
计算机科学与探索 ›› 2022, Vol. 16 ›› Issue (2): 438-447.DOI: 10.3778/j.issn.1673-9418.2105048
王燕妮, 余丽仙+( )
)
收稿日期:2021-05-13
修回日期:2021-07-16
出版日期:2022-02-01
发布日期:2021-07-22
通讯作者:
+ E-mail: ylx@xauat.edu.cn作者简介:王燕妮(1975—),女,陕西渭南人,博士,副教授,主要研究方向为智能信息处理、图像处理。基金资助:
WANG Yanni, YU Lixian+()
Received:2021-05-13
Revised:2021-07-16
Online:2022-02-01
Published:2021-07-22
About author:WANG Yanni, born in 1975, Ph.D., associate professor. Her research interests include intelligent information processing and image processing.Supported by:摘要:
针对传统的SSD目标检测算法在进行多尺度目标检测时,存在特征图有效信息弱和困难目标漏检率大等问题,提出一种改进的SSD目标检测算法。首先,在网络特征图输出处引入即插即用的轻量级注意力机制,通过不降维、局部跨通道交互以及核大小自适应选择等操作,在保持网络原始计算量的同时有效突出特征图中关键信息。该模块有利于增强背景信息和目标信息差,可以在有效提升网络性能的同时,不增加网络的复杂性。然后,构造了一种新的特征融合模块,可以将不同尺度的特征图进行有效融合,使浅层特征层既含有丰富的细节信息,又能充分利用上下文语义信息。多尺度融合模块有利于丰富特征图信息,提升网络对困难目标的检测性能。使用公开的PASCAL VOC数据集验证该方法,改进后的网络在PASCAL VOC2007测试集上的检测精度达到了79.6%,比原始SSD算法提升了2.4个百分点,在遮挡目标数据集上提升了4.7个百分点,充分证明改进方法具有一定的时效性和鲁棒性。
中图分类号:
王燕妮, 余丽仙. 注意力与多尺度有效融合的SSD目标检测算法[J]. 计算机科学与探索, 2022, 16(2): 438-447.
WANG Yanni, YU Lixian. SSD Object Detection Algorithm with Effective Fusion of Attention and Multi-scale[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(2): 438-447.
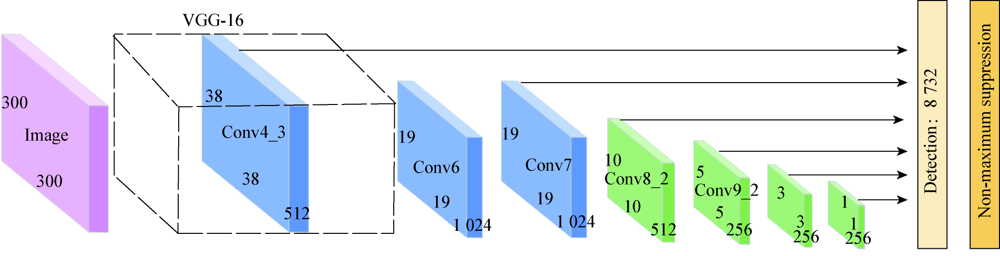
图1 SSD算法结构图
Fig.1 SSD algorithm structure diagram

图2 改进的SSD算法结构
Fig.2 Improved SSD algorithm structure

图3 挤压和激发网络模型图
Fig.3 Squeeze-and-excitation networks model structure

图4 空间域结构模型图
Fig.4 Spatial transformer model structure

图5 深度卷积神经网络的有效通道注意
Fig.5 Efficient channel attention for deep convolutional neural networks

