
计算机科学与探索 ›› 2022, Vol. 16 ›› Issue (9): 2078-2088.DOI: 10.3778/j.issn.1673-9418.2102018
刘学文1, 王继奎1,+( ), 杨正国1, 李冰1, 聂飞平2
), 杨正国1, 李冰1, 聂飞平2
收稿日期:2021-02-03
修回日期:2021-04-06
出版日期:2022-09-01
发布日期:2021-04-19
通讯作者:
+ E-mail: wjkweb@163.com作者简介:刘学文(1996—),男,硕士研究生,主要研究方向为机器学习、人工智能、大数据应用。基金资助:
LIU Xuewen1, WANG Jikui1,+(), YANG Zhengguo1, LI Bing1, NIE Feiping2
Received:2021-02-03
Revised:2021-04-06
Online:2022-09-01
Published:2021-04-19
About author:LIU Xuewen, born in 1996, M.S. candidate. His research interests include machine learning, arti-ficial intelligence and big data applications.Supported by:摘要:
现实中由于获取标签的成本很高,大部分的数据只含有少量标签。相比监督学习和无监督学习,半监督学习能充分利用数据集中的大量无标签数据和少量有标签数据,以较少的标签成本获得较高的学习性能。自训练算法是一种经典的半监督学习算法,在其迭代优化分类器的过程中,不断从无标签样本中选取高置信度样本并由基分类器赋予标签,再将这些样本和伪标签添加进训练集。选取高置信度样本是Self-Training算法的关键,受密度峰值聚类算法(DPC)启发,将密度峰值用于高置信度样本的选取,提出了密度峰值隶属度优化的半监督Self-Training算法(STDPM)。首先,STDPM利用密度峰值发现样本的潜在空间结构信息并构造原型树。其次,搜索有标签样本在原型树上的无标签近亲结点,将无标签近亲结点的隶属于不同类簇的峰值定义为簇峰值,归一化后作为密度峰值隶属度。最后,将隶属度大于设定阈值的样本作为高置信度样本,由基分类器赋予标签后添加进训练集。STDPM充分利用密度峰值所隐含的密度和距离信息,提升了高置信度样本的选取质量,进而提升了分类性能。在8个基准数据集上进行对比实验,结果验证了STDPM算法的有效性。
中图分类号:
刘学文, 王继奎, 杨正国, 李冰, 聂飞平. 密度峰值隶属度优化的半监督Self-Training算法[J]. 计算机科学与探索, 2022, 16(9): 2078-2088.
LIU Xuewen, WANG Jikui, YANG Zhengguo, LI Bing, NIE Feiping. Semi-supervised Self-Training Algorithm for Density Peak Membership Optimization[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(9): 2078-2088.
| 符号 | 说明 |
|---|---|
| | 包含 |
| | 包含 |
| | 包含 |
| | 包含 |
| | 样本 |
| | 包含样本 |
| | 样本 |
| | 包含 |
表1 STDPM中的符号
Table 1 Notations in STDPM
| 符号 | 说明 |
|---|---|
| | 包含 |
| | 包含 |
| | 包含 |
| | 包含 |
| | 样本 |
| | 包含样本 |
| | 样本 |
| | 包含 |
| 标记 | | | | |
|---|---|---|---|---|
| 1 | 1.000 | 1.000 | 1.000 | 1 |
| 2 | 0.690 | 0.747 | 0.515 | 12 |
| 3 | 0.513 | 0.571 | 0.293 | 2 |
| 4 | 0.443 | 0.183 | 0.081 | 15 |
| 5 | 0.831 | 0.028 | 0.023 | 1 |
| 6 | 0.301 | 0.068 | 0.020 | 7 |
