid networks[J]. Remote Sensing, 2018, 10(1):132.
DOI URL |
| [25] | HAN J, DING J, LI J, et al. Align deep features for oriented object detection[J]. arXiv: 2008. 09397, 2020. |
| [26] | CAI Z W, FAN Q F, FERIS R S, et al. A unified multi-scale deep convolutional neural network for fast object detection[C]// LNCS 9908: Proceedings of the 14th European Con-ference on Computer Vision, Amsterdam, Oct 11-14, 2016. Cham: Springer, 2016: 354-370. |
| [27] | ZHU C C, TAO R, LUU K, et al. Seeing small faces from robust anchor’s perspective[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-22, 2018. Piscataway: IEEE, 2018: 5127-5136. |
| [28] | KE W, ZHANG T, HUANG Z, et al. Multiple anchor learn-ing for visual object detection[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Re-cognition, Seatle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 10203-10212. |
| [29] |
XU Z, XU X, WANG L, et al. Deformable ConvNet with aspect ratio constrained NMS for object detection in remote sensing imagery[J]. Remote Sensing, 2017, 9(12):1312.
DOI URL |
| [30] | REN Y, ZHU C, XIAO S. Deformable faster R-CNN with aggregating multi-layer features for partially occluded object detection in optical remote sensing images[J]. Remote Sens-ing, 2018, 10(9):1470. |
| [31] | YANG T, ZHANG X Y, LI Z M, et al. MetaAnchor: learning to detect objects with customized anchors[C]// Proceedings of the 32nd Conference on Neural Information Processing Systems, Montréal, Dec 3-8, 2018. Red Hook: Curran Ass-ociates, 2018: 318-328. |
| [32] | MA W S, TIAN T Z, XU H, et al. AABO: adaptive anchor box optimization for object detection via Bayesian sub-sampling[C]// LNCS 12350: Proceedings of the 16th Euro-pean Conference on Computer Vision, Glasgow, Aug 23-28, 2020. Cham: Springer, 2020: 560-575. |
| [33] |
PAN S J, YANG Q. A survey on transfer learning[J]. IEEE Transactions on Knowledge and Data Engineering, 2010, 22(10):1345-1359.
DOI URL |
| [34] | LAW H, DENG J. CornerNet: detecting objects as paired keypoints[C]// LNCS 11218: Proceedings of the 15th Euro-pean Conference on Computer Vision, Munich, Sep 8-14, 2018. Cham: Springer, 2018: 765-781. |
| [35] | LAW H, TENG Y, RUSSAKOVSKY O, et al. CornerNet-Lite: efficient keypoint based object detection[J]. arXiv: 1904. 08900, 2019. |
| [36] | ZHOU X Y, ZHUO J C, KRÄHENBÜHL P. Bottom-up object detection by grouping extreme and center points[J]. arXiv: 1901. 08043, 2019. |
| [37] | ZHOU X Y, WANG D Q, KRÄHENBÜHL P. Objects as points[J]. arXiv: 1904. 07850, 2019. |
| [38] | ZHOU X Y, KOLTUN V, KRÄHENBÜHL P. Probabilistic two-stage detection[J]. arXiv: 2103. 07461, 2021. |
| [39] | NEWELL A, HUANG Z, DENG J. Associative embedding: end-to-end learning for joint detection and grouping[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, Dec 4-9, 2017. Red Hook: Curran Associates, 2017: 2277-2287. |
| [40] | IANDOLA F N, HAN S, MOSKEWICZ M W, et al. Squeeze-Net: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size[J]. arXiv: 1602. 07360, 2016. |
| [41] | HOWARD A G, ZHU M L, CHEN B, et al. MobileNets: eff-icient convolutional neural networks for mobile vision app-lications[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 7341-7349. |
| [42] | DUAN K, BAI S, XIE L X, et al. CenterNet: keypoint triplets for object detection[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Oct 27-Nov 2, 2019. Piscataway: IEEE, 2019: 6568-6577. |
| [43] | DONG Z W, LI G X, LIAO Y, et al. CentripetalNet: pursu-ing high-quality keypoint pairs for object detection[C]// Pro-ceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 10516-10525. |
