
计算机科学与探索 ›› 2022, Vol. 16 ›› Issue (1): 41-58.DOI: 10.3778/j.issn.1673-9418.2110003
李科岑1, 王晓强1,+( ), 林浩2, 李雷孝3, 杨艳艳3, 孟闯3, 高静4
), 林浩2, 李雷孝3, 杨艳艳3, 孟闯3, 高静4
收稿日期:2021-09-17
修回日期:2021-11-08
出版日期:2022-01-01
发布日期:2021-11-20
通讯作者:
+ E-mail: wangxiaoqiang@imut.edu.cn作者简介:李科岑(1997—),女,山西人,硕士研究生,主要研究方向为深度学习、目标检测。基金资助:
LI Kecen1, WANG Xiaoqiang1,+(), LIN Hao2, LI Leixiao3, YANG Yanyan3, MENG Chuang3, GAO Jing4
Received:2021-09-17
Revised:2021-11-08
Online:2022-01-01
Published:2021-11-20
About author:LI Kecen, born in 1997, M.S. candidate. Her research interests include deep learning and object detection.Supported by:摘要:
随着深度学习的不断发展,目标检测技术逐步从基于传统的手工检测方法向基于深度神经网络的检测方法转变。在众多基于深度学习的目标检测方法中,基于深度学习的单阶段目标检测方法因其网络结构较简单、运行速度较快以及具有更高的检测效率而被广泛运用。但现有的基于深度学习的单阶段目标检测方法由于小目标物体包含的特征信息较少、分辨率较低、背景信息较复杂、细节信息不明显以及定位精度要求较高等原因,导致在检测过程中对小目标物体的检测效果不理想,使得模型检测精度降低。针对目前基于深度学习的单阶段目标检测方法存在的问题,研究了大量基于深度学习的单阶段小目标检测技术。首先从单阶段目标检测方法的Anchor Box、网络结构、交并比函数以及损失函数等几个方面,系统地总结了针对小目标检测的优化方法;其次列举了常用的小目标检测数据集及其应用领域,并给出在各小目标检测数据集上的检测结果图;最后探讨了基于深度学习的单阶段小目标检测方法的未来研究方向。
中图分类号:
李科岑, 王晓强, 林浩, 李雷孝, 杨艳艳, 孟闯, 高静. 深度学习中的单阶段小目标检测方法综述[J]. 计算机科学与探索, 2022, 16(1): 41-58.
LI Kecen, WANG Xiaoqiang, LIN Hao, LI Leixiao, YANG Yanyan, MENG Chuang, GAO Jing. Survey of One-Stage Small Object Detection Methods in Deep Learning[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(1): 41-58.

图1 原始锚点框与自适应锚点框对比
Fig.1 Comparison of original anchor boxes and adaptive anchor boxes
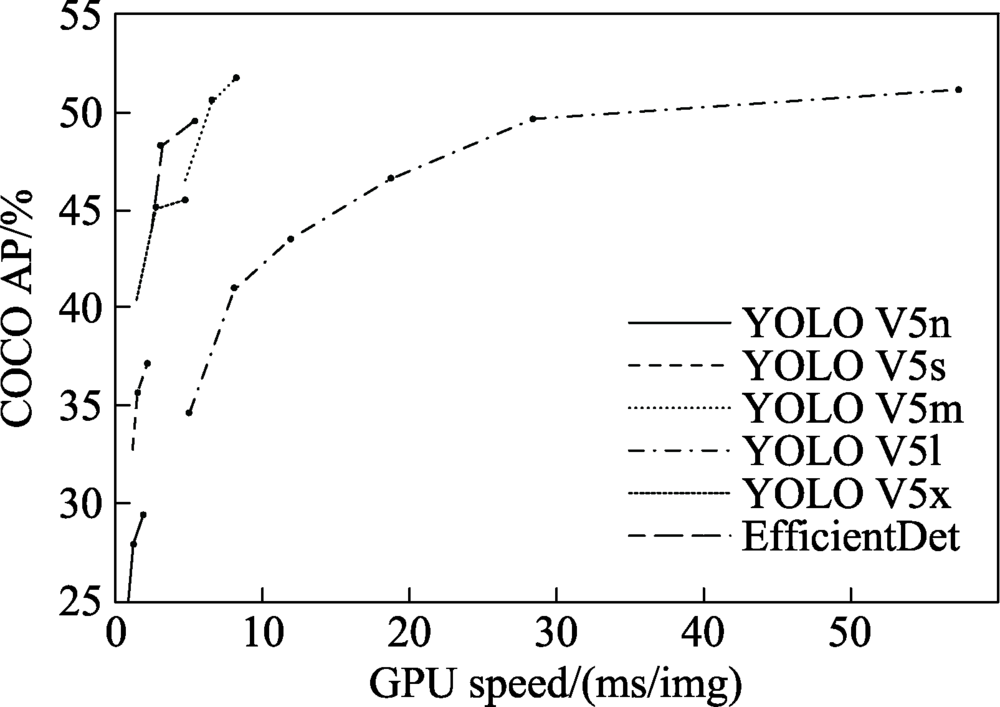
图2 YOLO V5算法性能测试对比图
Fig.2 Comparison chart of YOLO V5 algorithms performance
| 文献 | 年份 | 骨干网络 | 方法 | 优点 | 局限性 |
|---|---|---|---|---|---|
| Adamdad[ | 2019 | MobileNet | 该模型将YOLO V3中的骨干网络修改为MobileNet网络,去掉了原网络中的全连接层和SoftMax层 | 避免了普通卷积层中任意卷积核都需要对所有通道进行操作的缺陷 | 下采样操作导致浅层特征信息被忽略;待检目标被遮挡时,模型检测精度较低 |
| Li等人[ | 2021 | Shuffle_SENet | 在ShuffleNet模块之后引入SENet,使用全局平均池化将信道空间特征转化为全局特征,然后使用FC层降低模型复杂度 | 使用较少的组卷积来最小化内存访问成本,在保证速度的同时提升了模型的准确性 | 易产生边界效应,某个输出通道可能仅来自输入通道的一部分 |
| YOLO V4[ | 2020 | CSPDarkNet-53 | 包含29个3×3的卷积层,725×725大小的感受野以及2.76×107个参数 | 具有更大的感受野以及大量参数模型,能够在一张图像上检测不同尺寸的多个物体 | 采用CIoU损失,不能同时增大或缩小长和宽,导致收敛速度减慢 |
| 谢俊章等人[ | 2021 | CSPDarkNet-53 | 修改残差卷积次数为(×1,×3,×4,×6,×3),结合PANet,使用残差连接代替连续卷积操作,生成3个不同尺度的特征图 | 并行提取目标的类别和位置信息,适用于密集分布和混合分布目标 | 模型无法达到较高的检测精度 |
| YOLO V5[ | 2020 | Focus+CSP1_X | Focus模块进行切片操作,CSP1_X借鉴CSPNet,由3个卷积层和X个Res unint模块拼接组成 | 使用更轻量级的网络,模型简单,速度更快 | 通过长宽比筛选并过滤了大小和长宽比较极端的真实目标框 |
| Pan等人[ | 2019 | DenseNet | 在每个dense block中设置相同的特征图输出,每个dense block之间增加1×1卷积 | 减少了冗余参数,避免了梯度消失问题 | 与YOLOv3_Tiny相比,检测速度较慢,占用内存较大 |
| 李航等人[ | 2020 | slim-densenet | 采用跳跃式连接的方式,使得特征可以跳过部分网络直接传递至较深的网络层,并将7×7、5×5和3×3卷积换为深度可分离卷积 | 减少参数量,加速特征在网络中的传递,减轻了梯度消失问题 | 模型通道冗余,可通过剪枝操作压缩模型,进一步提升训练速度 |
| 齐榕等人[ | 2020 | MobileNet | 在Tiny-YOLO V3的基础上修改骨干网络为MobileNet,将原来的双尺度预测变为三尺度预测 | 适应不同类型的物体,增加网络层数,提高了检测精度 | 未考虑复杂环境下的目标,对于极端拍摄环境易造成漏检 |
| 郑秋梅等人[ | 2020 | DarkNet-50 | 过渡层使用1×1和3×3交替卷积,利用ResNet进行特征提取,并去除YOLO检测前的两组卷积层 | 避免了下采样操作导致的信息丢失问题,注重浅层特征信息,去除了冗余卷积层 | 依赖于车辆运动信息,模型泛化能力弱 |
表1 优化YOLO系列模型中的骨干网络
Table 1 Optimizing backbone network in YOLO series models
| 文献 | 年份 | 骨干网络 | 方法 | 优点 | 局限性 |
|---|---|---|---|---|---|
| Adamdad[ | 2019 | MobileNet | 该模型将YOLO V3中的骨干网络修改为MobileNet网络,去掉了原网络中的全连接层和SoftMax层 | 避免了普通卷积层中任意卷积核都需要对所有通道进行操作的缺陷 | 下采样操作导致浅层特征信息被忽略;待检目标被遮挡时,模型检测精度较低 |
| Li等人[ | 2021 | Shuffle_SENet | 在ShuffleNet模块之后引入SENet,使用全局平均池化将信道空间特征转化为全局特征,然后使用FC层降低模型复杂度 | 使用较少的组卷积来最小化内存访问成本,在保证速度的同时提升了模型的准确性 | 易产生边界效应,某个输出通道可能仅来自输入通道的一部分 |
| YOLO V4[ | 2020 | CSPDarkNet-53 | 包含29个3×3的卷积层,725×725大小的感受野以及2.76×107个参数 | 具有更大的感受野以及大量参数模型,能够在一张图像上检测不同尺寸的多个物体 | 采用CIoU损失,不能同时增大或缩小长和宽,导致收敛速度减慢 |
| 谢俊章等人[ | 2021 | CSPDarkNet-53 | 修改残差卷积次数为(×1,×3,×4,×6,×3),结合PANet,使用残差连接代替连续卷积操作,生成3个不同尺度的特征图 | 并行提取目标的类别和位置信息,适用于密集分布和混合分布目标 | 模型无法达到较高的检测精度 |
| YOLO V5[ | 2020 | Focus+CSP1_X | Focus模块进行切片操作,CSP1_X借鉴CSPNet,由3个卷积层和X个Res unint模块拼接组成 | 使用更轻量级的网络,模型简单,速度更快 | 通过长宽比筛选并过滤了大小和长宽比较极端的真实目标框 |
| Pan等人[ | 2019 | DenseNet | 在每个dense block中设置相同的特征图输出,每个dense block之间增加1×1卷积 | 减少了冗余参数,避免了梯度消失问题 | 与YOLOv3_Tiny相比,检测速度较慢,占用内存较大 |
