
Journal of Frontiers of Computer Science and Technology ›› 2022, Vol. 16 ›› Issue (5): 1043-1052.DOI: 10.3778/j.issn.1673-9418.2011062
• Database Technology • Previous Articles Next Articles
WU Sen, DONG Yaxian, WEI Guiying( ), GAO Xiaonan
), GAO Xiaonan
Received:2020-11-23
Revised:2021-03-15
Online:2022-05-01
Published:2022-05-19
About author:WU Sen, born in 1971, Ph.D., professor. Her research interests include data mining, personalized recommendation, etc.Supported by:
武森, 董雅贤, 魏桂英(), 高晓楠
通讯作者:
+ E-mail: weigy@manage.ustb.edu.cn作者简介:武森(1971—),女,辽宁开原人,博士,教授,主要研究方向为数据挖掘、个性化推荐等。基金资助:CLC Number:
WU Sen, DONG Yaxian, WEI Guiying, GAO Xiaonan. Research on User Similarity Calculation of Collaborative Filtering for Sparse Data[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(5): 1043-1052.
武森, 董雅贤, 魏桂英, 高晓楠. 面向稀疏数据的协同过滤用户相似度计算研究[J]. 计算机科学与探索, 2022, 16(5): 1043-1052.
Add to citation manager EndNote|Ris|BibTeX
URL: http://fcst.ceaj.org/EN/10.3778/j.issn.1673-9418.2011062
| 用户 | I1 | I2 | I3 | I4 | I5 | I6 | I7 | I8 | I9 | I10 |
|---|---|---|---|---|---|---|---|---|---|---|
| u1 | 5 | 3 | 5 | 4 | — | — | — | — | — | — |
| u2 | 3 | 5 | — | — | — | 2 | — | — | — | — |
| u3 | 3 | 5 | 5 | 2 | — | 2 | — | — | — | — |
| u4 | 2 | — | — | — | — | 1 | 2 | 1 | 1 | 1 |
| u5 | 4 | 3 | — | 2 | — | — | — | 1 | — | — |
Table 1 Example of user-item rating matrix
| 用户 | I1 | I2 | I3 | I4 | I5 | I6 | I7 | I8 | I9 | I10 |
|---|---|---|---|---|---|---|---|---|---|---|
| u1 | 5 | 3 | 5 | 4 | — | — | — | — | — | — |
| u2 | 3 | 5 | — | — | — | 2 | — | — | — | — |
| u3 | 3 | 5 | 5 | 2 | — | 2 | — | — | — | — |
| u4 | 2 | — | — | — | — | 1 | 2 | 1 | 1 | 1 |
| u5 | 4 | 3 | — | 2 | — | — | — | 1 | — | — |
| 用户对 | 共同评分项数 | 共同评分项 | 共同评分项占总评分项比重 | 共同评分项评分分析 |
|---|---|---|---|---|
| {u2,u3} | 3 | I1、I2、I6 | 3/5 | 评分均相等 |
| {u2,u5} | 2 | I1、I2 | 2/5 | u2更喜欢I2,u5更喜欢I1 |
| {u2,u1} | 2 | I1、I2 | 2/5 | u2更喜欢I2,u1更喜欢I1 |
| {u4,u1} | 1 | I1 | 1/9 | 评分差距较大 |
| {u4,u3} | 2 | I1、I6 | 2/9 | 评分差距较小 |
Table 2 Analysis of partial user ratings
| 用户对 | 共同评分项数 | 共同评分项 | 共同评分项占总评分项比重 | 共同评分项评分分析 |
|---|---|---|---|---|
| {u2,u3} | 3 | I1、I2、I6 | 3/5 | 评分均相等 |
| {u2,u5} | 2 | I1、I2 | 2/5 | u2更喜欢I2,u5更喜欢I1 |
