
Journal of Frontiers of Computer Science and Technology ›› 2022, Vol. 16 ›› Issue (9): 2061-2067.DOI: 10.3778/j.issn.1673-9418.2012119
• Artificial Intelligence • Previous Articles Next Articles
GONG Suming, CHEN Ying( )
)
Received:2020-12-31
Revised:2021-02-25
Online:2022-09-01
Published:2021-03-04
About author:GONG Suming, born in 1995, M.S. candidate. His research interests include pattern recognition and action recognition.Supported by:
龚苏明, 陈莹()
通讯作者:
+ E-mail: chenying@jiangnan.edu.cn作者简介:龚苏明(1995—),男,江苏镇江人,硕士研究生,主要研究方向为模式识别、行为识别。基金资助:CLC Number:
GONG Suming, CHEN Ying. Video Action Recognition Based on Spatio-Temporal Feature Pyramid Module[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(9): 2061-2067.
龚苏明, 陈莹. 时空特征金字塔模块下的视频行为识别[J]. 计算机科学与探索, 2022, 16(9): 2061-2067.
Add to citation manager EndNote|Ris|BibTeX
URL: http://fcst.ceaj.org/EN/10.3778/j.issn.1673-9418.2012119
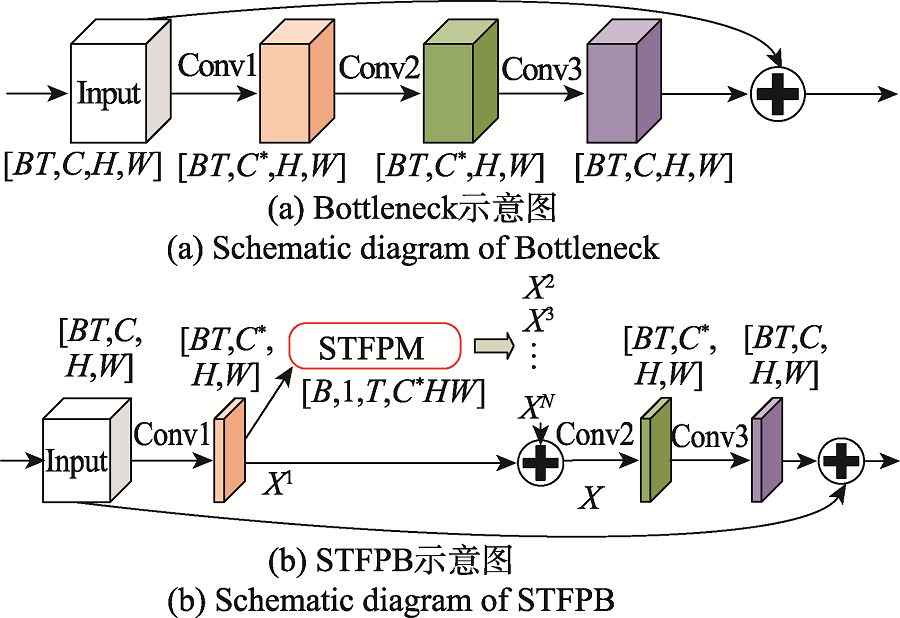
Fig.1 Composition module of ResNet50 and corresponding improvement module

Fig.2 Overall structure of network

Fig.3 Schematic diagram of feature pyramid
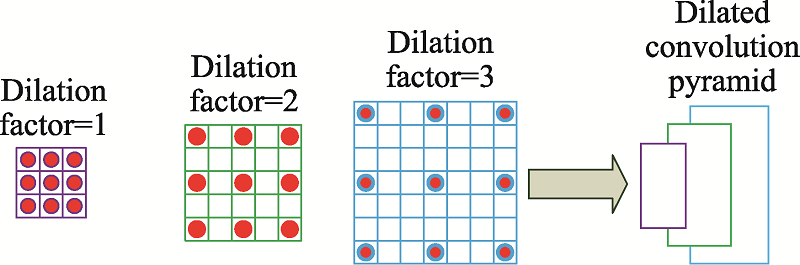
Fig.4 Dilated convolution and convolution pyramid

Fig.5 Detailed process of spatio-temporal feature pyramid
| 融合策略 | UCF101正确率/% |
|---|---|
| 特征级联 | 86.994 |
| 加权融合 | 90.325 |
Table 1 Influence of feature fusion strategy
| 融合策略 | UCF101正确率/% |
|---|---|
| 特征级联 | 86.994 |
| 加权融合 | 90.325 |
| 层数 | UCF101正确率/% |
|---|---|
| 2 | 88.686 |
| 3 | 90.325 |
| 4 | 89.638 |
Table 2 Influence of pyramid layers
| 层数 | UCF101正确率/% |
|---|---|
| 2 | 88.686 |
| 3 | 90.325 |
| 4 | 89.638 |
| 嵌入位置 | UCF101正确率/% |
|---|---|
| Stage{3, 4} | 90.219 |
| Stage4 | 90.325 |
Table 3 Influence of embedding position
| 嵌入位置 | UCF101正确率/% |
|---|---|
| Stage{3, 4} | 90.219 |
| Stage4 | 90.325 |
| 网络 | 模型大小/MB | FLOPs/109 |
|---|---|---|
| Baseline | 25.557 032 | 32.892 117 |
| STFP-Net(2层) | 25.557 059 | 32.902 955 |
| STFP-Net(3层) | 25.557 086 | 32.913 793 |
| STFP-Net(4层) | 25.557 113 | 32.924 631 |
Table 4 Model parameters and calculation amount
| 网络 | 模型大小/MB | FLOPs/109 |
|---|---|---|
| Baseline | 25.557 032 | 32.892 117 |
| STFP-Net(2层) | 25.557 059 | 32.902 955 |
| STFP-Net(3层) | 25.557 086 | 32.913 793 |
| STFP-Net(4层) | 25.557 113 | 32.924 631 |
| 方法 | UCF101 | HMDB51 | 方法 | UCF101 | HMDB51 |
|---|---|---|---|---|---|