| 7 | 0.496 | 0.034 | 0.017 | 3 |
| 8 | 0.223 | 0.059 | 0.013 | 5 |
| 9 | 0.160 | 0.077 | 0.012 | 2 |
| 10 | 0.443 | 0.022 | 0.010 | 4 |
| 11 | 0.055 | 0.110 | 0.006 | 3 |
| 12 | 0.829 | 0.001 | 0.001 | 1 |
| 13 | 0.002 | 0.155 | 0.000 | 11 |
| 14 | 0.000 | 0.186 | 0.000 | 12 |
| 15 | 0.639 | 0.000 | 0.000 | 2 |
表2 样本信息
Table 2 Samples information
| 标记 | | | | |
|---|---|---|---|---|
| 1 | 1.000 | 1.000 | 1.000 | 1 |
| 2 | 0.690 | 0.747 | 0.515 | 12 |
| 3 | 0.513 | 0.571 | 0.293 | 2 |
| 4 | 0.443 | 0.183 | 0.081 | 15 |
| 5 | 0.831 | 0.028 | 0.023 | 1 |
| 6 | 0.301 | 0.068 | 0.020 | 7 |
| 7 | 0.496 | 0.034 | 0.017 | 3 |
| 8 | 0.223 | 0.059 | 0.013 | 5 |
| 9 | 0.160 | 0.077 | 0.012 | 2 |
| 10 | 0.443 | 0.022 | 0.010 | 4 |
| 11 | 0.055 | 0.110 | 0.006 | 3 |
| 12 | 0.829 | 0.001 | 0.001 | 1 |
| 13 | 0.002 | 0.155 | 0.000 | 11 |
| 14 | 0.000 | 0.186 | 0.000 | 12 |
| 15 | 0.639 | 0.000 | 0.000 | 2 |

图1 样本分布和原型树示意图
Fig.1 Samples distribution and illustration of prototype tree

图2 簇峰值计算示意图
Fig.2 Illustration of calculating clusters-peak
| 算法 | 参数 |
|---|---|
| STDPM | |
| SETRED | |
| STDP | |
| STDPCEW | |
| STSFCM | |
表3 参数设置
Table 3 Parameters setting
| 算法 | 参数 |
|---|---|
| STDPM | |
| SETRED | |
| STDP | |
| STDPCEW | |
| STSFCM | |
| 数据集 | 样本数 | 维度 | 类簇数 |
|---|---|---|---|
| Banknote | 1 372 | 4 | 2 |
| Breast | 699 | 10 | 2 |
| Hepatitis | 142 | 13 | 2 |
| Ionosphere | 351 | 34 | 2 |
| Palm | 2 000 | 256 | 100 |
| Segment | 2 310 | 19 | 7 |
| Yale | 165 | 1 024 | 15 |
| Zoo | 101 | 16 | 7 |
表4 数据集信息
Table 4 Datasets information
| 数据集 | 样本数 | 维度 | 类簇数 |
|---|---|---|---|
| Banknote | 1 372 | 4 | 2 |
| Breast | 699 | 10 | 2 |
| Hepatitis | 142 | 13 | 2 |
| Ionosphere | 351 | 34 | 2 |
| Palm | 2 000 | 256 | 100 |
| Segment | 2 310 | 19 | 7 |
| Yale | 165 | 1 024 | 15 |
| Zoo | 101 | 16 | 7 |
| 指标 | 算法 | Banknote | Breast | Hepatitis | Ionosphere |