图6 ECA-Net热图
Fig.6 ECA-Net heat map

图7 特征图可视化对比图
Fig.7 Visualized comparison chart of feature maps

图8 CSPNet结构图
Fig.8 CSPNet structure diagram
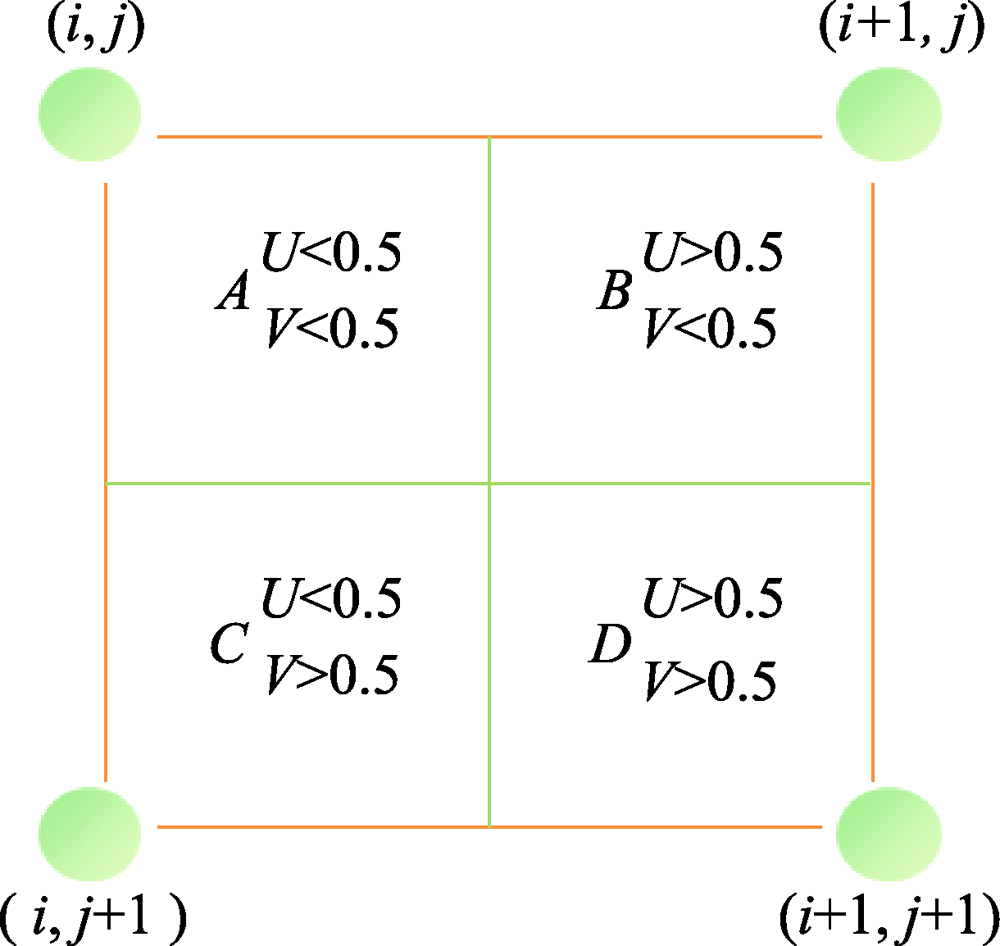
图9 最邻近插值法
Fig.9 The nearest interpolation

图10 特征融合模块
Fig.10 Feature fusion module
| 模型 | mAP | aero | bike | bird | boat | bottle | bus | car | cat | chair | cow | table | dog | horse | mbike | person | plant | sheep | sofa | train | tv |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Fast R-CNN[ | 70.0 | 77.0 | 78.1 | 69.3 | 59.4 | 38.3 | 81.6 | 78.6 | 86.7 | 42.8 | 78.8 | 68.9 | 84.7 | 82.0 | 76.6 | 69.9 | 31.8 | 70.1 | 74.8 | 80.4 | 70.4 |
| Faster R-CNN[ | 73.2 | 76.5 | 79.0 | 70.9 | 65.5 | 52.1 | 83.1 | 84.7 | 86.4 | 52.0 | 81.9 | 65.7 | 84.8 | 84.6 | 77.5 | 76.7 | 38.8 | 73.6 | 73.9 | 83.0 | 72.6 |
| SSD[ | 77.2 | 78.8 | 85.3 | 75.7 | 71.5 | 49.1 | 85.7 | 86.4 | 87.8 | 60.6 | 82.7 | 76.5 | 84.9 | 86.7 | 84.0 | 79.2 | 51.3 | 77.5 | 78.7 | 86.7 | 76.3 |
| DSSD[ | 78.6 | 81.9 | 84.9 | 80.5 | 68.4 | 53.9 | 85.6 | 86.2 | 88.9 | 61.1 | 83.5 | 78.7 | 86.7 | 88.7 | 86.7 | 79.7 | 51.7 | 78.0 | 80.9 | 87.2 | 79.4 |
| ION[ | 79.2 | 80.2 | 85.2 | 78.8 | 70.9 | 62.6 | 86.6 | 86.9 | 89.8 | 61.7 | 86.9 | 76.5 | 88.4 | 87.5 | 83.4 | 80.5 | 52.4 | 78.1 | 77.2 | 86.9 | 83.5 |
| Proposed | 79.6 | 78.3 | 88.7 | 77.1 | 73.6 | 55.8 | 87.2 | 87.1 | 90.1 | 62.5 | 85.3 | 78.7 | 87.6 | 90.1 | 87.6 | 82.8 | 51.3 | 80.7 | 79.8 | 89.4 | 78.4 |
表1 PASCAL VOC2007 test数据集上20种类别检测精度对比
Table 1 Comparison of detection accuracy of 20 classes on PASCAL VOC2007 test dataset %
