
计算机科学与探索 ›› 2022, Vol. 16 ›› Issue (3): 489-511.DOI: 10.3778/j.issn.1673-9418.2107076
刘颖1,2,3,+( ), 郭莹莹1, 房杰1,2,3, 范九伦1,3, 郝羽1,3, 刘继明4
), 郭莹莹1, 房杰1,2,3, 范九伦1,3, 郝羽1,3, 刘继明4
收稿日期:2021-07-21
修回日期:2021-09-23
出版日期:2022-03-01
发布日期:2021-09-23
通讯作者:
+ E-mail: liuying_ciip@163.com作者简介:刘颖(1972—),女,陕西户县人,博士,教授,主要研究方向为图像检索、图像增强等。基金资助:
LIU Ying1,2,3,+(), GUO Yingying1, FANG Jie1,2,3, FAN Jiulun1,3, HAO Yu1,3, LIU Jiming4
Received:2021-07-21
Revised:2021-09-23
Online:2022-03-01
Published:2021-09-23
About author:LIU Ying, born in 1972, Ph.D., professor. Her research interests include image retrieval, image enhancement, etc.Supported by:摘要:
随着深度神经网络的兴起,多模态学习受到广泛关注。跨模态检索是多模态学习的重要分支,其目的在于挖掘不同模态样本之间的关系,即通过一种模态样本来检索具有近似语义的另一种模态样本。近年来,跨模态检索逐渐成为国内外学术界研究的前沿和热点,是信息检索领域未来发展的重要方向。首先,聚焦于深度学习跨模态图文检索研究的最新进展,对基于实值表示学习和基于二进制表示学习方法的发展动态进行了详细介绍,其中,基于实值表示的方法用于提升跨模态语义相关性,进而提高跨模态检索准确度,基于二进制表示学习的方法用于提升跨模态图文检索效率,减小存储空间;其次,总结了跨模态检索领域常用的公开数据集,对比了不同算法在不同数据集上的性能表现;此外,总结并分析了跨模态图文检索技术在公安、传媒及医学等领域的具体应用情况;最后,结合现有技术探讨了该领域的发展趋势及未来研究方向。
中图分类号:
刘颖, 郭莹莹, 房杰, 范九伦, 郝羽, 刘继明. 深度学习跨模态图文检索研究综述[J]. 计算机科学与探索, 2022, 16(3): 489-511.
LIU Ying, GUO Yingying, FANG Jie, FAN Jiulun, HAO Yu, LIU Jiming. Survey of Research on Deep Learning Image-Text Cross-Modal Retrieval[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(3): 489-511.

图1 多模态、跨模态检索和跨模态图文检索关系图
Fig.1 Relationship among multi-modal retrieval, cross-modal retrieval and image-text cross-modal retrieval

图2 基于深度学习的跨模态图文检索的研究现状分类图示
Fig.2 Research status of image-text cross-modal retrieval based on deep learning

图3 IMRAM模型框架
Fig.3 Framework of IMRAM model
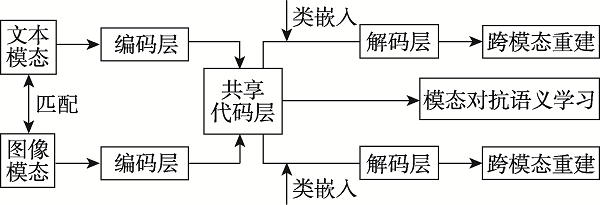
图4 MASLN模型框架
Fig.4 Framework of MASLN model

图5 CyTIR-Net网络架构
Fig.5 Network architecture of CyTIR-Net

图6 多义视觉语义嵌入体系结构
Fig.6 Architecture of polysemous visual-semantic embedding
| 类别 | 代表性方法 | 特点 | 适用场景 |
|---|---|---|---|
| 基于特征表示的方法 | MSDS | 能够更有效地提取文本特征,但对于样本数量较少的情况性能较差 | 大规模数据集 |
| DeCAF | 学习到的视觉特征具有足够的表征能力 | 单标签或多标签样本图文跨模态检索 | |
| deep-SM | 提高了对目标数据集的适应性,有效降低了图像与相应语义概念之间的鸿沟,但未能良好建立文本数据的低级特征和高级语义间的关系 |
表1 基于特征表示的代表性方法总结
Table 1 Summary of representative methods based on feature representation
| 类别 | 代表性方法 | 特点 | 适用场景 |
|---|---|---|---|
| 基于特征表示的方法 | MSDS | 能够更有效地提取文本特征,但对于样本数量较少的情况性能较差 | 大规模数据集 |
| DeCAF | 学习到的视觉特征具有足够的表征能力 | 单标签或多标签样本图文跨模态检索 | |
| deep-SM | 提高了对目标数据集的适应性,有效降低了图像与相应语义概念之间的鸿沟,但未能良好建立文本数据的低级特征和高级语义间的关系 |
| 类别 | 代表性方法 | 特点 | 适用场景 |
|---|---|---|---|
| 图像-文本对齐的方法 | Neural-Image-QA | 减少了爆炸梯度问题,且“单字”变体能使获得的准确率翻倍,实现最佳性能,但答案较长时准确率会迅速下降,且在训练数据点太少或图像有强遮挡等情况时容易匹配失败 | 现实世界的图像问答 任务 |
| FashionBERT | 可掩盖图像中的不相关信息,且补丁能提供不重复且合理相关的信息,但需要大量带注释的图像文本对,在实际场景中不易获得 | 细粒度的跨模态图文检索任务 | |
| CAAN | 检索速度快,模型小,在部署和应用上更方便实用,然而模态间比对和模态内相关性的结合要求更精细的模型设计 | 单词或图像区域在不同全局上下文中多种语义 | |
| IMRAM | 对小规模和大规模数据集都能达到最佳性能,具有鲁棒性 | 考虑语义复杂性的跨模态检索任务 | |
| 跨模态重构的方法 | SC-NLM | 训练模型后可在图像嵌入上对模型调节,且能够不断优化对生成新描述的评分函数,实现对图像和字幕的排序;但不能动态修改用于调节解码器的向量 | 解决图像字幕生成问题 |
| MASLN | 能够有效缩小不同模态间的统计差距,最大化语义区分能力,但训练模型可能不能很好地反映公共表示中目标集的成对相关性 | 可扩展跨模态检索任务 | |
| CyTIR-Net | 在中小型数据集情况下表现更好,且在训练数据稀缺时能够增强最终检索性能,无需额外注释成本,但在某些情况下无法检索到模态间对应的所有细节信息 | 中小型数据集 | |
| 图文联合嵌入的方法 | RE-DNN | 仅需要很少的模型训练先验知识,同时能解决模态缺失问题,且对大规模数据集可扩展 | 多媒体信息检索系统 |
| PVSE | 克服了被忽略信息在映射点丢失后无法恢复的问题 | 多义实例问题 | |
