
计算机科学与探索 ›› 2022, Vol. 16 ›› Issue (12): 2695-2717.DOI: 10.3778/j.issn.1673-9418.2206026
周燕, 蒲磊( ), 林良熙, 刘翔宇, 曾凡智, 周月霞
), 林良熙, 刘翔宇, 曾凡智, 周月霞
收稿日期:2022-06-06
修回日期:2022-08-31
出版日期:2022-12-01
发布日期:2022-12-16
通讯作者:
+E-mail: 2112151112@stu.fosu.edu.cn作者简介:周燕(1979—),女,江西抚州人,硕士,教授,硕士生导师,CCF会员,主要研究方向为图像处理、计算机视觉、机器学习。基金资助:
ZHOU Yan, PU Lei(), LIN Liangxi, LIU Xiangyu, ZENG Fanzhi, ZHOU Yuexia
Received:2022-06-06
Revised:2022-08-31
Online:2022-12-01
Published:2022-12-16
About author:ZHOU Yan, born in 1979, M.S., professor, M.S. supervisor, member of CCF. Her research inte-rests include image processing, computer vision and machine learning.Supported by:摘要:
三维目标检测是近年来新兴的研究方向,其主要任务是对空间中的目标进行定位与识别。目前采用单目或双目视觉的方法来完成三维目标检测任务,其容易受物体遮挡、视点变化和尺度变化的影响,导致检测精度不佳及鲁棒性差等问题。由于激光点云能描述三维场景的信息,在激光点云数据的基础上使用深度学习的方法完成三维目标检测任务,已成为三维视觉领域中研究的热点。针对激光点云的三维目标检测,梳理了近年来相关的研究工作。首先根据输入网络的数据形式,将基于激光点云的三维目标检测方法分为基于原始点云、基于点云投影、基于点云体素化及基于多模态融合的三维目标检测方法,并对各类最具有代表性的方法进行了详细阐述。然后介绍了当前常用的开源数据集及其评价指标,并在数据集上对各类方法进行了性能对比,从多个方面讨论了各类方法的优势及局限性。最后指出当前激光点云的三维目标检测研究存在的不足和难点,并对其未来的发展趋势进行了总结与展望。
中图分类号:
周燕, 蒲磊, 林良熙, 刘翔宇, 曾凡智, 周月霞. 激光点云的三维目标检测研究进展[J]. 计算机科学与探索, 2022, 16(12): 2695-2717.
ZHOU Yan, PU Lei, LIN Liangxi, LIU Xiangyu, ZENG Fanzhi, ZHOU Yuexia. Research Progress on 3D Object Detection of LiDAR Point Cloud[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(12): 2695-2717.

图1 基于激光点云的三维目标检测方法
Fig.1 3D object detection methods based on LiDAR point cloud
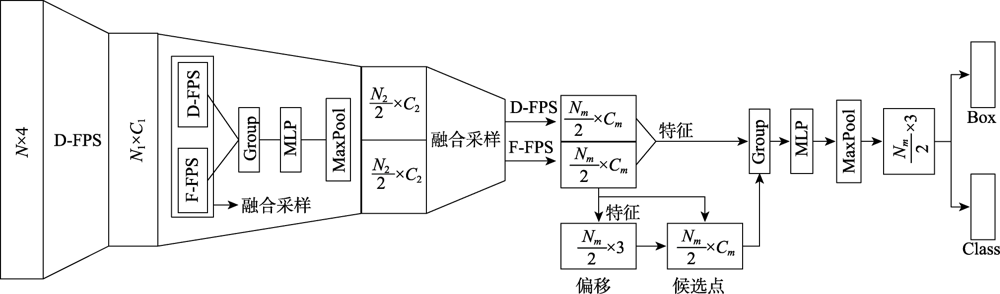
图2 3DSSD框架图
Fig.2 3DSSD framework diagram

图3 Pre-RoI pooling convolution示意图
Fig.3 Pre-RoI pooling convolution schematic diagram

图4 Meta-Kernel卷积操作示意图
Fig.4 Meta-Kernel convolution schematic diagram

图5 体素特征编码网络
Fig.5 Voxel feature encoding network

图6 MV3D框架
Fig.6 MV3D framework
| 模型 | 年份 | 特点 | 局限性 | 适用场景 |
|---|---|---|---|---|
| PointRCNN[ | 2019 | 直接对点云进行特征提取操作 | 点云前景点分割耗时 | 室外 |
| STD[ | 2019 | 对区域内的点云有序化 | 不进行上采样,损失性能 | 室外 |
| 3DSSD[ | 2020 | 使用融合采样的策略 | 对小尺度目标检测差 | 室外 |
| Point-GNN[ | 2020 | 对点云构建图,有利于学习点云结构特征 | 点云图构建耗时 | 室外 |
| 3D IoU-Net[ | 2020 | 通过对齐预测框与基准框提升识别准确率 | 对齐操作使网络复杂 | 室外 |
| SE-RCNN[ | 2020 | 不需要非极大值抑制操作 | 检测结果受点云密度的影响 | 室外 |
| PC-RGNN[ | 2021 | 对稀疏点云区域进行补全操作 | 网络复杂且实时性差 | 室外 |
| LiDAR R-CNN[ | 2021 | 感知边界偏移,解决目标的尺寸歧义 | 模块复杂,检测效率降低 | 室外 |
| SE-SSD[ | 2021 | 设置教师网络监督学生网络进行学习 | 需要大规模数据集进行训练 | 室外 |
| SASA[ | 2022 | 基于语义引导的采样模块 | 采样易受噪声点云的影响 | 室外 |
| IA-SSD[ | 2022 | 基于学习与实例感知的下采样策略 | 对大场景下远处物体识别较差 | 室外 |
表1 基于原始点云方法的分析与总结
Table 1 Analysis and summary of methods based on point cloud
| 模型 | 年份 | 特点 | 局限性 | 适用场景 |
|---|---|---|---|---|
| PointRCNN[ | 2019 | 直接对点云进行特征提取操作 | 点云前景点分割耗时 | 室外 |
| STD[ | 2019 | 对区域内的点云有序化 | 不进行上采样,损失性能 | 室外 |
| 3DSSD[ | 2020 | 使用融合采样的策略 | 对小尺度目标检测差 | 室外 |
| Point-GNN[ | 2020 | 对点云构建图,有利于学习点云结构特征 | 点云图构建耗时 | 室外 |
| 3D IoU-Net[ | 2020 | 通过对齐预测框与基准框提升识别准确率 | 对齐操作使网络复杂 | 室外 |
| SE-RCNN[ | 2020 | 不需要非极大值抑制操作 | 检测结果受点云密度的影响 | 室外 |
| PC-RGNN[ | 2021 | 对稀疏点云区域进行补全操作 | 网络复杂且实时性差 | 室外 |
| LiDAR R-CNN[ | 2021 | 感知边界偏移,解决目标的尺寸歧义 | 模块复杂,检测效率降低 | 室外 |
| SE-SSD[ | 2021 | 设置教师网络监督学生网络进行学习 | 需要大规模数据集进行训练 | 室外 |
| SASA[ | 2022 | 基于语义引导的采样模块 | 采样易受噪声点云的影响 | 室外 |
| IA-SSD[ | 2022 | 基于学习与实例感知的下采样策略 | 对大场景下远处物体识别较差 | 室外 |
| 模型 | 年份 | 特点 | 局限性 | 适用场景 |
|---|---|---|---|---|
| WS3D[ | 2020 | 使用弱标注的鸟瞰图与少量精确三维标注实现弱监督 | 还需要少量的精确三维标注 | 室外 |
| VS3D[ | 2020 | 不需要使用三维标注信息 | 性能与全监督方法差距较大 | 室外 |
| FGR[ | 2021 | 利用顶点和边与截锥体相交的条件来生成伪三维标签 | 依赖二维目标检测器 | 室外 |
| BR[ | 2022 | 利用虚拟标签辅助训练网络 | 仅在室内场景适用 | 室内 |
表2 基于点云的弱监督方法分析与总结
Table 2 Analysis and summary of weakly supervised methods based on point cloud
| 模型 | 年份 | 特点 | 局限性 | 适用场景 |
|---|---|---|---|---|
| WS3D[ | 2020 | 使用弱标注的鸟瞰图与少量精确三维标注实现弱监督 | 还需要少量的精确三维标注 | 室外 |
| VS3D[ | 2020 | 不需要使用三维标注信息 | 性能与全监督方法差距较大 | 室外 |
| FGR[ | 2021 | 利用顶点和边与截锥体相交的条件来生成伪三维标签 | 依赖二维目标检测器 | 室外 |
| BR[ | 2022 | 利用虚拟标签辅助训练网络 | 仅在室内场景适用 | 室内 |
| 模型 | 年份 | 特点 | 局限性 | 使用场景 |
|---|---|---|---|---|
| VeloFCN[ | 2017 | 率先使用前视图完成三维目标检测任务 | 无法通过单张视图特征挖掘空间信息 | 室外 |
| RT3D[ | 2018 | 对所有RoI只进行一次卷积操作 | 模型泛化能力不强 | 室外 |
| PIXOR[ | 2018 | 利用残差网络对鸟瞰图进行特征提取 | 对物体的尺寸感知不强 | 室外 |
| LaserNet[ | 2019 | 率先使用范围图完成三维目标检测任务 | 未充分挖掘范围图蕴藏的空间信息 | 室外 |
| RangeRCNN[ | 2020 | 将特征从范围图转移到鸟瞰图 | 特征转移时会存在信息丢失 | 室外 |
| PPC[ | 2021 | 多种方式编码范围图特征 | 网络复杂,实时性较差 | 室外 |
| RangeDet[ | 2021 | 使用新的卷积方式处理范围图 | 多检测头网络不易训练 | 室外 |
| RSN[ | 2021 | 在范围图上分割出前景区域 | 易受尺度变化的影响 | 室外 |
| FCOS-LiDAR[ | 2022 | 使用多回合范围图投影机制融合多帧点云 | 对输入的数据有较高的要求 | 室外 |
表3 基于点云投影方法的分析与总结
Table 3 Analysis and summary of methods based on point cloud projection
| 模型 | 年份 | 特点 | 局限性 | 使用场景 |
|---|---|---|---|---|
| VeloFCN[ | 2017 | 率先使用前视图完成三维目标检测任务 | 无法通过单张视图特征挖掘空间信息 | 室外 |
| RT3D[ | 2018 | 对所有RoI只进行一次卷积操作 | 模型泛化能力不强 | 室外 |
| PIXOR[ | 2018 | 利用残差网络对鸟瞰图进行特征提取 | 对物体的尺寸感知不强 | 室外 |
| LaserNet[ | 2019 | 率先使用范围图完成三维目标检测任务 | 未充分挖掘范围图蕴藏的空间信息 | 室外 |
| RangeRCNN[ | 2020 | 将特征从范围图转移到鸟瞰图 | 特征转移时会存在信息丢失 | 室外 |
| PPC[ | 2021 | 多种方式编码范围图特征 | 网络复杂,实时性较差 | 室外 |
| RangeDet[ | 2021 | 使用新的卷积方式处理范围图 | 多检测头网络不易训练 | 室外 |
| RSN[ | 2021 | 在范围图上分割出前景区域 | 易受尺度变化的影响 | 室外 |
| FCOS-LiDAR[ | 2022 | 使用多回合范围图投影机制融合多帧点云 | 对输入的数据有较高的要求 | 室外 |
| 模型 | 年份 | 特点 | 局限性 | 使用场景 |
|---|---|---|---|---|
