
Journal of Frontiers of Computer Science and Technology ›› 2022, Vol. 16 ›› Issue (4): 844-854.DOI: 10.3778/j.issn.1673-9418.2010087
• System Software and Software Engineering • Previous Articles Next Articles
HUANG Siyuan, ZHAO Yuhai+( ), LIANG Yiming
), LIANG Yiming
Received:2020-10-28
Revised:2021-01-18
Online:2022-04-01
Published:2021-02-04
About author:HUANG Siyuan, born in 1995, M.S. candidate. His research interests include deep learning, machine learning, etc.Supported by:
黄思远, 赵宇海+(), 梁燚铭
通讯作者:
+ E-mail: zhaoyuhai@mail.neu.edu.cn作者简介:黄思远(1995—),男,吉林四平人,硕士研究生,主要研究方向为深度学习、机器学习等。基金资助:CLC Number:
HUANG Siyuan, ZHAO Yuhai, LIANG Yiming. Code Search Combining Graph Embedding and Attention Mechanism[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(4): 844-854.
黄思远, 赵宇海, 梁燚铭. 融合图嵌入和注意力机制的代码搜索[J]. 计算机科学与探索, 2022, 16(4): 844-854.
Add to citation manager EndNote|Ris|BibTeX
URL: http://fcst.ceaj.org/EN/10.3778/j.issn.1673-9418.2010087

Fig.1 Code retrieval task framework
| 数据集 | 数据集大小 | 数据格式 |
|---|---|---|
| 原始数据集 | 3 564 213 | 方法体/注释 |
| 清洗后数据集 | 2 141 921 | 方法体/注释 |
| 检索代码库 | 1 569 525 | 方法体 |
Table 1 Dataset introduction
| 数据集 | 数据集大小 | 数据格式 |
|---|---|---|
| 原始数据集 | 3 564 213 | 方法体/注释 |
| 清洗后数据集 | 2 141 921 | 方法体/注释 |
| 检索代码库 | 1 569 525 | 方法体 |

Fig.2 Data processing
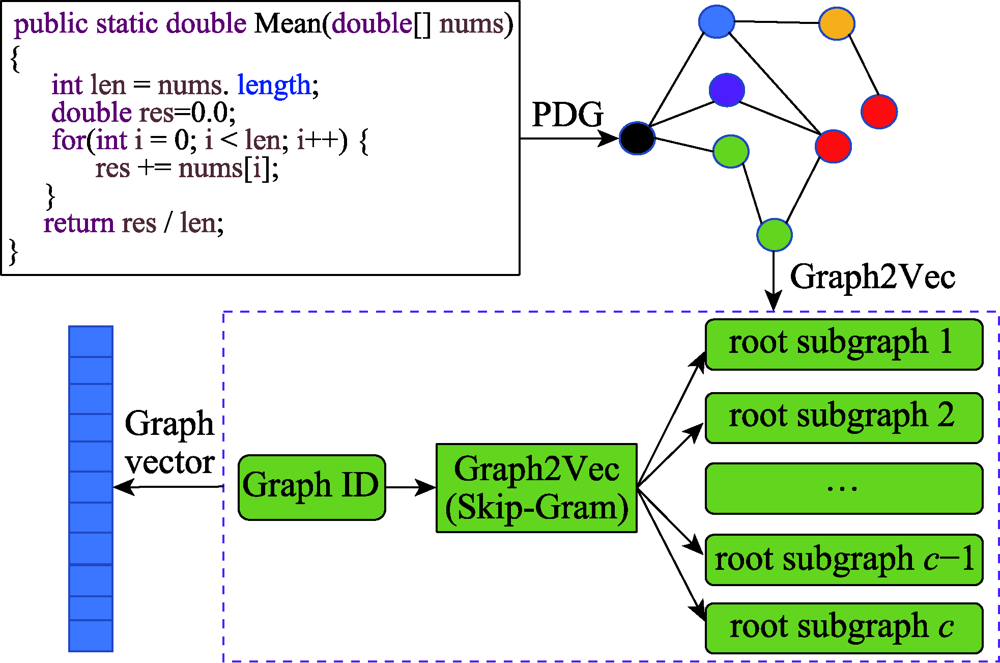
Fig.3 PDG vector extraction process

Fig.4 WL relabeling for graph G

Fig.5 LSTM network structure
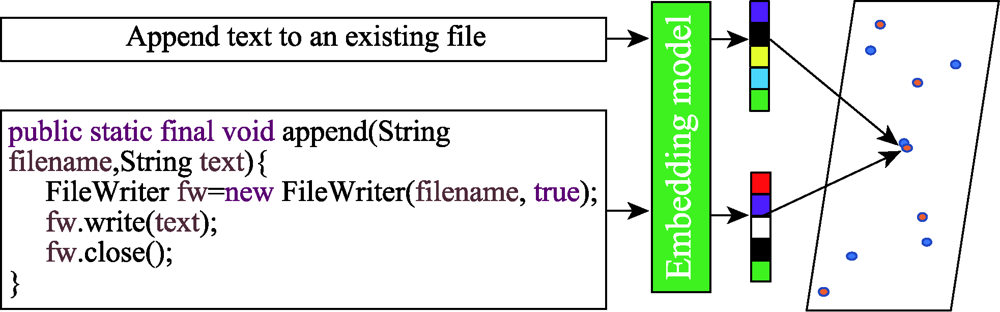
Fig.6 Vector space mapping

Fig.7 GraphCS model network structure
| 参数名称 | 参数数值 |
|---|---|
| 词向量维度 | 512 |
| LSTM隐藏层维度 | 256 |
| 图嵌入维度 | 128 |
| 代码/注释维度 | 512 |
| 词汇表大小 | 10 000 |
| 方法名序列最大长度 | 6 |
| 自然语言序列最大长度 | 30 |
| 令牌最大个数 | 50 |
| 批处理大小 | 64 |
| Dropout | 0.25 |
Table 2 Parameter introduction
| 参数名称 | 参数数值 |
|---|---|
| 词向量维度 | 512 |
| LSTM隐藏层维度 | 256 |
| 图嵌入维度 | 128 |
| 代码/注释维度 | 512 |
| 词汇表大小 | 10 000 |
| 方法名序列最大长度 | 6 |
| 自然语言序列最大长度 | 30 |
| 令牌最大个数 | 50 |
| 批处理大小 | 64 |
| Dropout | 0.25 |
| Query | CODEnn | GraphCS | Query | CODEnn | GraphCS |
|---|---|---|---|---|---|
| inputstream to string | 6 | 3 | round number to n decimal places | NF | 4 |
| create arraylist from array | 1 | 1 | pad an integers with zeros on the left | NF | NF |
| iterate hashmap | NF | 6 | create a generic array | 7 | 6 |
| generate random integers in specific range | 1 | 1 | read a plain text file | 1 | 1 |
| string to int | NF | NF | loop to iterate over enum | NF | NF |
