
Journal of Frontiers of Computer Science and Technology ›› 2022, Vol. 16 ›› Issue (5): 1064-1075.DOI: 10.3778/j.issn.1673-9418.2010064
• Database Technology • Previous Articles Next Articles
MAO Yimin( ), GENG Junhao
), GENG Junhao
Received:2020-10-26
Revised:2021-01-22
Online:2022-05-01
Published:2022-05-19
About author:MAO Yimin, born in 1970, Ph.D., professor, M.S. supervisor. Her research interests include data mining, big data, etc.Supported by:
毛伊敏(), 耿俊豪
通讯作者:
+ E-mail: mymlyc@163.com作者简介:毛伊敏(1970—),女,新疆伊犁人,博士,教授,硕士生导师,主要研究方向为数据挖掘、大数据等。基金资助:CLC Number:
MAO Yimin, GENG Junhao. Improved Parallel Random Forest Algorithm Combining Information Theory and Norm[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(5): 1064-1075.
毛伊敏, 耿俊豪. 结合信息论和范数的并行随机森林算法[J]. 计算机科学与探索, 2022, 16(5): 1064-1075.
Add to citation manager EndNote|Ris|BibTeX
URL: http://fcst.ceaj.org/EN/10.3778/j.issn.1673-9418.2010064

Fig.1 RSKP strategy

Fig.2 Construct random forests in parallel
| 主机名 | IP地址 | 角色 |
|---|---|---|
| Master | 192.168.1.109 | Master/JobTracker/NameNode |
| Slaver_1 | 192.168.1.110 | Slaver/TaskTracker/DateNode |
| Slaver_2 | 192.168.1.111 | Slaver/TaskTracker/DateNode |
| Slaver_3 | 192.168.1.112 | Slaver/TaskTracker/DateNode |
Table 1 Configuration of nodes in experiment
| 主机名 | IP地址 | 角色 |
|---|---|---|
| Master | 192.168.1.109 | Master/JobTracker/NameNode |
| Slaver_1 | 192.168.1.110 | Slaver/TaskTracker/DateNode |
| Slaver_2 | 192.168.1.111 | Slaver/TaskTracker/DateNode |
| Slaver_3 | 192.168.1.112 | Slaver/TaskTracker/DateNode |
| 数据集 | 样本数/条 | 属性数/种 | 大小/MB |
|---|---|---|---|
| Farm Ads | 1 692 082 | 5 267 656 | 1 481.9 |
| Susy | 990 002 | 41 270 | 32.1 |
| APS Failure at Scania Trucks | 5 000 000 | 190 | 321.0 |
Table 2 Experimental datasets
| 数据集 | 样本数/条 | 属性数/种 | 大小/MB |
|---|---|---|---|
| Farm Ads | 1 692 082 | 5 267 656 | 1 481.9 |
| Susy | 990 002 | 41 270 | 32.1 |
| APS Failure at Scania Trucks | 5 000 000 | 190 | 321.0 |

Fig.3 Performance analysis of PRFITN algorithm
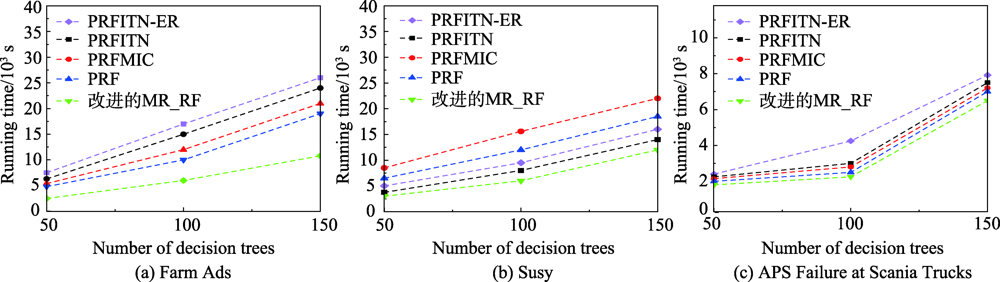
Fig.4 Running time of five algorithms on different datasets

Fig.5 Accuracy of four algorithms on different datasets
| [1] | 杨剑锋, 乔佩蕊, 李永梅, 等. 机器学习分类问题及算法研究综述[J]. 统计与决策, 2019, 35(6): 36-40. |
| YANG J F, QIAO P R, LI Y M, et al. A review of machine-learning classification and algorithms[J]. Statistics & Decision, 2019, 35(6): 36-40. | |
| [2] | 厉柏伸, 李领治, 孙涌, 等. 基于伪梯度提升决策树的内网防御算法[J]. 计算机科学, 2018, 45(4): 157-162. |
| LI B S, LI L Z, SUN Y, et al. Internet defense algorithm based on pseudo Boosting decision tree[J]. Computer Science, 2018, 45(4): 157-162. | |
| [3] |
SALLES T, GONCALVES M, RODRIGUES V, et al. Improving random forests by neighborhood projection for effective text classification[J]. Information Systems, 2018, 77(9): 1-21.
