
计算机科学与探索 ›› 2022, Vol. 16 ›› Issue (5): 1117-1127.DOI: 10.3778/j.issn.1673-9418.2010008
杨永兆, 张玉金( ), 张立军
), 张立军
收稿日期:2020-10-09
修回日期:2021-03-12
出版日期:2022-05-01
发布日期:2022-05-19
通讯作者:
+ E-mail: yjzhang@sues.edu.cn作者简介:杨永兆(1993—),男,江苏南京人,硕士研究生,主要研究方向为计算机视觉。基金资助:
YANG Yongzhao, ZHANG Yujin(), ZHANG Lijun
Received:2020-10-09
Revised:2021-03-12
Online:2022-05-01
Published:2022-05-19
About author:YANG Yongzhao, born in 1993, M.S. candidate. His research interest is computer vision.Supported by:摘要:
作为高分辨率三维重建的方法之一,从单张图像生成稠密三维点云在计算机视觉领域中一直有着较高的关注度。针对以往这个方法中大多关注目标单一特征信息和使用样本数据量大的问题,提出一个基于特征多样性的多阶段重建稠密点云网络。该网络模型是由第一阶段的3D重建网络和第二阶段的点云处理网络两部分两阶段组成。第一阶段的3D重建网络在融合2D图像目标形状特征与3D点云位姿特征基础上,实现从单张图像重建稀疏点云操作。第二阶段的点云处理网络在稀疏点云基础上提取全局特征和局部特征,通过融合全局和局部点特征增加点的稠密度,得到高分辨率稠密点云。运用深度学习微调技术组合两阶段网络形成一个能从单张图像生成稠密点云的端到端网络。该方法在合成和真实世界数据集上通过大量实验定量和定性分析,结果表明,该方法平均CD值为0.006 98,EMD值为2 823.53,结果优于一些现有方法,且点云重建效果较好。
中图分类号:
杨永兆, 张玉金, 张立军. 由形状结构和位姿特征学习的稠密点云重建[J]. 计算机科学与探索, 2022, 16(5): 1117-1127.
YANG Yongzhao, ZHANG Yujin, ZHANG Lijun. Dense Point Cloud Reconstruction by Shape and Pose Features Learning[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(5): 1117-1127.

图1 不同阶段重建点云
Fig.1 Reconstruction of point cloud at different stages

图2 网络整体结构图
Fig.2 Overall network structure diagram

图3 3D点云重建网络
Fig.3 3D point cloud reconstruction network

图4 稠密点云生成网络
Fig.4 Dense point cloud generation network
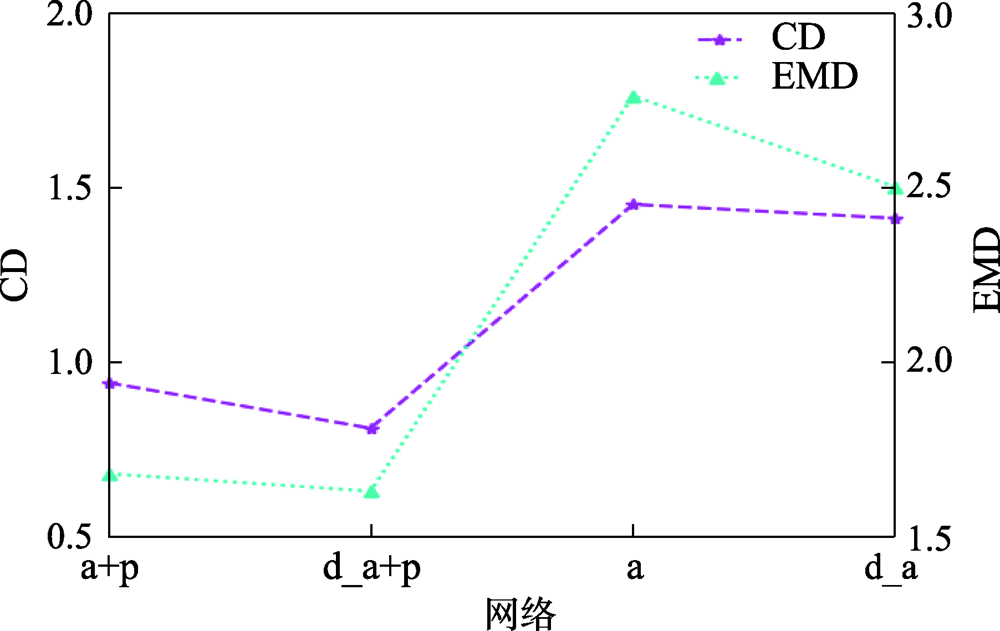
图5 3D重建网络的消融研究
Fig.5 Ablation of 3D reconstruction network
| Metric | DensePCR (sparse) | AttentionDPCR (sparse) | Proposed (sparse) |
|---|---|---|---|
| CD | 7.28 | 1.09 | 0.81 |
| EMD | 3.82 | 2.37 | 1.63 |
表1 与DensePCR、AttentionDPCR在sparse阶段的比较
Table 1 Comparison with DensePCR and AttentionDPCR in sparse phase
| Metric | DensePCR (sparse) | AttentionDPCR (sparse) | Proposed (sparse) |
|---|---|---|---|
| CD | 7.28 | 1.09 | 0.81 |
| EMD | 3.82 | 2.37 | 1.63 |
| Category | DensePCR | AttentionDPCR | Proposed | |||
|---|---|---|---|---|---|---|
| CD | EMD | CD | EMD | CD | EMD | |
| Airplane | 0.012 96 | 7 668.77 | 0.011 44 | 4 478.17 | 0.013 30 | 3 195.51 |
| Bench | 0.050 53 | 7 674.41 | 0.009 35 | 4 736.86 | 0.006 83 | 2 614.49 |
