
计算机科学与探索 ›› 2022, Vol. 16 ›› Issue (2): 296-304.DOI: 10.3778/j.issn.1673-9418.2107031
赵山, 罗睿, 蔡志平+( )
)
收稿日期:2021-07-08
修回日期:2021-09-22
出版日期:2022-02-01
发布日期:2021-09-28
通讯作者:
+ E-mail: zpcai@nudt.edu.cn作者简介:赵山(1990—),男,安徽六安人,博士研究生,主要研究方向为自然语言处理。基金资助:
ZHAO Shan, LUO Rui, CAI Zhiping+()
Received:2021-07-08
Revised:2021-09-22
Online:2022-02-01
Published:2021-09-28
About author:ZHAO Shan, born in 1990, Ph.D. candidate. His research interest is natural language processing.Supported by:摘要:
中文命名实体识别(NER)任务是信息抽取领域内的一个子任务,其任务目标是给定一段非结构文本后,从句子中寻找、识别和分类相关实体,例如人名、地名和机构名称。中文命名实体识别是一个自然语言处理(NLP)领域的基本任务,在许多下游NLP任务中,包括信息检索、关系抽取和问答系统中扮演着重要角色。全面回顾了现有的基于神经网络的单词-字符晶格结构的中文NER模型。首先介绍了中文NER相比英语NER难度更大,存在着中文文本相关实体边界难以确定和中文语法结构复杂等难点及挑战。然后调研了在不同神经网络架构下(RNN、CNN、GNN和Transformer)最具代表性的晶格结构的中文NER模型。由于单词序列信息可以给基于字符的序列学习更多边界信息,为了显式地利用每个字符所相关的词汇信息,过去的这些工作提出通过词-字符晶格结构将单词信息整合到字符序列中。这些在中文NER任务上基于神经网络的单词-字符晶格结构的性能要明显优于基于单词或基于字符的方法。最后介绍了中文NER的数据集及评价标准。
中图分类号:
赵山, 罗睿, 蔡志平. 中文命名实体识别综述[J]. 计算机科学与探索, 2022, 16(2): 296-304.
ZHAO Shan, LUO Rui, CAI Zhiping. Survey of Chinese Named Entity Recognition[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(2): 296-304.

图1 原始 Lattice LSTM
Fig.1 Original Lattice LSTM

图2 最长策略
Fig.2 Longest strategy
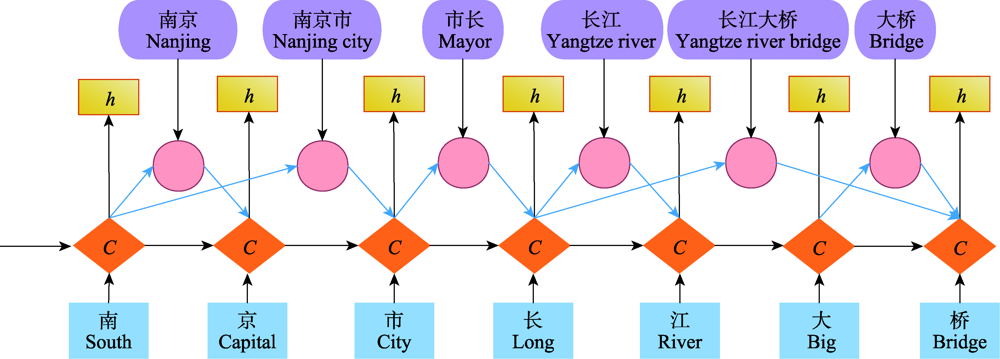
图3 晶格LSTM结构
Fig.3 Lattice-LSTM structure