| initialization of an array in one line | 7 | 7 | at least two out of three booleans are true | NF | NF |
| test if an array contains certain value | 6 | 6 | convert from int to string | NF | NF |
| lookup enum by string value | NF | NF | convert char to string | NF | NF |
| breaking out of nested loops | NF | NF | check if file exists | 6 | 3 |
| declare an array | 6 | 5 | java string to date conversion | 1 | 1 |
| generate a random alpha-numeric string | 2 | 2 | convert inputstream to byte array | 2 | 1 |
| simplest way to print a java array | NF | NF | check if string is numeric | NF | 8 |
| sort a map by values | 1 | 1 | copy an object | 1 | 1 |
| test if integer’s square root is integer | NF | NF | time a method’s execution | 5 | 3 |
| concatenate two arrays in java | 4 | 5 | read large text file line by line using java | 6 | 4 |
| create string from the contents of file | 1 | 1 | make new list | NF | NF |
| convert stack trace to string | 1 | 1 | append text to an existing file | 4 | 1 |
| compare strings in java | 4 | 2 | converting iso compliant string to date | 1 | 1 |
| split string in java | NF | 5 | best way to filter a java collection | 9 | 6 |
| create file and write to file | 4 | 3 | remove whitespace from strings in java | 10 | 7 |
| initialization static map | 5 | 5 | split string with any whitespace chars | 7 | 5 |
| iterate through collection avoid exception | NF | NF | best way to determine the size of an object | 5 | 2 |
| generate an md5 hash | 1 | 1 | invoke method when given method name | 7 | 6 |
| get current stack trace | 2 | 1 | get platform dependent new line character | 8 | 6 |
| sort arraylist of objects by property | 2 | 1 | convert map to list | NF | NF |
Table 3 Evaluation results on Frank
| Query | CODEnn | GraphCS | Query | CODEnn | GraphCS |
|---|---|---|---|---|---|
| inputstream to string | 6 | 3 | round number to n decimal places | NF | 4 |
| create arraylist from array | 1 | 1 | pad an integers with zeros on the left | NF | NF |
| iterate hashmap | NF | 6 | create a generic array | 7 | 6 |
| generate random integers in specific range | 1 | 1 | read a plain text file | 1 | 1 |
| string to int | NF | NF | loop to iterate over enum | NF | NF |
| initialization of an array in one line | 7 | 7 | at least two out of three booleans are true | NF | NF |
| test if an array contains certain value | 6 | 6 | convert from int to string | NF | NF |
