
计算机科学与探索 ›› 2022, Vol. 16 ›› Issue (12): 2734-2751.DOI: 10.3778/j.issn.1673-9418.2206078
史彩娟1,2,+( ), 任弼娟1,2, 王子雯1,2, 闫巾玮1,2, 石泽1,2
), 任弼娟1,2, 王子雯1,2, 闫巾玮1,2, 石泽1,2
收稿日期:2022-06-20
修回日期:2022-08-29
出版日期:2022-12-01
发布日期:2022-12-16
通讯作者:
+E-mail: scj-blue@163.com作者简介:史彩娟(1977—),女,河北唐山人,博士,教授,硕士生导师,CCF会员,主要研究方向为图像处理、计算机视觉、机器学习等。基金资助:
SHI Caijuan1,2,+(), REN Bijuan1,2, WANG Ziwen1,2, YAN Jinwei1,2, SHI Ze1,2
Received:2022-06-20
Revised:2022-08-29
Online:2022-12-01
Published:2022-12-16
About author:SHI Caijuan, born in 1977, Ph.D., professor, M.S. supervisor, member of CCF. Her research interests include image processing, computer vision, machine learning, etc.Supported by:摘要:
基于深度学习的伪装目标检测(COD)是一项新兴的视觉检测任务,其目的是精确且高效地检测出“完美”嵌入周围环境中的伪装目标。目前大多数工作旨在构建不同的伪装目标检测模型,对现有模型的归纳总结及深入分析的综述性工作还很少。因此,对基于深度学习的伪装目标检测模型进行了全面分析和总结,并探讨了伪装目标检测未来的研究方向。首先对基于深度学习的23个伪装目标检测模型分别从由粗到细策略、多任务学习策略、置信感知学习策略、多源信息融合策略以及基于Transformer共5个角度进行了分类介绍,并对每种策略的优劣进行了深入分析;其次介绍了伪装目标检测广泛使用的4个数据集以及4种评估准则;然后对现有基于深度学习的伪装目标检测模型在4个数据集上进行了性能比较,包括定量比较、视觉比较和效率分析,并分析了这些模型对不同类型目标的检测效果;接着简单介绍了伪装目标检测在医学、工业、农业、军事、艺术等领域的应用;最后指出了现有方法在复杂场景、多尺度目标、实时性、实际应用需求、多模态等方面存在的不足和挑战,并探讨了伪装目标检测未来的研究方向。
中图分类号:
史彩娟, 任弼娟, 王子雯, 闫巾玮, 石泽. 基于深度学习的伪装目标检测综述[J]. 计算机科学与探索, 2022, 16(12): 2734-2751.
SHI Caijuan, REN Bijuan, WANG Ziwen, YAN Jinwei, SHI Ze. Survey of Camouflaged Object Detection Based on Deep Learning[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(12): 2734-2751.

图1 从4个COD数据集中选取的多种类型伪装目标
Fig.1 Various types of camouflaged objects selected from 4 COD datasets

图2 基于深度学习的伪装目标检测方法导图
Fig.2 Map of camouflaged object detection methods based on deep learning

图3 不同特征融合策略的示意图
Fig.3 Different feature fusion strategies

图4 具有边缘模糊性和纹理欺骗性的伪装目标
Fig.4 Camouflaged objects with edge fuzziness and texture deception

图5 DGNet中使用的四种监督标签
Fig.5 Four types of supervision labels widely used in DGNet
| 策略 | 方法 | 描述 | 优点 | 缺点 |
|---|---|---|---|---|
| 由粗到 细策略 | 特征融合 (SINet[ | 构建多尺度特征连接器如PDC[ | 能在不增加额外线索的前提下充分利用多层特征中有用的多尺度信息 | 容易造成计算冗余,且目标与背景相似的区域并未被关注 |
| 分心挖掘 (PFNet[ SINetV2[ | 特征相减以反向注意的形式促使模型关注伪装目标中不易被检测的部分 | 以简单的减法运算达到最直接的细化目的,使得模型参数量少,运行速度快 | 可利用的补充信息较少 | |
| 边缘线索 (BASNet[ ERRNet[ | 以显式提取边缘信息或隐式增加边缘感知损失的方式关注边界信息,进行目标边界细化 | 能获取精细的边缘细节 | 使用边缘监督学习到的特征响应通常会引入噪声,尤其是复杂场景下 | |
| 多任务学 习策略 | 定位/排序+分割 (LSR[ | 分割之前找到伪装目标所在位置;对分割任务的结果按区分难易度进行排名 | 首次对伪装程度进行探索,能为人类观察伪装目标的难易程度提供一定指引 | 基于候选区域先检测再分割,容易产生冗余的分割图数量,使得分割任务学习较慢 |
| 分类+分割 (ANet[ | 在分割之前对图像中的像素进行分类以检测是否有伪装目标的存在 | 让模型聚焦于包含伪装目标的区域,能一定程度上排除非伪装和背景的干扰 | 图像中非伪装的显著目标极具迷惑性,因此分类流可能会产生错误判断导致分割失败 | |
| 仿生攻击+分割 (MirrorNet[ | 检测翻转图像中的伪装特征作为仿生攻击流辅助原始图像的分割 | 促使模型关注纹理和形状特征,能一定程度上增强模型的抗干扰能力 | 图像翻转并不会改变低辨识度的纹理或者边缘,因此仅使用翻转图像作为补充得到的性能增益十分有限 | |
| 纹理检测+分割 (TANet[ TINet[ | 设计独特的纹理标签,并使用矩阵方法、卷积方法等来提取纹理特征 | 基于纹理特征的旋转不变性等特点,使得模型具有较强的抗噪能力 | 由于伪装目标存在纹理欺骗性,仅关注纹理,会导致检测性能有限 | |
