
计算机科学与探索 ›› 2022, Vol. 16 ›› Issue (8): 1910-1922.DOI: 10.3778/j.issn.1673-9418.2111138
赵力衡1,+( ), 王建1,2, 陈虹君1
), 王建1,2, 陈虹君1
收稿日期:2021-11-30
修回日期:2022-03-24
出版日期:2022-08-01
发布日期:2022-08-19
通讯作者:
+E-mail: 1503233800@qq.com。作者简介:赵力衡(1976—),男,四川成都人,硕士,高级工程师,CCF专业会员,主要研究方向为数据挖掘、海量数据存储。基金资助:
ZHAO Liheng1,+(), WANG Jian1,2, CHEN Hongjun1
Received:2021-11-30
Revised:2022-03-24
Online:2022-08-01
Published:2022-08-19
About author:ZHAO Liheng, born in 1976, M.S., senior engineer, professional member of CCF. His research interests include data mining and massive data storage.Supported by:摘要:
快速搜索和寻找密度峰值聚类算法(DPC)是近年来提出的一种基于密度的聚类算法,具有原理简单、无需迭代并能实现任意形状聚类的优点。但该算法仍存在一些缺陷:围绕聚类中心点聚类,使聚类结果受中心点影响显著,且聚类中心点数量仍需人为指定;截断距离仅考虑了数据的分布密度,忽略了数据的内部特征;聚类过程中若有样本存在分配错误,会导致其后续样本聚类出现跟随错误。针对上述问题,尝试提出一种去中心化加权簇归并的密度峰值聚类算法(DCM-DPC)。该算法引入权重系数重新定义了局部密度,并由此划分出位于不同局部高密度区域的核心样本组,用于取代聚类中心点成为聚类的依据。最后将剩余样本按其近邻样本所在类簇的众数,或分配到最高耦合的核心样本组代表的类簇中或标注为离散点以完成聚类。在人工和UCI数据集上的实验结果表明,提出算法的聚类效果优于对比算法,对相互纠缠的类簇的边界样本划分也更加精确。
中图分类号:
赵力衡, 王建, 陈虹君. 去中心化加权簇归并的密度峰值聚类算法[J]. 计算机科学与探索, 2022, 16(8): 1910-1922.
ZHAO Liheng, WANG Jian, CHEN Hongjun. Density-Peak Clustering Algorithm on Decentralized and Weighted Clusters Merging[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(8): 1910-1922.
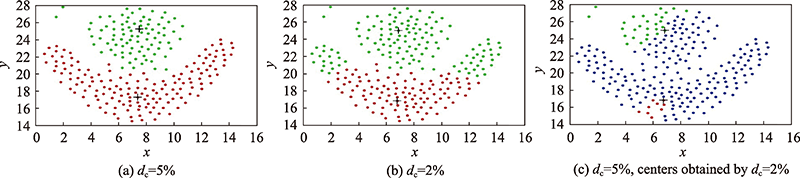
图1 不同聚类中心点的聚类效果对比图
Fig.1 Clustering effect contrast diagram of different clustering centers
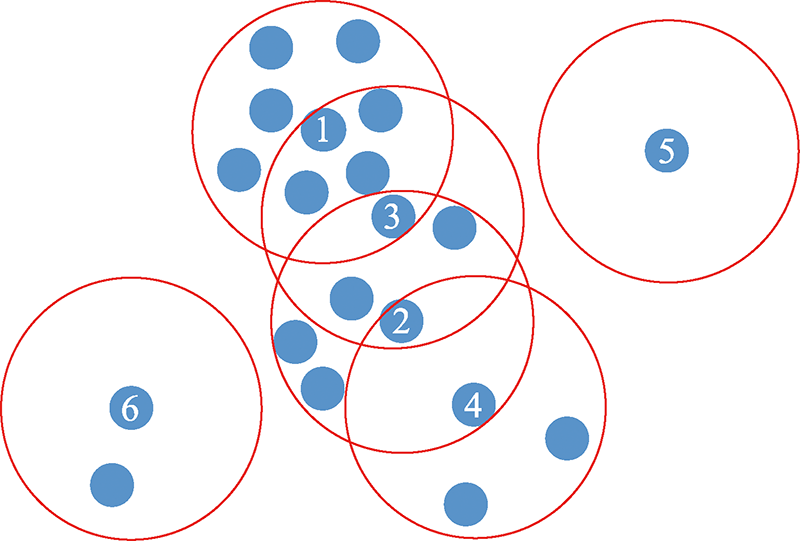
图2 数据分布示意图
Fig.2 Schematic diagram of data distribution

图3 Aggregation数据分布图
Fig.3 Distribution map of Aggregation dataset

图4 核心样本组归并示意图
Fig.4 Schematic diagram of core sample groups
| 数据集 | 样本数 | 属性数 | 类簇数 |
|---|---|---|---|
| Aggregation | 788 | 2 | 7 |
| D31 | 3 100 | 2 | 31 |
| Flame | 240 | 2 | 2 |
| Jain | 373 | 2 | 2 |
| Spiral | 312 | 2 | 3 |
| R15 | 600 | 2 | 15 |
表1 人工数据集
Table 1 Artificial datasets
| 数据集 | 样本数 | 属性数 | 类簇数 |
|---|---|---|---|
| Aggregation | 788 | 2 | 7 |
| D31 | 3 100 | 2 | 31 |
| Flame | 240 | 2 | 2 |
| Jain | 373 | 2 | 2 |
| Spiral | 312 | 2 | 3 |