| 李航等人[ | 2020 | slim-densenet | 采用跳跃式连接的方式,使得特征可以跳过部分网络直接传递至较深的网络层,并将7×7、5×5和3×3卷积换为深度可分离卷积 | 减少参数量,加速特征在网络中的传递,减轻了梯度消失问题 | 模型通道冗余,可通过剪枝操作压缩模型,进一步提升训练速度 |
| 齐榕等人[ | 2020 | MobileNet | 在Tiny-YOLO V3的基础上修改骨干网络为MobileNet,将原来的双尺度预测变为三尺度预测 | 适应不同类型的物体,增加网络层数,提高了检测精度 | 未考虑复杂环境下的目标,对于极端拍摄环境易造成漏检 |
| 郑秋梅等人[ | 2020 | DarkNet-50 | 过渡层使用1×1和3×3交替卷积,利用ResNet进行特征提取,并去除YOLO检测前的两组卷积层 | 避免了下采样操作导致的信息丢失问题,注重浅层特征信息,去除了冗余卷积层 | 依赖于车辆运动信息,模型泛化能力弱 |
| 文献 | 年份 | 骨干网络 | 方法 | 优点 | 局限性 |
|---|---|---|---|---|---|
| Fu等人[ | 2017 | ResNet101 | 在ResNet101后增加残差块,并使用卷积层3、5、6、7、8、9的输出作为预测层的输入;增加反卷积模块和预测模块 | 相比SSD,对小目标的检测效果得到显著提升 | 模型检测速度远不及SSD检测模型 |
| Shen等人[ | 2017 | DenseNet | 对DenseNet变形,包含Stem块、4个密集连接块、2个transition layer以及2个transition w/o pooling layer | 缓解梯度消失,保证特征图分辨率,增加模型鲁棒性 | 预训练模型大,参数多,优化空间存在差异,应用领域受限 |
| 张侣等人[ | 2021 | Res-Am | 一条独立的支路进行LCBAM操作,另一支路进行两次残差连接,最后使用Add进行特征融合 | 增强了网络的特征提取能力,引入注意力机制进行特征自适应学习,减少数据冗余 | 模型结构较复杂,较难满足网络实时性要求 |
| 赵鹏飞等人[ | 2021 | I-Darknet53 | 将1×1后的卷积层分为s个宽、高相同的通道组,输出包含不同感受野大小的组合 | 扩展网络宽度,提取更多全局信息,提升骨干网络的特征提取能力 | 在一定程度上加重了模型训练参数,速度减慢 |
| 奚琦等人[ | 2021 | DenseNet | 采用3个连续的3×3卷积核代替7×7卷积核,得到19×19像素的特征图 | 减少参数,降低输入图像特征信息的消耗,最大程度地保留了目标细节信息 | 需进行多次concat操作,数据需多次复制,增加显存消耗 |
| 徐先峰等人[ | 2020 | MobileNet | 构建深度可分离卷积,将Conv11和Conv13卷积层送入预测器预测 | 减少参数,降低模型复杂度,降低内存占用空间 | 检测精度不及SSD,当目标遮挡面积较大时容易产生漏检 |
| Lu等人[ | 2019 | ResNet | 将SSD中的VGG16至Conv8_2网络框架换为ResNet网络,对38×38、19×19、10×10、5×5、3×3、1×1像素的特征图进行检测 | 在复杂环境下学习更多特征,解决了网络退化的问题 | 网络层数增加,训练参数增多 |
表2 优化SSD骨干网络
Table 2 Optimizing SSD backbone network
| 文献 | 年份 | 骨干网络 | 方法 | 优点 | 局限性 |
|---|---|---|---|---|---|
| Fu等人[ | 2017 | ResNet101 | 在ResNet101后增加残差块,并使用卷积层3、5、6、7、8、9的输出作为预测层的输入;增加反卷积模块和预测模块 | 相比SSD,对小目标的检测效果得到显著提升 | 模型检测速度远不及SSD检测模型 |
| Shen等人[ | 2017 | DenseNet | 对DenseNet变形,包含Stem块、4个密集连接块、2个transition layer以及2个transition w/o pooling layer | 缓解梯度消失,保证特征图分辨率,增加模型鲁棒性 | 预训练模型大,参数多,优化空间存在差异,应用领域受限 |
| 张侣等人[ | 2021 | Res-Am | 一条独立的支路进行LCBAM操作,另一支路进行两次残差连接,最后使用Add进行特征融合 | 增强了网络的特征提取能力,引入注意力机制进行特征自适应学习,减少数据冗余 | 模型结构较复杂,较难满足网络实时性要求 |
| 赵鹏飞等人[ | 2021 | I-Darknet53 | 将1×1后的卷积层分为s个宽、高相同的通道组,输出包含不同感受野大小的组合 | 扩展网络宽度,提取更多全局信息,提升骨干网络的特征提取能力 | 在一定程度上加重了模型训练参数,速度减慢 |
| 奚琦等人[ | 2021 | DenseNet | 采用3个连续的3×3卷积核代替7×7卷积核,得到19×19像素的特征图 | 减少参数,降低输入图像特征信息的消耗,最大程度地保留了目标细节信息 | 需进行多次concat操作,数据需多次复制,增加显存消耗 |
| 徐先峰等人[ | 2020 | MobileNet | 构建深度可分离卷积,将Conv11和Conv13卷积层送入预测器预测 | 减少参数,降低模型复杂度,降低内存占用空间 | 检测精度不及SSD,当目标遮挡面积较大时容易产生漏检 |
| Lu等人[ | 2019 | ResNet | 将SSD中的VGG16至Conv8_2网络框架换为ResNet网络,对38×38、19×19、10×10、5×5、3×3、1×1像素的特征图进行检测 | 在复杂环境下学习更多特征,解决了网络退化的问题 | 网络层数增加,训练参数增多 |
| 文献 | 骨干网络 | 速度/(frame/s) | mAP/% | ||
|---|---|---|---|---|---|
| VOC2007 | VOC2012 | MS COCO | |||
| DSSD321[ | ResNet-101 | 9.5 | 78.60 | 76.3 | 33.20 |
| DSSD513[ | ResNet-101 | 5.5 | 81.50 | 80.8 | 33.20 |
| Shen等人[ | DenseNet | 17.4 | 77.70 | 76.3 | 29.30 |
| Adamdad[ | MobileNet | 29.0 | 64.22 | — | — |
| 齐榕等人[ | MobileNet | — | 73.30 | — | 40.20 |
| Li等人[ | Shuffle_SENet | 29.0 | 64.70 | — | — |
| YOLOv3_Tiny | Darknet-Tiny | 25.0 | 58.20 | — | 33.30 |
| YOLO V5l[ | CSPNet | 99.0 | — | — | 48.80 |
| Pan等人[ | DenseNet | 12.0 | 65.93 | — | — |
| 张侣等人[ | Res-Am | 51.0 | 71.40 | — | — |
| 赵鹏飞等人[ | I-Darknet53 | 32.0 | 82.30 | — | — |
| 奚琦等人[ | DenseNet | 58.0 | 82.30 | — | — |
| Cheng等人[ | MobileNetV2-FPN | 97.0 | 73.80 | 71.4 | — |
| 李文涛等人[ | ResNet | 30.0 | 82.70 | — | — |
| Zhai等人[ | DenseNet-S-32-1 | 11.6 | 78.90 | 76.5 | 29.50 |
表3 不同算法在公共数据集上的测试结果
Table 3 Results of different algorithms in public datasets
| 文献 | 骨干网络 | 速度/(frame/s) | mAP/% | ||
|---|---|---|---|---|---|
| VOC2007 | VOC2012 | MS COCO | |||
| DSSD321[ | ResNet-101 | 9.5 | 78.60 | 76.3 | 33.20 |
| DSSD513[ | ResNet-101 | 5.5 | 81.50 | 80.8 | 33.20 |
| Shen等人[ | DenseNet | 17.4 | 77.70 | 76.3 | 29.30 |
| Adamdad[ | MobileNet | 29.0 | 64.22 | — | — |
| 齐榕等人[ | MobileNet | — | 73.30 | — | 40.20 |
| Li等人[ | Shuffle_SENet | 29.0 | 64.70 | — | — |
| YOLOv3_Tiny | Darknet-Tiny | 25.0 | 58.20 | — | 33.30 |