| 边缘检测+分割 (MGL[ | 将边缘检测作为与分割并行的一大任务,来明确建模边缘并推理两个任务的互补信息 | 使用类型化函数明确推理两个任务间的互补信息 | 提取的信息种类繁多,很难保证每次提取的信息都是有效的,而且基于图推理的模型使得模型运行速度较慢 | |
| 置信感知 学习策略 | 对抗训练策略 (JCSOD[ | 引入对抗训练来显式建模由完全标注伪装目标的困难带来的不确定性 | 显式生成网络预测的置信度,为模型预测提供可解释性 | 包含对两种任务的学习,使得模型参数量巨大,推理速度慢 |
| 动态监督策略 (CANet[ | 利用预测图和真实标签的L1距离作为动态监督关注由硬像素引起的不确定性 | 能够引导网络重点学习预测不确定的区域上,模型的鲁棒性较高 | 得到的特征通常响应于伪装目标的稀疏边缘,因此容易在特征学习过程中引入噪声 | |
| 正则化约束策略 (Zoom-Net[ | 在目标检测损失中增加了模糊预测的正则化惩罚项,来迫使模型关注不确定像素 | 以简单的计算降低模糊背景带来的干扰 | 多尺度图像的输入,会增加内存占用量和模型运算量 | |
| 多源信息 融合策略 | RGB-D (DCNet[ | 利用现有的深度估计方法生成伪装深度图,并与RGB数据融合以实现RGB-D的COD | 深度图中包含丰富的空间信息,可以作为有效的补充信息提升伪装目标检测性能 | 提取的深度信息不够准确;没有充分考虑到两种模态信息之间的互补性和差异性 |
| RGB+频域 (FDNet[ | 使用离线离散余弦变换引入频域信息,同时用特征对齐融合RGB域和频域信息 | 频域信息的引入以及对所有频带系数的增强,使得模型可以提取判别性信息 | 使用离散余弦提取频域信息可能会产生方块效应,使得模型计算量增加 | |
| Transformer 策略 | 以Transformer为主干 (T2Net[ | 使用密集Transformer主干进行伪装目标检测,并使用深监督等策略补充空间信息 | 长距离特性使模型捕获全局信息的能力更强,对大目标有着较好的检测效果 | 忽略了局部信息的获取,并且模型参数量巨大,训练耗时 |
| Transformer+CNN (UGTR[ | 利用CNN生成的概率表示模型学习Transformer框架下伪装目标的不确定性 | 不确定性引导的上下文推理使得模型更多关注不确定区域 | 仅对不确定性建模,使得模型不确定响应区域总分布在弱边界和不可区分的纹理区域,学习过程中容易引入噪声 |
表1 不同类型伪装目标检测方法分析比较
Table 1 Analysis and comparison of different types of camouflaged object detection methods
| 策略 | 方法 | 描述 | 优点 | 缺点 |
|---|---|---|---|---|
| 由粗到 细策略 | 特征融合 (SINet[ | 构建多尺度特征连接器如PDC[ | 能在不增加额外线索的前提下充分利用多层特征中有用的多尺度信息 | 容易造成计算冗余,且目标与背景相似的区域并未被关注 |
| 分心挖掘 (PFNet[ SINetV2[ | 特征相减以反向注意的形式促使模型关注伪装目标中不易被检测的部分 | 以简单的减法运算达到最直接的细化目的,使得模型参数量少,运行速度快 | 可利用的补充信息较少 | |
| 边缘线索 (BASNet[ ERRNet[ | 以显式提取边缘信息或隐式增加边缘感知损失的方式关注边界信息,进行目标边界细化 | 能获取精细的边缘细节 | 使用边缘监督学习到的特征响应通常会引入噪声,尤其是复杂场景下 | |
| 多任务学 习策略 | 定位/排序+分割 (LSR[ | 分割之前找到伪装目标所在位置;对分割任务的结果按区分难易度进行排名 | 首次对伪装程度进行探索,能为人类观察伪装目标的难易程度提供一定指引 | 基于候选区域先检测再分割,容易产生冗余的分割图数量,使得分割任务学习较慢 |
| 分类+分割 (ANet[ | 在分割之前对图像中的像素进行分类以检测是否有伪装目标的存在 | 让模型聚焦于包含伪装目标的区域,能一定程度上排除非伪装和背景的干扰 | 图像中非伪装的显著目标极具迷惑性,因此分类流可能会产生错误判断导致分割失败 | |
| 仿生攻击+分割 (MirrorNet[ | 检测翻转图像中的伪装特征作为仿生攻击流辅助原始图像的分割 | 促使模型关注纹理和形状特征,能一定程度上增强模型的抗干扰能力 | 图像翻转并不会改变低辨识度的纹理或者边缘,因此仅使用翻转图像作为补充得到的性能增益十分有限 | |
| 纹理检测+分割 (TANet[ TINet[ | 设计独特的纹理标签,并使用矩阵方法、卷积方法等来提取纹理特征 | 基于纹理特征的旋转不变性等特点,使得模型具有较强的抗噪能力 | 由于伪装目标存在纹理欺骗性,仅关注纹理,会导致检测性能有限 | |
| 边缘检测+分割 (MGL[ | 将边缘检测作为与分割并行的一大任务,来明确建模边缘并推理两个任务的互补信息 | 使用类型化函数明确推理两个任务间的互补信息 | 提取的信息种类繁多,很难保证每次提取的信息都是有效的,而且基于图推理的模型使得模型运行速度较慢 | |
| 置信感知 学习策略 | 对抗训练策略 (JCSOD[ | 引入对抗训练来显式建模由完全标注伪装目标的困难带来的不确定性 | 显式生成网络预测的置信度,为模型预测提供可解释性 | 包含对两种任务的学习,使得模型参数量巨大,推理速度慢 |
| 动态监督策略 (CANet[ | 利用预测图和真实标签的L1距离作为动态监督关注由硬像素引起的不确定性 | 能够引导网络重点学习预测不确定的区域上,模型的鲁棒性较高 | 得到的特征通常响应于伪装目标的稀疏边缘,因此容易在特征学习过程中引入噪声 | |
| 正则化约束策略 (Zoom-Net[ | 在目标检测损失中增加了模糊预测的正则化惩罚项,来迫使模型关注不确定像素 | 以简单的计算降低模糊背景带来的干扰 | 多尺度图像的输入,会增加内存占用量和模型运算量 | |
| 多源信息 融合策略 | RGB-D (DCNet[ | 利用现有的深度估计方法生成伪装深度图,并与RGB数据融合以实现RGB-D的COD | 深度图中包含丰富的空间信息,可以作为有效的补充信息提升伪装目标检测性能 | 提取的深度信息不够准确;没有充分考虑到两种模态信息之间的互补性和差异性 |
| RGB+频域 (FDNet[ | 使用离线离散余弦变换引入频域信息,同时用特征对齐融合RGB域和频域信息 | 频域信息的引入以及对所有频带系数的增强,使得模型可以提取判别性信息 | 使用离散余弦提取频域信息可能会产生方块效应,使得模型计算量增加 | |