|---|---|---|---|---|---|
| Accuracy | STDPM | 99.57±0.43 | 58.87±3.05 | 61.33±9.73 | 88.59±3.08 |
| SETRED | 99.37±0.56 | 58.77±1.84 | 59.23±8.83 | 86.78±2.75 | |
| STDP | 99.10±0.55 | 57.18±1.21 | 58.50±4.69 | 85.59±4.07 | |
| STDPCEW | 99.39±0.55 | 57.22±2.53 | 53.77±3.72 | 86.98±4.23 | |
| STSFCM | 99.38±0.52 | 57.05±2.77 | 56.65±4.28 | 87.81±1.35 | |
| F-score | STDPM | 99.35±0.95 | 58.51±2.70 | 60.90±4.51 | 87.50±3.40 |
| SETRED | 99.14±1.24 | 58.42±2.99 | 58.46±9.51 | 85.97±3.93 | |
| STDP | 98.96±0.97 | 57.43±2.74 | 58.38±7.69 | 84.58±2.67 | |
| STDPCEW | 99.19±0.42 | 57.51±2.56 | 52.95±9.96 | 86.24±2.92 | |
| STSFCM | 99.21±0.59 | 57.21±1.78 | 55.77±8.12 | 86.88±2.97 |
表5 Performance on Banknote, Breast, Hepatitis and Ionosphere datasets (mean±std) 单位:%
Table 5
| 指标 | 算法 | Banknote | Breast | Hepatitis | Ionosphere |
|---|---|---|---|---|---|
| Accuracy | STDPM | 99.57±0.43 | 58.87±3.05 | 61.33±9.73 | 88.59±3.08 |
| SETRED | 99.37±0.56 | 58.77±1.84 | 59.23±8.83 | 86.78±2.75 | |
| STDP | 99.10±0.55 | 57.18±1.21 | 58.50±4.69 | 85.59±4.07 | |
| STDPCEW | 99.39±0.55 | 57.22±2.53 | 53.77±3.72 | 86.98±4.23 | |
| STSFCM | 99.38±0.52 | 57.05±2.77 | 56.65±4.28 | 87.81±1.35 | |
| F-score | STDPM | 99.35±0.95 | 58.51±2.70 | 60.90±4.51 | 87.50±3.40 |
| SETRED | 99.14±1.24 | 58.42±2.99 | 58.46±9.51 | 85.97±3.93 | |
| STDP | 98.96±0.97 | 57.43±2.74 | 58.38±7.69 | 84.58±2.67 | |
| STDPCEW | 99.19±0.42 | 57.51±2.56 | 52.95±9.96 | 86.24±2.92 | |
| STSFCM | 99.21±0.59 | 57.21±1.78 | 55.77±8.12 | 86.88±2.97 |
| 指标 | 算法 | Palm | Segment | Yale | Zoo |
|---|---|---|---|---|---|
| Accuracy | STDPM | 90.52±0.40 | 93.64±0.69 | 78.84±3.24 | 91.29±1.46 |
| SETRED | 88.18±0.60 | 93.54±0.66 | 77.63±2.88 | 87.73±3.07 | |
| STDP | 88.16±0.46 | 93.38±0.58 | 76.47±2.05 | 87.93±2.83 | |
| STDPCEW | 90.48±0.91 | 93.47±0.66 | 77.98±2.32 | 88.48±2.03 | |