| YOLO V5l[ | CSPNet | 99.0 | — | — | 48.80 |
| Pan等人[ | DenseNet | 12.0 | 65.93 | — | — |
| 张侣等人[ | Res-Am | 51.0 | 71.40 | — | — |
| 赵鹏飞等人[ | I-Darknet53 | 32.0 | 82.30 | — | — |
| 奚琦等人[ | DenseNet | 58.0 | 82.30 | — | — |
| Cheng等人[ | MobileNetV2-FPN | 97.0 | 73.80 | 71.4 | — |
| 李文涛等人[ | ResNet | 30.0 | 82.70 | — | — |
| Zhai等人[ | DenseNet-S-32-1 | 11.6 | 78.90 | 76.5 | 29.50 |
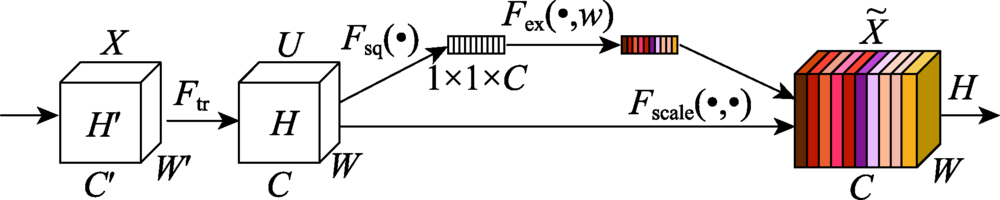
图3 SE模块
Fig.3 SE block
| 文献 | 算法 | 速度/(frame/s) | mAP/% | |
|---|---|---|---|---|
| VOC2007 | COCO | |||
| 李文涛等人[ | KNCA-Fusion | 30.0 | 82.70 | — |
| 赵鹏飞等人[ | — | 32.0 | 82.30 | — |
| 徐诚极等人[ | Attention- YOLO-A | 26.0 | 81.70 | 32.6 |
| 张陶宁等人[ | MSFAN | 46.0 | 75.50 | 33.6 |
| Li等人[ | Attention-YOLO-B | 25.0 | 81.90 | 33.5 |
| 于敏等人[ | 改进型RetinaNet | — | 79.50 | 40.9 |
| 刘建政等人[ | FIENet | 36.0 | 82.30 | 33.8 |
| 张海涛等人[ | — | 25.0 | 79.70 | — |
| Pan等人[ | ADFPNet300 | 62.5 | 81.10 | 31.8 |
| ADFPNet512 | 43.5 | 82.50 | 36.4 | |
| Zhu等人[ | ODMC300 | 34.8 | 79.60 | 30.2 |
| ODMC512 | 14.5 | 81.80 | 34.6 | |
| 赵文清等人[ | 改进型SSD300 | 33.0 | 80.60 | — |
| 改进型SSD321 | 30.0 | 81.50 | ||
| 改进型SSD512 | 12.0 | 82.50 | ||
| 鞠默然等人[ | AM-YOLO V3 416 | 38.9 | 82.69 | — |
| AM-YOLO V3 544 | 26.5 | 83.43 | ||
表4 引用注意力机制在公共数据集上的测试结果
Table 4 Test results of using attention in public datasets
| 文献 | 算法 | 速度/(frame/s) | mAP/% | |
|---|---|---|---|---|
| VOC2007 | COCO | |||
| 李文涛等人[ | KNCA-Fusion | 30.0 | 82.70 | — |
| 赵鹏飞等人[ | — | 32.0 | 82.30 | — |
| 徐诚极等人[ | Attention- YOLO-A | 26.0 | 81.70 | 32.6 |
| 张陶宁等人[ | MSFAN | 46.0 | 75.50 | 33.6 |
| Li等人[ | Attention-YOLO-B | 25.0 | 81.90 | 33.5 |
| 于敏等人[ | 改进型RetinaNet | — | 79.50 | 40.9 |
| 刘建政等人[ | FIENet | 36.0 | 82.30 | 33.8 |
| 张海涛等人[ | — | 25.0 | 79.70 | — |
| Pan等人[ | ADFPNet300 | 62.5 | 81.10 | 31.8 |
| ADFPNet512 | 43.5 | 82.50 | 36.4 | |
| Zhu等人[ | ODMC300 | 34.8 | 79.60 | 30.2 |
| ODMC512 | 14.5 | 81.80 | 34.6 | |
| 赵文清等人[ | 改进型SSD300 | 33.0 | 80.60 | — |
| 改进型SSD321 | 30.0 | 81.50 | ||
| 改进型SSD512 | 12.0 | 82.50 | ||
| 鞠默然等人[ | AM-YOLO V3 416 | 38.9 | 82.69 | — |
| AM-YOLO V3 544 | 26.5 | 83.43 | ||
| 文献 | 算法 | 特征融合策略 | 速度/(frame/s) | mAP/% | ||
|---|---|---|---|---|---|---|
| VOC2007 | VOC2012 | COCO | ||||
| Li等人[ | FSSD512 | 将Conv4_3、Fc7以及Conv7_2的特征图进行串联融合操作 | 35.7 | 80.9 | 82.4 | 31.8 |
| 赵鹏飞等人[ | — | 采用多尺度空洞卷积级联扩大特征图的感受野,然后使用1×1卷积将特征信息融合;并将38×38大小的特征图与10×10和19×19的特征图拼接,最后采用ECAM模块进行通道加权 | 32.0 | 82.3 | — | — |
| 于敏等人[ | 改进型RetinaNet | 设计了一个自底向上的路径聚合模块,将聚合后的结果经过缩放整合与优化,最后得到多特征{M3,M4,M5,M6,M7},并与N3~N7的特征层再次相加融合 | — | 79.5 | — | 40.9 |
| 刘建政等人[ | FIENet | 将Conv4_3和Fc7两个特征层融合,增加不同特征层之间的特征映射关系;将输入通道通过1×1卷积分成4份之后进行级联,增强细节语义信息 | 36.1 | 82.3 | — | 33.8 |
| Shi等人[ | FFESSD300 FFESSD512 | 设计了两种不同模式的FFM模块,在其中一种FFM模块中利用反卷积调整特征图大小;同时,设计了浅层特征增强和深层特征增强模块 | 54.3 30.2 | 79.1 81.8 | — | — |
| Woo等人[ | StairNet | 通过反卷积与浅层特征信息融合,同时将融合后的特征传递到下一个反卷积层,以自顶向下的方式增强目标语义信息 | 30.0 | 78.8 | 76.4 | 33.6 |
| 张思宇等人[ | hgSSD | 在SSD300的基础上对不同尺度的特征图进行反卷积操作与浅层特征融合,并在不同尺度的特征图上进行特征预测 | 36.0 | 82.3 | 82.3 | 33.8 |
| 王燕妮等人[ | 改进的SSD | 结合CSPNet的思想设计跳变连接网络,将特征图划分为两个分支,通过跨阶段层次结构合并 | 37.3 | 79.6 | — | — |
表5 不同特征融合策略在公共数据集上的测试结果
Table 5 Test results of different feature fusion strategies in public datasets
| 文献 | 算法 | 特征融合策略 | 速度/(frame/s) | mAP/% | ||
|---|---|---|---|---|---|---|
| VOC2007 | VOC2012 | COCO | ||||
| Li等人[ | FSSD512 | 将Conv4_3、Fc7以及Conv7_2的特征图进行串联融合操作 | 35.7 | 80.9 | 82.4 | 31.8 |
| 赵鹏飞等人[ | — | 采用多尺度空洞卷积级联扩大特征图的感受野,然后使用1×1卷积将特征信息融合;并将38×38大小的特征图与10×10和19×19的特征图拼接,最后采用ECAM模块进行通道加权 | 32.0 | 82.3 | — | — |
| 于敏等人[ | 改进型RetinaNet | 设计了一个自底向上的路径聚合模块,将聚合后的结果经过缩放整合与优化,最后得到多特征{M3,M4,M5,M6,M7},并与N3~N7的特征层再次相加融合 | — | 79.5 | — | 40.9 |
| 刘建政等人[ | FIENet | 将Conv4_3和Fc7两个特征层融合,增加不同特征层之间的特征映射关系;将输入通道通过1×1卷积分成4份之后进行级联,增强细节语义信息 | 36.1 | 82.3 | — | 33.8 |
| Shi等人[ | FFESSD300 FFESSD512 | 设计了两种不同模式的FFM模块,在其中一种FFM模块中利用反卷积调整特征图大小;同时,设计了浅层特征增强和深层特征增强模块 | 54.3 30.2 | 79.1 81.8 | — | — |
| Woo等人[ | StairNet | 通过反卷积与浅层特征信息融合,同时将融合后的特征传递到下一个反卷积层,以自顶向下的方式增强目标语义信息 | 30.0 | 78.8 | 76.4 | 33.6 |