| Transformer 策略 | 以Transformer为主干 (T2Net[ | 使用密集Transformer主干进行伪装目标检测,并使用深监督等策略补充空间信息 | 长距离特性使模型捕获全局信息的能力更强,对大目标有着较好的检测效果 | 忽略了局部信息的获取,并且模型参数量巨大,训练耗时 |
| Transformer+CNN (UGTR[ | 利用CNN生成的概率表示模型学习Transformer框架下伪装目标的不确定性 | 不确定性引导的上下文推理使得模型更多关注不确定区域 | 仅对不确定性建模,使得模型不确定响应区域总分布在弱边界和不可区分的纹理区域,学习过程中容易引入噪声 |
| 数据集 | 年份 | 发表于 | 规模 | 类 | |
|---|---|---|---|---|---|
| 训练集 | 测试集 | ||||
| CHAMELEON | 2018 | Unpublished | 76 | ||
| CAMO | 2019 | CVIU | 2 000 | 500 | 8 |
| COD10K | 2021 | TPAMI | 6 000 | 4 000 | 78 |
| NC4K | 2021 | CVPR | 4 121 | ||
表2 四个伪装目标检测数据集的主要信息
Table 2 Main information of four camouflaged object detection datasets
| 数据集 | 年份 | 发表于 | 规模 | 类 | |
|---|---|---|---|---|---|
| 训练集 | 测试集 | ||||
| CHAMELEON | 2018 | Unpublished | 76 | ||
| CAMO | 2019 | CVIU | 2 000 | 500 | 8 |
| COD10K | 2021 | TPAMI | 6 000 | 4 000 | 78 |
| NC4K | 2021 | CVPR | 4 121 | ||
| 策略 | 模型 | CHAMELEON | CAMO-Test | COD10K-Test | NC4K | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SINet | 0.869 | 0.891 | 0.740 | 0.044 | 0.751 | 0.771 | 0.606 | 0.100 | 0.771 | 0.806 | 0.551 | 0.051 | 0.808 | 0.871 | 0.769 | 0.058 |
| PFNet | 0.882 | 0.942 | 0.810 | 0.033 | 0.782 | 0.852 | 0.695 | 0.085 | 0.800 | 0.868 | 0.660 | 0.040 | 0.829 | 0.888 | 0.784 | 0.052 | |
| D2CNet | 0.889 | 0.939 | 0.848 | 0.030 | 0.774 | 0.818 | 0.735 | 0.087 | 0.807 | 0.876 | 0.720 | 0.037 | — | — | — | — | |
| C2F-Net | 0.888 | 0.935 | 0.828 | 0.032 | 0.796 | 0.854 | 0.719 | 0.080 | 0.813 | 0.890 | 0.686 | 0.036 | 0.838 | 0.898 | 0.762 | 0.049 | |
| SINetV2 | 0.888 | 0.942 | 0.816 | 0.030 | 0.820 | 0.882 | 0.743 | 0.070 | 0.815 | 0.887 | 0.680 | 0.037 | 0.847 | 0.903 | 0.805 | 0.048 | |
| BASNet | 0.914 | 0.954 | 0.866 | 0.022 | 0.749 | 0.796 | 0.646 | 0.096 | 0.802 | 0.855 | 0.677 | 0.038 | 0.817 | 0.859 | 0.732 | 0.058 | |
| ERRNet | 0.877 | 0.927 | 0.805 | 0.036 | 0.761 | 0.817 | 0.660 | 0.088 | 0.780 | 0.867 | 0.629 | 0.044 | 0.787 | 0.848 | 0.638 | 0.070 | |
| CubeNet | 0.873 | 0.928 | 0.787 | 0.037 | 0.788 | 0.838 | 0.682 | 0.085 | 0.795 | 0.864 | 0.644 | 0.041 | — | — | — | — | |
| SegMaR | 0.906 | 0.954 | 0.860 | 0.025 | 0.815 | 0.872 | 0.742 | 0.071 | 0.833 | 0.895 | 0.724 | 0.033 | — | — | — | — | |
| 2 | ANet | — | — | — | — | 0.682 | 0.685 | 0.484 | 0.126 | — | — | — | — | — | — | — | — |
| MirrorNet | — | — | — | — | 0.785 | 0.849 | 0.719 | 0.077 | — | — | — | — | — | — | — | — | |
| LSR | 0.893 | 0.938 | 0.839 | 0.033 | 0.793 | 0.826 | 0.725 | 0.085 | 0.793 | 0.868 | 0.685 | 0.041 | 0.839 | 0.883 | 0.779 | 0.053 | |
| TANet | 0.888 | 0.911 | 0.786 | 0.036 | 0.793 | 0.834 | 0.690 | 0.083 | 0.803 | 0.848 | 0.629 | 0.041 | — | — | — | — | |
| TINet | 0.874 | 0.916 | 0.783 | 0.038 | 0.781 | 0.847 | 0.678 | 0.087 | 0.793 | 0.848 | 0.645 | 0.043 | 0.829 | 0.879 | 0.734 | 0.055 | |