图4 WC-LSTM结构
Fig.4 WC-LSTM structure

图5 R-CNN模型示意图
Fig.5 R-CNN schematic model

图6 LGN的聚合
Fig.6 LGN aggregation

图7 跨自晶格模型注意网络方法
Fig.7 Cross- and self-lattice attention network

图8 多元数据嵌入的Cross-Transformer模型
Fig.8 Multi-meta data embedding based Cross-Transformer
| 数据集名称 | 年份 | 来源 | 实体类型数量 | 网址 |
|---|---|---|---|---|
| OntoNotes | 2007—2012 | Magazine,news,Web等 | 18 | https://catalog.ldc.upenn.edu/LDC2013T19 |
| Resume | 2018 | SinaFinance text | 8 | https://github.com/jiesutd/LatticeLSTM |
| 2015 | social media | 4 | https://github.com/quincyliang/nlp-public-dataset/tree/master/ner-data/weibo | |
| MSRA | 2006 | news | 3 | https://docs.qq.com/sheet/DVnpkTnF6VW9UeXdh?c=A1A0A0&tab=BB08J2 |
| E-commerce | 2019 | e-commerce | 2 | https://github.com/PhantomGrapes/MultiDigraphNER |
表1 常见NER数据集
Table 1 Common NER datasets
| 数据集名称 | 年份 | 来源 | 实体类型数量 | 网址 |
|---|---|---|---|---|
| OntoNotes | 2007—2012 | Magazine,news,Web等 | 18 | https://catalog.ldc.upenn.edu/LDC2013T19 |
| Resume | 2018 | SinaFinance text | 8 | https://github.com/jiesutd/LatticeLSTM |
| 2015 | social media | 4 | https://github.com/quincyliang/nlp-public-dataset/tree/master/ner-data/weibo | |
| MSRA | 2006 | news | 3 | https://docs.qq.com/sheet/DVnpkTnF6VW9UeXdh?c=A1A0A0&tab=BB08J2 |
| E-commerce | 2019 | e-commerce | 2 | https://github.com/PhantomGrapes/MultiDigraphNER |
| [1] | 郭喜跃, 何婷婷. 信息抽取研究综述[J]. 计算机科学, 2015, 42(2):14-17. |
| GUO X Y, HE T T. Survey about research on information extraction[J]. Computer Science, 2015, 42(2):14-17. | |
| [2] | 邹晶. 基于深度学习的实体与关系联合提取方法研究[D]. 成都: 电子科技大学, 2019. |
| ZOU J. Research on joint extraction method of entity and relation based on deep learning[D]. Chengdu: University of Electronic Science and Technology of China, 2019. | |
| [3] | ZHAO S, CAI Z P, CHEN H W, et al. Adversarial training based lattice LSTM for Chinese clinical named entity recognition[J]. Journal of Biomedical Informatics, 2019, 99:103290. |
| [4] | 石春丹, 秦岭. 基于BGRU-CRF的中文命名实体识别方法[J]. 计算机科学, 2019, 46(9):237-242. |
| SHI C D, QIN L. Chinese named entity recognition method based on BGRU-CRF[J]. Computer Science, 2019, 46(9):237-242. | |
| [5] | 卓玛措, 桑杰端珠, 才让加. 基于深度学习的古汉语命名实体识别研究[J]. 计算机科学与应用, 2020, 10(7):1359-1366. |
| ZHUO M C, SANGJIE D Z, CAI R J. Ancient Chinese named entity recognition based on deeping learning[J]. Computer Science and Application, 2020, 10(7):1359-1366. | |
| [6] | 孙长志. 基于深度学习的联合实体关系抽取[D]. 上海: 华东师范大学, 2019. |
| SUN C Z. Joint entity relation extraction with deep learning[D]. Shanghai: East China Normal University, 2019. | |
| [7] | CHEN Y B, XU L H, LIU K, et al. Event extraction via dynamic multi-pooling convolutional neural networks[C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing of the Asian Federation of Natural Language Processing, Jul 26-31, 2015. Stroudsburg: ACL, 2015: 167-176. |
| [8] | BUNESCU R C, MOONEY R J. A shortest path dependency kernel for relation extraction[C]//Proceedings of the Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, Vancouver, Oct 6-8, 2005. Stroudsburg: ACL, 2005: 724-731. |
| [9] |
DIEFENBACH D, LÓPEZ V, SINGH K D, et al. Core techniques of question answering systems over knowledge bases: a survey[J]. Knowledge and Information Systems, 2018, 55(3):529-569.
DOI URL |
| [10] | YANG J, TENG Z Y, ZHANG M S, et al. Combining discrete and neural features for sequence labeling[C]//LNCS 9623: Proceedings of the 17th International Conference on Computational Linguistics and Intelligent Text Processing, Konya, Apr 3-9, 2016. Cham: Springer, 2016: 140-154. |