| GXN | 能够检索具有局部相似性的图像或具有词级相似性的句子 |
表2 基于图文匹配的代表性方法总结
Table 2 Summary of representative methods based on image-text matching
| 类别 | 代表性方法 | 特点 | 适用场景 |
|---|---|---|---|
| 图像-文本对齐的方法 | Neural-Image-QA | 减少了爆炸梯度问题,且“单字”变体能使获得的准确率翻倍,实现最佳性能,但答案较长时准确率会迅速下降,且在训练数据点太少或图像有强遮挡等情况时容易匹配失败 | 现实世界的图像问答 任务 |
| FashionBERT | 可掩盖图像中的不相关信息,且补丁能提供不重复且合理相关的信息,但需要大量带注释的图像文本对,在实际场景中不易获得 | 细粒度的跨模态图文检索任务 | |
| CAAN | 检索速度快,模型小,在部署和应用上更方便实用,然而模态间比对和模态内相关性的结合要求更精细的模型设计 | 单词或图像区域在不同全局上下文中多种语义 | |
| IMRAM | 对小规模和大规模数据集都能达到最佳性能,具有鲁棒性 | 考虑语义复杂性的跨模态检索任务 | |
| 跨模态重构的方法 | SC-NLM | 训练模型后可在图像嵌入上对模型调节,且能够不断优化对生成新描述的评分函数,实现对图像和字幕的排序;但不能动态修改用于调节解码器的向量 | 解决图像字幕生成问题 |
| MASLN | 能够有效缩小不同模态间的统计差距,最大化语义区分能力,但训练模型可能不能很好地反映公共表示中目标集的成对相关性 | 可扩展跨模态检索任务 | |
| CyTIR-Net | 在中小型数据集情况下表现更好,且在训练数据稀缺时能够增强最终检索性能,无需额外注释成本,但在某些情况下无法检索到模态间对应的所有细节信息 | 中小型数据集 | |
| 图文联合嵌入的方法 | RE-DNN | 仅需要很少的模型训练先验知识,同时能解决模态缺失问题,且对大规模数据集可扩展 | 多媒体信息检索系统 |
| PVSE | 克服了被忽略信息在映射点丢失后无法恢复的问题 | 多义实例问题 | |
| GXN | 能够检索具有局部相似性的图像或具有词级相似性的句子 |
| 类别 | 代表性方法 | 特点 | 适用场景 |
|---|---|---|---|
| 二进制表示学习方法 | DVSH | 有效克服了传统融合网络对双峰对象联合嵌入的需求,对参数选择具有鲁棒性 | 适用高精度,同时能容忍较少最佳检索结果的应用程序 |
| DCMH | 直接学习离散的哈希码,避免了对所学习哈希码准确性的降低,但所需训练时间长 | 大规模数据集上的人工神经网络搜索 | |
| SSAH | 训练时间短,可捕获更精确的模态间相关性 | ||
| CYC-DGH | 可以有效压缩输入数据,同时能最大限度地保留其自身信息及来自不同模态的样本间关系 | 有限数量标记样本的跨模态检索任务 |
表3 二进制表示学习代表性方法总结
Table 3 Summary of representative methods of binary representation learning
| 类别 | 代表性方法 | 特点 | 适用场景 |
|---|---|---|---|
| 二进制表示学习方法 | DVSH | 有效克服了传统融合网络对双峰对象联合嵌入的需求,对参数选择具有鲁棒性 | 适用高精度,同时能容忍较少最佳检索结果的应用程序 |
| DCMH | 直接学习离散的哈希码,避免了对所学习哈希码准确性的降低,但所需训练时间长 | 大规模数据集上的人工神经网络搜索 | |
| SSAH | 训练时间短,可捕获更精确的模态间相关性 | ||
| CYC-DGH | 可以有效压缩输入数据,同时能最大限度地保留其自身信息及来自不同模态的样本间关系 | 有限数量标记样本的跨模态检索任务 |
| 数据集名称 | 年份 | 图像数量 | 图像对应标签数量 | 文本(标签)数量 | 介绍 | 来源 | 示例图像-文本对 |
|---|---|---|---|---|---|---|---|
| NUS-WIDE[ | 2009 | 269 648(删除重复图像后) | 2~5 | 5 108(去掉无意义标签后) | 多标签定义图像 | 新加坡国立大学 多媒体检索实验室 | |
| MSCOCO[ | 2014 | 123 287 | 5 | 616 435 | 图像描述 | 微软公司 | |
| Flickr30k[ | 2014 | 31 783 | 5 | 158 915 | 图像描述 | 雅虎网站 | |
| Wikipedia[ | 2014 | 2 866 | 1 | 2 866 | 图像/文本数据对 | 维基百科网站 | |
| IAPRTC-12[ | 2006 | 19 627 | 1~5 | 4 576 | 多标签定义图像 | CLEF |
表4 常用数据集介绍
Table 4 Introduction of common datasets
| 数据集名称 | 年份 | 图像数量 | 图像对应标签数量 | 文本(标签)数量 | 介绍 | 来源 | 示例图像-文本对 |
|---|---|---|---|---|---|---|---|
| NUS-WIDE[ | 2009 | 269 648(删除重复图像后) | 2~5 | 5 108(去掉无意义标签后) | 多标签定义图像 | 新加坡国立大学 多媒体检索实验室 | |
| MSCOCO[ | 2014 | 123 287 | 5 | 616 435 | 图像描述 | 微软公司 | |
| Flickr30k[ | 2014 | 31 783 | 5 | 158 915 | 图像描述 | 雅虎网站 | |
| Wikipedia[ | 2014 | 2 866 | 1 | 2 866 | 图像/文本数据对 | 维基百科网站 | |
| IAPRTC-12[ | 2006 | 19 627 | 1~5 | 4 576 | 多标签定义图像 | CLEF |

图7 不同数据集图像文本对示例图
Fig.7 Sample graph of image-text pairs in different datasets
| 模型 | 文本检索 | 图像检索 | ||||
|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |
| BRNN[ | — | — | — | 15.2 | 37.7 | 50.0 |
| SCAN[ | 67.4 | 90.3 | 95.8 | 48.6 | 77.7 | 85.2 |
| CAAN[ | 70.1 | 91.6 | 97.2 | 52.8 | 79.0 | 87.9 |
| IMRAM[ | 74.1 | 93.0 | 96.6 | 53.9 | 79.4 | 87.2 |
| CyTIR-Net[ | 36.9 | 67.8 | 79.2 | 21.6 | 51.8 | 65.5 |
表5 对于Flickr30k现有不同算法 R@K比较
Table 5 R @ Kcomparison of different existing algorithms for Flickr30k
| 模型 | 文本检索 | 图像检索 | ||||
|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |
