
计算机科学与探索 ›› 2022, Vol. 16 ›› Issue (9): 2163-2176.DOI: 10.3778/j.issn.1673-9418.2102021
• 理论与算法 • 上一篇
陈磊, 吴润秀( ), 李沛武, 赵嘉
), 李沛武, 赵嘉
收稿日期:2021-02-05
修回日期:2021-04-02
出版日期:2022-09-01
发布日期:2021-04-19
通讯作者:
+ E-mail: wurunxiu@tom.com作者简介:陈磊(1997—),男,硕士研究生,主要研究方向为数据挖掘。基金资助:
CHEN Lei, WU Runxiu(), LI Peiwu, ZHAO Jia
Received:2021-02-05
Revised:2021-04-02
Online:2022-09-01
Published:2021-04-19
About author:CHEN Lei, born in 1997, M.S. candidate. His research interest is data mining.Supported by:摘要:
密度峰值聚类(DPC)算法是一种基于密度的聚类算法。该算法原理简单、运行高效,可以找到任意非球形类簇。但是该算法存在一些缺陷:首先,该算法局部密度定义的度量准则不统一且两者的聚类结果存在较大差异;其次,该算法的分配策略易产生分配连带错误,即一旦某一个样本分配错误,会导致后续一连串的样本分配错误。为解决这些问题,提出了一种加权$K$近邻和多簇合并的密度峰值聚类算法(WKMM-DPC)。该算法结合加权$K$近邻的思想,引入样本的权重系数,重新定义样本的局部密度,使局部密度更加依赖于K近邻内样本的位置,且统一了密度定义的度量准则;定义了类簇间的相似度,并据此度量准则进行多簇合并,以避免分配剩余样本时的分配连带错误。在人工和UCI数据集上的实验表明,该算法的聚类效果优于FKNN-DPC、DPCSA、FNDPC、DPC和DBSCAN算法。
中图分类号:
陈磊, 吴润秀, 李沛武, 赵嘉. 加权K近邻和多簇合并的密度峰值聚类算法[J]. 计算机科学与探索, 2022, 16(9): 2163-2176.
CHEN Lei, WU Runxiu, LI Peiwu, ZHAO Jia. Weighted K-nearest Neighbors and Multi-cluster Merge Density Peaks Clustering Algorithm[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(9): 2163-2176.

图1 DPC算法对flame数据集的聚类结果 ( d c = 2 )
Fig.1 Clustering result of DPC for flame dataset ( d c = 2 )

图2 DPC算法对Spiral数据集的聚类结果 ( d c = 2 )
Fig.2 Clustering result of DPC for Spiral dataset ( d c = 2 )