| R15 | 600 | 2 | 15 |
| 数据集 | 样本数 | 属性数 | 类簇数 |
|---|---|---|---|
| Iris | 150 | 4 | 3 |
| Soybean(Small) | 35 | 47 | 4 |
| Statlog(Heart) | 270 | 13 | 2 |
表2 UCI数据集
Table 2 UCI datasets
| 数据集 | 样本数 | 属性数 | 类簇数 |
|---|---|---|---|
| Iris | 150 | 4 | 3 |
| Soybean(Small) | 35 | 47 | 4 |
| Statlog(Heart) | 270 | 13 | 2 |
| Algorithm | Iris | Soybean(Small) | Statlog(Heart) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| AMI | ARI | FMI | AMI | ARI | FMI | AMI | ARI | FMI | |
| DCM-DPC | 0.786 9 | 0.815 7 | 0.874 2 | 0.957 7 | 0.959 8 | 0.970 0 | 0.263 2 | 0.351 2 | 0.673 1 |
| DPC | 0.724 7 | 0.703 7 | 0.803 2 | 0.662 6 | 0.559 1 | 0.666 9 | 0.027 9 | 0.019 8 | 0.533 4 |
| FKNN-DPC | 0.883 1 | 0.903 8 | 0.935 5 | 0.662 6 | 0.559 1 | 0.666 9 | 0.073 6 | 0.107 0 | 0.579 1 |
| SNN-DPC | 0.540 5 | 0.482 6 | 0.695 7 | 0.555 8 | 0.474 1 | 0.672 3 | 0.241 7 | 0.266 0 | 0.639 7 |
| DBSCAN | 0.640 1 | 0.612 0 | 0.729 1 | 0.807 9 | 0.661 0 | 0.781 3 | 0.035 7 | 0.066 0 | 0.571 1 |
| K-means++ | 0.711 1 | 0.692 6 | 0.800 6 | 0.873 3 | 0.820 1 | 0.864 4 | 0.015 7 | 0.027 6 | 0.527 0 |
表3 6种算法在UCI数据集上的聚类性能
Table 3 Clustering performance of 6 algorithms on UCI datasets
| Algorithm | Iris | Soybean(Small) | Statlog(Heart) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| AMI | ARI | FMI | AMI | ARI | FMI | AMI | ARI | FMI | |
| DCM-DPC | 0.786 9 | 0.815 7 | 0.874 2 | 0.957 7 | 0.959 8 | 0.970 0 | 0.263 2 | 0.351 2 | 0.673 1 |
| DPC | 0.724 7 | 0.703 7 | 0.803 2 | 0.662 6 | 0.559 1 | 0.666 9 | 0.027 9 | 0.019 8 | 0.533 4 |
| FKNN-DPC | 0.883 1 | 0.903 8 | 0.935 5 | 0.662 6 | 0.559 1 | 0.666 9 | 0.073 6 | 0.107 0 | 0.579 1 |
| SNN-DPC | 0.540 5 | 0.482 6 | 0.695 7 | 0.555 8 | 0.474 1 | 0.672 3 | 0.241 7 | 0.266 0 | 0.639 7 |
| DBSCAN | 0.640 1 | 0.612 0 | 0.729 1 | 0.807 9 | 0.661 0 | 0.781 3 | 0.035 7 | 0.066 0 | 0.571 1 |
| K-means++ | 0.711 1 | 0.692 6 | 0.800 6 | 0.873 3 | 0.820 1 | 0.864 4 | 0.015 7 | 0.027 6 | 0.527 0 |
| Algorithm | Aggregation | D31 | Flame | ||||||