| STSFCM | 88.45±0.59 | 93.23±0.56 | 78.55±1.81 | 87.60±3.15 | |
| F-score | STDPM | 88.11±1.02 | 93.33±0.76 | 62.88±7.12 | 88.09±2.48 |
| SETRED | 84.54±1.25 | 93.22±0.73 | 58.92±5.59 | 81.02±7.25 | |
| STDP | 84.59±1.12 | 93.05±0.64 | 55.79±7.69 | 79.89±6.90 | |
| STDPCEW | 87.98±1.33 | 93.14±0.73 | 57.30±6.65 | 82.76±5.52 | |
| STSFCM | 85.03±1.10 | 92.89±0.62 | 61.05±3.18 | 78.63±6.94 |
表6 Performance on Palm, Segment, Yale and Zoo datasets (mean±std) 单位:%
Table 6
| 指标 | 算法 | Palm | Segment | Yale | Zoo |
|---|---|---|---|---|---|
| Accuracy | STDPM | 90.52±0.40 | 93.64±0.69 | 78.84±3.24 | 91.29±1.46 |
| SETRED | 88.18±0.60 | 93.54±0.66 | 77.63±2.88 | 87.73±3.07 | |
| STDP | 88.16±0.46 | 93.38±0.58 | 76.47±2.05 | 87.93±2.83 | |
| STDPCEW | 90.48±0.91 | 93.47±0.66 | 77.98±2.32 | 88.48±2.03 | |
| STSFCM | 88.45±0.59 | 93.23±0.56 | 78.55±1.81 | 87.60±3.15 | |
| F-score | STDPM | 88.11±1.02 | 93.33±0.76 | 62.88±7.12 | 88.09±2.48 |
| SETRED | 84.54±1.25 | 93.22±0.73 | 58.92±5.59 | 81.02±7.25 | |
| STDP | 84.59±1.12 | 93.05±0.64 | 55.79±7.69 | 79.89±6.90 | |
| STDPCEW | 87.98±1.33 | 93.14±0.73 | 57.30±6.65 | 82.76±5.52 | |
| STSFCM | 85.03±1.10 | 92.89±0.62 | 61.05±3.18 | 78.63±6.94 |
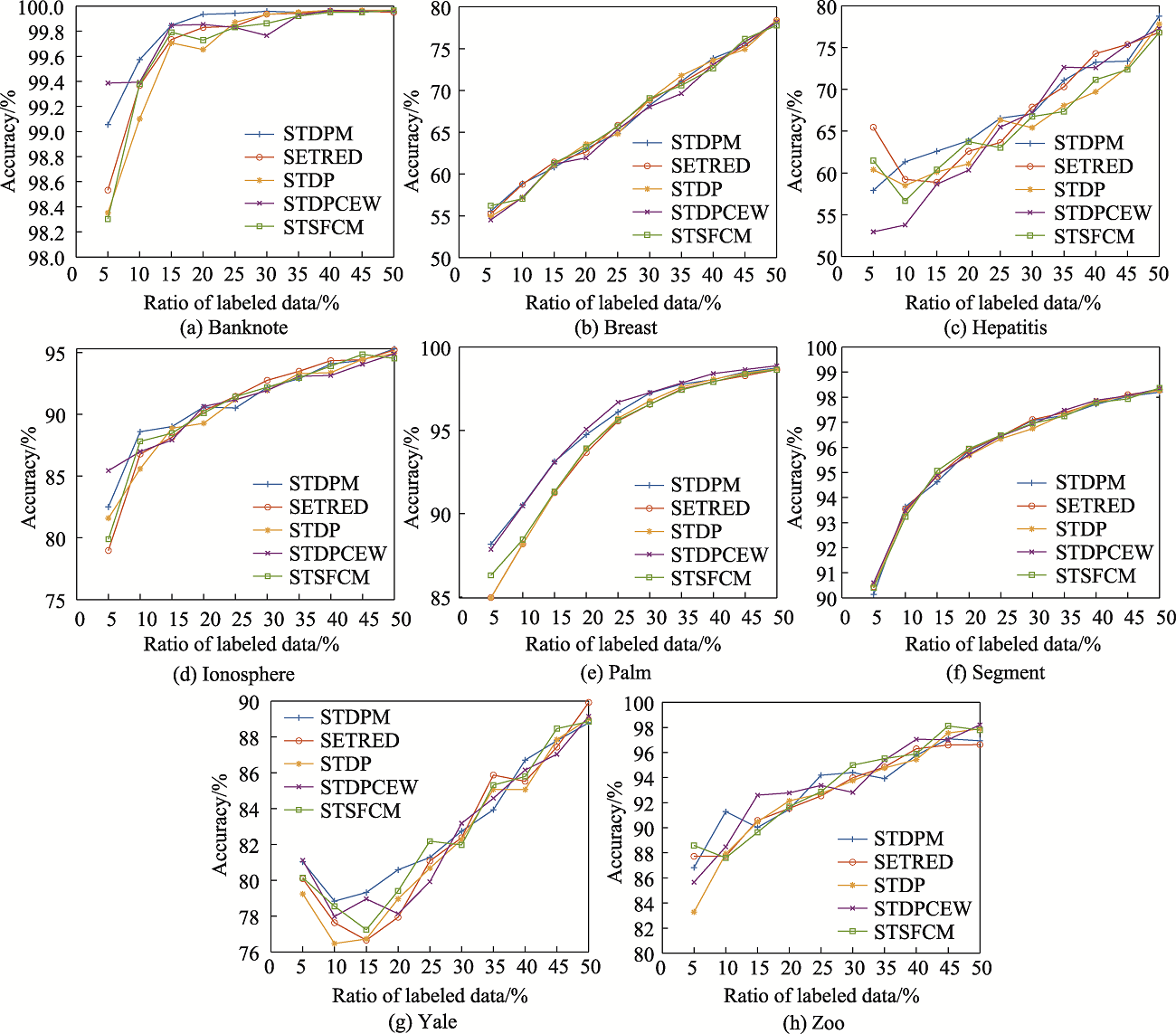
图3 不同有标签样本比例数据集上的准确率
Fig.3 Accuracy on different ratios of labeled datasets
| 数据集 | STDPM | SETRED | STDP | STDPCEW | STSFCM | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 时间/ms | 迭代次数 | 时间/ms | 迭代次数 | 时间/ms | 迭代次数 | 时间/ms | 迭代次数 | 时间/ms | 迭代次数 | |||||
| Banknote | 398 | 11 | 6 148 | 6 | 227 | 4 | 92 256 | 30 | 18 | 2 | ||||
| Breast | 169 | 9 | 2 362 | 21 | 85 | 4 | 13 818 | 40 | 15 | 2 | ||||
| Hepatitis | 59 | 6 | 1 331 | 10 | 39 | 3 | 228 | 7 | 12 | 2 | ||||
| Ionosphere | 85 | 8 | 1 516 | 15 | 46 | 4 | 989 | 17 | 14 | 2 | ||||
| Palm | 1 428 | 10 | 32 183 | 13 | 559 | 6 | 246 625 | 20 | 418 | 6 | ||||