| Vote3Deep[ | 2017 | 以投票的方式进行稀疏卷积操作 | 投票过程非端到端 | 室外 |
| VoxelNet[ | 2018 | 使用体素特征编码网络学习体素特征 | 模型较大,实时性差 | 室外 |
| SECOND[ | 2018 | 改进的稀疏卷积模块 | 稀疏卷积操作计算量大 | 室外 |
| PointPillars[ | 2019 | 采用体柱的方式编码点云 | 对小尺度目标识别较差 | 室外 |
| SA-SSD[ | 2020 | 通过辅助网络挖掘点与点之间的几何关系 | 辅助网络训练困难 | 室外 |
| SSN[ | 2020 | 使用形状标注网络学习结构特征 | 模型复杂,计算量大 | 室外 |
| HVNet[ | 2020 | 对不同分辨率的体素进行特征融合 | 多种分辨率体素需占用较大内存 | 室外 |
| Part-A2[ | 2020 | RoI生成阶段对边界框进行局部感知 | 实例分割操作计算开销大 | 室外 |
| TANet[ | 2020 | 通过Triple Attention模块获取体素的显著特征 | 更关注小尺度的目标 | 室外 |
| Voxel-FPN[ | 2020 | 对多个尺度体素进行编码 | 计算消耗大 | 室外 |
| HotSpotNet[ | 2020 | 在体素中分配热点区域并预测边界框 | 存在空体素的影响 | 室外 |
| AFDet[ | 2020 | 无锚框、无非极大值抑制操作的单阶段框架 | 对目标尺寸感知不强 | 室外 |
| CenterPoint[ | 2021 | 在鸟瞰伪图像中预测热点,通过热点检测目标 | 热点分配受点云密度影响 | 室外 |
| CADNet[ | 2021 | 使用动态卷积适应不同区域点云密度的变化 | 对大场景不适用 | 室外 |
| CIA-SSD[ | 2021 | 提出置信IoU感知模块对齐定位和分类任务 | 丢失了部分体素内点信息 | 室外 |
| PDV[ | 2022 | 密度感知的RoI网格池化模块聚集空间局部特征 | 核密度估计导致计算开销大 | 室外 |
| SST[ | 2022 | 基于单步长的稀疏Transformer框架 | 网络模型内存占用大 | 室外 |
表4 基于点云体素化方法的分析与总结
Table 4 Analysis and summary of methods based on point cloud voxelization
| 模型 | 年份 | 特点 | 局限性 | 使用场景 |
|---|---|---|---|---|
| Vote3Deep[ | 2017 | 以投票的方式进行稀疏卷积操作 | 投票过程非端到端 | 室外 |
| VoxelNet[ | 2018 | 使用体素特征编码网络学习体素特征 | 模型较大,实时性差 | 室外 |
| SECOND[ | 2018 | 改进的稀疏卷积模块 | 稀疏卷积操作计算量大 | 室外 |
| PointPillars[ | 2019 | 采用体柱的方式编码点云 | 对小尺度目标识别较差 | 室外 |
| SA-SSD[ | 2020 | 通过辅助网络挖掘点与点之间的几何关系 | 辅助网络训练困难 | 室外 |
| SSN[ | 2020 | 使用形状标注网络学习结构特征 | 模型复杂,计算量大 | 室外 |
| HVNet[ | 2020 | 对不同分辨率的体素进行特征融合 | 多种分辨率体素需占用较大内存 | 室外 |
| Part-A2[ | 2020 | RoI生成阶段对边界框进行局部感知 | 实例分割操作计算开销大 | 室外 |
| TANet[ | 2020 | 通过Triple Attention模块获取体素的显著特征 | 更关注小尺度的目标 | 室外 |
| Voxel-FPN[ | 2020 | 对多个尺度体素进行编码 | 计算消耗大 | 室外 |
| HotSpotNet[ | 2020 | 在体素中分配热点区域并预测边界框 | 存在空体素的影响 | 室外 |
| AFDet[ | 2020 | 无锚框、无非极大值抑制操作的单阶段框架 | 对目标尺寸感知不强 | 室外 |
| CenterPoint[ | 2021 | 在鸟瞰伪图像中预测热点,通过热点检测目标 | 热点分配受点云密度影响 | 室外 |
| CADNet[ | 2021 | 使用动态卷积适应不同区域点云密度的变化 | 对大场景不适用 | 室外 |
| CIA-SSD[ | 2021 | 提出置信IoU感知模块对齐定位和分类任务 | 丢失了部分体素内点信息 | 室外 |
| PDV[ | 2022 | 密度感知的RoI网格池化模块聚集空间局部特征 | 核密度估计导致计算开销大 | 室外 |
| SST[ | 2022 | 基于单步长的稀疏Transformer框架 | 网络模型内存占用大 | 室外 |
| 融合类型 | 模型 | 年份 | 特点 | 局限性 | 使用场景 |
|---|---|---|---|---|---|
| 点云与视图 | MV3D[ | 2017 | 鸟瞰图、前视图与RGB图像融合 | 未充分挖掘各视图之间的关系 | 室外 |
| AVOD[ | 2018 | 通过裁剪调整融合RGB图像与鸟瞰图 | 融合处理较为简单 | 室外 | |
| PointFusion[ | 2018 | 采用早融合的策略 | 非端到端的网络 | 室外、室内 | |
| F-PointNet[ | 2018 | RGB图像候选框投影为视锥体 | 实例分割模块计算消耗大 | 室外、室内 | |
| 文献[ | 2018 | 使用连续卷积融合图像与点云特征 | 视图转换过程中存在稀疏情况 | 室外 | |
| F-ConvNet[ | 2019 | 对视锥体分序列进行特征提取 | 受点云稀疏程度的影响 | 室外、室内 | |
| SCANet[ | 2019 | 使用逐元素平均的融合方式 | 模型计算量大 | 室外 | |
| MMF[ | 2019 | 对RGB图像深度补全后生成伪点云 | 检测精度依赖于深度补全 | 室外 | |
| PI-RCNN[ | 2020 | 通过注意力连续卷积融合图像与点云 | 图像实例分割任务耗时 | 室外 | |
| EPNet[ | 2020 | 分级融合点云与图像 | 点云与图像校准要求高 | 室外、室内 | |
| PointPainting[ | 2020 | 将图像分割分数附加在点云上 | 分割分数难以代表图像特征 | 室外 | |
| PointAugmenting[ | 2021 | 将卷积网络的高维特征附加在点云上 | 数据增强方法通用性不高 | 室外 | |
| CAT-Det[ | 2022 | 利用Transformer挖掘点云与图像的关系 | 网络模型内存占用大 | 室外 | |
| CVFNet[ | 2022 | 融合点云与范围图并转换至鸟瞰图形式 | 转换会导致特征丢失 | 室外 | |
| 点云与体素 | PV-RCNN[ | 2019 | 点云与体素融合开拓者 | 点云采样操作耗时 | 室外 |
| HVPR[ | 2021 | 在训练时引入内存模块增强点云特征 | 训练阶段较为复杂 | 室外 | |
| PVGNet[ | 2021 | 将点、体素与网格特征进行融合 | 三种层次特征融合方式简单 | 室外 | |
| BADet[ | 2022 | 对候选框构建图并学习图的结点特征 | 构图过程计算消耗大 | 室外 | |
| 体素与视图 | MVF[ | 2020 | 采用动态体素化的方法减少内存消耗 | 网络性能受点云变化影响 | 室外 |
| 文献[ | 2020 | 使用柱面投影的方式生成视图 | 对稀疏区域投影插值存在偏差 | 室外 | |
| 文献[ | 2022 | 对范围图进行全景分割,增强体素特征 | 检测性能受全景分割影响 | 室外 |
表5 基于多模态融合方法的分析与总结
Table 5 Analysis and summary of methods based on multi-modal fusion
| 融合类型 | 模型 | 年份 | 特点 | 局限性 | 使用场景 |
|---|---|---|---|---|---|
| 点云与视图 | MV3D[ | 2017 | 鸟瞰图、前视图与RGB图像融合 | 未充分挖掘各视图之间的关系 | 室外 |
| AVOD[ | 2018 | 通过裁剪调整融合RGB图像与鸟瞰图 | 融合处理较为简单 | 室外 | |
| PointFusion[ | 2018 | 采用早融合的策略 | 非端到端的网络 | 室外、室内 | |
| F-PointNet[ | 2018 | RGB图像候选框投影为视锥体 | 实例分割模块计算消耗大 | 室外、室内 | |
| 文献[ | 2018 | 使用连续卷积融合图像与点云特征 | 视图转换过程中存在稀疏情况 | 室外 | |
| F-ConvNet[ | 2019 | 对视锥体分序列进行特征提取 | 受点云稀疏程度的影响 | 室外、室内 | |
| SCANet[ | 2019 | 使用逐元素平均的融合方式 | 模型计算量大 | 室外 | |
| MMF[ | 2019 | 对RGB图像深度补全后生成伪点云 | 检测精度依赖于深度补全 | 室外 | |
| PI-RCNN[ | 2020 | 通过注意力连续卷积融合图像与点云 | 图像实例分割任务耗时 | 室外 | |
| EPNet[ | 2020 | 分级融合点云与图像 | 点云与图像校准要求高 | 室外、室内 | |
| PointPainting[ | 2020 | 将图像分割分数附加在点云上 | 分割分数难以代表图像特征 | 室外 | |
| PointAugmenting[ | 2021 | 将卷积网络的高维特征附加在点云上 | 数据增强方法通用性不高 | 室外 | |
| CAT-Det[ | 2022 | 利用Transformer挖掘点云与图像的关系 | 网络模型内存占用大 | 室外 | |
| CVFNet[ | 2022 | 融合点云与范围图并转换至鸟瞰图形式 | 转换会导致特征丢失 | 室外 | |
| 点云与体素 | PV-RCNN[ | 2019 | 点云与体素融合开拓者 | 点云采样操作耗时 | 室外 |
| HVPR[ | 2021 | 在训练时引入内存模块增强点云特征 | 训练阶段较为复杂 | 室外 | |
| PVGNet[ | 2021 | 将点、体素与网格特征进行融合 | 三种层次特征融合方式简单 | 室外 | |
| BADet[ | 2022 | 对候选框构建图并学习图的结点特征 | 构图过程计算消耗大 | 室外 | |
| 体素与视图 | MVF[ | 2020 | 采用动态体素化的方法减少内存消耗 | 网络性能受点云变化影响 | 室外 |
| 文献[ | 2020 | 使用柱面投影的方式生成视图 | 对稀疏区域投影插值存在偏差 | 室外 | |
| 文献[ | 2022 | 对范围图进行全景分割,增强体素特征 | 检测性能受全景分割影响 | 室外 |
| Method | Year | Type | Car AP/% | Pedestrian AP/% | Cyclist AP/% | Speed/ms | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Easy | Mod | Hard | Easy | Mod | Hard | Easy | Mod | Hard | ||||
| PointRCNN[ | 2019 | 2-stage | 86.96 | 75.64 | 70.70 | 47.98 | 39.37 | 36.01 | 74.96 | 58.82 | 52.53 | 100 |