图3 Aggregation数据集的真实分布图
Fig.3 True distribution of Aggregation dataset

图4 Aggregation数据集的聚类决策图
Fig.4 Decision gragh of Aggregation dataset
| 数据集 | 数据来源 | 样本规模 | 数据维数 | 类簇个数 |
|---|---|---|---|---|
| Aggregation | [ | 788 | 2 | 7 |
| Flame | [ | 240 | 2 | 2 |
| Jain | [ | 373 | 2 | 2 |
| Pathbased | [ | 300 | 2 | 3 |
| Spiral | [ | 312 | 2 | 3 |
| R15 | [ | 600 | 2 | 15 |
| D31 | [ | 3 100 | 2 | 31 |
| S2 | [ | 5 000 | 2 | 15 |
表1 人工数据集
Table 1 Synthetic datasets
| 数据集 | 数据来源 | 样本规模 | 数据维数 | 类簇个数 |
|---|---|---|---|---|
| Aggregation | [ | 788 | 2 | 7 |
| Flame | [ | 240 | 2 | 2 |
| Jain | [ | 373 | 2 | 2 |
| Pathbased | [ | 300 | 2 | 3 |
| Spiral | [ | 312 | 2 | 3 |
| R15 | [ | 600 | 2 | 15 |
| D31 | [ | 3 100 | 2 | 31 |
| S2 | [ | 5 000 | 2 | 15 |
| 数据集 | 数据来源 | 样本规模 | 数据维数 | 类簇个数 |
|---|---|---|---|---|
| Seeds | [ | 210 | 7 | 3 |
| Libras | [ | 360 | 90 | 15 |
| Iris | [ | 150 | 4 | 3 |
| Wine | [ | 178 | 13 | 3 |
| Ecoli | [ | 336 | 8 | 8 |
| Dermatology | [ | 366 | 33 | 6 |
| Glass | [ | 214 | 9 | 6 |
| Waveform | [ | 2 310 | 19 | 7 |
表2 UCI数据集
Table 2 UCI datasets
| 数据集 | 数据来源 | 样本规模 | 数据维数 | 类簇个数 |
|---|---|---|---|---|
| Seeds | [ | 210 | 7 | 3 |
| Libras | [ | 360 | 90 | 15 |
| Iris | [ | 150 | 4 | 3 |
| Wine | [ | 178 | 13 | 3 |
| Ecoli | [ | 336 | 8 | 8 |
| Dermatology | [ | 366 | 33 | 6 |
| Glass | [ | 214 | 9 | 6 |
| Waveform | [ | 2 310 | 19 | 7 |
| Clustering algorithm | Aggregation | Spiral | ||||||
|---|---|---|---|---|---|---|---|---|
| AMI | ARI | FMI | Arg- | AMI | ARI | FMI | Arg- | |
| WKMM-DPC | 1.000 0 | 1.000 0 | 1.000 0 | 14 | 1.000 0 | 1.000 0 | 1.000 0 | 9 |
| FKNN-DPC | 0.990 5 | 0.994 9 | 0.996 0 | 20 | 1.000 0 | 1.000 0 | 1.000 0 | 6 |
| DPCSA | 0.953 7 | 0.958 1 | 0.967 3 | — | 1.000 0 | 1.000 0 | 1.000 0 | — |
| FNDPC | 0.986 4 | 0.991 3 | 0.993 2 | 0.02 | 1.000 0 | 1.000 0 | 1.000 0 | 0.07 |
| DPC | 0.992 2 | 0.995 6 | 0.996 6 | 4.00 | 1.000 0 | 1.000 0 | 1.000 0 | 1.80 |
| DBSCAN | 0.968 1 | 0.977 9 | 0.982 7 | 0.04/6 | 1.000 0 | 1.000 0 | 1.000 0 | 0.04/2 |
| Clustering algorithm | Flame | R15 | ||||||
| AMI | ARI | FMI | Arg- | AMI | ARI | FMI | Arg- | |
| WKMM-DPC | 1.000 0 | 1.000 0 | 1.000 0 | 18 | 0.994 2 | 0.992 8 | 0.993 2 | 17 |
| FKNN-DPC | 0.926 7 | 0.966 7 | 0.984 5 | 5 | 0.993 8 | 0.992 8 | 0.993 3 | 25 |
| DPCSA | 1.000 0 | 1.000 0 | 1.000 0 | — | 0.988 5 | 0.985 7 | 0.986 6 | — |
| FNDPC | 1.000 0 | 1.000 0 | 1.000 0 | 0.13 | 0.993 8 | 0.992 8 | 0.993 3 | 0.03 |
| DPC | 1.000 0 | 1.000 0 | 1.000 0 | 2.80 | 0.993 8 | 0.992 8 | 0.993 2 | 0.70 |
| DBSCAN | 0.866 5 | 0.938 8 | 0.971 2 | 0.09/8 | 0.983 2 | 0.975 8 | 0.979 9 | 0.04/12 |
| Clustering algorithm | Jain | D31 | ||||||
| AMI | ARI | FMI | Arg- | AMI | ARI | FMI | Arg- | |
| WKMM-DPC | 1.000 0 | 1.000 0 | 1.000 0 | 16 | 0.957 1 | 0.915 9 | 0.919 1 | 36 |
| FKNN-DPC | 0.709 2 | 0.822 4 | 0.935 9 | 43 | 0.965 4 | 0.952 3 | 0.953 8 | 28 |
| DPCSA | 0.216 7 | 0.044 2 | 0.592 4 | — | 0.955 2 | 0.935 3 | 0.937 4 | — |
| FNDPC | 0.596 1 | 0.725 7 | 0.905 1 | 0.47 | 0.955 5 | 0.936 4 | 0.938 5 | 0.04 |
| DPC | 0.618 3 | 0.714 6 | 0.881 9 | 0.90 | 0.955 4 | 0.936 5 | 0.938 5 | 0.60 |
| DBSCAN | 0.928 1 | 0.975 8 | 0.990 6 | 0.08/2 | 0.903 2 | 0.809 5 | 0.816 3 | 0.04/47 |
