
计算机科学与探索 ›› 2022, Vol. 16 ›› Issue (10): 2193-2218.DOI: 10.3778/j.issn.1673-9418.2204101
罗海银1,2,+( ), 郑钰辉1,2
), 郑钰辉1,2
收稿日期:2022-04-06
修回日期:2022-06-09
出版日期:2022-10-01
发布日期:2022-10-14
通讯作者:
+ E-mail: 20201220026@nuist.edu.cn作者简介:郑钰辉(1982—),男,山西芮城人,博士,教授,CCF会员,主要研究方向为计算机视觉、模式识别等。基金资助:
LUO Haiyin1,2,+(), ZHENG Yuhui1,2
Received:2022-04-06
Revised:2022-06-09
Online:2022-10-01
Published:2022-10-14
About author:ZHENG Yuhui, born in 1982, Ph.D., professor, member of CCF. His research interests include computer vision, pattern recognition, etc.Supported by:摘要:
图像修复是指恢复图像中受损区域像素,使其尽可能地与原始图像保持一致。图像修复不仅在计算机视觉任务中至关重要,同时也是其他图像处理任务研究的重要基石。然而现存图像修复相关总结研究较少,为了更好地学习和推进图像修复任务研究,对近十年的经典图像修复算法和极具代表性的深度学习图像修复方法进行了回顾和分析。首先,简单概述了经典的传统图像修复方法,并将其分为基于偏微分方程和基于样本的图像修复方法,同时进一步分析了传统图像方法局限性;着重分类且阐述了现有基于深度学习的图像修复方法,根据模型输出图像数量的不同,将其划分为单元图像修复和多元图像修复,结合方法应用图像、损失函数、类型、优势以及局限性对不同方法进行分析总结。之后,详述了图像修复方法常用数据集和定量评价指标,并给出图像修复方法在不同图像数据集上修复不同面积损坏区域的定量数据,根据定量数据对比分析了基于深度学习的图像修复方法性能。最后,归纳分析了现有图像修复方法的局限性,并对未来重点研究方向提出了新的思路和展望。
中图分类号:
罗海银, 郑钰辉. 图像修复方法研究综述[J]. 计算机科学与探索, 2022, 16(10): 2193-2218.
LUO Haiyin, ZHENG Yuhui. Survey of Research on Image Inpainting Methods[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(10): 2193-2218.

图1 图像修复示例图
Fig.1 Example of image inpainting
| 方法 | 使用思想 | 优势 | 局限 |
|---|---|---|---|
| BSCB[ | 等光线方向 | 自动修复 应用区域广 | 大区域纹理修复 |
| VFGL[ | 梯度方向 灰度级 | 纹理修复 | 灰度图像修复 |
| TV[ | 各向异性扩散 | 边界修复 | 直线修复 |
| CDD[ | 曲率驱动扩散 | 断裂修复 | 水平线插值 |
| Mumford-Shah-Euler[ | 曲率 Euler相同阶数 | 大区域修复 | 计算时间长 |
| Euler’s Elastica[ | Euler弹性模型 | 曲线修复 | 计算时间长 |
| 改进TV[ | 破损区域边缘参考点权值设置 | 边缘信息过渡自然 | 大区域纹理修复 |
| 改进CDD[ | 引入梯度和等照度线的曲率 | 时间短 断裂水平线连接光滑 | 纹理模糊 |
| 改进BSCB[ | 快速信息扩散 | 线性扩散 模型速度快 | 灰度图像修复 |
| 改进TV[ | 边界引导扩散函数 | 边缘过渡自然 大区域修复 | 图像模糊 计算时间长 |
表1 基于偏微分方程的图像修复方法特点
Table 1 Characteristics of image inpainting methods based on partial differential equation
| 方法 | 使用思想 | 优势 | 局限 |
|---|---|---|---|
| BSCB[ | 等光线方向 | 自动修复 应用区域广 | 大区域纹理修复 |
| VFGL[ | 梯度方向 灰度级 | 纹理修复 | 灰度图像修复 |
| TV[ | 各向异性扩散 | 边界修复 | 直线修复 |
| CDD[ | 曲率驱动扩散 | 断裂修复 | 水平线插值 |
| Mumford-Shah-Euler[ | 曲率 Euler相同阶数 | 大区域修复 | 计算时间长 |
| Euler’s Elastica[ | Euler弹性模型 | 曲线修复 | 计算时间长 |
| 改进TV[ | 破损区域边缘参考点权值设置 | 边缘信息过渡自然 | 大区域纹理修复 |
| 改进CDD[ | 引入梯度和等照度线的曲率 | 时间短 断裂水平线连接光滑 | 纹理模糊 |
| 改进BSCB[ | 快速信息扩散 | 线性扩散 模型速度快 | 灰度图像修复 |
| 改进TV[ | 边界引导扩散函数 | 边缘过渡自然 大区域修复 | 图像模糊 计算时间长 |
| 方法 | 使用思想 | 优势 | 局限 |
|---|---|---|---|
| Texture Synthesis[ | 马尔科夫随机场模型 | 保留局部图像结构 | 部分纹理错误 算法时间过长 |
| WL[ | 多分辨率金字塔结构 | 运行速度快 算法通用 | 无法捕捉深度、反射等线索 |
| SNT[ | 视觉掩码隐藏样本边界 | 不规则修复 合成纹理自然 | 规则结构或规则特征修复 |
| Fragment-Based[ | 已知图像上下文内容指导修复 | 自适应片段区域组合修复 | 边界区域修复模糊 速度慢 |
| GlobalImageStatistics[ | 基于图像局部特定分布修复 | 全局图像修复 计算时间短 | 细节模糊 仅用于结构图像 |
| Criminisi算法[ | 复制结构和纹理信息 | 修复图像结构和纹理 | 计算相似度函数不稳定 |
| 改进Criminisi算法[ | 引入曲率及梯度信息 | 克服高纹理区域过渡填充 | 图像细节不清晰 |
| 改进Criminisi算法[ | 引入相邻像素间颜色插值信息 | 边界部分过渡自然 | 搜索策略不稳定 |
| 改进Criminisi算法[ | 基于马尔科夫随机场匹配准则 | 解决图像误匹配现象 | 速度慢 不适用复杂图像修复 |
| PatchMatch[ | 近似最近邻匹配 | 图像纹理修复连贯 | 收敛性差 计算时间长 |
| SceneCompletion[ | 数据库查找相似图像 | 数据驱动 使用大部分场景 | 不适用没有相似内容修复 |
表2 基于样本的图像修复方法特点
Table 2 Characteristics of image inpainting methods based on patch
| 方法 | 使用思想 | 优势 | 局限 |
|---|---|---|---|
| Texture Synthesis[ | 马尔科夫随机场模型 | 保留局部图像结构 | 部分纹理错误 算法时间过长 |
| WL[ | 多分辨率金字塔结构 | 运行速度快 算法通用 | 无法捕捉深度、反射等线索 |
| SNT[ | 视觉掩码隐藏样本边界 | 不规则修复 合成纹理自然 | 规则结构或规则特征修复 |
| Fragment-Based[ | 已知图像上下文内容指导修复 | 自适应片段区域组合修复 | 边界区域修复模糊 速度慢 |
| GlobalImageStatistics[ | 基于图像局部特定分布修复 | 全局图像修复 计算时间短 | 细节模糊 仅用于结构图像 |
| Criminisi算法[ | 复制结构和纹理信息 | 修复图像结构和纹理 | 计算相似度函数不稳定 |
| 改进Criminisi算法[ | 引入曲率及梯度信息 | 克服高纹理区域过渡填充 | 图像细节不清晰 |
| 改进Criminisi算法[ | 引入相邻像素间颜色插值信息 | 边界部分过渡自然 | 搜索策略不稳定 |
| 改进Criminisi算法[ | 基于马尔科夫随机场匹配准则 | 解决图像误匹配现象 | 速度慢 不适用复杂图像修复 |
| PatchMatch[ | 近似最近邻匹配 | 图像纹理修复连贯 | 收敛性差 计算时间长 |
| SceneCompletion[ | 数据库查找相似图像 | 数据驱动 使用大部分场景 | 不适用没有相似内容修复 |
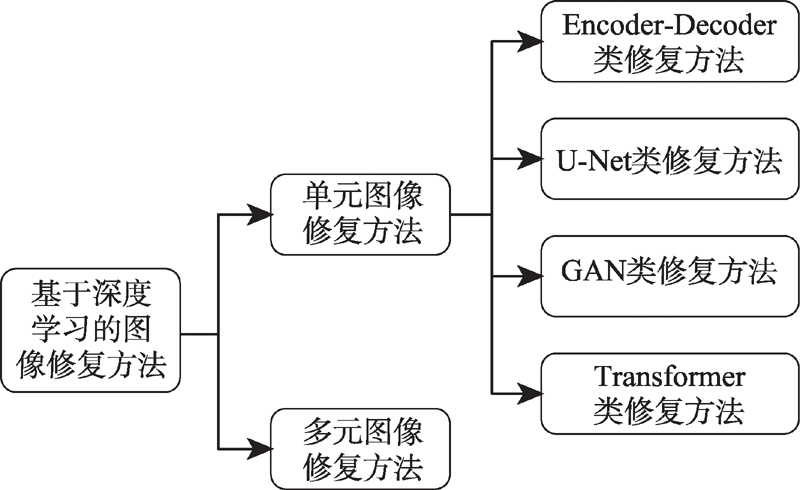
图2 基于深度学习的图像修复方法整体分类
Fig.2 Overall classification of image inpainting methods based on deep learning
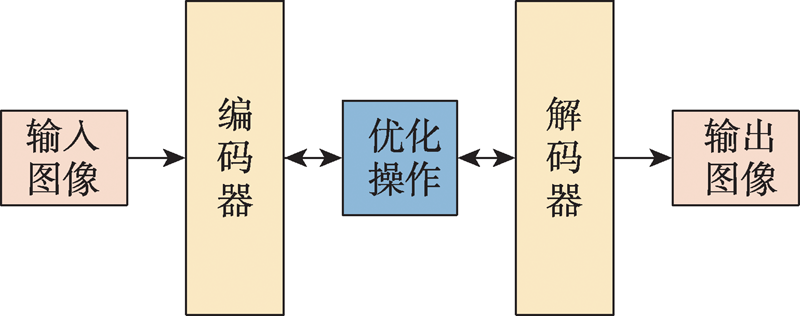
图3 编码器-解码器模型结构
Fig.3 Structure of Encoder-Decoder model
| 方法 | 分辨率 | 损失函数 | 类型 | 优势 | 局限 |
|---|---|---|---|---|---|
| CE[ | 128×128 | L1 L2 对抗 | 端到端的语义修复 | CE结合GAN思想 | 边缘模糊 |
| GLCIC[ | 256×256 | 加权L2 对抗 | 端到端的语义修复 | 全局和局部GAN | 纹理模糊 |
| E-CE[ | 128×128 | L1 WGAN | 两阶段的边缘指导修复 | 边缘感知CE | 纹理模糊 |
| SI[ | 128×128 | 结构重建 对抗 | 端到端的结构修复 | 结构重建损失 | 颜色差异 |
| LISK[ | 256×256 | 感知 风格 | 端到端的结构指导修复 | 多任务学习结构嵌入 | 边缘断裂 |
| MST-Net[ | 256×256 | 对抗 L1 感知 风格 | 两阶段的草图指导修复 | 草图张量空间 | 结构扭曲 |
| GMCNN[ | 512×512 | ID-MRF变量重建 对抗 | 端到端的结构纹理修复 | 多列结构 | 复杂图像修复 |
| MED[ | 256×256 | 重建 感知 风格 对抗 | 端到端的结构纹理修复 | 共享编解码器 特征均衡 | 上下文信息混合 |
| MSDN[ | 256×256 | 对抗重建特征匹配 | 端到端的纹理修复 | 多级解码器 | 结构扭曲 |
| PEPSI[ | 256×256 | 对抗 Hinge L1 | 端到端的语义修复 | 共享编码器 并行解码器 | 边界明显 |
| Diet-PEPSI[ | 256×256 | L1 对抗 | 端到端的语义修复 | 速率自适应卷积层 | 颜色差异 |
| DII[ | 256×256 | 蒸馏 注意力转移 | 端到端的结构修复 | 知识蒸馏 特征融合 | 模糊伪影 |
| RN[ | 256×256 | L1 对抗 感知 风格 | 端到端的语义修复 | 区域特征归一化 | 复杂场景修复 |
| MADF[ | 256×256 | 重建 感知 风格 TV | 端到端的结构修复 | 掩码感知动态过滤模块 | 大区域修复 |
| DE[ | 224×224 | L2 对抗 | 端到端的纹理修复 | 双编码器 跳跃连接 | 颜色差异 |
| T-MAD[ | 256×256 | 样本分布 L1感知 TV | 两阶段的样本指导修复 | 纹理内存引导、检索 | 边界模糊 |
| MRF-Net[ | 256×256 | 重建 对抗 | 端到端的纹理修复 | 并行多分辨率融合网络 | 背景混乱修复 |
| MAP[ | 256×256 | 对抗 特征匹配 重建 | 端到端的纹理修复 | 多级注意力传播编码器 | 纹理模糊 |
| Wave Fill[ | 256×256 | L1 对抗 特征匹配 感知 | 端到端的样本修复 | 小波变换 多频带修复 | 多频特征混乱 |
| CII[ | 512×512 | 感知 重建 对抗 | 两阶段的纹理样本修复 | 推理、翻译阶段 | 边界明显 |
| EILMB[ | 512×512 | 掩码重建 着色 | 两阶段的结构颜色修复 | 外部-内部学习 单色瓶颈 | 计算时间长 |
表3 Encoder-Decoder类图像修复方法特点
Table 3 Characteristics of Encoder-Decoder image inpainting methods
| 方法 | 分辨率 | 损失函数 | 类型 | 优势 | 局限 |
|---|---|---|---|---|---|
| CE[ | 128×128 | L1 L2 对抗 | 端到端的语义修复 | CE结合GAN思想 | 边缘模糊 |
| GLCIC[ | 256×256 | 加权L2 对抗 | 端到端的语义修复 | 全局和局部GAN | 纹理模糊 |
