
计算机科学与探索 ›› 2022, Vol. 16 ›› Issue (10): 2234-2248.DOI: 10.3778/j.issn.1673-9418.2112080
耿耀港, 梅红岩+( ), 张兴, 李晓会
), 张兴, 李晓会
收稿日期:2021-12-20
修回日期:2022-04-19
出版日期:2022-10-01
发布日期:2022-10-14
通讯作者:
+ E-mail: 715014795@qq.com作者简介:耿耀港(1997—),男,山东济宁人,硕士研究生,主要研究方向为自然语言处理、图像标题生成。基金资助:
GENG Yaogang, MEI Hongyan+(), ZHANG Xing, LI Xiaohui
Received:2021-12-20
Revised:2022-04-19
Online:2022-10-01
Published:2022-10-14
About author:GENG Yaogang, born in 1997, M.S. candidate.His research interests include natural language processing and image captioning.Supported by:摘要:
近年来,图像标题生成作为人工智能领域中的多模态任务,融合了计算机视觉和自然语言处理的相关研究,能够实现从图像到文本的模态转换,在视觉辅助和图像理解等方面有着重要作用,备受研究者们的广泛关注。首先对图像标题生成任务进行了阐述,介绍了三种图像标题生成方法,基于模板的方法、基于检索的方法和基于编码-解码的方法以及各自的方法思路、代表性研究和优缺点。其次从方法的模型构成、图像理解阶段和标题生成阶段的研究进展等方面对基于编码-解码的方法进行了详细阐述。将近年来的研究总结归纳为图像理解方面的研究和标题生成方面的研究,其中图像理解方面的研究包括注意力机制的研究和语义获取方面的研究,标题生成方面的研究分为传统标题、密集标题和个性化标题生成的研究,并总结了模型性能及优缺点,介绍了图像标题生成模型进行性能评估的数据集和评测指标。最后指出图像标题生成领域研究面对的挑战和难点。
中图分类号:
耿耀港, 梅红岩, 张兴, 李晓会. 编码-解码技术的图像标题生成方法研究综述[J]. 计算机科学与探索, 2022, 16(10): 2234-2248.
GENG Yaogang, MEI Hongyan, ZHANG Xing, LI Xiaohui. Review of Image Captioning Methods Based on Encoding-Decoding Technology[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(10): 2234-2248.

图1 基于模板的方法流程
Fig.1 Template-based method flow

图2 基于检索的方法流程
Fig.2 Retrieval-based method flow
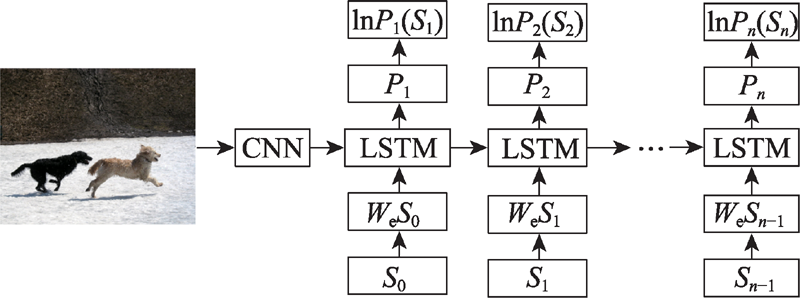
图3 基于编码-解码方法流程
Fig.3 Method flow based on encode-decode
| 模型 | 发表时间 | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METEOR | ROUGE-L | CIDEr |
|---|---|---|---|---|---|---|---|---|
| Google-NIC[ | 2015 | 0.666 | 0.461 | 0.329 | 0.246 | 0.200 | 0.860 | |
| Soft-Attention[ | 2015 | 0.707 | 0.492 | 0.344 | 0.243 | 0.239 | ||
| Hard-Attention[ | 2015 | 0.718 | 0.504 | 0.357 | 0.250 | 0.230 | ||
| att-CNN[ | 2016 | 0.730 | 0.560 | 0.410 | 0.310 | 0.250 | 0.530 | 0.920 |
| Semantic Attention[ | 2016 | 0.709 | 0.537 | 0.402 | 0.304 | 0.243 | ||
| LSTM-A5[ | 2017 | 0.734 | 0.567 | 0.430 | 0.326 | 0.254 | 0.540 | 1.002 |
| High-level Attention[ | 2019 | 0.764 | 0.563 | 0.436 | 0.317 | 0.265 | 0.535 | 1.103 |
| AOA[ | 2019 | 0.810 | 0.658 | 0.514 | 0.394 | 0.291 | 0.589 | 1.269 |
| HIP[ | 2019 | 0.816 | 0.662 | 0.515 | 0.393 | 0.288 | 0.590 | 1.279 |
| Entangle-Transformer[ | 2019 | 0.776 | 0.378 | 0.284 | 0.574 | 1.193 | ||
| CGVRG[ | 2020 | 0.386 | 0.286 | 0.588 | 1.267 | |||
| ASGCaption[ | 2020 | 0.230 | 0.245 | 0.501 | 2.042 | |||