|---|---|---|---|---|---|---|---|---|---|
| AMI | ARI | FMI | AMI | ARI | FMI | AMI | ARI | FMI | |
| DCM-DPC | 0.995 6 | 0.997 8 | 0.998 3 | 0.960 8 | 0.946 1 | 0.947 8 | 0.970 4 | 0.988 1 | 0.994 5 |
| DPC | 0.992 2 | 0.995 6 | 0.996 6 | 0.955 4 | 0.936 5 | 0.938 5 | 1.000 0 | 1.000 0 | 1.000 0 |
| FKNN-DPC | 0.990 5 | 0.994 9 | 0.996 0 | 0.965 4 | 0.952 3 | 0.953 8 | 0.926 7 | 0.966 7 | 0.984 5 |
| SNN-DPC | 0.950 0 | 0.959 4 | 0.968 1 | 0.964 2 | 0.950 9 | 0.952 5 | 0.897 4 | 0.950 1 | 0.976 8 |
| DBSCAN | 0.968 1 | 0.977 9 | 0.982 7 | 0.903 2 | 0.809 5 | 0.816 3 | 0.866 5 | 0.938 8 | 0.971 2 |
| K-means++ | 0.807 6 | 0.741 1 | 0.792 0 | 0.926 6 | 0.852 5 | 0.858 3 | 0.430 4 | 0.490 7 | 0.755 1 |
| Algorithm | Jain | Spiral | R15 | ||||||
| AMI | ARI | FMI | AMI | ARI | FMI | AMI | ARI | FMI | |
| DCM-DPC | 1.000 0 | 1.000 0 | 1.000 0 | 1.000 0 | 1.000 0 | 1.000 0 | 0.993 8 | 0.992 8 | 0.993 3 |
| DPC | 0.618 3 | 0.714 6 | 0.881 9 | 1.000 0 | 1.000 0 | 1.000 0 | 0.993 8 | 0.992 8 | 0.993 3 |
| FKNN-DPC | 0.709 2 | 0.822 4 | 0.935 9 | 1.000 0 | 1.000 0 | 1.000 0 | 0.993 8 | 0.992 8 | 0.993 3 |
| SNN-DPC | 0.466 7 | 0.514 6 | 0.790 5 | 1.000 0 | 1.000 0 | 1.000 0 | 0.993 8 | 0.992 8 | 0.993 3 |
| DBSCAN | 0.928 1 | 0.975 8 | 0.990 6 | 1.000 0 | 1.000 0 | 1.000 0 | 0.983 2 | 0.975 8 | 0.979 9 |
| K-means++ | 0.491 6 | 0.584 7 | 0.820 5 | -0.005 5 | -0.006 0 | 0.327 4 | 0.943 8 | 0.897 1 | 0.905 1 |
表4 6种算法在人工数据集上的聚类性能
Table 4 Clustering performance of 6 algorithms on artificial datasets
| Algorithm | Aggregation | D31 | Flame | ||||||
|---|---|---|---|---|---|---|---|---|---|
| AMI | ARI | FMI | AMI | ARI | FMI | AMI | ARI | FMI | |
| DCM-DPC | 0.995 6 | 0.997 8 | 0.998 3 | 0.960 8 | 0.946 1 | 0.947 8 | 0.970 4 | 0.988 1 | 0.994 5 |
| DPC | 0.992 2 | 0.995 6 | 0.996 6 | 0.955 4 | 0.936 5 | 0.938 5 | 1.000 0 | 1.000 0 | 1.000 0 |
| FKNN-DPC | 0.990 5 | 0.994 9 | 0.996 0 | 0.965 4 | 0.952 3 | 0.953 8 | 0.926 7 | 0.966 7 | 0.984 5 |
| SNN-DPC | 0.950 0 | 0.959 4 | 0.968 1 | 0.964 2 | 0.950 9 | 0.952 5 | 0.897 4 | 0.950 1 | 0.976 8 |