| 模型 | mAP | aero | bike | bird | boat | bottle | bus | car | cat | chair | cow | table | dog | horse | mbike | person | plant | sheep | sofa | train | tv |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Fast R-CNN[ | 70.0 | 77.0 | 78.1 | 69.3 | 59.4 | 38.3 | 81.6 | 78.6 | 86.7 | 42.8 | 78.8 | 68.9 | 84.7 | 82.0 | 76.6 | 69.9 | 31.8 | 70.1 | 74.8 | 80.4 | 70.4 |
| Faster R-CNN[ | 73.2 | 76.5 | 79.0 | 70.9 | 65.5 | 52.1 | 83.1 | 84.7 | 86.4 | 52.0 | 81.9 | 65.7 | 84.8 | 84.6 | 77.5 | 76.7 | 38.8 | 73.6 | 73.9 | 83.0 | 72.6 |
| SSD[ | 77.2 | 78.8 | 85.3 | 75.7 | 71.5 | 49.1 | 85.7 | 86.4 | 87.8 | 60.6 | 82.7 | 76.5 | 84.9 | 86.7 | 84.0 | 79.2 | 51.3 | 77.5 | 78.7 | 86.7 | 76.3 |
| DSSD[ | 78.6 | 81.9 | 84.9 | 80.5 | 68.4 | 53.9 | 85.6 | 86.2 | 88.9 | 61.1 | 83.5 | 78.7 | 86.7 | 88.7 | 86.7 | 79.7 | 51.7 | 78.0 | 80.9 | 87.2 | 79.4 |
| ION[ | 79.2 | 80.2 | 85.2 | 78.8 | 70.9 | 62.6 | 86.6 | 86.9 | 89.8 | 61.7 | 86.9 | 76.5 | 88.4 | 87.5 | 83.4 | 80.5 | 52.4 | 78.1 | 77.2 | 86.9 | 83.5 |
| Proposed | 79.6 | 78.3 | 88.7 | 77.1 | 73.6 | 55.8 | 87.2 | 87.1 | 90.1 | 62.5 | 85.3 | 78.7 | 87.6 | 90.1 | 87.6 | 82.8 | 51.3 | 80.7 | 79.8 | 89.4 | 78.4 |
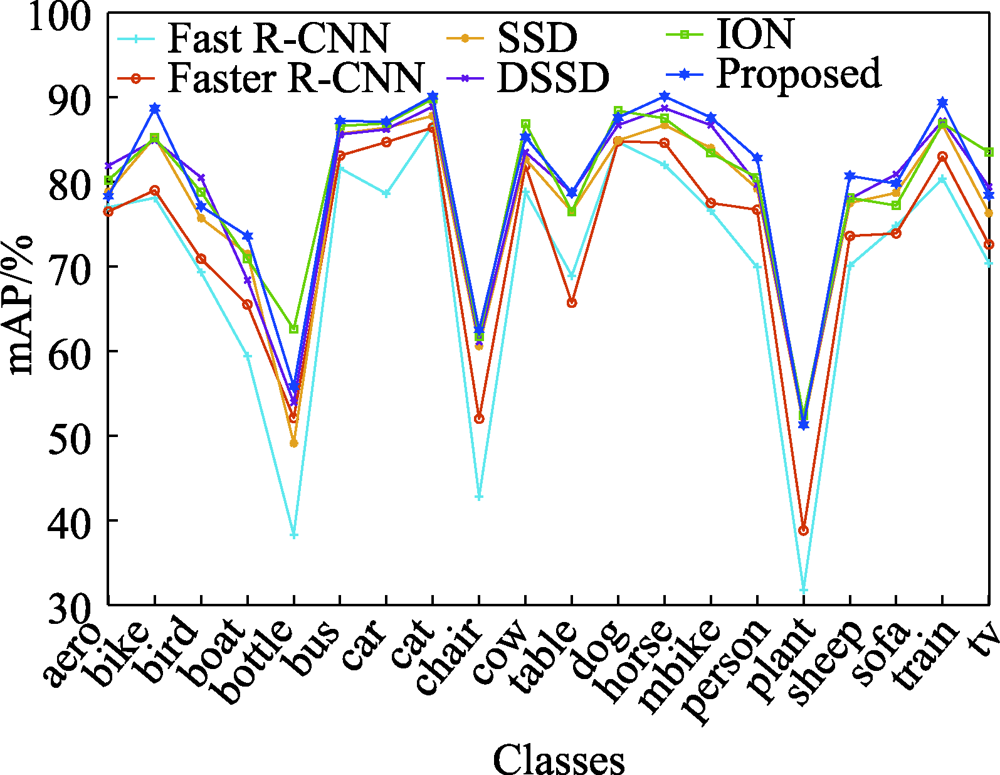
图11 PASCAL VOC2007 test数据集上20种类别AP对比
Fig.11 Comparison of AP of 20 classes on PASCAL VOC2007 test dataset
| 算法 | 网络 | 检测速度/(frame/s) | 锚框个数 | 输入尺寸 | mAP/% |
|---|---|---|---|---|---|
| Faster R-CNN 1[ | VGG-16 | 7.5 | 6 000 | ~600×1 000 | 73.2 |
| Faster R-CNN 2[ | ResNet-101 | 3.9 | 300 | ~600×1 000 | 76.4 |