| DLCT[ | 2021 | 0.824 | 0.674 | 0.528 | 0.406 | 0.298 | 0.598 | 1.333 |
表1 图像理解模型在MSCOCO数据集上的性能表现
Table 1 Performance of image understanding models on MSCOCO dataset
| 模型 | 发表时间 | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METEOR | ROUGE-L | CIDEr |
|---|---|---|---|---|---|---|---|---|
| Google-NIC[ | 2015 | 0.666 | 0.461 | 0.329 | 0.246 | 0.200 | 0.860 | |
| Soft-Attention[ | 2015 | 0.707 | 0.492 | 0.344 | 0.243 | 0.239 | ||
| Hard-Attention[ | 2015 | 0.718 | 0.504 | 0.357 | 0.250 | 0.230 | ||
| att-CNN[ | 2016 | 0.730 | 0.560 | 0.410 | 0.310 | 0.250 | 0.530 | 0.920 |
| Semantic Attention[ | 2016 | 0.709 | 0.537 | 0.402 | 0.304 | 0.243 | ||
| LSTM-A5[ | 2017 | 0.734 | 0.567 | 0.430 | 0.326 | 0.254 | 0.540 | 1.002 |
| High-level Attention[ | 2019 | 0.764 | 0.563 | 0.436 | 0.317 | 0.265 | 0.535 | 1.103 |
| AOA[ | 2019 | 0.810 | 0.658 | 0.514 | 0.394 | 0.291 | 0.589 | 1.269 |
| HIP[ | 2019 | 0.816 | 0.662 | 0.515 | 0.393 | 0.288 | 0.590 | 1.279 |
| Entangle-Transformer[ | 2019 | 0.776 | 0.378 | 0.284 | 0.574 | 1.193 | ||
| CGVRG[ | 2020 | 0.386 | 0.286 | 0.588 | 1.267 | |||
| ASGCaption[ | 2020 | 0.230 | 0.245 | 0.501 | 2.042 | |||
| DLCT[ | 2021 | 0.824 | 0.674 | 0.528 | 0.406 | 0.298 | 0.598 | 1.333 |
| 模型 | 发表时间 | 模型机制 | 优势 | 局限性 |
|---|---|---|---|---|
| Google-NIC[ | 2015 | CNN+LSTM | 构造简单,句式灵活 | 模型没有关注重点区域的能力;模型没有获取图像高层语义的能力 |
| Soft-Attention[ | 2015 | CNN+Att+LSTM | 模型能够关注图像重点区域 | 虚词强制对应图像区域,浪费算力 |
| Adaptive Attention[ | 2017 | CNN+Att+LSTM | 模型能够动态选择使用图像特征或语言模型生成单词 | 未充分考虑到高层卷积层特征图对注意力机制的限制 |
| SCA-CNN[ | 2017 | SCA-CNN-LSTM | 模型能够综合使用高层特征图和低层特征图,获取的图像信息更加丰富 | 模型较为注重图像信息,只能获取粗粒度的语义 |
| High-Level Attention[ | 2019 | CNN+LSTM+Att | 借助目标检测技术,结合高级特征和低级特征,获取的图像信息更加精细 | 未充分考虑到区域级特征的语义局限性 |
| att-CNN[ | 2016 | Att-CNN+LSTM | 模型能够提取简单的图像语义信息 | 只能提取到粗粒度语义信息,如图中的对象和对象的属性 |
| HIP[ | 2019 | GCN+LSTM | 树结构加实例级分割,模型语义获取能力更高,泛化能力强 | 树结构表达图像中对象之间的复杂关系的能力有限 |
| Entangle-Transformer[ | 2019 | Transformer | 缓解图像语义和文本语义融合的语义鸿沟问题 | 未能充分解决语义鸿沟问题 |
| CGVRG[ | 2020 | GCN+LSTM | 构造标题指导视觉关系图,融合了一定上下文信息和语义信息 | 未能考虑到区域级特征的语义局限性 |
| ASGCaption[ | 2020 | GCN+LSTM | 复杂的场景图和三种注意力机制配合,生成的标题语义丰富 | 三种注意力机制计算成本高,牺牲了其生成标题的流畅度 |
| DLCT[ | 2021 | Transformer | 融合了两种级别特征的语义信息 | 未考虑到文本语义的融合问题 |
表2 图像理解模型优势及局限性
Table 2 Advantages and limitations of image understanding models
| 模型 | 发表时间 | 模型机制 | 优势 | 局限性 |
|---|---|---|---|---|