| E-CE[ | 128×128 | L1 WGAN | 两阶段的边缘指导修复 | 边缘感知CE | 纹理模糊 |
| SI[ | 128×128 | 结构重建 对抗 | 端到端的结构修复 | 结构重建损失 | 颜色差异 |
| LISK[ | 256×256 | 感知 风格 | 端到端的结构指导修复 | 多任务学习结构嵌入 | 边缘断裂 |
| MST-Net[ | 256×256 | 对抗 L1 感知 风格 | 两阶段的草图指导修复 | 草图张量空间 | 结构扭曲 |
| GMCNN[ | 512×512 | ID-MRF变量重建 对抗 | 端到端的结构纹理修复 | 多列结构 | 复杂图像修复 |
| MED[ | 256×256 | 重建 感知 风格 对抗 | 端到端的结构纹理修复 | 共享编解码器 特征均衡 | 上下文信息混合 |
| MSDN[ | 256×256 | 对抗重建特征匹配 | 端到端的纹理修复 | 多级解码器 | 结构扭曲 |
| PEPSI[ | 256×256 | 对抗 Hinge L1 | 端到端的语义修复 | 共享编码器 并行解码器 | 边界明显 |
| Diet-PEPSI[ | 256×256 | L1 对抗 | 端到端的语义修复 | 速率自适应卷积层 | 颜色差异 |
| DII[ | 256×256 | 蒸馏 注意力转移 | 端到端的结构修复 | 知识蒸馏 特征融合 | 模糊伪影 |
| RN[ | 256×256 | L1 对抗 感知 风格 | 端到端的语义修复 | 区域特征归一化 | 复杂场景修复 |
| MADF[ | 256×256 | 重建 感知 风格 TV | 端到端的结构修复 | 掩码感知动态过滤模块 | 大区域修复 |
| DE[ | 224×224 | L2 对抗 | 端到端的纹理修复 | 双编码器 跳跃连接 | 颜色差异 |
| T-MAD[ | 256×256 | 样本分布 L1感知 TV | 两阶段的样本指导修复 | 纹理内存引导、检索 | 边界模糊 |
| MRF-Net[ | 256×256 | 重建 对抗 | 端到端的纹理修复 | 并行多分辨率融合网络 | 背景混乱修复 |
| MAP[ | 256×256 | 对抗 特征匹配 重建 | 端到端的纹理修复 | 多级注意力传播编码器 | 纹理模糊 |
| Wave Fill[ | 256×256 | L1 对抗 特征匹配 感知 | 端到端的样本修复 | 小波变换 多频带修复 | 多频特征混乱 |
| CII[ | 512×512 | 感知 重建 对抗 | 两阶段的纹理样本修复 | 推理、翻译阶段 | 边界明显 |
| EILMB[ | 512×512 | 掩码重建 着色 | 两阶段的结构颜色修复 | 外部-内部学习 单色瓶颈 | 计算时间长 |

图4 U-Net模型结构
Fig.4 Structure of U-Net model
| 方法 | 分辨率 | 损失函数 | 类型 | 优势 | 局限 |
|---|---|---|---|---|---|
| Shift-Net[ | 256×256 | 指导 L1 对抗 | 端到端的图像修复 | 移位连接层 | 边界信息混合 |
| FRRN[ | 256×256 | 逐步 重建 对抗 风格 | 端到端的纹理修复 | 全分辨率残差网络 | 计算成本高 |
| Pconv[ | 512×512 | 像素 感知 风格 TV | 端到端的掩码更新修复 | 自动掩码更新部分卷积 | 更新不稳定 |
| DFNet[ | 512×512 | 上下文真实感梯度差异 | 端到端的纹理修复 | 自适应融合模块 | 语义混乱 |
| PEN-Net[ | 256×256 | 对抗 金字塔 L1 | 端到端的语义修复 | 金字塔注意力转移网络 | 纹理伪影 |
| MSA-Net[ | 256×256 | L2 感知 风格 | 端到端的语义修复 | 多尺度注意力单元 | 样本模糊 |
| DPNet[ | 256×256 | 重建 感知 ID-MRF 对抗 | 端到端的样本修复 | 双金字塔 动态归一化 | 分辨率较低 |
| CSA[ | 256×256 | 一致 L1 对抗 | 两阶段的语义修复 | 连贯语义注意层 | 边界伪影 |
| LGNet[ | 256×256 | 重建 对抗 感知 风格 TV | 两阶段的全局局部修复 | 全局-局部细化网络 | 语义不一致 |
| LBAM[ | 256×256 | 像素重建 感知 对抗 | 端到端的结构修复 | 可学习注意力图 | 颜色差异 |
| VCNet[ | 256×256 | 自适应 IDMRF 对抗 | 两阶段的掩码指导修复 | 视觉一致性网络 | 语义不一致 |
| DSNet[ | 256×256 | 感知 风格 TV孔洞 有效 | 端到端的掩码修复 | 动态选择机制 | 结构扭曲 |
| PRVS[ | 256×256 | 对抗 金字塔 L1 | 两阶段的结构指导修复 | 视觉结构重建层 | 纹理模糊 |
| SGE-Net[ | 256×256 | 重建 对抗 交叉熵 | 两阶段的语义指导修复 | 语义引导 评估机制 | 纹理伪影 |
| CTSDG[ | 256×256 | 监督 对抗 感知 风格 | 两阶段的纹理结构修复 | 纹理约束 结构引导 | 分辨率较低 |
| MUSICAL[ | 256×256 | 风格 感知 对抗 TV L1 | 端到端的纹理修复 | 金字塔注意力模块 | 边界明显 |
| SWAP[ | 256×256 | 相关 重建 对抗 交叉熵 | 端到端的语义纹理修复 | 语义注意传播模块 | 边界不一致 |
| RFR-Net[ | 256×256 | 感知 风格 | 端到端的特征修复 | 循环特征推理模块 | 纹理重影 |
| HiFill[ | 1 024×1 024 | 重建 对抗 | 两阶段的纹理修复 | 上下文加权聚合残差 | 大区域修复 |
表4 U-Net类图像修复方法特点
Table 4 Characteristics of U-Net image inpainting methods
| 方法 | 分辨率 | 损失函数 | 类型 | 优势 | 局限 |
|---|---|---|---|---|---|
| Shift-Net[ | 256×256 | 指导 L1 对抗 | 端到端的图像修复 | 移位连接层 | 边界信息混合 |
| FRRN[ | 256×256 | 逐步 重建 对抗 风格 | 端到端的纹理修复 | 全分辨率残差网络 | 计算成本高 |
| Pconv[ | 512×512 | 像素 感知 风格 TV | 端到端的掩码更新修复 | 自动掩码更新部分卷积 | 更新不稳定 |
| DFNet[ | 512×512 | 上下文真实感梯度差异 | 端到端的纹理修复 | 自适应融合模块 | 语义混乱 |
| PEN-Net[ | 256×256 | 对抗 金字塔 L1 | 端到端的语义修复 | 金字塔注意力转移网络 | 纹理伪影 |
| MSA-Net[ | 256×256 | L2 感知 风格 | 端到端的语义修复 | 多尺度注意力单元 | 样本模糊 |
| DPNet[ | 256×256 | 重建 感知 ID-MRF 对抗 | 端到端的样本修复 | 双金字塔 动态归一化 | 分辨率较低 |
| CSA[ | 256×256 | 一致 L1 对抗 | 两阶段的语义修复 | 连贯语义注意层 | 边界伪影 |
| LGNet[ | 256×256 | 重建 对抗 感知 风格 TV | 两阶段的全局局部修复 | 全局-局部细化网络 | 语义不一致 |
| LBAM[ | 256×256 | 像素重建 感知 对抗 | 端到端的结构修复 | 可学习注意力图 | 颜色差异 |
| VCNet[ | 256×256 | 自适应 IDMRF 对抗 | 两阶段的掩码指导修复 | 视觉一致性网络 | 语义不一致 |
| DSNet[ | 256×256 | 感知 风格 TV孔洞 有效 | 端到端的掩码修复 | 动态选择机制 | 结构扭曲 |
| PRVS[ | 256×256 | 对抗 金字塔 L1 | 两阶段的结构指导修复 | 视觉结构重建层 | 纹理模糊 |
| SGE-Net[ | 256×256 | 重建 对抗 交叉熵 | 两阶段的语义指导修复 | 语义引导 评估机制 | 纹理伪影 |
| CTSDG[ | 256×256 | 监督 对抗 感知 风格 | 两阶段的纹理结构修复 | 纹理约束 结构引导 | 分辨率较低 |
| MUSICAL[ | 256×256 | 风格 感知 对抗 TV L1 | 端到端的纹理修复 | 金字塔注意力模块 | 边界明显 |
| SWAP[ | 256×256 | 相关 重建 对抗 交叉熵 | 端到端的语义纹理修复 | 语义注意传播模块 | 边界不一致 |
| RFR-Net[ | 256×256 | 感知 风格 | 端到端的特征修复 | 循环特征推理模块 | 纹理重影 |
| HiFill[ | 1 024×1 024 | 重建 对抗 | 两阶段的纹理修复 | 上下文加权聚合残差 | 大区域修复 |
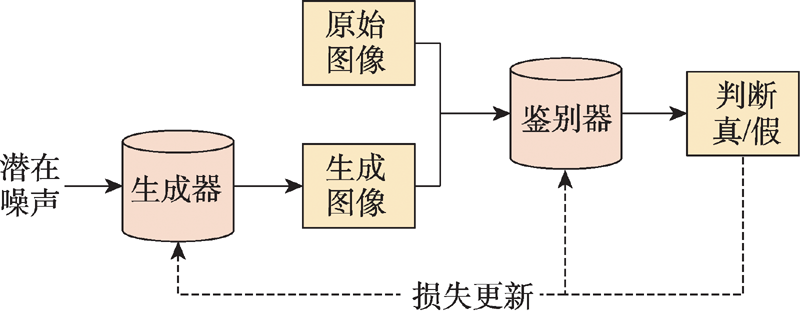
图5 生成对抗网络模型结构
Fig.5 Structure of GAN model
| 方法 | 分辨率 | 损失函数 | 类型 | 优势 | 局限 |
|---|---|---|---|---|---|
| DGM[ | 64×64 | 指导 L1 对抗 | 端到端的语义修复 | 先验知识 上下文损失 | 模型不稳定 |
| GFC[ | 128×128 | L2 对抗 像素Softmax | 端到端的语义修复 | 语义解析网络 | 纹理模糊 |
| NEO[ | 256×256 | L2 对抗 L1 | 两阶段的标志指导修复 | U-Net标志生成器 | 边界明显 |
| ExGANs[ | 不定 | 重建 感知 对抗 | 两阶段的示例指导修复 | 示例GAN | 不规则区域修复 |
| SKC[ | 128×128 | 重建 对抗 | 端到端的协作修复 | 协作GAN | 纹理模糊 |
| DE-GAN[ | 256×256 | 域嵌入 多模型对抗 | 端到端的人脸修复 | 域嵌入GAN | 多张人脸修复 |
| HR[ | 512×512 | TV 内容 L2 对抗 | 两阶段的内容纹理修复 | 图像内容纹理约束 | 纹理伪影 |
| HRⅡ[ | 512×512 | L1 hinge对抗 置信度预测 | 两阶段的样本迭代修复 | 反馈机制迭代修复 | 计算资源大 |
| CA[ | 512×680 | 对抗 重建 空间衰减重建 | 两阶段的草图指导修复 | Wasserstein GAN | 边缘伪影 |
| GC[ | 512×512 | 重建 感知 风格 TV | 两阶段的样本修复 | 样本草图 SN-PatchGAN | 边缘明显 |
| SPG-Net[ | 256×256 | L1 对抗 TV | 两阶段的分割指导修复 | 分割预测分割指导 | 纹理重影 |
| FII[ | 256×256 | 像素重建 感知 对抗 | 两阶段的轮廓指导修复 | 前景感知 轮廓预测补全 | 纹理伪影 |
| StrucFlow[ | 256×256 | 一致性 L1 对抗 | 两阶段的结构纹理修复 | 结构重构纹理生成 | 计算成本高 |
| EC[ | 256×256 | 逐步 重建 风格 对抗 | 两阶段的边缘指导修复 | 边缘生成器 | 颜色差异 |
| EIGC[ | 256×256 | L1 感知风格 对抗 | 两阶段的边缘指导修复 | 门卷积GAN | 分辨率较低 |
| PG-GAN[ | 256×256 | 样本分布 L1 感知 TV | 两阶段的噪声先验修复 | 噪声先验知识 | 自然场景图像 |
| CR-Fill[ | 256×256 | 上下文重建 L1 对抗 | 两阶段的上下文修复 | 上下文重建损失 | 分辨率较低 |
| PGN[ | 128×128 | L1 对抗 TV | 端到端的语义修复 | 课程学习 渐进式GAN | 不规则区域修复 |
| SGI-Net[ | 256×256 | 重建 特征匹配 感知 风格 | 两阶段的分割指导修复 | 空间自适应归一化 | 计算成本高 |
| DMFN[ | 256×256 | 自导回归 特征匹配 对抗 | 端到端的特征修复 | 密集多尺度融合块 | 结构扭曲 |
| MSGAN[ | 256×256 | L2 WGAN | 端到端的语义修复 | 双金字塔 动态归一化 | 纹理伪影 |
| AOTGAN[ | 512×512 | 对抗 重建 风格 感知 | 端到端的语义修复 | 聚合上下文转换GAN | 计算成本高 |
表5 GAN类图像修复方法特点
Table 5 Characteristics of GAN image inpainting methods
| 方法 | 分辨率 | 损失函数 | 类型 | 优势 | 局限 |
|---|---|---|---|---|---|
| DGM[ | 64×64 | 指导 L1 对抗 | 端到端的语义修复 | 先验知识 上下文损失 | 模型不稳定 |