| Segment | 1 042 | 12 | 62 533 | 21 | 726 | 4 | 564 969 | 24 | 90 | 7 | ||||
| Yale | 65 | 5 | 1 661 | 6 | 31 | 4 | 214 | 16 | 38 | 4 | ||||
| Zoo | 37 | 4 | 1 477 | 9 | 38 | 4 | 103 | 12 | 19 | 3 | ||||
表7 运行时间对比
Table 7 Comparison of running time
| 数据集 | STDPM | SETRED | STDP | STDPCEW | STSFCM | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 时间/ms | 迭代次数 | 时间/ms | 迭代次数 | 时间/ms | 迭代次数 | 时间/ms | 迭代次数 | 时间/ms | 迭代次数 | |||||
| Banknote | 398 | 11 | 6 148 | 6 | 227 | 4 | 92 256 | 30 | 18 | 2 | ||||
| Breast | 169 | 9 | 2 362 | 21 | 85 | 4 | 13 818 | 40 | 15 | 2 | ||||
| Hepatitis | 59 | 6 | 1 331 | 10 | 39 | 3 | 228 | 7 | 12 | 2 | ||||
| Ionosphere | 85 | 8 | 1 516 | 15 | 46 | 4 | 989 | 17 | 14 | 2 | ||||
| Palm | 1 428 | 10 | 32 183 | 13 | 559 | 6 | 246 625 | 20 | 418 | 6 | ||||
| Segment | 1 042 | 12 | 62 533 | 21 | 726 | 4 | 564 969 | 24 | 90 | 7 | ||||
| Yale | 65 | 5 | 1 661 | 6 | 31 | 4 | 214 | 16 | 38 | 4 | ||||
| Zoo | 37 | 4 | 1 477 | 9 | 38 | 4 | 103 | 12 | 19 | 3 | ||||

图4 不同参数 α和 β在不同数据集上的准确率
Fig.4 Accuracy on different datasets with different parameters α and β
| [1] | SEN P C, HAJRA M, GHOSH M. Supervised classification algorithms in machine learning: a survey and review[C]// Proceedings of IEM Graph 2018. Cham: Springer, 2020: 99-111. |
| [2] | ALLOGHANI M, AL-JUMEILY D, MUSTAFINA J, et al. A systematic review on supervised and unsupervised ma-chine learning algorithms for data science[M]// BERRYM W, MOHAMEDA, YAPB W. Supervised and Unsuper-vised Learning for Data Science. Cham: Springer, 2020: 3-21. |
| [3] |
CHONG Y, DING Y, YAN Q, et al. Graph-based semi-super-vised learning: a review[J]. Neurocomputing, 2020, 408: 216-230.
DOI URL |
| [4] | KOSTOPOULOS G, KARLOS S, KOTSIANTIS S, et al. Semi-supervised regression: a recent review[J]. Journal of In-telligent & Fuzzy Systems, 2018, 35(2): 1483-1500. |
| [5] |
韩嵩, 韩秋弘. 半监督学习研究的述评[J]. 计算机工程与应用, 2020, 56(6): 19-27.