| Google-NIC[ | 2015 | CNN+LSTM | 构造简单,句式灵活 | 模型没有关注重点区域的能力;模型没有获取图像高层语义的能力 |
| Soft-Attention[ | 2015 | CNN+Att+LSTM | 模型能够关注图像重点区域 | 虚词强制对应图像区域,浪费算力 |
| Adaptive Attention[ | 2017 | CNN+Att+LSTM | 模型能够动态选择使用图像特征或语言模型生成单词 | 未充分考虑到高层卷积层特征图对注意力机制的限制 |
| SCA-CNN[ | 2017 | SCA-CNN-LSTM | 模型能够综合使用高层特征图和低层特征图,获取的图像信息更加丰富 | 模型较为注重图像信息,只能获取粗粒度的语义 |
| High-Level Attention[ | 2019 | CNN+LSTM+Att | 借助目标检测技术,结合高级特征和低级特征,获取的图像信息更加精细 | 未充分考虑到区域级特征的语义局限性 |
| att-CNN[ | 2016 | Att-CNN+LSTM | 模型能够提取简单的图像语义信息 | 只能提取到粗粒度语义信息,如图中的对象和对象的属性 |
| HIP[ | 2019 | GCN+LSTM | 树结构加实例级分割,模型语义获取能力更高,泛化能力强 | 树结构表达图像中对象之间的复杂关系的能力有限 |
| Entangle-Transformer[ | 2019 | Transformer | 缓解图像语义和文本语义融合的语义鸿沟问题 | 未能充分解决语义鸿沟问题 |
| CGVRG[ | 2020 | GCN+LSTM | 构造标题指导视觉关系图,融合了一定上下文信息和语义信息 | 未能考虑到区域级特征的语义局限性 |
| ASGCaption[ | 2020 | GCN+LSTM | 复杂的场景图和三种注意力机制配合,生成的标题语义丰富 | 三种注意力机制计算成本高,牺牲了其生成标题的流畅度 |
| DLCT[ | 2021 | Transformer | 融合了两种级别特征的语义信息 | 未考虑到文本语义的融合问题 |

图4 密集标题
Fig.4 Dense caption

图5 个性化标题
Fig.5 Stylish caption
| 模型 | 发表时间 | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METEOR | ROUGE-L | CIDEr |
|---|---|---|---|---|---|---|---|---|
| Bidirectional Models[ | 2016 | 0.672 | 0.492 | 0.352 | 0.244 | |||
| SentiCap[ | 2016 | 0.500 | 0.312 | 0.203 | 0.131 | 0.168 | 0.379 | 0.618 |
| Skeleton LSTM[ | 2017 | 0.673 | 0.489 | 0.355 | 0.259 | 0.247 | 0.489 | 0.966 |
| Convolutional Image Captioning[ | 2018 | 0.711 | 0.538 | 0.394 | 0.287 | 0.244 | 0.522 | 0.912 |
| RDN[ | 2019 | 0.775 | 0.618 | 0.479 | 0.368 | 0.272 | 0.568 | 1.153 |
| Recall Mechanism[ | 2020 | 0.385 | 0.287 | 0.584 | 1.291 | |||
| BilingualImageCaptions[ | 2020 | 0.384 | 0.267 | 0.561 | 1.146 | |||
| M2[32] | 2020 | 0.816 | 0.664 | 0.518 | 0.397 | 0.294 | 0.592 | 1.293 |
表3 标题生成模型在MSCOCO数据集上的表现
Table 3 Performance of caption generation models on MSCOCO dataset
| 模型 | 发表时间 | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METEOR | ROUGE-L | CIDEr |
|---|---|---|---|---|---|---|---|---|
| Bidirectional Models[ | 2016 | 0.672 | 0.492 | 0.352 | 0.244 | |||
| SentiCap[ | 2016 | 0.500 | 0.312 | 0.203 | 0.131 | 0.168 | 0.379 | 0.618 |
| Skeleton LSTM[ | 2017 | 0.673 | 0.489 | 0.355 | 0.259 | 0.247 | 0.489 | 0.966 |
| Convolutional Image Captioning[ | 2018 | 0.711 | 0.538 | 0.394 | 0.287 | 0.244 | 0.522 | 0.912 |
| RDN[ | 2019 | 0.775 | 0.618 | 0.479 | 0.368 | 0.272 | 0.568 | 1.153 |
| Recall Mechanism[ | 2020 | 0.385 | 0.287 | 0.584 | 1.291 | |||