| GFC[ | 128×128 | L2 对抗 像素Softmax | 端到端的语义修复 | 语义解析网络 | 纹理模糊 |
| NEO[ | 256×256 | L2 对抗 L1 | 两阶段的标志指导修复 | U-Net标志生成器 | 边界明显 |
| ExGANs[ | 不定 | 重建 感知 对抗 | 两阶段的示例指导修复 | 示例GAN | 不规则区域修复 |
| SKC[ | 128×128 | 重建 对抗 | 端到端的协作修复 | 协作GAN | 纹理模糊 |
| DE-GAN[ | 256×256 | 域嵌入 多模型对抗 | 端到端的人脸修复 | 域嵌入GAN | 多张人脸修复 |
| HR[ | 512×512 | TV 内容 L2 对抗 | 两阶段的内容纹理修复 | 图像内容纹理约束 | 纹理伪影 |
| HRⅡ[ | 512×512 | L1 hinge对抗 置信度预测 | 两阶段的样本迭代修复 | 反馈机制迭代修复 | 计算资源大 |
| CA[ | 512×680 | 对抗 重建 空间衰减重建 | 两阶段的草图指导修复 | Wasserstein GAN | 边缘伪影 |
| GC[ | 512×512 | 重建 感知 风格 TV | 两阶段的样本修复 | 样本草图 SN-PatchGAN | 边缘明显 |
| SPG-Net[ | 256×256 | L1 对抗 TV | 两阶段的分割指导修复 | 分割预测分割指导 | 纹理重影 |
| FII[ | 256×256 | 像素重建 感知 对抗 | 两阶段的轮廓指导修复 | 前景感知 轮廓预测补全 | 纹理伪影 |
| StrucFlow[ | 256×256 | 一致性 L1 对抗 | 两阶段的结构纹理修复 | 结构重构纹理生成 | 计算成本高 |
| EC[ | 256×256 | 逐步 重建 风格 对抗 | 两阶段的边缘指导修复 | 边缘生成器 | 颜色差异 |
| EIGC[ | 256×256 | L1 感知风格 对抗 | 两阶段的边缘指导修复 | 门卷积GAN | 分辨率较低 |
| PG-GAN[ | 256×256 | 样本分布 L1 感知 TV | 两阶段的噪声先验修复 | 噪声先验知识 | 自然场景图像 |
| CR-Fill[ | 256×256 | 上下文重建 L1 对抗 | 两阶段的上下文修复 | 上下文重建损失 | 分辨率较低 |
| PGN[ | 128×128 | L1 对抗 TV | 端到端的语义修复 | 课程学习 渐进式GAN | 不规则区域修复 |
| SGI-Net[ | 256×256 | 重建 特征匹配 感知 风格 | 两阶段的分割指导修复 | 空间自适应归一化 | 计算成本高 |
| DMFN[ | 256×256 | 自导回归 特征匹配 对抗 | 端到端的特征修复 | 密集多尺度融合块 | 结构扭曲 |
| MSGAN[ | 256×256 | L2 WGAN | 端到端的语义修复 | 双金字塔 动态归一化 | 纹理伪影 |
| AOTGAN[ | 512×512 | 对抗 重建 风格 感知 | 端到端的语义修复 | 聚合上下文转换GAN | 计算成本高 |

图6 Transformer模型结构
Fig.6 Structure of Transformer model
| 方法 | 分辨率 | 损失函数 | 类型 | 优势 | 局限 |
|---|---|---|---|---|---|
| TransFill[ | 256×256 | TV VGG | 两阶段的深度颜色修复 | 颜色空间Transformer | 低光照修复 |
| FT-TDR[ | 256×256 | 重建 对抗 感知 风格 TV | 两阶段的掩码预测修复 | 频率引导Transformer | 小视觉对象修复 |
| TFill[ | 512×512 | Softmax正则化 | 两阶段的语义修复 | Transformer编码器 | 高级语义修复 |
| ZITS[ | 1 024×1 024 | 重建 感知 对抗 | 两阶段的示例指导修复 | 增量结构Transformer | 远景复杂修复 |
表6 Transformer类图像修复方法特点
Table 6 Characteristics of Transformer image inpainting methods
| 方法 | 分辨率 | 损失函数 | 类型 | 优势 | 局限 |
|---|---|---|---|---|---|
| TransFill[ | 256×256 | TV VGG | 两阶段的深度颜色修复 | 颜色空间Transformer | 低光照修复 |
| FT-TDR[ | 256×256 | 重建 对抗 感知 风格 TV | 两阶段的掩码预测修复 | 频率引导Transformer | 小视觉对象修复 |
| TFill[ | 512×512 | Softmax正则化 | 两阶段的语义修复 | Transformer编码器 | 高级语义修复 |
| ZITS[ | 1 024×1 024 | 重建 感知 对抗 | 两阶段的示例指导修复 | 增量结构Transformer | 远景复杂修复 |
| 方法 | 分辨率 | 损失函数 | 类型 | 优势 | 局限 |
|---|---|---|---|---|---|
| FiNet[ | 256×256 | 交叉熵 KL散度 风格 | 两阶段的形状外观修复 | 形状、外观生成网络 | 单一类型图像 |
| PSI[ | 32×32 | 掩码分布 Softmax | 端到端的语义修复 | 像素约束CNN | 训练速度慢 |
| PICNet[ | 256×256 | 正则化 外观匹配 对抗 | 端到端的结构修复 | 生成路径 重建路径 | 纹理模糊 |
| TDANet[ | 256×256 | 分布 对抗 重建 特征匹配 | 两阶段的文本指导修复 | 双重多模态注意力机制 | 简单编码器 |
| UCTGAN[ | 256×256 | 约束 KL散度 重建 对抗 | 两阶段的掩码指导修复 | 掩码先验 | 结构扭曲 |
| HVQ-VAE[ | 256×256 | 重建 特征 对抗 | 两阶段的结构纹理修复 | 分层向量量化VAE | 分辨率较低 |
| PD-GAN[ | 256×256 | 多样性 重建 匹配 对抗 | 两阶段的概率修复 | 空间概率多样性归一化 | 分辨率较低 |
| DRF[ | 256×256 | L1 感知 边缘 对抗 | 端到端的孔洞修复 | 对抗并发编码器 | 颜色差异 |
| BAT-Fill[ | 256×256 | 重建 对抗 感知 | 两阶段的结构纹理修复 | 双向自回Transformer | 纹理模糊 |
| ICT[ | 256×256 | L1 对抗 | 两阶段的外观纹理修复 | 双向Transformer | 分辨率较低 |
| CoModGAN[ | 512×512 | 重建 感知 风格 TV | 两阶段的样本修复 | 协作调制GAN | 结构扭曲 |
| MAT[ | 512×512 | 感知对抗 R1正则化 | 端到端的掩码感知修复 | 掩码感知Transformer | 任意形状修复 |
| PUT[ | 512×512 | 重建 交叉熵 | 两阶段的样本修复 | 非量化Transformer | 推理时间长 |
表7 多元图像修复方法特点
Table 7 Characteristics of pluralistic image inpainting methods
| 方法 | 分辨率 | 损失函数 | 类型 | 优势 | 局限 |
|---|---|---|---|---|---|
| FiNet[ | 256×256 | 交叉熵 KL散度 风格 | 两阶段的形状外观修复 | 形状、外观生成网络 | 单一类型图像 |
| PSI[ | 32×32 | 掩码分布 Softmax | 端到端的语义修复 | 像素约束CNN | 训练速度慢 |
| PICNet[ | 256×256 | 正则化 外观匹配 对抗 | 端到端的结构修复 | 生成路径 重建路径 | 纹理模糊 |
| TDANet[ | 256×256 | 分布 对抗 重建 特征匹配 | 两阶段的文本指导修复 | 双重多模态注意力机制 | 简单编码器 |
| UCTGAN[ | 256×256 | 约束 KL散度 重建 对抗 | 两阶段的掩码指导修复 | 掩码先验 | 结构扭曲 |
| HVQ-VAE[ | 256×256 | 重建 特征 对抗 | 两阶段的结构纹理修复 | 分层向量量化VAE | 分辨率较低 |
| PD-GAN[ | 256×256 | 多样性 重建 匹配 对抗 | 两阶段的概率修复 | 空间概率多样性归一化 | 分辨率较低 |
| DRF[ | 256×256 | L1 感知 边缘 对抗 | 端到端的孔洞修复 | 对抗并发编码器 | 颜色差异 |
| BAT-Fill[ | 256×256 | 重建 对抗 感知 | 两阶段的结构纹理修复 | 双向自回Transformer | 纹理模糊 |
| ICT[ | 256×256 | L1 对抗 | 两阶段的外观纹理修复 | 双向Transformer | 分辨率较低 |
| CoModGAN[ | 512×512 | 重建 感知 风格 TV | 两阶段的样本修复 | 协作调制GAN | 结构扭曲 |
| MAT[ | 512×512 | 感知对抗 R1正则化 | 端到端的掩码感知修复 | 掩码感知Transformer | 任意形状修复 |
| PUT[ | 512×512 | 重建 交叉熵 | 两阶段的样本修复 | 非量化Transformer | 推理时间长 |
| 类型 | 数据集 | 年份 | 总数 | 分辨率 | 使用方法 |
|---|---|---|---|---|---|
| 建筑 | Facade[ | 2013 | 606 | — | [ |
| 纹理 | DTD[ | 2014 | 5 640 | — | [ |
| 街景 | SVHN[ | 2011 | >600 000 | 32×32 | [ |
| Paris StreetView[ | 2012 | 15 000 | 936×537 | [ | |
| Cityscapes[ | 2016 | 25 000 | 2 048×1 024 | [ | |
| 场景 | MS COCO[ | 2014 | 328 000 | — | [ |
| ImageNet[ | 2015 | 14 197 122 | — | [ | |
| Places2[ | 2017 | 1 000 000 | 256×256 | [ | |
| 人脸 | Helen Face[ | 2012 | 2 000 | — | [ |
| CelebA[ | 2015 | 202 599 | 178×218 | [ | |
| CelebA-HQ[ | 2017 | 30 000 | 1 024×1 024 | [ | |
| FFHQ[ | 2019 | 70 000 | 1 024×1 024 | [ |
表8 常用数据集描述
Table 8 Description of common datasets
| 类型 | 数据集 | 年份 | 总数 | 分辨率 | 使用方法 |
|---|---|---|---|---|---|
| 建筑 | Facade[ | 2013 | 606 | — | [ |
| 纹理 | DTD[ | 2014 | 5 640 | — | [ |
| 街景 | SVHN[ | 2011 | >600 000 | 32×32 | [ |
| Paris StreetView[ | 2012 | 15 000 | 936×537 | [ | |
| Cityscapes[ | 2016 | 25 000 | 2 048×1 024 | [ | |
| 场景 | MS COCO[ | 2014 | 328 000 | — | [ |
| ImageNet[ | 2015 | 14 197 122 | — | [ | |
| Places2[ | 2017 | 1 000 000 | 256×256 | [ | |
| 人脸 | Helen Face[ | 2012 | 2 000 | — | [ |
| CelebA[ | 2015 | 202 599 | 178×218 | [ | |
| CelebA-HQ[ | 2017 | 30 000 | 1 024×1 024 | [ | |
| FFHQ[ | 2019 | 70 000 | 1 024×1 024 | [ |

图7 部分掩码数据集示例图
Fig.7 Some mask dataset sample images

图8 部分图像数据集示例图
Fig.8 Sample images of some image datasets
| 类型 | 评价指标 | 数值大小 | 作用 | 优势 | 局限性 |
|---|---|---|---|---|---|
| 全参考 | MAE[ | ↓ | 衡量图像误差 | 模型稳健 | 不利于模型收敛 |
| MSE[ | ↓ | 衡量图像相似度 | 加快模型收敛 | 受误差影响大 | |
