
计算机科学与探索 ›› 2022, Vol. 16 ›› Issue (12): 2809-2819.DOI: 10.3778/j.issn.1673-9418.2104019
宋鹏1,2, 葛洪伟1,2,+( )
)
收稿日期:2021-04-08
修回日期:2021-05-26
出版日期:2022-12-01
发布日期:2021-05-18
通讯作者:
+E-mail: ghw8601@163.com作者简介:宋鹏(1996—),男,辽宁丹东人,硕士研究生,CCF学生会员,主要研究方向为模式识别、机器学习。基金资助:
SONG Peng1,2, GE Hongwei1,2,+()
Received:2021-04-08
Revised:2021-05-26
Online:2022-12-01
Published:2021-05-18
About author:SONG Peng, born in 1996, M.S. candidate, stu-dent member of CCF. His research interests include pattern recognition and machine learning.Supported by:摘要:
基于动态图的密度峰值聚类标签传播算法(DPC-DLP)是密度峰值聚类算法(DPC)的一种改进算法,该算法涉及的相关参数过于复杂,并且算法在每次迭代时都会使用标签数据,会出现标签错误扩大化现象,存在迭代次数过多导致聚类效果恶化等问题。针对上述问题,提出了一种最近邻的密度峰值聚类标签传播算法(DPC-NLP)。该算法主要有三个步骤:首先利用局部密度和最小距离对样本点进行打分,根据分数确定聚类中心,然后使用聚类中心的标签在其最近邻内形成簇骨干,最后使用最近邻的标签传播方法将簇骨干的标签传播到剩余样本上,并形成最终的聚类结果。最近邻标签传播算法充分考虑数据间的结构关联性情况,并在传播的过程中不断更新数据的状态,利用更充分的信息提高分配正确率。在人工和真实数据集上对算法进行验证,并与目前主流的聚类算法进行比较,实验结果表明,DPC-NLP在性能和鲁棒性方面表现优越,并可以处理流形和非线性等复杂数据。
中图分类号:
宋鹏, 葛洪伟. 最近邻的密度峰值聚类标签传播算法[J]. 计算机科学与探索, 2022, 16(12): 2809-2819.
SONG Peng, GE Hongwei. Nearest Neighbor Label Propagation for Density Peak Clustering[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(12): 2809-2819.

图1 测试数据集
Fig.1 Testing dataset

图2 错误点位置
Fig.2 Location of error point

图3 经过DPC-DLP算法后得到的结果
Fig.3 Result of DPC-DLP

图4 DPC-DLP获得的最优结果
Fig.4 Optimal result of DPC-DLP

图5 DPC-DLP增加迭代次数得到的结果
Fig.5 Result of DPC-DLP by increasing the number of iterations

图6 聚类中心选取示意图
Fig.6 Schematic diagram of cluster center selection

图7 DPC-NLP算法鲁棒性实验示意图
Fig.7 Schematic diagram of DPC-NLP algorithm robustness experiment
| 数据集名称 | 样本数量 | 簇个数 |
|---|---|---|
| Aggregation | 788 | 7 |
| CMC | 1 002 | 3 |
| Flame | 515 | 2 |
| Spiral | 312 | 3 |
表1 人工数据集
Table 1 Synthetic datasets
| 数据集名称 | 样本数量 | 簇个数 |
|---|---|---|
| Aggregation | 788 | 7 |
| CMC | 1 002 | 3 |
| Flame | 515 | 2 |
| Spiral | 312 | 3 |
| 数据集 | 样本数 | 属性 | 类数 | 应用 |
|---|---|---|---|---|
| Iris | 150 | 4 | 3 | 植物生物学 |
| Parkinson | 195 | 22 | 2 | 医学 |
| Sonar | 208 | 60 | 2 | 物理学 |
| Seeds | 210 | 7 | 3 | 农业物理学 |
| Thyroid | 215 | 5 | 3 | 医学 |
| Ecoli | 336 | 7 | 8 | 分子生物学 |
| WDBC | 569 | 30 | 2 | 医学 |
