
Journal of Frontiers of Computer Science and Technology ›› 2022, Vol. 16 ›› Issue (5): 959-971.DOI: 10.3778/j.issn.1673-9418.2110036
• Surveys and Frontiers • Previous Articles Next Articles
TONG Gan, HUANG Libo( )
)
Received:2021-10-18
Revised:2022-01-05
Online:2022-05-01
Published:2022-05-19
About author:TONG Gan, born in 1995, M.S. candidate, asso-ciate engineer. His research interest is CNN acceleration for computer architecture.Supported by:
童敢, 黄立波()
通讯作者:
+ E-mail: libohuang@nudt.edu.cn作者简介:童敢(1995—),男,安徽宣城人,硕士研究生,助理工程师,主要研究方向为面向计算机体系结构的CNN加速。基金资助:CLC Number:
TONG Gan, HUANG Libo. Review of Winograd Fast Convolution Technique Research[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(5): 959-971.
童敢, 黄立波. Winograd快速卷积相关研究综述[J]. 计算机科学与探索, 2022, 16(5): 959-971.
Add to citation manager EndNote|Ris|BibTeX
URL: http://fcst.ceaj.org/EN/10.3778/j.issn.1673-9418.2110036
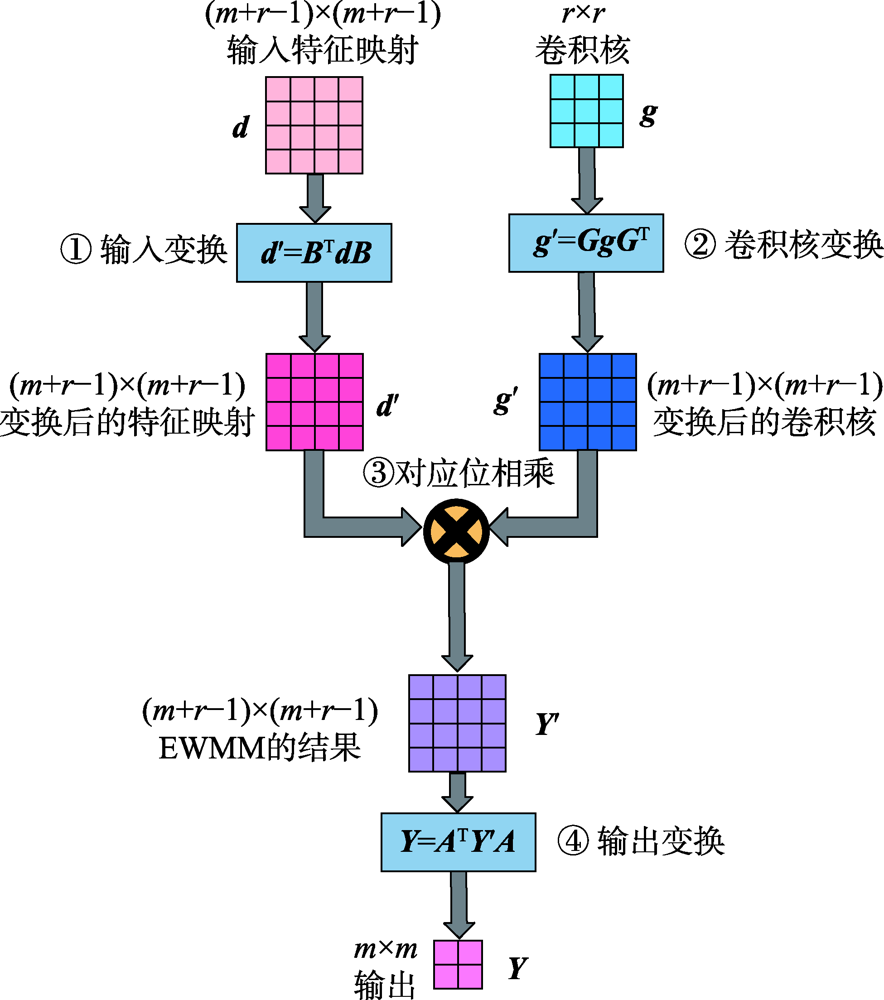
Fig.1 Four stages of Winograd convolution
| 文献 | 嵌套方法 | 分解方法 | 其他方法 | 维度 | 大切片 | 大卷积核 | 跨步卷积 | 空洞卷积 | 转置卷积 | 备注 |
|---|---|---|---|---|---|---|---|---|---|---|
| [ | — | — | — | 一/二维 | — | — | — | — | — | 引入Winograd卷积 |
| [ | √ | — | — | | — | — | — | — | — | 仅实现了CPU上的二维 |
| [ | √ | — | — | 三维 | — | — | — | — | — | FPGA实现 |
| [ | √ | — | — | 三维 | — | — | — | — | — | GPU实现 |
| [ | √ | — | — | | √ | √ | — | — | — | 覆盖了CPU上各类常规卷积 |
| [ | √ | — | — | 三维 | — | — | — | — | — | 在FPGA上实现了动作识别 |
| [ | — | √ | — | 三维 | — | — | — | — | — | 向量DSP上的实现 |
| [ | √ | — | — | 二/三维 | — | — | — | — | — | 统一了FPGA上的多维实现 |
| [ | — | √ | — | 二/三维 | — | √ | √ | — | — | 可变分解方法 |
| [ | — | — | — | 二维 | √ | √ | — | — | — | 在FPGA上进行了全面评估 |
| [ | — | — | — | 二维 | √ | — | — | — | — | FPGA上大切片的精度测试 |
| [ | — | √ | √ | 二维 | √ | √ | — | — | — | 基于符号编程兼容各种硬件 |
| [ | — | √ | — | 二维 | — | √ | √ | — | — | 支持depth-wise和分组卷积 |
| [ | √ | √ | — | 二维 | √ | √ | √ | — | — | FPGA实现,分解为 |
| [ | — | √ | — | 二维 | — | √ | — | — | — | 在FPGA上实现了不同尺寸卷积核的Winograd模块 |
| [ | √ | √ | — | 一/二/三维 | — | √ | √ | — | — | FPGA和GPU上均有实现 |
| [ | — | √ | — | 二维 | — | √ | √ | — | — | GPU实现,形式化了分解方法 |
| [ | — | √ | — | 二维 | √ | √ | √ | — | — | FPGA实现,分解为 |
| [ | — | √ | — | 二维 | — | √ | √ | — | — | 支持步幅为2或3的卷积 |
| [ | — | √ | — | 二维 | — | √ | — | — | — | 可变分解方法 |
| [ | — | — | √ | 二维 | — | √ | — | — | — | 利用近似计算将 |
| [ | — | — | √ | 二维 | — | — | √ | √ | — | 方法为拓展 |
| [ | — | √ | — | 二维 | — | √ | √ | — | √ | 在FPGA上实现了实时超分 |
Table 1 Generalization of Winograd convolution
| 文献 | 嵌套方法 | 分解方法 | 其他方法 | 维度 | 大切片 | 大卷积核 | 跨步卷积 | 空洞卷积 | 转置卷积 | 备注 |
|---|---|---|---|---|---|---|---|---|---|---|
| [ | — | — | — | 一/二维 | — | — | — | — | — | 引入Winograd卷积 |
| [ | √ | — | — | | — | — | — | — | — | 仅实现了CPU上的二维 |
| [ | √ | — | — | 三维 | — | — | — | — | — | FPGA实现 |
| [ | √ | — | — | 三维 | — | — | — | — | — | GPU实现 |
| [ | √ | — | — | | √ | √ | — | — | — | 覆盖了CPU上各类常规卷积 |
| [ | √ | — | — | 三维 | — | — | — | — | — | 在FPGA上实现了动作识别 |
| [ | — | √ | — | 三维 | — | — | — | — | — | 向量DSP上的实现 |
| [ | √ | — | — | 二/三维 | — | — | — | — | — | 统一了FPGA上的多维实现 |
| [ | — | √ | — | 二/三维 | — | √ | √ | — | — | 可变分解方法 |