| BRNN[ | — | — | — | 15.2 | 37.7 | 50.0 |
| SCAN[ | 67.4 | 90.3 | 95.8 | 48.6 | 77.7 | 85.2 |
| CAAN[ | 70.1 | 91.6 | 97.2 | 52.8 | 79.0 | 87.9 |
| IMRAM[ | 74.1 | 93.0 | 96.6 | 53.9 | 79.4 | 87.2 |
| CyTIR-Net[ | 36.9 | 67.8 | 79.2 | 21.6 | 51.8 | 65.5 |
| 模型 | 文本检索 | 图像检索 | ||||
|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |
| BRNN[ | — | — | — | 27.4 | 60.2 | 74.8 |
| SCAN[ | 72.7 | 94.8 | 98.4 | 58.8 | 88.4 | 94.8 |
| CAAN[ | 75.5 | 95.4 | 98.5 | 61.3 | 89.7 | 95.2 |
| IMRAM[ | 76.7 | 95.6 | 98.5 | 61.7 | 89.1 | 95.0 |
| CyTIR-Net[ | 44.7 | 78.0 | 88.1 | 28.9 | 63.8 | 79.4 |
| PVSE[ | 55.2 | 86.5 | 93.7 | 69.2 | 91.6 | 96.6 |
| GXN[ | 56.6 | — | 94.5 | 68.5 | — | 97.9 |
表6 对于MSCOCO现有不同算法 R@ K比较(1 000幅测试图像)
Table 6 R @ Kcomparison of different existing algorithms for MSCOCO (1000 test images)
| 模型 | 文本检索 | 图像检索 | ||||
|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |
| BRNN[ | — | — | — | 27.4 | 60.2 | 74.8 |
| SCAN[ | 72.7 | 94.8 | 98.4 | 58.8 | 88.4 | 94.8 |
| CAAN[ | 75.5 | 95.4 | 98.5 | 61.3 | 89.7 | 95.2 |
| IMRAM[ | 76.7 | 95.6 | 98.5 | 61.7 | 89.1 | 95.0 |
| CyTIR-Net[ | 44.7 | 78.0 | 88.1 | 28.9 | 63.8 | 79.4 |
| PVSE[ | 55.2 | 86.5 | 93.7 | 69.2 | 91.6 | 96.6 |
| GXN[ | 56.6 | — | 94.5 | 68.5 | — | 97.9 |
| 模型 | 文本检索 | 图像检索 | ||||
|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |
| BRNN[ | — | — | — | 10.7 | 29.6 | 42.2 |
| SCAN[ | 50.4 | 82.2 | 90.0 | 38.6 | 69.3 | 80.4 |
| CAAN[ | 52.5 | 83.3 | 90.9 | 41.2 | 70.3 | 82.9 |
| IMRAM[ | 53.7 | 83.2 | 91.0 | 39.7 | 69.1 | 79.8 |
| PVSE[ | 32.4 | 63.0 | 75.0 | 45.2 | 74.3 | 84.5 |
| GXN[ | 31.7 | — | 74.6 | 42.0 | — | 84.7 |
表7 对于MSCOCO现有不同算法 R@ K比较(5 000幅测试图像)
Table 7 R @ Kcomparison of different existing algorithms for MSCOCO (5000 test images)
| 模型 | 文本检索 | 图像检索 | ||||
|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |
| BRNN[ | — | — | — | 10.7 | 29.6 | 42.2 |
| SCAN[ | 50.4 | 82.2 | 90.0 | 38.6 | 69.3 | 80.4 |
| CAAN[ | 52.5 | 83.3 | 90.9 | 41.2 | 70.3 | 82.9 |
| IMRAM[ | 53.7 | 83.2 | 91.0 | 39.7 | 69.1 | 79.8 |
| PVSE[ | 32.4 | 63.0 | 75.0 | 45.2 | 74.3 | 84.5 |
| GXN[ | 31.7 | — | 74.6 | 42.0 | — | 84.7 |
| 模型 | 文本查询 | 图像查询 | 平均值 |
|---|---|---|---|
| ACMR[ | 0.871 0 | 0.932 0 | 0.902 0 |
| DVSH[ | 0.767 3 | 0.755 2 | 0.761 3 |
| SSAH[ | 0.578 0 | 0.577 0 | 0.578 0 |
| CYC-DGH[ | 0.859 0 | 0.781 0 | 0.820 0 |
表8 对于MSCOCO现有不同算法MAP比较
Table 8 MAP comparison of different existing algorithms for MSCOCO
| 模型 | 文本查询 | 图像查询 | 平均值 |
|---|---|---|---|
| ACMR[ | 0.871 0 | 0.932 0 | 0.902 0 |
| DVSH[ | 0.767 3 | 0.755 2 | 0.761 3 |
| SSAH[ | 0.578 0 | 0.577 0 | 0.578 0 |
| CYC-DGH[ | 0.859 0 | 0.781 0 | 0.820 0 |
| 模型 | 文本查询 | 图像查询 | 平均值 |
|---|---|---|---|
| SCM (semantic correlation matching)[ | 0.226 | 0.227 | 0.252 |
| deep-SM[ | 0.354 | 0.398 | 0.376 |
| MSFN+TextNet[ | 0.453 | 0.518 | 0.486 |
| MASLN[ | 0.499 | 0.623 | 0.561 |
| MASLN[ | 0.287 | 0.331 | 0.309 |
| DSCMR[ | 0.478 | 0.521 | 0.499 |
| ACMR[ | 0.489 | 0.619 | 0.546 |
| CYC-DGH[ | 0.826 | 0.820 | 0.823 |
表9 对于Wikipedia现有不同算法MAP比较
Table 9 MAP comparison of different existing algorithms for Wikipedia
| 模型 | 文本查询 | 图像查询 | 平均值 |
|---|---|---|---|