| 张思宇等人[ | hgSSD | 在SSD300的基础上对不同尺度的特征图进行反卷积操作与浅层特征融合,并在不同尺度的特征图上进行特征预测 | 36.0 | 82.3 | 82.3 | 33.8 |
| 王燕妮等人[ | 改进的SSD | 结合CSPNet的思想设计跳变连接网络,将特征图划分为两个分支,通过跨阶段层次结构合并 | 37.3 | 79.6 | — | — |

图4 两目标框IoU为0
Fig.4 IoU of two boxes is 0
| 数据集名称 | 图像总数 | 实例数 | 类别数量 | 年份 | 应用场景 |
|---|---|---|---|---|---|
| EuroCity Persons[ | 47 300 | 238 200 | 7 | 2019 | 行人检测 |
| DOTA[ | 2 806 | 188 282 | 15 | 2018 | 航空图像检测 |
| WIDER FACE[ | 32 203 | 393 703 | 60 | 2016 | 人脸检测 |
| CityPersons[ | 5 000 | 约35 000 | 4 | 2017 | 行人检测 |
| TinyPerson[ | 1 610 | 72 651 | 5 | 2020 | 航空图像中的行人检测 |
| Behrendt[ | 8 334 | 13 493 | 4 | 2017 | 交通灯检测 |
| AI-TOD[ | 28 036 | 700 621 | 8 | 2021 | 航空图像检测 |
| iSAID[ | 2 806 | 655 451 | 15 | 2019 | 航空图像检测 |
| WiderPerson[ | 13 382 | 399 786 | 5 | 2019 | 行人检测 |
| DeepScores[ | 300 000 | 数百万 | 118 | 2018 | 乐谱图像检测 |
表6 相关小目标检测数据集
Table 6 Small object detection datasets
| 数据集名称 | 图像总数 | 实例数 | 类别数量 | 年份 | 应用场景 |
|---|---|---|---|---|---|
| EuroCity Persons[ | 47 300 | 238 200 | 7 | 2019 | 行人检测 |
| DOTA[ | 2 806 | 188 282 | 15 | 2018 | 航空图像检测 |
| WIDER FACE[ | 32 203 | 393 703 | 60 | 2016 | 人脸检测 |
| CityPersons[ | 5 000 | 约35 000 | 4 | 2017 | 行人检测 |
| TinyPerson[ | 1 610 | 72 651 | 5 | 2020 | 航空图像中的行人检测 |
| Behrendt[ | 8 334 | 13 493 | 4 | 2017 | 交通灯检测 |
| AI-TOD[ | 28 036 | 700 621 | 8 | 2021 | 航空图像检测 |
| iSAID[ | 2 806 | 655 451 | 15 | 2019 | 航空图像检测 |
| WiderPerson[ | 13 382 | 399 786 | 5 | 2019 | 行人检测 |
| DeepScores[ | 300 000 | 数百万 | 118 | 2018 | 乐谱图像检测 |

图5 小目标数据集检测结果
Fig.5 Detection results of small object detection datasets
| [1] | GU J, WANG Z, KUEN J, et al. Recent advances in convolutional neural networks[J]. arXiv:1512.07108, 2015. |
| [2] | REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 779-788. |
| [3] | REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 6517-6525. |
| [4] | REDMON J, FARHADI A. YOLOv3: an incremental improvement[J]. arXiv:1804.02767, 2018. |
| [5] | LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector[C]// Proceedings of the 14th European Conference on Computer Vision, Amsterdam, Oct 11-14, 2016. Cham: Springer, 2016: 21-37. |
| [6] | FU C Y, LIU W, RANGA A, et al. DSSD: deconvolutional single shot detector[J]. arXiv:1701.06659, 2017. |
| [7] | SHEN Z Q, LIU Z, LI J G, et al. DSOD: learning deeply supervised object detectors from scratch[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Oct 22-29, 2017. Washington: IEEE Computer Society, 2017: 1937-1945. |
| [8] | JEONG J, PARK H, KWAK N. Enhancement of SSD by concatenating feature maps for object detection[J]. arXiv:1705.09587, 2017. |
| [9] | LI Z X, ZHOU F Q. FSSD: feature fusion single shot multibox detector[J]. arXiv:1712.00960, 2018. |
| [10] | LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Oct 22-29, 2017. Washington: IEEE Computer Society, 2017: 2999-3007. |
| [11] | 王迪聪, 白晨帅, 邬开俊. 基于深度学习的视频目标检测综述[J]. 计算机科学与探索, 2021, 15(9):1563-1577. |
| WANG D C, BAI C S, WU K J. Survey of video object detection based on deep learning[J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(9):1563-1577. | |
| [12] | 史彩娟, 张卫明, 陈厚儒, 等. 基于深度学习的显著性目标检测综述[J]. 计算机科学与探索, 2021, 15(2):219-232. |
| SHI C J, ZHANG W M, CHEN H R, et al. Survey of salient object detection based on deep learning[J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(2):219-232. | |
| [13] | 蔡强, 刘亚奇, 曹健, 等. 图像目标类别检测综述[J]. 计算机科学与探索, 2015, 9(3):257-265. |
| CAI Q, LIU Y Q, CAO J, et al. Review on object class detection of images[J]. Journal of Frontiers of Computer Science and Technology, 2015, 9(3):257-265. | |
| [14] | 许德刚, 王露, 李凡. 深度学习的典型目标检测算法研究综述[J]. 计算机工程与应用, 2021, 57(8):10-25. |
| XU D G, WANG L, LI F. Review of typical object detection algorithms for deep learning[J]. Computer Engineering and Applications, 2021, 57(8):10-25. | |
| [15] | 谢文亮, 朱丹, 佟新鑫. 一种基于视觉注意的小目标检测方法[J]. 计算机工程与应用, 2013, 49(12):125-128. |