| DGNet | — | — | — | — | 0.839 | 0.901 | 0.769 | 0.057 | 0.822 | 0.896 | 0.693 | 0.033 | 0.857 | 0.911 | 0.784 | 0.042 | |
| MGL | 0.893 | 0.923 | 0.813 | 0.030 | 0.775 | 0.847 | 0.673 | 0.088 | 0.814 | 0.865 | 0.666 | 0.035 | 0.833 | 0.867 | 0.782 | 0.052 | |
| 3 | JCSOD | 0.894 | 0.943 | 0.848 | 0.030 | 0.803 | 0.853 | 0.759 | 0.076 | 0.817 | 0.892 | 0.726 | 0.035 | 0.842 | 0.898 | 0.771 | 0.047 |
| CANet | 0.885 | 0.940 | 0.831 | 0.029 | 0.799 | 0.865 | 0.770 | 0.075 | 0.809 | 0.885 | 0.703 | 0.035 | 0.842 | 0.904 | 0.803 | 0.047 | |
| Zoom-Net | 0.902 | 0.958 | 0.845 | 0.023 | 0.820 | 0.892 | 0.794 | 0.066 | 0.838 | 0.911 | 0.729 | 0.029 | 0.853 | 0.912 | 0.784 | 0.043 | |
| 4 | DCNet | 0.895 | 0.951 | 0.856 | 0.027 | 0.819 | 0.881 | 0.798 | 0.069 | 0.829 | 0.903 | 0.751 | 0.032 | 0.855 | 0.910 | 0.825 | 0.042 |
| FDNet | 0.898 | 0.949 | 0.837 | 0.027 | 0.844 | 0.898 | 0.778 | 0.062 | 0.837 | 0.918 | 0.731 | 0.030 | — | — | — | — | |
| 5 | UGTR | 0.888 | 0.918 | 0.796 | 0.031 | 0.785 | 0.859 | 0.686 | 0.086 | 0.818 | 0.850 | 0.667 | 0.035 | 0.839 | 0.874 | 0.747 | 0.052 |
| T2Net | 0.899 | 0.958 | 0.858 | 0.023 | 0.860 | 0.920 | 0.832 | 0.050 | 0.843 | 0.917 | 0.765 | 0.029 | 0.872 | 0.927 | 0.837 | 0.037 | |
表3 基于深度学习的伪装目标检测方法的定量比较
Table 3 Quantitative comparison of camouflaged target detection methods based on deep learning
| 策略 | 模型 | CHAMELEON | CAMO-Test | COD10K-Test | NC4K | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SINet | 0.869 | 0.891 | 0.740 | 0.044 | 0.751 | 0.771 | 0.606 | 0.100 | 0.771 | 0.806 | 0.551 | 0.051 | 0.808 | 0.871 | 0.769 | 0.058 |
| PFNet | 0.882 | 0.942 | 0.810 | 0.033 | 0.782 | 0.852 | 0.695 | 0.085 | 0.800 | 0.868 | 0.660 | 0.040 | 0.829 | 0.888 | 0.784 | 0.052 | |
| D2CNet | 0.889 | 0.939 | 0.848 | 0.030 | 0.774 | 0.818 | 0.735 | 0.087 | 0.807 | 0.876 | 0.720 | 0.037 | — | — | — | — | |
| C2F-Net | 0.888 | 0.935 | 0.828 | 0.032 | 0.796 | 0.854 | 0.719 | 0.080 | 0.813 | 0.890 | 0.686 | 0.036 | 0.838 | 0.898 | 0.762 | 0.049 | |
| SINetV2 | 0.888 | 0.942 | 0.816 | 0.030 | 0.820 | 0.882 | 0.743 | 0.070 | 0.815 | 0.887 | 0.680 | 0.037 | 0.847 | 0.903 | 0.805 | 0.048 | |
| BASNet | 0.914 | 0.954 | 0.866 | 0.022 | 0.749 | 0.796 | 0.646 | 0.096 | 0.802 | 0.855 | 0.677 | 0.038 | 0.817 | 0.859 | 0.732 | 0.058 | |
| ERRNet | 0.877 | 0.927 | 0.805 | 0.036 | 0.761 | 0.817 | 0.660 | 0.088 | 0.780 | 0.867 | 0.629 | 0.044 | 0.787 | 0.848 | 0.638 | 0.070 | |
| CubeNet | 0.873 | 0.928 | 0.787 | 0.037 | 0.788 | 0.838 | 0.682 | 0.085 | 0.795 | 0.864 | 0.644 | 0.041 | — | — | — | — | |
| SegMaR | 0.906 | 0.954 | 0.860 | 0.025 | 0.815 | 0.872 | 0.742 | 0.071 | 0.833 | 0.895 | 0.724 | 0.033 | — | — | — | — | |
| 2 | ANet | — | — | — | — | 0.682 | 0.685 | 0.484 | 0.126 | — | — | — | — | — | — | — | — |
| MirrorNet | — | — | — | — | 0.785 | 0.849 | 0.719 | 0.077 | — | — | — | — | — | — | — | — | |