| lookup enum by string value | NF | NF | convert char to string | NF | NF |
| breaking out of nested loops | NF | NF | check if file exists | 6 | 3 |
| declare an array | 6 | 5 | java string to date conversion | 1 | 1 |
| generate a random alpha-numeric string | 2 | 2 | convert inputstream to byte array | 2 | 1 |
| simplest way to print a java array | NF | NF | check if string is numeric | NF | 8 |
| sort a map by values | 1 | 1 | copy an object | 1 | 1 |
| test if integer’s square root is integer | NF | NF | time a method’s execution | 5 | 3 |
| concatenate two arrays in java | 4 | 5 | read large text file line by line using java | 6 | 4 |
| create string from the contents of file | 1 | 1 | make new list | NF | NF |
| convert stack trace to string | 1 | 1 | append text to an existing file | 4 | 1 |
| compare strings in java | 4 | 2 | converting iso compliant string to date | 1 | 1 |
| split string in java | NF | 5 | best way to filter a java collection | 9 | 6 |
| create file and write to file | 4 | 3 | remove whitespace from strings in java | 10 | 7 |
| initialization static map | 5 | 5 | split string with any whitespace chars | 7 | 5 |
| iterate through collection avoid exception | NF | NF | best way to determine the size of an object | 5 | 2 |
| generate an md5 hash | 1 | 1 | invoke method when given method name | 7 | 6 |
| get current stack trace | 2 | 1 | get platform dependent new line character | 8 | 6 |
| sort arraylist of objects by property | 2 | 1 | convert map to list | NF | NF |
| Model | SuccessRate@1/5/10 | Precision@1/5/10 | MRR |
|---|---|---|---|
| CODEnn | 0.20/0.42/0.66 | 0.20/0.24/0.23 | 0.31 |
| GraphGS | 0.28/0.56/0.74 | 0.28/0.35/0.36 | 0.39 |
Table 4 Performance comparison
| Model | SuccessRate@1/5/10 | Precision@1/5/10 | MRR |
|---|---|---|---|
| CODEnn | 0.20/0.42/0.66 | 0.20/0.24/0.23 | 0.31 |
| GraphGS | 0.28/0.56/0.74 | 0.28/0.35/0.36 | 0.39 |
| Model | Training time/h | Retrieval time/s |
|---|---|---|
| CODEnn | 49.3 | 157 |
| GraphCS | 67.4 | 164 |
Table 5 Retrieval result statistics
| Model | Training time/h | Retrieval time/s |
|---|---|---|
| CODEnn | 49.3 | 157 |
| GraphCS | 67.4 | 164 |
| Model | Method name | Semantic | Method name/Semantic |
|---|---|---|---|
| CODEnn | 18 | 33 | 0.545 |
| GraphCS | 24 | 37 | 0.649 |
Table 6 Retrieval result statistics
| Model | Method name | Semantic | Method name/Semantic |
|---|---|---|---|