| Diabetes | 768 | 8 | 2 | 医学 |
| Vehicle | 846 | 18 | 4 | 车辆识别 |
表2 低维数据基本情况
Table 2 Low-dimensional datasets
| 数据集 | 样本数 | 属性 | 类数 | 应用 |
|---|---|---|---|---|
| Iris | 150 | 4 | 3 | 植物生物学 |
| Parkinson | 195 | 22 | 2 | 医学 |
| Sonar | 208 | 60 | 2 | 物理学 |
| Seeds | 210 | 7 | 3 | 农业物理学 |
| Thyroid | 215 | 5 | 3 | 医学 |
| Ecoli | 336 | 7 | 8 | 分子生物学 |
| WDBC | 569 | 30 | 2 | 医学 |
| Diabetes | 768 | 8 | 2 | 医学 |
| Vehicle | 846 | 18 | 4 | 车辆识别 |
| 数据集 | 样本数 | 属性 | 类数 | 应用 |
|---|---|---|---|---|
| Drivface | 606 | 6 400 | 3 | 头部姿态估计 |
| Coil20 | 1 440 | 1 024 | 20 | 物体识别 |
| Yeast | 1 483 | 8 | 10 | 细胞生物学 |
| Mfeat | 2 000 | 649 | 10 | 手写数字识别 |
| Segment | 2 310 | 19 | 7 | 图像处理 |
| Abalone | 4 177 | 8 | 28 | 种群生物学 |
| Waveform | 5 000 | 21 | 3 | 物理学 |
| USPS | 9 298 | 256 | 10 | 手写数字识别 |
表3 高维数据基本情况
Table 3 High-dimensional datasets
| 数据集 | 样本数 | 属性 | 类数 | 应用 |
|---|---|---|---|---|
| Drivface | 606 | 6 400 | 3 | 头部姿态估计 |
| Coil20 | 1 440 | 1 024 | 20 | 物体识别 |
| Yeast | 1 483 | 8 | 10 | 细胞生物学 |
| Mfeat | 2 000 | 649 | 10 | 手写数字识别 |
| Segment | 2 310 | 19 | 7 | 图像处理 |
| Abalone | 4 177 | 8 | 28 | 种群生物学 |
| Waveform | 5 000 | 21 | 3 | 物理学 |
| USPS | 9 298 | 256 | 10 | 手写数字识别 |

图8 DPC-DLP和DPC-NLP在Aggregation数据集上的结果
Fig.8 Result of DPC-DLP and DPC-NLP on Aggregation dataset

图9 DPC-DLP和DPC-NLP在Flame数据集上的结果
Fig.9 Result of DPC-DLP and DPC-NLP on Flame dataset

图10 DPC-DLP和DPC-NLP在CMC数据集上的结果
Fig.10 Result of DPC-DLP and DPC-NLP on CMC dataset
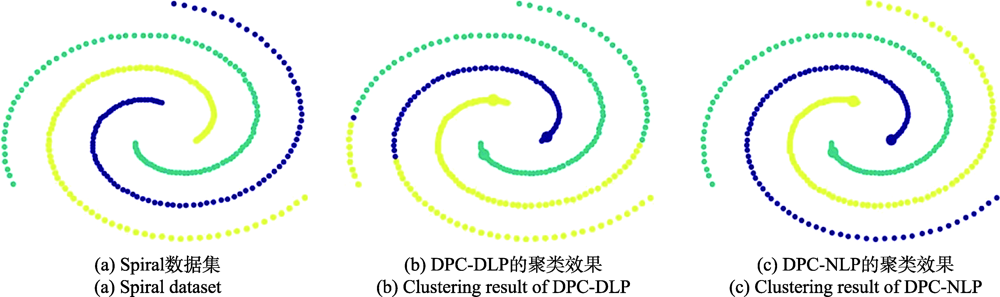
图11 DPC-DLP和DPC-NLP在Spiral数据集上的结果
Fig.11 Result of DPC-DLP and DPC-NLP on Spiral dataset
| Dataset | FCM | DPC-KNN | IDPC | DPC-DLP | Ours |
|---|---|---|---|---|---|
| Iris | 0.819 6 | 0.866 8 | 0.900 4 | 0.947 8 | 0.947 9 |
| Parkinson | 0.770 7 | 0.649 5 | 0.732 2 | 0.800 5 | 0.824 5 |
| Sonar | 0.502 7 | 0.527 9 | 0.544 0 | 0.574 0 | 0.659 7 |
| Seeds | 0.810 6 | 0.817 7 | 0.839 6 | 0.849 5 | 0.900 4 |
| Thyroid | 0.806 1 | 0.636 9 | 0.636 9 | 0.774 3 | 0.923 1 |
| Ecoli | 0.621 1 | 0.785 8 | 0.785 8 | 0.800 8 | 0.822 0 |
| WDBC | 0.786 0 | 0.665 3 | 0.728 0 | 0.844 1 | 0.925 2 |
| Diabetes | 0.612 5 | 0.601 6 | 0.601 6 | 0.633 3 | 0.705 6 |
