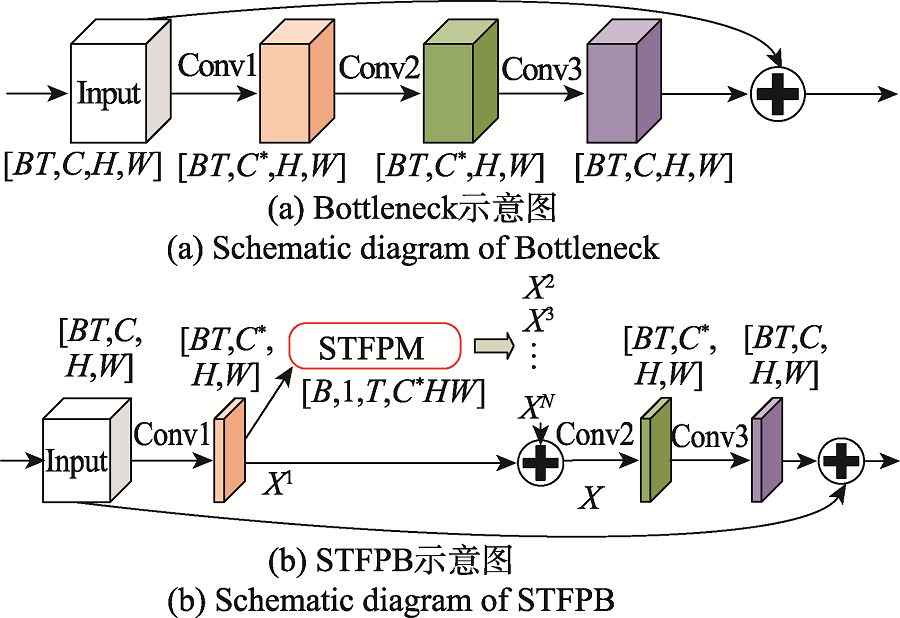
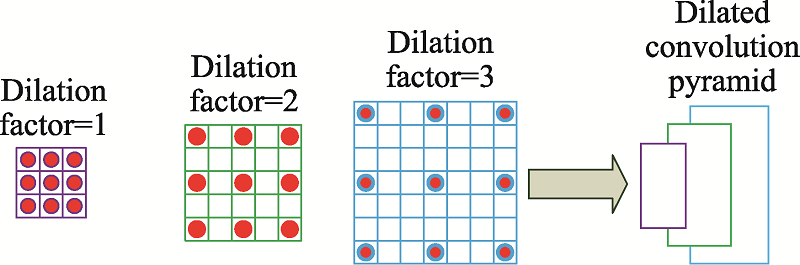
| [1] |
朱红蕾, 朱昶胜, 徐志刚. 人体行为识别数据集研究进展[J]. 自动化学报, 2018, 44(6): 978-1004.
|
|
ZHU H L, ZHU C S, XU Z G. Research progress of human action recognition datasets[J]. Acta Automatica Sinica, 2018, 44(6): 978-1004.
|
| [2] |
IKIZLER-CINBIS N, SCLAROFF S. Object, scene and actions: combining multiple features for human action recognition[C]// LNCS 6311: Proceedings of the 11th Europ-ean Conference on Computer Vision, Heraklion, Sep 5-11, 2010. Berlin, Heidelberg: Springer, 2010: 494-507.
|
| [3] |
张良, 鲁梦梦, 姜华. 局部分布信息增强的视觉单词描述与动作识别[J]. 电子与信息学报, 2016, 38(3): 549-556.
|
|
ZHANG L, LU M M, JIANG H. An improved scheme of visual words description and action recognition using local enhanced distribution information[J]. Journal of Electronics & Information Technology, 2016, 38(3): 549-556.
|
| [4] |
KARPATHY A, TODERICI G, SHETTY S, et al. Large-scale video classification with convolutional neural networks[C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, Jun 23-28, 2014. Washington: IEEE Computer Society, 2014: 1725-1732.
|
| [5] |
SIMONYAN K, ZISSERMAN A. Two-stream convoluti-onal networks for action recognition in videos[C]// Procee-dings of the Annual Conference on Neural Information Processing Systems 2014, Montreal, Dec 8-11, 2014. Red Hook: Curran Associates, 2014: 568-576.
|
| [6] |
WANG L M, XIONG Y J, WANG Z, et al. Temporal segm-ent networks: towards good practices for deep action recognition[C]// LNCS 9912: Proceedings of the 14th European Conference on Computer Vision, Amsterdam, Oct 8-16, 2016. Cham: Springer, 2016: 20-36.
|
| [7] |
周波, 李俊峰. 结合目标检测的人体行为识别[J]. 自动化学报, 2019, 42(5): 56-67.