| DBSCAN | 0.968 1 | 0.977 9 | 0.982 7 | 0.903 2 | 0.809 5 | 0.816 3 | 0.866 5 | 0.938 8 | 0.971 2 |
| K-means++ | 0.807 6 | 0.741 1 | 0.792 0 | 0.926 6 | 0.852 5 | 0.858 3 | 0.430 4 | 0.490 7 | 0.755 1 |
| Algorithm | Jain | Spiral | R15 | ||||||
| AMI | ARI | FMI | AMI | ARI | FMI | AMI | ARI | FMI | |
| DCM-DPC | 1.000 0 | 1.000 0 | 1.000 0 | 1.000 0 | 1.000 0 | 1.000 0 | 0.993 8 | 0.992 8 | 0.993 3 |
| DPC | 0.618 3 | 0.714 6 | 0.881 9 | 1.000 0 | 1.000 0 | 1.000 0 | 0.993 8 | 0.992 8 | 0.993 3 |
| FKNN-DPC | 0.709 2 | 0.822 4 | 0.935 9 | 1.000 0 | 1.000 0 | 1.000 0 | 0.993 8 | 0.992 8 | 0.993 3 |
| SNN-DPC | 0.466 7 | 0.514 6 | 0.790 5 | 1.000 0 | 1.000 0 | 1.000 0 | 0.993 8 | 0.992 8 | 0.993 3 |
| DBSCAN | 0.928 1 | 0.975 8 | 0.990 6 | 1.000 0 | 1.000 0 | 1.000 0 | 0.983 2 | 0.975 8 | 0.979 9 |
| K-means++ | 0.491 6 | 0.584 7 | 0.820 5 | -0.005 5 | -0.006 0 | 0.327 4 | 0.943 8 | 0.897 1 | 0.905 1 |

图5 Aggregation数据集聚类效果
Fig.5 Clustering effect on Aggregation dataset

图6 D31数据集聚类效果
Fig.6 Clustering effect on D31 dataset
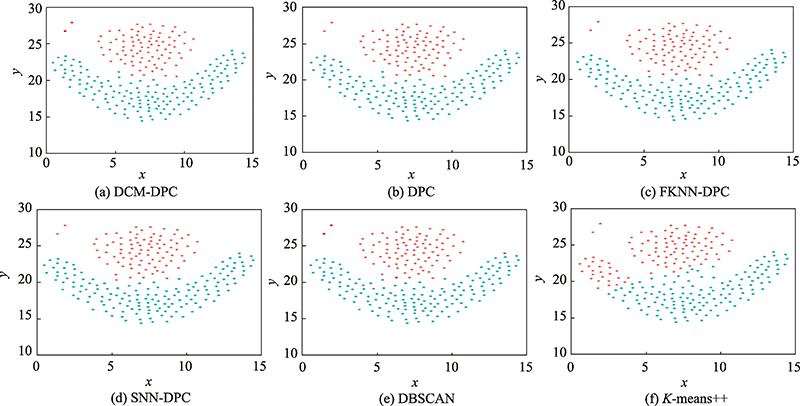
图7 Flame数据集聚类效果
Fig.7 Clustering effect on Flame dataset
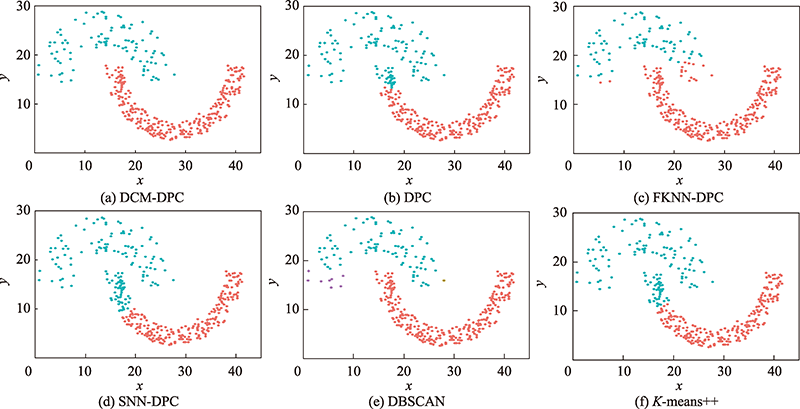
图8 Jain数据集聚类效果
Fig.8 Clustering effect on Jain dataset
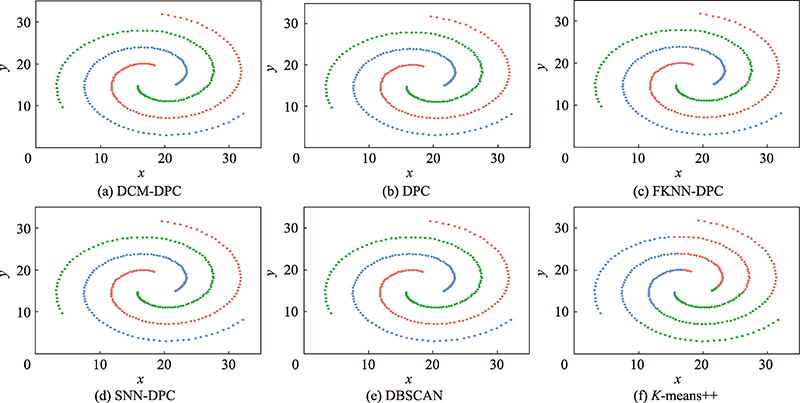
图9 Spiral数据集聚类效果
Fig.9 Clustering effect on Spiral
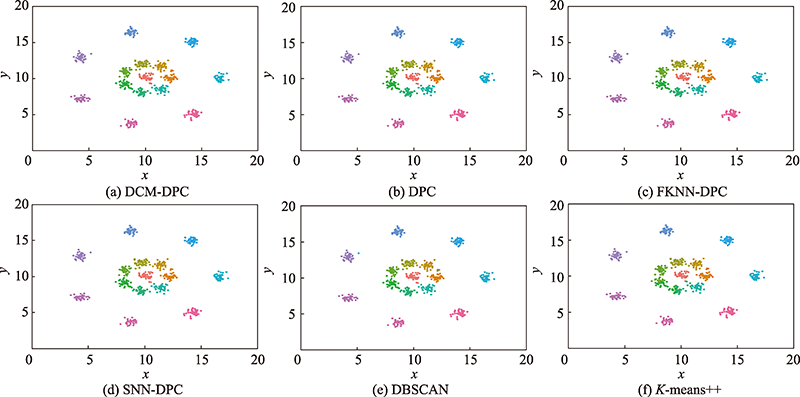
图10 R15数据集聚类效果
Fig.10 Clustering effect on R15 dataset
| [1] | ROSENBERGER C, CHEHDI K. Unsupervised clustering method with optimal estimation of the number of clusters: application to image segmentation[C]// Proceedings of the 15th International Conference on Pattern Recognition, Barcelona, Sep 3-8, 2000. Washington:IEEE Computer Society, 2000: 1656-1659. |
| [2] | WANG C D, LAI J H, HUANG D, et al. SVStream: a support vector-based algorithm for clustering data streams[J]. IEEE Transactions on Knowledge and Data Engineering, 2013, 25(6): 1410-1424. |
| [3] | 陈叶旺, 申莲莲, 钟才明, 等. 密度峰值聚类算法综述[J]. 计算机研究与发展, 2020, 57(2): 378-394. |