| {u2,u1} | 2 | I1、I2 | 2/5 | u2更喜欢I2,u1更喜欢I1 |
| {u4,u1} | 1 | I1 | 1/9 | 评分差距较大 |
| {u4,u3} | 2 | I1、I6 | 2/9 | 评分差距较小 |
| 相似度 | {u2,u3} | {u2,u5} | {u2,u1} | {u4,u1} | {u4,u3} |
|---|---|---|---|---|---|
| PCC | 0.643 | 0.718 | 0.362 | -0.224 | -0.383 |
| COS | 0.753 | 0.800 | 0.562 | 0.333 | 0.282 |
| ACOS | 0.999 | 0.124 | -0.942 | 1.000 | 0.184 |
Table 3 Similarity measure of partial users
| 相似度 | {u2,u3} | {u2,u5} | {u2,u1} | {u4,u1} | {u4,u3} |
|---|---|---|---|---|---|
| PCC | 0.643 | 0.718 | 0.362 | -0.224 | -0.383 |
| COS | 0.753 | 0.800 | 0.562 | 0.333 | 0.282 |
| ACOS | 0.999 | 0.124 | -0.942 | 1.000 | 0.184 |
| 数据集 | 用户M | 项目N | 评分R | 稀疏度 |
|---|---|---|---|---|
| MovieLens-100K | 943 | 1 682 | 100 000 | 93.7 |
| MovieLens-latest-small | 610 | 9 742 | 100 836 | 98.3 |
| FilmTrust | 1 508 | 2 071 | 35 497 | 98.9 |
Table 4 Description of datasets
| 数据集 | 用户M | 项目N | 评分R | 稀疏度 |
|---|---|---|---|---|
| MovieLens-100K | 943 | 1 682 | 100 000 | 93.7 |
| MovieLens-latest-small | 610 | 9 742 | 100 836 | 98.3 |
| FilmTrust | 1 508 | 2 071 | 35 497 | 98.9 |
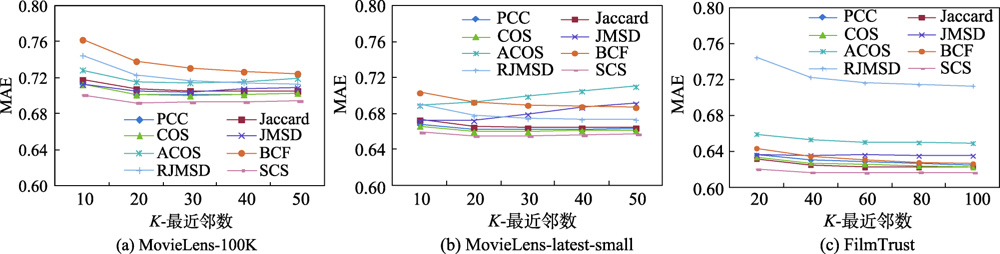
Fig.1 Comparison of MAE with different similarities

Fig.2 Comparison of RMSE with different similarities
| 相似度 | 类型 | 是否适用于稀疏数据 | 作用 |
|---|---|---|---|
| COS | 数值相似度 | 否 | 对比方法[ |
| ACOS | 数值相似度 | 否 | 对比方法[ |
| PCC | 数值相似度 | 否 | 对比方法[ |
| Jaccard | 结构相似度 | 否 | 对比方法[ |
| JMSD | 综合相似度 | 否 | 对比方法[ |
| BCF | 综合相似度 | 是 | 对比方法[ |
| RJMSD | 综合相似度 | 是 | 对比方法[ |
| SCS | 综合相似度 | 是 | 提出方法 |
Table 5 Description of comparison methods
| 相似度 | 类型 | 是否适用于稀疏数据 | 作用 |
|---|---|---|---|
| COS | 数值相似度 | 否 | 对比方法[ |
| ACOS | 数值相似度 | 否 | 对比方法[ |
| PCC | 数值相似度 | 否 | 对比方法[ |
| Jaccard | 结构相似度 | 否 | 对比方法[ |
| JMSD | 综合相似度 | 否 | 对比方法[ |
| BCF | 综合相似度 | 是 | 对比方法[ |
| RJMSD | 综合相似度 | 是 | 对比方法[ |
| SCS | 综合相似度 | 是 | 提出方法 |
| 指标 | 方法 | MovieLens-100K | MovieLens-latest-small | FilmTrust | |||
|---|---|---|---|---|---|---|---|
| 最优值 | 均值 | 最优值 | 均值 | 最优值 | 均值 | ||
| MAE | SCS | 0.689 | 0.695 | 0.652 | 0.657 | 0.603 | 0.617 |
| NMF | 0.749 | 0.758 | 0.697 | 0.707 | 0.653 | 0.656 | |
| RMSE | SCS | 0.970 | 0.981 | 0.883 | 0.889 | 0.841 | 0.860 |