| C3D+IDT[ | 90.4 | — | I3D[ | 95.7 | 74.3 |
| R(2+1)D[ | 95.0 | 72.7 | StNet[ | 93.5 | — |
| LTC[ | 91.7 | 64.8 | Hidden-ts[ | 93.2 | 66.8 |
| Ts+LSTM[ | 88.6 | — | STH[ | 96.0 | 74.8 |
| TLE[ | 95.4 | 71.1 | ISTPA-Net[ | 95.5 | 70.7 |
| MiCT[ | 94.7 | 70.5 | Baseline | 94.2 | 69.4 |
| TSM[ | 94.5 | 70.7 | Ours(STFP-Net) | 96.4 | 75.5 |
| P3D[ | 93.7 | — |
Table 5 Comparison of accuracy with mainstream methods 单位:%
| 方法 | UCF101 | HMDB51 | 方法 | UCF101 | HMDB51 |
|---|---|---|---|---|---|
| C3D+IDT[ | 90.4 | — | I3D[ | 95.7 | 74.3 |
| R(2+1)D[ | 95.0 | 72.7 | StNet[ | 93.5 | — |
| LTC[ | 91.7 | 64.8 | Hidden-ts[ | 93.2 | 66.8 |
| Ts+LSTM[ | 88.6 | — | STH[ | 96.0 | 74.8 |
| TLE[ | 95.4 | 71.1 | ISTPA-Net[ | 95.5 | 70.7 |
| MiCT[ | 94.7 | 70.5 | Baseline | 94.2 | 69.4 |
| TSM[ | 94.5 | 70.7 | Ours(STFP-Net) | 96.4 | 75.5 |
| P3D[ | 93.7 | — |
| [1] | 朱红蕾, 朱昶胜, 徐志刚. 人体行为识别数据集研究进展[J]. 自动化学报, 2018, 44(6): 978-1004. |
| ZHU H L, ZHU C S, XU Z G. Research progress of human action recognition datasets[J]. Acta Automatica Sinica, 2018, 44(6): 978-1004. | |
| [2] | IKIZLER-CINBIS N, SCLAROFF S. Object, scene and actions: combining multiple features for human action recognition[C]// LNCS 6311: Proceedings of the 11th Europ-ean Conference on Computer Vision, Heraklion, Sep 5-11, 2010. Berlin, Heidelberg: Springer, 2010: 494-507. |
| [3] | 张良, 鲁梦梦, 姜华. 局部分布信息增强的视觉单词描述与动作识别[J]. 电子与信息学报, 2016, 38(3): 549-556. |
| ZHANG L, LU M M, JIANG H. An improved scheme of visual words description and action recognition using local enhanced distribution information[J]. Journal of Electronics & Information Technology, 2016, 38(3): 549-556. | |
| [4] | KARPATHY A, TODERICI G, SHETTY S, et al. Large-scale video classification with convolutional neural networks[C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, Jun 23-28, 2014. Washington: IEEE Computer Society, 2014: 1725-1732. |
| [5] | SIMONYAN K, ZISSERMAN A. Two-stream convoluti-onal networks for action recognition in videos[C]// Procee-dings of the Annual Conference on Neural Information Processing Systems 2014, Montreal, Dec 8-11, 2014. Red Hook: Curran Associates, 2014: 568-576. |
| [6] | WANG L M, XIONG Y J, WANG Z, et al. Temporal segm-ent networks: towards good practices for deep action recognition[C]// LNCS 9912: Proceedings of the 14th European Conference on Computer Vision, Amsterdam, Oct 8-16, 2016. Cham: Springer, 2016: 20-36. |