| [ | — | — | — | 二维 | √ | √ | — | — | — | 在FPGA上进行了全面评估 |
| [ | — | — | — | 二维 | √ | — | — | — | — | FPGA上大切片的精度测试 |
| [ | — | √ | √ | 二维 | √ | √ | — | — | — | 基于符号编程兼容各种硬件 |
| [ | — | √ | — | 二维 | — | √ | √ | — | — | 支持depth-wise和分组卷积 |
| [ | √ | √ | — | 二维 | √ | √ | √ | — | — | FPGA实现,分解为 |
| [ | — | √ | — | 二维 | — | √ | — | — | — | 在FPGA上实现了不同尺寸卷积核的Winograd模块 |
| [ | √ | √ | — | 一/二/三维 | — | √ | √ | — | — | FPGA和GPU上均有实现 |
| [ | — | √ | — | 二维 | — | √ | √ | — | — | GPU实现,形式化了分解方法 |
| [ | — | √ | — | 二维 | √ | √ | √ | — | — | FPGA实现,分解为 |
| [ | — | √ | — | 二维 | — | √ | √ | — | — | 支持步幅为2或3的卷积 |
| [ | — | √ | — | 二维 | — | √ | — | — | — | 可变分解方法 |
| [ | — | — | √ | 二维 | — | √ | — | — | — | 利用近似计算将 |
| [ | — | — | √ | 二维 | — | — | √ | √ | — | 方法为拓展 |
| [ | — | √ | — | 二维 | — | √ | √ | — | √ | 在FPGA上实现了实时超分 |

Fig.2 Pruning by applying ReLU in Winograd convolution
| 文献 | 方法 | 优点 | 缺点 |
|---|---|---|---|
| [ | 在卷积核变换后引入剪枝 | 取代了特征向量空间的剪枝,变换不会恢复稠密 | 需要在Winograd域重新训练 |
| [ | 把ReLU层置于输入变换后 | 赋予了特征向量稀疏性,和卷积核的剪枝结合加强了EWMM阶段的稀疏性 | 对网络结构进行了重构 |
| [ | 在输入变换前结构化剪枝 | 将特征向量空间的稀疏性转移到了Winograd域 | 在特征向量空间和Winograd域都需要重新训练 |
Table 2 Pruning in Winograd convolution
| 文献 | 方法 | 优点 | 缺点 |
|---|---|---|---|
| [ | 在卷积核变换后引入剪枝 | 取代了特征向量空间的剪枝,变换不会恢复稠密 | 需要在Winograd域重新训练 |
| [ | 把ReLU层置于输入变换后 | 赋予了特征向量稀疏性,和卷积核的剪枝结合加强了EWMM阶段的稀疏性 | 对网络结构进行了重构 |
| [ | 在输入变换前结构化剪枝 | 将特征向量空间的稀疏性转移到了Winograd域 | 在特征向量空间和Winograd域都需要重新训练 |
| 方法 | 适用场合 |
|---|---|
| 重新训练 | 不限 |
| 调整量化级别 | 量化操作的参数可调整 |
| 修改Winograd变换 | 新的变换直接变换到量化空间 |
Table 3 Methods to alleviate accuracy loss of quantization in Winograd convolution
| 方法 | 适用场合 |
|---|---|
| 重新训练 | 不限 |
| 调整量化级别 | 量化操作的参数可调整 |
| 修改Winograd变换 | 新的变换直接变换到量化空间 |

Fig.3 Platform distribution of Winograd convolution implementation
| 优化方法 | CPU | GPU | FPGA |
|---|---|---|---|
| 调用计算库 | √ | √ | — |
| 利用向量化指令 | √ | √ | — |
| 数据重用 | √ | √ | √ |
| 自定义数据布局 | √ | √ | √ |
| 自定义计算模块 | — | — | √ |
| 软流水 | √ | √ | — |
| 硬流水 | — | — | √ |
| 算法自适应 | √ | √ | √ |
Table 4 Performance optimization methods on different platforms
| 优化方法 | CPU | GPU | FPGA |
|---|---|---|---|
| 调用计算库 | √ | √ | — |
| 利用向量化指令 | √ | √ | — |
| 数据重用 | √ | √ | √ |
| 自定义数据布局 | √ | √ | √ |
| 自定义计算模块 | — | — | √ |
| 软流水 | √ | √ | — |
| 硬流水 | — | — | √ |
| 算法自适应 | √ | √ | √ |
| [1] | MATHIEU M, HENAFF M, LECUN Y. Fast training of convolutional networks through FFTs[C]// Proceedings of the 2014 International Conference on Learning Representa-tions, Banff, Apr 14-16, 2014: 1-9. |
| [2] | LAVIN A, GRAY S. Fast algorithms for convolutional neu-ral networks[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 4013-4021. |
| [3] | VINCENT K, STEPHANO K, FRUMKIN M, et al. On improving the numerical stability of Winograd convolutions[C]// Proceedings of the 5th International Conference on Learning Representations, Toulon, Apr 24-26, 2017: 1-4. |
| [4] | PERKINS H. Cltorch: a hardware-agnostic backend for the torch deep neural network library, based on OpenCL[J]. arXiv:1606.04884, 2016. |