| STD[ | 2019 | 2-stage | 87.95 | 79.71 | 75.09 | 53.29 | 42.47 | 38.35 | 78.69 | 61.59 | 55.30 | 80 |
| Point-GNN[ | 2020 | 2-stage | 88.33 | 79.47 | 72.29 | 51.92 | 43.77 | 40.14 | 78.60 | 63.48 | 57.08 | 600 |
| 3DSSD[ | 2020 | 1-stage | 88.36 | 79.57 | 74.55 | 54.64 | 44.27 | 40.23 | 82.48 | 64.10 | 56.90 | 40 |
| 3D IoU-Net[ | 2020 | 2-stage | 87.96 | 79.03 | 72.78 | N/A | N/A | N/A | N/A | N/A | N/A | 100 |
| SE-RCNN[ | 2020 | 2-stage | 87.74 | 78.96 | 74.30 | N/A | N/A | N/A | N/A | N/A | N/A | 100 |
| PC-RGNN[ | 2021 | 2-stage | 89.13 | 79.90 | 75.54 | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| SE-SSD[ | 2021 | 1-stage | 91.49 | 82.54 | 77.15 | N/A | N/A | N/A | N/A | N/A | N/A | 30 |
| IA-SSD[ | 2022 | 1-stage | 88.87 | 80.32 | 75.10 | 47.90 | 41.03 | 37.98 | 82.36 | 66.25 | 59.70 | 13 |
| SASA[ | 2022 | 1-stage | 88.76 | 82.16 | 77.16 | N/A | N/A | N/A | N/A | N/A | N/A | 40 |
表6 基于原始点云方法的性能指标(KITTI数据集)
Table 6 Performance of methods based on point cloud (KITTI dataset)
| Method | Year | Type | Car AP/% | Pedestrian AP/% | Cyclist AP/% | Speed/ms | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Easy | Mod | Hard | Easy | Mod | Hard | Easy | Mod | Hard | ||||
| PointRCNN[ | 2019 | 2-stage | 86.96 | 75.64 | 70.70 | 47.98 | 39.37 | 36.01 | 74.96 | 58.82 | 52.53 | 100 |
| STD[ | 2019 | 2-stage | 87.95 | 79.71 | 75.09 | 53.29 | 42.47 | 38.35 | 78.69 | 61.59 | 55.30 | 80 |
| Point-GNN[ | 2020 | 2-stage | 88.33 | 79.47 | 72.29 | 51.92 | 43.77 | 40.14 | 78.60 | 63.48 | 57.08 | 600 |
| 3DSSD[ | 2020 | 1-stage | 88.36 | 79.57 | 74.55 | 54.64 | 44.27 | 40.23 | 82.48 | 64.10 | 56.90 | 40 |
| 3D IoU-Net[ | 2020 | 2-stage | 87.96 | 79.03 | 72.78 | N/A | N/A | N/A | N/A | N/A | N/A | 100 |
| SE-RCNN[ | 2020 | 2-stage | 87.74 | 78.96 | 74.30 | N/A | N/A | N/A | N/A | N/A | N/A | 100 |
| PC-RGNN[ | 2021 | 2-stage | 89.13 | 79.90 | 75.54 | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| SE-SSD[ | 2021 | 1-stage | 91.49 | 82.54 | 77.15 | N/A | N/A | N/A | N/A | N/A | N/A | 30 |
| IA-SSD[ | 2022 | 1-stage | 88.87 | 80.32 | 75.10 | 47.90 | 41.03 | 37.98 | 82.36 | 66.25 | 59.70 | 13 |
| SASA[ | 2022 | 1-stage | 88.76 | 82.16 | 77.16 | N/A | N/A | N/A | N/A | N/A | N/A | 40 |
| Method | Year | Type | Car AP/% | Pedestrian AP/% | Cyclist AP/% | Speed/ms | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Easy | Mod | Hard | Easy | Mod | Hard | Easy | Mod | Hard | ||||
| VeloFCN[ | 2017 | 1-stage | 69.94 | 62.54 | 55.94 | N/A | N/A | N/A | N/A | N/A | N/A | 5 000 |
| RT3D[ | 2018 | 2-stage | 23.74 | 19.14 | 18.86 | N/A | N/A | N/A | N/A | N/A | N/A | 90 |
| PIXOR[ | 2018 | 1-stage | 81.70 | 77.05 | 72.95 | N/A | N/A | N/A | N/A | N/A | N/A | 90 |
| LaserNet[ | 2019 | 1-stage | 78.25 | 73.77 | 66.47 | N/A | N/A | N/A | N/A | N/A | N/A | 30 |
| RangeRCNN[ | 2020 | 2-stage | 88.47 | 81.33 | 77.09 | N/A | N/A | N/A | N/A | N/A | N/A | 60 |
| RangeIoUDet[ | 2021 | 2-stage | 88.60 | 79.80 | 76.76 | N/A | N/A | N/A | 83.12 | 67.77 | 60.26 | 20 |
表7 基于点云投影方法的性能指标(KITTI数据集)
Table 7 Performance of methods based on point cloud projection (KITTI dataset)
| Method | Year | Type | Car AP/% | Pedestrian AP/% | Cyclist AP/% | Speed/ms | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Easy | Mod | Hard | Easy | Mod | Hard | Easy | Mod | Hard | ||||
| VeloFCN[ | 2017 | 1-stage | 69.94 | 62.54 | 55.94 | N/A | N/A | N/A | N/A | N/A | N/A | 5 000 |
| RT3D[ | 2018 | 2-stage | 23.74 | 19.14 | 18.86 | N/A | N/A | N/A | N/A | N/A | N/A | 90 |
| PIXOR[ | 2018 | 1-stage | 81.70 | 77.05 | 72.95 | N/A | N/A | N/A | N/A | N/A | N/A | 90 |
| LaserNet[ | 2019 | 1-stage | 78.25 | 73.77 | 66.47 | N/A | N/A | N/A | N/A | N/A | N/A | 30 |
| RangeRCNN[ | 2020 | 2-stage | 88.47 | 81.33 | 77.09 | N/A | N/A | N/A | N/A | N/A | N/A | 60 |
| RangeIoUDet[ | 2021 | 2-stage | 88.60 | 79.80 | 76.76 | N/A | N/A | N/A | 83.12 | 67.77 | 60.26 | 20 |
| Method | Year | Type | LEVEL_1 | LEVEL_2 | Speed/ms | ||||
|---|---|---|---|---|---|---|---|---|---|
| Car AP/% | Pedestrian AP/% | Cyclist AP/% | Car AP/% | Pedestrian AP/% | Cyclist AP/% | ||||
| LaserNet[ | 2019 | 1-stage | 52.10 | 63.40 | N/A | N/A | N/A | N/A | 60 |
| RangeRCNN[ | 2020 | 2-stage | 75.43 | N/A | N/A | N/A | N/A | N/A | 50 |
| PPC[ | 2021 | 1-stage | 65.20 | 75.50 | N/A | N/A | N/A | N/A | N/A |
| RangeDet[ | 2021 | 1-stage | 75.83 | 74.77 | 64.59 | 67.12 | 68.58 | 61.93 | 80 |
| RSN[ | 2021 | 1-stage | 81.38 | 82.41 | 54.60 | 72.80 | 74.75 | 49.18 | N/A |
表8 基于点云投影方法的性能指标(Waymo数据集)
Table 8 Performance of methods based on point cloud projection (Waymo dataset)
| Method | Year | Type | LEVEL_1 | LEVEL_2 | Speed/ms | ||||
|---|---|---|---|---|---|---|---|---|---|
| Car AP/% | Pedestrian AP/% | Cyclist AP/% | Car AP/% | Pedestrian AP/% | Cyclist AP/% | ||||
| LaserNet[ | 2019 | 1-stage | 52.10 | 63.40 | N/A | N/A | N/A | N/A | 60 |
| RangeRCNN[ | 2020 | 2-stage | 75.43 | N/A | N/A | N/A | N/A | N/A | 50 |
| PPC[ | 2021 | 1-stage | 65.20 | 75.50 | N/A | N/A | N/A | N/A | N/A |