| Vehicle | 0.307 5 | 0.347 0 | 0.354 8 | 0.396 5 | 0.431 9 |
| Average | 0.670 8 | 0.655 4 | 0.680 4 | 0.735 3 | 0.793 4 |
表4 低维数据集上的F-measure指标结果
Table 4 F-measure index results on low-dimensional datasets
| Dataset | FCM | DPC-KNN | IDPC | DPC-DLP | Ours |
|---|---|---|---|---|---|
| Iris | 0.819 6 | 0.866 8 | 0.900 4 | 0.947 8 | 0.947 9 |
| Parkinson | 0.770 7 | 0.649 5 | 0.732 2 | 0.800 5 | 0.824 5 |
| Sonar | 0.502 7 | 0.527 9 | 0.544 0 | 0.574 0 | 0.659 7 |
| Seeds | 0.810 6 | 0.817 7 | 0.839 6 | 0.849 5 | 0.900 4 |
| Thyroid | 0.806 1 | 0.636 9 | 0.636 9 | 0.774 3 | 0.923 1 |
| Ecoli | 0.621 1 | 0.785 8 | 0.785 8 | 0.800 8 | 0.822 0 |
| WDBC | 0.786 0 | 0.665 3 | 0.728 0 | 0.844 1 | 0.925 2 |
| Diabetes | 0.612 5 | 0.601 6 | 0.601 6 | 0.633 3 | 0.705 6 |
| Vehicle | 0.307 5 | 0.347 0 | 0.354 8 | 0.396 5 | 0.431 9 |
| Average | 0.670 8 | 0.655 4 | 0.680 4 | 0.735 3 | 0.793 4 |
| Dataset | FCM | DPC-KNN | IDPC | DPC-DLP | Ours |
|---|---|---|---|---|---|
| Iris | 0.879 7 | 0.912 4 | 0.934 1 | 0.965 6 | 0.965 6 |
| Parkinson | 0.626 9 | 0.592 9 | 0.648 7 | 0.703 9 | 0.745 5 |
| Sonar | 0.503 2 | 0.522 2 | 0.534 0 | 0.564 7 | 0.557 8 |
| Seeds | 0.874 3 | 0.879 5 | 0.893 9 | 0.900 4 | 0.934 2 |
| Thyroid | 0.790 7 | 0.606 4 | 0.606 4 | 0.701 1 | 0.914 6 |
| Ecoli | 0.819 9 | 0.868 1 | 0.868 1 | 0.877 0 | 0.895 3 |
| WDBC | 0.747 8 | 0.650 7 | 0.652 6 | 0.827 9 | 0.919 1 |
| Diabetes | 0.549 8 | 0.583 0 | 0.583 0 | 0.596 3 | 0.595 2 |
| Vehicle | 0.653 2 | 0.657 9 | 0.657 3 | 0.680 7 | 0.686 4 |
| Average | 0.716 2 | 0.697 0 | 0.708 7 | 0.757 5 | 0.801 5 |
表5 低维数据集上的RI指标结果
Table 5 RI index results on low-dimensional datasets
| Dataset | FCM | DPC-KNN | IDPC | DPC-DLP | Ours |
|---|---|---|---|---|---|
| Iris | 0.879 7 | 0.912 4 | 0.934 1 | 0.965 6 | 0.965 6 |
| Parkinson | 0.626 9 | 0.592 9 | 0.648 7 | 0.703 9 | 0.745 5 |
| Sonar | 0.503 2 | 0.522 2 | 0.534 0 | 0.564 7 | 0.557 8 |
| Seeds | 0.874 3 | 0.879 5 | 0.893 9 | 0.900 4 | 0.934 2 |
| Thyroid | 0.790 7 | 0.606 4 | 0.606 4 | 0.701 1 | 0.914 6 |
| Ecoli | 0.819 9 | 0.868 1 | 0.868 1 | 0.877 0 | 0.895 3 |
| WDBC | 0.747 8 | 0.650 7 | 0.652 6 | 0.827 9 | 0.919 1 |
