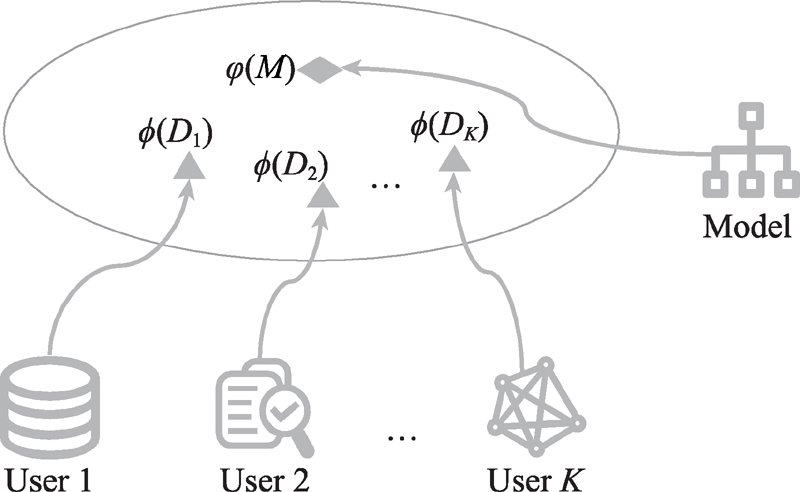
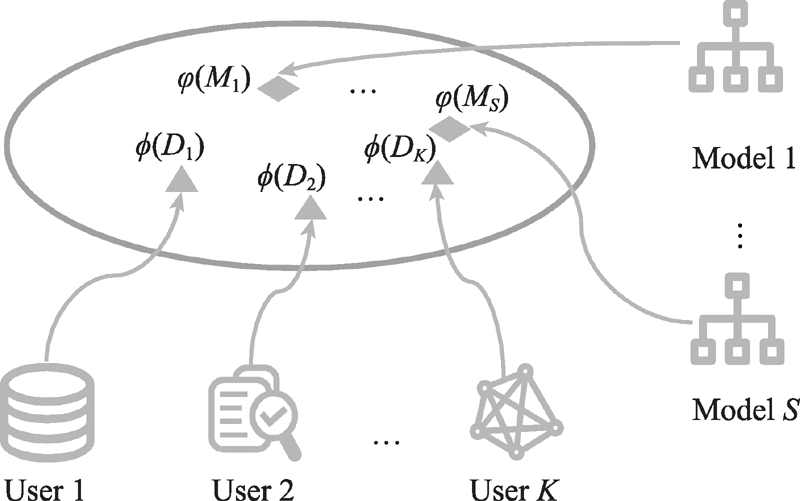
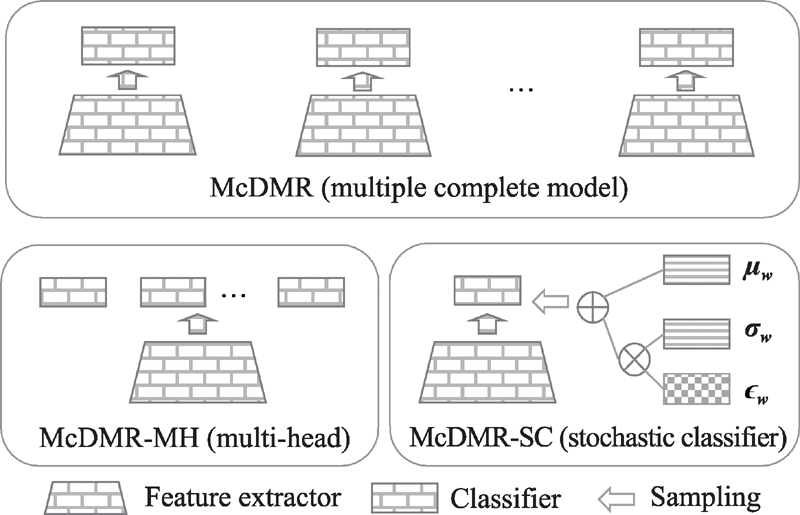
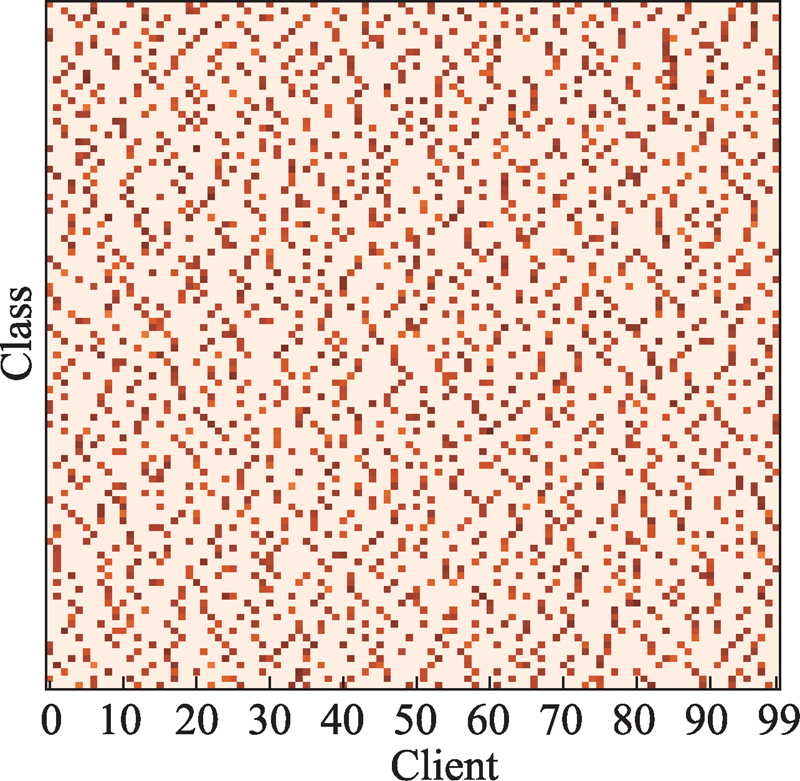
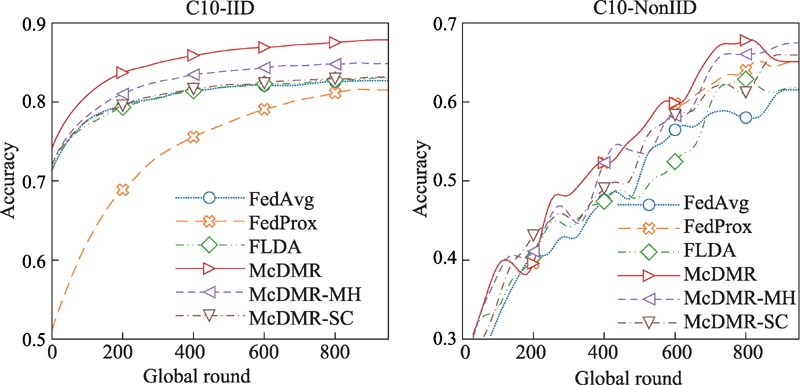
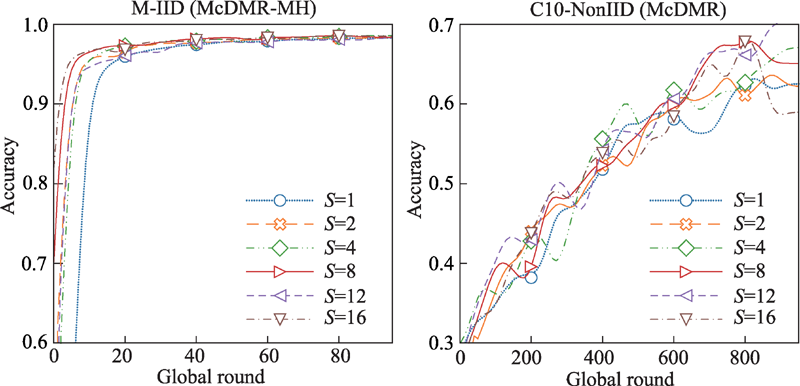
| [1] |
KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[C]// Advances in Neural Information Processing Systems 25, Lake Tahoe, Dec 3-6, 2012. Red Hook: Curran Associates, 2012: 1106-1114.
|
| [2] |
HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 770-778.
|
| [3] |
DEAN J, CORRADO G S, MONGA R, et al. Large scale distributed deep networks[C]// Advances in Neural Information Processing Systems 25, Lake Tahoe, Dec 3-6, 2012. Red Hook: Curran Associates, 2012: 1232-1240.
|
| [4] |
朱泓睿, 元国军, 姚成吉, 等. 分布式深度学习训练网络综述[J]. 计算机研究与发展, 2021, 58(1): 98-115.
|
|
ZHU H R, YUAN G J, YAO C J, et al. Survey on network of distributed deep learning training[J]. Journal of Computer Research and Development, 2021, 58(1): 98-115.
|
| [5] |
MCMAHAN B, MOORE E, RAMAGE D, et al. Communi-cation-efficient learning of deep networks from decentralized data[C]// Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale,Apr 20-22, 2017. New York: ACM, 2017: 1273-1282.
|
| [6] |
LI M, ZHOU L, YANG Z, et al. Parameter server for distri-buted machine learning[C]// Advances in Neural Informa-tion Processing Systems 26, Lake Tahoe, Dec 5-10, 2013. Red Hook: Curran Associates, 2013: 2.
|
| [7] |
ABADI M, CHU A, GOODFELLOW I, et al. Deep learning with differential privacy[C]// Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Oct 24-28, 2016. New York: ACM, 2016: 308-318.
|
| [8] |
LIU Y, KANG Y, XING C, et al. A secure federated transfer learning framework[J]. IEEE Intelligent Systems, 2020, 35(4): 70-82.