| LSR | 0.893 | 0.938 | 0.839 | 0.033 | 0.793 | 0.826 | 0.725 | 0.085 | 0.793 | 0.868 | 0.685 | 0.041 | 0.839 | 0.883 | 0.779 | 0.053 | |
| TANet | 0.888 | 0.911 | 0.786 | 0.036 | 0.793 | 0.834 | 0.690 | 0.083 | 0.803 | 0.848 | 0.629 | 0.041 | — | — | — | — | |
| TINet | 0.874 | 0.916 | 0.783 | 0.038 | 0.781 | 0.847 | 0.678 | 0.087 | 0.793 | 0.848 | 0.645 | 0.043 | 0.829 | 0.879 | 0.734 | 0.055 | |
| DGNet | — | — | — | — | 0.839 | 0.901 | 0.769 | 0.057 | 0.822 | 0.896 | 0.693 | 0.033 | 0.857 | 0.911 | 0.784 | 0.042 | |
| MGL | 0.893 | 0.923 | 0.813 | 0.030 | 0.775 | 0.847 | 0.673 | 0.088 | 0.814 | 0.865 | 0.666 | 0.035 | 0.833 | 0.867 | 0.782 | 0.052 | |
| 3 | JCSOD | 0.894 | 0.943 | 0.848 | 0.030 | 0.803 | 0.853 | 0.759 | 0.076 | 0.817 | 0.892 | 0.726 | 0.035 | 0.842 | 0.898 | 0.771 | 0.047 |
| CANet | 0.885 | 0.940 | 0.831 | 0.029 | 0.799 | 0.865 | 0.770 | 0.075 | 0.809 | 0.885 | 0.703 | 0.035 | 0.842 | 0.904 | 0.803 | 0.047 | |
| Zoom-Net | 0.902 | 0.958 | 0.845 | 0.023 | 0.820 | 0.892 | 0.794 | 0.066 | 0.838 | 0.911 | 0.729 | 0.029 | 0.853 | 0.912 | 0.784 | 0.043 | |
| 4 | DCNet | 0.895 | 0.951 | 0.856 | 0.027 | 0.819 | 0.881 | 0.798 | 0.069 | 0.829 | 0.903 | 0.751 | 0.032 | 0.855 | 0.910 | 0.825 | 0.042 |
| FDNet | 0.898 | 0.949 | 0.837 | 0.027 | 0.844 | 0.898 | 0.778 | 0.062 | 0.837 | 0.918 | 0.731 | 0.030 | — | — | — | — | |
| 5 | UGTR | 0.888 | 0.918 | 0.796 | 0.031 | 0.785 | 0.859 | 0.686 | 0.086 | 0.818 | 0.850 | 0.667 | 0.035 | 0.839 | 0.874 | 0.747 | 0.052 |
| T2Net | 0.899 | 0.958 | 0.858 | 0.023 | 0.860 | 0.920 | 0.832 | 0.050 | 0.843 | 0.917 | 0.765 | 0.029 | 0.872 | 0.927 | 0.837 | 0.037 | |

图6 基于深度学习的伪装目标检测方法的视觉比较
Fig.6 Visual comparison of deep learning-based camouflaged object detection methods

图7 现有COD方法的效率分析
Fig.7 Efficiency analysis of existing COD methods

图8 COD在医学领域的应用
Fig.8 Applications of COD in medicine
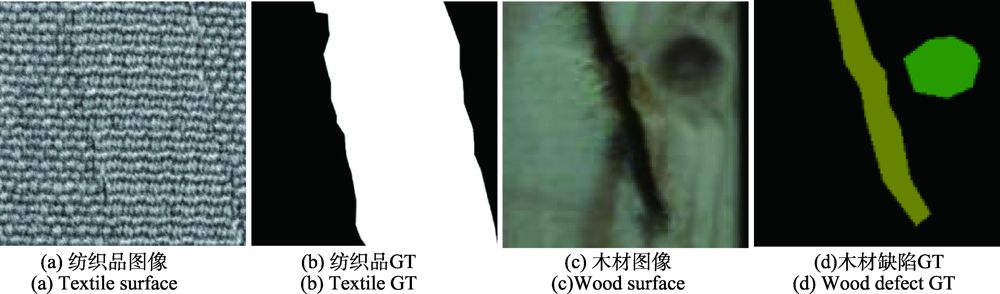
图9 COD在工业领域的应用
Fig.9 Applications of COD in industry

图10 COD在农业领域的应用
Fig.10 Applications of COD in agriculture

图11 迷彩伪装士兵检测
Fig.11 Camouflage soldier detection

图12 动物嵌入在风景图像中
Fig.12 Some animals embedded into landscape images
| [1] | REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]// Proceedings of the Annual Conference on Neural Information Processing Systems 2015, Montreal, Dec 7-12, 2015. Red Hook: Curran Associates, 2015: 91-99. |
| [2] | LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Oct 22-29, 2017. Washington: IEEE Computer Society, 2017: 2999-3007. |
| [3] | HE K, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Oct 22-29, 2017. Washington: IEEE Computer Society, 2017: 2980-2988. |
| [4] |
WU Y H, LIU Y, ZHANG L, et al. EDN: salient object detection via extremely-downsampled network[J]. IEEE Transactions on Image Processing, 2022, 31: 3125-3136.