| Diabetes | 0.549 8 | 0.583 0 | 0.583 0 | 0.596 3 | 0.595 2 |
| Vehicle | 0.653 2 | 0.657 9 | 0.657 3 | 0.680 7 | 0.686 4 |
| Average | 0.716 2 | 0.697 0 | 0.708 7 | 0.757 5 | 0.801 5 |
| Dataset | FCM | DPC-KNN | IDPC | DPC-DLP | Ours |
|---|---|---|---|---|---|
| Iris | 0.729 4 | 0.801 5 | 0.851 2 | 0.922 2 | 0.922 2 |
| Parkinson | 0 | 0.171 3 | 0.224 8 | 0.276 6 | 0.413 5 |
| Sonar | 0.006 4 | 0.044 3 | 0.068 0 | 0.129 3 | 0.115 6 |
| Seeds | 0.716 6 | 0.727 7 | 0.760 4 | 0.775 1 | 0.851 2 |
| Thyroid | 0.579 0 | 0.207 7 | 0.207 7 | 0.207 7 | 0.827 6 |
| Ecoli | 0.505 9 | 0.692 5 | 0.692 5 | 0.714 4 | 0.748 1 |
| WDBC | 0.486 2 | 0.300 3 | 0.283 0 | 0.652 6 | 0.837 1 |
| Diabetes | 0.080 4 | 0.165 9 | 0.165 9 | 0.184 4 | 0.167 9 |
| Vehicle | 0.076 2 | 0.116 0 | 0.122 6 | 0.180 4 | 0.201 7 |
| Average | 0.353 3 | 0.358 6 | 0.375 1 | 0.449 2 | 0.801 5 |
表6 低维数据集上的ARI指标结果
Table 6 ARI index results on low-dimensional datasets
| Dataset | FCM | DPC-KNN | IDPC | DPC-DLP | Ours |
|---|---|---|---|---|---|
| Iris | 0.729 4 | 0.801 5 | 0.851 2 | 0.922 2 | 0.922 2 |
| Parkinson | 0 | 0.171 3 | 0.224 8 | 0.276 6 | 0.413 5 |
| Sonar | 0.006 4 | 0.044 3 | 0.068 0 | 0.129 3 | 0.115 6 |
| Seeds | 0.716 6 | 0.727 7 | 0.760 4 | 0.775 1 | 0.851 2 |
| Thyroid | 0.579 0 | 0.207 7 | 0.207 7 | 0.207 7 | 0.827 6 |
| Ecoli | 0.505 9 | 0.692 5 | 0.692 5 | 0.714 4 | 0.748 1 |
| WDBC | 0.486 2 | 0.300 3 | 0.283 0 | 0.652 6 | 0.837 1 |
| Diabetes | 0.080 4 | 0.165 9 | 0.165 9 | 0.184 4 | 0.167 9 |
| Vehicle | 0.076 2 | 0.116 0 | 0.122 6 | 0.180 4 | 0.201 7 |
| Average | 0.353 3 | 0.358 6 | 0.375 1 | 0.449 2 | 0.801 5 |
| Dataset | FCM | DPC-KNN | IDPC | DPC-DLP | Ours |
|---|---|---|---|---|---|
| Drivface | 0.428 3 | 0.561 5 | 0.693 9 | 0.816 4 | 0.814 1 |
| Coil20 | 0.646 5 | 0.854 7 | 0.847 5 | 0.850 7 | 0.927 8 |
| Yeast | 0.716 2 | 0.648 2 | 0.722 0 | 0.725 7 | 0.733 6 |
| Mfeat | 0.887 7 | 0.837 7 | 0.750 7 | 0.786 7 | 0.889 0 |
| Segment | 0.879 2 | 0.837 4 | 0.885 9 | 0.884 9 | 0.890 1 |
| Abalone | 0.868 4 | 0.826 7 | 0.848 4 | 0.830 2 | 0.848 1 |
| Waveform | 0.660 0 | 0.707 2 | 0.775 4 | 0.779 4 | 0.869 4 |