| [44] | TIAN Z, SHEN C H, CHEN H, et al. FCOS: fully convolu-tional one-stage object detection[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Oct 27-Nov 2, 2019. Piscataway: IEEE, 2019: 9626-9635. |
| [45] | DUAN K W, XIE L X, QI H G, et al. Location-sensitive vis-ual recognition with cross-IOU loss[J]. arXiv: 2104. 04899,2021. |
| [46] | ZHANG S F, CHI C, YAO Y Q, et al. Bridging the gap be-tween anchor-based and anchor-free detection via adaptive training sample selection[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recogni-tion, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 9756-9765. |
| [47] | DAI J F, QI H Z, XIONG Y W, et al. Deformable convolu-tional networks[C]// Proceedings of the 2017 IEEE Interna-tional Conference on Computer Vision, Venice, Oct 22-29, 2017. Washington: IEEE Computer Society, 2017: 764-773. |
| [48] | AHN S, CHANG J W, KANG S J. An efficient accelerator design methodology for deformable convolutional networks[C]// Proceedings of the 2020 IEEE International Confer-ence on Image Processing, Oct 25-28, 2020. Washington: IEEE Computer Society, 2020: 3075-3079. |
| [49] | 邓志鹏, 孙浩, 雷琳, 等. 基于多尺度形变特征卷积网络的高分辨率遥感影像目标检测[J]. 测绘学报, 2018, 47(9):1216-1227. |
| DENG Z P, SUN H, LEI L, et al. Object detection in remote sensing imagery with multi-scale deformable convolutional networks[J]. Acta Geodaetica et Cartographica Sinica, 2018, 47(9):1216-1227. | |
| [50] | ZHANG H Y, WANG Y, DAYOUB F, et al. VarifocalNet: an iou-aware dense object detector[J]. arXiv: 2008. 13367, 2020. |
| [51] | ZHU C C, HE Y H, SAVVIDES M. Feature selective anchor-free module for single-shot object detection[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, Jun 15-20, 2019. Pisca-taway: IEEE, 2019: 840-849. |
| [52] | CAO Y H, CHEN K, LOY C C, et al. Prime sample atten-tion in object detection[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recogni-tion, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 11580-11588. |
| [53] | ZHANG X S, WAN F, LIU C, et al. FreeAnchor: learning to match anchors for visual object detection[C]// Proceedings of the Annual Conference on Neural Information Processing Systems, Vancouver, Dec 8-14, 2019. California: NeurIPS, 2019: 147-155. |
| [54] | ZHU B J, WANG J F, JIANG Z K, et al. AutoAssign: diff-erentiable label assignment for dense object detection[J]. arXiv: 2007. 03496, 2020. |
| [55] | ZHANG S F, WEN L Y, BIAN X, et al. Single-shot refine-ment neural network for object detection[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-23, 2018. Washington: IEEE Computer Society, 2018: 4203-4212. |
| [56] | LIN T Y, DOLLÁR P, GIRSHICK R B, et al. Feature pyr-amid networks for object detection[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 936-944. |
| [57] | LI X, WANG W H, WU L J, et al. Generalized focal loss: learning qualified and distributed bounding boxes for dense object detection[J]. arXiv: 2006. 04388, 2020. |
| [58] | TAN M X, PANG R M, LE Q V. EfficientDet: scalable and efficient object detection[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Reco-gnition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 10778-10787. |
| [59] | TAN M X, LE Q V. EfficientNet: rethinking model scaling for convolutional neural networks[C]// Proceedings of the 36th International Conference on Machine Learning, Long Beach, Jun 9-15, 2019: 6105-6114. |
| [60] |
GAO S H, CHENG M M, ZHAO K, et al. Res2Net: a new multi-scale backbone architecture[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 43(2):652-662.
