
Journal of Frontiers of Computer Science and Technology ›› 2022, Vol. 16 ›› Issue (1): 120-136.DOI: 10.3778/j.issn.1673-9418.2008068
• Database Technology • Previous Articles Next Articles
LIU Weiming, ZHANG Chi, MAO Yimin+( )
)
Received:2020-08-21
Revised:2020-11-03
Online:2022-01-01
Published:2020-11-19
About author:LIU Weiming, born in 1964, professor, M.S. supervisor. His research interests include data mining and big data.Supported by:
刘卫明, 张弛, 毛伊敏+()
通讯作者:
+ E-mail: mymlyc@163.com作者简介:刘卫明(1964-),男,江西新余人,教授,硕士生导师,主要研究方向为数据挖掘、大数据。基金资助:CLC Number:
LIU Weiming, ZHANG Chi, MAO Yimin. Hybrid Parallel Frequent Itemsets Mining Algorithm by Using N-List Structure[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(1): 120-136.
刘卫明, 张弛, 毛伊敏. 采用N-list结构的混合并行频繁项集挖掘算法[J]. 计算机科学与探索, 2022, 16(1): 120-136.
Add to citation manager EndNote|Ris|BibTeX
URL: http://fcst.ceaj.org/EN/10.3778/j.issn.1673-9418.2008068
| ID | Items |
|---|---|
| 1 | a,c,g,f |
| 2 | e,b,h |
| 3 | e,c,b,i |
| 4 | b,c,e |
| 5 | b,f,a,c,e |
| 6 | b,c,f,a |
Table 1 Transaction database - DB
| ID | Items |
|---|---|
| 1 | a,c,g,f |
| 2 | e,b,h |
| 3 | e,c,b,i |
| 4 | b,c,e |
| 5 | b,f,a,c,e |
| 6 | b,c,f,a |
| 原始数据 | Map | Combine | Reduce |
|---|---|---|---|
| a,c,g,f | <a:1>,<c:1>,<g:1>, <f:1> | <a:3>, <b:5> <c:5>, <g:1> <e:4>, <f:3> <h:1>, <i:1> | <b:5> <c:5> <e:4> <a:3> <f:3> |
| e,b,h | <e:1>,<b:1>,<h:1> | ||
| e,c,b,i | <e:1>,<c:1>,<b:1>,<i:1> | ||
| b,c,e | <b:1><c:1>,<e:1> | ||
| b,f,a,c,e | <b:1>,<f:1>,<a:1>,<c:1>,<e:1> | ||
| b, f, c, a | <b:1>,<f:1>,<c:1>,<a:1> |
Table 2 Process of getting F-list
| 原始数据 | Map | Combine | Reduce |
|---|---|---|---|
| a,c,g,f | <a:1>,<c:1>,<g:1>, <f:1> | <a:3>, <b:5> <c:5>, <g:1> <e:4>, <f:3> <h:1>, <i:1> | <b:5> <c:5> <e:4> <a:3> <f:3> |
| e,b,h | <e:1>,<b:1>,<h:1> | ||
| e,c,b,i | <e:1>,<c:1>,<b:1>,<i:1> | ||