| USPS | 0.558 5 | 0.873 7 | 0.843 5 | 0.835 0 | 0.923 3 |
| Average | 0.627 2 | 0.589 9 | 0.707 5 | 0.723 2 | 0.766 2 |
表7 在高维数据集上的RI指标结果
Table 7 RI index results on high-dimensional datasets
| Dataset | FCM | DPC-KNN | IDPC | DPC-DLP | Ours |
|---|---|---|---|---|---|
| Drivface | 0.428 3 | 0.561 5 | 0.693 9 | 0.816 4 | 0.814 1 |
| Coil20 | 0.646 5 | 0.854 7 | 0.847 5 | 0.850 7 | 0.927 8 |
| Yeast | 0.716 2 | 0.648 2 | 0.722 0 | 0.725 7 | 0.733 6 |
| Mfeat | 0.887 7 | 0.837 7 | 0.750 7 | 0.786 7 | 0.889 0 |
| Segment | 0.879 2 | 0.837 4 | 0.885 9 | 0.884 9 | 0.890 1 |
| Abalone | 0.868 4 | 0.826 7 | 0.848 4 | 0.830 2 | 0.848 1 |
| Waveform | 0.660 0 | 0.707 2 | 0.775 4 | 0.779 4 | 0.869 4 |
| USPS | 0.558 5 | 0.873 7 | 0.843 5 | 0.835 0 | 0.923 3 |
| Average | 0.627 2 | 0.589 9 | 0.707 5 | 0.723 2 | 0.766 2 |
| Dataset | FCM | DPC-KNN | IDPC | DPC-DLP | Ours |
|---|---|---|---|---|---|
| Drivface | 0.014 3 | 0.123 3 | 0.193 9 | 0.296 2 | 0.304 2 |
| Coil20 | 0.090 8 | 0.192 1 | 0.172 1 | 0.230 3 | 0.467 0 |
| Yeast | 0.095 0 | 0.107 2 | 0.138 7 | 0.187 5 | 0.171 4 |
| Mfeat | 0.418 1 | 0.286 0 | 0.251 7 | 0.350 7 | 0.538 7 |
| Segment | 0.506 3 | 0.489 6 | 0.603 7 | 0.585 7 | 0.601 4 |
| Abalone | 0.035 2 | 0.065 1 | 0.069 1 | 0.073 3 | 0.068 2 |
| Waveform | 0.236 4 | 0.354 2 | 0.508 6 | 0.516 4 | 0.514 2 |
| USPS | 0.118 3 | 0.425 3 | 0.243 4 | 0.428 7 | 0.663 0 |
| Average | 0.189 3 | 0.255 4 | 0.272 7 | 0.333 6 | 0.365 0 |
表8 在高维数据集上的ARI指标结果
Table 8 ARI index results on high-dimensional datasets
| Dataset | FCM | DPC-KNN | IDPC | DPC-DLP | Ours |
|---|---|---|---|---|---|
| Drivface | 0.014 3 | 0.123 3 | 0.193 9 | 0.296 2 | 0.304 2 |
| Coil20 | 0.090 8 | 0.192 1 | 0.172 1 | 0.230 3 | 0.467 0 |
| Yeast | 0.095 0 | 0.107 2 | 0.138 7 | 0.187 5 | 0.171 4 |
| Mfeat | 0.418 1 | 0.286 0 | 0.251 7 | 0.350 7 | 0.538 7 |
| Segment | 0.506 3 | 0.489 6 | 0.603 7 | 0.585 7 | 0.601 4 |
| Abalone | 0.035 2 | 0.065 1 | 0.069 1 | 0.073 3 | 0.068 2 |
| Waveform | 0.236 4 | 0.354 2 | 0.508 6 | 0.516 4 | 0.514 2 |
| USPS | 0.118 3 | 0.425 3 | 0.243 4 | 0.428 7 | 0.663 0 |
| Average | 0.189 3 | 0.255 4 | 0.272 7 | 0.333 6 | 0.365 0 |