| XIE W L, ZHU D, TONG X X. Small target detection method based on visual attention[J]. Computer Engineering and Applications, 2013, 49(12):125-128. | |
| [16] | LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context[C]// Proceedings of the 13th European Conference on Computer Vision, Zurich, Sep 6-12, 2014. Cham: Springer, 2014: 740-755. |
| [17] | CHEN C, LIU M Y, TUZEL O, et al. R-CNN for small object detection[C]// Proceedings of the 13th Asian Conference on Computer Vision, Taipei, China, Nov 20-24, 2016. Cham: Springer, 2016: 214-230. |
| [18] | BRAUN M, KREBS S, FLOHR F, et al. The EuroCity persons dataset: a novel benchmark for object detection[J]. arXiv.1805.07193, 2018. |
| [19] | XIA G S, BAI X, DING J, et al. DOTA: a large-scale dataset for object detection in aerial images[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-23, 2018. Piscataway: IEEE, 2018: 3974-3983. |
| [20] | YANG S, LUO P, LOY C C, et al. WIDER FACE: a face detection benchmark[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 5525-5533. |
| [21] | ZHANG S, BENENSON R, SCHIELE B. CityPersons: a diverse dataset for pedestrian detection[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 3213-3221. |
| [22] | YU X, GONG Y, JIANG N, et al. Scale match for tiny person detection[J]. arXiv:1912.10664, 2019. |
| [23] | MACQUEEN J. Some methods for classification and analysis of multivariate observations[C]// Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability. Berkeley: University of California Press, 1967: 281-297. |
| [24] | KE W, ZHANG T, HUANG Z, et al. Multiple anchor learning for visual object detection[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10206-10215. |
| [25] | 周慧, 严凤龙, 褚娜, 等. 一种改进复杂场景下小目标检测模型的方法[J/OL]. 计算机工程与应用 [2021-09-04]. http://kns.cnki.net/kcms/detail/11.2127.TP.20210419.1404.049.html. |
| ZHOU H, YAN F L, CHU N, et al. An approach to improve detection model for small object in complex scenes[J/OL]. Computer Engineering and Applications [2021-09-04]. http://kns.cnki.net/kcms/detail/11.2127.TP.20210419.1404.049.html. | |
| [26] | ESTER M, KRIEGEL H P, SANDER J, et al. A density-based algorithm for discovering clusters in large spatial databases with noise[C]// Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining, Portland, 1996. Menlo Park: AAAI, 1996: 226-231. |
| [27] | 岳晓新, 贾君霞, 陈喜东, 等. 改进YOLO V3的道路小目标检测[J]. 计算机工程与应用, 2020, 56(21):218-223. |
| YUE X X, JIA J X, CHEN X D, et al. Road small target detection algorithm based on improved YOLO V3[J]. Computer Engineering and Applications, 2020, 56(21):218-223. | |
| [28] | 李云红, 张轩, 李传真, 等. 融合DBSCAN的改进YOLOv3目标检测算法[J/OL]. 计算机工程与应用 [2021-09-04]. http://kns.cnki.net/kcms/detail/11.2127.TP.20210327.1437.002.html. |
| LI Y H, ZHANG X, LI C Z, et al. Improved YOLOv3 target detection algorithm combined with DBSCAN[J/OL]. Computer Engineering and Applications [2021-09-04]. . | |
| [29] | 罗建华, 黄俊, 白鑫宇, 改进YOLOv3的道路小目标检测方法[J/OL]. 小型微型计算机系统 [2021-09-12]. http://kns.cnki.net/kcms/detail/21.1106.TP.20210420.1111.023.html. |
| LUO J H, HUANG J, BAI X Y. Road small target detection method based on improved YOLOv3[J/OL]. Journal of Chinese Computer Systems [2021-09-12]. http://kns.cnki.net/kcms/detail/21.1106.TP.20210420.1111.023.html. | |
| [30] | 刘家乐, 吴怀宇, 陈志环. 改进YOLOv3的工业指针式仪表检测方法[J]. 计算机工程与设计, 2021, 42(7):2001-2008. |
| LIU J L, WU H Y, CHEN Z H. Improved YOLOv3 industrial pointer instrument detection method[J]. Computer Engineering and Design, 2021, 42(7):2001-2008. | |
| [31] | MU X, LIN Y, LIU J, et al. Surface navigation target detection and recognition based on SSD[C]// Proceedings of the 2019 3rd International Conference on Electronic Information Technology and Computer Engineering, Xiamen, Oct 18-20, 2019. Washington: IEEE Computer Society, 2019: 649-653. |
| [32] | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[J]. arXiv1409. 1556, 2014. |
| [33] |
HE K, ZHANG X, REN S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9):1904-1916.