|
|
ZHOU B, LI J F. Human action recognition combined with object detection[J]. Acta Automatica Sinica, 2019, 42(5): 56-67.
|
| [8] |
刘天亮, 谯庆伟, 万俊伟, 等. 融合空间-时间双网络流和视觉注意的人体行为识别[J]. 电子与信息学报, 2018, 40(10): 2395-2401.
|
|
LIU T L, QIAO Q W, WAN J W, et al. Human action recognition based on spatial-temporal double network flow and visual attention[J]. Journal of Electronics and Inform-ation Technology, 2018, 40(10): 2395-2401.
|
| [9] |
JI S W, XU W, YANG M, et al. 3D convolutional neural networks for human action recognition[J]. IEEE Transa-ctions on Pattern Analysis and Machine Intelligence, 2013, 35(1): 221-231.
|
| [10] |
QIU Z F, YAO T, MEI T. Learning spatio-temporal repr-esentation with pseudo-3D residual networks[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Oct 22-29, 2017. Washington: IEEE Comp-uter Society, 2017: 5533-5541.
|
| [11] |
ZHOU Y, SUN X, ZHA Z J, et al. MICT: mixed 3D/2D convolutional tube for human action recognition[C]// Proce-edings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-22, 2018. Washington: IEEE Computer Society, 2018: 449-458.
|
| [12] |
YU F, KOLTUN V. Multi-scale context aggregation by dil-ated convolutions[C]// Proceedings of the 4th International Conference on Learning Representations, San Juan, May 2-4, 2016: 1-13.
|
| [13] |
HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recogn-ition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Com-puter Society, 2016: 770-778.
|
| [14] |
SOOMRO K, ROSHAN ZAMIR A, SHAH M. UCF101: a dataset of 101 human actions classes from videos in the wild[J]. arXiv:1212.0402, 2012.
|
| [15] |
KUEHNE H, JHUANG H, GARROTE E, et al. HMDB: a large video database for human motion recognition[C]// Pro-ceedings of the 2011 International Conference on Computer Vision, Barcelona, Nov 6-13, 2011. Washington: IEEE Com-puter Society, 2011: 2556-2563.
|
| [16] |
TRAN D, WANG H, TORRESANI L, et al. A closer look at spatiotemporal convolutions for action recognition[C]// Pro-ceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-22, 2018. Washington: IEEE Computer Society, 2018: 6450-6459.
|
| [17] |
VAROL G, LAPTEV I, SCHMID C. Long-term temporal convolutions for action recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(6): 1510-1517.
DOI
URL
|
| [18] |
NG Y H, HAUSKNECHT M J, VIJAYANARASIMHAN S, et al. Beyond short snippets: deep networks for video class-ification[C]// Proceedings of the 2015 IEEE Confer-ence on Computer Vision and Pattern Recognition, Boston, Jun 7-12, 2015. Washington: IEEE Computer Society, 2015: 4694-4702.
|
| [19] |
DIBA A, SHARMA V, VAN GOOL L. Deep temporal lin-ear encoding networks[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 1541-1550.
|
| [20] |
LIN J, GAN C, HAN S. TSM: temporal shift module for efficient video understanding[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Oct 27-Nov 2, 2019. Piscataway: IEEE, 2019: 7082-7092.
|
| [21] |
CARREIRA J, ZISSERMAN A. Quo vadis, action recogn-ition? A new model and the kinetics dataset[C]// Procee-dings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Was-hington: IEEE Computer Society, 2017: 4724-4733.
|
| [22] |
HE D L, ZHOU Z C, GAN C, et al. StNet: local and global spatial-temporal modeling for action recognition[C]// Proc-eedings of the 33rd AAAI Conference on Artificial Intelli-gence, the 31st Innovative Applications of Artificial Intellig-ence Conference, the 9th AAAI Symposium on Educational Advances in Artificial Intelligence, Honolulu, Jan 27-Feb 1, 2019. Menlo Park: AAAI, 2019: 8401-8408.
|
| [23] |
ZHU Y, LAN Z Z, NEWSAM S D, et al. Hidden two-stream convolutional networks for action recognition[C]// LNCS 11363: Proceedings of the 14th Asian Conference on Computer Vision, Perth, Dec 2-6, 2018. Cham: Springer, 2018: 363-378.
|
| [24] |
LI X, WANG J, MA L, et al. STH: spatio-temporal hybrid convolution for efficient action recognition[J]. arXiv:2003.08042, 2020.
|
| [25] |
DU Y, YUAN C F, LI B, et al. Interaction-aware spatio-temporal pyramid attention networks for action classifica-tion[C]// LNCS 11220: Proceedings of the 15th European Conference on Computer Vision, Munich, Sep 8-14, 2018. Cham: Springer, 2018: 388-404.
|

 )
)