| CODEnn | 18 | 33 | 0.545 |
| GraphCS | 24 | 37 | 0.649 |

Fig.8 GraphCS retrieval result

Fig.9 CODEnn retrieval result
| Model | SuccessRate@1/5/10 | MRR |
|---|---|---|
| CODEnn | 0.20/0.42/0.66 | 0.31 |
| GraphGS | 0.28/0.56/0.74 | 0.39 |
| RNN | 0.16/0.40/0.50 | 0.26 |
| NeuralBOW | 0.12/0.30/0.42 | 0.21 |
Table 7 Experimental result statistics
| Model | SuccessRate@1/5/10 | MRR |
|---|---|---|
| CODEnn | 0.20/0.42/0.66 | 0.31 |
| GraphGS | 0.28/0.56/0.74 | 0.39 |
| RNN | 0.16/0.40/0.50 | 0.26 |
| NeuralBOW | 0.12/0.30/0.42 | 0.21 |
| [1] |
KO A J, MYERS B A, COBLENZ M J, et al. An exploratory study of how developers seek, relate, and collect relevant information during software maintenance tasks[J]. IEEE Transactions on Software Engineering, 2006, 32(12):971-987.
DOI URL |
| [2] | BRANDT J, GUO P J, LEWENSTEIN J, et al. Two studies of opportunistic programming: interleaving web foraging, learning, and writing code[C]// Proceedings of the 27th International Conference on Human Factors in Computing Systems, Boston, Apr 4-9, 2009. New York: ACM, 2009: 1589-1598. |
| [3] |
LINSTEAD E, BAJRACHARYA S, NGO T, et al. Sourcerer: mining and searching internet-scale software repositories[J]. Data Mining and Knowledge Discovery, 2009, 18(2):300-336.
DOI URL |
| [4] | REISS S P. Semantics-based code search[C]// Proceedings of the 31st International Conference on Software Engineering, Vancouver, May 16-24, 2009. Piscataway: IEEE, 2009: 243-253. |
| [5] | CHATTERJEE S, JUVEKAR S, SEN K. SNIFF: a search engine for Java using free-form queries[C]// LNCS 5503: Proceedings of the 12th International Conference on Fundamental Approaches to Software Engineering, York, Mar 22-29, 2009. Berlin, Heidelberg: Springer, 2009: 385-400. |
| [6] | MCMILLAN C, GRECHANIK M, POSHYVANYK D, et al. Portfolio: finding relevant functions and their usage[C]// Proceedings of the 33rd International Conference on Software Engineering, Waikiki, May 22-30, 2011. New York: ACM, 2011: 111-120. |
| [7] | LU M L, SUN X B, WANG S W, et al. Query expansion via wordnet for effective code search[C]// Proceedings of the IEEE 22nd International Conference on Software Analysis, Evolution, and Reengineering, Montreal, Mar 2-6, 2015. Washington: IEEE Computer Society, 2015: 545-549. |
| [8] |
LU J T, WEI Y, SUN X B, et al. Interactive query reformulation for source-code search with word relations[J]. IEEE Access, 2018, 6:75660-75668.
