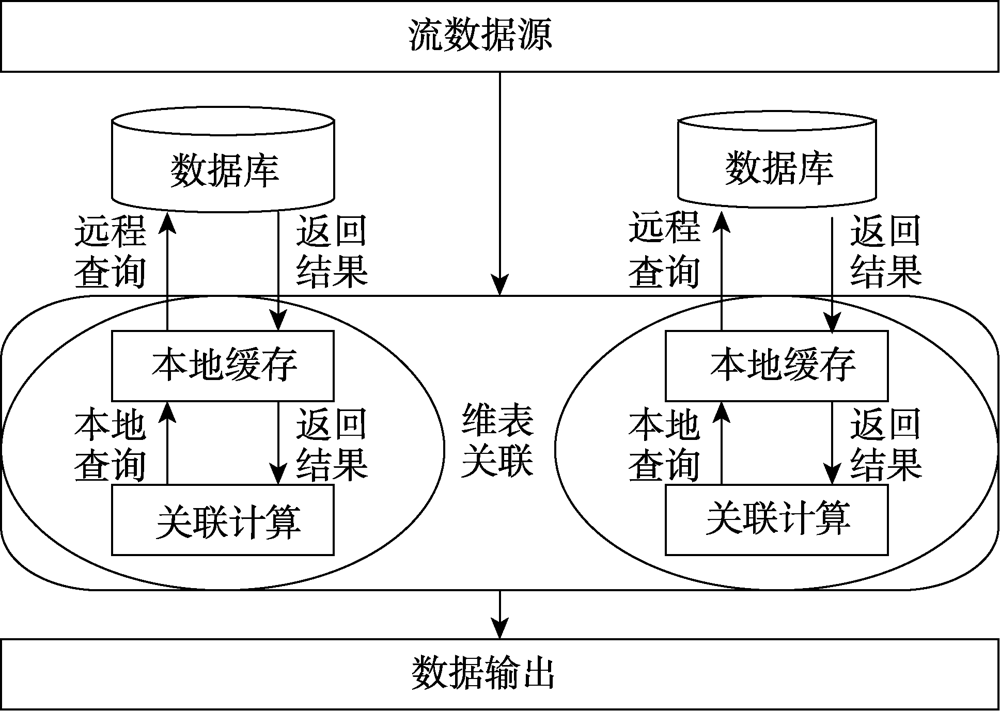
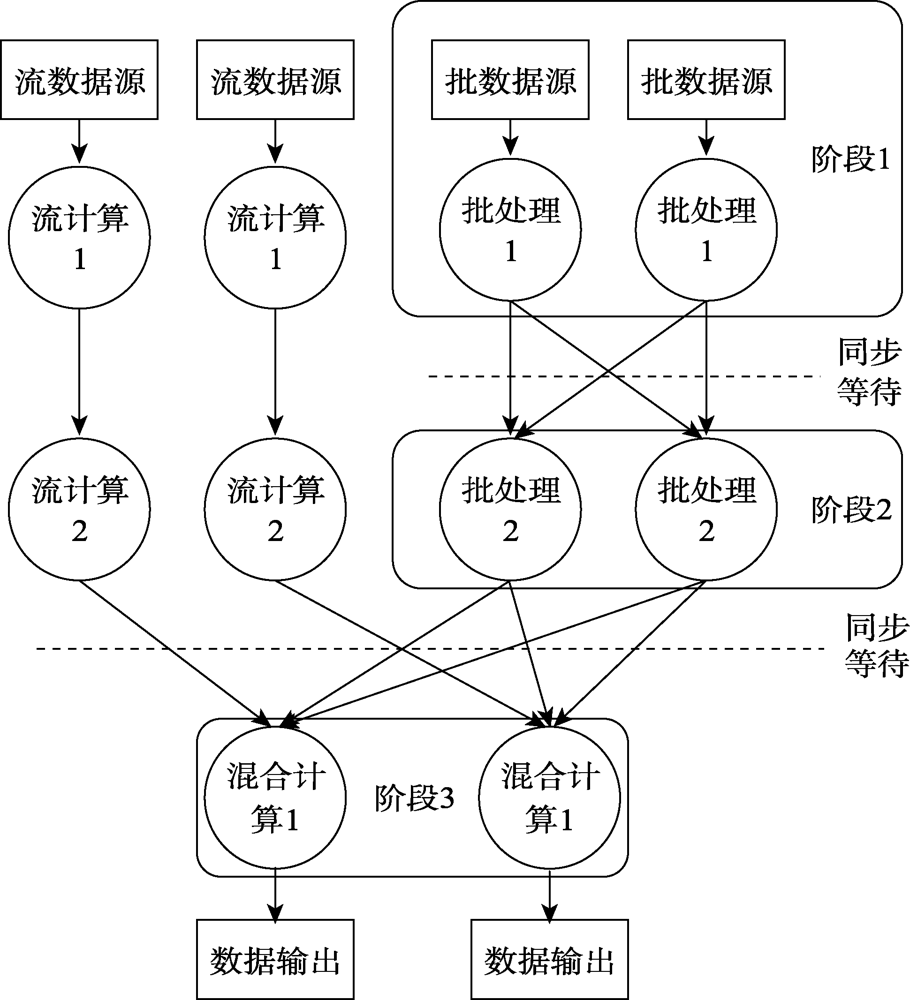
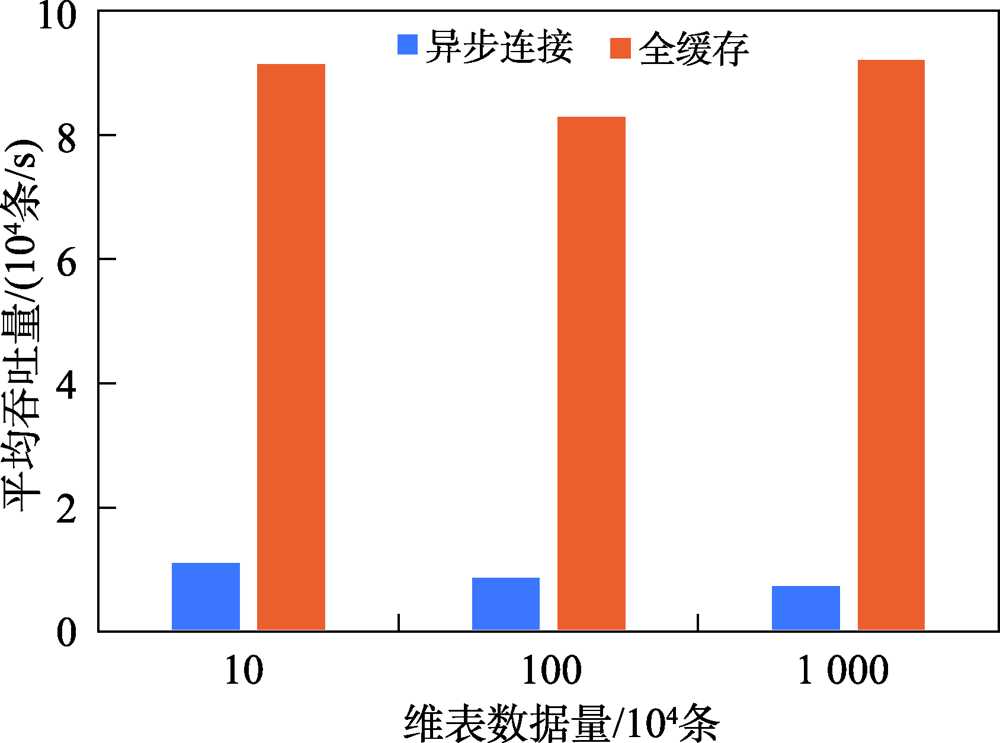
| [1] |
LAVALLE S, LESSER E, SHOCKLEY R, et al. Big data, analytics and the path from insights to value[J]. MIT Sloan Management Review, 2011, 52(2):21-32.
|
| [2] |
WALKER S J. Big data: a revolution that will transform how we live, work, and think[J]. Mathematics & Computer Education, 2014, 47(17):181-183.
|
| [3] |
TAYLOR R C. An overview of the Hadoop/MapReduce/HBase framework and its current applications in bioinformatics[J]. BMC Bioinformatics, 2010, 11:S1.
|
| [4] |
DEAN J, GHEMAWAT S. MapReduce: a flexible data pro-cessing tool[J]. Communications of the ACM, 2010, 53(1):72-77.
|
| [5] |
崔星灿, 禹晓辉, 刘洋, 等. 分布式流处理技术综述[J]. 计算机研究与发展, 2015, 52(2):318-332.
|
|
CUI X C, YU X H, LIU Y, et al. Distributed stream proces-sing: a survey[J]. Journal of Computer Research and Deve-lopment, 2015, 52(2):318-332.
|
| [6] |
ZAHARIA M, CHOWDHURY M, FRANKLIN M J, et al. Spark: cluster computing with working sets[C]// Procee-dings of the 2nd USENIX Workshop on Hot Topics in Cloud Computing, Boston, Jun 22, 2010.
|
| [7] |
KATSIFODIMOS A, SCHELTER S. Apache Flink: stream analytics at scale[C]//Proceedings of the 2016 IEEE Interna-tional Conference on Cloud Engineering Workshop, Berlin, Apr 4-8, 2016. Washington: IEEE Computer Society, 2016: 193.
|
| [8] |
杨莉国, 欧付娜, 刘庆海, 等. 数据仓库相关技术研究综述[J]. 电脑知识与技术, 2011, 7(10):2234-2236.
|
|
YANG L G, OU F N, LIU Q H, et al. Research related tech-nology on data warehouse[J]. Computer Knowledge and Technology, 2011, 7(10):2234-2236.
|
| [9] |
POLYZOTIS N, SKIADOPOULOS S, VASSILIADIS P, et al. Meshing streaming updates with persistent data in an active data warehouse[J]. IEEE Transactions on Knowledge and Data Engineering, 2008, 20(7):976-991.