| [7] | 周波, 李俊峰. 结合目标检测的人体行为识别[J]. 自动化学报, 2019, 42(5): 56-67. |
| ZHOU B, LI J F. Human action recognition combined with object detection[J]. Acta Automatica Sinica, 2019, 42(5): 56-67. | |
| [8] | 刘天亮, 谯庆伟, 万俊伟, 等. 融合空间-时间双网络流和视觉注意的人体行为识别[J]. 电子与信息学报, 2018, 40(10): 2395-2401. |
| LIU T L, QIAO Q W, WAN J W, et al. Human action recognition based on spatial-temporal double network flow and visual attention[J]. Journal of Electronics and Inform-ation Technology, 2018, 40(10): 2395-2401. | |
| [9] | JI S W, XU W, YANG M, et al. 3D convolutional neural networks for human action recognition[J]. IEEE Transa-ctions on Pattern Analysis and Machine Intelligence, 2013, 35(1): 221-231. |
| [10] | QIU Z F, YAO T, MEI T. Learning spatio-temporal repr-esentation with pseudo-3D residual networks[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Oct 22-29, 2017. Washington: IEEE Comp-uter Society, 2017: 5533-5541. |
| [11] | ZHOU Y, SUN X, ZHA Z J, et al. MICT: mixed 3D/2D convolutional tube for human action recognition[C]// Proce-edings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-22, 2018. Washington: IEEE Computer Society, 2018: 449-458. |
| [12] | YU F, KOLTUN V. Multi-scale context aggregation by dil-ated convolutions[C]// Proceedings of the 4th International Conference on Learning Representations, San Juan, May 2-4, 2016: 1-13. |
| [13] | HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recogn-ition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Com-puter Society, 2016: 770-778. |
| [14] | SOOMRO K, ROSHAN ZAMIR A, SHAH M. UCF101: a dataset of 101 human actions classes from videos in the wild[J]. arXiv:1212.0402, 2012. |
| [15] | KUEHNE H, JHUANG H, GARROTE E, et al. HMDB: a large video database for human motion recognition[C]// Pro-ceedings of the 2011 International Conference on Computer Vision, Barcelona, Nov 6-13, 2011. Washington: IEEE Com-puter Society, 2011: 2556-2563. |
| [16] | TRAN D, WANG H, TORRESANI L, et al. A closer look at spatiotemporal convolutions for action recognition[C]// Pro-ceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-22, 2018. Washington: IEEE Computer Society, 2018: 6450-6459. |
| [17] |
VAROL G, LAPTEV I, SCHMID C. Long-term temporal convolutions for action recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(6): 1510-1517.