| NMF | 0.954 | 0.965 | 0.908 | 0.903 | 0.843 | 0.857 | |
Table 6 Recommended performance comparison of SCS and NMF
| 指标 | 方法 | MovieLens-100K | MovieLens-latest-small | FilmTrust | |||
|---|---|---|---|---|---|---|---|
| 最优值 | 均值 | 最优值 | 均值 | 最优值 | 均值 | ||
| MAE | SCS | 0.689 | 0.695 | 0.652 | 0.657 | 0.603 | 0.617 |
| NMF | 0.749 | 0.758 | 0.697 | 0.707 | 0.653 | 0.656 | |
| RMSE | SCS | 0.970 | 0.981 | 0.883 | 0.889 | 0.841 | 0.860 |
| NMF | 0.954 | 0.965 | 0.908 | 0.903 | 0.843 | 0.857 | |
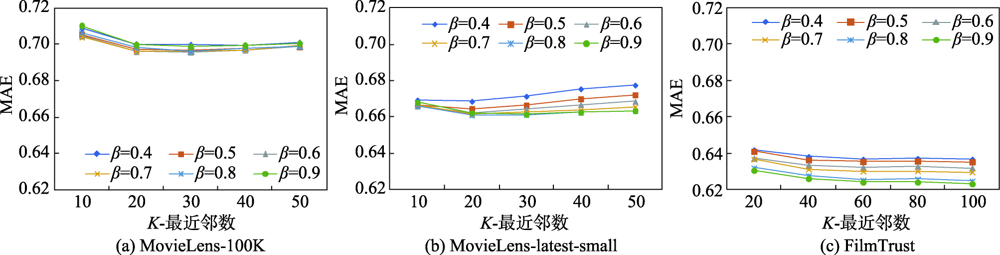
Fig.3 Influence of β on sparse cosine similarity MAE

Fig.4 Influence of β on sparse cosine similarity RMSE

Fig.5 Influence of b on sparse cosine similarity MAE
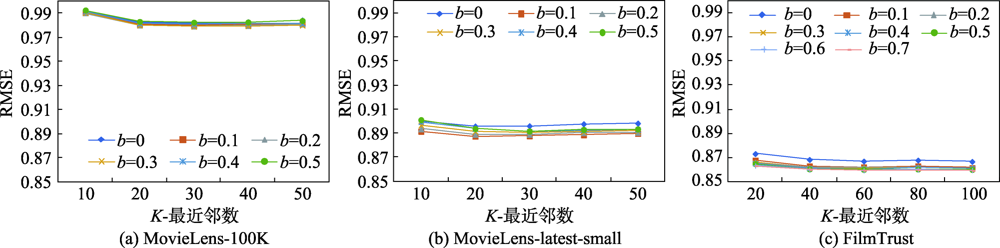
Fig.6 Influence of b on sparse cosine similarity RMSE
| [1] | DESROSIERS C, KARYPIS G. Recommender systems hand- book: a comprehensive survey of neigborhood-based reco-mmendation methods[M]. Berlin, Heidelberg: Springer, 2011. |
| [2] |
GAZDAR A. A new similarity measure for collaborative filtering based recommender systems[J]. Knowledge-Based Systems, 2020, 188: 105058.
DOI URL |
| [3] |
FENG C, LIANG J, SONG P, et al. A fusion collaborative filtering method for sparse data in recommender systems[J]. Information Sciences, 2020, 521: 365-379.
DOI URL |
| [4] | SU X, KHOSHGOFTAAR T M. A survey of collaborative filtering techniques[J]. Advances in Artificial Intelligence, 2009, 12: 421425. |
| [5] | AHN H J. A new similarity measure for collaborative filte-ring to alleviate the new user cold-starting problem[J]. Infor-mation Sciences, 2008, 178(1): 37-51. |
| [6] |
SURYAKANT, MAHARA T. A new similarity measure based on mean measure of divergence for collaborative filtering in sparse environment[J]. Procedia Computer Science, 2016, 89: 450-456.
DOI URL |
| [7] |
WANG D, YIH Y, VENTRESCA M. Improving neighbor-based collaborative filtering by using a hybrid similarity measurement[J]. Expert Systems with Applications, 2020, 160: 113651.
DOI URL |
| [8] |
BOBADILLA J, SERRADILLA F, BERNAL J. A new coll-aborative filtering metric that improves the behavior of re-commender systems[J]. Knowledge-Based Systems, 2010, 23(6): 520-528.