DOI URL |
| [61] | XIE S N, GIRSHICK R B, DOLLÁR P, et al. Aggregated residual transformations for deep neural networks[C]// Pro-ceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Wash-ington: IEEE Computer Society, 2017: 5987-5995. |
| [62] |
LIU X, DI X, WU J, et al. Vector encoded bounding box regression for detecting remote-sensing objects with anchor-free methods[J]. International Journal of Remote Sensing, 2021, 42(2):693-713.
DOI URL |
| [63] | 蒋光峰, 胡鹏程, 叶桦, 等. 基于旋转中心点估计的遥感目标精确检测算法[J]. 计算机应用研究, 2021, 38(9):2866-2870. |
| JIANG G F, HU P C, YE H, et al. Remote sensing target accurate detection algorithm based on rotation center point estimation[J]. Application Research of Computers, 2021, 38(9):2866-2870. | |
| [64] |
CAO H C, PU S L, TAN W M, et al. Breast mass detection in digital mammography based on anchor-free architecture[J]. Computer Methods and Programs in Biomedicine, 2021, 205:106033.
DOI URL |
| [65] | LUO X D, SONG T, WANG G T, et al. SCPM-Net: an anchor-free 3D lung nodule detection network using sphere repre-sentation and center points matching[J]. arXiv: 2104. 05215, 2021. |
| [66] |
ZHE L, XI X, SONG Y Q, et al. MLANet: multi-layer anchor-free network for generic lesion detection[J]. Engineering Applications of Artificial Intelligence, 2021, 102:104255.
DOI URL |
| [67] | YANG H C, DENG R N, LU Y Z, et al. CircleNet: anchor-free glomerulus detection with circle representation[C]// LNCS 12264: Proceedings of the 23rd International Conference on Medical Image Computing and Computer Assisted Interven-tion, Lima, Oct 4-8, 2020. Cham: Springer, 2020: 35-44. |
| [68] |
ZHENG Z, LIU W, WANG H, et al. Real-time enumeration of metro passenger volume using anchor-free object detec-tion network on edge devices[J]. IEEE Access, 2021, 9:21593-21603.
DOI URL |
| [69] |
范红超, 李万志, 章超权. 基于Anchor-free的交通标志检测[J]. 地球信息科学学报, 2020, 22(1):88-99.
DOI |
| FAN H C, LI W Z, ZHANG C Q. Anchor-free traffic sign detection[J]. Journal of Geo-Information Science, 2020, 22(1):88-99. | |
| [70] | 梁礼明, 熊文, 蓝智敏, 等. 改进的CornerNet-Saccade车辆检测算法[J]. 重庆理工大学学报(自然科学), 2021, 35(6):137-146. |
| LIANG L M, XIONG W, LAN Z M, et al. Improved CornerNet-Saccade algorithm for vehicle detection[J]. Jour-nal of Chongqing University of Technology (Natural Science), 2021, 35(6):137-146. | |
| [71] | 何泽文, 张文生. 保持高分辨率信息的无锚点框检测算法[J]. 计算机辅助设计与图形学学报, 2021, 33(4):580-589. |