DOI URL |
| [4] |
YAN L, DIAO Y, GAO K. Analysis of environmental factors affecting the atmospheric corrosion rate of low-alloy steel using random forest-based models[J]. Materials, 2020, 13(15): 3266.
DOI URL |
| [5] | 周永圣, 崔佳丽, 周琳云, 等. 基于改进的随机森林模型的个人信用风险评估研究[J]. 征信, 2020, 38(1): 28-32. |
| ZHOU Y S, CUI J L, ZHOU L Y, et al. Study on the evaluation of personal credit risk based on the improved random forest model[J]. Credit Reference, 2020, 38(1): 28-32. | |
| [6] | BOULESTEIX A L, JANITZA S, KRUPPA J, et al. Overview of random forest methodology and practical guidance with emphasis on computational biology and bioinformatics[J]. Wiley Interdisciplinary Reviews: Data Mining and Know-ledge Discovery, 2012, 2(6): 493-507. |
| [7] |
ELYAN E, GABER M M. A fine-grained random forests using class decomposition: an application to medical diagnosis[J]. Neural Computing and Applications, 2016, 27(8): 2279-2288.
DOI URL |
| [8] | 米允龙, 米春桥, 刘文奇. 海量数据挖掘过程相关技术研究进展[J]. 计算机科学与探索, 2015, 9(6): 641-659. |
| MI Y L, MI C Q, LIU W Q. Research advance on related technology of massive data mining process[J]. Journal of Frontiers of Computer Science and Technology, 2015, 9(6): 641-659. | |
| [9] | 宋杰, 孙宗哲, 毛克明, 等. MapReduce大数据处理平台与算法研究进展[J]. 软件学报, 2017, 28(3): 514-543. |
| SONG J, SUN Z Z, MAO K M, et al. Research advance on MapReduce based on big data processing platforms and algorithms[J]. Journal of Software, 2017, 28(3): 514-543. | |
| [10] | 曹蒙蒙, 郭朝有. Hadoop平台下Mahout随机森林算法的分析与实现[J]. 舰船电子工程, 2018, 38(9): 40-44. |
| CAO M M, GUO C Y. Analysis and implementation of random forest algorithm in Mahout based on Hadoop[J]. Ship Electronic Engineering, 2018, 38(9): 40-44. | |
| [11] | 钱雪忠, 秦静, 宋威. 改进的并行随机森林算法及其包外估计[J]. 计算机应用研究, 2018, 35(6): 1651-1654. |
| QIAN X Z, QIN J, SONG W. Improved parallel random forest and its out_of_bag estimator[J]. Application Research of Computers, 2018, 35(6): 1651-1654. | |
| [12] |
CHEN J G, LI K L, TANG Z, et al. A parallel random forest algorithm for big data in a spark cloud computing environment[J]. IEEE Transactions on Parallel and Distributed Systems, 2017, 28(4): 919-933.
DOI URL |
| [13] | LIU S, HU T Y. Parallel random forest algorithm optimization based on maximal information coefficient[C]// Proceedings of the 9th International Conference on Software Engineering and Service Science, Beijing, Nov 23-25, 2018. Piscataway: IEEE, 2018: 1-5. |
| [14] |
SENA I G W, DILLAK J W, LEUNUPUN P, et al. Predicting rainfall intensity using Naïve Bayes and information gain methods[J]. Journal of Physics: Conference Series, 2020, 1577(1): 012011.
DOI URL |
| [15] |
GAO W F, HU L, ZHANG P. Feature redundancy term variation for mutual information-based feature selection[J]. Applied Intelligence, 2020, 50(4): 1272-1288.
DOI URL |
| [16] |
ZHANG F, GAO W F, LIU G X. Feature selection considering weighted relevancy[J]. Applied Intelligence, 2018, 48(12): 4615-4625.
DOI URL |
| [17] |
SERGEEV I. Generalizations of 2-dimensional diagonal quantum channels with constant Frobenius norm[J]. Reports on Mathematical Physics, 2019, 83(3): 349-372.