| b,c,e | <b:1><c:1>,<e:1> | ||
| b,f,a,c,e | <b:1>,<f:1>,<a:1>,<c:1>,<e:1> | ||
| b, f, c, a | <b:1>,<f:1>,<c:1>,<a:1> |
| F-list | L-list | G-list | 负载量 |
|---|---|---|---|
| {(b:5),(c:5),(e:4),(a:3),(f:3)} | {(e:4),(a:3),(f:3),(c:2),(b:1)} | gid=1:{(e,f, b)} gid=2:{(a,c)} | 8 5 |
Table 3 Without using GM-GS to group F-list
| F-list | L-list | G-list | 负载量 |
|---|---|---|---|
| {(b:5),(c:5),(e:4),(a:3),(f:3)} | {(e:4),(a:3),(f:3),(c:2),(b:1)} | gid=1:{(e,f, b)} gid=2:{(a,c)} | 8 5 |
| F-list | L-list | G-list | 负载量 |
|---|---|---|---|
| {(b:5),(c:5),(e:4),(a:3),(f:3)} | {(e:4),(a:3),(f:3),(c:2),(b:1)} | gid=1:{(f, c, b)} gid=2:{(e,a)} | 6 7 |
Table 4 Using GM-GS to group F-list
| F-list | L-list | G-list | 负载量 |
|---|---|---|---|
| {(b:5),(c:5),(e:4),(a:3),(f:3)} | {(e:4),(a:3),(f:3),(c:2),(b:1)} | gid=1:{(f, c, b)} gid=2:{(e,a)} | 6 7 |
| Gid | 属于该组的记录 |
|---|---|
| 1 | 1-(c,a,f);2-(b);3-(b,c);4-(b,c);5-(b,c,e,a,f);6-(b,c,a,f) |
| 2 | 1-(c,a);2-(b,e);3-(b,c,e);4-(b,c,e);5-(b,c,e,a);6-(b,c,a) |
Table 5 Each group data allocated to Reducestage by using GM-GS method
| Gid | 属于该组的记录 |
|---|---|
| 1 | 1-(c,a,f);2-(b);3-(b,c);4-(b,c);5-(b,c,e,a,f);6-(b,c,a,f) |
| 2 | 1-(c,a);2-(b,e);3-(b,c,e);4-(b,c,e);5-(b,c,e,a);6-(b,c,a) |
| Gid | 属于该组的记录 |
|---|---|
| 1 | 1-(c,a,f);2-(b,e);3-(b,c,e);4-(b,c,e);5-(b,c,e,a,f);6-(b,c,a,f) |
| 2 | 1-(c,a);2-( |
Table 6 Each group data allocated to Reducestage without using GM-GS method
| Gid | 属于该组的记录 |
|---|---|
| 1 | 1-(c,a,f);2-(b,e);3-(b,c,e);4-(b,c,e);5-(b,c,e,a,f);6-(b,c,a,f) |
| 2 | 1-(c,a);2-( |

Fig.1 PPC-Tree
| 步骤 | MRPrePost中N-list合并过程 | EAS合并策略 |
|---|---|---|
| 1 | | |
| 2 | | |
| 3 | | |
| 4 | |
Table 7 Comparison of two methods for merging N-list
| 步骤 | MRPrePost中N-list合并过程 | EAS合并策略 |
|---|---|---|
| 1 | | |
| 2 | | |
| 3 | | |