| CHEN Y W, SHEN L L, ZHONG C M, et al. Survey on density peak clustering algorithm[J]. Journal of Computer Research and Development, 2020, 57(2): 378-394. | |
| [4] | DING J J, HE X X, YUAN J Q, et al. Automatic clustering based on density peak detection using generalized extreme value distribution[J]. Soft Computing, 2018, 22(9): 2777-2796. |
| [5] | ABE K, MINOURA K, MAEDA Y, et al. Model-based clustering for flow and mass cytometry data with clinical information[J]. BMC Bioinformatics, 2020, 21(13): 393. |
| [6] | XIA S Y, PENG D W, MENG D Y, et al. A fast adaptive K-means with no bounds[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020: 1-13. |
| [7] | POTHULA K R, SMYRNOVA D, SCHRODER G F. Clustering cryo-EM images of helical protein polymers for helical reconstructions[J]. Ultramicroscopy, 2019, 203: 132-138. |
| [8] | BARANWAL M, SALAPAKA S. Clustering and supervisory voltage control in power systems[J]. International Journal of Electrical Power & Energy Systems, 2019, 109: 641-651. |
| [9] | 陆川伟, 孙群, 季晓林, 等. 一种基于核距离的车辆轨迹点聚类方法[J]. 武汉大学学报(信息科学版), 2020, 45(7): 1082-1088. |
| LU C W, SUN Q, JI X L, et al. A method of vehicle trajectory points clustering based on kernel distance[J]. Geomatics and Information Science of Wuhan University, 2020, 45(7): 1082-1088. | |
| [10] | YAN X Q, YE Y D, QIU X Y, et al. Synergetic information bottleneck for joint multiview and ensemble clustering[J]. Information Fusion, 2020, 56: 15-27. |
| [11] | 柏锷湘, 罗可, 罗潇. 结合自然和共享最近邻的密度峰值聚类算法[J]. 计算机科学与探索, 2021, 15(5): 931-940. |
| BAI E X, LUO K, LUO X. Peak density clustering algorithm combining natural and shared nearest neighbor[J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(5): 931-940. | |
| [12] | RODRIGUEZ A, LAIO A. Clustering by fast search and find of density peaks[J]. Science, 2014, 344(6191): 1492-1496. |
| [13] | XIE J Y, GAO H C, XIE W X, et al. Robust clustering by detecting density peaks and assigning points based on fuzzy weighted K-nearest neighbors[J]. Information Sciences, 2016, 354: 19-40. |