DOI URL |
| [9] | BREESE J S, HECKERMAN D, KADIE C. Empirical anal-ysis of predictive algorithms for collaborative filtering[J]. Uncertainty in Artificial Intelligence, 2013, 98(7): 43-52. |
| [10] | HAN S, CHEE S, HAN J, et al. RecTree: an efficient coll-aborative filtering method[C]// LNCS 2114:Proceedings of the 3rd International Conference on Data Warehousing and Knowledge Discovery, Munich, Sep 5-7, 2001. Berlin, Hei-delberg: Springer, 2001: 141-151. |
| [11] | SARWAR B M, KARYPIS G, KONSTAN J A, et al. App-lication of dimensionality reduction in recommender sys-tem-a case study[C]// Proceedings of the ACM WebKDD Web Mining for E-Commerce Workshop, Boston, Aug 1,2000. New York: ACM, 2000: 82-90. |
| [12] | MNIH A, SALAKHUTDINOV R R. Probabilistic matrix factorization[C]// Advances in Neural Information Processing Systems 20: Proceedings of the 21st Annual Conference on Neural Information Processing Systems, Vancouver, Dec 3-6, 2007. Red Hook: Curran Associates, 2008: 1257-1264. |
| [13] |
BERRY M W, BROWNE M, LANGVILLE A N, et al. Al-gorithms and applications for approximate nonnegative matrix factorization[J]. Computational Statistics & Data Analysis, 2007, 52(1): 155-173.
DOI URL |
| [14] | 李乐, 章毓晋. 非负矩阵分解算法综述[J]. 电子学报, 2008(4): 737-743. |
| LI L, ZHANG Y J. A survey on algorithms of non-negative matrix factorization[J]. Acta Electronica Sinica, 2008(4):737-743. | |
| [15] |
ZHANG F, QI S, LIU Q, et al. Alleviating the data sparsity problem of recommender systems by clustering nodes in bipartite networks[J]. Expert Systems with Applications, 2020, 149: 113346.
DOI URL |
| [16] |
WANG Y, WANG P Y, LIU Z, et al. A new item similarity based on α-divergence for collaborative filtering in sparse data[J]. Expert Systems with Applications, 2020, 166: 114074.
DOI URL |
| [17] |
POLATIDIS N, GEORGIADIS C K. A multi-level collabo-rative filtering method that improves recommendations[J]. Expert Systems with Applications, 2016, 48: 100-110.
DOI URL |
| [18] |
RIYAHI M, SOHRABI M K. Providing effective recommen-dations in discussion groups using a new hybrid recom-mender system based on implicit ratings and semantic simi-larity[J]. Electronic Commerce Research and Applications, 2020, 40: 100938.
DOI URL |
| [19] |
YU S, YANG M, QU Q. Contextual-boosted deep neural co-llaborative filtering model for interpretable recommendation[J]. Expert Systems with Applications, 2019, 136: 365-375.
DOI URL |
| [20] | 荣辉桂, 火生旭, 胡春华, 等. 基于用户相似度的协同过滤推荐算法[J]. 通信学报, 2014, 35(2): 16-24. |
| RONG H G, HUO S X, HU C H, et al. User similarity-based collaborative filtering recommendation algorithm[J]. Journal on Communications, 2014, 35(2): 16-24. | |
| [21] | 陈洁敏, 李建国, 汤非易, 等. 融合“用户-项目-用户兴趣标签图”的协同好友推荐算法[J]. 计算机科学与探索, 2018, 12(1): 92-100. |
| CHEN J M, LI J G, TANG F Y, et al. Combining user-item-tag tripartite graph and users’ personal interests for friends recommendation[J]. Journal of Frontiers of Computer Science and Technology, 2018, 12(1): 92-100. | |
| [22] | AIOLLI F. Efficient top-n recommendation for very large scale binary rated datasets[C]// Proceedings of the 7th ACM Conference on Recommender Systems, Hong Kong, China,Oct 12-16, 2013. New York: ACM, 2013: 273-280. |
| [23] |
JIANG S, FANG S C, AN Q, et al. A sub-one quasi-norm-based similarity measure for collaborative filtering in recom-mender systems[J]. Information Sciences, 2019, 487: 142-155.
DOI URL |
| [24] |
LIU H, HU Z, MIAN A, et al. A new user similarity model to improve the accuracy of collaborative filtering[J]. Knowledge-Based Systems, 2014, 56: 156-166.
DOI URL |
| [25] | WANG Y, DENG J, GAO J, et al. A hybrid user similarity model for collaborative filtering[J]. Information Sciences, 2017, 418: 102-118. |
| [26] |
PATRA B K, LAUNONEN R, OLLIKAINEN V, et al. A new similarity measure using Bhattacharyya coefficient for collaborative filtering in sparse data[J]. Knowledge Based Systems, 2015, 82: 163-177.
DOI URL |
| [27] |
BAG S, KUMAR S, AWASTHI A, et al. A noise correction-based approach to support a recommender system in a highly sparse rating environment[J]. Decision Support Systems, 2019, 118: 46-57.