| [11] | PENG N Y, DREDZE M. Named entity recognition for Chinese social media with jointly trained embeddings[C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Sep 17-21, 2015. Stroudsburg: ACL, 2015: 548-554. |
| [12] | HE H F, SUN X. F-score driven max margin neural network for named entity recognition in Chinese social media[J]. arXiv:1611.04234, 2016. |
| [13] | LIU W, XU T G, XU Q H, et al. An encoding strategy based word-character LSTM for Chinese NER[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, Jun 2-7, 2019. Stroudsburg: ACL, 2019: 2379-2389. |
| [14] | ZHANG Y, YANG J. Chinese NER using lattice LSTM[C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Jul 15-20, 2018. Stroudsburg: ACL, 2018: 1554-1564. |
| [15] | HUMPHREYS K, GAIZAUSKAS R, AZZAM S, et al. University of Sheffield: description of the LaSIE-II system as used for MUC-7[C]//Proceedings of the 7th Message Understanding Conference, Fairfax, Apr 29-May 1, 1998. Stroudsburg: ACL, 1998: 1-20. |
| [16] | KRUPKA G R, HAUSMAN K. IsoQuest Inc.: description of the NetOwl™ extractor system as used for MUC-7[C]// Proceedings of the 7th Message Understanding Conference, Fairfax, Apr 29-May 1, 1998. Stroudsburg: ACL, 1998: 1-10. |
| [17] | BLACK W J, RINALDI F, MOWATT D. FACILE: description of the NE system used for MUC-7[C]//Proceedings of the 7th Message Understanding Conference, Fairfax, Apr 29- May 1, 1998. Stroudsburg: ACL, 1998: 1-10. |
| [18] | AONE C, HALVERSON L, HAMPTON T, et al. SRA: description of the IE2 system used for MUC-7[C]//Proceedings of the 7th Message Understanding Conference, Fairfax, Apr 29-May 1, 1998. Stroudsburg: ACL, 1998: 1-14. |
| [19] |
NADEAU D, SEKINE S. A survey of named entity recog-nition and classification[J]. Lingvisticae Investigationes, 2007, 30(1):3-26.
DOI URL |
| [20] | COLLINS M, SINGER Y. Unsupervised models for named entity classification[C]//Proceedings of the 1999 Joint SIGDAT Conference on Empirical Methods in Natural Language Processing and Very Large Corpora, College Park, Jun 21-22, 1999. Stroudsburg: ACL, 1999: 1-11. |
| [21] | NADEAU D, TURNEY P D, MATWIN S. Unsupervised named-entity recognition: generating gazetteers and resolving ambiguity[C]//LNCS 4013: Proceedings of the 19th Con-ference of the Canadian Society for Computational Studies of Intelligence, Québec City, Jun 7-9, 2006. Berlin, Heid-elberg: Springer, 2006: 266-277. |
| [22] |
EDDY S R. Hidden Markov models[J]. Current Opinion in Structural Biology, 1996, 6(3):361-365.
DOI URL |
| [23] | QUINLAN J R. Induction of decision trees[J]. Machine Learning, 1986, 1(1):81-106. |
| [24] | KAPUR J N. Maximum-entropy models in science and engineering[M]. New York: John Wiley & Sons, Inc., 1989. |
| [25] | SUTHAHARAN S. Support vector machine[M]. Cham: Springer, 2016. |
| [26] | LAFFERTY J D, MCCALLUM A, PEREIRA F C. Conditional random fields: probabilistic models for segmenting and labe-ling sequence data[C]//Proceedings of the 18th International Conference on Machine Learning, Williamstown, Jun 28-Jul 1, 2001. San Mateo: Morgan Kaufmann, 2001: 282-289. |
| [27] | COLLOBERT R, WESTON J, BOTTOU L, et al. Natural language processing (almost) from scratch[J]. Journal of Machine Learning Research, 2011, 12:2493-2537. |
| [28] | YADAV V, BETHARD S. A survey on recent advances in named entity recognition from deep learning models[J]. arXiv:1910.11470, 2019. |