| UQI[ | ↑ | 衡量图像质量 | 判断相关性结构失真 | 较难捕捉相关性 | |
| PSNR[ | ↑ | 衡量图像失真度 | 简单快速 | 依赖像素点误差 | |
| SSIM[ | ↑ | 衡量图像结构相似性 | 引入结构判断 | 非结构性误差难以判断 | |
| MS-SSIM[ | ↑ | 衡量图像结构相似性 | 多尺度结构判断 | 聚合度过高 | |
| LPIPS[ | ↓ | 衡量图像感知相似性、多样性 | 学习感知相似性 | 难以判断相关性不高任务 | |
| FID[ | ↓ | 衡量图像相似度、多样性 | 鲁棒性高 | 依赖特征出现 | |
| 半参考 | BPE[ | ↓ | 衡量图像边界平滑度 | 引入边界误差 | 未考虑全局信息 |
| 无参考 | IS[ | ↑ | 衡量图像感知质量、多样性 | 判断语义相关性 | 无法检测过度拟合 |
| MIS[ | ↑ | 衡量图像质量 | 无需大量数据集 | 仅适用基于GAN方法 |
表9 图像评价指标特点
Table 9 Characteristics of image evaluation index
| 类型 | 评价指标 | 数值大小 | 作用 | 优势 | 局限性 |
|---|---|---|---|---|---|
| 全参考 | MAE[ | ↓ | 衡量图像误差 | 模型稳健 | 不利于模型收敛 |
| MSE[ | ↓ | 衡量图像相似度 | 加快模型收敛 | 受误差影响大 | |
| UQI[ | ↑ | 衡量图像质量 | 判断相关性结构失真 | 较难捕捉相关性 | |
| PSNR[ | ↑ | 衡量图像失真度 | 简单快速 | 依赖像素点误差 | |
| SSIM[ | ↑ | 衡量图像结构相似性 | 引入结构判断 | 非结构性误差难以判断 | |
| MS-SSIM[ | ↑ | 衡量图像结构相似性 | 多尺度结构判断 | 聚合度过高 | |
| LPIPS[ | ↓ | 衡量图像感知相似性、多样性 | 学习感知相似性 | 难以判断相关性不高任务 | |
| FID[ | ↓ | 衡量图像相似度、多样性 | 鲁棒性高 | 依赖特征出现 | |
| 半参考 | BPE[ | ↓ | 衡量图像边界平滑度 | 引入边界误差 | 未考虑全局信息 |
| 无参考 | IS[ | ↑ | 衡量图像感知质量、多样性 | 判断语义相关性 | 无法检测过度拟合 |
| MIS[ | ↑ | 衡量图像质量 | 无需大量数据集 | 仅适用基于GAN方法 |
| 方法 | CelebA-HQ[ | Paris StreetView[ | Places2[ | |||
|---|---|---|---|---|---|---|
| PSNR/dB[134] ↑ | SSIM/%[135] ↑ | PSNR/dB[134] ↑ | SSIM/%[135] ↑ | PSNR/dB[134] ↑ | SSIM/%[135] ↑ | |
| GMCNN[ | 25.00 | 90.50 | 24.65 | 86.50 | 20.16 | 86.17 |
| MED[ | 26.49 | 85.90 | 24.67 | 80.80 | 23.64 | 77.80 |
| PEN-Net[ | 25.47 | 89.03 | — | — | 23.80 | 78.68 |
| MUSICAL[ | 26.64 | 90.08 | 24.42 | 84.28 | 21.84 | 80.25 |
| GC[ | 25.94 | 83.30 | 24.13 | 77.30 | 22.73 | 76.10 |
| DMFN[ | 26.50 | 89.32 | 25.00 | 85.63 | 22.36 | 81.94 |
| FT-TDR[ | 26.16 | 91.20 | — | — | — | — |
| ZITS[ | — | — | — | — | 24.42 | 87.00 |
| 平均值 | 26.03 | 88.48 | 24.56 | 82.00 | 22.52 | 79.35 |
表10 单元图像修复方法在规则区域的性能分析
Table 10 Quantitative analysis of single image inpainting methods on regular regions
| 方法 | CelebA-HQ[ | Paris StreetView[ | Places2[ | |||
|---|---|---|---|---|---|---|
| PSNR/dB[134] ↑ | SSIM/%[135] ↑ | PSNR/dB[134] ↑ | SSIM/%[135] ↑ | PSNR/dB[134] ↑ | SSIM/%[135] ↑ | |
| GMCNN[ | 25.00 | 90.50 | 24.65 | 86.50 | 20.16 | 86.17 |
| MED[ | 26.49 | 85.90 | 24.67 | 80.80 | 23.64 | 77.80 |
| PEN-Net[ | 25.47 | 89.03 | — | — | 23.80 | 78.68 |
| MUSICAL[ | 26.64 | 90.08 | 24.42 | 84.28 | 21.84 | 80.25 |
| GC[ | 25.94 | 83.30 | 24.13 | 77.30 | 22.73 | 76.10 |
| DMFN[ | 26.50 | 89.32 | 25.00 | 85.63 | 22.36 | 81.94 |
| FT-TDR[ | 26.16 | 91.20 | — | — | — | — |
| ZITS[ | — | — | — | — | 24.42 | 87.00 |
| 平均值 | 26.03 | 88.48 | 24.56 | 82.00 | 22.52 | 79.35 |
| 掩码区域面积占比 | 方法 | CelebA-HQ[ | Paris StreetView[ | Places2[ | ||||
|---|---|---|---|---|---|---|---|---|
| PSNR/dB[134] ↑ | SSIM/%[135] ↑ | PSNR/dB[134] ↑ | SSIM/%[135] ↑ | PSNR/dB[134] ↑ | SSIM/%[135] ↑ | |||
| 10%~20% | MED[ | 30.97 | 97.10 | 30.25 | 95.40 | 29.05 | 94.10 | |
| MADF[ | 33.77 | 98.40 | 31.99 | 96.60 | 29.42 | 96.10 | ||
| PEN-Net[ | 29.76 | 96.50 | 28.97 | 93.90 | 27.90 | 92.70 | ||
| RFR-Net[ | 31.87 | 97.60 | 31.43 | 96.20 | 27.75 | 95.20 | ||
| EC[ | 33.51 | 96.10 | 31.23 | 93.80 | 27.95 | 93.90 | ||
| GC[ | 31.02 | 97.10 | 28.95 | 94.00 | 27.42 | 91.70 | ||
| FT-TDR[ | 31.75 | 97.80 | — | — | — | — | ||
| ZITS[ | — | — | — | — | 28.31 | 94.20 | ||
| 平均值 | 31.80 | 97.23 | 30.47 | 94.98 | 28.26 | 93.99 | ||
| 20%~30% | MED[ | 27.75 | 94.30 | 27.08 | 90.90 | 25.92 | 88.80 | |
| MADF[ | 30.42 | 96.70 | 28.71 | 93.30 | 26.29 | 92.20 | ||
| PEN-Net[ | 26.79 | 93.30 | 26.03 | 88.40 | 25.09 | 86.70 | ||
| RFR-Net[ | 29.07 | 95.70 | 28.39 | 92.80 | 27.24 | 91.10 | ||
| EC[ | 30.02 | 92.80 | 28.26 | 89.20 | 24.92 | 86.10 | ||
| GC[ | 27.57 | 94.10 | 25.73 | 88.50 | 24.65 | 85.60 | ||
| FT-TDR[ | 28.57 | 95.90 | — | — | — | — | ||
| ZITS[ | — | — | — | — | 25.40 | 90.20 | ||
| 平均值 | 28.60 | 94.69 | 27.37 | 90.52 | 25.64 | 88.67 | ||
| 30%~40% | MED[ | 25.36 | 90.80 | 24.91 | 85.40 | 23.78 | 82.50 | |
| MADF[ | 27.95 | 94.50 | 26.44 | 89.20 | 23.84 | 87.30 | ||
| PEN-Net[ | 24.70 | 89.40 | 24.12 | 82.10 | 23.21 | 80.10 | ||
| RFR-Net[ | 26.87 | 93.10 | 26.30 | 88.60 | 22.63 | 81.90 | ||
| EC[ | 27.39 | 89.00 | 26.05 | 84.20 | 22.84 | 79.90 | ||
| GC[ | 25.03 | 90.20 | 23.62 | 82.50 | 22.81 | 79.20 | ||
| FT-TDR[ | 26.40 | 93.20 | — | — | — | — | ||
| ZITS[ | — | — | — | — | 23.51 | 86.00 | ||
| 平均值 | 26.24 | 91.46 | 25.24 | 85.33 | 23.23 | 82.41 | ||
| 40%~50% | MED[ | 23.47 | 86.50 | 23.12 | 78.70 | 22.07 | 75.20 | |
| MADF[ | 25.99 | 91.70 | 24.65 | 84.10 | 21.92 | 81.20 | ||
| PEN-Net[ | 23.06 | 84.90 | 22.56 | 74.50 | 21.74 | 72.70 | ||
| RFR-Net[ | 25.09 | 90.20 | 24.60 | 83.60 | 23.48 | 80.50 | ||
| EC[ | 25.28 | 84.60 | 24.20 | 78.40 | 21.16 | 73.10 | ||
| GC[ | 23.10 | 85.60 | 21.95 | 75.70 | 21.34 | 72.20 | ||
| FT-TDR[ | 24.45 | 88.50 | — | — | — | — | ||
| ZITS[ | — | — | — | — | 22.11 | 81.70 | ||
| 平均值 | 24.35 | 87.43 | 23.51 | 79.17 | 21.97 | 76.66 | ||
表11 单元图像修复方法在不规则区域的性能分析
Table 11 Quantitative analysis of single image inpainting methods on irregular regions
| 掩码区域面积占比 | 方法 | CelebA-HQ[ | Paris StreetView[ | Places2[ | ||||
|---|---|---|---|---|---|---|---|---|
| PSNR/dB[134] ↑ | SSIM/%[135] ↑ | PSNR/dB[134] ↑ | SSIM/%[135] ↑ | PSNR/dB[134] ↑ | SSIM/%[135] ↑ | |||
| 10%~20% | MED[ | 30.97 | 97.10 | 30.25 | 95.40 | 29.05 | 94.10 | |
| MADF[ | 33.77 | 98.40 | 31.99 | 96.60 | 29.42 | 96.10 | ||
| PEN-Net[ | 29.76 | 96.50 | 28.97 | 93.90 | 27.90 | 92.70 | ||
| RFR-Net[ | 31.87 | 97.60 | 31.43 | 96.20 | 27.75 | 95.20 | ||
| EC[ | 33.51 | 96.10 | 31.23 | 93.80 | 27.95 | 93.90 | ||
| GC[ | 31.02 | 97.10 | 28.95 | 94.00 | 27.42 | 91.70 | ||
| FT-TDR[ | 31.75 | 97.80 | — | — | — | — | ||
| ZITS[ | — | — | — | — | 28.31 | 94.20 | ||