| [5] | LIU X, TURAKHIA Y. Pruning of Winograd and FFT based convolution algorithm: CS231n-117[R/OL]. California: Stan-ford University, 2016. http://cs231n.stanford.edu/reports/2016/pdfs/117_Report.pdf. |
| [6] | WINOGRAD S. Arithmetic complexity of computations[M]. Philadelphia: SIAM, 1980. |
| [7] | BUDDEN D, MATVEEV A, SANTURKAR S, et al. Deep tensor convolution on multicores[C]// Proceedings of the 34th International Conference on Machine Learning, Sydney, Aug 6-11, 2017: 615-624. |
| [8] | LAN Q, WANG Z, WEN M, et al. High-performance im-plementation of 3D convolutional neural networks on a GPU[J]. Computational Intelligence and Neuroscience, 2017: 8348671. |
| [9] | WANG Z, LAN Q, HE H, et al. Winograd algorithm for 3D convolution neural networks[C]// LNCS 10614:Proceedings of the 26th International Conference on Artificial Neural Networks, Algher, Sep 11-14, 2017. Cham: Springer, 2017: 609-616. |
| [10] | JIA Z, ZLATESKI A, DURAND F, et al. Optimizing N-dimensional, Winograd-based convolution for manycore CPUs[C]// Proceedings of the 23rd ACM SIGPLAN Sym-posium on Principles and Practice of Parallel Programming,Vienna, Feb 24-28, 2018. New York: ACM, 2018: 109-123. |
| [11] | LOU M, LI J, WANG G, et al. AR-C3D: action recognition accelerator for human-computer interaction on FPGA[C]// Proceedings of the 2019 IEEE International Symposium on Circuits and Systems,Sapporo, May 26-29, 2019. Piscata-way: IEEE, 2019: 1-4. |
| [12] | CHEN W, WANG Y, YANG C, et al. Hardware acceleration implementation of three-dimensional convolutional neural network on vector digital signal processors[C]// Proceedings of the 2020 4th International Conference on Robotics and Automation Sciences, Wuhan, Jun 12-14, 2020. Piscataway:IEEE, 2020: 122-129. |
| [13] | SHEN J, HUANG Y, WANG Z, et al. Towards a uniform template-based architecture for accelerating 2D and 3D CNNs on FPGA[C]// Proceedings of the 2018 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, Feb 25-27, 2018. New York: ACM, 2018: 97-106. |
| [14] | SHEN J, HUANG Y, WEN M, et al. Toward an efficient deep pipelined template-based architecture for accelerating the entire 2-D and 3-D CNNs on FPGA[J]. IEEE Transac-tions on Computer-Aided Design of Integrated Circuits and Systems, 2019, 39(7): 1442-1455. |
| [15] | DENG H, WANG J, YE H, et al. 3D-VNPU: a flexible acce-lerator for 2D/3D CNNs on FPGA[C]// Proceedings of the 29th IEEE Annual International Symposium on Field-Programmable Custom Computing Machines, Orlando, May 9-12, 2021. Piscataway: IEEE, 2021: 181-185. |
| [16] | LU L, LIANG Y, XIAO Q, et al. Evaluating fast algorithms for convolutional neural networks on FPGAs[C]// Procee-dings of the 25th IEEE Annual International Symposium on Field-Programmable Custom Computing Machines, Napa, Apr 30-May 2, 2017. Washington: IEEE Computer Society, 2017: 101-108. |
| [17] | HUANG Y, SHEN J, WANG Z, et al. A high-efficiency FPGA-based accelerator for convolutional neural networks using Winograd algorithm[J]. Journal of Physics: Confe-rence Series, 2018, 1026(1): 012019. |