| [14] | SEYED A S, ABDULRAHMAN L, PARHAM M, et al. Dynamic graph-based label propagation for density peaks clustering[J]. Expert Systems with Applications, 2019, 115: 314-328. |
| [15] | 丁世飞, 徐晓, 王艳茹. 基于不相似性度量优化的密度峰值聚类算法[J]. 软件学报, 2020, 31(11): 3321-3333. |
| DING S F, XU X, WANG Y R. Optimized density peaks clustering algorithm based on dissimilarity measure[J]. Journal of Software, 2020, 31(11): 3321-3333. | |
| [16] | LIU R, WANG H, YU X M. Shared-nearest-neighbor-based clustering by fast search and find of density peaks[J]. Information Sciences, 2018, 450: 200-226. |
| [17] | 王大刚, 丁世飞, 钟锦,. 基于二阶 k近邻的密度峰值聚类算法研究[J]. 计算机科学与探索, 2021, 15(8): 1490-1500. |
| WANG D G, DING S F, ZHONG J. Research of density peaks clustering algorithm based on second-order k neighbors[J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(8): 1490-1500. | |
| [18] | 王芙银, 张德生, 张晓. 结合鲸鱼优化算法的自适应密度峰值聚类算法[J]. 计算机工程与应用, 2021, 57(3): 94-102. |
| WANG F Y, ZHANG D S, ZHANG X. Adaptive density peaks clustering algorithm combining with whale optimization algorithm[J]. Computer Engineering and Applications, 2021, 57(3): 94-102. | |
| [19] | 纪霞, 姚晟, 赵鹏. 相对邻域与剪枝策略优化的密度峰值聚类算法[J]. 自动化学报, 2020, 46(3): 562-575. |
| JI X, YAO S, ZHAO P. Relative neighborhood and pruning strategy optimized density peaks clustering algorithm[J]. Acta Automatica Sinica, 2020, 46(3): 562-575. | |
| [20] | 陆佳炜, 吴涵, 张元鸣, 等. 融合功能语义关联计算与密度峰值检测的Mashup服务聚类方法[J]. 计算机学报, 2021, 44(7): 1501-1516. |
| LU J W, WU H, ZHANG Y M, et al. Mashup service clustering method via integrating functional semantic association calculation and density peak detection[J]. Chinese Journal of Computers, 2021, 44(7): 1501-1516. | |
| [21] | 刘娟, 万静. 自然反向最近邻优化的密度峰值聚类算法[J]. 计算机科学与探索, 2021, 15(10): 1888-1899. |
| LIU J, WAN J. Optimized density peak clustering algorithm by natural reverse nearest neighbor[J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(10): 1888-1899. | |