| 4 | |
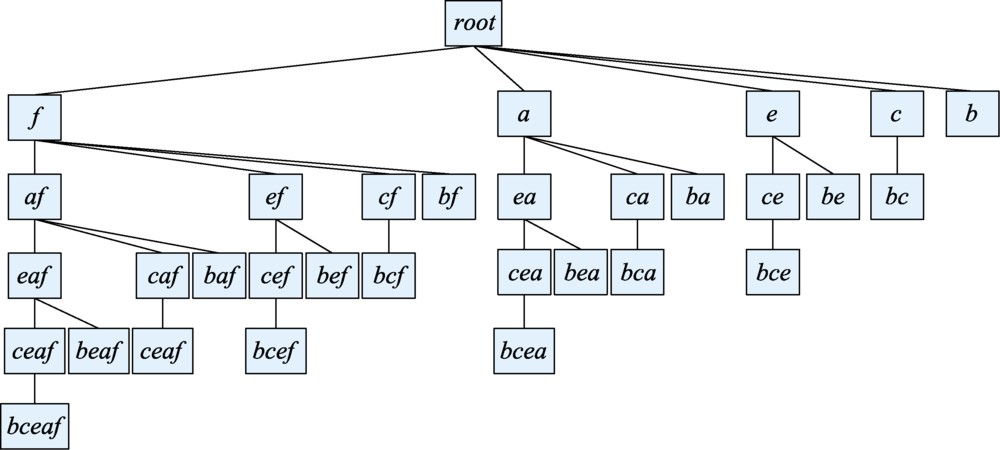
Fig.2 Set-enumeration tree

Fig.3 Set-enumeration tree after pruning

Fig.4 Comparison of PPC-Tree
| Item | (gid=1:c,f,b) | Item | (gid=2:e,a) |
|---|---|---|---|
| b | {(4,9,5)} | b | {(3,7,5)} |
| c | {(1,2,1),(5,8,4)} | c | {(1,1,1),(5,6,4)} |
| e | {(6,5,3)} | e | {(4,2,1),(6,4,3)} |
| a | {(2,1,1),(9,7,1)} | a | {(2,0,1),(7,3,1),(8,5,1)} |
| f | {(3,0,1),(8,3,1),(10,6,1)} | — | — |
Table 8 N-list sequence of each node in each group
| Item | (gid=1:c,f,b) | Item | (gid=2:e,a) |
|---|---|---|---|
| b | {(4,9,5)} | b | {(3,7,5)} |
| c | {(1,2,1),(5,8,4)} | c | {(1,1,1),(5,6,4)} |
| e | {(6,5,3)} | e | {(4,2,1),(6,4,3)} |
| a | {(2,1,1),(9,7,1)} | a | {(2,0,1),(7,3,1),(8,5,1)} |
| f | {(3,0,1),(8,3,1),(10,6,1)} | — | — |
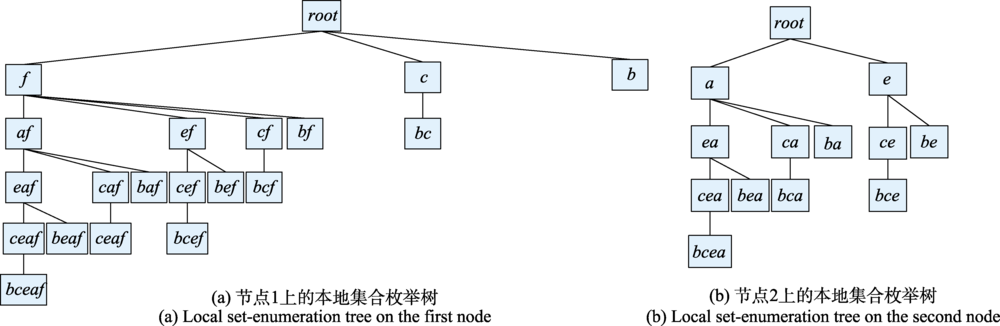
Fig.5 Local set-enumeration tree on different nodes
| 频繁项集 | 计算节点1 | 计算节点2 |
|---|---|---|
| 频繁1项集 | (b:5),(c:5),(f:3) | (e:4),(a:3) |
| 频繁2项集 | (bc:4),(bf:2),(cf:2),(af:3) | (be:4),(ba:2)(ce:3),(ca:3) |
| 频繁3项集 | (caf:3),(baf:3) | (bce:3),(bca:2) |
| 频繁4项集 | (bcaf:2) | — |
Table 9 All frequent itemsets
| 频繁项集 | 计算节点1 | 计算节点2 |
|---|---|---|
| 频繁1项集 | (b:5),(c:5),(f:3) | (e:4),(a:3) |
| 频繁2项集 | (bc:4),(bf:2),(cf:2),(af:3) | (be:4),(ba:2)(ce:3),(ca:3) |
| 频繁3项集 | (caf:3),(baf:3) | (bce:3),(bca:2) |
| 频繁4项集 | (bcaf:2) | — |
| 主机名 | IP地址 | 角色 |
|---|---|---|
| Master | 192.168.1.109 | Master/JobTracker/NameNode |
| Slaver_1 | 192.168.1.110 | Slaver/TaskTracker/DateNode |
| Slaver_2 | 192.168.1.111 | Slaver/TaskTracker/DateNode |
| Slaver_3 | 192.168.1.112 | Slaver/TaskTracker/DateNode |
Table 10 Basic configuration of nodes in experimental environment
| 主机名 | IP地址 | 角色 |
|---|---|---|
| Master | 192.168.1.109 | Master/JobTracker/NameNode |
| Slaver_1 | 192.168.1.110 | Slaver/TaskTracker/DateNode |