| R-FCN[ | ResNet-101 | 9.6 | 300 | ~600×1 000 | 79.5 |
| YOLOv2[ | Darknet-19 | 43.1 | — | 544×544 | 78.6 |
| SSD300[ | VGG-16 | 49.5 | 8 732 | 300×300 | 74.3 |
| SSD300*[ | VGG-16 | 49.5 | 8 732 | 300×300 | 77.2 |
| SSD512[ | VGG-16 | 22.5 | 24 564 | 512×512 | 79.5 |
| RSSD300[ | VGG-16 | 37.6 | 8 732 | 300×300 | 78.5 |
| DSSD321[ | ResNet-101 | 10.1 | 17 080 | 321×321 | 78.6 |
| Proposed | VGG-16 | 37.3 | 8 732 | 300×300 | 79.6 |
表2 PASCAL VOC2007 test数据集上检测速度和检测精度对比
Table 2 Comparison of detection speed and detection accuracy on PASCAL VOC2007 test dataset
| 算法 | 网络 | 检测速度/(frame/s) | 锚框个数 | 输入尺寸 | mAP/% |
|---|---|---|---|---|---|
| Faster R-CNN 1[ | VGG-16 | 7.5 | 6 000 | ~600×1 000 | 73.2 |
| Faster R-CNN 2[ | ResNet-101 | 3.9 | 300 | ~600×1 000 | 76.4 |
| R-FCN[ | ResNet-101 | 9.6 | 300 | ~600×1 000 | 79.5 |
| YOLOv2[ | Darknet-19 | 43.1 | — | 544×544 | 78.6 |
| SSD300[ | VGG-16 | 49.5 | 8 732 | 300×300 | 74.3 |
| SSD300*[ | VGG-16 | 49.5 | 8 732 | 300×300 | 77.2 |
| SSD512[ | VGG-16 | 22.5 | 24 564 | 512×512 | 79.5 |
| RSSD300[ | VGG-16 | 37.6 | 8 732 | 300×300 | 78.5 |
| DSSD321[ | ResNet-101 | 10.1 | 17 080 | 321×321 | 78.6 |
| Proposed | VGG-16 | 37.3 | 8 732 | 300×300 | 79.6 |

图12 SSD与本文算法检测结果对比
Fig.12 Comparison of detection results between SSD and proposed method
| 模型 | mAP/% | 检测速度/(frame/s) |
|---|---|---|
| SSD[ | 72.7 | 49.5 |
| Proposed | 77.4 | 37.3 |
表3 遮挡目标数据集上检测速度和检测精度对比
Table 3 Comparison of detection speed and detection accuracy on occluded objects dataset
| 模型 | mAP/% | 检测速度/(frame/s) |