| 平均值 | 31.80 | 97.23 | 30.47 | 94.98 | 28.26 | 93.99 | ||
| 20%~30% | MED[ | 27.75 | 94.30 | 27.08 | 90.90 | 25.92 | 88.80 | |
| MADF[ | 30.42 | 96.70 | 28.71 | 93.30 | 26.29 | 92.20 | ||
| PEN-Net[ | 26.79 | 93.30 | 26.03 | 88.40 | 25.09 | 86.70 | ||
| RFR-Net[ | 29.07 | 95.70 | 28.39 | 92.80 | 27.24 | 91.10 | ||
| EC[ | 30.02 | 92.80 | 28.26 | 89.20 | 24.92 | 86.10 | ||
| GC[ | 27.57 | 94.10 | 25.73 | 88.50 | 24.65 | 85.60 | ||
| FT-TDR[ | 28.57 | 95.90 | — | — | — | — | ||
| ZITS[ | — | — | — | — | 25.40 | 90.20 | ||
| 平均值 | 28.60 | 94.69 | 27.37 | 90.52 | 25.64 | 88.67 | ||
| 30%~40% | MED[ | 25.36 | 90.80 | 24.91 | 85.40 | 23.78 | 82.50 | |
| MADF[ | 27.95 | 94.50 | 26.44 | 89.20 | 23.84 | 87.30 | ||
| PEN-Net[ | 24.70 | 89.40 | 24.12 | 82.10 | 23.21 | 80.10 | ||
| RFR-Net[ | 26.87 | 93.10 | 26.30 | 88.60 | 22.63 | 81.90 | ||
| EC[ | 27.39 | 89.00 | 26.05 | 84.20 | 22.84 | 79.90 | ||
| GC[ | 25.03 | 90.20 | 23.62 | 82.50 | 22.81 | 79.20 | ||
| FT-TDR[ | 26.40 | 93.20 | — | — | — | — | ||
| ZITS[ | — | — | — | — | 23.51 | 86.00 | ||
| 平均值 | 26.24 | 91.46 | 25.24 | 85.33 | 23.23 | 82.41 | ||
| 40%~50% | MED[ | 23.47 | 86.50 | 23.12 | 78.70 | 22.07 | 75.20 | |
| MADF[ | 25.99 | 91.70 | 24.65 | 84.10 | 21.92 | 81.20 | ||
| PEN-Net[ | 23.06 | 84.90 | 22.56 | 74.50 | 21.74 | 72.70 | ||
| RFR-Net[ | 25.09 | 90.20 | 24.60 | 83.60 | 23.48 | 80.50 | ||
| EC[ | 25.28 | 84.60 | 24.20 | 78.40 | 21.16 | 73.10 | ||
| GC[ | 23.10 | 85.60 | 21.95 | 75.70 | 21.34 | 72.20 | ||
| FT-TDR[ | 24.45 | 88.50 | — | — | — | — | ||
| ZITS[ | — | — | — | — | 22.11 | 81.70 | ||
| 平均值 | 24.35 | 87.43 | 23.51 | 79.17 | 21.97 | 76.66 | ||
| 方法 | CelebA-HQ[ | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR/dB[134] ↑ | SSIM/%[135] ↑ | IS[139] ↑ | MIS[109] ↑ | ||||||
| UCTGAN[ | 26.38 | 88.62 | 3.012 7 | 0.017 8 | |||||
| HVQ-VAE[ | 24.56 | 86.75 | 3.456 0 | 0.024 5 | |||||
| 方法 | CelebA-HQ[ | Places2[ | |||||||
| LPIPS[ | LPIPS[ | LPIPS[ | LPIPS[ | ||||||
| PICNet[ | 0.029 0 | 0.088 0 | 0.109 6 | 0.123 8 | |||||
| UCTGAN[ | 0.030 0 | 0.092 0 | — | — | |||||
| PD-GAN[ | — | — | 0.123 8 | 0.179 9 | |||||
| 平均值 | 0.029 5 | 0.090 0 | 0.116 7 | 0.151 9 | |||||
表12 多元图像修复方法在规则区域的性能分析
Table 12 Quantitative analysis of pluralistic image inpainting methods on regular regions
| 方法 | CelebA-HQ[ | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR/dB[134] ↑ | SSIM/%[135] ↑ | IS[139] ↑ | MIS[109] ↑ | ||||||
| UCTGAN[ | 26.38 | 88.62 | 3.012 7 | 0.017 8 | |||||
| HVQ-VAE[ | 24.56 | 86.75 | 3.456 0 | 0.024 5 | |||||
| 方法 | CelebA-HQ[ | Places2[ | |||||||
| LPIPS[ | LPIPS[ | LPIPS[ | LPIPS[ | ||||||
| PICNet[ | 0.029 0 | 0.088 0 | 0.109 6 | 0.123 8 | |||||
| UCTGAN[ | 0.030 0 | 0.092 0 | — | — | |||||
| PD-GAN[ | — | — | 0.123 8 | 0.179 9 | |||||
| 平均值 | 0.029 5 | 0.090 0 | 0.116 7 | 0.151 9 | |||||
| 掩码区域面积占比 | 方法 | FFHQ[ | ImageNet[ | Places2[ | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR/dB[134] ↑ | SSIM/%[135] ↑ | FID[137] ↓ | PSNR/dB[134] ↑ | SSIM/%[135] ↑ | FID[137] ↓ | PSNR/dB[134] ↑ | SSIM/%[135] ↑ | FID[137] ↓ | |||
| 20%~40% | PICNet[ | 26.78 | 93.30 | 14.51 | 24.01 | 86.70 | 47.75 | 26.10 | 86.50 | 26.39 | |
| ICT[ | 28.24 | 95.20 | 10.51 | 24.76 | 88.80 | 28.82 | 26.71 | 88.40 | 20.43 | ||
| PUT[ | 26.88 | 93.60 | 12.78 | 24.24 | 87.50 | 21.27 | 25.45 | 86.10 | 19.62 | ||
| 平均值 | 27.30 | 94.03 | 12.60 | 24.34 | 87.67 | 32.61 | 26.09 | 87.00 | 21.15 | ||
| 40%~60% | PICNet[ | 21.72 | 81.10 | 25.03 | 18.84 | 64.20 | 101.28 | 21.50 | 68.00 | 49.09 | |
| ICT[ | 23.08 | 86.40 | 20.84 | 20.14 | 72.10 | 59.49 | 22.64 | 73.90 | 34.21 | ||
| PUT[ | 22.38 | 84.50 | 21.38 | 19.74 | 70.40 | 45.15 | 21.53 | 70.30 | 31.49 | ||
| 平均值 | 22.39 | 84.00 | 22.42 | 19.57 | 68.90 | 68.64 | 21.89 | 70.73 | 38.26 | ||
| 10%~60% | PICNet[ | 25.58 | 88.90 | 17.36 | 22.71 | 79.10 | 59.43 | 25.04 | 80.60 | 33.47 | |
| ICT[ | 26.16 | 92.20 | 14.04 | 23.78 | 83.50 | 35.84 | 25.98 | 83.90 | 25.42 | ||
| PUT[ | 25.94 | 90.60 | 14.55 | 23.26 | 80.60 | 27.65 | 24.49 | 80.60 | 22.12 | ||
| 平均值 | 25.89 | 90.57 | 15.32 | 23.25 | 81.07 | 40.97 | 25.17 | 81.70 | 27.00 | ||
表13 多元图像修复方法在不规则区域的性能分析
Table 13 Quantitative analysis of pluralistic image inpainting methods on irregular regions
| 掩码区域面积占比 | 方法 | FFHQ[ | ImageNet[ | Places2[ | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR/dB[134] ↑ | SSIM/%[135] ↑ | FID[137] ↓ | PSNR/dB[134] ↑ | SSIM/%[135] ↑ | FID[137] ↓ | PSNR/dB[134] ↑ | SSIM/%[135] ↑ | FID[137] ↓ | |||
| 20%~40% | PICNet[ | 26.78 | 93.30 | 14.51 | 24.01 | 86.70 | 47.75 | 26.10 | 86.50 | 26.39 | |
| ICT[ | 28.24 | 95.20 | 10.51 | 24.76 | 88.80 | 28.82 | 26.71 | 88.40 | 20.43 | ||
| PUT[ | 26.88 | 93.60 | 12.78 | 24.24 | 87.50 | 21.27 | 25.45 | 86.10 | 19.62 | ||
| 平均值 | 27.30 | 94.03 | 12.60 | 24.34 | 87.67 | 32.61 | 26.09 | 87.00 | 21.15 | ||
| 40%~60% | PICNet[ | 21.72 | 81.10 | 25.03 | 18.84 | 64.20 | 101.28 | 21.50 | 68.00 | 49.09 | |
| ICT[ | 23.08 | 86.40 | 20.84 | 20.14 | 72.10 | 59.49 | 22.64 | 73.90 | 34.21 | ||
| PUT[ | 22.38 | 84.50 | 21.38 | 19.74 | 70.40 | 45.15 | 21.53 | 70.30 | 31.49 | ||
| 平均值 | 22.39 | 84.00 | 22.42 | 19.57 | 68.90 | 68.64 | 21.89 | 70.73 | 38.26 | ||
| 10%~60% | PICNet[ | 25.58 | 88.90 | 17.36 | 22.71 | 79.10 | 59.43 | 25.04 | 80.60 | 33.47 | |
| ICT[ | 26.16 | 92.20 | 14.04 | 23.78 | 83.50 | 35.84 | 25.98 | 83.90 | 25.42 | ||
| PUT[ | 25.94 | 90.60 | 14.55 | 23.26 | 80.60 | 27.65 | 24.49 | 80.60 | 22.12 | ||
| 平均值 | 25.89 | 90.57 | 15.32 | 23.25 | 81.07 | 40.97 | 25.17 | 81.70 | 27.00 | ||
| [1] |
JAM J, KENDRICK C, WALKER K, et al. A comprehensive review of past and present image inpainting methods[J]. Computer Vision and Image Understanding, 2021, 203: 103147.