| [18] | MAZAHERI A, BERINGER T, MOSKEWICZ M, et al. Accelerating Winograd convolutions using symbolic com-putation and meta-programming[C]// Proceedings of the 15th EuroSys Conference 2020, Heraklion, Apr 27-30, 2020. New York: ACM, 2020: 1-14. |
| [19] |
YANG C, WANG Y, WANG X, et al. WRA: a 2.2-to-6.3 TOPS highly unified dynamically reconfigurable accelerator using a novel Winograd decomposition algorithm for convol-utional neural networks[J]. IEEE Transactions on Circuits and Systems I: Regular Papers, 2019, 66(9): 3480-3493.
DOI URL |
| [20] | JIANG J, CHEN X, TSUI C Y. A reconfigurable Winograd CNN accelerator with nesting decomposition algorithm for computing convolution with large filters[J]. arXiv:2102.13272, 2021. |
| [21] | CARIOW A, CARIOWA G. Minimal filtering algorithms for convolutional neural networks[M]//Reliability Engineering and Computational Intelligence. Berlin, Heidelberg: Springer, 2021. |
| [22] |
YEPEZ J, KO S B. Stride 2 1-D, 2-D, and 3-D Winograd for convolutional neural networks[J]. IEEE Transactions on Very Large-Scale Integration Systems, 2020, 28(4): 853-863.
DOI URL |
| [23] | HUANG D, ZHANG X, ZHANG R, et al. DWM: a decom-posable Winograd method for convolution acceleration[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence, the 32nd Innovative Applications of Artificial Intelligence Conference, the 10th AAAI Symposium on Educational Advances in Artificial Intelligence, New York, Feb 7-12, 2020. Menlo Park: AAAI, 2020: 4174-4181. |
| [24] |
YANG C, WANG Y, WANG X, et al. A stride-based convo-lution decomposition method to stretch CNN acceleration algorithms for efficient and flexible hardware implemen-tation[J]. IEEE Transactions on Circuits and Systems I: Regular Papers, 2020, 67(9): 3007-3020.
DOI URL |
| [25] |
XU W, ZHANG Z, YOU X, et al. Reconfigurable and low-complexity accelerator for convolutional and generative net-works over finite fields[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2020, 39(12): 4894-4907.
DOI URL |
| [26] | SHI F, LI H, GAO Y, et al. Sparse Winograd convolutional neural networks on small-scale systolic arrays[J]. arXiv:1810.01973, 2018. |
| [27] | PAN J, CHEN D. Accelerate non-unit stride convolutions with Winograd algorithms[C]// Proceedings of the 26th Asia and South Pacific Design Automation Conference, Tokyo, Jan 18-21, 2021. New York: ACM, 2021: 358-364. |
| [28] | LENTARIS G, CHATZITSOMPANIS G, LEON V, et al. Combining arithmetic approximation techniques for im-proved CNN circuit design[C]// Proceedings of the 27th IEEE International Conference on Electronics, Circuits and Syst-ems, Glasgow, Nov 23-25, 2020. Piscataway: IEEE, 2020: 1-4. |
| [29] | LIU X, CHEN Y, HAO C, et al. WinoCNN: kernel sharing Winograd systolic array for efficient convolutional neural network acceleration on FPGAs[C]// Proceedings of the 32nd IEEE International Conference on Application-Specific Systems, Architectures and Processors, Jul 7-9, 2021. Pisca-taway: IEEE, 2021: 258-265. |
| [30] |
SABIR D, HANIF M A, HASSAN A, et al. TiQSA: work-load minimization in convolutional neural networks using tile quantization and symmetry approximation[J]. IEEE Access, 2021, 9: 53647-53668.