| Dataset | FCM | DPC-KNN | IDPC | DPC-DLP | Ours |
|---|---|---|---|---|---|
| Drivface | 0.058 4 | 0.116 9 | 0.165 3 | 0.227 8 | 0.231 8 |
| Coil20 | 0.388 3 | 0.479 5 | 0.437 9 | 0.604 4 | 0.797 5 |
| Yeast | 0.173 9 | 0.194 0 | 0.246 8 | 0.311 2 | 0.275 0 |
| Mfeat | 0.558 5 | 0.499 6 | 0.471 7 | 0.604 9 | 0.732 0 |
| Segment | 0.610 2 | 0.682 0 | 0.715 7 | 0.713 3 | 0.744 5 |
| Abalone | 0.160 5 | 0.178 0 | 0.177 8 | 0.213 8 | 0.223 4 |
| Waveform | 0.320 9 | 0.376 8 | 0.500 7 | 0.504 1 | 0.664 1 |
| USPS | 0.230 5 | 0.506 6 | 0.354 2 | 0.642 4 | 0.752 4 |
| Average | 0.312 7 | 0.379 2 | 0.383 8 | 0.477 7 | 0.491 2 |
表9 在高维数据集上的NMI指标结果
Table 9 NMI index results on high-dimensional datasets
| Dataset | FCM | DPC-KNN | IDPC | DPC-DLP | Ours |
|---|---|---|---|---|---|
| Drivface | 0.058 4 | 0.116 9 | 0.165 3 | 0.227 8 | 0.231 8 |
| Coil20 | 0.388 3 | 0.479 5 | 0.437 9 | 0.604 4 | 0.797 5 |
| Yeast | 0.173 9 | 0.194 0 | 0.246 8 | 0.311 2 | 0.275 0 |
| Mfeat | 0.558 5 | 0.499 6 | 0.471 7 | 0.604 9 | 0.732 0 |
| Segment | 0.610 2 | 0.682 0 | 0.715 7 | 0.713 3 | 0.744 5 |
| Abalone | 0.160 5 | 0.178 0 | 0.177 8 | 0.213 8 | 0.223 4 |
| Waveform | 0.320 9 | 0.376 8 | 0.500 7 | 0.504 1 | 0.664 1 |
| USPS | 0.230 5 | 0.506 6 | 0.354 2 | 0.642 4 | 0.752 4 |
| Average | 0.312 7 | 0.379 2 | 0.383 8 | 0.477 7 | 0.491 2 |
| [1] |
JORDAN M I, MITCHELL T M. Machine learning: trends, perspectives, and prospects[J]. Science, 2015, 349: 255-260.
DOI PMID |
| [2] |
JAIN A K, DUIN R P W, MAO J C. Statistical pattern reco-gnition: a review[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2000, 22: 4-37.
DOI URL |
| [3] |
WU Z Y, LEATHY R. An optimal graph theoretic approach to data clustering: theory and its application to image seg-mentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1993, 15: 1101-1113.
DOI URL |
| [4] | CHEN X, SU Z C. Identification of cell types from single-cell transcriptomes using a novel clustering method[J]. Bio-informatics, 2015, 31: 1974-1980. |
| [5] |
DE ANDRADES R K, DORN M, FARENZENA D S, et al. A cluster-DEE-based strategy to empower protein design[J]. Expert Systems with Applications, 2013, 40: 5210-5218.