| Slaver_2 | 192.168.1.111 | Slaver/TaskTracker/DateNode |
| Slaver_3 | 192.168.1.112 | Slaver/TaskTracker/DateNode |
| 项目 | | | | |
|---|---|---|---|---|
| 记录数/条 | 1 692 082 | 990 002 | 5 000 000 | 340 183 |
| 项数/个 | 5 267 656 | 41 270 | 190 | 468 |
| 大小/MB | 1 481.9 | 32.1 | 321.0 | 35.5 |
Table 11 Experimental data sets
| 项目 | | | | |
|---|---|---|---|---|
| 记录数/条 | 1 692 082 | 990 002 | 5 000 000 | 340 183 |
| 项数/个 | 5 267 656 | 41 270 | 190 | 468 |
| 大小/MB | 1 481.9 | 32.1 | 321.0 | 35.5 |
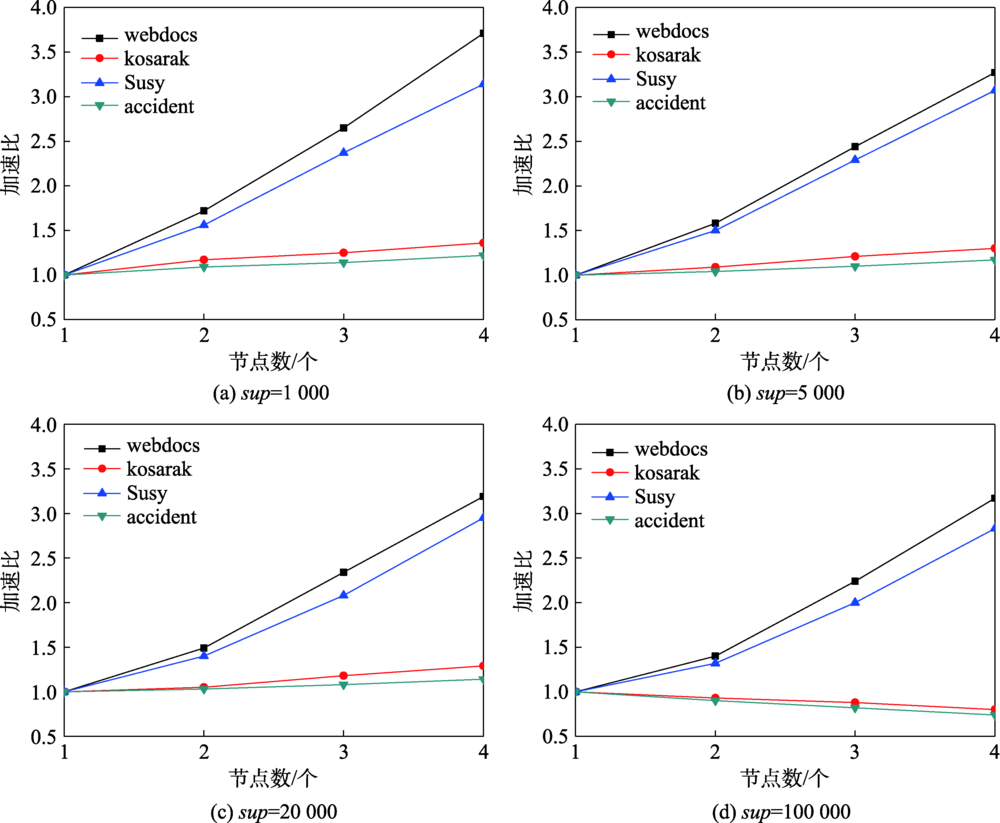
Fig.6 Acceleration rate of algorithm on different computing nodes

Fig.7 Comparison of algorithm running time with or without GM-GS strategy
| 数据集 | 支持数 | |||
|---|---|---|---|---|
| 1 000 | 5 000 | 20 000 | 100 000 | |
| webdocs | 17 104 | 6 385 | 2 420 | 556 |
| kosarak | 1 253 | 156 | 27 | 4 |
| Susy | 117 | 112 | 99 | 91 |
| accident | 207 | 151 | 102 | 32 |
Table 12 F-list size of four data setswith different support degrees
| 数据集 | 支持数 | |||
|---|---|---|---|---|
| 1 000 | 5 000 | 20 000 | 100 000 | |
| webdocs | 17 104 | 6 385 | 2 420 | 556 |
| kosarak | 1 253 | 156 | 27 | 4 |
| Susy | 117 | 112 | 99 | 91 |
| accident | 207 | 151 | 102 | 32 |

Fig.8 Comparison of running time of four algorithms on different data sets
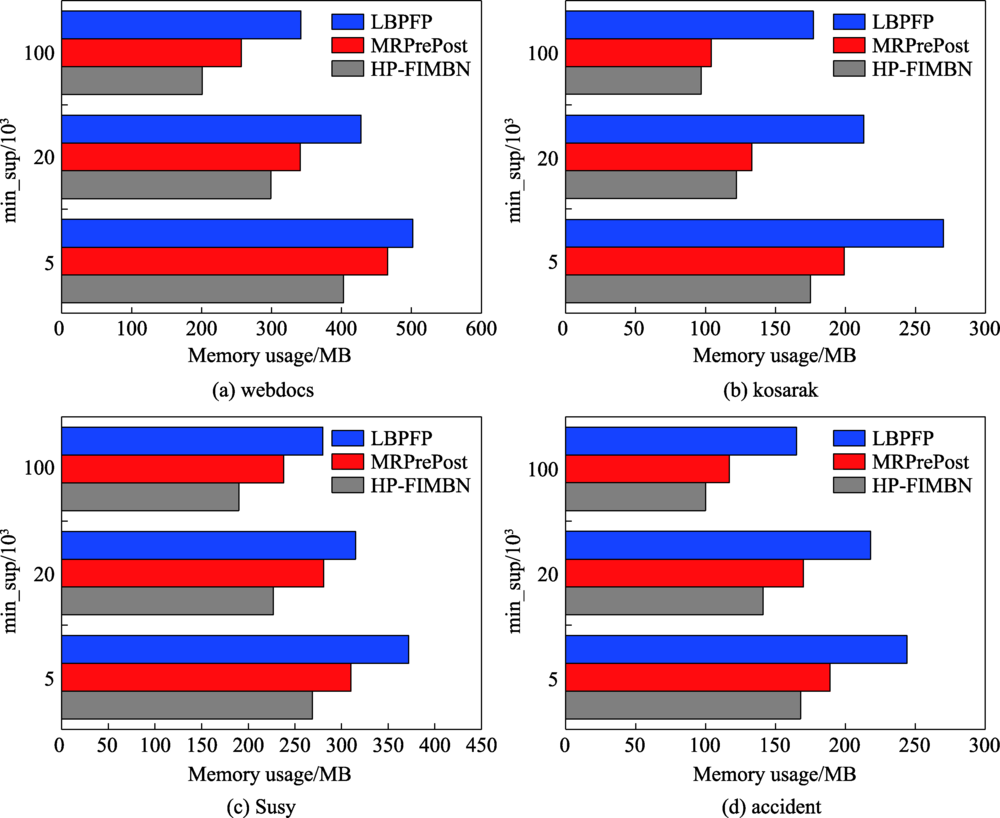
Fig.9 Comparison of memory usage of different algorithms on different data sets
| [1] | KUANG Z J, ZHOU H, ZHOU D D, et al. A non-group parallel frequent pattern mining algorithm based on conditional patterns[J]. Frontiers of Information Technology & Electronic Engineering, 2019, 20(9):1234-1245. |
| [2] | 李琪. 基于MapReduce并行的关联规则挖掘算法研究与应用[D]. 北京: 北京邮电大学, 2018. |
| LI Q. Research and application of association rules mining algorithm based on MapReduce[D]. Beijing: Beijing University of Posts and Telecommunications, 2018. | |