| SCM (semantic correlation matching)[ | 0.226 | 0.227 | 0.252 |
| deep-SM[ | 0.354 | 0.398 | 0.376 |
| MSFN+TextNet[ | 0.453 | 0.518 | 0.486 |
| MASLN[ | 0.499 | 0.623 | 0.561 |
| MASLN[ | 0.287 | 0.331 | 0.309 |
| DSCMR[ | 0.478 | 0.521 | 0.499 |
| ACMR[ | 0.489 | 0.619 | 0.546 |
| CYC-DGH[ | 0.826 | 0.820 | 0.823 |
| 模型 | 文本查询 | 图像查询 | 平均值 |
|---|---|---|---|
| DeCAF[ | 0.409 | 0.486 | 0.448 |
| deep-SM[ | 0.776 | 0.823 | 0.800 |
| MSFN+TextNet[ | 0.453 | 0.518 | 0.486 |
| MASLN[ | 0.552 | 0.550 | 0.551 |
| MASLN[ | 0.284 | 0.291 | 0.287 |
| DSCMR[ | 0.615 | 0.611 | 0.613 |
| ACMR[ | 0.538 | 0.544 | 0.541 |
| DCMH[ | 0.691 | 0.644 | 0.667 |
| SSAH[ | 0.683 | 0.639 | 0.661 |
表10 对于NUS-WIDE现有不同算法MAP比较
Table 10 MAP comparison of different existing algorithms for NUS-WIDE
| 模型 | 文本查询 | 图像查询 | 平均值 |
|---|---|---|---|
| DeCAF[ | 0.409 | 0.486 | 0.448 |
| deep-SM[ | 0.776 | 0.823 | 0.800 |
| MSFN+TextNet[ | 0.453 | 0.518 | 0.486 |
| MASLN[ | 0.552 | 0.550 | 0.551 |
| MASLN[ | 0.284 | 0.291 | 0.287 |
| DSCMR[ | 0.615 | 0.611 | 0.613 |
| ACMR[ | 0.538 | 0.544 | 0.541 |
| DCMH[ | 0.691 | 0.644 | 0.667 |
| SSAH[ | 0.683 | 0.639 | 0.661 |
| 模型 | 文本查询 | 图像查询 |
|---|---|---|
| DVSH[ | 0.680 6 | 0.723 6 |
| CYC-DGH[ | 0.837 0 | 0.832 0 |
表11 对于IAPRTC-12现有不同算法MAP比较
Table 11 MAP comparison of different existing algorithms for IAPRTC-12
| 模型 | 文本查询 | 图像查询 |
|---|---|---|
| DVSH[ | 0.680 6 | 0.723 6 |
| CYC-DGH[ | 0.837 0 | 0.832 0 |
| 模型 | 文本检索 | 图像检索 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| top@1 | top@2 | top@10 | top@20 | top@100 | top@1 | top@2 | top@10 | top@20 | top@100 | |
| MSDS[ | 0.256 0 | 0.364 0 | 0.626 0 | 0.740 0 | 0.921 0 | 0.255 0 | 0.362 0 | 0.633 0 | 0.742 0 | 0.919 0 |
| DBRLM [ | 0.207 0 | 0.296 0 | 0.557 0 | 0.673 0 | 0.895 0 | 0.201 0 | 0.292 0 | 0.567 0 | 0.682 0 | 0.904 0 |
表12 对于IAPRTC-12现有不同算法 top@ k比较
Table 12 top@ k comparison of different existing algorithms for IAPRTC-12
| 模型 | 文本检索 | 图像检索 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| top@1 | top@2 | top@10 | top@20 | top@100 | top@1 | top@2 | top@10 | top@20 | top@100 | |
| MSDS[ | 0.256 0 | 0.364 0 | 0.626 0 | 0.740 0 | 0.921 0 | 0.255 0 | 0.362 0 | 0.633 0 | 0.742 0 | 0.919 0 |
| DBRLM [ | 0.207 0 | 0.296 0 | 0.557 0 | 0.673 0 | 0.895 0 | 0.201 0 | 0.292 0 | 0.567 0 | 0.682 0 | 0.904 0 |
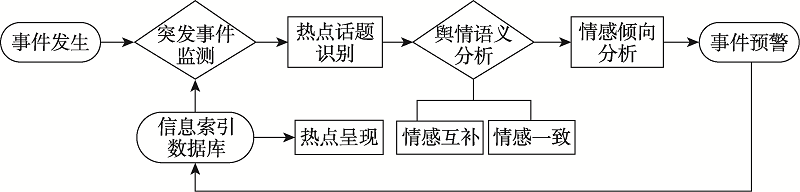
图8 舆情分析一般流程图
Fig.8 General flow chart of public opinion analysis

图9 图文特征联合的证据图像检索系统工作原理图
Fig.9 Schematic diagram of evidence image retrieval system based on combination of image and text features
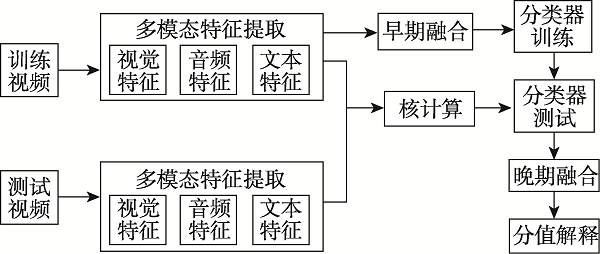
图10 多媒体事件检测系统示意图
Fig.10 Schematic diagram of multimedia event detection system

图11 基于模态网络模型的医学数据检索技术流程图
Fig.11 Flow chart of medical data retrieval based on modal network model
| [1] |
MCGURK H, MACDONALD H. Hearing lips and seeing voices[J]. Nature, 1976, 264(5588): 746-748.
DOI URL |
| [2] | ATREY P K, HOSSAIN M A, SADDIK A EI, et al. Multi-modal fusion for multimedia analysis: a survey[J]. Multi-media Systems, 2010, 16(6): 345-379. |
| [3] |
JIANG X, WU F, ZHANG Y, et al. The classification of multi-modal data with hidden conditional random field[J]. Pattern Recognition Letters, 2015, 51: 63-69.