DOI URL |
| [34] | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 770-778. |
| [35] | HOWARD A G, ZHU M L, CHEN B, et al. MobileNets: efficient convolutional neural networks for mobile vision applications[J]. arXiv:1704.04861, 2017. |
| [36] | HUANG G, LIU Z, et al. Densely connected convolutional networks[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 2261-2269. |
| [37] | SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, Jun 7-12, 2015. Washington: IEEE Computer Society, 2015: 1-8. |
| [38] | ZHANG X Y, ZHOU X Y, LIN M X, et al. ShuffleNet: an extremely efficient convolutional neural network for mobile devices[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-23, 2018. Washington: IEEE Computer Society, 2018: 6848-6856. |
| [39] | ADAMDAD. Keras-YOLOv3-mobilenet.[EB/OL]. (2019)[2021-08-20]. https://github.com/Adamdad/keras-YOLOv3-mobilenet. |
| [40] | 王建军, 魏江, 梅少辉, 等. 面向遥感图像小目标检测的改进YOLOv3算法[J]. 计算机工程与应用, 2021, 57(20):133-141. |
| WANG J J, WEI J, MEI S H, et al. Improved YOLOv3 for small object detection in remote sensing images[J]. Computer Engineering and Applications, 2021, 57(20):133-141. | |
| [41] | LI Y, LV C. SS-YOLO: an object detection algorithm based on YOLOv3 and ShuffleNet[C]// Proceedings of the 2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference, Chongqing, Jun 12-14, 2020. Piscataway: IEEE, 2020: 769-772. |
| [42] | HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-22, 2018. Washington: IEEE Computer Society, 2018: 7132-7141. |
| [43] | BOCHKOVSKIY A, WANG C Y, LIAO H . M. YOLOv4: optimal speed and accuracy of object detection[J]. arXiv: 2004.10934, 2020. |
| [44] | MAHTO P, GARG P, SETH P, et al. Refining YOLOV4 for vehicle detection[J]. International Journal of Advanced Research in Engineering and Technology, 2020, 11(5):409-419. |
| [45] | 谢俊章, 彭辉, 唐健峰, 等. 改进YOLOv4的密集遥感目标检测[J]. 计算机工程与应用, 2021, 57(22):247-256. |
| XIE J Z, PENG H, TANG J F, et al. Improve YOLOv4 for dense remote sensing target detection[J]. Computer Engineering and Applications, 2021, 57(22):247-256. | |
| [46] | JOCHER G. YOLOv5[EB/OL]. [2020-08-10]. https://github.com/ultralytics/yolov5. |
| [47] | PAN Z H, CHEN Y. Object detection algorithm based on dense connection[C]// Proceedings of the 2019 IEEE 4th Advanced Information Technology, Electronic and Automation Control Conference, Chengdu, Dec 20-22, 2019. Piscataway: IEEE, 2019: 1558-1562. |
| [48] | 李航, 朱明. 基于深度卷积神经网络的小目标检测算法[J]. 计算机工程与科学, 2020, 42(4):649-657. |
| LI H, ZHU M. A small object detection algorithm based on deep convolutional neural network[J]. Computer Engineering and Science, 2020, 42(4):649-657. | |
| [49] | 齐榕, 贾瑞生, 徐志峰, 等. 基于YOLOv3的轻量级目标检测网络[J]. 计算机应用与软件, 2020, 37(10):208-213. |
| QI R, JIA R S, XU Z F, et al. Lightweight object detection network based on YOLOv3[J]. Computer Applications and Software, 2020, 37(10):208-213. | |
| [50] | 郑秋梅, 王璐璐, 王风华. 基于改进卷积神经网络的交通场景小目标检测[J]. 计算机工程, 2020, 46(6):26-33. |
| ZHENG Q M, WANG L L, WANG F H. Small object detection in traffic scene based on improved convolutional neural network[J]. Computer Engineering, 2020, 46(6):26-33. | |
| [51] | 张侣, 周博文, 吴亮红. 基于改进卷积注意力模块与残差结构的SSD网络[J/OL]. 计算机科学 [2021-09-12]. . |
| ZHANG L, ZHOU B W, WU L H. SSD network based on improved convolutional attention module and residual structure[J/OL]. Computer Science [2021-09-12]. http://kns.cnki.net/kcms/detail/50.1075.TP.20211012.1354.006. html. | |
| [52] | 赵鹏飞, 谢林柏, 彭力. 融合注意力机制的深层次小目标检测算法[J/OL]. 计算机科学与探索 [2021-10-18]. http://kns.cnki.net/kcms/detail/11.5602.TP20211014.2108.010.html. |
| ZHAO P F, XIE L B, PENG L. Deep small object detection algorithm integrating attention mechanism[J/OL]. Journal of Frontiers of Computer Science and Technology [2021-10-18]. http://kns.cnki.net/kcms/detail/11.5602.TP.20211014.2108.010.html. | |
| [53] | 奚琦, 张正道, 彭力. 基于改进密集网络与二次回归的小目标检测算法[J]. 计算机工程, 2021, 47(4):241-247. |
| XI Q, ZHANG Z D, PENG L. Small object detection algorithm based on improved dense network and quadratic regression[J]. Computer Engineering, 2021, 47(4):241-247. | |
| [54] | 徐先峰, 赵万福, 邹浩泉, 等. 基于MobileNet-SSD的安全帽佩戴检测算法[J]. 计算机工程, 2021, 47(10):298-305. |
| XU X F, ZHAO W F, ZOU H Q, et al. Safety helmet wearing detection method based on MobileNet-SSD[J]. Computer Engineering, 2021, 47(10):298-305. | |
| [55] | LU X, KANG X, NISHIDE S, et al. Object detection based on SSD-ResNet[C]// Proceedings of the 2019 IEEE 6th International Conference on Cloud Computing and Intelligence Systems, Singapore, Dec 19-21, 2019. Piscataway: IEEE, 2019: 89-92. |
| [56] | CHENG M, BAI J, LI L, et al. Tiny-RetinaNet: a one-stage detector for realtime object detection[C]// SPIE 11373: Proceedings of the 11th International Conference on Graphics and Image Processing, Hangzhou, 2020. |
| [57] | 李文涛, 彭力. 多尺度通道注意力融合网络的小目标检测算法[J]. 计算机科学与探索, 2021, 15(12):2390-2400. |
| LI W T, PENG L. Small objects detection algorithm with multi-scale channel attention fusion network[J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(12):2390-2400. | |
| [58] |
ZHAI S P, SHANG D R, WANG S H, et al. DF-SSD: an improved SSD object detection algorithm based on DenseNet and feature fusion[J]. IEEE Access, 2020, 8:24344-24357.
DOI URL |
| [59] | ZHU X, CHENG D, ZHANG Z, et al. An empirical study of spatial attention mechanisms in deep networks[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Oct 27-Nov 2, 2019. Piscataway: IEEE, 2019: 6687-6696. |
| [60] | 徐诚极, 王晓峰, 杨亚东. Attention-YOLO: 引入注意力机制的YOLO检测算法[J]. 计算机工程与应用, 2019, 55(6):13-23. |
| XU C J, WANG X F, YANG Y D. Attention-YOLO: YOLO detection algorithm that introduces attention mechanism[J]. Computer Engineering and Applications, 2019, 55(6):13-23. | |
| [61] | 张陶宁, 陈恩庆, 肖文福. 一种改进MobileNet_YOLOv3网络的快速目标检测方法[J]. 小型微型计算机系统, 2021, 42(5):1008-1014. |
| ZHAG T N, CHEN E Q, XIAO W F. Fast target detection method for improving MobileNet_YOLOv3 network[J]. Journal of Chinese Computer Systems, 2021, 42(5):1008-1014. | |
| [62] |
LI Y, LI S, DU H, et al. YOLO-ACN: focusing on small target and occluded object detection[J]. IEEE Access, 2020, 8:227288-227303.
DOI URL |
| [63] | 麻森权, 周克. 基于注意力机制和特征融合改进的小目标检测算法[J]. 计算机应用与软件, 2020, 37(5):194-199. |
| MA S Q, ZHOU K. An improved small object detection algorithm based on attention mechanism and feature fusion[J]. Computer Applications and Software, 2020, 37(5):194-199. | |
| [64] | WANG Q, WU B G, ZHU P F, et al. ECA-Net: efficient channel attention for deep convolutional neural networks[C]// Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition, Seattle, Jun 14-19, 2020. Piscataway: IEEE, 2020: 11531-11539. |
| [65] | 于敏, 屈丹, 司念文. 改进型RetinaNet的目标检测算法[J/OL]. 计算机工程 [2021-08-27]. https://doi.org/10.19678/j.issn.1000-3428.0062134. |
| YU M, QU D, SI N W. Object detection algorithm for improved RetinaNet[J/OL]. Computer Engineering [2021-08-27]. https://doi.org/10.19678/j.issn.1000-3428.0062134. | |
| [66] | QIN Z Q, ZHANG P Y, WU F, et al. FcaNet: frequency channel attention networks[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 783-792. |
| [67] | 刘建政, 梁鸿, 崔学荣, 等. 融入特征融合与特征增强的SSD目标检测[J/OL]. 计算机工程与应用 [2021-09-16]. http://kns.cnki.net/kcms/detail/11.2127.TP.20210203.1148.022.html. |
| LIU J Z, LIANG H, CUI X R, et al. SSD visual target detector based on feature integration and feature enhancement[J/OL]. Computer Engineering and Applications [2021-09-16]. http://kns.cnki.net/kcms/detail/11.2127.TP.20210203.1148.022.html. | |
| [68] | 张海涛, 张梦. 引入通道注意力机制的SSD目标检测算法[J]. 计算机工程, 2020, 46(8):264-270. |
| ZHANG H T, ZHANG M. SSD target detection algorithm with channel attention mechanism[J]. Computer Engineering, 2020, 46(8):264-270. | |
| [69] |
PAN H, CHEN G, JIANG J. Adaptively dense feature pyramid network for object detection[J]. IEEE Access, 2019, 7:81132-81144.