| RangeDet[ | 2021 | 1-stage | 75.83 | 74.77 | 64.59 | 67.12 | 68.58 | 61.93 | 80 |
| RSN[ | 2021 | 1-stage | 81.38 | 82.41 | 54.60 | 72.80 | 74.75 | 49.18 | N/A |
| Method | Year | Type | Car AP/% | Pedestrian AP/% | Cyclist AP/% | Speed/ms | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Easy | Mod | Hard | Easy | Mod | Hard | Easy | Mod | Hard | ||||
| Vote3Deep[ | 2017 | 1-stage | 76.79 | 68.24 | 62.23 | 68.39 | 55.37 | 52.59 | 79.92 | 67.88 | 62.98 | 1 100 |
| VoxelNet[ | 2018 | 1-stage | 77.49 | 65.11 | 57.73 | 39.48 | 33.69 | 31.51 | 61.22 | 48.36 | 44.37 | 230 |
| SECOND[ | 2018 | 1-stage | 83.13 | 73.66 | 66.20 | 51.07 | 42.56 | 37.29 | 70.51 | 53.85 | 46.90 | 40 |
| PointPillars[ | 2019 | 1-stage | 82.58 | 74.31 | 68.99 | 51.45 | 41.92 | 38.89 | 77.10 | 58.65 | 51.92 | 16 |
| SA-SSD[ | 2020 | 1-stage | 88.75 | 79.79 | 74.16 | N/A | N/A | N/A | N/A | N/A | N/A | 40 |
| HVNet[ | 2020 | 1-stage | 87.21 | 77.58 | 71.79 | 69.13 | 64.81 | 59.42 | 87.21 | 73.75 | 68.98 | 30 |
| Part-A2[ | 2020 | 2-stage | 87.81 | 78.49 | 73.51 | 53.10 | 43.35 | 40.06 | 79.17 | 63.52 | 56.93 | 80 |
| TANet[ | 2020 | 1-stage | 84.39 | 75.94 | 68.82 | 53.72 | 44.34 | 40.49 | 75.70 | 59.44 | 52.53 | 40 |
| Voxel-FPN[ | 2020 | 1-stage | 85.64 | 76.70 | 69.44 | N/A | N/A | N/A | N/A | N/A | N/A | 20 |
| HotSpotNet[ | 2020 | 1-stage | 87.60 | 78.31 | 73.34 | 53.10 | 45.37 | 41.47 | 82.59 | 65.95 | 59.00 | 40 |
| AFDet[ | 2020 | 1-stage | 85.68 | 75.57 | 69.31 | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| CenterNet3D[ | 2021 | 1-stage | 86.20 | 77.90 | 73.03 | N/A | N/A | N/A | N/A | N/A | N/A | 40 |
| CADNet[ | 2021 | 1-stage | 88.44 | 78.25 | 76.03 | N/A | N/A | N/A | 75.43 | 59.54 | 53.37 | 30 |
| CIA-SSD[ | 2021 | 1-stage | 89.59 | 80.28 | 72.87 | N/A | N/A | N/A | N/A | N/A | N/A | 30 |
| Voxel R-CNN[ | 2021 | 2-stage | 90.90 | 81.62 | 77.06 | N/A | N/A | N/A | N/A | N/A | N/A | 40 |
| PDV[ | 2022 | 2-stage | 90.43 | 81.86 | 77.36 | 47.80 | 40.56 | 38.46 | 83.04 | 67.81 | 60.46 | 100 |
表9 基于点云体素化方法的性能指标(KITTI数据集)
Table 9 Performance of methods based on point cloud voxelization (KITTI dataset)
| Method | Year | Type | Car AP/% | Pedestrian AP/% | Cyclist AP/% | Speed/ms | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Easy | Mod | Hard | Easy | Mod | Hard | Easy | Mod | Hard | ||||
| Vote3Deep[ | 2017 | 1-stage | 76.79 | 68.24 | 62.23 | 68.39 | 55.37 | 52.59 | 79.92 | 67.88 | 62.98 | 1 100 |
| VoxelNet[ | 2018 | 1-stage | 77.49 | 65.11 | 57.73 | 39.48 | 33.69 | 31.51 | 61.22 | 48.36 | 44.37 | 230 |
| SECOND[ | 2018 | 1-stage | 83.13 | 73.66 | 66.20 | 51.07 | 42.56 | 37.29 | 70.51 | 53.85 | 46.90 | 40 |
| PointPillars[ | 2019 | 1-stage | 82.58 | 74.31 | 68.99 | 51.45 | 41.92 | 38.89 | 77.10 | 58.65 | 51.92 | 16 |
| SA-SSD[ | 2020 | 1-stage | 88.75 | 79.79 | 74.16 | N/A | N/A | N/A | N/A | N/A | N/A | 40 |
| HVNet[ | 2020 | 1-stage | 87.21 | 77.58 | 71.79 | 69.13 | 64.81 | 59.42 | 87.21 | 73.75 | 68.98 | 30 |
| Part-A2[ | 2020 | 2-stage | 87.81 | 78.49 | 73.51 | 53.10 | 43.35 | 40.06 | 79.17 | 63.52 | 56.93 | 80 |
| TANet[ | 2020 | 1-stage | 84.39 | 75.94 | 68.82 | 53.72 | 44.34 | 40.49 | 75.70 | 59.44 | 52.53 | 40 |
| Voxel-FPN[ | 2020 | 1-stage | 85.64 | 76.70 | 69.44 | N/A | N/A | N/A | N/A | N/A | N/A | 20 |
| HotSpotNet[ | 2020 | 1-stage | 87.60 | 78.31 | 73.34 | 53.10 | 45.37 | 41.47 | 82.59 | 65.95 | 59.00 | 40 |
| AFDet[ | 2020 | 1-stage | 85.68 | 75.57 | 69.31 | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| CenterNet3D[ | 2021 | 1-stage | 86.20 | 77.90 | 73.03 | N/A | N/A | N/A | N/A | N/A | N/A | 40 |
| CADNet[ | 2021 | 1-stage | 88.44 | 78.25 | 76.03 | N/A | N/A | N/A | 75.43 | 59.54 | 53.37 | 30 |
| CIA-SSD[ | 2021 | 1-stage | 89.59 | 80.28 | 72.87 | N/A | N/A | N/A | N/A | N/A | N/A | 30 |
| Voxel R-CNN[ | 2021 | 2-stage | 90.90 | 81.62 | 77.06 | N/A | N/A | N/A | N/A | N/A | N/A | 40 |
| PDV[ | 2022 | 2-stage | 90.43 | 81.86 | 77.36 | 47.80 | 40.56 | 38.46 | 83.04 | 67.81 | 60.46 | 100 |
| Method | Year | Type | LEVEL_1 | LEVEL_2 | Speed/ms | ||||
|---|---|---|---|---|---|---|---|---|---|
| Car AP/% | Pedestrian AP/% | Cyclist AP/% | Car AP/% | Pedestrian AP/% | Cyclist AP/% | ||||
| SECOND[ | 2018 | 1-stage | 58.50 | 63.90 | 48.60 | 51.60 | 51.10 | 56.00 | N/A |
| PointPillars[ | 2019 | 1-stage | 56.62 | 59.25 | N/A | N/A | N/A | N/A | 40 |
| Part-A2[ | 2020 | 2-stage | 77.05 | 75.24 | 68.60 | 68.47 | 66.18 | 66.13 | N/A |
| AFDet[ | 2020 | 1-stage | 63.69 | N/A | N/A | N/A | N/A | N/A | N/A |
| Voxel R-CNN[ | 2021 | 2-stage | 75.90 | N/A | N/A | 66.59 | N/A | N/A | N/A |
| CenterPoint[ | 2021 | 1-stage | 76.70 | 79.00 | N/A | 68.80 | 71.00 | N/A | 80 |
| PDV[ | 2022 | 2-stage | 76.85 | 74.19 | 68.71 | 69.30 | 65.85 | 66.49 | 340 |
| SST[ | 2022 | 1-stage | 80.99 | 83.30 | 75.69 | 73.08 | 76.93 | 73.22 | 90 |
表10 基于点云体素化方法的性能指标(Waymo数据集)
Table 10 Performance of methods based on point cloud voxelization (Waymo dataset)
| Method | Year | Type | LEVEL_1 | LEVEL_2 | Speed/ms | ||||
|---|---|---|---|---|---|---|---|---|---|