|---|---|---|
| SSD[ | 72.7 | 49.5 |
| Proposed | 77.4 | 37.3 |

图13 SSD与本文算法遮挡目标的检测结果对比
Fig.13 Comparison of detection results of occluded objects between SSD and proposed method
| [1] | 袁益琴, 何国金, 王桂周, 等. 背景差分与帧间差分相融合的遥感卫星视频运动车辆检测方法[J]. 中国科学院大学学报, 2018, 35(1):50-58. |
| YUAN Y Q, HE G J, WANG G Z, et al. A background sub-traction and frame subtraction combined method for moving vehicle detection in satellite video data[J]. Journal of Univ-ersity of Chinese Academy of Sciences, 2018, 35(1):50-58. | |
| [2] |
LOWE D G. Distinctive image features from scale-invariant keypoints[J]. International Journal of Computer Vision, 2004, 60(2):91-110.
DOI URL |
| [3] | 张晓露, 李玲, 辛云宏. 基于小波变换的自适应多模红外小目标检测[J]. 激光与红外, 2017, 47(5):647-652. |
| ZHANG X L, LI L, XIN Y H. Adaptive multi-mode infrared small target detection based on wavelet transform[J]. Laser and Infrared, 2017, 47(5):647-652. | |
| [4] |
HASTIE T, ROSSET S, ZHU J, et al. Multi-class AdaBoost[J]. Statistics and Its Interface, 2009, 2(3):349-360.
DOI URL |
| [5] | DALAL N, TRIGGS B. Histograms of oriented gradients for human detection[C]//Proceedings of the 2005 IEEE Com-puter Society Conference on Computer Vision and Pattern Recognition, San Diego, Jun 20-25, 2005. Washington: IEEE Computer Society, 2005: 886-893. |
| [6] |
OJALA T, PIETIKAINEN M, MAENPAA T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(7):971-987.
DOI URL |
| [7] |
BURGES C. A tutorial on support vector machines for pattern recognition[J]. Data Mining and Knowledge Discovery, 1998, 2(2):121-167.