DOI URL |
| [6] |
CASTELLANOS-GARZON J A, GARCIA C A, NOVAIS P, et al. A visual analytics framework for cluster analysis of DNA microarray data[J]. Expert Systems with Applications, 2013, 40: 758-774.
DOI URL |
| [7] |
MCGARRY K. Discovery of functional protein groups by clu-stering community links and integration of ontological know-ledge[J]. Expert Systems with Applications, 2013, 40: 5101-5112.
DOI URL |
| [8] |
FAZENDEIRO P, DE OLIVEIRA J V. Observer-biased fu-zzy clustering[J]. IEEE Transactions on Fuzzy Systems, 2015, 23: 85-97.
DOI URL |
| [9] | JIN H, LEUNG K S, WONG M L, et al. Scalable model-based cluster analysis using clustering features[J]. Pattern Re-cognition, 2005, 38: 637-649. |
| [10] |
GOVAERT G, NADIF M. An EM algorithm for the block mixture model[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27: 643-647.
DOI PMID |
| [11] |
GURRUTXAGA I, ALBISUA I, ARBELAITZ O, et al. SEP/COP: an efficient method to find the best partition in hie-rarchical clustering based on a new cluster validity index[J]. Pattern Recognition, 2010, 43: 3364-3373.
DOI URL |
| [12] | LOTFI A, MORADI P, BEIGY H. Density peaks clustering based on density backbone and fuzzy neighborhood[J]. Pat-tern Recognition, 2020, 107: 107449. |
| [13] |
刘娟, 万静. 自然反向最近邻优化的密度峰值聚类算法[J]. 计算机科学与探索, 2021, 15(10): 1888-1899.
DOI URL |
| LIU J, WAN J. Optimized density peak clustering algori-thm by natural reverse nearest neighbor[J]. Journal of Fron-tiers of Computer Science and Technology, 2021, 15(10): 1888-1899. | |
| [14] |
王芙银, 张德生, 张晓. 结合鲸鱼优化算法的自适应密度峰值聚类算法[J]. 计算机工程与应用, 2021, 57(3): 94-102.
DOI |
| WANG F Y, ZHANG D S, ZHANG X. Adaptive density peaks clustering algorithm combining with whale optimiza-tion algorithm[J]. Computer Engineering and Applications, 2021, 57(3): 94-102. | |
| [15] |
贾露, 张德生, 吕端端. 物理学优化的密度峰值聚类算法[J]. 计算机工程与应用, 2020, 56(13): 47-53.
DOI |
|
JIA L, ZHANG D S, LV D D. Optimized density peak clus-tering algorithm in physics[J]. Computer Engineering and Applications, 2020, 56(13): 47-53.
DOI |
|
| [16] | ESTER M, KRIEGEL H P, SANDER J, et al. A density-based algorithm for discovering clusters in large spatial data-bases with noise[C]// Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining, Port-land, 1996. Menlo Park: AAAI, 1996: 226-231. |
| [17] | ANANT R, SUNITA J, AS J, et al. A density based algori-thm for discovering density varied clusters in large spatial databases[J]. International Journal of Computer Applications, 2010, 3: 1-4. |
| [18] | LIU P, ZHOU D, WU N. VDBSCAN: varied density based spatial clustering of applications with noise[C]// Proceedings of the 2007 International Conference on Service Systems and Service Management, Chengdu, Jun 9-11, 2007. Pisca-taway: IEEE, 2007: 1-4. |
| [19] |
RODRIGUEZ A, LAIO A. Clustering by fast search and find of density peaks[J]. Science, 2014, 344: 1492-1496.
DOI URL |
| [20] |
DU M, DING S, JIA H. Study on density peaks clustering based on k-nearest neighbors and principal component anal-ysis[J]. Knowledge-Based Systems, 2016, 99: 135-145.
DOI URL |
| [21] |
DU M, DING S, XU X, et al. Density peaks clustering using geodesic distances[J]. International Journal of Machine Learning and Cybernetics, 2018, 9: 1335-1349.