| BilingualImageCaptions[ | 2020 | 0.384 | 0.267 | 0.561 | 1.146 | |||
| M2[32] | 2020 | 0.816 | 0.664 | 0.518 | 0.397 | 0.294 | 0.592 | 1.293 |
| 模型 | 发表时间 | 模型机制 | 优势 | 局限性 |
|---|---|---|---|---|
| Bidirectional Models[ | 2016 | CNN+BiLSTM | 解码器能够获取更多的上下文及图像-文本语义信息 | 模型复杂度高,训练成本高 |
| SentiCap[ | 2016 | CNN+LSTM | 标题带有积极或消极的倾向 | 只能粗粒度地区分积极和消极,没有其他风格,且句子流畅度低 |
| StyleNet[ | 2017 | CNN+Factored-LSTM | 能够生成多种风格的标题,如幽默、浪漫等 | 句子流畅度低,需要构造相应风格的语料库进行训练 |
| Convolutional Image Captioning[ | 2018 | CNN+Masked-CNN | 模型复杂度低,训练成本低 | 标题的序列性低 |
| RDN[ | 2019 | CNN+RDN | 模型长序列依赖性和位置感知能力高,具备推理和联想能力 | 标题流畅度低 |
| Recall Mechanism[ | 2020 | CNN+Recall-LSTM | 模型长依赖性高,标题逻辑性好 | 需要先训练召回词 |
| BilingualImageCaptions[ | 2020 | CNN+LSTM+Att | 模型能够生成双语标题 | 不同语言文本融合时会存在噪声,影响模型效果 |
| Compositional Neural Module Networks[ | 2020 | CNN+LSTM+Att | 标题多样,且流畅度高 | 未充分考虑语义鸿沟问题 |
| Different caption[ | 2021 | Transformer | 能够完成描述两图之间细微差别的任务 |
表4 标题生成模型优势及局限性
Table 4 Advantages and limitations of caption generation models
| 模型 | 发表时间 | 模型机制 | 优势 | 局限性 |
|---|---|---|---|---|
| Bidirectional Models[ | 2016 | CNN+BiLSTM | 解码器能够获取更多的上下文及图像-文本语义信息 | 模型复杂度高,训练成本高 |
| SentiCap[ | 2016 | CNN+LSTM | 标题带有积极或消极的倾向 | 只能粗粒度地区分积极和消极,没有其他风格,且句子流畅度低 |
| StyleNet[ | 2017 | CNN+Factored-LSTM | 能够生成多种风格的标题,如幽默、浪漫等 | 句子流畅度低,需要构造相应风格的语料库进行训练 |
| Convolutional Image Captioning[ | 2018 | CNN+Masked-CNN | 模型复杂度低,训练成本低 | 标题的序列性低 |
| RDN[ | 2019 | CNN+RDN | 模型长序列依赖性和位置感知能力高,具备推理和联想能力 | 标题流畅度低 |
| Recall Mechanism[ | 2020 | CNN+Recall-LSTM | 模型长依赖性高,标题逻辑性好 | 需要先训练召回词 |
| BilingualImageCaptions[ | 2020 | CNN+LSTM+Att | 模型能够生成双语标题 | 不同语言文本融合时会存在噪声,影响模型效果 |
| Compositional Neural Module Networks[ | 2020 | CNN+LSTM+Att | 标题多样,且流畅度高 | 未充分考虑语义鸿沟问题 |
| Different caption[ | 2021 | Transformer | 能够完成描述两图之间细微差别的任务 |
| 数据集 | 训练集 | 验证集 | 测试集 | 语言 | 年份 |
|---|---|---|---|---|---|
| MSCOCO[ | 82 783 | 40 504 | 40 775 | 英文 | 2014 |
| Flickr30K[ | 28 000 | 1 000 | 1 000 | 英文 | 2014 |
| Flickr8K[ | 6 000 | 1 000 | 1 000 | 英文 | 2013 |
| Flickr8kCN[ | 6 000 | 1 000 | 1 000 | 中文 | 2016 |
| STAIR[ | 113 287 | 5 000 | 5 000 | 日文 | 2017 |
表5 图像标题生成数据集信息
Table 5 Information of image captions generation datasets
| 数据集 | 训练集 | 验证集 | 测试集 | 语言 | 年份 |
|---|---|---|---|---|---|
| MSCOCO[ | 82 783 | 40 504 | 40 775 | 英文 | 2014 |
| Flickr30K[ | 28 000 | 1 000 | 1 000 | 英文 | 2014 |
| Flickr8K[ | 6 000 | 1 000 | 1 000 | 英文 | 2013 |
| Flickr8kCN[ | 6 000 | 1 000 | 1 000 | 中文 | 2016 |