| Cabinet | 0.033 65 | 6 523.34 | 0.005 50 | 5 358.08 | 0.003 39 | 2 597.19 |
| Car | 0.028 27 | 6 609.19 | 0.005 76 | 4 676.27 | 0.003 01 | 2 651.46 |
| Chair | 0.022 47 | 7 166.00 | 0.017 78 | 4 687.47 | 0.012 16 | 3 255.84 |
| Lamp | 0.030 97 | 6 885.38 | 0.009 78 | 4 940.78 | 0.011 85 | 3 252.39 |
| Monitor | 0.061 64 | 7 835.55 | 0.009 40 | 5 193.07 | 0.006 70 | 2 759.85 |
| Rifle | 0.056 24 | 7 685.88 | 0.011 41 | 4 376.69 | 0.005 54 | 2 749.35 |
| Sofa | 0.030 83 | 7 149.55 | 0.010 50 | 4 763.43 | 0.005 52 | 2 748.80 |
| Speaker | 0.029 02 | 6 801.10 | 0.005 30 | 5 343.47 | 0.004 67 | 2 741.46 |
| Table | 0.023 61 | 6 460.96 | 0.006 14 | 4 591.36 | 0.008 54 | 2 953.96 |
| Telephone | 0.022 42 | 5 005.21 | 0.004 75 | 5 213.99 | 0.005 16 | 2 561.94 |
| Vessel | 0.035 37 | 6 975.10 | 0.007 50 | 4 429.93 | 0.004 14 | 2 623.63 |
| Mean | 0.033 69 | 6 956.95 | 0.008 81 | 4 829.96 | 0.006 98 | 2 823.53 |
表2 各算法在ShapeNet上定量结果比较
Table 2 Comparison of quantitative results of various algorithms on ShapeNet
| Category | DensePCR | AttentionDPCR | Proposed | |||
|---|---|---|---|---|---|---|
| CD | EMD | CD | EMD | CD | EMD | |
| Airplane | 0.012 96 | 7 668.77 | 0.011 44 | 4 478.17 | 0.013 30 | 3 195.51 |
| Bench | 0.050 53 | 7 674.41 | 0.009 35 | 4 736.86 | 0.006 83 | 2 614.49 |
| Cabinet | 0.033 65 | 6 523.34 | 0.005 50 | 5 358.08 | 0.003 39 | 2 597.19 |
| Car | 0.028 27 | 6 609.19 | 0.005 76 | 4 676.27 | 0.003 01 | 2 651.46 |
| Chair | 0.022 47 | 7 166.00 | 0.017 78 | 4 687.47 | 0.012 16 | 3 255.84 |
| Lamp | 0.030 97 | 6 885.38 | 0.009 78 | 4 940.78 | 0.011 85 | 3 252.39 |
| Monitor | 0.061 64 | 7 835.55 | 0.009 40 | 5 193.07 | 0.006 70 | 2 759.85 |
| Rifle | 0.056 24 | 7 685.88 | 0.011 41 | 4 376.69 | 0.005 54 | 2 749.35 |
| Sofa | 0.030 83 | 7 149.55 | 0.010 50 | 4 763.43 | 0.005 52 | 2 748.80 |
| Speaker | 0.029 02 | 6 801.10 | 0.005 30 | 5 343.47 | 0.004 67 | 2 741.46 |
| Table | 0.023 61 | 6 460.96 | 0.006 14 | 4 591.36 | 0.008 54 | 2 953.96 |
| Telephone | 0.022 42 | 5 005.21 | 0.004 75 | 5 213.99 | 0.005 16 | 2 561.94 |
| Vessel | 0.035 37 | 6 975.10 | 0.007 50 | 4 429.93 | 0.004 14 | 2 623.63 |