DOI URL |
| [8] | MARIN J, VÁZQUEZ D, LÓPEZ A M, et al. Random forests of local experts for pedestrian detection[C]//Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Dec 1-8, 2013. Piscataway: IEEE, 2013: 2592-2599. |
| [9] |
BAEK J, HONG S, KIM J, et al. Efficient pedestrian detec-tion at nighttime using a thermal camera[J]. Sensors, 2017, 17(8):1850.
DOI URL |
| [10] | GOVARDHAN P, PATI U C. NIR image based pedestrian detection in night vision with cascade classification and validation[C]//Proceedings of the 2014 IEEE International Conference on Advanced Communications, Control and Computing Technologies, Ramanathapuram, May 8-10, 2014. Piscataway: IEEE, 2014: 1435-1438. |
| [11] | GIRSHICK R B. Fast R-CNN[J]. arXiv:1504.08083v2, 2015. |
| [12] | REN S, HE K, GIRSHICK R B, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelli-gence, 2017, 39(6):1137-1149. |
| [13] | RAJARAM R N, OHN-BAR E, TRIVEDI M M. RefineNet: iterative refinement for accurate object localization[C]//Pro-ceedings of the 19th International Conference on Intelligent Transportation Systems, Rio de Janeiro, Nov 1-4, 2016. Piscataway: IEEE, 2016: 1528-1533. |
| [14] | REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Piscataway: IEEE, 2016: 779-788. |
| [15] | REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]//Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Piscataway: IEEE, 2017: 6517-6525. |
| [16] | REDMON J, FARHADI A. YOLOv3: an incremental improvement[J]. arXiv:1804.02767, 2018. |
| [17] | LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector[C]//LNCS 9905: Proceedings of the 14th European Conference on Computer Vision, Amsterdam, Oct 11-14, 2016. Cham: Springer, 2016: 21-37. |
| [18] | LIN T Y, GOYAL P, GIRSHICK R B, et al. Focal loss for dense object detection[C]//Proceedings of 2017 IEEE Intern-ational Conference on Computer Vision, Venice, Oct 22-29, 2017. Washington: IEEE Computer Society, 2017: 2999-3007. |
| [19] | LIN T Y, DOLLÁR P, GIRSHICK R B, et al. Feature pyramid networks for object detection[C]//Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 936-944. |
| [20] | LIU S, QI L, QIN H F, et al. Path aggregation network for instance segmentation[C]//Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-23, 2018. Washington: IEEE Computer Society, 2018: 8759-8768. |
| [21] | JI Z, KONG Q K, WANG H R, et al. Small and dense commodity object detection with multi-scale receptive field attention[C]//Proceedings of the 27th ACM International Conference on Multimedia, Nice, Oct 21-25, 2019. New York: ACM, 2019: 1349-1357. |
| [22] | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[J]. arXiv:1409. 1556, 2014. |
| [23] |
LIANG S, GU Y. Computer-aided diagnosis of Alzheimer’s disease through weak supervision deep learning framework with attention mechanism[J]. Sensors, 2021, 21(1):220.
DOI URL |
| [24] |
CHEN L F, WENG T, XING J, et al. A new deep learning network for automatic bridge detection from SAR images based on balanced and attention mechanism[J]. Remote Sensing, 2020, 12(3):441.