DOI URL |
| [4] | WANG D X, CUI P, OU M D, et al. Deep multimodal Hash-ing with orthogonal regularization[C]// Proceedings of the 24th International Joint Conference on Artificial Intelligence, Buenos Aires, Jul 25-31, 2015. Menlo Park: AAAI, 2015: 2291-2297. |
| [5] | BALTRUSAITIS T, AHUJA C, MORENCY L P. Multimodal machine learning: a survey and taxonomy[J]. IEEE Transac-tions on Pattern Analysis and Machine Intelligence, 2019, 41(2): 423-443. |
| [6] | RAMACHANDRAM D, TAYLOR G W. Deep multimodal learning: a survey on recent advances and trends[J]. IEEE Signal Processing Magazine, 2017, 34(6): 96-108. |
| [7] | 欧卫华, 刘彬, 周永辉, 等. 跨模态检索研究综述[J]. 贵州师范大学学报(自然科学版), 2018, 36(2): 114-120. |
| OU W H, LIU B, ZHOU Y H, et al. Survey on the cross-modal retrieval research[J]. Journal of Guizhou Normal Uni-versity (Natural Sciences), 2018, 36(2): 114-120. | |
| [8] | WANG J, HE Y H, KANG C C, et al. Image-text cross-modal retrieval via modality-specific feature learning[C]// Proceed-ings of the 5th ACM on International Conference on Multi-media Retrieval, Shanghai, Jun 23-26, 2015. New York: ACM, 2015: 347-354. |
| [9] |
OTTO C, SPRINGSTEIN M, ANAND A, et al. Characteri-zation and classification of semantic image-text relations[J]. International Journal of Multimedia Information Retrieval, 2020, 9(1): 31-45.
DOI URL |
| [10] |
HAROLD H. Relations between two sets of variates[J]. Biometrika, 1936, 28(3): 321-377.
DOI URL |
| [11] | LI D G, DIMITROVA N, LI M K, et al. Multimedia content processing through cross-modal association[C]// Proceedings of the 11th ACM International Conference on Multimedia, Berkeley, Nov 2-8, 2003. New York: ACM, 2003: 604-611. |
| [12] | RASIWASIA N, PEREIRA J C, COVIELLO E, et al. A new approach to cross-modal multimedia retrieval[C]// Proceed-ings of the 18th International Conference on Firenze, Oct 25-29, 2010. New York: ACM, 2010: 251-260. |
| [13] |
JI Z Y, YAO W N, WEI W, et al. Deep multi-level semantic Hashing for cross-modal retrieval[J]. IEEE Access, 2019, 7: 23667-23674.
DOI URL |
| [14] | WANG C, YANG H J, MEINEL C. Deep semantic mapping for cross-modal retrieval[C]// Proceedings of the 27th Inter-national Conference on Tools with Artificial Intelligence, Vietri sul Mare, Nov 9-11, 2015. Washington: IEEE Computer Society, 2015: 234-241. |
| [15] | FENG F X, WANG X J, LI R F. Cross-modal retrieval with correspondence autoencoder[C]// Proceedings of the 2014 ACM International Conference on Multimedia, Orlando, Nov 3-7, 2014. New York: ACM, 2014: 7-16. |
| [16] | 冯方向. 基于深度学习的跨模态检索研究[D]. 北京: 北京邮电大学, 2015. |
| FENG F X. Deep learning for cross-modal retrieval[D]. Bei-jing: Beijing University of Posts and Telecommunications, 2015. | |
| [17] | WANG K, YIN Q, WANG W, et al. A comprehensive survey on cross-modal retrieval[J]. arXiv:1607.06215, 2016. |
| [18] |
PENG Y, HUANG X, ZHAO Y. An overview of cross-media retrieval: concepts, methodologies, benchmarks, and chall-enges[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2018, 28(9): 2372-2385.
DOI URL |
| [19] | 李志义, 黄子风, 许晓绵. 基于表示学习的跨模态检索模型与特征抽取研究综述[J]. 情报学报, 2018, 37(4): 422-435. |
| LI Z Y, HUANG Z F, XU X M. A review of the cross-modal retrieval model and feature extraction based on representa-tion learning[J]. Journal of the China Society for Scientific and Technical Information, 2018, 37(4): 422-435. | |
| [20] | AYYAVARAIAH M, VENKATESWARLU B. Joint graph regularization based semantic analysis for cross-media retri-eval: a systematic review[J]. International Journal of Eng-ineering & Technology, 2018, 7: 257-261. |
| [21] | AYYAVARAIAH M, VENKATESWARLU B. Cross media feature retrieval and optimization: a contemporary review of research scope, challenges and objectives[C]// Proceedings of the 3rd International Conference on Computational Vision and Bio Inspired Computing, Coimbatore, Sep 25-26, 2019. Cham: Springer, 2019: 1125-1136. |
| [22] | 邵杰. 基于深度学习的跨模态检索[D]. 北京: 北京邮电大学, 2017. |
| SHAO J. Cross-modal retrieval based on deep learning[D]. Beijing: Beijing University of Posts and Telecommunica-tions, 2017. | |
| [23] | 赵天. 基于深度学习的跨模态图文检索方法研究[D]. 桂林: 桂林电子科技大学, 2019. |
| ZHAO T. Research on the method of cross-modal image and text retrieval based on deep learning[D]. Guilin: Guilin University of Electronic Technology, 2019. | |
| [24] |
KAUR P, PANNU H S, MALHI A K. Comparative analysis on cross-modal information retrieval: a review[J]. Computer Science Review, 2021, 39(2): 100336.
DOI URL |
| [25] |
HINTON G E, SALAKHUTDINOV R R. Reducing the dimensionality of data with neural networks[J]. Science, 2006, 313(5786): 504-507.
DOI URL |
| [26] |
HINTON G E, OSINDERO S, TEH Y W. A fast learning algorithm for deep belief nets[J]. Neural Computation, 2014, 18(7): 1527-1554.
DOI URL |
| [27] | SRIVASTAVA N, SALAHUTDINOV R. Multimodal learn-ing with deep Boltzmann machines[C]// Proceedings of the 26th Annual Conference on Neural Information Processing Systems, Lake Tahoe, Dec 3-6, 2012. Red Hook: Curran Asso-ciates, 2012: 2231-2239. |
| [28] | HERMANN K M, KOCISKÝ T, GREFENSTETTE E, et al. Teaching machines to read and comprehend[C]// Proceedings of the Annual Conference on Neural Information Processing Systems, Montreal, Dec 7-12, 2015. Red Hook: Curran Asso-ciates, 2015: 1693-1701. |
| [29] | MAO J H, XU W, YANG Y, et al. Explain images with multi-modal recurrent neural networks[J]. arXiv:1410.1090, 2014. |
| [30] | GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]// Proceedings of the 27th In-ternational Conference on Neural Information Processing Systems, Montreal, Dec 8-13, 2014. Red Hook: Curran Asso-ciates, 2014: 2672-2680. |
| [31] |
LECUN Y, BOTTOU L, BEBGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.