DOI URL |
| [22] | SEVEDI S A, LOTFI A, MORADI P, et al. Dynamic graph-based label propagation for density peaks clustering[J]. Ex-pert Systems with Applications, 2019, 115: 314-328. |
| [23] | JEBARA T, WANG J, CHANG S F. Graph construction and b-matching for semi-supervised learning[C]// Proceedings of the 26th Annual International Conference on Machine Lear-ning, Montreal, Jun 14-18, 2009. New York: ACM, 2009: 441-448. |
| [24] |
BEZDEK J C, EHRLICH R, FULL W. FCM: the fuzzy c-means clustering algorithm[J]. Computers & Geosciences, 1984, 10: 191-203.
DOI URL |
| [25] | LOTFI A, SEYEDI S A, MORADI P. An improved density peaks method for data clustering[C]// Proceedings of the 6th International Conference on Computer and Knowledge Engi-neering, Mashhad, Oct 20, 2016. Piscataway: IEEE, 2016: 263-268. |
| [1] | 马涪元, 王英, 李丽娜, 汪洪吉. 融合结构和特征的图层次化池化模型[J]. 计算机科学与探索, 2023, 17(1): 179-186. |
| [2] | 谢子鹏, 包崇明, 周丽华, 王崇云, 孔兵. 类不平衡数据的EM聚类过采样算法[J]. 计算机科学与探索, 2023, 17(1): 228-237. |
| [3] | 许嘉, 莫晓琨, 于戈, 吕品, 韦婷婷. SQL-Detector:基于编码特征的SQL习题抄袭检测技术[J]. 计算机科学与探索, 2022, 16(9): 2030-2040. |
| [4] | 陈磊, 吴润秀, 李沛武, 赵嘉. 加权K近邻和多簇合并的密度峰值聚类算法[J]. 计算机科学与探索, 2022, 16(9): 2163-2176. |
| [5] | 何云斌, 刘婉旭, 万静. 障碍空间中Voronoi图优化的反向近邻数聚类算法[J]. 计算机科学与探索, 2022, 16(9): 2041-2049. |
| [6] | 叶廷宇, 叶军, 王晖, 王磊. 结合人工蜂群优化的粗糙K-means聚类算法[J]. 计算机科学与探索, 2022, 16(8): 1923-1932. |
| [7] | 赵力衡, 王建, 陈虹君. 去中心化加权簇归并的密度峰值聚类算法[J]. 计算机科学与探索, 2022, 16(8): 1910-1922. |
| [8] | 张祥平, 刘建勋, 肖巧翔, 曹步清. 融合多维信息的Web服务表征方法[J]. 计算机科学与探索, 2022, 16(7): 1561-1569. |
| [9] | 刘雅芬, 郑艺峰, 江铃燚, 李国和, 张文杰. 深度半监督学习中伪标签方法综述[J]. 计算机科学与探索, 2022, 16(6): 1279-1290. |
| [10] | 蒋祎莹, 张丽平, 金飞虎, 郝晓红. 空间数据库中混合数据组最近邻查询[J]. 计算机科学与探索, 2022, 16(2): 348-358. |
| [11] | 董新玉, 解滨, 赵旭升, 高新宝. 多视角层次聚类下的无线网络入侵检测算法[J]. 计算机科学与探索, 2022, 16(12): 2752-2764. |
| [12] | 陈俊芬, 张明, 赵佳成, 谢博鋆, 李艳. 结合降噪和自注意力的深度聚类算法[J]. 计算机科学与探索, 2021, 15(9): 1717-1727. |
| [13] | 王大刚, 丁世飞, 钟锦. 基于二阶[k]近邻的密度峰值聚类算法研究[J]. 计算机科学与探索, 2021, 15(8): 1490-1500. |
| [14] | 沈学利, 秦鑫宇. 密度Canopy的增强聚类与深度特征的KNN算法[J]. 计算机科学与探索, 2021, 15(7): 1289-1301. |
| [15] | 范瑞东, 侯臣平. 鲁棒自加权的多视图子空间聚类[J]. 计算机科学与探索, 2021, 15(6): 1062-1073. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||