| Car AP/% | Pedestrian AP/% | Cyclist AP/% | Car AP/% | Pedestrian AP/% | Cyclist AP/% | ||||
| SECOND[ | 2018 | 1-stage | 58.50 | 63.90 | 48.60 | 51.60 | 51.10 | 56.00 | N/A |
| PointPillars[ | 2019 | 1-stage | 56.62 | 59.25 | N/A | N/A | N/A | N/A | 40 |
| Part-A2[ | 2020 | 2-stage | 77.05 | 75.24 | 68.60 | 68.47 | 66.18 | 66.13 | N/A |
| AFDet[ | 2020 | 1-stage | 63.69 | N/A | N/A | N/A | N/A | N/A | N/A |
| Voxel R-CNN[ | 2021 | 2-stage | 75.90 | N/A | N/A | 66.59 | N/A | N/A | N/A |
| CenterPoint[ | 2021 | 1-stage | 76.70 | 79.00 | N/A | 68.80 | 71.00 | N/A | 80 |
| PDV[ | 2022 | 2-stage | 76.85 | 74.19 | 68.71 | 69.30 | 65.85 | 66.49 | 340 |
| SST[ | 2022 | 1-stage | 80.99 | 83.30 | 75.69 | 73.08 | 76.93 | 73.22 | 90 |
| Method | Year | Type | Car AP/% | Pedestrian AP/% | Cyclist AP/% | Speed/ms | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Easy | Mod | Hard | Easy | Mod | Hard | Easy | Mod | Hard | ||||
| MV3D[ | 2017 | 2-stage | 74.97 | 63.63 | 54.00 | N/A | N/A | N/A | N/A | N/A | N/A | 360 |
| F-PointNet[ | 2018 | 2-stage | 82.19 | 69.79 | 60.59 | 50.53 | 42.15 | 38.08 | 72.27 | 56.12 | 49.01 | 170 |
| AVOD[ | 2018 | 2-stage | 76.39 | 66.47 | 60.23 | 36.10 | 27.86 | 25.76 | 57.19 | 42.08 | 38.29 | 80 |
| PointFusion[ | 2018 | 2-stage | 77.92 | 63.00 | 53.27 | 33.36 | 28.04 | 23.38 | 49.34 | 29.42 | 26.98 | N/A |
| RoarNet[ | 2018 | 2-stage | 84.25 | 74.29 | 59.78 | N/A | N/A | N/A | N/A | N/A | N/A | 100 |
| MMF[ | 2019 | 2-stage | 88.40 | 77.43 | 70.22 | N/A | N/A | N/A | N/A | N/A | N/A | 80 |
| SCANet[ | 2019 | 2-stage | 76.09 | 66.30 | 58.68 | 50.66 | 41.44 | 36.60 | 67.97 | 53.07 | 50.81 | 90 |
| F-ConvNet[ | 2019 | 2-stage | 87.36 | 76.39 | 66.69 | 52.16 | 43.38 | 38.80 | 81.98 | 65.07 | 56.54 | 470 |
| Fast Point R-CNN[ | 2019 | 2-stage | 85.29 | 77.40 | 70.24 | N/A | N/A | N/A | N/A | N/A | N/A | 60 |
| PV-RCNN[ | 2020 | 2-stage | 90.25 | 81.43 | 76.82 | 52.17 | 43.29 | 40.29 | 78.60 | 63.71 | 57.65 | 80 |
| PI-RCNN[ | 2020 | 2-stage | 84.37 | 74.82 | 70.03 | N/A | N/A | N/A | N/A | N/A | N/A | 100 |
| EPNet[ | 2020 | 1-stage | 89.81 | 79.28 | 74.59 | N/A | N/A | N/A | N/A | N/A | N/A | 100 |
| PVGNet[ | 2021 | 2-stage | 89.94 | 81.81 | 77.09 | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| HVPR[ | 2021 | 1-stage | 86.38 | 77.92 | 73.04 | 53.47 | 43.96 | 40.64 | N/A | N/A | N/A | 20 |
| CAT-Det[ | 2022 | 2-stage | 89.87 | 81.32 | 76.68 | 54.26 | 45.44 | 41.94 | 83.68 | 68.81 | 61.45 | 300 |
表11 基于多模态融合方法的性能指标(KITTI数据集)
Table 11 Performance of methods based on multi-modal fusion (KITTI dataset)
| Method | Year | Type | Car AP/% | Pedestrian AP/% | Cyclist AP/% | Speed/ms | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Easy | Mod | Hard | Easy | Mod | Hard | Easy | Mod | Hard | ||||
| MV3D[ | 2017 | 2-stage | 74.97 | 63.63 | 54.00 | N/A | N/A | N/A | N/A | N/A | N/A | 360 |
| F-PointNet[ | 2018 | 2-stage | 82.19 | 69.79 | 60.59 | 50.53 | 42.15 | 38.08 | 72.27 | 56.12 | 49.01 | 170 |
| AVOD[ | 2018 | 2-stage | 76.39 | 66.47 | 60.23 | 36.10 | 27.86 | 25.76 | 57.19 | 42.08 | 38.29 | 80 |
| PointFusion[ | 2018 | 2-stage | 77.92 | 63.00 | 53.27 | 33.36 | 28.04 | 23.38 | 49.34 | 29.42 | 26.98 | N/A |
| RoarNet[ | 2018 | 2-stage | 84.25 | 74.29 | 59.78 | N/A | N/A | N/A | N/A | N/A | N/A | 100 |
| MMF[ | 2019 | 2-stage | 88.40 | 77.43 | 70.22 | N/A | N/A | N/A | N/A | N/A | N/A | 80 |
| SCANet[ | 2019 | 2-stage | 76.09 | 66.30 | 58.68 | 50.66 | 41.44 | 36.60 | 67.97 | 53.07 | 50.81 | 90 |
| F-ConvNet[ | 2019 | 2-stage | 87.36 | 76.39 | 66.69 | 52.16 | 43.38 | 38.80 | 81.98 | 65.07 | 56.54 | 470 |
| Fast Point R-CNN[ | 2019 | 2-stage | 85.29 | 77.40 | 70.24 | N/A | N/A | N/A | N/A | N/A | N/A | 60 |
| PV-RCNN[ | 2020 | 2-stage | 90.25 | 81.43 | 76.82 | 52.17 | 43.29 | 40.29 | 78.60 | 63.71 | 57.65 | 80 |
| PI-RCNN[ | 2020 | 2-stage | 84.37 | 74.82 | 70.03 | N/A | N/A | N/A | N/A | N/A | N/A | 100 |
| EPNet[ | 2020 | 1-stage | 89.81 | 79.28 | 74.59 | N/A | N/A | N/A | N/A | N/A | N/A | 100 |
| PVGNet[ | 2021 | 2-stage | 89.94 | 81.81 | 77.09 | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| HVPR[ | 2021 | 1-stage | 86.38 | 77.92 | 73.04 | 53.47 | 43.96 | 40.64 | N/A | N/A | N/A | 20 |
| CAT-Det[ | 2022 | 2-stage | 89.87 | 81.32 | 76.68 | 54.26 | 45.44 | 41.94 | 83.68 | 68.81 | 61.45 | 300 |

图7 “汽车”类别性能对比图
Fig.7 Performance comparison diagram of “Car”
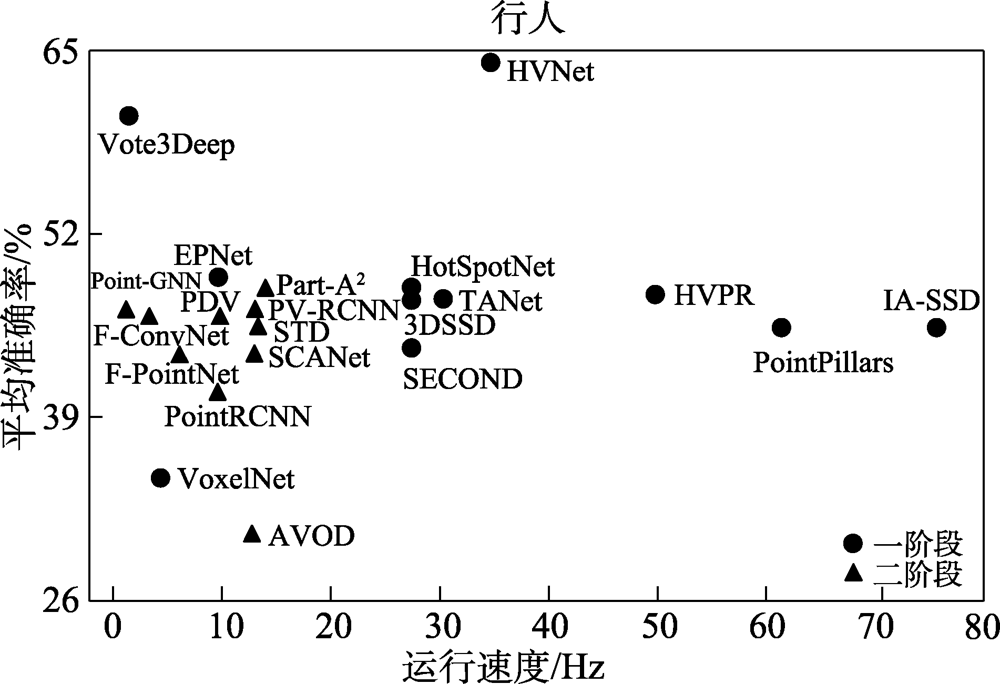
图8 “行人”类别性能对比图
Fig.8 Performance comparison diagram of “Pedestrian”

图9 “自行车”类别性能对比图
Fig.9 Performance comparison diagram of “Cyclist”
| [1] | REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelli-gence, 2016, 39(6): 1137-1149. |
| [2] | REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]// Procee-dings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Pis-cataway: IEEE, 2016: 779-788. |
| [3] | LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector[C]// Proceedings of the 14th European Conference on Computer Vision, Amsterdam, Oct 11-14, 2016. Cham: Springer, 2016: 21-37. |
| [4] |
王鑫鹏, 王晓强, 林浩, 等. 深度学习典型目标检测算法的改进综述[J]. 计算机工程与应用, 2022, 58(6): 42-57.