DOI URL |
| [18] | 陈向阳, 胡晓倩, 吴永祥, 等. 主成分分析法在生物技术专业核心课程成绩评价中的应用[J]. 安徽农业科学, 2020, 48(16): 262-264. |
| CHEN X Y, HU X Q, WU Y X, et al. Application of principal component analysis in the grade evaluation of biotechnology specialty[J]. Journal of Anhui Agricultural Sciences, 2020, 48(16): 262-264. | |
| [19] | 李素, 袁志高, 王聪, 等. 群智能算法优化支持向量机参数综述[J]. 智能系统学报, 2018, 13(1): 70-84. |
| LI S, YUAN Z G, WANG C, et al. Optimization of support vector machine parameters based on group intelligence algorithm[J]. CAAI Transactions on Intelligent Systems, 2018, 13(1): 70-84. |
| [1] | XIA Xiaoqiu, CHEN Songcan. Improved Two-View Random Forest [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(1): 144-152. |
| [2] | YIN Ru, MEN Changqian, WANG Wenjian. Model Decision Forest Algorithm [J]. Journal of Frontiers of Computer Science and Technology, 2020, 14(1): 108-116. |
| [3] | ZHANG Jingwei, SHANG Hongjia, QIAN Junyan, ZHOU Ping, YANG Qing. Join Query Optimization Based on MapReduce under Skewed Data [J]. Journal of Frontiers of Computer Science and Technology, 2017, 11(5): 752-767. |
| [4] | GUO Xinyu, YUE Kun, LI Jin, WU Hao, ZHANG Binbin. Evidence-Theory Approach for Discovering User Preferences in Rating Data [J]. Journal of Frontiers of Computer Science and Technology, 2017, 11(2): 231-241. |
| [5] | LI Dong, DENG Zehang, LI Zuli. Structural Join Processing for XML Based on MapReduce [J]. Journal of Frontiers of Computer Science and Technology, 2016, 10(8): 1080-1091. |
| [6] | HU Zhigang, JING Dongmei, CHEN Bailin, YANG Liu. Research on Semantic Data Query Method Based on Hadoop [J]. Journal of Frontiers of Computer Science and Technology, 2016, 10(7): 948-958. |
| [7] | SHAN Guanmin, DONG Yihong, HE Xianmang. Continuous Probabilistic Skyline Query Based on MapReduce [J]. Journal of Frontiers of Computer Science and Technology, 2016, 10(2): 182-193. |
| [8] | YIN Zidu, YUE Kun, WU Hao, FU Xiaodong, LIU Weiyi. Data Intensive Modeling of Dynamic User Behaviors Based on Forgetting Curve [J]. Journal of Frontiers of Computer Science and Technology, 2016, 10(10): 1376-1386. |
| [9] | ZHANG Anzhen, MEN Xueying, WANG Hongzhi, LI Jianzhong, GAO Hong. Hadoop-Based Inconsistence Detection and Reparation Algorithm for Big Data [J]. Journal of Frontiers of Computer Science and Technology, 2015, 9(9): 1044-1055. |
| [10] | LIU Chao, XU Yabin, WU Zhuang. Method for Rapid Detecting Micro-Blog Communities [J]. Journal of Frontiers of Computer Science and Technology, 2015, 9(9): 1100-1107. |
| [11] | JIANG Yong, ZHAO Zuopeng. Research on Optimization of Sorting Algorithm Based on MapReduce [J]. Journal of Frontiers of Computer Science and Technology, 2015, 9(4): 410-417. |
| [12] | SUN Heli, CHEN Qiang, LIU Wei, HUANG Jianbin, ZOU Jianhua. Using MapReduce Platform to Achieve Efficient Parallel Mining of Frequent Subgraphs [J]. Journal of Frontiers of Computer Science and Technology, 2014, 8(7): 790-801. |
| [13] | YAN Cairong, ZHANG Yangshun, XU Guangwei. Crowdsourcing Entity Resolution with Privacy Protection [J]. Journal of Frontiers of Computer Science and Technology, 2014, 8(7): 802-811. |
| [14] | SHI Jingang, ZHENG Yan, SUN Huanliang, LUAN Fangjun. Parallel Processing of Block Cipher for Massive Data in Cloud Computing [J]. Journal of Frontiers of Computer Science and Technology, 2014, 8(2): 161-170. |
| [15] | LIU Heng, KOU Yue, SHEN Derong, WANG Taiming, YU Ge. Distributed SimRank Algorithm Based on Random Walk Path [J]. Journal of Frontiers of Computer Science and Technology, 2014, 8(12): 1422-1431. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
/D:/magtech/JO/Jwk3_kxyts/WEB-INF/classes/