DOI
URL
|
| [10] |
NAEEM M, DOBBIE G, WEBER G. R-MESHJOIN for near-real-time data warehousing[C]//Proceedings of the 13th International Workshop on Data Warehousing and OLAP, Toronto, Oct 30, 2010. New York: ACM, 2010: 53-60.
|
| [11] |
CHAKRABORTY A, SINGH A. A partition-based approach to support streaming updates over persistent data in an active data warehouse[C]//Proceedings of the 2009 IEEE International Symposium on Parallel and Distributed Pro-cessing, Rome, May 23-29, 2009. Piscataway: IEEE, 2009: 1-11.
|
| [12] |
林子雨, 林琛, 冯少荣, 等. MESHJOIN∗: 实时数据仓库环境下的数据流更新算法[J]. 计算机科学与探索, 2010, 4(10):927-939.
|
|
LIN Z Y, LIN C, FENG S R, et al. MESHJOIN*: an algo-rithm supporting streaming updates in a real-time data ware-house[J]. Journal of Frontiers of Computer Science and Technology, 2010, 4(10):927-939.
|
| [13] |
潘郑冰, 戴牡红. 实时数据仓库中一种改进的数据流更新算法[J]. 计算机工程, 2014, 40(10):43-46.
|
|
PAN Z B, DAI M H. An improved data stream update al-gorithm in real-time data warehouse[J]. Computer Enginee-ring, 2014, 40(10):43-46.
|
| [14] |
NAEEM M A, BAJWA I S, JAMIL N. A cached-based stream-relation join operator for semi-stream data processing[J]. International Journal of Data Warehousing and Mining, 2016, 12(3):14-31.
DOI
URL
|
| [15] |
ZAHARIA M, DAS T, LI H, et al. Discretized streams: fault-tolerant streaming computation at scale[C]//Procee-dings of the 24th ACM Symposium on Operating Systems Principles, Farmington, Nov 3-6, 2013. New York: ACM, 2013: 423-438.
|
| [16] |
ARMBRUST M, DAS T, TORRES J, et al. Structured streaming: a declarative API for real-time applications in Apache Spark[C]//Proceedings of the 2018 International Conference on Management of Data, Houston, Jun 10-15, 2018. New York: ACM, 2018: 601-613.
|
| [17] |
FRICKER C, ROBERT P, ROBERTS J. A versatile and accurate approximation for LRU cache performance[C]//Proceedings of the 2012 24th International Teletraffic Con-gress, Kraków, Sep 4-7, 2012. Piscataway: IEEE, 2012: 1-8.
|
| [18] |
BERTOLUCCI M, CARLINI E, DAZZI P, et al. Static and dynamic big data partitioning on Apache Spark[C]//Procee-dings of the 2015 International Conference on Parallel Com-puting, Edinburgh, Sep 1-4, 2015. Amsterdam: IOS Press, 2015: 489-498.
|
| [19] |
GOUNARIS A, KOUGKA G, TOUS R, et al. Dynamic configuration of partitioning in Spark applications[J]. IEEE Transactions on Parallel and Distributed Systems, 2017, 28(7):1891-1904.
DOI
URL
|
| [20] |
MACEDO T, OLIVEIRA F. Redis Cookbook: practical tech-niques for fast data manipulation[M]. Sebastopol: O’Reilly Media, Inc., 2011.
|
| [21] |
CHINTAPALLI S, DAGIT D, EVANS B, et al. Benchmar-king streaming computation engines: storm, flink and spark streaming[C]//Proceedings of the 2016 IEEE International Parallel and Distributed Processing Symposium Work-shops, Chicago, May 23-27, 2016. Washington: IEEE Com-puter Society, 2016: 1789-1792.
|
| [22] |
HIRES S D, TABACZYNSKI R J, NOVAK J M. The pre-diction of ignition delay and combustion intervals for a homo-geneous charge, spark ignition engine[C]// Proceedings of the 1978 Automotive Engineering Congress and Exposition, 1978.
|

 ), YUAN Ye2, JI Hangxu1, QIAO Baiyou1, WANG Guoren2
), YUAN Ye2, JI Hangxu1, QIAO Baiyou1, WANG Guoren2