| HE Z W, ZHANG W S. High resolution information reser-ved anchor-free detection algorithm[J]. Journal of Computer-Aided Design & Computer Graphics, 2021, 33(4):580-589. | |
| [72] | 黄思维, 李志丹, 程吉祥, 等. 基于多特征融合的轻量化无锚人脸检测方法[J/OL]. 计算机工程与应用(2021-04-12) [2021-08-25]. https://kns.cnki.net/kcms/detail/11.2127.TP.20210409.1746.030.html. |
| HUANG S W, LI Z D, CHENG J X, et al. Light-weight an-chor free face detection based on multi feature fusion[J/OL]. Computer Engineering and Applications(2021-04-12) [2021-08-25]. https://kns.cnki.net/kcms/detail/11.2127.TP.20210409.1746.030.html. | |
| [73] | 李晨瑄, 顾佼佼, 王磊, 等. 多尺度特征融合的Anchor-Free轻量化舰船要害检测算法[J/OL]. 北京航空航天大学学报(2021-04-26)[2021-08-23]. https://kns.cnki.net/kcms/detail/11.2625.V.20210425.1724.001.html. |
| LI C X, GU J J, WANG L, et al. Warship’s vital parts detec-tion algorithm based on lightweight Anchor-Free network with multi-scale feature fusion[J/OL]. Journal of Beijing Un-iversity of Aeronautics and Astronautics(2021-04-26)[2021-08-23]. https://kns.cnki.net/kcms/detail/11.2625.V.20210425.1724.001.html. | |
| [74] | YU F, WANG D Q, SHELHAMER E, et al. Deep layer agg-regation[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-22, 2018. Piscataway: IEEE, 2018: 2403-2412. |
| [1] | 彭豪, 李晓明. 多尺度选择金字塔网络的小样本目标检测算法[J]. 计算机科学与探索, 2022, 16(7): 1649-1660. |
| [2] | 孙方伟, 李承阳, 谢永强, 李忠博, 杨才东, 齐锦. 深度学习应用于遮挡目标检测算法综述[J]. 计算机科学与探索, 2022, 16(6): 1243-1259. |
| [3] | 董文轩, 梁宏涛, 刘国柱, 胡强, 于旭. 深度卷积应用于目标检测算法综述[J]. 计算机科学与探索, 2022, 16(5): 1025-1042. |
| [4] | 赵鹏飞, 谢林柏, 彭力. 融合注意力机制的深层次小目标检测算法[J]. 计算机科学与探索, 2022, 16(4): 927-937. |
| [5] | 王燕妮, 余丽仙. 注意力与多尺度有效融合的SSD目标检测算法[J]. 计算机科学与探索, 2022, 16(2): 438-447. |
| [6] | 阮晨钊, 张祥森, 刘科, 赵增顺. 深度学习的人-物体交互检测研究进展[J]. 计算机科学与探索, 2022, 16(2): 323-336. |
| [7] | 李科岑, 王晓强, 林浩, 李雷孝, 杨艳艳, 孟闯, 高静. 深度学习中的单阶段小目标检测方法综述[J]. 计算机科学与探索, 2022, 16(1): 41-58. |
| [8] | 李志欣, 陈圣嘉, 周韬, 马慧芳. 协同级联网络和对抗网络的目标检测[J]. 计算机科学与探索, 2022, 16(1): 217-230. |
| [9] | 王迪聪, 白晨帅, 邬开俊. 基于深度学习的视频目标检测综述[J]. 计算机科学与探索, 2021, 15(9): 1563-1577. |
| [10] | 方钧婷, 谭晓阳. 注意力级联网络的金属表面缺陷检测算法[J]. 计算机科学与探索, 2021, 15(7): 1245-1254. |
| [11] | 史彩娟, 张卫明, 陈厚儒, 葛录录. 基于深度学习的显著性目标检测综述[J]. 计算机科学与探索, 2021, 15(2): 219-232. |
| [12] | 陈睿龙, 罗磊, 蔡志平, 马文涛. 基于深度学习的实时吸烟检测算法[J]. 计算机科学与探索, 2021, 15(2): 327-337. |
| [13] | 李文涛, 彭力. 多尺度通道注意力融合网络的小目标检测算法[J]. 计算机科学与探索, 2021, 15(12): 2390-2400. |
| [14] | 宋艳艳, 谭励, 马子豪, 任雪平. 改进YOLOV3算法的视频目标检测[J]. 计算机科学与探索, 2021, 15(1): 163-172. |
| [15] | 黄致君,桑庆兵. 改进R-FCN的船舶识别方法[J]. 计算机科学与探索, 2020, 14(6): 1045-1053. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||