| STAIR[ | 113 287 | 5 000 | 5 000 | 日文 | 2017 |
| [1] | FARHADI A, HEJRATI S M M, SADEGHI M A, et al. Every picture tells a story:generating sentences from images[C]// LNCS 6314: Proceedings of the 11th European Conference on Computer Vision, Heraklion, Sep 5-11, 2010. Berlin, Heidel-berg: Springer, 2010: 15-29. |
| [2] | KUZNETSOVA P, ORDONEZ V, BERG A C, et al. Collective generation of natural image descriptions[C]// Proceedings of the 50th Annual Meeting of the Association for Computa-tional Linguistics, Jeju Island, Jul 8-14, 2012. Stroudsburg: ACL, 2012: 359-368. |
| [3] | KULKARNI G, PREMRAJ V, ORDONEZ V, et al. Babytalk: understanding and generating simple image descriptions[J]. IEEE Transactions on Pattern Analysis and Machine Intel-ligence, 2013, 35(12): 2891-2903. |
| [4] | ORDONEZ V, KULKARNI G, BERG T. Im2text: describing images using 1 million captioned photographs[C]// Advances in Neural Information Processing Systems 24, Granada, Dec 12-14, 2011: 1143-1151. |
| [5] | CHO K, VAN MERRIËNBOER B, GULCEHRE C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[J]. arXiv:1406.1078, 2014. |
| [6] | VINYALS O, TOSHEV A, BENGIO S, et al. Show and tell: a neural image caption generator[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recog-nition, Boston, Jun 7-12, 2015. Washington: IEEE Computer Society, 2015: 3156-3164. |
| [7] | XU K, BA J, KIROS R, et al. Show, attend and tell: neural image caption generation with visual attention[C]// Procee-dings of the 32nd International Conference on Machine Learning, Lille, Jul 6-11, 2015: 2048-2057. |
| [8] | LU J S, XIONG C M, PARIKH D, et al. Knowing when to look: adaptive attention via a visual sentinel for image cap-tioning[C]// Proceedings of the 2017 IEEE Conference on Com-puter Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 375-383. |
| [9] | HUANG L, WANG W M, CHEN J, et al. Attention on atten-tion for image captioning[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Oct 27-Nov 2, 2019. Piscataway: IEEE, 2019: 4634-4643. |
| [10] | CHEN L, ZHANG H W, XIAO J, et al. SCA-CNN: spatial and channel-wise attention in convolutional networks for image captioning[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 5659-5667. |
| [11] |
DING S, QU S, XI Y, et al. Image caption generation with high-level image features[J]. Pattern Recognition Letters, 2019, 123: 89-95.