DOI URL |
| [70] |
ZHU G, WEI Z, LIN F. An object detection method combining multi-level feature fusion and region channel attention[J]. IEEE Access, 2021, 9:25101-25109.
DOI URL |
| [71] | 赵文清, 杨盼盼. 双向特征融合与注意力机制结合的目标检测[J]. 智能系统学报, 2021, 16(6):1098-1105. |
| ZHAO W Q, YANG P P. Target detection based on bidirectional feature fusion and attention mechanism[J]. CAAI Transactions on Intelligent Systems, 2021, 16(6):1098-1105. | |
| [72] | 鞠默然, 罗江宁, 王仲博, 等. 融合注意力机制的多尺度目标检测算法[J]. 光学学报, 2020, 40(13):132-140. |
| JU M R, LUO J N, WANG Z B, et al. Multi-scale target detection algorithm based on attention mechanism[J]. Acta Optica Sinica, 2020, 40(13):132-140. | |
| [73] | 宋忠浩, 谷雨, 陈旭, 等. 基于加权策略的高分辨率遥感图像目标检测[J]. 计算机工程与应用, 2021, 57(13):199-206. |
| SONG Z H, GU Y, CHEN X, et al. Target detection in high-resolution remote sensing image based on weighted strategy[J]. Computer Engineering and Applications, 2021, 57(13):199-206. | |
| [74] |
SHI W, BAO S, TAN D. FFESSD: an accurate and efficient single-shot detector for target detection[J]. Applied Sciences, 2019, 9(20):4276.
DOI URL |
| [75] | WOO S, HWANG S, KWEON I S. StairNet: top-down semantic aggregation for accurate one shot detection[C]// Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, Mar 12-15, 2018. Piscataway: IEEE, 2018: 1093-1102. |
| [76] | 张思宇, 张轶. 基于多尺度特征融合的小目标行人检测[J]. 计算机工程与科学, 2019, 41(9):1627-1634. |
| ZHANG S Y, ZHANG Y. Small target pedestrian detection based on multi-scale feature fusion[J]. Computer Engineering and Science, 2019, 41(9):1627-1634. | |
| [77] | 王燕妮, 余丽仙. 注意力与多尺度有效融合的SSD目标检测算法[J/OL]. 计算机科学与探索 [2021-09-12]. http://kns.cnki.net/kcms/detail/11.5602.TP.20210722.1315.004.html. |
| WANG Y N, YU L X. SSD object detection algorithm with effective fusion of attention and multi-scale[J/OL]. Journal of Frontiers of Computer Science and Technology [2021-09-12]. http://kns.cnki.net/kcms/detail/11.5602.TP.20210722.1315.004.html. | |
| [78] | 赵文清, 孔子旭, 周震东, 等. 增强小目标特征的航空遥感目标检测[J]. 中国图象图形学报, 2021, 26(3):644-653. |
| ZHAO W Q, KONG Z X, ZHOU Z D, et al. Target detection algorithm of aerial remote sensing based on feature enhancement technology[J]. Journal of Image and Graphics, 26(3):644-653. | |
| [79] | SUN K, XIAO B, LIU D, et al. Deep high-resolution representation learning for human pose estimation[C]// Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, Jun 16-20, 2019. Piscataway: IEEE, 2019: 5693-5703. |
| [80] | SHI X, CHEN Z, WANG H, et al. Convolutional LSTM network: a machine learning approach for precipitation[J]. Advances in Neural Information Processing Systems, 2015, 28:802-810. |
| [81] | 鲁博, 瞿绍军. 融合BiFPN和改进YOLOv3-Tiny网络的航拍图像车辆检测方法[J]. 小型微型计算机系统, 2021, 42(8):1694-1698. |
| LU B, QU S J. Vehicle detection method in aerial images based on BiFPN and improved YOLOv3-Tiny network[J]. Journal of Chinese Computer Systems, 2021, 42(8):1694-1698. | |
| [82] | 潘昕晖, 邵清, 卢军国. 基于CBD-YOLOv3的小目标检测算法[J/OL]. 小型微型计算机系统 [2021-09-05]. http://kns.cnki.net/kcms/detail/21.1106.TP.20210818.1055.032.html. |
| PAN X H, SHAO Q, LU J G. Small object detection algorithm based on CBD-YOLOv3[J/OL]. Journal of Chinese Computer Systems [2021-09-05]. http://kns.cnki.net/kcms/detail/21.1106.TP.20210818.1055.032.html. | |
| [83] | REZATOFIGHI H, TSOI N, GWAK J Y, et al. Generalized intersection over union: a metric and a loss for bounding box regression[C]// Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, Jun 16-20, 2019. Piscataway: IEEE, 2019: 658-666. |
| [84] | YANG Y M, LIAO Y R, CHENG L F, et al. Remote sensing image aircraft target detection based on GIoU-YOLOv3[C]// Proceedings of the 2021 6th International Conference on Intelligent Computing and Signal Processing, Xi’an, Apr 9-11, 2021. Piscataway: IEEE, 2021: 474-478. |
| [85] | 邹承明, 薛榕刚. 融合GIoU和Focal loss的YOLOv3目标检测算法[J]. 计算机工程与应用, 2020, 56(24):214-222. |
| ZOU C M, XUE R G. Improved YOLOv3 object detection algorithm: combining GIoU and Focal loss[J]. Computer Engineering and Applications, 2020, 56(24):214-222. | |
| [86] | ZHENG Z H, WANG P, LIU W, et al. Distance-IoU loss: faster and better learning for bounding box regression[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence, the 32nd Innovative Applications of Artificial Intelligence Conference, the 10th AAAI Symposium on Educational Advances in Artificial Intelligence, New York, Feb 7-12, 2020. Menlo Park: AAAI, 2020: 12993-13000. |
| [87] | LIANG T J, BAO H. A optimized YOLO method for object detection[C]// Proceedings of the 2020 16th International Conference on Computational Intelligence and Security, Nanning, Nov 27-30, 2020. Piscataway: IEEE, 2020: 30-34. |
| [88] | ZHENG Z, WANG P, REN D, et al. Enhancing geometric factors in model learning and inference for object detection and instance segmentation[J]. arXiv:2005.03572, 2020. |
| [89] | 单美静, 秦龙飞, 张会兵. L-YOLO: 适用于车载边缘计算的实时交通标识检测模型[J]. 计算机科学, 2021, 48(1):89-95. |
| SHAN M J, QIN L F, ZHANG H B. L-YOLO: real time traffic sign detection model for vehicle edge computing[J]. Computer Science, 2021, 48(1):89-95. | |
| [90] | 张炳力, 秦浩然, 江尚, 等. 基于RetinaNet及优化损失函数的夜间车辆检测方法[J]. 汽车工程, 2021, 43(8):1195-1202. |
| ZHANG B L, QIN H R, JIANG S, et al. A method of vehicle detection at night based on RetinaNet and optimized loss functions[J]. Automotive Engineering, 2021, 43(8):1195-1202. | |
| [91] | HU Y Y, WU X J, ZHENG G D, et al. Object detection of UAV for Anti-UAV based on improved YOLO v3[C]// Proceedings of the 2019 Chinese Control Conference, Guangzhou, Jul 27-30 2019. Piscataway: IEEE, 2019: 8386-8390. |
| [92] | 黄凤琪, 陈明, 冯国富. 基于可变形卷积改进的YOLO目标检测算法[J]. 计算机工程, 2021, 47(10):269-275. |
| HUANG F Q, CHEN M, FENG G F. Improved YOLO object detection algorithm based on deformable convolution[J]. Computer Engineering, 2021, 47(10):269-275. | |
| [93] | WANG Z H, LI L H, LI L, et al. Object detection algorithm based on improved YOLOv3-Tiny network in traffic scenes[C]// Proceedings of the 2020 4th CAA International Conference on Vehicular Control and Intelligence, Hangzhou, Dec 18-20, 2020. Piscataway: IEEE, 2020: 514-518. |
| [94] | 黄同愿, 杨雪姣, 向国徽, 等. 基于单目视觉的小目标行人检测与测距研究[J]. 计算机科学, 2020, 47(11):205-211. |
| HUANG T Y, YANG X J, XIANG G H, et al. Study on small target pedestrian detection and ranging based on monocular vision[J]. Computer Science, 2020, 47(11):205-211. | |
| [95] |
CHENG X B, QIU G H, JIANG Y, et al. An improved small object detection method based on YOLO V3[J]. Pattern Analysis and Applications, 2021, 24(3):1347-1355.