DOI |
| WANG X P, WANG X Q, LIN H, et al. Review on improve-ment of typical object detection algorithms in deep learning[J]. Computer Engineering and Applications, 2022, 58(6): 42-57. | |
| [5] |
邱起璐, 赵杰煜, 陈瑜. 面向三维目标的矢量型卷积网络[J]. 模式识别与人工智能, 2022, 35(3): 271-282.
DOI |
| QIU Q L, ZHAO J Y, CHEN Y. A convolutional vector net-work for 3D mesh object Recognition[J]. Pattern Recog-nition and Artificial Intelligence, 2022, 35(3): 271-282. | |
| [6] | IOANNIDOU A, CHATZILARI E, NIKOLOPOULOS S, et al. Deep learning advances in computer vision with 3D data: a survey[J]. ACM Computing Surveys, 2017, 50(2): 1-38. |
| [7] |
LI Y, MA L, ZHONG Z, et al. Deep learning for LiDAR point clouds in autonomous driving: a review[J]. IEEE Transactions on Neural Networks and Learning Systems, 2020, 32(8): 3412-3432.
DOI URL |
| [8] | DING M, HUO Y, YI H, et al. Learning depth-guided con-volutions for monocular 3D object detection[C]// Procee-dings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscata-way: IEEE, 2020: 11669-11678. |
| [9] | MA X, WANG Z, LI H, et al. Accurate monocular 3D object detection via color-embedded 3D reconstruction for auto-nomous driving[C]// Proceedings of the 2019 International Conference on Pattern Recognition, Seoul, Oct 27-Nov 2, 2019. Piscataway: IEEE, 2019: 6850-6859. |
| [10] | QI C R, SU H, MO K, et al. PointNet: deep learning on point sets for 3D classification and segmentation[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, July 21-26, 2017. Piscata-way: IEEE, 2017: 77-85. |
| [11] | SHI S, WANG X, LI H. PointRCNN: 3D object proposal generation and detection from point cloud[C]// Proceedings of the 2019 IEEE Conference on Computer Vision and Pat-tern Recognition, Long Beach, Jun 15-20, 2019. Piscataway: IEEE, 2019: 770-779. |
| [12] | YANG Z, SUN Y, LIU S, et al. 3DSSD: point-based 3D sin-gle stage object detector[C]// Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 11037-11045. |
| [13] | LI B. 3D fully convolutional network for vehicle detection in point cloud[C]// Proceeding of the 2017 IEEE Interna-tional Conference on Intelligent Robots and Systems, Van-couver, Sep 24-28, 2017. Piscataway: IEEE, 2017: 1513-1518. |
| [14] |
ZENG Y, HU Y, LIU S, et al. RT3D: real-time 3-D vehicle detection in LiDAR point cloud for autonomous driving[J]. IEEE Robotics and Automation Letters, 2018, 3(4): 3434-3440.
DOI URL |
| [15] | ZHOU Y, TUZEL O. VoxelNet: end-to-end learning for point cloud based 3D object detection[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-23, 2018. Piscataway: IEEE, 2018: 4490-4499. |
| [16] |
YAN Y, MAO Y, LI B. SECOND: sparsely embedded con-volutional detection[J]. Sensors, 2018, 18(10): 3337-3353.
DOI URL |
| [17] | SINDAGI V A, ZHOU Y, TUZEL O. MVX-Net: multi-modal VoxelNet for 3D object detection[C]// Proceedings of the 2019 International Conference on Robotics and Automa-tion, Montreal, May 20-24, 2019. Piscataway: IEEE, 2019: 7276-7282. |
| [18] | CHEN X, MA H, WAN J, et al. Multi-view 3D object detec-tion network for autonomous driving[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Piscataway: IEEE, 2017: 1907-1915. |
| [19] |
GUO Y, WANG H, HU Q, et al. Deep learning for 3D point clouds: a survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 43(12): 4338-4364.
DOI URL |
| [20] |
张鹏, 宋一凡, 宗立波, 等. 3D目标检测进展综述[J]. 计算机科学, 2020, 47(4): 94-102.
DOI |
|
ZHANG P, SONG Y F, ZONG L B, et al. Advances in 3D object detection: a brief survey[J]. Computer Science, 2020, 47(4): 94-102.
DOI |
|
| [21] |
肖雨晴, 杨慧敏. 目标检测算法在交通场景中应用综述[J]. 计算机工程与应用, 2021, 57(6): 30-41.
DOI |
| XIAO Y Q, YANG H M. Research on application of object detection algorithm in traffic scene[J]. Computer Enginee-ring and Applications, 2021, 57(6): 30-41. | |
| [22] | ARNOLD E, AL-JARRAH O Y, DIANATI M, et al. A sur-vey on 3D object detection methods for autonomous dri-ving applications[J]. IEEE Transactions on Intelligent Tran-sportation Systems, 2019, 20(10): 3782-3795. |
| [23] | QI C R, LI Y, SU H, et al. PointNet++: deep hierarchical feature learning on point sets in a metric space[C]// Procee-dings of the Annual Conference on Neural Information Processing Systems, Long Beach, Dec 4-9, 2017. Red Hook: Curran Associates, 2017: 5105-5114. |
| [24] | YANG Z, SUN Y, LIU S, et al. STD: sparse-to-dense 3D object detector for point cloud[C]// Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recog-nition, Long Beach, Jun 15-20, 2019. Piscataway: IEEE, 2019: 1951-1960. |
| [25] | LI Z, WANG F, WANG N. LiDAR R-CNN: an efficient and universal 3D object detector[C]// Proceedings of the 2021 IEEE Conference on Computer Vision and Pattern Recog-nition, Nashville, Jun 20-25, 2021. Piscataway: IEEE, 2021: 7542-7551. |
| [26] | CHEN C, CHEN Z, ZHANG J, et al. SASA: semantics-augmented set abstraction for point-based 3D object detec-tion[J]. arXiv:2201.01976, 2022. |
| [27] | ZHANG Y, HU Q, XU G, et al. Not all points are equal: learning highly efficient point-based detectors for 3D LiDAR point clouds[C]// Proceedings of the 2022 IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, Jun 19-24, 2022. Piscataway: IEEE, 2022: 18953-18962. |
| [28] | ZHENG W, TANG W, JIANG L, et al. SE-SSD: self-ensem-bling single-stage object detector from point cloud[C]// Pro-ceedings of the 2021 IEEE Conference on Computer Vi-sion and Pattern Recognition, Nashville, June 20-25, 2021. Piscataway: IEEE, 2021: 14494-14503. |
| [29] | TARVAINEN A, VALPOLA H. Mean teachers are better role models: weight-averaged consistency targets improve semi-supervised deep learning results[C]// Proceedings of the Annual Conference on Neural Information Processing Sys-tems, Long Beach, Dec 4-9, 2017. Red Hook: Curran Asso-ciates, 2017: 1195-1204. |
| [30] | HE C, ZENG H, HUANG J, et al. Structure aware single-stage 3D object detection from point cloud[C]// Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 11873-11882. |
| [31] | LIU Z, ZHAO X, HUANG T, et al. TANet: robust 3D ob-ject detection from point clouds with triple attention[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence, the 32nd Innovative Applications of Artificial Intelligence Conference, the 10th AAAI Symposium on Educational Advances in Artificial Intelligence, New York, Feb 7-12, 2020. Menlo Park: AAAI, 2020: 11677-11684. |
| [32] | SHI S, GUO C, JIANG L, et al. PV-RCNN: point-voxel fea-ture set abstraction for 3D object detection[C]// Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 10529-10538. |