| Clustering algorithm | Pathbased | S2 | ||||||
| AMI | ARI | FMI | Arg- | AMI | ARI | FMI | Arg- | |
| WKMM-DPC | 0.751 0 | 0.715 0 | 0.811 1 | 18 | 0.944 5 | 0.935 6 | 0.939 9 | 25 |
| FKNN-DPC | 0.930 5 | 0.949 9 | 0.966 5 | 9 | 0.918 0 | 0.888 9 | 0.896 3 | 22 |
| DPCSA | 0.707 3 | 0.613 3 | 0.751 1 | — | 0.933 3 | 0.915 2 | 0.920 9 | — |
| FNDPC | 0.575 1 | 0.506 7 | 0.706 5 | 0.01 | 0.943 1 | 0.935 1 | 0.939 5 | 0.03 |
| DPC | 0.521 2 | 0.471 7 | 0.666 4 | 3.80 | 0.943 7 | 0.935 2 | 0.939 5 | 1.50 |
| DBSCAN | 0.872 1 | 0.901 1 | 0.934 0 | 0.08/10 | 0.878 1 | 0.751 0 | 0.776 7 | 0.04/30 |
表3 6种聚类算法在8个人工数据集上的聚类性能
Table 3 Performance of 6 clustering algorithms on 8 synthetic datasets
| Clustering algorithm | Aggregation | Spiral | ||||||
|---|---|---|---|---|---|---|---|---|
| AMI | ARI | FMI | Arg- | AMI | ARI | FMI | Arg- | |
| WKMM-DPC | 1.000 0 | 1.000 0 | 1.000 0 | 14 | 1.000 0 | 1.000 0 | 1.000 0 | 9 |
| FKNN-DPC | 0.990 5 | 0.994 9 | 0.996 0 | 20 | 1.000 0 | 1.000 0 | 1.000 0 | 6 |
| DPCSA | 0.953 7 | 0.958 1 | 0.967 3 | — | 1.000 0 | 1.000 0 | 1.000 0 | — |
| FNDPC | 0.986 4 | 0.991 3 | 0.993 2 | 0.02 | 1.000 0 | 1.000 0 | 1.000 0 | 0.07 |
| DPC | 0.992 2 | 0.995 6 | 0.996 6 | 4.00 | 1.000 0 | 1.000 0 | 1.000 0 | 1.80 |
| DBSCAN | 0.968 1 | 0.977 9 | 0.982 7 | 0.04/6 | 1.000 0 | 1.000 0 | 1.000 0 | 0.04/2 |
| Clustering algorithm | Flame | R15 | ||||||
| AMI | ARI | FMI | Arg- | AMI | ARI | FMI | Arg- | |
| WKMM-DPC | 1.000 0 | 1.000 0 | 1.000 0 | 18 | 0.994 2 | 0.992 8 | 0.993 2 | 17 |
| FKNN-DPC | 0.926 7 | 0.966 7 | 0.984 5 | 5 | 0.993 8 | 0.992 8 | 0.993 3 | 25 |
| DPCSA | 1.000 0 | 1.000 0 | 1.000 0 | — | 0.988 5 | 0.985 7 | 0.986 6 | — |
| FNDPC | 1.000 0 | 1.000 0 | 1.000 0 | 0.13 | 0.993 8 | 0.992 8 | 0.993 3 | 0.03 |
| DPC | 1.000 0 | 1.000 0 | 1.000 0 | 2.80 | 0.993 8 | 0.992 8 | 0.993 2 | 0.70 |
| DBSCAN | 0.866 5 | 0.938 8 | 0.971 2 | 0.09/8 | 0.983 2 | 0.975 8 | 0.979 9 | 0.04/12 |
| Clustering algorithm | Jain | D31 | ||||||
| AMI | ARI | FMI | Arg- | AMI | ARI | FMI | Arg- | |
| WKMM-DPC | 1.000 0 | 1.000 0 | 1.000 0 | 16 | 0.957 1 | 0.915 9 | 0.919 1 | 36 |
| FKNN-DPC | 0.709 2 | 0.822 4 | 0.935 9 | 43 | 0.965 4 | 0.952 3 | 0.953 8 | 28 |
| DPCSA | 0.216 7 | 0.044 2 | 0.592 4 | — | 0.955 2 | 0.935 3 | 0.937 4 | — |
| FNDPC | 0.596 1 | 0.725 7 | 0.905 1 | 0.47 | 0.955 5 | 0.936 4 | 0.938 5 | 0.04 |
| DPC | 0.618 3 | 0.714 6 | 0.881 9 | 0.90 | 0.955 4 | 0.936 5 | 0.938 5 | 0.60 |
| DBSCAN | 0.928 1 | 0.975 8 | 0.990 6 | 0.08/2 | 0.903 2 | 0.809 5 | 0.816 3 | 0.04/47 |
| Clustering algorithm | Pathbased | S2 | ||||||
| AMI | ARI | FMI | Arg- | AMI | ARI | FMI | Arg- | |
| WKMM-DPC | 0.751 0 | 0.715 0 | 0.811 1 | 18 | 0.944 5 | 0.935 6 | 0.939 9 | 25 |
| FKNN-DPC | 0.930 5 | 0.949 9 | 0.966 5 | 9 | 0.918 0 | 0.888 9 | 0.896 3 | 22 |
| DPCSA | 0.707 3 | 0.613 3 | 0.751 1 | — | 0.933 3 | 0.915 2 | 0.920 9 | — |
| FNDPC | 0.575 1 | 0.506 7 | 0.706 5 | 0.01 | 0.943 1 | 0.935 1 | 0.939 5 | 0.03 |
| DPC | 0.521 2 | 0.471 7 | 0.666 4 | 3.80 | 0.943 7 | 0.935 2 | 0.939 5 | 1.50 |
| DBSCAN | 0.872 1 | 0.901 1 | 0.934 0 | 0.08/10 | 0.878 1 | 0.751 0 | 0.776 7 | 0.04/30 |