| [29] | MA X Z, HOVY E H. End-to-end sequence labeling via bi-directional LSTM-CNNs-CRF[J]. arXiv:1603.01354, 2016. |
| [30] | PETERS M E, NEUMANN M, IYYER M, et al. Deep contextualized word representations[J]. arXiv:1802.05365, 2018. |
| [31] | GUI T, MA R T, ZHANG Q, et al. CNN-based Chinese NER with lexicon rethinking[C]// Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, Aug 10-16, 2019: 4982-4988. |
| [32] | GUI T, ZOU Y C, ZHANG Q, et al. A lexicon-based graph neural network for Chinese NER[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, Nov 3-7, 2019. Stroudsburg: ACL, 2019: 1040-1050. |
| [33] | SUI D B, CHEN Y B, LIU K, et al. Leverage lexical know-ledge for Chinese named entity recognition via collaborative graph network[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, Nov 3-7, 2019. Stroudsburg: ACL, 2019: 3828-3838. |
| [34] | DING R X, XIE P J, ZHANG X Y, et al. A neural multi-digraph model for Chinese NER with gazetteers[C]//Proceedings of the 57th Conference of the Association for Computational Linguistics, Florence, Jul 28-Aug 2, 2019. Stroudsburg: ACL, 2019: 1462-1467. |
| [35] | YAN H, DENG B C, LI X N, et al. TENER: adapting transformer encoder for name entity recognition[J]. arXiv: 1911.04474, 2019. |
| [36] | MA R T, PENG M L, ZHANG Q, et al. Simplify the usage of lexicon in Chinese NER[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Jul 5-10, 2020. Stroudsburg: ACL, 2020: 5951-5960. |
| [37] | LI X N, YAN H, QIU X P, et al. FLAT: Chinese NER using flat-lattice transformer[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Jul 5-10, 2020. Stroudsburg: ACL, 2020: 6836-6842. |
| [38] | ZHAO S, HU M H, CAI Z P, et al. Dynamic modeling cross-and self-lattice attention network for Chinese NER[C]//Proceedings of the 35th AAAI Conference on Artificial Intelligence, 33rd Conference on Innovative Applications of Artificial Intelligence, the 11th Symposium on Educational Advances in Artificial Intelligence, Feb 2-9, 2021. Menlo Park: AAAI, 2021: 14515-14523. |
| [39] | WU S, SONG X N, FENG Z H. MECT: multi-metadata embedding based cross-transformer for Chinese named entity recognition[C]//Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Aug 1-6, 2021. Stroudsburg: ACL, 2021: 1529-1539. |
| [1] | 安凤平, 李晓薇, 曹翔. 权重初始化-滑动窗口CNN的医学图像分类[J]. 计算机科学与探索, 2022, 16(8): 1885-1897. |
| [2] | 黄浩, 葛洪伟. 强化类间区分的深度残差表情识别网络[J]. 计算机科学与探索, 2022, 16(8): 1842-1849. |
| [3] | 于慧琳, 陈炜, 王琪, 高建伟, 万怀宇. 使用子图推理实现知识图谱关系预测[J]. 计算机科学与探索, 2022, 16(8): 1800-1808. |
| [4] | 李玉轩, 洪学海, 汪洋, 唐正正, 班艳. 引入激活加权策略的分组排序学习方法[J]. 计算机科学与探索, 2022, 16(7): 1594-1602. |
| [5] | 张雁操, 赵宇海, 史岚. 融合图注意力的多特征链接预测算法[J]. 计算机科学与探索, 2022, 16(5): 1096-1106. |
| [6] | 欧阳柳, 贺禧, 瞿绍军. 全卷积注意力机制神经网络的图像语义分割[J]. 计算机科学与探索, 2022, 16(5): 1136-1145. |
| [7] | 程卫月, 张雪琴, 林克正, 李骜. 融合全局与局部特征的深度卷积神经网络算法[J]. 计算机科学与探索, 2022, 16(5): 1146-1154. |
| [8] | 童敢, 黄立波. Winograd快速卷积相关研究综述[J]. 计算机科学与探索, 2022, 16(5): 959-971. |
| [9] | 裴利沈, 赵雪专. 群体行为识别深度学习方法研究综述[J]. 计算机科学与探索, 2022, 16(4): 775-790. |
| [10] | 张少伟, 王鑫, 陈子睿, 王林, 徐大为, 贾勇哲. 有监督实体关系联合抽取方法研究综述[J]. 计算机科学与探索, 2022, 16(4): 713-733. |
| [11] | 卓天天, 桑庆兵. 注意力机制与复合卷积在手写识别中的应用[J]. 计算机科学与探索, 2022, 16(4): 888-897. |
| [12] | 陆仲达, 张春达, 张佳奇, 王子菲, 许军华. 双分支网络的苹果叶部病害识别[J]. 计算机科学与探索, 2022, 16(4): 917-926. |
| [13] | 马金林, 张裕, 马自萍, 毛凯绩. 轻量化神经网络卷积设计研究进展[J]. 计算机科学与探索, 2022, 16(3): 512-528. |
| [14] | 裴利沈, 刘少博, 赵雪专. 人体行为识别研究综述[J]. 计算机科学与探索, 2022, 16(2): 305-322. |
| [15] | 肖泽管, 陈清亮. 融合多种类型语法信息的属性级情感分析模型[J]. 计算机科学与探索, 2022, 16(2): 395-402. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||