DOI URL |
| [31] | KIM M, PARK C, KIM S, et al. Efficient dilated-Winograd convolutional neural networks[C]// Proceedings of the 2019 IEEE International Conference on Image Processing, Taipei, China, Sep 22-25, 2019. Piscataway: IEEE, 2019: 2711-2715. |
| [32] | SHI B, TANG Z, LUO G, et al. Winograd-based real-time super-resolution system on FPGA[C]// Proceedings of the 2019 International Conference on Field-Programmable Technology, Tianjin, Dec 9-13, 2019. Piscataway: IEEE, 2019: 423-426. |
| [33] | BARABASZ B, GREGG D. Winograd convolution for DNNs: beyond linear polynomials[C]// LNCS 11946: Proceedings of the XVIIIth International Conference of the Italian Association for Artificial Intelligence, Rende, Nov 19-22, 2019. Cham: Springer, 2019: 307-320. |
| [34] |
JU C, SOLOMONIK E. Derivation and analysis of fast bili-near algorithms for convolution[J]. SIAM Review, 2020, 62(4): 743-777.
DOI URL |
| [35] | MENG L, BROTHERS J. Efficient Winograd convolution via integer arithmetic[J]. arXiv:1901.01965, 2019. |
| [36] | LIU Z G, MATTINA M. Efficient residue number system based Winograd convolution[C]// LNCS 12364: Proceedings of the 16th European Conference on Computer Vision, Glasgow, Aug 23-28, 2020. Cham: Springer, 2020: 53-68. |
| [37] |
ZHAO Y, WANG D, WANG L. Convolution accelerator designs using fast algorithms[J]. Algorithms, 2019, 12(5): 112.
DOI URL |
| [38] | STRASSEN V. Gaussian elimination is not optimal[J]. Nume-rische Mathematik, 1969, 13(4): 354-356. |
| [39] | LI W, CHEN H, HUANG M, et al. Winograd algorithm for Adder-Net[J]. arXiv:2105.05530, 2021. |
| [40] | LIU X, POOL J, HAN S, et al. Efficient sparse-Winograd convolutional neural networks[J]. arXiv:1802.06367, 2018. |
| [41] | WANG H, LIU W, XU T, et al. A low-latency sparse-Winograd accelerator for convolutional neural networks[C]// Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing, Brighton, May 12-17, 2019. Piscataway: IEEE, 2019: 1448-1452. |
| [42] | LI S, PARK J, TANG P T P. Enabling sparse Winograd convolution by native pruning[J]. arXiv:1702.08597, 2017. |
| [43] | LU L, LIANG Y. SpWA: an efficient sparse Winograd convolutional neural networks accelerator on FPGAs[C]// Proceedings of the 55th Annual Design Automation Con-ference, San Francisco, Jun 24-29, 2018. New York: ACM, 2018: 1-6. |
| [44] | YU J, PARK J, NAUMOV M. Spatial-Winograd pruning ena-bling sparse Winograd convolution[J]. arXiv:1901.02132, 2019. |
| [45] | ZHENG S, WANG L, GUPTA G. Efficient ensemble sparse convolutional neural networks with dynamic batch size[C]// Proceedings of the 5th International Conference on Com-puter Vision and Image Processing,Prayagraj, Dec 4-6, 2020. Cham: Springer, 2020: 262-277. |
| [46] | PARK H, KIM D, AHN J, et al. Zero and data reuse-aware fast convolution for deep neural networks on GPU[C]// Proceedings of the 11th IEEE/ACM/IFIP International Con-ference on Hardware/Software Codesign and System Syn-thesis, Pittsburgh, Oct 1-7, 2016. New York: ACM, 2016: 1-10. |
| [47] | CHOI Y, EL-KHAMY M, LEE J. Jointly sparse convolu-tional neural networks in dual spatial-Winograd domains[C]// Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing, Brighton, May 12-17, 2019. Piscataway: IEEE, 2019: 2792-2796. |
| [48] | YANG T, LIAO Y, SHI J, et al. A Winograd-based CNN accelerator with a fine-grained regular sparsity pattern[C]// Proceedings of the 30th International Conference on Field-Programmable Logic and Applications, Gothenburg, Aug 31-Sep 4, 2020. Piscataway: IEEE, 2020: 254-261. |
| [49] |
WANG X, WANG C, CAO J, et al. WinoNN: optimizing FPGA-based convolutional neural network accelerators using sparse Winograd algorithm[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2020, 39(11): 4290-4302.