DOI |
| HAN S, HAN Q H. Review of semi-supervised learning re-search[J]. Computer Engineering and Applications, 2020, 56(6): 19-27. | |
| [6] | LI M, ZHOU Z H. SETRED: self-training with editing[C]// LNCS 3518: Proceedings of the 9th Pacific-Asia Conference on Knowledge Discovery and Data Mining, Hanoi, May 18-20, 2005. Berlin, Heidelberg: Springer, 2005: 611-621. |
| [7] | ZIGHED D A, LALLICH S, MUHLENBACH F. Separa-bility index in supervised learning[C]// LNCS 2431: Procee-dings of the 6th European Conference on Principles of Data Mining and Knowledge Discovery, Helsinki, Aug 19-23, 2002. Berlin, Heidelberg: Springer, 2002: 475-487. |
| [8] |
MUHLENBACH F, LALLICH S, ZIGHED D A. Iden-tifying and handling mislabelled instances[J]. Journal of Intelligent Information Systems, 2004, 22(1): 89-109.
DOI URL |
| [9] |
XIA S, PENG D, MENG D, et al. A fast adaptive k-means with no bounds[J]. IEEE Transactions on Pattern Analy-sis and Machine Intelligence, 2020. DOI: 10.1109/TPAMI. 2020.3008694.
DOI |
| [10] | HASECKE F, HAHN L, KUMMERT A. Fast lidar clus-tering by density and connectivity[J]. arXiv:2003.00575, 2020. |
| [11] | GAN H, SANG N, HUANG R, et al. Using clustering ana-lysis to improve semi-supervised classification[J]. Neurocom-puting, 2013, 101: 290-298. |
| [12] | GAN H, TONG X, JIANG Q, et al. Discussion of FCM al-gorithm with partial supervision[C]// Proceedings of the 8th International Symposium on Distributed Computing and Applications to Business, Engineering and Science, Wuhan, 2009. Beijing: Publishing House of Electronics Industry, 2009: 27-31. |
| [13] | TONG X, JIANG Q, SANG N, et al. The feature weighted FCM algorithm with semi-supervised[C]// Proceedings of the 8th International Symposium on Distributed Computing and Applications to Business, Engineering and Science,Wuhan, 2009. Beijing: Publishing House of Electronics Industry, 2009: 22-26. |
| [14] |
RODRIGUEZ A, LAIO A. Clustering by fast search and find of density peaks[J]. Science, 2014, 344(6191): 1492-1496.
DOI URL |
| [15] | 陈叶旺, 申莲莲, 钟才明, 等. 密度峰值聚类算法综述[J]. 计算机研究与发展, 2020, 57(2): 378-394. |
| CHEN Y W, SHEN L L, ZHONG C M, et al. Survey on density peak clustering algorithm[J]. Journal of Computer Research and Development, 2020, 57(2): 378-394. | |
| [16] |
丁志成, 葛洪伟. 优化分配策略的密度峰值聚类算法[J]. 计算机科学与探索, 2020, 14(5): 792-802.
DOI |
| DING Z C, GE H W. Density peaks clustering with opti-mized allocation strategy[J]. Journal of Frontiers of Com-puter Science and Technology, 2020, 14(5): 792-802. | |
| [17] | 丁世飞, 徐晓, 王艳茹. 基于不相似性度量优化的密度峰值聚类算法[J]. 软件学报, 2020, 31(11): 3321-3333. |
| DING S F, XU X, WANG Y R. Optimized density peaks clustering algorithm based on dissimilarity measure[J]. Jour-nal of Software, 2020, 31(11): 3321-3333. | |
| [18] |
柏锷湘, 罗可, 罗潇. 结合自然和共享最近邻的密度峰值聚类算法[J]. 计算机科学与探索, 2021, 15(5): 931-940.
DOI |
| BAI E X, LUO K, LUO X. Peak density clustering algori-thm combining natural and shared nearest neighbor[J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(5): 931-940. | |
| [19] |
刘娟, 万静. 自然反向最近邻优化的密度峰值聚类算法[J]. 计算机科学与探索, 2021, 15(10): 1888-1899.
DOI |
| LIU J, WAN J. Optimized density peak clustering algorithm by natural reverse nearest neighbor[J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(10): 1888-1899. | |
| [20] |
钱雪忠, 金辉. 自适应聚合策略优化的密度峰值聚类算法[J]. 计算机科学与探索, 2020, 14(4): 712-720.