DOI URL |
| [18] | NG Y H, HAUSKNECHT M J, VIJAYANARASIMHAN S, et al. Beyond short snippets: deep networks for video class-ification[C]// Proceedings of the 2015 IEEE Confer-ence on Computer Vision and Pattern Recognition, Boston, Jun 7-12, 2015. Washington: IEEE Computer Society, 2015: 4694-4702. |
| [19] | DIBA A, SHARMA V, VAN GOOL L. Deep temporal lin-ear encoding networks[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 1541-1550. |
| [20] | LIN J, GAN C, HAN S. TSM: temporal shift module for efficient video understanding[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Oct 27-Nov 2, 2019. Piscataway: IEEE, 2019: 7082-7092. |
| [21] | CARREIRA J, ZISSERMAN A. Quo vadis, action recogn-ition? A new model and the kinetics dataset[C]// Procee-dings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Was-hington: IEEE Computer Society, 2017: 4724-4733. |
| [22] | HE D L, ZHOU Z C, GAN C, et al. StNet: local and global spatial-temporal modeling for action recognition[C]// Proc-eedings of the 33rd AAAI Conference on Artificial Intelli-gence, the 31st Innovative Applications of Artificial Intellig-ence Conference, the 9th AAAI Symposium on Educational Advances in Artificial Intelligence, Honolulu, Jan 27-Feb 1, 2019. Menlo Park: AAAI, 2019: 8401-8408. |
| [23] | ZHU Y, LAN Z Z, NEWSAM S D, et al. Hidden two-stream convolutional networks for action recognition[C]// LNCS 11363: Proceedings of the 14th Asian Conference on Computer Vision, Perth, Dec 2-6, 2018. Cham: Springer, 2018: 363-378. |
| [24] | LI X, WANG J, MA L, et al. STH: spatio-temporal hybrid convolution for efficient action recognition[J]. arXiv:2003.08042, 2020. |
| [25] | DU Y, YUAN C F, LI B, et al. Interaction-aware spatio-temporal pyramid attention networks for action classifica-tion[C]// LNCS 11220: Proceedings of the 15th European Conference on Computer Vision, Munich, Sep 8-14, 2018. Cham: Springer, 2018: 388-404. |
| [1] | YANG Gang, ZHANG Yushu, SONG Zhen. Human Action Recognition and Evaluation—Differences, Connections and Research Progress [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(5): 991-1007. |
| [2] | SU Jiangyi, SONG Xiaoning, WU Xiaojun, YU Dongjun. Skeleton Based Action Recognition Algorithm on Multi-modal Lightweight Graph Convolutional Network [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(4): 733-742. |
| [3] | QIAN Huifang, YI Jianping, FU Yunhu. Review of Human Action Recognition Based on Deep Learning [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(3): 438-455. |
| [4] | WANG Xinwen, XIE Linbo, PENG Li. Double Residual Network Recognition Method for Falling Abnormal Behavior [J]. Journal of Frontiers of Computer Science and Technology, 2020, 14(9): 1580-1589. |
| [5] | YIN Congcong, ZHANG Qiuju. Review of Research on Robot Programming by Learning from Demonstration [J]. Journal of Frontiers of Computer Science and Technology, 2020, 14(8): 1275-1287. |
| [6] | DONG Xu, TAN Li, ZHOU Lina, SONG Yanyan. Short Video Behavior Recognition Combining Scene and Behavior Features [J]. Journal of Frontiers of Computer Science and Technology, 2020, 14(10): 1754-1761. |
| [7] | HUANG Feifei, CAO Jiangtao, JI Xiaofei, WANG Peiyao. Research on Human Interaction Recognition Algorithm Based on Mixed Features [J]. Journal of Frontiers of Computer Science and Technology, 2017, 11(2): 294-302. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
/D:/magtech/JO/Jwk3_kxyts/WEB-INF/classes/