DOI URL |
| [2] | BERTALMIO M, SAPIRO G, CASELLES V, et al. Image inpainting[C]// Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, Jul 23-28, 2000. New York: ACM, 2000: 417-424. |
| [3] |
QURESHI M A, DERICHE M. A bibliography of pixel-based blind image forgery detection techniques[J]. Signal Processing: Image Communication, 2015, 39: 46-74.
DOI URL |
| [4] |
GUILLEMOT C, LE MEUR O. Image inpainting: overview and recent advances[J]. IEEE Signal Processing Magazine, 2013, 31(1): 127-144.
DOI URL |
| [5] |
ELHARROUSS O, ALMAADEED N, AL-MAADEED S, et al. Image inpainting: a review[J]. Neural Processing Letters, 2020, 51(2): 2007-2028.
DOI URL |
| [6] | RUMELHART D E, HINTON G E, WILLIAMS R J. Learning internal representations by error propagation[R]. California Univ San Diego La Jolla Inst for Cognitive Science, 1985. |
| [7] | RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation[C]// LNCS 9351: Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Oct 5-9, 2015. Cham: Springer, 2015: 234-241. |
| [8] | GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]// Proceedings of the Annual Conference on Neural Information Processing Systems 2014, Montreal, Dec 8-13, 2014. Red Hook: Curran Associates, 2014: 2672-2680. |
| [9] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the Annual Conference on Neural Information Processing Systems 2017, Long Beach, Dec 4-9, 2017. Red Hook: Curran Associates, 2017: 5998-6008. |
| [10] |
BALLESTER C, BERTALMIO M, CASELLES V, et al. Filling-in by joint interpolation of vector fields and gray levels[J]. IEEE Transactions on Image Processing, 2001, 10(8): 1200-1211.
DOI PMID |
| [11] |
SHEN J, CHAN T F. Mathematical models for local nontexture inpaintings[J]. SIAM Journal on Applied Mathematics, 2002, 62(3): 1019-1043.
DOI URL |
| [12] |
CHAN T F, SHEN J. Nontexture inpainting by curvature-driven diffusions[J]. Journal of Visual Communication and Image Representation, 2001, 12(4): 436-449.
DOI URL |
| [13] |
TSAI A, YEZZI A, WILLSKY A S. Curve evolution implementation of the Mumford-Shah functional for image segmentation, denoising, interpolation, and magnification[J]. IEEE Transactions on Image Processing, 2001, 10(8): 1169-1186.
DOI PMID |
| [14] |
SHEN J, KANG S H, CHAN T F. Euler’s elastica and curvature-based inpainting[J]. SIAM Journal on Applied Mathematics, 2003, 63(2): 564-592.
DOI URL |
| [15] | 周密, 彭进业, 赵健, 等. 改进的整体变分法在图像修复中的应用[J]. 计算机工程与应用, 2007, 43(27): 88-90. |
| ZHOU M, PENG J Y, ZHAO J, et al. Improved total variation method for image inpainting[J]. Computer Engineering and Applications, 2007, 43(27): 88-90. | |
| [16] | 田艳艳, 祝轩, 彭进业, 等. 一种基于整体变分的图像修补算法及其应用[J]. 计算机工程与应用, 2008, 44(26): 180-182. |
| TIAN Y Y, ZHU X, PENG J Y, et al. Implementation for digital image inpainting based on total variation[J]. Computer Engineering and Applications, 2008, 44(26): 180-182. | |
| [17] | 李薇, 何金海, 屈磊, 等. 一种改进的BSCB修复模型[J]. 计算机工程与应用, 2008, 44(9): 184-186. |
| LI W, HE J H, QU L, et al. Improved method for BSCB image inpainting[J]. Computer Engineering and Applications, 2008, 44(9): 184-186. | |
| [18] | 刘庚龙, 檀结庆. 一种改进的整体变分图像修复方法[J]. 计算机工程与应用, 2012, 48(7): 194-196. |
| LIU G L, TAN J Q. Improved method of total variation image inpainting[J]. Computer Engineering and Applications, 2012, 48(7): 194-196. | |
| [19] | EFROS A A, LEUNG T K. Texture synthesis by non-parametric sampling[C]// Proceedings of the 1999 International Conference on Computer Vision, Kerkyra, Sep 20-25, 1999. Washington: IEEE Computer Society, 1999: 1033-1038. |
| [20] | WEI L Y, LEVOY M. Fast texture synthesis using tree-structured vector quantization[C]// Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, Jul 23-28, 2000. New York: ACM, 2000: 479-488. |
| [21] | ASHIKHMIN M. Synthesizing natural textures[C]// Proceedings of the 2001 Symposium on Interactive 3D Graphics, Chapel Hill, Mar 26-29, 2001. New York: ACM, 2001: 217-226. |
| [22] |
DRORI I, COHEN-OR D, YESHURUN H. Fragment-based image completion[J]. ACM Transactions on Graphics, 2003, 22(3): 303-312.
DOI URL |
| [23] | LEVIN A, ZOMET A, WEISS Y. Learning how to inpaint from global image statistics[C]// Proceedings of the 9th IEEE International Conference on Computer Vision, Nice, Oct 14-17, 2003. Washington: IEEE Computer Society, 2003: 305-312. |
| [24] |
CRIMINISI A, PÉREZ P, TOYAMA K. Region filling and object removal by exemplar-based image inpainting[J]. IEEE Transactions on Image Processing, 2004, 13(9): 1200-1212.
PMID |
| [25] | 张申华, 王克刚, 祝轩. 局部特征信息约束的改进Criminisi算法[J]. 计算机工程与应用, 2014, 50(8): 127-130. |
| ZHANG S H, WANG K G, ZHU X. Improved Criminisi algorithm constrained by local feature[J]. Computer Engineering and Applications, 2014, 50(8): 127-130. | |
| [26] | 方宝龙, 尹立新, 常晨. 改进的基于样例的图像修复方法[J]. 计算机工程与应用, 2014, 50(8): 143-146. |
| FANG B L, YIN L X, CHANG C. Improved exemplar-based algorithm for image inpainting[J]. Computer Engineering and Applications, 2014, 50(8): 143-146. | |
| [27] |
赵娜, 王慧琴, 吴萌. 基于马尔科夫随机场匹配准则的Criminisi修复算法[J]. 计算机科学与探索, 2017, 11(7): 1150-1158.
DOI |
|
ZHAO N, WANG H Q, WU M. Criminisi digital inpainting algorithm based on Markov random field matching criterion[J]. Journal of Frontiers of Computer Science and Technology, 2017, 11(7): 1150-1158.
DOI |
|
| [28] |
CROSS G R, JAIN A K. Markov random field texture models[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1983(1): 25-39.
PMID |
| [29] | BARNES C, SHECHTMAN E, FINKELSTEIN A, et al. PatchMatch: a randomized correspondence algorithm for structural image editing[J]. ACM Transactions on Graphics, 2009, 28(3): 24. |
| [30] | HAYS J, EFROS A A. Scene completion using millions of photographs[J]. ACM Transactions on Graphics, 2007, 26(3): 4. |
| [31] | PATHAK D, KRÄHENBÜHL P, DONAHUE J, et al. Context encoders: feature learning by inpainting[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 2536-2544. |
| [32] | IIZUKA S, SIMO-SERRA E, ISHIKAWA H. Globally and locally consistent image completion[J]. ACM Transactions on Graphics, 2017, 36(4): 1-14. |
| [33] | LIAO L, HU R, XIAO J, et al. Edge-aware context encoder for image inpainting[C]// Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing, Seoul, Apr 22-27, 2018. Piscataway: IEEE, 2018: 3156-3160. |
| [34] | VO H V, DUONG N Q K, PÉREZ P. Structural inpainting[C]// Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Oct 22-26, 2018. New York: ACM, 2018: 1948-1956. |
| [35] | YANG J, QI Z, SHI Y. Learning to incorporate structure knowledge for image inpainting[C]// Proceedings of the 2020 AAAI Conference on Artificial Intelligence, New York, Feb 7-12, 2020: 12605-12612. |
| [36] | CAO C, FU Y. Learning a sketch tensor space for image inpainting of man-made scenes[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Oct 10-17, 2021. Piscataway: IEEE, 2021: 14509-14518. |
| [37] | YU J, LIN Z, YANG J, et al. Free-form image inpainting with gated convolution[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Oct 27-Nov 3, 2019. Piscataway: IEEE, 2019: 4470-4479. |
| [38] | WANG Y, TAO X, QI X, et al. Image inpainting via generative multi-column convolutional neural networks[C]// Proceedings of the Annual Conference on Neural Information Processing Systems 2018, Montréal, Dec 3-8, 2018: 329-338. |
| [39] | LIU H, JIANG B, SONG Y, et al. Rethinking image inpainting via a mutual encoder-decoder with feature equalizations[C]// LNCS 12347: Proceedings of the 16th European Conference on Computer Vision, Glasgow, Aug 23-28, 2020. Cham: Springer, 2020: 725-741. |
| [40] |
刘微容, 米彦春, 杨帆, 等. 基于多级解码网络的图像修复[J]. 电子学报, 2022, 50(3): 625-636.
DOI |
| LIU W R, MI Y C, YANG F, et al. Generative image inpainting with multi-stage decoding network[J]. Acta Electronica Sinica, 2022, 50(3): 625-636. | |
| [41] | SAGONG M, SHIN Y, KIM S, et al. PEPSI: fast image inpainting with parallel decoding network[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Los Angeles, Jun 15-21, 2019. Piscataway: IEEE, 2019: 11360-11368. |
| [42] | YU J, LIN Z, YANG J, et al. Generative image inpainting with contextual attention[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-23, 2018. Washington: IEEE Computer Society, 2018: 5505-5514. |
| [43] |
SHIN Y G, SAGONG M C, YEO Y J, et al. PEPSI++: fast and lightweight network for image inpainting[J]. IEEE Transactions on Neural Networks and Learning Systems, 2020, 32(1): 252-265.
DOI URL |
| [44] | SUIN M, PUROHIT K, RAJAGOPALAN A N. Distillation-guided image inpainting[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Jun 19-25, 2021. Piscataway: IEEE, 2021: 2461-2470. |
| [45] | YU T, GUO Z, JIN X, et al. Region normalization for image inpainting[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence, the 32nd Innovative Applications of Artificial Intelligence Conference, the 10th AAAI Symposium on Educational Advances in Artificial Intelligence, New York, Feb 7-12, 2020. Menlo Park: AAAI, 2020: 12733-12740. |
| [46] |
ZHU M, HE D, LI X, et al. Image inpainting by end-to-end cascaded refinement with mask awareness[J]. IEEE Transactions on Image Processing, 2021, 30: 4855-4866.