DOI |
| [12] | YOU Q Z, JIN H L, WANG Z W, et al. Image captioning with semantic attention[C]// Proceedings of the 2016 IEEE Confer-ence on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 4651-4659. |
| [13] | WU Q, SHEN C H, LIU L Q, et al. What value do explicit high level concepts have in vision to language problems?[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 203-212. |
| [14] | YAO T, PAN Y W, LI Y H, et al. Boosting image captioning with attributes[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Oct 22-29, 2017. Wa-shington: IEEE Computer Society, 2017: 4904-4912. |
| [15] | TANTI M, GATT A, CAMILLERI K P. What is the role of recurrent neural networks (RNNs) in an image caption gene-ration generator?[J]. arXiv:1708.02043, 2017. |
| [16] | KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks[J]. arXiv:1609.02907, 2016. |
| [17] | YAO T, PAN Y W, LI Y H, et al. Exploring visual relationship for image captioning[C]// LNCS 11218: Proceedings of the 15th European Conference on Computer Vision, Munich, Sep 8-14, 2018. Cham: Springer, 2018: 711-727. |
| [18] | YAO T, PAN Y W, LI Y H, et al. Hierarchy parsing for image captioning[C]// Proceedings of the 2019 IEEE/CVF Interna-tional Conference on Computer Vision, Seoul, Oct 27-Nov 2, 2019. Piscataway: IEEE, 2019: 2621-2629. |
| [19] | SHI Z, ZHOU X, QIU X, et al. Improving image captioning with better use of captions[J]. arXiv:2006.11807, 2020. |
| [20] | CHEN S Z, JIN Q, WANG P, et al. Say as you wish: fine-grained control of image caption generation with abstract scene graphs[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 9959-9968. |
| [21] | LUO Y, JI J, SUN X, et al. Dual-level collaborative trans-former for image captioning[J]. arXiv:2101.06462, 2021. |
| [22] | LI G, ZHU L C, LIU P, et al. Entangled transformer for image captioning[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Oct 27-Nov 2, 2019. Piscataway: IEEE, 2019: 8927-8936. |
| [23] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Advances in Neural Information Processing Systems 30, Long Beach, Dec 4-9, 2017. Red Hook: Curran Associates, 2017: 5998-6008. |
| [24] | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]// Proceedings of the 2019 Conference of the North Ameri-can Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, Jun 2-7, 2019. Stroudsburg: ACL, 2019: 4171-4186. |
| [25] | WANG C, YANG H J, BARTZ C, et al. Image captioning with deep bidirectional LSTMs[C]// Proceedings of the 2016 ACM Conference on Multimedia Conference, Amsterdam, Oct 15-19, 2016. New York: ACM, 2016: 988-997. |
| [26] | WANG Y F, LIN Z, SHEN X H, et al. Skeleton key: image captioning by skeleton-attribute decomposition[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 7378-7387. |
| [27] | DAI B, FIDLER S, LIN D H. A neural compositional para-digm for image captioning[C]// Advances in Neural Infor-mation Processing Systems 31, Montréal, Dec 3-8, 2018: 656-666. |
| [28] | TIAN J, OH J. Image caption generationing with compositional neural module networks[J]. arXiv: 2007.05608, 2020. |
| [29] | KE L, PEI W J, LI R Y, et al. Reflective decoding network for image captioning[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Oct 27-Nov 2, 2019. Piscataway: IEEE, 2019: 8887-8896. |
| [30] | WANG L, BAI Z C, ZHANG Y H, et al. Show, recall, and tell: image captioning with recall mechanism[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence, the 32nd Innovative Applications of Artificial Intelligence Conference, the 10th AAAI Symposium on Educational Advances in Ar-tificial Intelligence, New York, Feb 7-12, 2020. Menlo Park: AAAI, 2020: 12176-12183. |