| [33] | SHI S, WANG Z, SHI J, et al. From points to parts: 3D ob-ject detection from point cloud with part-aware and part-aggregation network[J]. IEEE Transactions on Pattern Ana-lysis and Machine Intelligence, 2020, 43(8): 2647-2664. |
| [34] | SHI W, RAJKUMAR R. Point-GNN: graph neural network for 3D object detection in a point cloud[C]// Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 1711-1719. |
| [35] | ZHANG Y, HUANG D, WANG Y. PC-RGNN: point cloud completion and graph neural network for 3D object detec-tion[J]. arXiv:2012.10412, 2020. |
| [36] | ZHU L, XIE Z, LIU L, et al. IoU-uniform R-CNN: brea-king through the limitations of RPN[J]. arXiv:1912.05190, 2019. |
| [37] | LI J, LUO S, ZHU Z, et al. 3D IoU-Net: IoU guided 3D object detector for point clouds[J]. arXiv:2004.04962, 2020. |
| [38] | GEIGER A, LENZ P, URTASUN R. Are we ready for au-tonomous driving? the KITTI vision benchmark suite[C]// Proceedings of the 2012 IEEE Conference on Computer Vi-sion and Pattern Recognition, Providence, Jun 16-21, 2012. Piscataway: IEEE, 2012: 3354-3361. |
| [39] | ZHOU D, FANG J, SONG X, et al. Joint 3D instance seg-mentation and object detection for autonomous driving[C]// Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 1839-1849. |
| [40] | MENG Q, WANG W, ZHOU T, et al. Weakly supervised 3D object detection from LiDAR point cloud[C]// LNCS 12358: Proceedings of the 16th European Conference on Computer Vision, Glasgow, Aug 23-28, 2020. Cham: Springer, 2020: 515-531. |
| [41] | QIN Z, WANG J, LU Y. Weakly supervised 3D object detec-tion from point clouds[C]// Proceedings of the 28th ACM International Conference on Multimedia, Seattle, Oct 12-16, 2020. New York: ACM, 2020: 4144-4152. |
| [42] | WEI Y, SU S, LU J, et al. FGR: frustum-aware geometric rea-soning for weakly supervised 3D vehicle detection[C]// Pro-ceedings of the 2021 IEEE International Conference on Robotics and Automation, Xi’an, May 30-Jun 5, 2021. Pis-cataway: IEEE, 2021: 4348-4354. |
| [43] | XU X, WANG Y, ZHENG Y, et al. Back to reality: weakly-supervised 3D object detection with shape-guided label enhancement[C]// Proceedings of the 2022 IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, Jun 19-24, 2022. Piscataway: IEEE, 2022: 8438-8447. |
| [44] | LI B, ZHANG T, XIA T. Vehicle detection from 3D LiDAR using fully convolutional network[J]. arXiv:1608.07916, 2016. |
| [45] | YANG B, LUO W, URTASUN R. PIXOR: real-time 3D object detection from point clouds[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-23, 2018. Piscataway: IEEE, 2018: 7652-7660. |
| [46] | MEYER G P, LADDHA A, KEE E, et al. LaserNet: an efficient probabilistic 3D object detector for autonomous driving[C]// Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, Jun 15-20, 2019. Piscataway: IEEE, 2019: 12677-12686. |
| [47] | LIANG Z, ZHANG M, ZHANG Z, et al. RangeRCNN: to-wards fast and accurate 3D object detection with range image representation[J]. arXiv:2009.00206, 2020. |
| [48] | CHAI Y, SUN P, NGIAM J, et al. To the point: efficient 3D object detection in the range image with graph convolution kernels[C]// Proceedings of the 2021 IEEE Conference on Computer Vision and Pattern Recognition, Nashville, Jun 20-25, 2021. Piscataway: IEEE, 2021: 16000-16009. |
| [49] | LANG A H, VORA S, CAESAR H, et al. PointPillars: fast encoders for object detection from point clouds[C]// Pro-ceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, Jun 15-20, 2019. Pis-cataway: IEEE, 2019: 12697-12705. |
| [50] | FAN L, XIONG X, WANG F, et al. RangeDet: in defense of range view for LiDAR-based 3D object detection[C]// Proceedings of the 2021 IEEE Conference on Computer Vision and Pattern Recognition, Nashville, Jun 20-25, 2021. Piscataway: IEEE, 2021: 2918-2927. |
| [51] | SUN P, WANG W, CHAI Y, et al. RSN: range sparse net for efficient, accurate LiDAR 3D object detection[C]// Procee-dings of the 2021 IEEE Conference on Computer Vision and Pattern Recognition, Nashville, Jun 20-25, 2021. Pis-cataway: IEEE, 2021: 5725-5734. |
| [52] | DUAN K, BAI S, XIE L, et al. CenterNet: keypoint triplets for object detection[C]// Proceedings of the 2019 IEEE Con-ference on Computer Vision and Pattern Recognition, Long Beach, Jun 15-20, 2019. Piscataway: IEEE, 2019: 6569-6578. |
| [53] | TIAN Z, CHU X, WANG X, et al. Fully convolutional one-stage 3D object detection on LiDAR range images[J]. arXiv:2205.13764, 2022. |
| [54] | ENGELCKE M, RAO D, WANG D Z, et al. Vote3Deep: fast object detection in 3D point clouds using efficient convolu-tional neural networks[C]// Proceedings of the 2017 IEEE International Conference on Robotics and Automation, Sin-gapore, May 29-Jun 3, 2017. Piscataway: IEEE, 2017: 1355-1361. |
| [55] | WANG D Z, POSNER I. Voting for voting in online point cloud object detection[C]// Proceedings of the Robotics: Science and Systems, Rome, Jul 13-17, 2015. Los Angeles: SAGE Publishing, 2015: 10-15. |
| [56] | TIAN Y, HUANG L, LI X, et al. Context-aware dynamic feature extraction for 3D object detection in point clouds[J]. arXiv:1912.04775, 2019. |
| [57] | ZHU X, MA Y, WANG T, et al. SSN:shape signature net-works for multi-class object detection from point clouds[C]// LNCS 12370: Proceedings of the 16th European Con-ference on Computer Vision, Glasgow, Aug 23-28, 2020. Cham: Springer, 2020: 581-597. |
| [58] | CAESAR H, BANKITI V, LANG A H, et al. nuScenes: a multimodal dataset for autonomous driving[C]// Proceedings of the 2020 IEEE Conference on Computer Vision and Pat-tern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 11621-11631. |
| [59] | CHEN Q, SUN L, WANG Z, et al. Object as hotspots: an anchor-free 3D object detection approach via firing of hot-spots[C]// Proceedings of the 16th European Conference on Computer Vision, Glasgow, Aug 23-28, 2020. Cham: Sp-ringer, 2020: 68-84. |
| [60] | GE R, DING Z, HU Y, et al. AFDet: anchor free one stage 3D object detection[J]. arXiv:2006.12671, 2020. |
| [61] | YIN T, ZHOU X, KRAHENBUHL P. Center-based 3D object detection and tracking[C]// Proceedings of the 2021 IEEE Conference on Computer Vision and Pattern Recog-nition, Nashville, Jun 20-25, 2021. Piscataway: IEEE, 2021: 11784-11793. |
| [62] | SUN P, KRETZSCHMAR H, DOTIWALLA X, et al. Scala-bility in perception for autonomous driving: Waymo open dataset[C]// Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 2446-2454. |
| [63] | WANG G, TIAN B, AI Y, et al. CenterNet3D: an anchor free object detector for autonomous driving[J]. arXiv:2007.07214, 2020. |
| [64] |
KUANG H, WANG B, AN J, et al. Voxel-FPN: multi-scale voxel feature aggregation for 3D object detection from LiDAR point clouds[J]. Sensors, 2020, 20(3): 704-721.