DOI URL |
| [50] | ZHUGE C, LIU X, ZHANG X, et al. Face recognition with hybrid efficient convolution algorithms on FPGAs[C]// Pro-ceedings of the 2018 on Great Lakes Symposium on VLSI, Chicago, May 23-25, 2018. New York: ACM, 2018: 123-128. |
| [51] | ZHANG W, LIAO X, JIN H. Fine-grained scheduling in FPGA-based convolutional neural networks[C]// Proceedings of the 2020 IEEE 5th International Conference on Cloud Compu-ting and Big Data Analytics, Chengdu, Apr 10-13, 2020. Pis-cataway: IEEE, 2020: 120-128. |
| [52] | YE H, ZHANG X, HUANG Z, et al. HybridDNN: a frame-work for high-performance hybrid DNN accelerator design and implementation[C]// Proceedings of the 2020 57th ACM/ IEEE Design Automation Conference, San Francisco, Jul 20-24, 2020. Piscataway: IEEE, 2020: 1-6. |
| [53] | GHAFFAR M M, SUDARSHAN C, WEIS C, et al. A low power in-dram architecture for quantized CNNs using fast Wino-grad convolutions[C]// Proceedings of the 2020 Internatio-nal Symposium on Memory Systems, Washington, Sep 28-Oct 1, 2020. New York: ACM: 158-168. |
| [54] | YAO Y, LI Y, WANG C, et al. INT8 Winograd acceleration for Conv1D equipped ASR models deployed on mobile de-vices[J]. arXiv:2010.14841, 2020. |
| [55] | CAO Y, SONG C, TANG Y. Efficient LUT-based FPGA accelerator design for universal quantized CNN inference[C]// Proceedings of the 2nd Asia Service Sciences and Software Engineering Conference, Macau, China, Feb 24-26, 2021. New York: ACM, 2021: 108-115. |
| [56] | WU D, FAN X, CAO W, et al. SWM: a high-performance sparse-Winograd matrix multiplication CNN accelerator[J]. IEEE Transactions on Very Large Scale Integration Sys-tems, 2021, 29(5): 936-949. |
| [57] | HAN Q, HU Y, YU F, et al. Extremely low-bit convolution optimization for quantized neural network on modern computer architectures[C]// Proceedings of the 49th Interna-tional Conference on Parallel Processing, Edmonton,Aug 17-20, 2020. New York: ACM, 2020: 1-12. |
| [58] | LI G, LIU L, WANG X, et al. Searching for Winograd-aware quantized networks[J]. arXiv:2002.10711, 2020. |
| [59] | FERNANDEZ-MARQUES J, WHATMOUGH P N, MUNDY A, et al. Searching for Winograd-aware quantized networks[C]// Proceedings of Machine Learning and Systems 2020, Austin, Mar 2-4, 2020: 16. |
| [60] | AHMAD A, PASHA M A. FFConv: an FPGA-based acce-lerator for fast convolution layers in convolutional neural networks[J]. ACM Transactions on Embedded Computing Systems, 2020, 19(2): 1-24. |
| [61] | BARABASZ B. Quantized Winograd/Toom-cook convolu-tion for DNNs: beyond canonical polynomials base[J]. arXiv:2004.11077, 2020. |
| [62] | BARABASZ B, ANDERSON A, SOODHALTER K M, et al. Error analysis and improving the accuracy of Winograd convolution for deep neural networks[J]. ACM Transac-tions on Mathematical Software, 2020, 46(4): 1-33. |
| [63] | MAJI P, MUNDY A, DASIKA G, et al. Efficient Winograd or Cook-Toom convolution kernel implementation on widely used mobile CPUs[C]// Proceedings of the 2019 2nd Work-shop on Energy Efficient Machine Learning and Cognitive Computing for Embedded Applications, Washington, Feb 17, 2019. Piscataway: IEEE, 2019: 1-5. |
| [64] |
LAN H, MENG J, HUNDT C, et al. FeatherCNN: fast inference computation with TensorGEMM on ARM archi-tectures[J]. IEEE Transactions on Parallel and Distributed Systems, 2019, 31(3): 580-594.
DOI URL |
| [65] | XYGKIS A, PAPADOPOULOS L, MOLONEY D, et al. Efficient Winograd-based convolution kernel implementation on edge devices[C]// Proceedings of the 55th Annual Design Automation Conference, San Francisco, Jun 24-29, 2018. New York: ACM, 2018: 1-6. |
| [66] |
MAHALE G, UDUPA P, CHANDRASEKHARAN K K, et al. WinDConv: a fused datapath CNN accelerator for power-efficient edge devices[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2020, 39(11): 4278-4289.