| [3] | 肖文, 胡娟, 周晓峰. 基于MapReduce计算模型的并行关联规则挖掘算法研究综述[J]. 计算机应用研究, 2018, 35(1):13-23. |
| XIAO W, HU J, ZHOU X F. Parallel association rules mining algorithm based on MapReduce: a survey[J]. Application Research of Computers, 2018, 35(1):13-23. | |
| [4] | AGRAWAL R, SRIKANT R. Fast algorithm for mining association rules[C]// Proceedings of the 20th International Conference on Very Large Data Bases. San Francisco: Morgan Kaufmann Publishers Inc., 1994: 487-499. |
| [5] | HAN J W, PEI J, YIN Y W, et al. Mining frequent patterns without candidate generation: a frequent-pattern tree approach[J]. Data Mining & Knowledge-Based Systems, 2004, 8(1):53-87. |
| [6] |
PYUN G, YUN U, RYU K H. Efficient frequent pattern mining based on liner prefix tree[J]. Knowledge-Based Systems, 2014, 55:125-139.
DOI URL |
| [7] | ZAKI M J, PARTHASARATHY S, OGIHARA M. New algorithms for fast discovery of association rules[C]// Proceedings of the 3rd International Conference on Knowledge Discovery and Data Mining, Newport Beach, Aug 14-17, 1997. Menlo Park: AAAI, 1997: 283-286. |
| [8] | 宋杰, 孙宗哲, 毛克明, 等. MapReduce大数据处理平台与算法研究进展[J]. 软件学报, 2017, 28(3):514-543. |
| SONG J, SUN Z Z, MAO K M, et al. Research advance on MapReduce based on big data processing platforms and algorithms[J]. Journal of Software, 2017, 28(3):514-543. | |
| [9] | 程阳, 章韵. 基于MapReduce-HBase的Apriori算法的改进与研究[J]. 南京邮电大学学报(自然科学版), 2018, 38(5):91-99. |
| CHENG Y, ZHANG Y. Improvement and research on Apriori algorithm based on MapReduce-HBase[J]. Journal of Nanjing University of Posts and Telecommunications (Natural Science), 2018, 38(5):91-99. | |
| [10] | HUANG D C, SONG Y, ROUTRAY R, et al. Smart cache: an optimized MapReduce implementation of frequent itemset mining[C]// Proceedings of the 2015 IEEE International Conference on Cloud Engineering, Tempe, Mar 9-13, 2015. Washington: IEEE Computer Society, 2015: 16-25. |