| Mean | 0.033 69 | 6 956.95 | 0.008 81 | 4 829.96 | 0.006 98 | 2 823.53 |
| Metric | angled (sparse) | original (sparse) |
|---|---|---|
| CD | 0.61 | 0.81 |
| EMD | 1.30 | 1.63 |
表3 提议模型在有无方向角度下定量结果比较
Table 3 Comparison of quantitative results of proposed model with or without angle
| Metric | angled (sparse) | original (sparse) |
|---|---|---|
| CD | 0.61 | 0.81 |
| EMD | 1.30 | 1.63 |

图6 稀疏点云重建结果
Fig.6 Reconstruction results of sparse point cloud

图7 各种算法在ShapeNet上定性结果比较
Fig.7 Comparison of qualitative results of various algorithms on ShapeNet
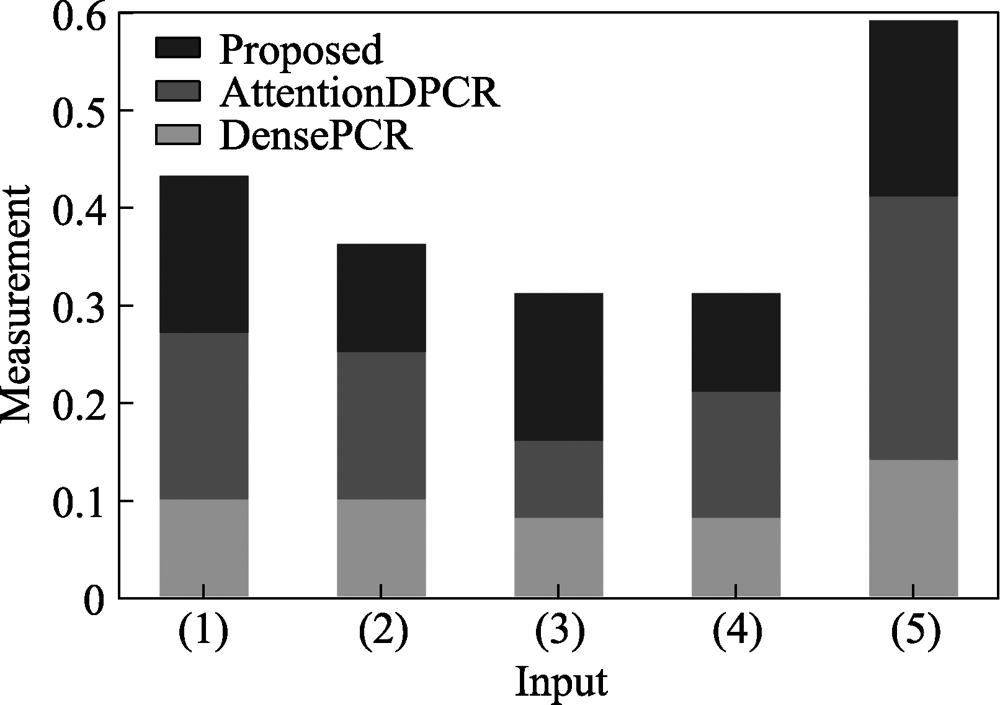
图8 各种算法与Ground Truth相似性度量结果比较
Fig.8 Comparison of similarity measurement results between various algorithms and Ground Truth
| Category | CD | EMD | ||||
|---|---|---|---|---|---|---|
| DensePCR | AttentionDPCR | Proposed | DensePCR | AttentionDPCR | Proposed | |
| Chair | 0.083 03 | 0.018 90 | 0.027 10 | 7 509.14 | 5 356.83 | 4 020.31 |
| Sofa | 0.108 15 | 0.019 88 | 0.010 07 | 8 610.34 | 6 023.24 | 2 771.44 |
| Table | 0.208 19 | 0.033 30 | 0.041 23 | 9 988.14 | 5 654.59 | 4 692.94 |
| Mean | 0.133 12 | 0.024 02 | 0.026 13 | 8 702.54 | 5 678.22 | 3 828.33 |
表4 各算法在Pix3D数据集上定量结果比较
Table 4 Comparison of quantitative results of various algorithms on Pix3D dataset
| Category | CD | EMD | ||||
|---|---|---|---|---|---|---|
| DensePCR | AttentionDPCR | Proposed | DensePCR | AttentionDPCR | Proposed | |
| Chair | 0.083 03 | 0.018 90 | 0.027 10 | 7 509.14 | 5 356.83 | 4 020.31 |
| Sofa | 0.108 15 | 0.019 88 | 0.010 07 | 8 610.34 | 6 023.24 | 2 771.44 |
| Table | 0.208 19 | 0.033 30 | 0.041 23 | 9 988.14 | 5 654.59 | 4 692.94 |
| Mean | 0.133 12 | 0.024 02 | 0.026 13 | 8 702.54 | 5 678.22 | 3 828.33 |

图9 各种算法在Pix3D数据集上定性结果比较
Fig.9 Comparison of qualitative results of various algorithms on Pix3D dataset
| [1] | FAN H, SU H, GUIBAS L J. A point set generation network for 3D object reconstruction from a single image[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Piscataway: IEEE, 2017: 605-613. |
| [2] | LIN C H, KONG C, LUCEY S. Learning efficient point cloud generation for dense 3D object reconstruction[J]. arXiv: 1706.07036, 2017. |