DOI URL |
| [9] | RAGHOTHAMAN M, WEI Y, HAMADI Y. SWIM: synthesizing what I mean: code search and idiomatic snippet synconfproc[C]// Proceedings of the 38th International Conference on Software Engineering, Austin, May 14-22, 2016. New York: ACM, 2016: 357-367. |
| [10] | LV F, ZHANG H Y, LOU J G, et al. CodeHow: effective code search based on API understanding and extended Boolean model (E)[C]// Proceedings of the 30th IEEE/ACM International Conference on Automated Software Engineering, Lincoln, Nov 9-13, 2015. Washington: IEEE Computer Society, 2015: 260-270. |
| [11] | SACHDEV S, LI H Y, LUAN S F, et al. Retrieval on source code: a neural code search[C]// Proceedings of the 2nd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, Philadelphia, Jun 18-22, 2018. New York: ACM, 2018: 31-41. |
| [12] | CAMBRONERO J, LI H Y, KIM S, et al. When deep learning met code search[C]// Proceedings of the 2019 ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Tallinn, Aug 26-30, 2019. New York: ACM, 2019: 964-974. |
| [13] | HUSAIN H, WU H H. How to create natural language semantic search for arbitrary objects with deep learning[EB/OL]. (2018-05-29)[2020-07-16]. https://medium.com/@hamelhusain. |
| [14] | GU X D, ZHANG H Y, KIM S. Deep code search[C]// Proceedings of the 40th International Conference on Software Engineering, Gothenburg, May 27-Jun 3, 2018. New York: ACM, 2018: 933-944. |
| [15] | YAO Z Y, PEDDAMAIL J R, SUN H. CoaCor: code annotation for code retrieval with reinforcement learning[C]// Proceedings of the 2019 World Wide Web Conference, San Francisco, May 13-17, 2019. New York: ACM, 2019: 2203-2214. |
| [1] | YANG Zhiqiao, ZHANG Ying, WANG Xinjie, ZHANG Dongbo, WANG Yu. Application Research of Improved U-shaped Network in Detection of Retinopathy [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(8): 1877-1884. |
| [2] | TIAN Xuan, CHEN Hangxue. Survey on Applications of Knowledge Graph Embedding in Recommendation Tasks [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(8): 1681-1705. |
| [3] | HAN Yi, QIAO Linbo, LI Dongsheng, LIAO Xiangke. Review of Knowledge-Enhanced Pre-trained Language Models [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(7): 1439-1461. |
| [4] | XIA Hongbin, XIAO Yifei, LIU Yuan. Long Text Generation Adversarial Network Model with Self-Attention Mechanism [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(7): 1603-1610. |
| [5] | LI Yunhuan, WEN Jiwei, PENG Li. High Frame Rate Light-Weight Siamese Network Target Tracking [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(6): 1405-1416. |
| [6] | ZHANG Yancao, ZHAO Yuhai, SHI Lan. Multi-feature Based Link Prediction Algorithm Fusing Graph Attention [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(5): 1096-1106. |
| [7] | ZHAO Pengfei, XIE Linbo, PENG Li. Deep Small Object Detection Algorithm Integrating Attention Mechanism [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(4): 927-937. |
| [8] | LU Zhongda, ZHANG Chunda, ZHANG Jiaqi, WANG Zifei, XU Junhua. Identification of Apple Leaf Disease Based on Dual Branch Network [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(4): 917-926. |
| [9] | CHEN Gongchi, RONG Huan, MA Tinghuai. Abstractive Text Summarization Model with Coherence Reinforcement and No Ground Truth Dependency [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(3): 621-636. |
| [10] | WANG Yanni, YU Lixian. SSD Object Detection Algorithm with Effective Fusion of Attention and Multi-scale [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(2): 438-447. |
| [11] | YUAN Lining, LI Xin, WANG Xiaodong, LIU Zhao. Graph Embedding Models: A Survey [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(1): 59-87. |
| [12] | JIANG Guangfeng, HU Pengcheng, YE Hua, YANG Yanlan. Isomorphic Graph Classification Model Based on Reconstruction Error [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(1): 185-193. |
| [13] | CAI Mingxin, SUN Jing, WANG Bin. Multi-aspect Semantic Trajectory Similarity Computation Model [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(9): 1632-1640. |
| [14] | CHEN Junfen, ZHANG Ming, ZHAO Jiacheng, XIE Bojun, LI Yan. Deep Clustering Algorithm Based on Denoising and Self-Attention [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(9): 1717-1727. |
| [15] | CHEN Deguang, MA Jinlin, MA Ziping, ZHOU Jie. Review of Pre-training Techniques for Natural Language Processing [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(8): 1359-1389. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
/D:/magtech/JO/Jwk3_kxyts/WEB-INF/classes/