| [11] | 秦军, 郝天曙, 董倩倩. 基于MapReduce的Apriori算法并行化改进[J]. 计算机技术与发展, 2017, 27(4):64-68. |
| QIN J, HAO T S, DONG Q Q. Parallel improvement of Apriori algorithm based on MapReduce[J]. Computer Technology and Development, 2017, 27(4):64-68. | |
| [12] | LI H Y, WANG Y, ZHANG D, et al. PFP: parallel FP-growth for query recommendation[C]// Proceedings of the 2008 ACM Conference on Recommender Systems, Lausanne, Oct 23-25, 2008. New York: ACM, 2008: 107-114. |
| [13] | ZHOU L, ZHONG Z Y, CHANG J, et al. Balanced parallel FP-growth with MapReduce[C]// Proceedings of the 2010 IEEE Youth Conference on Information, Computing and Telecommunications, Beijing, Nov 28-30, 2010. Piscataway: IEEE, 2010: 243-246. |
| [14] | WANG Y, ZHANG Z, WANG F. A parallel algorithm of association rules based on cloud computing[C]// Proceedings of the 2013 8th International Conference on Communications and Networking in China, Guilin, Aug 14-16, 2013. Piscataway: IEEE, 2013: 415-419. |
| [15] | 陈兴蜀, 张帅, 童浩, 等. 基于布尔矩阵和MapReduce的FP-Growth算法[J]. 华南理工大学学报(自然科学版), 2014, 42(1):135-141. |
| CHEN X S, ZHANG S, TONG H, et al. FP-Growth algorithm based on Boolean matrix and MapReduce[J]. Journal of South China University of Technology (Natural Science Edition), 2014, 42(1):135-141. | |
| [16] | 高权, 万晓东. 基于负载均衡的并行FP-Growth算法[J]. 计算机工程, 2019, 45(3):32-35. |
| GAO Q, WAN X D. Parallel FP-Growth algorithm based on load balance[J]. Computer Engineering, 2019, 45(3):32-35. | |
| [17] | 孙宗鑫, 张桂芸. 基于位存储Tid的CPU并行化Eclat算法[J]. 计算机工程, 2018, 44(12):79-84. |
| SUN Z X, ZHANG G Y. CPU parallelization Eclat algorithm based on bit storage Tid[J]. Computer Engineering, 2018, 44(12):79-84. | |