| [31] | ANEJA J, DESHPANDE A, SCHWING A G. Convolutional image captioning[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-22, 2018. Washington: IEEE Computer Society, 2018: 5561-5570. |
| [32] | CORNIA M, STEFANINI M, BARALDI L, et al. Meshed-memory transformer for image captioning[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 10575-10584. |
| [33] | HOSSEINZADEH M, WANG Y. Image change captioning by learning from an auxiliary task[C]// Proceedings of the 2021 IEEE Conference on Computer Vision and Pattern Recogni-tion. Washington: IEEE Computer Society, 2021: 2725-2734. |
| [34] | CHEN D Z, GHOLAMI A, NIEßNER M, et al. Scan2Cap: context-aware dense captioning in RGB-D scans[J]. arXiv:2012.02206, 2020. |
| [35] | JOHNSON J, KARPATHY A, LI F F. DenseCap: fully con-volutional localization networks for dense captioning[C]// Pro-ceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Wa-shington: IEEE Computer Society, 2016: 4565-4574. |
| [36] | YANG L J, TANG K D, YANG J C, et al. Dense captioning with joint inference and visual context[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 1978-1987. |
| [37] | KIM D J, CHOI J, OH T H, et al. Dense relational cap-tioning: triple-stream networks for relationship-based cap-tioning[C]// Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, Jun 16-20, 2019. Piscataway: IEEE, 2019: 6271-6280. |
| [38] | MATHEWS A P, XIE L X, HE X M. SentiCap: generating image descriptions with sentiments[C]// Proceedings of the 30th AAAI Conference on Artificial Intelligence, Phoenix, Feb 12-17, 2016. Menlo Park: AAAI, 2016: 3574-3580. |
| [39] | CHEN T L, ZHANG Z P, YOU Q Z, et al. “Factual” or “Emotional”:stylized image captioning with adaptive lear-ning and attention[C]// LNCS 11214: Proceedings of the 15th European Conference on Computer Vision, Munich, Sep 8-14, 2018. Cham: Springer, 2018: 527-543. |
| [40] | GAN C, GAN Z, HE X D, et al. StyleNet: generating attrac-tive visual captions with styles[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recogni-tion, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 955-964. |
| [41] |
张凯, 李军辉, 周国栋. 双语图像标题联合生成研究[J]. 计算机科学, 2020, 47(12): 183-189.
DOI |
|
ZHANG K, LI J H, ZHOU G D. Study on joint generation of bilingual image captions[J]. Computer Science, 2020, 47(12): 183-189.
DOI |
|
| [42] | CHEN C K, PAN Z F, LIU M Y, et al. Unsupervised stylish image description generation via domain layer norm[C]// Proceedings of the 33rd AAAI Conference on Artificial In-telligence, the 31st Innovative Applications of Artificial Intelligence Conference, the 9th AAAI Symposium on Edu-cational Advances in Artificial Intelligence, Honolulu, Jan 27-Feb 1, 2019. Menlo Park: AAAI, 2019: 8151-8158. |
| [43] | ZHAO W T, WU X X, ZHANG X X. MemCap: memorizing style knowledge for image captioning[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence, the 32nd Innovative Applications of Artificial Intelligence Conference, the 10th AAAI Symposium on Educational Advances in Artificial Intelligence, New York, Feb 7-12, 2020. Menlo Park: AAAI, 2020: 12984-12992. |
| [44] | LIN T Y, MAIRE M, BELONGIE S J, et al. Microsoft COCO: common objects in context[C]// LNCS 8693: Proceedings of the 13th European Conference on Computer Vision, Zurich, Sep 6-12, 2014. Cham: Springer, 2014: 740-755. |
| [45] | YOUNG P, LAI A, HODOSH M, et al. From image descrip-tions to visual denotations: new similarity metrics for semantic inference over event descriptions[J]. Transactions of the Asso-ciation for Computational Linguistics, 2014, 2: 67-78. |
| [46] |
HODOSH M, YOUNG P, HOCKENMAIER J. Framing image description as a ranking task: data, models and evaluation metrics[J]. Journal of Artificial Intelligence Research, 2013, 47: 853-899.