DOI URL |
| [28] |
MU Y, XIAO N, TANG R, et al. An efficient similarity measure for collaborative filtering[J]. Procedia Computer Science, 2019, 147: 416-421.
DOI URL |
| [29] |
BAG S, KUMAR S K, TIWARI M K. An efficient recom-mendation generation using relevant Jaccard similarity[J]. Information Sciences, 2019, 483: 53-64.
DOI URL |
| [30] | MAXWELL H F, JOSEPH A K. The MovieLens datasets: history and context[J]. ACM Transactions on Interactive Inte-lligent Systems, 2016, 5(4): 19. |
| [31] | GUO G, ZHANG J, YORKE S N. A novel bayesian simi-larity measure for recommender systems[C]// Proceedings of the 23rd International Joint Conference on Artificial Inte-lligence, Beijing, Aug 3-9, 2013. Menlo Park: AAAI, 2013: 2619-2625. |
| [1] | WANG Xuechun, LYU Shengkai, WU Hao, HE Peng, ZENG Cheng. Research on Service Recommendation Method of Multi-network Hybrid Embed-ding Learning [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(7): 1529-1542. |
| [2] | CHEN Jiangmei, ZHANG Wende. Review of Point of Interest Recommendation Systems in Location-Based Social Networks [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(7): 1462-1478. |
| [3] | YANG Gang, ZHANG Yushu, SONG Zhen. Human Action Recognition and Evaluation—Differences, Connections and Research Progress [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(5): 991-1007. |
| [4] | ZHANG Quangui, HU Jiayan, WANG Li. One Class Collaborative Filtering Recommendation Algorithm Coupled with User Common Characteristics [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(3): 637-648. |
| [5] | WU Jiawei, SUN Yanchun. Recommendation System for Medical Consultation Integrating Knowledge Graph and Deep Learning Methods [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(8): 1432-1440. |
| [6] | SUN Dongpu, QU Li. Survey on Feature Representation and Similarity Measurement of Time Series [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(2): 195-205. |
| [7] | XING Changzheng, GUO Yalan, ZHANG Quangui, ZHAO Hongbao. Recommendation Method Integrating Review Text Hierarchical Attention with Time Information [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(11): 2222-2232. |
| [8] | XING Changzheng, ZHAO Hongbao, ZHANG Quangui, GUO Yalan. Review Text Hierarchical Attention and Outer Product for Recommendation Method [J]. Journal of Frontiers of Computer Science and Technology, 2020, 14(6): 947-957. |
| [9] | LI Guangli, HUA Jin, YUAN Tian, ZHU Tao, WU Renzhong, JI Donghong, ZHANG Hongbin. Recommendation System Based on Users' Preference Mining Generative Adversarial Networks [J]. Journal of Frontiers of Computer Science and Technology, 2020, 14(5): 803-814. |
| [10] | WANG Shaoqing, LI Xinxin, SUN Fuzhen, FANG Chun. Survey of Research on Personalized News Recommendation Techniques [J]. Journal of Frontiers of Computer Science and Technology, 2020, 14(1): 18-29. |
| [11] | LI Xingxing, LIU Huafeng, JING Liping. Mixture Rank Matrix Factorization Model [J]. Journal of Frontiers of Computer Science and Technology, 2019, 13(7): 1114-1122. |
| [12] | WANG Yuchen, WANG Baoliang, HOU Yonghong. Bandits Recommendation Algorithm Based on Collaborative Filtering and Context Information [J]. Journal of Frontiers of Computer Science and Technology, 2019, 13(3): 361-373. |
| [13] | ZHU Hongwei, YOU Xiaoming, LIU Sheng. Heterogeneous Dual Population Ant Colony Algorithm Based on Cooperative Filtering Strategy [J]. Journal of Frontiers of Computer Science and Technology, 2019, 13(10): 1754-1767. |
| [14] | ZHANG Yiwen, AI Xiaofei, CUI Guangming, QIAN Fulan. Recommendation Algorithm with User's Interest Matrix and Global Preference [J]. Journal of Frontiers of Computer Science and Technology, 2018, 12(2): 197-207. |
| [15] | GUO Ningning, WANG Baoliang, HOU Yonghong, CHANG Peng. Collaborative Filtering Recommendation Algorithm Based on Characteristics of Social Network [J]. Journal of Frontiers of Computer Science and Technology, 2018, 12(2): 208-217. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
/D:/magtech/JO/Jwk3_kxyts/WEB-INF/classes/