DOI URL |
| [32] | GOODFELLOW I, BENGIO Y, COURVILLE A. Deep learning[M]. Cambridge: MIT Press, 2016. |
| [33] |
GU J X, WANG Z H, KUEN J, et al. Recent advances in convolutional neural networks[J]. Pattern Recognition, 2018, 77: 354-377.
DOI URL |
| [34] |
KRIZHEVSKY A, SUTSKEVER I, HINTON G. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84-90.
DOI URL |
| [35] | SZEGEDY C, LIU W, JIA Y Q, et al. Going deeper with convolutions[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, Jun 7-12, 2015. Washington: IEEE Computer Society, 2015: 1-9. |
| [36] | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[J]. arXiv:1409.1556, 2014. |
| [37] | XIE S N, GIRSHICK R B, DOLLAR P, et al. Aggregated residual transformations for deep neural networks[C]// Pro-ceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Wash-ington: IEEE Computer Society, 2017: 1492-1500. |
| [38] | HUANG G, LIU Z, VAN DER MAATEN L, et al. Densely connected convolutional networks[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 2261-2269. |
| [39] | JIA Y Q, SHELHAMER E, DONAHUE J, et al. Caffe: con-volutional architecture for fast feature embedding[C]// Pro-ceedings of the 22nd ACM International Conference on Multi-media, Orlando, Nov 3-7, 2014. New York: ACM, 2014: 675-678. |
| [40] | PASZKE A, GROSS S, MASSA F, et al. PyTorch: an imper-ative style, high-performance deep learning library[C]// Pro-ceedings of the Annual Conference on Neural Information Processing Systems, Vancouver, Dec 8-14, 2019: 8026-8037. |
| [41] | ABADI M, AGARWAL A, BARHAM P, et al. TensorFlow: large-scale machine learning on heterogeneous distributed systems[J]. arXiv:1603.04467, 2016. |
| [42] |
HOCHREITER S, SCHMIDHUBER J. Long short-term me-mory[J]. Neural Computation, 1997, 9(8): 1735-1780.
DOI URL |
| [43] |
SCHUSTER M, PALIWAL K K. Bidirectional recurrent ne-ural networks[J]. IEEE Transactions on Signal Processing, 1997, 45(11): 2673-2681.
DOI URL |
| [44] | KIM Y. Convolutional neural networks for sentence classifi-cation[J]. arXiv:1408.5882, 2014. |
| [45] |
GIRSHICK R, DONAHUE J, DARRELL T, et al. Region-based convolutional networks for accurate object detection and segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 38(1): 142-158.
DOI URL |
| [46] | HE Y, XIANG S, KANG C, et al. Cross-modal retrieval via deep and bidirectional representation learning[J]. IEEE Tran-sactions on Multimedia, 2016, 18(7): 1363-1377. |
| [47] | LI Z, LU W, BAO E, et al. Learning a semantic space by deep network for cross-media retrieval[C]// Proceedings of the 21st International Conference on Distributed Multimedia Systems, Vancouver, Aug 31-Sep 2, 2015. Skokie: Knowledge Systems Institute, 2015: 199-203. |
| [48] | WEI Y, ZHAO Y, LU C, et al. Cross-modal retrieval with CNN visual features: a new baseline[J]. IEEE Transactions on Cybernetics, 2017, 47(2): 449-460. |
| [49] | FAN M D, WANG W M, DONG P L, et al. Cross-media re-trieval by learning rich semantic embeddings of multimedia[C]// Proceedings of the 2017 ACM on Multimedia Confer-ence, Mountain View, Oct 23-27, 2017. New York: ACM, 2017: 1698-1706. |
| [50] | KARPATHY A, LI F F. Deep visual-semantic alignments for generating image descriptions[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recogni-tion, Boston, Jun 8-10, 2015. Washington: IEEE Computer Society, 2015: 3128-3137. |
| [51] | MALINOWSKI M, ROHRBACH M, FRITZ M. Ask your neurons: a neural-based approach to answering questions about images[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Dec 7-13, 2015. Washington: IEEE Computer Society, 2015: 1-9. |
| [52] | GAO D H, JIN L B, CHEN B, et al. FashionBERT: text and image matching with adaptive loss for cross-modal retrieval[C]// Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Jul 25-30, 2020. New York: ACM, 2020: 2251-2260. |
| [53] | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understand-ing[J]. arXiv:1810.04805, 2018. |
| [54] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the Annual Conference on Neural Information Processing Systems, Long Beach, Dec 4-9, 2017. Cambridge: MIT Press, 2017: 5998-6008. |
| [55] | LEE K H, CHEN X, HUA G, et al. Stacked cross attention for image-text matching[C]// LNCS 11208: Proceedings of the 15th European Conference on Computer Vision, Munich, Sep 8-14, 2018. Cham: Springer, 2018: 212-228. |
| [56] | ZHANG Q, LEI Z, ZHANG Z X, et al. Context-aware atten-tion network for image-text retrieval[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, Jun 16-20, 2020. Piscataway: IEEE, 2020: 3533-3542. |
| [57] | CHEN H, DING G G, LIU X D, et al. IMRAM: iterative matching with recurrent attention memory for cross-modal image-text retrieval[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition,Seattle, Jun 16-20, 2020. Piscataway: IEEE, 2020: 12652-12660. |
| [58] | NGIAM J, KHOSLA A, KIM M, et al. Multimodal deep learning[C]// Proceedings of the 28th International Confer-ence on Machine Learning, Bellevue, Jun 28-Jul 2, 2011. Madison: Omnipress, 2011: 689-696. |
| [59] | KIROS R, SALAKHUTDINOV R, ZEMEL R S. Unifying visual-semantic embeddings with multimodal neural language models[J]. arXiv:1411.2539, 2014. |
| [60] | XU X, SONG J K, LU H M, et al. Modal-adversarial semantic learning network for extendable cross-modal retrieval[C]// Proceedings of the 2018 ACM on International Conference on Multimedia Retrieval, Yokohama, Jun 11-14, 2018. New York: ACM, 2018: 46-54. |
| [61] |
CORNIA M, BARALDI L, TAVAKOLI H R, et al. A unified cycle-consistent neural model for text and image retrieval[J]. Multimedia Tools and Applications, 2020, 79(35): 25697-25721.