图5 6种算法对Aggregation数据集的聚类结果
Fig.5 Clustering results of 6 algorithms on Aggregation dataset
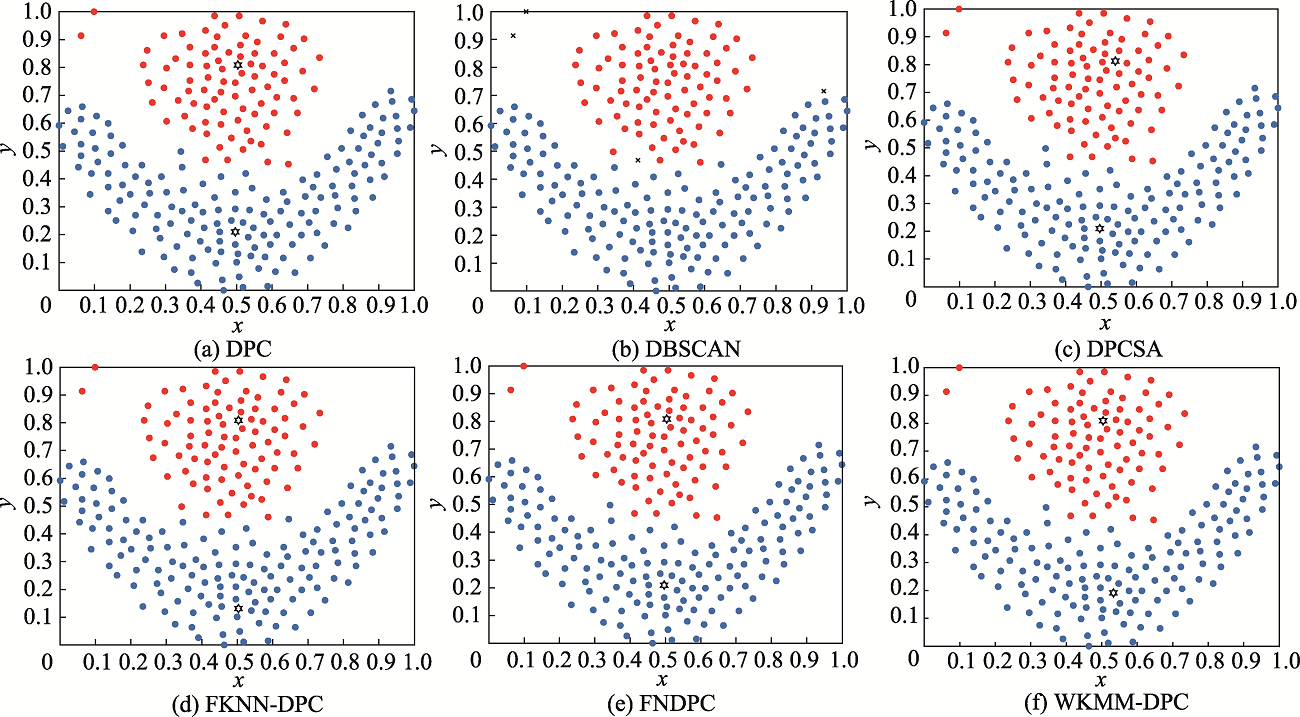
图6 6种算法对Flame数据集的聚类结果
Fig.6 Clustering results of 6 algorithms on Flame dataset