DOI URL |
| [5] | PANG Y, ZHAO X, ZHANG L, et al. Multi-scale interactive network for salient object detection[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 9410-9419. |
| [6] | FENG M, LU H, DING E. Attentive feedback network for boundary-aware salient object detection[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, Jun 16-20, 2019. Piscataway: IEEE, 2019: 1623-1632. |
| [7] | TANKUS A, YESHURUN Y. Detection of regions of interest and camouflage breaking by direct convexity estimation[C]// Proceedings of the 1998 IEEE Workshop on Visual Surveillance, Bombay, Dec 5- 8, 1998. Washington: IEEE Computer Society, 1998: 42-48. |
| [8] |
ZHANG X, ZHU C, WANG S, et al. A Bayesian approach to camouflaged moving object detection[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2016, 27(9): 2001-2013.
DOI URL |
| [9] |
BEIDERMAN Y, TEICHER M, GARCIA J, et al. Optical technique for classification, recognition and identification of obscured objects[J]. Optics Communications, 2010, 283(21): 4274-4282.
DOI URL |
| [10] | GALUN M, SHARON E, BASRI R, et al. Texture segmen-tation by multiscale aggregation of filter responses and shape elements[C]// Proceedings of the 9th IEEE International Conference on Computer Vision, Nice, Oct 14-17, 2003. Washington: IEEE Computer Society, 2003: 716-723. |
| [11] | GUO H, DOU Y, TIAN T, et al. A robust foreground segmentation method by temporal averaging multiple video frames[C]// Proceedings of the 2008 International Conference on Audio, Language and Image Processing, Shanghai, Jul 7-9, 2008. Piscataway: IEEE, 2008: 878-882. |
| [12] | KAVITHA C, RAO B P, GOVARDHAN A. An efficient content based image retrieval using color and texture of image sub-blocks[J]. International Journal of Engineering Science and Technology, 2011, 3(2): 1060-1068. |
| [13] |
HALL J R, CUTHILL I C, BADDELEY R, et al. Camouflage, detection and identification of moving targets[J]. Proceedings of the Royal Society B: Biological Sciences, 2013, 280(1758): 20130064.
DOI URL |
| [14] |
BI H, ZHANG C, WANG K, et al. Rethinking camouflaged object detection: models and datasets[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(9): 5708-5724.
DOI URL |
| [15] | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[C]// Proceedings of the 2015 International Conference on Learning Represen-tations, San Diego, May 7-9, 2015. Piscataway: IEEE, 2015: 1-14. |
| [16] | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Con-ference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 770-778. |
| [17] |
GAO S H, CHENG M M, ZHAO K, et al. Res2net: a new multi-scale backbone architecture[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 43(2): 652-662.
DOI URL |
| [18] | FAN D P, JI G P, SUN G, et al. Camouflaged object detection[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 2774-2784. |
| [19] | WU Z, SU L, HUANG Q. Cascaded partial decoder for fast and accurate salient object detection[C]// Proceedings of the 2019 IEEE/CVF conference on Computer Vision and Pattern Recognition, Long Beach, Jun 16-20, 2019. Piscataway:IEEE, 2019: 3907-3916. |
| [20] | WANG K, BI H, ZHANG Y, et al. D2C-Net: a dual-branch, dual-guidance and cross-refine network for camouflaged object detection[J]. IEEE Transactions on Industrial Electr-onics, 2022, 69(5): 5364-5374. |
| [21] | RONNEBERGER O, FISCHER P, BROX T. U-net: con-volutional networks for biomedical image segmentation[C]// LNCS 9351: Proceedings of the 2015 International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Oct 5-9, 2015. Cham:Springer, 2015: 234-241. |
| [22] |
ZHUGE M, LU X, GUO Y, et al. CubeNet: X-shape connection for camouflaged object detection[J]. Pattern Recognition, 2022, 127: 108644.
DOI URL |
| [23] | SUN Y, CHEN G, ZHOU T, et al. Context-aware cross-level fusion network for camouflaged object detection[J]. arXiv:2105.12555, 2021. |
| [24] | MEI H, JI G P, WEI Z, et al. Camouflaged object segmentation with distraction mining[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 8772-8781. |
| [25] | FAN D P, JI G P, CHENG M M, et al. Concealed object detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(10): 6024-6042. |
| [26] | QIN X, FAN D P, HUANG C, et al. Boundary-aware segmentation network for mobile and web applications[J]. arXiv:2101.04704, 2021. |
| [27] |
DE BOER P T, KROESE D P, MANNOR S, et al. A tutorial on the cross-entropy method[J]. Annals of Operations Research, 2005, 134(1): 19-67.
DOI URL |
| [28] | WANG Z, SIMONCELLI E P, BOVIK A C. Multiscale structural similarity for image quality assessment[C]// Proceedings of the 37th Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, Nov 9-12, 2003. Piscataway:IEEE, 2003: 1398-1402. |
| [29] | MÁTTYUS G, LUO W, URTASUN R. DeepRoadMapper: extracting road topology from aerial images[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Oct 22-29, 2017. Washington: IEEE Computer Society, 2017: 3438-3446. |
| [30] |
JI G P, ZHU L, ZHUGE M, et al. Fast camouflaged object detection via edge-based reversible re-calibration network[J]. Pattern Recognition, 2022, 123: 108414.
DOI URL |
| [31] | JIA Q, YAO S, LIU Y, et al. Segment, magnify and reiterate: detecting camouflaged objects the hard way[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, Jun 19-20, 2022. Piscataway: IEEE, 2022: 4713-4722. |
| [32] | LV Y, ZHANG J, DAI Y, et al. Simultaneously localize, segment and rank the camouflaged objects[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 11591-11601. |
| [33] |
LE T N, NGUYEN T V, NIE Z, et al. Anabranch network for camouflaged object segmentation[J]. Computer Vision and Image Understanding, 2019, 184: 45-56.