DOI URL |
| [62] | CASTREJÓN L, AYTAR Y, VONDRICK C, et al. Learning aligned cross-modal representations from weakly aligned data[C]// Proceedings of the 2016 IEEE Conference on Com-puter Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 2940-2949. |
| [63] | ZHEN L L, HU P, WANG X, et al. Deep supervised cross-modal retrieval[C]// Proceedings of the 2019 IEEE/CVF Con-ference on Computer Vision and Pattern Recognition, Long Beach, Jun 15-20, 2019. Piscataway: IEEE, 2019: 10394-10403. |
| [64] | SONG Y, SOLEYMANI M. Polysemous visual-semantic embedding for cross-modal retrieval[C]// Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, Jun 15-20, 2019. Piscataway: IEEE, 2019: 1979-1988. |
| [65] | GU J X, CAI J F, JOTY S R, et al. Look, imagine and match: improving textual-visual cross-modal retrieval with genera-tive models[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-22, 2018. Piscataway: IEEE, 2018: 7181-7189. |
| [66] | WANG B K, YANG Y, XU X, et al. Adversarial cross-modal retrieval[C]// Proceedings of the 2017 ACM on Multimedia Conference, Mountain View, Oct 23-27, 2017. New York: ACM, 2017: 154-162. |
| [67] |
SALAKHUTDINOV R, HINTON G E. Semantic Hashing[J]. International Journal of Approximate Reasoning, 2009, 50(7): 969-978.
DOI URL |
| [68] | XIA R K, PAN Y, LAI H J, et al. Supervised Hashing for image retrieval via image representation learning[C]// Pro-ceedings of the 28th AAAI Conference on Artificial Intelli-gence, Québec, Jul 27-31, 2014. Menlo Park: AAAI, 2014: 2156-2162. |
| [69] | LIN K, YANG H F, HSIAO J H, et al. Deep learning of binary Hash codes for fast image retrieval[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Rec-ognition Workshops, Boston, Jun 7-12, 2015. Washington: IEEE Computer Society, 2015: 27-35. |
| [70] | ZHAO F, HUANG Y Z, WANG L, et al. Deep semantic ranking based Hashing for multi-label image retrieval[C]// Proceedings of the 2015 IEEE Conference on Computer Vi-sion and Pattern Recognition, Boston, Jun 8-10, 2015. Wash-ington: IEEE Computer Society, 2015: 1556-1564. |
| [71] | ZHANG D, WANG F, SI L. Composite Hashing with multiple information sources[C]// Proceeding of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval, Beijing, Jul 25-29, 2011. New York: ACM, 2011: 225-234. |
| [72] | CAO Y, LONG M S, WANG J M, et al. Deep visual-semantic Hashing for cross-modal retrieval[C]// Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Dis-covery and Data Mining, San Francisco, Aug 13-17, 2016. New York: ACM, 2016: 1445-1454. |
| [73] | JIANG Q Y, LI W J. Deep cross-modal Hashing[C]// Proceed-ings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 3270-3278. |
| [74] | LI C, DENG C, LI N, et al. Self-supervised adversarial Hash-ing networks for cross-modal retrieval[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-22, 2018. Pis-cataway: IEEE, 2018: 4242-4251. |
| [75] |
WU L, WANG Y, SHAO L. Cycle-consistent deep generative Hashing for cross-modal retrieval[J]. IEEE Transactions on Image Processing, 2019, 28(4): 1602-1612.
DOI URL |
| [76] | CHUA T S, TANG J H, HONG R C, et al. NUS-WIDE: a real-world web image database from national University of Singapore[C]// Proceedings of the 8th ACM International Conference on Image and Video Retrieval, Santorini Island, Jul 8-10, 2009. New York: ACM, 2009: 1-9. |
| [77] | LIN T Y, MAIRE M, BELONGIE S J, et al. Microsoft COCO: common objects in context[C]// LNCS 8693: Proceedings of the 13th European Conference on Computer Vision, Zurich, Sep 6-12, 2014. Cham: Springer, 2014: 740-755. |
| [78] |
YOUNG P, LAI A, HODOSH M, et al. From image descri-ptions to visual denotations: new similarity metrics for semantic inference over event descriptions[J]. Transactions of the Association for Computational Linguistics, 2014, 2: 67-78.
DOI URL |
| [79] | PEREIRA J C, COVIELLO E, DOYLE G, et al. On the role of correlation and abstraction in cross-modal multimedia re-trieval[J]. IEEE Transactions on Pattern Analysis and Mach-ine Intelligence, 2014, 36(3): 521-535. |
| [80] | HENNING M, CLOUGH P, MÜLLER H, et al. The IAPR benchmark: a new evaluation resource for visual informa-tion systems[C]// Proceedings of the 2006 International Con-ference on Language Resources and Evaluation, Genova, May 24-26, 2006. European Language Resources Associa-tion, 2006: 13-23. |
| [81] | 刘德鹏. 互联网舆情监控分析系统的研究与实现[D]. 成都: 电子科技大学, 2011. |
| LU D P. Design and implementation of Internet opinions monitoring and analyzing system[D]. Chengdu: University of Electronic Science and Technology of China, 2011. | |
| [82] | 何奕江. 社交网络跨媒体国民安全事件语义学习与行为分析研究[D]. 北京: 北京邮电大学, 2018. |
| HE Y J. Social network cross-media national security incid-ents semantic study and behavioral analysis[D]. Beijing: Beijing University of Posts and Telecommunications, 2018. | |
| [83] | 申自强. 基于文本和图像的舆情分析方法研究[D]. 镇江: 江苏大学, 2018. |
| SHEN Z Q. Research on public opinion analysis methods based on text and image[D]. Zhenjiang: Jiangsu University, 2018. | |
| [84] |
HUANG F R, ZHANG X M, ZHAO Z H, et al. Image-text sentiment analysis via deep multimodal attentive fusion[J]. Knowledge-Based Systems, 2019, 167: 26-37.