DOI URL |
| [65] | HU J S K, KUAI T, WASLANDER S L. Point density-aware voxels for LiDAR 3D object detection[C]// Proceedings of the 2022 IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, Jun 19-24, 2022. Piscataway: IEEE, 2022: 8469-8478. |
| [66] | YE M, XU S, CAO T. HVNet: hybrid voxel network for LiDAR based 3D object detection[C]// Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Re-cognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 1631-1640. |
| [67] | ZHENG W, TANG W, CHEN S, et al. CIA-SSD: confident IoU-aware single-stage object detector from point cloud[C]// Proceedings of the 35th AAAI Conference on Artifi-cial Intelligence, the 33rd Conference on Innovative Applica-tions of Artificial Intelligence, the 11th Symposium on Educational Advances in Artificial Intelligence, Feb 2-9, 2021. Menlo Park: AAAI, 2021: 3555-3562. |
| [68] | FAN L, PANG Z, ZHANG T, et al. Embracing single stride 3D object detector with sparse transformer[C]// Proceedings of the 2022 IEEE Conference on Computer Vision and Pat-tern Recognition, New Orleans, Jun 19-24, 2022. Piscata-way: IEEE, 2022: 8458-8468. |
| [69] | KU J, MOZIFIAN M, LEE J, et al. Joint 3D proposal gene-ration and object detection from view aggregation[C]// Pro-ceedings of the 2018 IEEE International Conference on Intelligent Robots and Systems, Madrid, Oct 1-5, 2018. Pis-cataway: IEEE, 2018: 1-8. |
| [70] | XU D, ANGUELOV D, JAIN A. PointFusion: deep sensor fusion for 3D bounding box estimation[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-23, 2018. Piscataway: IEEE, 2018: 244-253. |
| [71] | QI C R, LIU W, WU C, et al. Frustum PointNets for 3D object detection from RGB-D data[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-23, 2018. Piscataway: IEEE, 2018: 918-927. |
| [72] | WANG Z, JIA K. Frustum ConvNet: sliding frustums to agg-regate local point-wise features for amodal 3D object detec-tion[C]// Proceedings of the 2019 IEEE International Confe-rence on Intelligent Robots and Systems, Macau, China, Nov 3-8, 2019. Piscataway: IEEE, 2019: 1742-1749. |
| [73] | LIANG M, YANG B, WANG S, et al. Deep continuous fu-sion for multi-sensor 3D object detection[C]// LNCS 11220: Proceedings of the 15th European Conference on Computer Vision, Munich, Sep 8-14, 2018. Cham: Springer, 2018: 663-678. |
| [74] | BOSCAINI D, MASCI J, et al. Learning shape correspon-dence with anisotropic convolutional neural networks[C]// Proceedings of the Annual Conference on Neural Informa-tion Processing Systems, Barcelona, Dec 5-10, 2016. Red Hook: Curran Associates, 2016: 3189-3197. |
| [75] | XIE L, XIANG C, YU Z, et al. PI-RCNN: an efficient multi-sensor 3D object detector with point-based attentive cont-conv fusion module[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence, the 32nd Innovative Applications of Artificial Intelligence Conference, the 10th AAAI Symposium on Educational Advances in Artificial In-telligence, New York, Feb 7-12, 2020. Menlo Park: AAAI, 2020: 12460-12467. |
| [76] | HUANG T, LIU Z, CHEN X, et al. EPNet: enhancing point features with image semantics for 3D object detection[C]// LNCS 12360: Proceedings of the 16th European Conferen-ce on Computer Vision, Glasgow, Aug 23-28, 2020. Cham: Springer, 2020: 35-52. |
| [77] | VORA S, LANG A H, HELOU B, et al. PointPainting: sequential fusion for 3D object detection[C]// Proceedings of the 2020 IEEE Conference on Computer Vision and Pat-tern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 4604-4612. |
| [78] | WANG C, MA C, ZHU M, et al. PointAugmenting: cross-modal augmentation for 3D object detection[C]// Procee-dings of the 2021 IEEE Conference on Computer Vision and Pattern Recognition, Nashville, Jun 20-25, 2021. Pisca-taway: IEEE, 2021: 11794-11803. |
| [79] | ZHANG Y, CHEN J, HUANG D. CAT-Det: contrastively augmented transformer for multi-modal 3D object detection[C]// Proceedings of the 2022 IEEE Conference on Com-puter Vision and Pattern Recognition, New Orleans, Jun 19-24, 2022. Piscataway: IEEE, 2022: 908-917. |
| [80] | GU J, XIANG Z, ZHAO P, et al. CVFNet: real-time 3D ob-ject detection by learning cross view features[J]. arXiv:2203.06585, 2022. |
| [81] | ZHAO X, LIU Z, HU R, et al. 3D object detection using scale invariant and feature reweighting networks[C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence, the 31st Innovative Applications of Artificial Intelligence Con-ference, the 9th AAAI Symposium on Educational Advan-ces in Artificial Intelligence, Honolulu, Jan 27-Feb 1, 2019. Menlo Park: AAAI, 2019: 9267-9274. |
| [82] | LU H, CHEN X, ZHANG G, et al. SCANet: spatial-channel attention network for 3D object detection[C]// Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing, Brighton, May 12-17, 2019. Piscataway: IEEE, 2019: 1992-1996. |
| [83] | LIANG M, YANG B, CHEN Y, et al. Multi-task multi-sensor fusion for 3D object detection[C]// Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recog-nition, Long Beach, Jun 15-20, 2019. Piscataway: IEEE, 2019: 7345-7353. |
| [84] | ZHOU Y, SUN P, ZHANG Y, et al. End-to-end multi-view fusion for 3D object detection in LiDAR point clouds[C]// Proceedings of the 2020 Conference on Robot Learning, Nov 16-18, 2020: 923-932. |
| [85] | WANG Y, FATHI A, KUNDU A, et al. Pillar-based object detection for autonomous driving[C]// LNCS 12367: Procee-dings of the 16th European Conference on Computer Vision, Glasgow, Aug 23-28, 2020. Cham: Springer, 2020: 18-34. |
| [86] | FAZLALI H, XU Y, REN Y, et al. A versatile multi-view framework for LiDAR-based 3D object detection with gui-dance from panoptic segmentation[C]// Proceedings of the 2022 IEEE Conference on Computer Vision and Pattern Re-cognition, New Orleans, Jun 19-24, 2022. Piscataway: IEEE, 2022: 17192-17201. |
| [87] | NOH J, LEE S, HAM B. HVPR: hybrid voxel-point repre-sentation for single-stage 3D object detection[C]// Procee-dings of the 2021 IEEE Conference on Computer Vision and Pattern Recognition, Nashville, Jun 20-25, 2021. Pisca-taway: IEEE, 2021: 14605-14614. |
| [88] | MIAO Z, CHEN J, PAN H, et al. PVGNet: a bottom-up one-stage 3D object detector with integrated multi-level features[C]// Proceedings of the 2021 IEEE Conference on Com-puter Vision and Pattern Recognition, Nashville, Jun 20-25, 2021. Piscataway: IEEE, 2021: 3279-3288. |
| [89] |
QIAN R, LAI X, LI X. BADet: boundary-aware 3D object detection from point clouds[J]. Pattern Recognition, 2022, 125: 108524.
DOI URL |
| [90] | SIMONELLI A, BULO S R, PORZI L, et al. Disentangling monocular 3D object detection[C]// Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recogni-tion, Long Beach, Jun 15-20, 2019. Piscataway: IEEE, 2019: 1991-1999. |
| [91] | LIANG Z, ZHANG Z, ZHANG M, et al. RangeIoUDet: range image based real-time 3D object detector optimized by intersection over union[C]// Proceedings of the 2021 IEEE Conference on Computer Vision and Pattern Recogni-tion, Nashville, Jun 20-25, 2021. Piscataway: IEEE, 2021: 7140-7149. |
| [92] | YANG B, LIANG M, URTASUN R. HDNet: exploiting HD maps for 3D object detection[C]// Proceedings of the Conference on Robot Learning, Zürich, Oct 29-31, 2018. New York: PMLR, 2018: 146-155. |
| [93] | DENG J, SHI S, LI P, et al. Voxel R-CNN: towards high performance voxel-based 3D object detection[C]// Procee-dings of the 35th AAAI Conference on Artificial Intelligence, the 33rd Conference on Innovative Applications of Artifi-cial Intelligence, the 11th Symposium on Educational Ad-vances in Artificial Intelligence, Feb 2-9, 2021. Menlo Park: AAAI, 2021: 1201-1209. |
| [94] | SHIN K, KWON Y P, TOMIZUKA M. RoarNet: a robust 3D object detection based on region approximation refine-ment[C]// Proceedings of the 2019 IEEE Intelligent Vehicles Symposium, Paris, Jun 9-12, 2019. Piscataway: IEEE, 2019: 2510-2515. |
| [95] | CHEN Y, LIU S, SHEN X, et al. Fast point R-CNN[C]// Proceedings of the 2019 IEEE Conference on Computer Vi-sion and Pattern Recognition, Long Beach, Jun 15-20, 2019. Piscataway: IEEE, 2019: 9775-9784. |
| [1] | 张璐, 芦天亮, 杜彦辉. 人脸视频深度伪造检测方法综述[J]. 计算机科学与探索, 2023, 17(1): 1-26. |
| [2] | 王仕宸, 黄凯, 陈志刚, 张文东. 深度学习的三维人体姿态估计综述[J]. 计算机科学与探索, 2023, 17(1): 74-87. |
| [3] | 梁佳利, 华保健, 吕雅帅, 苏振宇. 面向深度学习算子的循环不变式外提算法[J]. 计算机科学与探索, 2023, 17(1): 127-139. |
| [4] | 王剑哲, 吴秦. 坐标注意力特征金字塔的显著性目标检测算法[J]. 计算机科学与探索, 2023, 17(1): 154-165. |
| [5] | 张祥平, 刘建勋. 基于深度学习的代码表征及其应用综述[J]. 计算机科学与探索, 2022, 16(9): 2011-2029. |
| [6] | 李冬梅, 罗斯斯, 张小平, 许福. 命名实体识别方法研究综述[J]. 计算机科学与探索, 2022, 16(9): 1954-1968. |
| [7] | 任宁, 付岩, 吴艳霞, 梁鹏举, 韩希. 深度学习应用于目标检测中失衡问题研究综述[J]. 计算机科学与探索, 2022, 16(9): 1933-1953. |
| [8] | 杨才东, 李承阳, 李忠博, 谢永强, 孙方伟, 齐锦. 深度学习的图像超分辨率重建技术综述[J]. 计算机科学与探索, 2022, 16(9): 1990-2010. |
| [9] | 吕晓琦, 纪科, 陈贞翔, 孙润元, 马坤, 邬俊, 李浥东. 结合注意力与循环神经网络的专家推荐算法[J]. 计算机科学与探索, 2022, 16(9): 2068-2077. |
| [10] | 安凤平, 李晓薇, 曹翔. 权重初始化-滑动窗口CNN的医学图像分类[J]. 计算机科学与探索, 2022, 16(8): 1885-1897. |
| [11] | 曾凡智, 许露倩, 周燕, 周月霞, 廖俊玮. 面向智慧教育的知识追踪模型研究综述[J]. 计算机科学与探索, 2022, 16(8): 1742-1763. |
| [12] | 刘艺, 李蒙蒙, 郑奇斌, 秦伟, 任小广. 视频目标跟踪算法综述[J]. 计算机科学与探索, 2022, 16(7): 1504-1515. |
| [13] | 赵小明, 杨轶娇, 张石清. 面向深度学习的多模态情感识别研究进展[J]. 计算机科学与探索, 2022, 16(7): 1479-1503. |
| [14] | 夏鸿斌, 肖奕飞, 刘渊. 融合自注意力机制的长文本生成对抗网络模型[J]. 计算机科学与探索, 2022, 16(7): 1603-1610. |
| [15] | 孙方伟, 李承阳, 谢永强, 李忠博, 杨才东, 齐锦. 深度学习应用于遮挡目标检测算法综述[J]. 计算机科学与探索, 2022, 16(6): 1243-1259. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||