DOI URL |
| [34] |
YAN J, LE T N, NGUYEN K D, et al. MirrorNet: bio-inspired camouflaged object segmentation[J]. IEEE Access, 2021, 9: 43290-43300.
DOI URL |
| [35] | REN J, HU X, ZHU L, et al. Deep texture-aware features for camouflaged object detection[J]. arXiv:2102.02996, 2021. |
| [36] | ZHU J, ZHANG X, ZHANG S, et al. Inferring camouflaged objects by texture-aware interactive guidance network[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence, the 33rd Conference on Innovative Applications of Artificial Intelligence, the 11th Symposium on Educational Advances in Artificial Intelligence. Menlo Park: AAAI, 2021: 3599-3607. |
| [37] | JI G P, FAN D P, CHOU Y C, et al. Deep gradient learning for efficient camouflaged object detection[J]. arXiv:2205.12853, 2022. |
| [38] | ZHAI Q, LI X, YANG F, et al. Mutual graph learning for camouflaged object detection[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 12997-13007. |
| [39] | KENDALL A, GAL Y. What uncertainties do we need in Bayesian deep learning for computer vision?[C]// Proceedings of the Annual Conference on Neural Information Processing Systems 2017, Long Beach, Dec 4-9, 2017. Red Hook: Curran Associates, 2017: 5574-5584. |
| [40] | SHEN Y, ZHANG Z, SABUNCU M R, et al. Real-time uncertainty estimation in computer vision via uncertainty-aware distribution distillation[C]// Proceedings of the 2021 IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, Jan 3-8, 2021. Piscataway: IEEE, 2021: 707-716. |
| [41] | LAKSHMINARAYANAN B, PRITZEL A, BLUNDELL C. Simple and scalable predictive uncertainty estimation using deep ensembles[C]// Proceedings of the Annual Conference on Neural Information Processing Systems 2017, Long Beach, Dec 4-9, 2017. Red Hook: Curran Associates, 2017: 6402-6413. |
| [42] | LI A, ZHANG J, LV Y, et al. Uncertainty-aware joint salient object and camouflaged object detection[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 10071-10081. |
| [43] | LIU J, ZHANG J, BARNES N. Confidence-aware learning for camouflaged object detection[J]. arXiv:2106.11641, 2021. |
| [44] | PANG Y W, ZHAO X Q, XIANG T Z, et al. Zoom in and out: a mixed-scale triplet network for camouflaged object detection[J]. arXiv:2203.02688, 2022. |
| [45] | ZHANG J, LV Y, XIANG M, et al. Depth confidence-aware camouflaged object detection[J]. arXiv:2106.13217, 2021. |
| [46] | ZHONG Y, LI B, TANG L, et al. Detecting camouflaged object in frequency domain[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, Jun 19-20, 2022. Piscataway: IEEE, 2022: 4504-4513. |
| [47] | LUO W, LI Y, URTASUN R, et al. Understanding the effective receptive field in deep convolutional neural networks[C]// Proceedings of the Annual Conference on Neural Information Processing Systems 2016, Barcelona, Dec 5-10, 2016. Red Hook: Curran Associates, 2016: 4898-4906. |
| [48] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the Annual Conference on Neural Information Processing Systems 2017, Long Beach, Dec 4-9, 2017. Red Hook: Curran Associates, 2017: 5998-6008. |
| [49] | 周雪, 柏正尧, 陆倩杰, 等. 融合金字塔Transformer和轴向注意的结直肠息肉分割[J/OL]. 计算机工程与应用(2022-03-28)[2022-04-16]. https://kns.cnki.net/kcms/detail/11.2127.TP.20220325.1526.016.html. |
| ZHOU X, BO Z R, LU Q J, et al. Colorectal polyp segmentation combining pyramid Transformer and axial attention[J/OL]. Computer Engineering and Applications(2022-03-28)[2022-04-16]. https://kns.cnki.net/kcms/detail/11.2127.TP.20220325.1526.016.html. | |
| [50] | 赵琛琦, 王华虎, 赵涓涓, 等. 视觉Transformer与多特征融合的脑卒中检测算法[J]. 中国图象图形学报, 2022, 27(3):923-934. |
| ZHAO C Q, WANG H H, ZHAO J J, et al. Cerebral stroke detection algorithm for visual Transformer and multi-feature fusion[J]. Journal of Image and Graphics, 2022, 27(3): 923-934. | |
| [51] | DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16 × 16 words: Transformers for image recognition at scale[J]. arXiv:2010.11929, 2020. |
| [52] | WANG W, XIE E, LI X, et al. Pyramid vision Transformer: a versatile backbone for dense prediction without convolutions[C]// Proceedings of the 2021 IEEE/CVF International Con-ference on Computer Vision, Montreal, Oct 10-17, 2021. Piscataway: IEEE, 2021: 548-558. |
| [53] | ZHENG S, LU J, ZHAO H, et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with Transformers[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 6881-6890. |
| [54] | CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with Transformers[C]// LNCS 12346:Proc-eedings of the 16th European Conference on Computer Vision, Glasgow, Aug 23-28, 2020. Cham: Springer, 2020: 213-229. |
| [55] | LIU Z, LIN Y, CAO Y, et al. Swin Transformer: hierarchical vision transformer using shifted widows[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Oct 10-17, 2021. Piscataway: IEEE, 2021: 10012-10022. |
| [56] | MAO Y, ZHANG J, WAN Z, et al. Transformer transforms salient object detection and camouflaged object detection[J]. arXiv:2104.10127, 2021. |
| [57] | YANG F, ZHAI Q, LI X, et al. Uncertainty-guided Trans-former reasoning for camouflaged object detection[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Oct 10-17, 2021. Piscataway: IEEE, 2021: 4146-4155. |
| [58] | FAN D P, CHENG M M, LIU Y, et al. Structure-measure: a new way to evaluate foreground maps[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Oct 22-29, 2017. Washington: IEEE Computer Society, 2017: 4548-4557. |
| [59] | FAN D P, GONG C, CAO Y, et al. Enhanced-alignment measure for binary foreground map evaluation[C]// Proceedings of the 27th International Joint Conference on Artificial Intelligence, 2018: 698-704. |
| [60] | MARGOLIN R, ZELNIK-MANOR L, TAL A. How to evaluate foreground maps?[C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, Jun 23-28, 2014. Washington: IEEE Computer Society, 2014: 248-255. |
| [61] | PERAZZI F, KRÄHENBÜHL P, PRITCH Y, et al. Saliency filters: contrast based filtering for salient region detection[C]// Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, Jun 16-21, 2012. Washington: IEEE Computer Society, 2012: 733-740. |
| [62] | JI G P, XIAO G, CHOU Y C, et al. Video polyp segmentation: a deep learning perspective[J]. arXiv:2203.14291, 2022. |
| [63] |
FAN D P, ZHOU T, JI G P, et al. Inf-net: automatic covid-19 lung infection segmentation from CT images[J]. IEEE Transactions on Medical Imaging, 2020, 39(8): 2626-2637.