DOI URL |
| [85] | 曾倩倩, 张婷婷. 基于大数据的图像检索技术在侦查中的应用[J]. 电子技术与软件工程, 2018, 143(21): 175-176. |
| ZENG Q Q, ZHANG T T. Application of image retrieval technology based on big data in investigation[J]. Electronic Technology & Software Engineering, 2018, 143(21): 175-176. | |
| [86] | 乔凤才. 图文特征联合的证据图像检索技术研究[D]. 长沙: 国防科学技术大学, 2013. |
| QIAO F C. Research on the technology of evidence images retrieval using visual and text features[D]. Changsha: Na-tional University of Defense Technology, 2013. | |
| [87] | VINYALS O, TOSHEV A, BENGIO S, et al. Show and tell: a neural image caption generator[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recogni-tion, Boston, Jun 8-10, 2015. Washington: IEEE Computer Society, 2015: 3156-3164. |
| [88] | VENUGOPALAN S, XU H, DONAHUE J, et al. Translat-ing videos to natural language using deep recurrent neural networks[J]. arXiv:1412.4729, 2014. |
| [89] | LAN Z Z, BAO L, YU S I, et al. Multimedia classification and event detection using double fusion[J]. Multimedia Tools & Applications, 2014, 71(1): 333-347. |
| [90] | CAI G Y, XIA B B. Convolutional neural networks for multi-media sentiment analysis[C]// LNCS 9362: Proceedings of the 4th CCF Conference on Natural Language Processing and Chinese Computing, Nanchang, Oct 9-13, 2015. Cham: Springer, 2015: 159-167. |
| [91] | 凌海彬, 缪裕青, 张万桢, 等. 多特征融合的图文微博情感分析[J]. 计算机应用研究, 2020, 37(7): 1935-1939. |
| LIN H B, MIAO Y Q, ZHANG W Z, et al. Multimedia sen-timent analysis on microblog based on multi-feature fusion[J]. Application Research of Computers, 2020, 37(7): 1935-1939. | |
| [92] | CHEN X Y, WANG Y H, LIU Q J. Visual and textual senti-ment analysis using deep fusion convolutional neural net-works[C]// Proceedings of the 2017 IEEE International Con-ference on Image Processing, Beijing, Sep 17-20, 2017. Pis-cataway: IEEE, 2017: 1557-1561. |
| [93] | ZHANG Y Y, LI G R, CHU L Y, et al. Cross-media topic detection: a multi-modality fusion framework[C]// Proceed-ings of the 2013 IEEE International Conference on Multi-media and Expo, San Jose, Jul 15-19, 2013. Washington: IEEE Computer Society, 2013: 1-6. |
| [94] | YUAN Z Q, SANG J T, LIU Y, et al. Latent feature learning in social media network[C]// Proceedings of the 21st ACM International Conference on Multimedia, Barcelona, Oct 21-25, 2013. New York: ACM, 2013: 253-262. |
| [95] | 于玉海, 林鸿飞, 孟佳娜, 等. 跨模态多标签生物医学图像分类建模识别[J]. 中国图象图形学报, 2018, 23(6): 917-927. |
| YU Y H, LIN H F, MENG J N, et al. Classification modeling and recognition for cross modal and multi-label biomedical image[J]. Journal of Image and Graphics, 2018, 23(6): 917-927. | |
| [96] | COOKE R E, GAETA M G, KAUFMAN D M, et al. Picture archiving and communication system: US6574629 B1[P]. 2003-06-03. |
| [97] | 翟霄. 基于模态网络模型的医学数据检索技术[D]. 哈尔滨: 哈尔滨工程大学, 2017. |
| ZHAI X. Medical data retrieval technology based on mode network[D]. Harbin: Harbin Engineering University, 2017. | |
| [98] | ZHEN Y, YEUNG D Y. Co-regularized Hashing for multi-modal data[C]// Proceedings of the 26th Annual Conference on Neural Information Processing Systems, Lake Tahoe, Dec 3-6, 2012. Red Hook: Curran Associates, 2012: 1385-1393. |
| [1] | 安凤平, 李晓薇, 曹翔. 权重初始化-滑动窗口CNN的医学图像分类[J]. 计算机科学与探索, 2022, 16(8): 1885-1897. |
| [2] | 曾凡智, 许露倩, 周燕, 周月霞, 廖俊玮. 面向智慧教育的知识追踪模型研究综述[J]. 计算机科学与探索, 2022, 16(8): 1742-1763. |
| [3] | 刘艺, 李蒙蒙, 郑奇斌, 秦伟, 任小广. 视频目标跟踪算法综述[J]. 计算机科学与探索, 2022, 16(7): 1504-1515. |
| [4] | 赵小明, 杨轶娇, 张石清. 面向深度学习的多模态情感识别研究进展[J]. 计算机科学与探索, 2022, 16(7): 1479-1503. |
| [5] | 夏鸿斌, 肖奕飞, 刘渊. 融合自注意力机制的长文本生成对抗网络模型[J]. 计算机科学与探索, 2022, 16(7): 1603-1610. |
| [6] | 孙方伟, 李承阳, 谢永强, 李忠博, 杨才东, 齐锦. 深度学习应用于遮挡目标检测算法综述[J]. 计算机科学与探索, 2022, 16(6): 1243-1259. |
| [7] | 刘雅芬, 郑艺峰, 江铃燚, 李国和, 张文杰. 深度半监督学习中伪标签方法综述[J]. 计算机科学与探索, 2022, 16(6): 1279-1290. |
| [8] | 程卫月, 张雪琴, 林克正, 李骜. 融合全局与局部特征的深度卷积神经网络算法[J]. 计算机科学与探索, 2022, 16(5): 1146-1154. |
| [9] | 钟梦圆, 姜麟. 超分辨率图像重建算法综述[J]. 计算机科学与探索, 2022, 16(5): 972-990. |
| [10] | 裴利沈, 赵雪专. 群体行为识别深度学习方法研究综述[J]. 计算机科学与探索, 2022, 16(4): 775-790. |
| [11] | 许嘉, 韦婷婷, 于戈, 黄欣悦, 吕品. 题目难度评估方法研究综述[J]. 计算机科学与探索, 2022, 16(4): 734-759. |
| [12] | 朱伟杰, 陈莹. 双流时间域信息交互的微表情识别卷积网络[J]. 计算机科学与探索, 2022, 16(4): 950-958. |
| [13] | 姜艺, 胥加洁, 柳絮, 朱俊武. 边缘指导图像修复算法研究[J]. 计算机科学与探索, 2022, 16(3): 669-682. |
| [14] | 张全贵, 胡嘉燕, 王丽. 耦合用户公共特征的单类协同过滤推荐算法[J]. 计算机科学与探索, 2022, 16(3): 637-648. |
| [15] | 刘利平, 孙建, 高世妍. 单图像盲去模糊方法概述[J]. 计算机科学与探索, 2022, 16(3): 552-564. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||