DOI URL |
| [25] | HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]//Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 2011-2023. |
| [26] | JADERBERG M, SIMONYAN K, ZISSERMAN A, et al. Spatial transformer networks[J]. arXiv:1506.02025, 2015. |
| [27] | WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C]//LNCS 11211: Proceedings of the 15th European Conference on Computer Vision, Munich, Sep 8-14, 2018. Cham: Springer, 2018: 3-19. |
| [28] | WANG Q L, WU B G, ZHU P F, et al. ECA-Net: efficient channel attention for deep convolutional neural networks[C]//Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 11531-11539. |
| [29] | WANG C Y, LIAO H Y M, WU Y H, et al. CSPNet: a new backbone that can enhance learning capability of CNN[C]//Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 1571-1580. |
| [30] | FU C Y, LIU W, RANGA A, et al. DSSD: deconvolutional single shot detector[J]. arXiv:1701.06659, 2017. |
| [31] | BELL S, ZITNICK C L, BALA K, et al. Inside-Outside net: detecting objects in context with skip pooling and recurrent neural networks[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 2874-2883. |
| [32] | DAI J F, LI Y, HE K M, et al. R-FCN: object detection via region-based fully convolutional networks[C]//Proceedings of the Annual Conference on Neural Information Processing Systems, Barcelona, Dec 5-10, 2016. Red Hook: Curran Associates, 2016: 379-387. |
| [33] | JEONG J, PARK H, KWAK N. Enhancement of SSD by concatenating feature maps for object detection[J]. arXiv:1705.09587, 2017. |
| [1] | 安凤平, 李晓薇, 曹翔. 权重初始化-滑动窗口CNN的医学图像分类[J]. 计算机科学与探索, 2022, 16(8): 1885-1897. |
| [2] | 曾凡智, 许露倩, 周燕, 周月霞, 廖俊玮. 面向智慧教育的知识追踪模型研究综述[J]. 计算机科学与探索, 2022, 16(8): 1742-1763. |
| [3] | 刘艺, 李蒙蒙, 郑奇斌, 秦伟, 任小广. 视频目标跟踪算法综述[J]. 计算机科学与探索, 2022, 16(7): 1504-1515. |
| [4] | 赵小明, 杨轶娇, 张石清. 面向深度学习的多模态情感识别研究进展[J]. 计算机科学与探索, 2022, 16(7): 1479-1503. |
| [5] | 夏鸿斌, 肖奕飞, 刘渊. 融合自注意力机制的长文本生成对抗网络模型[J]. 计算机科学与探索, 2022, 16(7): 1603-1610. |
| [6] | 彭豪, 李晓明. 多尺度选择金字塔网络的小样本目标检测算法[J]. 计算机科学与探索, 2022, 16(7): 1649-1660. |
| [7] | 刘雅芬, 郑艺峰, 江铃燚, 李国和, 张文杰. 深度半监督学习中伪标签方法综述[J]. 计算机科学与探索, 2022, 16(6): 1279-1290. |
| [8] | 孙方伟, 李承阳, 谢永强, 李忠博, 杨才东, 齐锦. 深度学习应用于遮挡目标检测算法综述[J]. 计算机科学与探索, 2022, 16(6): 1243-1259. |
| [9] | 董文轩, 梁宏涛, 刘国柱, 胡强, 于旭. 深度卷积应用于目标检测算法综述[J]. 计算机科学与探索, 2022, 16(5): 1025-1042. |
| [10] | 程卫月, 张雪琴, 林克正, 李骜. 融合全局与局部特征的深度卷积神经网络算法[J]. 计算机科学与探索, 2022, 16(5): 1146-1154. |
| [11] | 钟梦圆, 姜麟. 超分辨率图像重建算法综述[J]. 计算机科学与探索, 2022, 16(5): 972-990. |
| [12] | 伏轩仪, 张銮景, 梁文科, 毕方明, 房卫东. 锚点机制在目标检测领域的发展综述[J]. 计算机科学与探索, 2022, 16(4): 791-805. |
| [13] | 赵鹏飞, 谢林柏, 彭力. 融合注意力机制的深层次小目标检测算法[J]. 计算机科学与探索, 2022, 16(4): 927-937. |
| [14] | 许嘉, 韦婷婷, 于戈, 黄欣悦, 吕品. 题目难度评估方法研究综述[J]. 计算机科学与探索, 2022, 16(4): 734-759. |
| [15] | 裴利沈, 赵雪专. 群体行为识别深度学习方法研究综述[J]. 计算机科学与探索, 2022, 16(4): 775-790. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||