DOI URL |
| [67] | JEON H, LEE K, HAN S, et al. The parallelization of convolution on a CNN using a SIMT based GPGPU[C]// Proceedings of the 2016 International SoC Design Confe-rence, Jeju, Oct 23-26, 2016. Piscataway: IEEE, 2016: 333-334. |
| [68] | XIAO Q, LIANG Y, LU L, et al. Exploring heterogeneous algorithms for accelerating deep convolutional neural networks on FPGAs[C]// Proceedings of the 54th Annual Design Automation Conference, Austin, Jun 18-22, 2017. New York: ACM, 2017: 1-6. |
| [69] | DICECCO R, LACEY G, VASILJEVIC J, et al. Caffeinated FPGAs: FPGA framework for convolutional neural networks[C]// Proceedings of the 2016 International Conference on Field-Programmable Technology, Xi’an, Dec 7-9, 2016. Pis-cataway: IEEE, 2016: 265-268. |
| [70] | DEMIDOVSKIJ A, GORBACHEV Y, FEDOROV M, et al. OpenVINO deep learning workbench: comprehensive analysis and tuning of neural networks inference[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop, Seoul, Oct 27-28, 2019. Piscataway: IEEE, 2019: 783-787. |
| [71] | LIN J, LI S, HU X, et al. CNNWIRE: boosting convolu-tional neural network with Winograd on ReRAM based accelerators[C]// Proceedings of the 2019 on Great Lakes Symposium on VLSI, Tysons Corner, May 9-11, 2019. New York: ACM, 2019: 283-286. |
| [72] | WANG H, ZHANG Z, YOU X, et al. Low-complexity Wino-grad convolution architecture based on stochastic compu-ting[C]// Proceedings of the 23rd IEEE International Con-ference on Digital Signal Processing, Shanghai, Nov 19-21, 2018. Piscataway: IEEE, 2018: 1-5. |
| [73] |
GONG Y, LIU B, GE W, et al. ARA: cross-layer approxi-mate computing framework based reconfigurable architecture for CNNs[J]. Microelectronics Journal, 2019, 87: 33-44.
DOI URL |
| [74] | WANG S, ZHU J, WANG Q, et al. Customized instruction on RISC-V for Winograd-based convolution acceleration[C]// Proceedings of the 32nd IEEE International Conf-erence on Application-Specific Systems, Architectures and Processors, Jul 7-9, 2021. Piscataway: IEEE, 2021: 65-68. |
| [75] | HEINECKE A, GEORGANAS E, BANERJEE K, et al. Understanding the performance of small convolution opera-tions for CNN on Intel architecture[C]// Proceedings of ACM SC17 Conference. New York: ACM, 2017: 1-2. |
| [76] | RAGATE S N. Optimization of spatial convolution in Conv-Nets on Intel KNL[D]. Knoxiville: University of Tennessee, 2017. |
| [77] | GELASHVILI R, SHAVIT N, ZLATESKI A. L3 fusion: fast transformed convolutions on CPUs[J]. arXiv:1912.02165, 2019. |
| [78] | WU R, ZHANG F, ZHENG Z, et al. Exploring deep reuse in Winograd CNN inference[C]// Proceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, Feb 27-Mar 3, 2021. New York: ACM, 2021: 483-484. |
| [79] | HONG B, RO Y, KIM J. Multi-dimensional parallel trai-ning of Winograd layer on memory-centric architecture[C]// Proceedings of the 51st Annual IEEE/ACM International Symposium on Microarchitecture, Fukuoka, Oct 20-24, 2018. Washington: IEEE Computer Society, 2018: 682-695. |
| [80] | JIA L, LIANG Y, LI X, et al. Enabling efficient fast convo-lution algorithms on GPUs via MegaKernels[J]. IEEE Tran-sactions on Computers, 2020, 69(7): 986-997. |
| [81] | YAN D, WANG W, CHU X. Optimizing batched Winograd convolution on GPUs[C]// Proceedings of the 25th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, San Diego, Feb 22-26, 2020. New York: ACM, 2020: 32-44. |
| [82] | CARIOW A, CARIOWA G. Hardware-efficient structure of the accelerating module for implementation of convolu-tional neural network basic operation[J]. arXiv:1811.03458, 2018. |
| [83] | AYDONAT U, O’CONNELL S, CAPALIJA D, et al. An OpenCLTM deep learning accelerator on Arria 10[C]// Pro-ceedings of the 2017 ACM/SIGDA International Sympo-sium on Field-Programmable Gate Arrays, Monterey, Feb 22-24, 2017. New York: ACM, 2017: 55-64. |
| [84] | KALA S, MATHEW J, JOSE B R, et al. UniWiG: unified Winograd-GEMM architecture for accelerating CNN on FPGAs[C]// Proceedings of the 32nd International Confe-rence on VLSI Design and 18th International Conference on Embedded Systems, Delhi, Jan 5-9, 2019. Piscataway: IEEE, 2019: 209-214. |
| [85] | KALA S, JOSE B R, MATHEW J, et al. High-performance CNN accelerator on FPGA using unified Winograd-GEMM architecture[J]. IEEE Transactions on Very Large Scale Inte-gration Systems, 2019, 27(12): 2816-2828. |
| [86] |
KALA S, NALESH S. Efficient CNN accelerator on FPGA[J]. IETE Journal of Research, 2020, 66(6): 733-740.