DOI |
| QIAN X Z, JIN H. Optimized density peak clustering algo-rithm by adaptive aggregation strategy[J]. Journal of Frontiers of Computer Science and Technology, 2020, 14(4): 712-720. | |
| [21] |
刘沧生, 许青林. 基于密度峰值优化的模糊C均值聚类算法[J]. 计算机工程与应用, 2018, 54(14): 153-157.
DOI |
| LIU C S, XU Q L. Fuzzy C-means clustering algorithm based on density peak value optimization[J]. Computer Enginee-ring and Applications, 2018, 54(14): 153-157. | |
| [22] | WU D, SHANG M, LUO X, et al. Self-training semi-super-vised classification based on density peaks of data[J]. Neu-rocomputing, 2018, 275: 180-191. |
| [23] | 艾震鹏, 王振友. 基于数据密度的半监督自训练分类算法[J]. 计算机应用研究, 2019, 36(4): 1072-1074. |
| AI Z P, WANG Z Y. Self-training semi-supervised classifi-cation based on density of data[J]. Application Research of Computers, 2019, 36(4): 1072-1074. | |
| [24] |
卫丹妮, 杨有龙, 仇海全. 结合密度峰值和切边权值的自训练算法[J]. 计算机工程与应用, 2021, 57(2): 70-76.
DOI |
| WEI D N, YANG Y L, QIU H Q. Self-training algorithm combining density peak and cut edge weight[J]. Computer Engineering and Applications, 2021, 57(2): 70-76. |
| [1] | 陈洋, 王士同. 多样性正则化极限学习机的集成方法[J]. 计算机科学与探索, 2022, 16(8): 1819-1928. |
| [2] | 谢娟英, 张凯云. XR-MSF-Unet:新冠肺炎肺部CT图像自动分割模型[J]. 计算机科学与探索, 2022, 16(8): 1850-1864. |
| [3] | 杨政, 邓赵红, 罗晓清, 顾鑫, 王士同. 利用ELM-AE和迁移表征学习构建的目标跟踪系统[J]. 计算机科学与探索, 2022, 16(7): 1633-1648. |
| [4] | 张壮, 王士同. 不平衡数据的Takagi-Sugeno-Kang模糊分类集成模型[J]. 计算机科学与探索, 2022, 16(6): 1374-1382. |
| [5] | 谢欣彤, 胡悦阳, 刘譞哲, 赵耀帅, 姜海鸥. 传播用户代表性特征学习的谣言检测方法[J]. 计算机科学与探索, 2022, 16(6): 1334-1342. |
| [6] | 董文波, 孙仕亮, 殷敏智. 医学知识推理研究现状与发展[J]. 计算机科学与探索, 2022, 16(6): 1193-1213. |
| [7] | 申瑞彩, 翟俊海, 侯璎真. 选择性集成学习多判别器生成对抗网络[J]. 计算机科学与探索, 2022, 16(6): 1429-1438. |
| [8] | 林佳伟, 王士同. 用于无监督域适应的深度对抗重构分类网络[J]. 计算机科学与探索, 2022, 16(5): 1107-1116. |
| [9] | 孙武, 邓赵红, 娄琼丹, 顾鑫, 王士同. 基于模糊规则学习的无监督异构领域自适应[J]. 计算机科学与探索, 2022, 16(2): 403-412. |
| [10] | 章枫叶欣, 王骏, 贾修一, 潘祥, 邓赵红, 施俊, 王士同. 面向多分类自闭症辅助诊断的标记分布学习[J]. 计算机科学与探索, 2022, 16(1): 194-204. |
| [11] | 付 彬, 王志海, 王中锋. 最大化边际的分类器选取算法 [J]. 计算机科学与探索, 2011, 5(1): 59-67. |
| [12] | 潘世瑞1 , 张阳1,2+ , 李雪 3 , 王勇 4 . 针对不确定正例和未标记学习的最近邻算法*[J]. 计算机科学与探索, 2010, 4(9): 769-779. |
| [13] | 袁 磊1 , 张 阳2+ , 李 梅1 , 李 雪3 , 王 勇4 . 在数据流管理系统中实现快速决策树算法*[J]. 计算机科学与探索, 2010, 4(8): 673-682. |
| [14] | 石国强, 牛常勇, 范 明+ . 使用PCA建立基于规则的组合分类器*[J]. 计算机科学与探索, 2010, 4(5): 455-463. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||