DOI URL |
| [47] |
李健, 孙大松, 张备伟. 结合双编码器与对抗训练的图像修复[J]. 计算机工程与应用, 2021, 57(7): 192-197.
DOI |
|
LI J, SUN D S, ZHANG B W. Image restoration using dual-encoder and adversarial training[J]. Computer Engineering and Applications, 2021, 57(7): 192-197.
DOI |
|
| [48] |
XU R, GUO M, WANG J, et al. Texture memory-augmented deep patch-based image inpainting[J]. IEEE Transactions on Image Processing, 2021, 30: 9112-9124.
DOI URL |
| [49] | WANG W, ZHANG J, NIU L, et al. Parallel multi-resolution fusion network for image inpainting[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Oct 10-17, 2021. Piscataway: IEEE, 2021: 14539-14548. |
| [50] | 曹承瑞, 刘微容, 史长宏, 等. 多级注意力传播驱动的生成式图像修复方法[J]. 自动化学报, 2022, 48(5): 1343-1352. |
| CAO C R, LIU W R, SHI C H, et al. Generative image inpainting with attention propagation[J]. Acta Automatica Sinica, 2022, 48(5): 1343-1352. | |
| [51] | YU Y, ZHAN F, LU S, et al. WaveFill: a wavelet-based generation network for image inpainting[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Oct 10-17, 2021. Piscataway: IEEE, 2021: 14094-14103. |
| [52] | SONG Y, YANG C, LIN Z, et al. Contextual-based image inpainting: infer, match, and translate[C]// LNCS 11206: Proceedings of the 15th European Conference on Computer Vision, Munich, Sep 8-14, 2018. Cham: Springer, 2018: 3-18. |
| [53] | WANG T, OUYANG H, CHEN Q. Image inpainting with external-internal learning and monochromic bottleneck[C]// Proceedings of the 2021 IEEE Conference on Computer Vision and Pattern Recognition. Washington: IEEE Computer Society, 2021: 5120-5129. |
| [54] | LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, Jun 7-12, 2015. Washington: IEEE Computer Society, 2015: 3431-3440. |
| [55] | YAN Z, LI X, LI M, et al. Shift-net: image inpainting via deep feature rearrangement[C]// LNCS 11218: Proceedings of the 15th European Conference on Computer Vision, Munich, Sep 8-14, 2018. Cham: Springer, 2018: 3-19. |
| [56] | GUO Z Y, CHEN Z B, YU T, et al. Progressive image inpainting with full-resolution residual network[C]// Proceedings of the 27th ACM International Conference on Multimedia, Nice, Oct 21-25, 2019. New York: ACM, 2019: 2496-2504. |
| [57] | LIU G, REDA F A, SHIH K J, et al. Image inpainting for irregular holes using partial convolutions[C]// LNCS 11215:Proceedings of the 15th European Conference on Computer Vision, Munich, Sep 8-14, 2018. Cham: Springer, 2018: 89-105. |
| [58] | HONG X, XIONG P, JI R, et al. Deep fusion network for image completion[C]// Proceedings of the 27th ACM International Conference on Multimedia, Nice, Oct 21-25, 2019. New York: ACM, 2019: 2033-2042. |
| [59] | ZENG Y H, FU J L, CHAO H Y, et al. Learning pyramid-context encoder network for high-quality image inpainting[C]// Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, Jun 16-20, 2019. Piscataway: IEEE, 2019: 1486-1494. |
| [60] |
QIN J, BAI H, ZHAO Y. Multi-scale attention network for image inpainting[J]. Computer Vision and Image Understanding, 2021, 204: 103155.
DOI URL |
| [61] | WANG C, SHAO M, MENG D, et al. Dual-pyramidal image inpainting with dynamic normalization[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32. |
| [62] | LIU H Y, JIANG B, XIAO Y, et al. Coherent semantic attention for image inpainting[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Oct 27-Nov 2, 2019. Piscataway: IEEE, 2019: 4170-4179. |
| [63] |
QUAN W, ZHANG R, ZHANG Y, et al. Image inpainting with local and global refinement[J]. IEEE Transactions on Image Processing, 2022, 31: 2405-2420.
DOI PMID |
| [64] | XIE C H, LIU S H, LI C, et al. Image inpainting with learnable bidirectional attention maps[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Oct 27-Nov 2, 2019. Piscataway: IEEE, 2019: 8857-8866. |
| [65] | WANG Y, CHEN Y C, TAO X, et al. VCNet: a robust approach to blind image inpainting[C]// LNCS 12370: Proceedings of the 16th European Conference on Computer Vision, Glasgow, Aug 23-28, 2020. Cham: Springer, 2020: 752-768. |
| [66] |
WANG N, ZHANG Y, ZHANG L. Dynamic selection network for image inpainting[J]. IEEE Transactions on Image Processing, 2021, 30: 1784-1798.
DOI PMID |
| [67] | LI J Y, HE F X, ZHANG L F, et al. Progressive reconstruction of visual structure for image inpainting[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Oct 27-Nov 2, 2019. Piscataway: IEEE, 2019: 5962-5971. |
| [68] | ISOLA P, ZHU J Y, ZHOU T, et al. Image-to-image translation with image inpainting via conditional texture and structure dual generationtional adversarial networks[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 1125-1134. |
| [69] | MIYATO T, KATAOKA T, KOYAMA M, et al. Spectral normalization for generative adversarial networks[J]. arXiv:1802.05957, 2018. |
| [70] | LIAO L, XIAO J, WANG Z, et al. Guidance and evaluation: semantic-aware image inpainting for mixed scenes[C]// LNCS 12372: Proceedings of the 16th European Conference on Computer Vision, Glasgow, Aug 23-28, 2020. Cham: Springer, 2020: 683-700. |
| [71] | GUO X, YANG H, HUANG D. Image inpainting via conditional texture and structure dual generation[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Oct 10-17, 2021. Piscataway: IEEE, 2021: 14114-14123. |
| [72] | WANG N, LI J Y, ZHANG L F, et al. MUSICAL: multi-scale image contextual attention learning for inpainting[C]// Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, Aug 10-16, 2019: 3748-3754. |
| [73] | LIAO L, XIAO J, WANG Z, et al. Image inpainting guided by coherence priors of semantics and textures[C]// Proceedings of the 2021 IEEE Conference on Computer Vision and Pattern Recognition. Washington: IEEE Computer Society, 2021: 6539-6548. |
| [74] | LI J, WANG N, ZHANG L, et al. Recurrent feature reasoning for image inpainting[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 7757-7765. |
| [75] | ALBAWI S, MOHAMMED T A, AL-ZAWI S. Understanding of a convolutional neural network[C]// Proceedings of the 2017 International Conference on Engineering and Technology, Antalya, Aug 21-23, 2017. Piscataway: IEEE, 2017: 1-6. |
| [76] | YI Z L, TANG Q, AZIZI S, et al. Contextual residual aggregation for ultra high-resolution image inpainting[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, Jun 19-25, 2020. Piscataway: IEEE, 2020: 7505-7514. |
| [77] | YEH R A, CHEN C, YIAN LIM T, et al. Semantic image inpainting with deep generative models[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 6882-6890. |
| [78] | RADFORD A, METZ L, CHINTALA S. Unsupervised representation learning with deep convolutional generative adversarial networks[J]. arXiv:1511.06434, 2015. |
| [79] | LI Y J, LIU S F, YANG J M, et al. Generative face completion[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 5892-5900. |
| [80] | SUN Q R, MA L Q, OH S J, et al. Natural and effective obfuscation by head inpainting[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-22, 2018. Washington: IEEE Computer Society, 2018: 5050-5059. |
| [81] | DOLHANSKY B, FERRER C C. Eye in-painting with exemplar generative adversarial networks[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-22, 2018. Washington: IEEE Computer Society, 2018: 7902-7911. |
| [82] | LIAO H F, FUNKA-LEA G, ZHENG Y, et al. Face completion with semantic knowledge and collaborative adversarial learning[C]// LNCS 11361: Proceedings of the 14th Asian Conference on Computer Vision, Perth, Dec 2-6, 2018. Cham: Springer, 2018: 382-397. |
| [83] |
ZHANG X, WANG X, SHI C H, et al. DE-GAN: domain embedded GAN for high quality face image inpainting[J]. Pattern Recognition, 2022, 124: 108415.
DOI URL |
| [84] | YANG C, LU X, LIN Z, et al. High-resolution image inpainting using multi-scale neural patch synthesis[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 6721-6729. |
| [85] | ZENG Y, LIN Z, YANG J, et al. High-resolution image inpainting with iterative confidence feedback and guided upsampling[C]// LNCS 12364: Proceedings of the 16th European Conference on Computer Vision, Glasgow, Aug 23-28, 2020. Cham: Springer, 2020: 1-17. |
| [86] | GULRAJANI I, AHMED F, ARJOVSKY M, et al. Improved training of Wasserstein GANs[C]// Proceedings of the Annual Conference on Neural Information Processing Systems 2017, Long Beach, Dec 4-9, 2017. Red Hook: Curran Associates, 2017: 5767-5777. |
| [87] | SONG Y, YANG C, SHEN Y, et al. SPG-Net: segmentation prediction and guidance network for image inpainting[J]. arXiv:1805.03356, 2018. |
| [88] | XIONG W, YU J, LIN Z, et al. Foreground-aware image inpainting[C]// Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, Jun 16-20, 2019. Piscataway: IEEE, 2019: 5840-5848. |
| [89] | REN Y, YU X, ZHANG R, et al. StructureFlow: image inpainting via structure-aware appearance flow[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Oct 27-Nov 3, 2019. Piscataway: IEEE, 2019: 181-190. |
| [90] | NAZERI K, NG E, JOSEPH T, et al. EdgeConnect: generative image inpainting with adversarial edge learning[J]. arXiv:1901.00212, 2019. |
| [91] |
王富平, 李文楼, 刘颖, 等. 结合边缘信息和门卷积的人脸修复算法[J]. 计算机科学与探索, 2021, 15(1): 150-162.
DOI |
|
WANG F P, LI W L, LIU Y, et al. Face inpainting algorithm combining edge information with gated convolution[J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(1): 150-162.
DOI |
|
| [92] | LAHIRI A, JAIN A K, AGRAWAL S, et al. Prior guided GAN based semantic inpainting[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, Jun 19-25, 2020. Piscataway: IEEE, 2020: 13693-13702. |
| [93] | ZENG Y, LIN Z, LU H C, et al. CR-Fill: generative image inpainting with auxiliary contextual reconstruction[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Oct 10-17, 2021. Piscataway: IEEE, 2021: 14144-14153. |
| [94] | ZHANG H, HU Z, LUO C, et al. Semantic image inpainting with progressive generative networks[C]// Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Oct 22-26, 2018. New York: ACM, 2018: 1939-1947. |
| [95] |
HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780.
PMID |
| [96] | ARDINO P, LIU Y, RICCI E, et al. Semantic-guided inpainting network for complex urban scenes manipulation[C]// Proceedings of the 25th International Conference on Pattern Recognition, Milan, Jan 10-15, 2021. Piscataway: IEEE, 2021: 9280-9287. |
| [97] | HUI Z, LI J, WANG X, et al. Image fine-grained inpainting[J]. arXiv:2002.02609, 2020. |
| [98] |
李克文, 张文韬, 邵明文, 等. 多尺度生成式对抗网络图像修复算法[J]. 计算机科学与探索, 2020, 14(1): 159-170.
DOI |
|
LI K W, ZHANG W T, SHAO M W, et al. Multi-scale generative adversarial networks image inpainting algorithm[J]. Journal of Frontiers of Computer Science and Technology, 2020, 14(1): 159-170.