| [18] | ZHANG Z G, JI G L, TANG M M. MREclat: an algorithm for parallel mining frequent itemsets[C]// Proceedings of the 2013 International Conference on Advanced Cloud and Big Data, Nanjing, Dec 13-15, 2013. Washington: IEEE Computer Society, 2013: 177-180. |
| [19] | 张春, 汲磊举. 基于MapReduce的Eclat改进算法研究与应用[J]. 北京交通大学学报, 2016, 40(3):1-6. |
| ZHANG C, JI L J. Research and application of Eclat improved algorithm based on MapReduce[J]. Journal of Beijing Jiaotong University, 2016, 40(3):1-6. | |
| [20] | LIAO J G, ZHAO Y L, LONG S Q. MRPrePost—a parallel algorithm adapted for mining big data[C]// Proceedings of the 2014 IEEE Workshop on Electronics, Computer and Applications, Ottawa, May 8-9, 2014. Piscataway: IEEE, 2014: 564-568. |
| [21] | 尹远, 张昌, 文凯, 等. 基于DiffNodeset结构的最大频繁项集挖掘算法[J]. 计算机应用, 2018, 38(12):3438-3443. |
| YIN Y, ZHANG C, WEN K, et al. Maximal frequent itemset mining algorithm based on DiffNodeset structure[J]. Journal of Computer Applications, 2018, 38(12):3438-3443. | |
| [22] |
DENG Z H, WANG Z H, JIANG J J. A new algorithm for fast mining frequent itemsets using N-lists[J]. Science China Information Sciences, 2012, 55(9):2008-2030.
DOI URL |
| [23] |
DENG Z H, LV S L. PrePost+: an efficient N-lists-based algorithm for mining frequent itemsets via children-parent equivalence pruning[J]. Expert Systems with Applications, 2015, 42(13):5424-5432.
DOI URL |
| [1] | XU Xudong, ZHANG Zhixiang, ZHANG Xian. Message Clustering Method for Private Binary Protocol [J]. Journal of Frontiers of Computer Science and Technology, 2020, 14(6): 958-965. |
| [2] | ZHU Xiaohu1,2, SONG Wenjun1,2, WANG Chongjun1,2+, XIE Junyuan1,2. Improved Algorithm Based on Girvan-Newman Algorithm for Community Detection [J]. Journal of Frontiers of Computer Science and Technology, 2010, 4(12): 1101-1108. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
/D:/magtech/JO/Jwk3_kxyts/WEB-INF/classes/