| [22] | LIU Y H, MA Z M, YU F. Adaptive density peak clustering based on K-nearest neighbors with aggregating strategy[J]. Knowledge-Based Systems, 2017, 133: 208-220. |
| [23] | SUN L P, TAO T, ZHENG X Y, et al. Combining density peaks clustering and gravitational search method to enhance data clustering[J]. Engineering Applications of Artifical Intelligence, 2019, 85: 865-873. |
| [24] | HUANG D, WANG C D, WU J S, et al. Ultra-scalable spectral clustering and ensemble clustering[J]. IEEE Transactions on Knowledge and Data Engineering, 2020, 32(6): 1212-1226. |
| [25] | WANG S L, LI Q, ZHAO C F, et al. Extreme clustering—a clustering method via density extreme points[J]. Information Sciences, 2021, 542: 24-39. |
| [26] | 朱庆峰, 葛洪伟. K近邻相似度优化的密度峰聚类[J]. 计算机工程与应用, 2019, 55(2): 148-153. |
| ZHU Q F, GE H W. Density peaks clustering optimized by K nearest neighbor’s similarity[J]. Computer Engineering and Applications, 2019, 55(2): 148-153. | |
| [27] | 陈磊, 吴润秀, 李沛武, 等. 加权K近邻和多簇合并的密度峰值聚类算法[J/OL]. 计算机科学与探索(2021-04-19)[2021-12-16]. https://kns.cnki.net/kcms/detail/11.5602.tp.20210416.1428.002.html. |
| CHEN L, WU R X, LI P W, et al. Weighted K-nearest neighbors and multi-clusters merge density peaks clustering algorithm[J/OL]. Journal of Frontiers of Computer Science and Technology (2021-04-19) [2021-12-16]. https://kns.cnki.net/kcms/detail/11.5602.tp.20210416.1428.002.html. | |
| [28] | 杜浩翠, 谢维信. 基于改进的密度峰值聚类的扩展目标跟踪算法[J]. 信号处理, 2021, 37(5): 735-746. |
| DU H C, XIE W X. Extended target tracking algorithm based on improved density peak clustering[J]. Journal of Signal Processing, 2021, 37(5): 735-746. | |
| [29] | 赵嘉, 姚占峰, 吕莉, 等. 基于相互邻近度的密度峰值聚类算法[J]. 控制与决策, 2021, 36(3): 543-552. |
| ZHAO J, YAO Z F, LV L, et al. Density peaks clustering based on mutual neighbor degree[J]. Control and Decision, 2021, 36(3): 543-552. | |
| [30] | ESTER M, KRIEGEL H P, SANDER J, et al. A density-based algorithm for discovering clusters in large spatial databases with noise[C]// Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining, Portland, 1996. Menlo Park:AAAI, 1996: 226-231. |