DOI |
|
| [99] | ZENG Y, FU J, CHAO H, et al. Aggregated contextual transformations for high-resolution image inpainting[J]. arXiv: 2104.01431, 2021. |
| [100] | ZHOU Y, BARNES C, SHECHTMAN E, et al. TransFill: reference-guided image inpainting by merging multiple color and spatial transformations[C]// Proceedings of the 2021 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 2266-2276. |
| [101] | WANG J, CHEN S, WU Z, et al. FT-TDR: frequency-guided transformer and top-down refinement network for blind face inpainting[J]. arXiv:2108.04424, 2021. |
| [102] | ZHENG C, CHAM T J, CAI J. TFill: image completion via a transformer-based architecture[J]. arXiv:2104.00845, 2021. |
| [103] | DONG Q, CAO C, FU Y. Incremental transformer structure enhanced image inpainting with masking positional encoding[J]. arXiv:2203.00867, 2022. |
| [104] | KINGMA D P, WELLING M. Auto-encoding variational Bayes[J]. arXiv:1312.6114, 2013. |
| [105] | HAN X, WU Z, HUANG W, et al. FiNet: compatible and diverse fashion image inpainting[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Oct 27-Nov 2, 2019. Piscataway: IEEE, 2019: 4480-4490. |
| [106] | DUPONT E, SURESHA S. Probabilistic semantic inpainting with pixel constrained CNNs[C]// Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics, Apr 16-18, 2019: 2261-2270. |
| [107] | ZHENG C X, CHAM T J, CAI J F. Pluralistic image completion[C]// Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, Jun 16-20, 2019. Piscataway: IEEE, 2019: 1438-1447. |
| [108] | ZHANG L, CHEN Q, HU B, et al. Text-guided neural image inpainting[C]// Proceedings of the 28th ACM International Conference on Multimedia, Seattle, Oct 12-16, 2020. New York: ACM, 2020: 1302-1310. |
| [109] | ZHAO L, MO Q, LIN S, et al. UCTGAN: diverse image inpainting based on unsupervised cross-space translation[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 5740-5749. |
| [110] | PENG J, LIU D, XU S, et al. Generating diverse structure for image inpainting with hierarchical VQ-VAE[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Kuala Lumpur, Dec 18-20, 2021. Piscataway: IEEE, 2021: 10775-10784. |
| [111] | LIU H, WAN Z, HUANG W, et al. PD-GAN: probabilistic diverse GAN for image inpainting[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Kuala Lumpur, Dec 18-20, 2021. Piscataway: IEEE, 2021: 9371-9381. |
| [112] |
PHUTKE S S, MURALA S. Diverse receptive field based adversarial concurrent encoder network for image inpainting[J]. IEEE Signal Processing Letters, 2021, 28: 1873-1877.
DOI URL |
| [113] | YU Y, ZHAN F, WU R, et al. Diverse image inpainting with bidirectional and autoregressive transformers[C]// Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, Oct 20-24, 2021. New York: ACM, 2021: 69-78. |
| [114] | WAN Z, ZHANG J, CHEN D, et al. High-fidelity pluralistic image completion with transformers[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Jun 19-25, 2021. Piscataway: IEEE, 2021: 4672-4681. |
| [115] | ZHAO S, CUI J, SHENG Y, et al. Large scale image completion via co-modulated generative adversarial networks[J]. arXiv:2103.10428, 2021. |
| [116] | LI W, LIN Z, ZHOU K, et al. MAT: mask-aware transformer for large hole image inpainting[J]. arXiv:2203. 15270, 2022. |
| [117] | LIU Q, TAN Z, CHEN D, et al. Reduce information loss in transformers for pluralistic image inpainting[J]. arXiv:2205.05076, 2022. |
| [118] | ISKAKOV K. Semi-parametric image inpainting[J]. arXiv:1807.02855, 2018. |
| [119] | TYLEČEK R, ŠÁRA R. Spatial pattern templates for recognition of objects with regular structure[C]// LNCS 8142: Proceedings of the 35th German Conference on Pattern Recognition, Saarbrücken, Sep 3-6, 2013. Berlin, Heidelberg: Springer, 2013: 364-374. |
| [120] | CIMPOI M, MAJI S, KOKKINOS I, et al. Describing textures in the wild[C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, Jun 23-28, 2014. Washington: IEEE Computer Society, 2014: 3606-3613. |
| [121] | NETZER Y, WANG T, COATES A, et al. Reading digits in natural images with unsupervised feature learning[C]// Proceedings of the 2011 NIPS Workshop on Deep Learning & Unsupervised Feature Learning, 2011. |
| [122] | DOERSCH C, SINGH S, GUPTA A, et al. What makes paris look like paris?[J]. ACM Transactions on Graphics, 2012, 31(4): 101. |
| [123] | CORDTS M, OMRAN M, RAMOS S, et al. The cityscapes dataset for semantic urban scene understanding[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-Jul 1, 2016. Washington: IEEE Computer Society, 2016: 3213-3223. |
| [124] | LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: Microsoft COCO: common objects in context[C]//LNCS 8693: Proceedings of the 13th European Conference on Computer Vision, Zurich, Sep 6-12, 2014. Cham: Springer, 2014: 740-755. |
| [125] |
RUSSAKOVSKY O, DENG J, SU H, et al. ImageNet large scale visual recognition challenge[J]. International Journal of Computer Vision, 2015, 115(3): 211-252.
DOI URL |
| [126] |
ZHOU B, LAPEDRIZA A, KHOSLA A, et al. Places: a 10 million image database for scene recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 40(6): 1452-1464.
DOI URL |
| [127] | LE V, BRANDT J, LIN Z, et al. Interactive facial feature localization[C]// LNCS 7574: Proceedings of the 12th European Conference on Computer Vision, Florence, Oct 7-13, 2012. Berlin, Heidelberg: Springer, 2012: 679-692. |
| [128] | LIU Z W, LUO P, WANG X G, et al. Deep learning face attributes in the wild[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Dec 7-13, 2015. Washington: IEEE Computer Society, 2015: 3730-3738. |
| [129] | KARRAS T, AILA T, LAINE S, et al. Progressive growing of GANs for improved quality, stability, and variation[J]. arXiv:1710.10196, 2017. |
| [130] | KARRAS T, LAINE S, AILA T. A style-based generator architecture for generative adversarial networks[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seoul, Oct 27-Nov 3, 2019: 4401-4410. |
| [131] | LOSSON O, MACAIRE L, YANG Y. Comparison of color demosaicing methods[M]//HAWKES P W. Advances in Imaging and Electron Physics. New York: Elsevier Science Inc., 2010: 173-265. |
| [132] | HACCIUS C, HERFET T. Computer vision performance and image quality metrics: a reciprocal relation[C]// Proceedings of the 2nd International Conference on Computer Science, Information Technology and Applications, 2017: 27-37. |
| [133] |
WANG Z, BOVIK A C. A universal image quality index[J]. IEEE Signal Processing Letters, 2002, 9(3): 81-84.
DOI URL |
| [134] |
AVCIBAS I, SANKUR B, SAYOOD K. Statistical evaluation of image quality measures[J]. Journal of Electronic Imaging, 2002, 11(2): 206-223.
DOI URL |
| [135] |
WANG Z, BOVIK A C, SHEIKH H R, et al. Image quality assessment: from error visibility to structural similarity[J]. IEEE Transactions on Image Processing, 2004, 13(4): 600-612.
PMID |
| [136] | WANG Z, SIMONCELLI E P, BOVIK A C. Multiscale structural similarity for image quality assessment[C]// Proceedings of the 37th Asilomar Conference on Signals, Systems & Computers, Pacific Grove, Nov 9-12, 2003. Piscataway: IEEE, 2003: 1398-1402. |
| [137] | ZHANG R, ISOLA P, EFROS A A, et al. The unreasonable effectiveness of deep features as a perceptual metric[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-22, 2018. Washington: IEEE Computer Society, 2018: 586-595. |
| [138] | HEUSEL M, RAMSAUER H, UNTERTHINER T, et al. GANs trained by a two time-scale update rule converge to a local Nash equilibrium[C]// Proceedings of the Annual Conference on Neural Information Processing Systems 2017, Long Beach, Dec 4-9, 2017. Red Hook: Curran Associates, 2017: 6626-6637. |
| [139] | SALIMANS T, GOODFELLOW I, ZAREMBA W, et al. Improved techniques for training GANs[C]// Proceedings of the Annual Conference on Neural Information Processing Systems 2016, Barcelona, Dec 5-10, 2016. Red Hook: Curran Associates, 2016: 2226-2234. |
| [140] | SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking the inception architecture for computer vision[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 2818-2826. |
| [1] | 吕晓琦, 纪科, 陈贞翔, 孙润元, 马坤, 邬俊, 李浥东. 结合注意力与循环神经网络的专家推荐算法[J]. 计算机科学与探索, 2022, 16(9): 2068-2077. |
| [2] | 张祥平, 刘建勋. 基于深度学习的代码表征及其应用综述[J]. 计算机科学与探索, 2022, 16(9): 2011-2029. |
| [3] | 李冬梅, 罗斯斯, 张小平, 许福. 命名实体识别方法研究综述[J]. 计算机科学与探索, 2022, 16(9): 1954-1968. |
| [4] | 任宁, 付岩, 吴艳霞, 梁鹏举, 韩希. 深度学习应用于目标检测中失衡问题研究综述[J]. 计算机科学与探索, 2022, 16(9): 1933-1953. |
| [5] | 杨才东, 李承阳, 李忠博, 谢永强, 孙方伟, 齐锦. 深度学习的图像超分辨率重建技术综述[J]. 计算机科学与探索, 2022, 16(9): 1990-2010. |
| [6] | 曾凡智, 许露倩, 周燕, 周月霞, 廖俊玮. 面向智慧教育的知识追踪模型研究综述[J]. 计算机科学与探索, 2022, 16(8): 1742-1763. |
| [7] | 安凤平, 李晓薇, 曹翔. 权重初始化-滑动窗口CNN的医学图像分类[J]. 计算机科学与探索, 2022, 16(8): 1885-1897. |
| [8] | 张好聪, 李涛, 邢立冬, 潘风蕊. OpenVX特征抽取函数在可编程并行架构的实现[J]. 计算机科学与探索, 2022, 16(7): 1583-1593. |
| [9] | 刘艺, 李蒙蒙, 郑奇斌, 秦伟, 任小广. 视频目标跟踪算法综述[J]. 计算机科学与探索, 2022, 16(7): 1504-1515. |
| [10] | 赵小明, 杨轶娇, 张石清. 面向深度学习的多模态情感识别研究进展[J]. 计算机科学与探索, 2022, 16(7): 1479-1503. |
| [11] | 夏鸿斌, 肖奕飞, 刘渊. 融合自注意力机制的长文本生成对抗网络模型[J]. 计算机科学与探索, 2022, 16(7): 1603-1610. |
| [12] | 孙方伟, 李承阳, 谢永强, 李忠博, 杨才东, 齐锦. 深度学习应用于遮挡目标检测算法综述[J]. 计算机科学与探索, 2022, 16(6): 1243-1259. |
| [13] | 刘雅芬, 郑艺峰, 江铃燚, 李国和, 张文杰. 深度半监督学习中伪标签方法综述[J]. 计算机科学与探索, 2022, 16(6): 1279-1290. |
| [14] | 董文轩, 梁宏涛, 刘国柱, 胡强, 于旭. 深度卷积应用于目标检测算法综述[J]. 计算机科学与探索, 2022, 16(5): 1025-1042. |
| [15] | 程卫月, 张雪琴, 林克正, 李骜. 融合全局与局部特征的深度卷积神经网络算法[J]. 计算机科学与探索, 2022, 16(5): 1146-1154. |
| 阅读次数 | ||||||||||||||||||||||||||||||||||||||||||||||||||
|
全文 1524
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||
|
摘要 2253
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||