DOI URL |
| [47] | LI X R, LAN W Y, DONG J F, et al. Adding Chinese captions to images[C]// Proceedings of the 2016 ACM on International Conference on Multimedia Retrieval, New York, Jun 6-9, 2016. New York: ACM, 2016: 271-275. |
| [48] | YOSHIKAWA Y, SHIGETO Y, TAKEUCHI A. Stair captions: constructing a large-scale Japanese image caption dataset[J]. arXiv:1705.00823, 2017. |
| [49] | PAPINENI K, ROUKOS S, WARD T, et al. BLEU: a method for automatic evaluation of machine translation[C]// Proceedings of the 40th Annual Meeting of the Association for Compu-tational Linguistics, Philadelphia, Jul 6-12, 2002. Stroudsburg: ACL, 2002: 311-318. |
| [50] | BANERJEE S, LAVIE A. METEOR: an automatic metric for MT evaluation with improved correlation with human judg-ments[C]// Proceedings of the 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, Jun 29, 2005. Stroudsburg: ACL, 2005: 65-72. |
| [51] | LIN C Y. ROUGE: a package for automatic evaluation of summaries[C]// Proceedings of 2004 Workshop on Text Sum-marization Branches Out, Barcelona, Jul, 2004. Stroudsburg: ACL, 2004: 74-81. |
| [52] | VEDANTAM R, ZITNICK C L, PARIKH D. CIDEr: consensus-based image description evaluation[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Re-cognition, Boston, Jun 7-12, 2015. Washington: IEEE Com-puter Society, 2015: 4566-4575. |
| [53] | ANDERSON P, FERNANDO B, JOHNSON M, et al. SPICE: semantic propositional image caption evaluation[C]// LNCS 9909: Proceedings of the 14th European Conferenceon Com-puter Vision, Amsterdam, Oct 11-14, 2016. Cham: Springer, 2016: 382-398. |
| [1] | 吕晓琦, 纪科, 陈贞翔, 孙润元, 马坤, 邬俊, 李浥东. 结合注意力与循环神经网络的专家推荐算法[J]. 计算机科学与探索, 2022, 16(9): 2068-2077. |
| [2] | 李珍琦, 王晶, 贾子钰, 林友芳. 融合注意力的多维特征图卷积运动想象分类[J]. 计算机科学与探索, 2022, 16(9): 2050-2060. |
| [3] | 许嘉, 莫晓琨, 于戈, 吕品, 韦婷婷. SQL-Detector:基于编码特征的SQL习题抄袭检测技术[J]. 计算机科学与探索, 2022, 16(9): 2030-2040. |
| [4] | 洪惠群, 沈贵萍, 黄风华. 表情识别技术综述[J]. 计算机科学与探索, 2022, 16(8): 1764-1778. |
| [5] | 杨知桥, 张莹, 王新杰, 张东波, 王玉. 改进U型网络在视网膜病变检测中的应用研究[J]. 计算机科学与探索, 2022, 16(8): 1877-1884. |
| [6] | 杨政, 邓赵红, 罗晓清, 顾鑫, 王士同. 利用ELM-AE和迁移表征学习构建的目标跟踪系统[J]. 计算机科学与探索, 2022, 16(7): 1633-1648. |
| [7] | 夏鸿斌, 肖奕飞, 刘渊. 融合自注意力机制的长文本生成对抗网络模型[J]. 计算机科学与探索, 2022, 16(7): 1603-1610. |
| [8] | 赵小明, 杨轶娇, 张石清. 面向深度学习的多模态情感识别研究进展[J]. 计算机科学与探索, 2022, 16(7): 1479-1503. |
| [9] | 刘颖, 王哲, 房杰, 朱婷鸽, 李琳娜, 刘继明. 基于图文融合的多模态舆情分析[J]. 计算机科学与探索, 2022, 16(6): 1260-1278. |
| [10] | 李运寰, 闻继伟, 彭力. 高帧率的轻量级孪生网络目标跟踪[J]. 计算机科学与探索, 2022, 16(6): 1405-1416. |
| [11] | 张雁操, 赵宇海, 史岚. 融合图注意力的多特征链接预测算法[J]. 计算机科学与探索, 2022, 16(5): 1096-1106. |
| [12] | 林佳伟, 王士同. 用于无监督域适应的深度对抗重构分类网络[J]. 计算机科学与探索, 2022, 16(5): 1107-1116. |
| [13] | 朱壮壮, 周治平. 高斯混合生成模型检测健康数据异常[J]. 计算机科学与探索, 2022, 16(5): 1128-1135. |
| [14] | 赵鹏飞, 谢林柏, 彭力. 融合注意力机制的深层次小目标检测算法[J]. 计算机科学与探索, 2022, 16(4): 927-937. |
| [15] | 包广斌, 李港乐, 王国雄. 面向多模态情感分析的双模态交互注意力[J]. 计算机科学与探索, 2022, 16(4): 909-916. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||