| [31] | ARTHUR D, VASSILVITSKII S. K-means++: the advantages of careful seeding[C]// Proceedings of the 18th Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, Jan 7-9, 2007. New York: ACM, 2007: 1027-1035. |
| [32] | NGUYEN X V, EPPS J, BAILEY J. Information theoretic measures for clusterings comparison: variants, properties, normalization and correction for chance[J]. Journal of Machine Learning Research, 2010, 11(1): 2837-2854. |
| [33] | FOWLKES E B, MALLOWS C L. A method for comparing two hierarchical clusterings[J]. Journal of the American Statistical Association, 1983, 78(383): 553-569. |
| [1] | 陈磊, 吴润秀, 李沛武, 赵嘉. 加权K近邻和多簇合并的密度峰值聚类算法[J]. 计算机科学与探索, 2022, 16(9): 2163-2176. |
| [2] | 刘学文, 王继奎, 杨正国, 李冰, 聂飞平. 密度峰值隶属度优化的半监督Self-Training算法[J]. 计算机科学与探索, 2022, 16(9): 2078-2088. |
| [3] | 何云斌, 刘婉旭, 万静. 障碍空间中Voronoi图优化的反向近邻数聚类算法[J]. 计算机科学与探索, 2022, 16(9): 2041-2049. |
| [4] | 许嘉, 莫晓琨, 于戈, 吕品, 韦婷婷. SQL-Detector:基于编码特征的SQL习题抄袭检测技术[J]. 计算机科学与探索, 2022, 16(9): 2030-2040. |
| [5] | 叶廷宇, 叶军, 王晖, 王磊. 结合人工蜂群优化的粗糙K-means聚类算法[J]. 计算机科学与探索, 2022, 16(8): 1923-1932. |
| [6] | 李珺, 段钰蓉, 郝丽艳, 张维维. 混合优化算法求解同时送取货车辆路径问题[J]. 计算机科学与探索, 2022, 16(7): 1623-1632. |
| [7] | 张祥平, 刘建勋, 肖巧翔, 曹步清. 融合多维信息的Web服务表征方法[J]. 计算机科学与探索, 2022, 16(7): 1561-1569. |
| [8] | 郭晓旺, 夏鸿斌, 刘渊. 融合知识图谱与图卷积网络的混合推荐模型[J]. 计算机科学与探索, 2022, 16(6): 1343-1353. |
| [9] | 陈俊芬, 张明, 赵佳成, 谢博鋆, 李艳. 结合降噪和自注意力的深度聚类算法[J]. 计算机科学与探索, 2021, 15(9): 1717-1727. |
| [10] | 王大刚, 丁世飞, 钟锦. 基于二阶[k]近邻的密度峰值聚类算法研究[J]. 计算机科学与探索, 2021, 15(8): 1490-1500. |
| [11] | 吴将, 宋晶晶, 程富豪, 王平心, 杨习贝. 面向连续参数的多粒度属性约简方法研究[J]. 计算机科学与探索, 2021, 15(8): 1555-1562. |
| [12] | 沈学利, 秦鑫宇. 密度Canopy的增强聚类与深度特征的KNN算法[J]. 计算机科学与探索, 2021, 15(7): 1289-1301. |
| [13] | 范瑞东, 侯臣平. 鲁棒自加权的多视图子空间聚类[J]. 计算机科学与探索, 2021, 15(6): 1062-1073. |
| [14] | 柏锷湘, 罗可, 罗潇. 结合自然和共享最近邻的密度峰值聚类算法[J]. 计算机科学与探索, 2021, 15(5): 931-940. |
| [15] | 张倪妮, 葛洪伟. 稳定的K-多均值聚类算法[J]. 计算机科学与探索, 2021, 15(5): 941-948. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||