DOI URL |
| [64] |
HE T, LIU Y, XU C, et al. A fully convolutional neural network for wood defect location and identification[J]. IEEE Access, 2019, 7: 123453-123462.
DOI URL |
| [65] | 张文霞. 基于图像处理技术的蝗虫识别算法研究[D]. 呼和浩特: 内蒙古大学, 2020. |
| ZHANG W X. Research on locust recognition algorithm based on image processing technology[D]. Hohhot: Inner Mongolia University, 2020. | |
| [66] | 刘芳, 刘玉坤, 林森. 基于改进型YOLO的复杂环境下番茄果实快速识别方法[J]. 农业机械学报, 2020, 51(6):229-237. |
| LIU F, LIU Y K, LIN S. Fast recognition method for tomatoes under complex environments based on improved YOLO[J]. Transactions of the Chinese Society of Agri-cultural Machinery, 2020, 51(6):229-237. | |
| [67] | CHU H K, HSU W H, MITRA N J, et al. Camouflage images[J]. ACM Transactions on Graphics, 2010, 29(4): 51. |
| [68] | CHENG X, XIONG H, FAN D P, et al. Implicit motion handling for video camouflaged object detection[C]// Pro-ceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, Jun 19-20, 2022. Piscataway: IEEE, 2022: 13864-13873. |
| [1] | 张璐, 芦天亮, 杜彦辉. 人脸视频深度伪造检测方法综述[J]. 计算机科学与探索, 2023, 17(1): 1-26. |
| [2] | 王仕宸, 黄凯, 陈志刚, 张文东. 深度学习的三维人体姿态估计综述[J]. 计算机科学与探索, 2023, 17(1): 74-87. |
| [3] | 梁佳利, 华保健, 吕雅帅, 苏振宇. 面向深度学习算子的循环不变式外提算法[J]. 计算机科学与探索, 2023, 17(1): 127-139. |
| [4] | 王剑哲, 吴秦. 坐标注意力特征金字塔的显著性目标检测算法[J]. 计算机科学与探索, 2023, 17(1): 154-165. |
| [5] | 杨才东, 李承阳, 李忠博, 谢永强, 孙方伟, 齐锦. 深度学习的图像超分辨率重建技术综述[J]. 计算机科学与探索, 2022, 16(9): 1990-2010. |
| [6] | 张祥平, 刘建勋. 基于深度学习的代码表征及其应用综述[J]. 计算机科学与探索, 2022, 16(9): 2011-2029. |
| [7] | 李冬梅, 罗斯斯, 张小平, 许福. 命名实体识别方法研究综述[J]. 计算机科学与探索, 2022, 16(9): 1954-1968. |
| [8] | 任宁, 付岩, 吴艳霞, 梁鹏举, 韩希. 深度学习应用于目标检测中失衡问题研究综述[J]. 计算机科学与探索, 2022, 16(9): 1933-1953. |
| [9] | 吕晓琦, 纪科, 陈贞翔, 孙润元, 马坤, 邬俊, 李浥东. 结合注意力与循环神经网络的专家推荐算法[J]. 计算机科学与探索, 2022, 16(9): 2068-2077. |
| [10] | 安凤平, 李晓薇, 曹翔. 权重初始化-滑动窗口CNN的医学图像分类[J]. 计算机科学与探索, 2022, 16(8): 1885-1897. |
| [11] | 曾凡智, 许露倩, 周燕, 周月霞, 廖俊玮. 面向智慧教育的知识追踪模型研究综述[J]. 计算机科学与探索, 2022, 16(8): 1742-1763. |
| [12] | 刘艺, 李蒙蒙, 郑奇斌, 秦伟, 任小广. 视频目标跟踪算法综述[J]. 计算机科学与探索, 2022, 16(7): 1504-1515. |
| [13] | 赵小明, 杨轶娇, 张石清. 面向深度学习的多模态情感识别研究进展[J]. 计算机科学与探索, 2022, 16(7): 1479-1503. |
| [14] | 夏鸿斌, 肖奕飞, 刘渊. 融合自注意力机制的长文本生成对抗网络模型[J]. 计算机科学与探索, 2022, 16(7): 1603-1610. |
| [15] | 孙方伟, 李承阳, 谢永强, 李忠博, 杨才东, 齐锦. 深度学习应用于遮挡目标检测算法综述[J]. 计算机科学与探索, 2022, 16(6): 1243-1259. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||