| [3] | QI C R, SU H, MO K, et al. PointNet: deep learning on point sets for 3D classification and segmentation[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Piscataway: IEEE, 2017: 652-660. |
| [4] | QI C R, YI L, SU H, et al. PointNet++: deep hierarchical feature learning on point sets in a metric space[C]// Advances in Neural Information Processing Systems 30, Long Beach, Dec 4-9, 2017. Red Hook: Curran Associates, 2017: 5099-5108. |
| [5] | YU L, LI X, FU C W, et al. PU-Net: point cloud upsampling network[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake, Jun 18-23, 2018. Piscataway: IEEE, 2018: 2790-2799. |
| [6] |
YANG B, ROSA S, MARKHAM A, et al. Dense 3D object reconstruction from a single depth view[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 41(12): 2820-2834.
DOI URL |
| [7] | GIRDHAR R, FOUHEY D F, RODRIGUEZ M, et al. Lear-ning a predictable and generative vector representation for objects[C]// LNCS 9910: Proceedings of the 14th European Conference on Computer Vision, Amsterdam, Oct 11-14, 2016. Cham: Springer, 2016: 484-499. |
| [8] | CHOY C B, XU D, GWAK J Y, et al. 3D-R2N2: a unified approach for single and multi-view 3D object reconstruction[C]// LNCS 9912: Proceedings of the 14th European Conference on Computer Vision, Amsterdam, Oct 11-14, 2016. Cham: Springer, 2016: 628-644. |
| [9] | KURENKOV A, JI J W, GARG A, et al. DeformNet: free-form deformation network for 3D shape reconstruction from a single image[C]// Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, Mar 12-15, 2018. Washington: IEEE Computer Society, 2018: 858-866. |
| [10] | JACK D, PONTES J K, SRIDHARAN S, et al. Learning free-form deformations for 3D object reconstruction[C]// LNCS 11362: Proceedings of the 14th Asian Conference on Computer Vision, Perth, Dec 2-6, 2018. Cham: Springer, 2018: 317-333. |
| [11] | MANDIKAL P, NAVANEET K L, AGARWAL M, et al. 3D-LMNet: latent embedding matching for accurate and diverse 3D point cloud reconstruction from a single image[J]. arXiv: 1807.07796, 2018. |
| [12] |
ZHANG Y, LIU Z, LIU T, et al. RealPoint3D: an efficient generation network for 3D object reconstruction from a single image[J]. IEEE Access, 2019, 7: 57539-57549.