DOI
URL
|
| [9] |
ZHOU Z H. Learnware: on the future of machine learning[J]. Frontiers in Computer Science, 2016, 10(4): 589-590.
|
| [10] |
ZHAO Y, LI M, LAI L, et al. Federated learning with non-IID data[J]. arXiv:1806.00582, 2018.
|
| [11] |
WU X Z, LIU S, ZHOU Z H. Heterogeneous model reuse via optimizing multiparty multiclass margin[C]// Proceedings of the 36th International Conference on Machine Learning,California, Jun 9-15, 2019. New York: ACM, 2019: 6840-6849.
|
| [12] |
LI T, SAHU A K, ZAHEER M, et al. Federated optimization in heterogeneous networks[J]. arXiv:1812.06127, 2018.
|
| [13] |
YAO X, HUANG C, SUN L. Two-stream federated learning: reduce the communication costs[C]// Proceedings of the 2018 IEEE Visual Communications and Image Processing, Taichung, China, Dec 9-12, 2018. Piscataway: IEEE, 2018: 1-4.
|
| [14] |
ARIVAZHAGAN M G, AGGARWAL V, SINGH A K, et al. Federated learning with personalization layers[J]. arXiv:1912.00818, 2019.
|
| [15] |
PETERSON D, KANANI P, MARATHE V J. Private federated learning with domain adaptation[J]. arXiv:1912.06733, 2019.
|
| [16] |
KARIMIREDDY S P, KALE S, MOHRI M, et al. SCAFFOLD: stochastic controlled averaging for federated learning[C]// Proceedings of the 37th International Conference on Machine Learning. New York: ACM, 2020: 5132-5143.
|
| [17] |
SMITH V, CHIANG C K, SANJABI M, et al. Federated multi-task learning[J]. arXiv:1705.10467, 2017.
|
| [18] |
JIANG Y, KONEČNÝ J, RUSH K, et al. Improving federated learning personalization via model agnostic meta learning[J]. arXiv:1909.12488, 2019.
|
| [19] |
ZHANG M L, ZHOU Z H. Exploiting unlabeled data to enhance ensemble diversity[J]. Data Mining and Knowledge Discovery, 2013, 26(1): 98-129.
DOI
URL
|
| [20] |
ZHOU Z H, LI N. Multi-information ensemble diversity[C]// LNCS 5997: Proceedings of the 9th International Workshop on Multiple Classifier Systems, Cairo, Apr 7-9, 2010. Berlin, Heidelberg: Springer, 2010: 134-144.
|
| [21] |
HINTON G, VINYALS O, DEAN J. Distilling the knowledge in a neural network[J]. arXiv:1503.02531, 2015.
|
| [22] |
GAO H, LI Y, PLEISS G, et al. Snapshot ensembles: train 1, get M for free[J]. arXiv:1704.00109, 2017.
|
| [23] |
LI H, NG J Y H, NATSEV P. EnsembleNet: end-to-end optimization of multi-headed models[J]. arXiv:1905.09979, 2019.
|
| [24] |
YANG Y, ZHAN D C, FAN Y, et al. Deep learning for fixed model reuse[C]// Proceedings of the 31st Conference on Artificial Intelligence, San Francisco, Feb 4-9, 2017. Menlo Park: AAAI, 2017: 2831-2837.
|
| [25] |
YE H J, ZHAN D C, JIANG Y, et al. Rectify heterogeneous models with semantic mapping[C]// Proceedings of the 35th International Conference on Machine Learning, Stockhol-msmässan, Jul 10-15, 2018. New York: ACM, 2018: 1904-1913.
|
| [26] |
赵鹏, 周志华. 基于决策树模型重用的分布变化流数据学习[J]. 中国科学: 信息科学, 2021, 51(1): 1-12.
|
|
ZHAO P, ZHOU Z H. Learning from distribution-changing data streams via decision tree model reuse[J]. SCIENTIA SINICA Informationis, 2021, 51(1): 1-12.
DOI
URL
|
| [27] |
李新春, 詹德川. 一种保持语义关系的词向量复用方法[J]. 中国科学: 信息科学, 2020, 50(6): 813-823.
|
|
LI X C, ZHAN D C. A semantic relation preserved word embedding reuse method[J]. SCIENTIA SINICA Informationis, 2020, 50(6): 813-823.
DOI
URL
|
| [28] |
HAMER J, MOHRI M, SURESH A T. FedBoost: a comm-unication-efficient algorithm for federated learning[C]// Proceedings of the 37th International Conference on Machine Learning. New York: ACM, 2020: 3973-3983.
|
| [29] |
YOSINSKI J, CLUNE J, BENGIO Y, et al. How transferable are features in deep neural networks?[J]. arXiv:1411.1792, 2014.
|
| [30] |
KINGMA D P, WELLING M. Auto-encoding variational Bayes[J]. arXiv:1312.6114, 2013.
|
| [31] |
LI X C, ZHAN D C, YANG J Q, et al. Deep multiple instance selection[J]. Science China Information Sciences, 2021, 64(3): 130102.
DOI
URL
|

 )
)