DOI URL |
| [87] | AHMAD A, PASHA M A. Towards design space explora-tion and optimization of fast algorithms for convolutional neural networks (CNNs) on FPGAs[C]// Proceedings of the 2019 Design, Automation & Test in Europe Conference & Exhibition, Florence, Mar 25-29, 2019. Piscataway: IEEE, 2019: 1106-1111. |
| [88] | PODILI A, ZHANG C, PRASANNA V. Fast and efficient implementation of convolutional neural networks on FPGA[C]// Proceedings of the 28th IEEE International Conference on Application-Specific Systems, Architectures and Proces-sors, Seattle, Jul 10-12, 2017. Washington: IEEE Computer So-ciety, 2017: 11-18. |
| [89] | VEMPARALA M R, FRICKENSTEIN A, STECHELE W. An efficient FPGA accelerator design for optimized CNNs using OpenCL[C]// Proceedings of the 2019 International Conference on Architecture of Computing Systems. Cham: Springer, 2019: 236-249. |
| [90] | BAI Z, FAN H, LIU L, et al. An OpenCL-based FPGA accelerator with the Winograd’s minimal filtering algorithm for convolution neuron networks[C]// LNCS 11479: Procee-dings of the 32nd International Conference, Copenhagen, May 20-23, 2019. Cham: Springer, 2019: 277-282. |
| [91] | ZLATESKI A, JIA Z, LI K, et al. FFT convolutions are faster than Winograd on modern CPUs, here is why[J]. arXiv:1809.07851, 2018. |
| [92] | ZLATESKI A, JIA Z, LI K, et al. The anatomy of efficient FFT and Winograd convolutions on modern CPUs[C]// Pro-ceedings of the 2019 ACM International Conference on Supercomputing, Phoenix, Jun 26-28, 2019. New York: ACM, 2019: 414-424. |
| [93] | KIM H, NAM H, JUNG W, et al. Performance analysis of CNN frameworks for GPUs[C]// Proceedings of the 2017 IEEE International Symposium on Performance Analysis of Systems and Software, Santa Rosa, Apr 24-25, 2017. Was-hington: IEEE Computer Society, 2017: 55-64. |
| [94] | YEN P W, LIN Y S, CHANG C Y, et al. Real-time super resolution CNN accelerator with constant kernel size Wino-grad convolution[C]// Proceedings of the 2nd IEEE Interna-tional Conference on Artificial Intelligence Circuits and Sys-tems, Genova, Aug 31-Sep 2, 2020. Piscataway: IEEE, 2020: 193-197. |
| [1] | AN Fengping, LI Xiaowei, CAO Xiang. Medical Image Classification Algorithm Based on Weight Initialization-Sliding Window CNN [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(8): 1885-1897. |
| [2] | LU Zhongda, ZHANG Chunda, ZHANG Jiaqi, WANG Zifei, XU Junhua. Identification of Apple Leaf Disease Based on Dual Branch Network [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(4): 917-926. |
| [3] | PEI Lishen, ZHAO Xuezhuan. Survey of Collective Activity Recognition Based on Deep Learning [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(4): 775-790. |
| [4] | LI Zhixin, CHEN Shengjia, ZHOU Tao, MA Huifang. Combining Cascaded Network and Adversarial Network for Object Detection [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(1): 217-230. |
| [5] | ZHANG Mengqian, ZHANG Li. Coarse-to-Fine Two-Stage Convolutional Neural Network Algorithm [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(8): 1501-1510. |
| [6] | FANG Junting, TAN Xiaoyang. Defect Detection of Metal Surface Based on Attention Cascade R-CNN [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(7): 1245-1254. |
| [7] | NENG Wenpeng, LU Jun, ZHAO Caihong. Survey of Sleep Staging Based on Relational Induction Biases [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(6): 1026-1037. |
| [8] | MA Dan, WAN Liang, CHENG Qiqin, SUN Zhiqiang. Research on Application of Attention-CNN in Malware Detection [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(4): 670-681. |
| [9] | ZHANG Li, QIU Cunyue, ZHANG Kaixin, ZHANG Dabo, LUO Hao. Optimized Layered Convolutional Sub-health Recognition Algorithm of Improved Capsule Network [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(4): 712-722. |
| [10] | XIAO Zhenjiu, YANG Xiaodi, WEI Xian, TANG Xiaoliang. Improved Lightweight Network in Image Recognition [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(4): 743-753. |
| [11] | TAN Yaya, KONG Guangqian. Review of Research on Video Quality Assessment Based on Deep Learning [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(3): 423-437. |
| [12] | CHAI Enhui, MA Zhanfei, ZHI Min. Optimized Pedestrian Detection Algorithm for Norm-DP Model [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(3): 545-552. |
| [13] | LIU Huilin, FENG Yue, XU Hong, LUO Jianyi. Survey of Tongue Segmentation in Deep Learning [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(12): 2276-2291. |
| [14] | LI Xingxiu, TANG Jianjun, HUA Jing. Arrhythmia Classification Based on CNN and Bidirectional LSTM [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(12): 2353-2361. |
| [15] | LI Wentao, PENG Li. Small Objects Detection Algorithm with Multi-scale Channel Attention Fusion Network [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(12): 2390-2400. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
/D:/magtech/JO/Jwk3_kxyts/WEB-INF/classes/