DOI URL |
| [96] | ZHAO Q J, SHENG T, WANG Y T, et al. M2Det: a single-shot object detector based on multi-level feature pyramid network[C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Honolulu, Jan 27-Feb 1, 2019. Menlo Park, AAAI, 2019: 9259-9266. |
| [97] | 王鹏, 陆振宇, 詹天明, 等. 基于PDSSD改进型神经网络的小目标检测算法[J]. 计算机应用与软件, 2021, 38(1):149-156. |
| WANG P, LU Z Y, ZHAN T M, et al. Small object detection algorithm based on PDSSD improved neural network[J]. Computer Applications and Software, 2021, 38(1):149-156. | |
| [98] | 张新良, 谢恒, 赵运基, 等. 融合多维空洞卷积算子和多层次特征的深度网络检测算法[J]. 模式识别与人工智能, 2020, 33(10):898-905. |
| ZHANG X L, XIE H, ZHAO Y J, et al. Deep networks detection algorithm fusing multiple dilated convolution operator and multi-level characteristics[J]. Pattern Recognition and Artificial Intelligence, 2020, 33(10):898-905. | |
| [99] | 陈灏然, 彭力. 感受野下的小目标检测算法[J]. 计算机科学与探索, 2021, 15(2):346-353. |
| CHEN H R, PENG L. Detection algorithm of small target in receptive field block[J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(2):346-353. | |
| [100] | 宋云博, 陈冬艳, 郝赟, 等. 基于级联卷积神经网络的高效目标检测方法[J]. 计算机工程与应用, 2021, 57(5):139-145. |
| SONG Y B, CHEN D Y, HAO Y, et al. Efficient object detection method based on cascaded convolutional neural network[J]. Computer Engineering and Applications, 2021, 57(5):139-145. | |
| [101] | LAW H, DENG J. CornerNet: detecting objects as paired keypoints[C]// Proceedings of the 15th European Conference on Computer Vision, Munich, Sep 8-14, 2018. Cham: Springer, 2018: 765-781. |
| [102] | DUAN K, BAI S, XIE L, et al. CenterNet: keypoint triplets for object detection[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Oct 27-Nov 2, 2019. Piscataway: IEEE, 2019: 6569-6578. |
| [103] | TIAN Z, SHEN C, CHEN H, et al. FCOS: fully convolutional one-stage object detection[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Oct 27-Nov 2, 2019. Piscataway: IEEE, 2019: 9626-9635. |
| [104] | BEHRENDT K, NOVAK L, BOTROS R. A deep learning approach to traffic lights: detection, tracking, and classification[C]// Proceedings of the 2017 IEEE International Conference on Robotics and Automation, Singapore, May 29- Jun 3, 2017. Piscataway: IEEE, 2017: 1370-1377. |
| [105] | WANG J W, YANG W, GUO H W, et al. Tiny object detection in aerial images[C]// Proceedings of the 2020 25th International Conference on Pattern Recognition, Milan, Jan 10-15, 2021. Piscataway: IEEE, 2021: 3791-3798. |
| [106] | ZAMIR S W, ARORA A, GUPTA A, et al. iSAID: a large-scale dataset for instance segmentation in aerial images[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, Jun 16-20, 2019. Piscataway: IEEE, 2019: 28-37. |
| [107] | BONDI E, JAIN R, AGGRAWAL P, et al. BIRDSAI: a data-set for detection and tracking in aerial thermal infrared videos[C]// Proceedings of the 2020 IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, Mar 1-5, 2020. Piscataway: IEEE, 2020: 1747-1756. |
| [108] |
ZHANG S F, XIE Y L, WAN J, et al. WiderPerson: a diverse dataset for dense pedestrian detection in the wild[J]. IEEE Transactions on Multimedia, 2020, 22(2):380-393.
DOI URL |
| [109] | NEUMANN L, KARG M, ZHANG S, et al. NightOwls: a pedestrians at night dataset[C]// Proceedings of the 14th Asian Conference on Computer Vision, Perth, Dec 2-6, 2018. Cham: Springer, 2018: 691-705. |
| [110] | TUGGENER L, ELEZI I, SCHMIDHUBER J, et al. DeepScores—a dataset for segmentation, detection and classification of tiny objects[C]// Proceedings of the 2018 24th International Conference on Pattern Recognition, Beijing, Aug 20-24, 2018. Piscataway: IEEE, 2018: 3704-3709. |
| [1] | 安凤平, 李晓薇, 曹翔. 权重初始化-滑动窗口CNN的医学图像分类[J]. 计算机科学与探索, 2022, 16(8): 1885-1897. |
| [2] | 曾凡智, 许露倩, 周燕, 周月霞, 廖俊玮. 面向智慧教育的知识追踪模型研究综述[J]. 计算机科学与探索, 2022, 16(8): 1742-1763. |
| [3] | 刘艺, 李蒙蒙, 郑奇斌, 秦伟, 任小广. 视频目标跟踪算法综述[J]. 计算机科学与探索, 2022, 16(7): 1504-1515. |
| [4] | 赵小明, 杨轶娇, 张石清. 面向深度学习的多模态情感识别研究进展[J]. 计算机科学与探索, 2022, 16(7): 1479-1503. |
| [5] | 夏鸿斌, 肖奕飞, 刘渊. 融合自注意力机制的长文本生成对抗网络模型[J]. 计算机科学与探索, 2022, 16(7): 1603-1610. |
| [6] | 孙方伟, 李承阳, 谢永强, 李忠博, 杨才东, 齐锦. 深度学习应用于遮挡目标检测算法综述[J]. 计算机科学与探索, 2022, 16(6): 1243-1259. |
| [7] | 刘雅芬, 郑艺峰, 江铃燚, 李国和, 张文杰. 深度半监督学习中伪标签方法综述[J]. 计算机科学与探索, 2022, 16(6): 1279-1290. |
| [8] | 程卫月, 张雪琴, 林克正, 李骜. 融合全局与局部特征的深度卷积神经网络算法[J]. 计算机科学与探索, 2022, 16(5): 1146-1154. |
| [9] | 钟梦圆, 姜麟. 超分辨率图像重建算法综述[J]. 计算机科学与探索, 2022, 16(5): 972-990. |
| [10] | 赵鹏飞, 谢林柏, 彭力. 融合注意力机制的深层次小目标检测算法[J]. 计算机科学与探索, 2022, 16(4): 927-937. |
| [11] | 裴利沈, 赵雪专. 群体行为识别深度学习方法研究综述[J]. 计算机科学与探索, 2022, 16(4): 775-790. |
| [12] | 许嘉, 韦婷婷, 于戈, 黄欣悦, 吕品. 题目难度评估方法研究综述[J]. 计算机科学与探索, 2022, 16(4): 734-759. |
| [13] | 朱伟杰, 陈莹. 双流时间域信息交互的微表情识别卷积网络[J]. 计算机科学与探索, 2022, 16(4): 950-958. |
| [14] | 姜艺, 胥加洁, 柳絮, 朱俊武. 边缘指导图像修复算法研究[J]. 计算机科学与探索, 2022, 16(3): 669-682. |
| [15] | 张全贵, 胡嘉燕, 王丽. 耦合用户公共特征的单类协同过滤推荐算法[J]. 计算机科学与探索, 2022, 16(3): 637-648. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||