DOI URL |
| [13] | LI K J, PHAM T, ZHAN H Y, et al. Efficient dense point cloud object reconstruction using deformation vector fields[C]// LNCS 11216: Proceedings of the 15th European Conference on Computer Vision, Munich, Sep 8-14, 2018. Cham: Springer, 2018: 508-524. |
| [14] | HUANG Z, YU Y, XU J, et al. PF-Net: point fractal network for 3D point cloud completion[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 7659-7667. |
| [15] |
LI B, ZHANG Y, ZHAO B, et al. 3D-ReConstnet: a single-view 3D-object point cloud reconstruction network[J]. IEEE Access, 2020, 8: 83782-83790.
DOI URL |
| [16] | LIN M, CHEN Q, YAN S. Network in network[J]. arXiv: 1312.4400, 2013. |
| [17] | WANG Y, SUN Y B, LIU Z W, et al. Dynamic graph CNN for learning on point clouds[J]. ACM Transactions on Graphics, 2019, 38(5): 1-12. |
| [18] | WU W X, QI Z A, LI F X. PointConv: deep convolutional networks on 3D point clouds[C]// Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, Jun 16-20, 2019. Piscataway: IEEE, 2019: 9621-9630. |
| [19] | MANDIKAL P, RADHAKRISHNAN V B. Dense 3D point cloud reconstruction using a deep pyramid network[C]// Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision, Waikoloa Village, Jan 7-11, 2019. Piscataway: IEEE, 2019: 1052-1060. |
| [20] |
LU Q, XIAO M J, LU Y Y, et al. Attention-based dense point cloud reconstruction from a single image[J]. IEEE Access, 2019, 7: 137420-137431.
DOI URL |
| [21] | SIMONYAN K, ZISSERNMAN A. Very deep convolutional networks for large-scale image recognition[J]. arXiv:1409.1556, 2014. |
| [22] | WANG F, JIANG M Q, QIAN C, et al. Residual attention network for image classification[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Piscataway: IEEE, 2017: 6450-6458. |
| [23] | FU J, LIU J, TIAN H J, et al. Dual attention network for scene segmentation[C]// Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, Jun 16-20, 2019. Piscataway: IEEE, 2019: 3146-3154. |
| [24] |
JIN X, JING P G, SU Y T. AMFNet: an adversarial network for median filtering detection[J]. IEEE Access, 2018, 6: 50459-50467.
DOI URL |
| [25] | RONNEBERGER O, FISCHER P, BROX T. U-net: convolutional networks for biomedical image segmentation[C]// LNCS 9351: Proceedings of the 2015 International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Oct 5-9, 2015. Cham: Springer, 2015: 234-241. |
| [26] | CHANG A X, FUNKHOUSER T, GUIBAS L, et al. Shape-Net: an information-rich 3D model repository[J]. arXiv:1512.03012, 2015. |
| [27] | FELLBAUM C. WordNet[M]// The Encyclopedia of Applied Linguistics. New York: John Wiley & Sons, Inc., 2012. |
| [28] | SUN X Y, WU J J, ZHANG X M, et al. Pix3D:dataset and methods for single-image 3D shape modeling[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-22, 2018. Washington: IEEE Computer Society, 2018: 2974-2983. |
| [1] | 李昌华,田思敏,周方晓. 自适应分块的BIM墙体轮廓提取及三维重建研究[J]. 计算机科学与探索, 2018, 12(3): 452-461. |
| [2] | 王海菲,贾金原,谢宁. 复杂室内图像的灭点检测与箱体重建方法[J]. 计算机科学与探索, 2016, 10(5): 678-687. |
| [3] | 郭复胜,许华荣,高伟,胡占义. 利用相机辅助信息的分组三维场景重建[J]. 计算机科学与探索, 2013, 7(9): 783-799. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||