图7 6种算法对Jain数据集的聚类结果
Fig.7 Clustering results of 6 algorithms on Jain dataset

图8 6种算法对Pathbased数据集的聚类结果
Fig.8 Clustering results of 6 algorithms on Pathbased dataset

图9 6种算法对Spiral数据集的聚类结果
Fig.9 Clustering results of 6 algorithms on Spiral dataset

图10 6种算法对R15数据集的聚类结果
Fig.10 Clustering results of 6 algorithms on R15 dataset

图11 6种算法对D31数据集的聚类结果
Fig.11 Clustering results of 6 algorithms on D31 dataset

图12 6种算法对S2数据集的聚类结果
Fig.12 Clustering results of 6 algorithms on S2 dataset
| 算法 | 秩均值 | ||
|---|---|---|---|
| AMI | ARI | FMI | |
| WKMM-DPC | 5.13 | 4.56 | 4.50 |
| FKNN-DPC | 3.94 | 4.00 | 4.19 |
| DPCSA | 2.50 | 2.63 | 2.63 |
| FNDPC | 3.38 | 3.56 | 3.63 |
| DPC | 3.63 | 3.81 | 3.63 |
| DBSCAN | 2.44 | 2.44 | 2.44 |
表4 3种评价指标在人工数据集上的Friedman检验值
Table 4 Friedman test value of 3 evaluation indices on synthetic datasets
| 算法 | 秩均值 | ||
|---|---|---|---|
| AMI | ARI | FMI | |
| WKMM-DPC | 5.13 | 4.56 | 4.50 |
| FKNN-DPC | 3.94 | 4.00 | 4.19 |
| DPCSA | 2.50 | 2.63 | 2.63 |
| FNDPC | 3.38 | 3.56 | 3.63 |
| DPC | 3.63 | 3.81 | 3.63 |
| DBSCAN | 2.44 | 2.44 | 2.44 |
| Clustering algorithm | Seeds | Ecoli | ||||||
|---|---|---|---|---|---|---|---|---|
| AMI | ARI | FMI | Arg- | AMI | ARI | FMI | Arg- | |
| WKMM-DPC | 0.705 4 | 0.730 6 | 0.820 7 | 5 | 0.716 2 | 0.747 9 | 0.824 4 | 25 |
| FKNN-DPC | 0.775 7 | 0.802 4 | 0.868 2 | 9 | 0.587 8 | 0.589 4 | 0.702 7 | 2 |
| DPCSA | 0.660 9 | 0.687 3 | 0.791 8 | — | 0.440 6 | 0.459 3 | 0.646 7 | — |
| FNDPC | 0.713 6 | 0.754 5 | 0.836 1 | 0.07 | 0.483 3 | 0.561 8 | 0.717 8 | 0.35 |
| DPC | 0.729 8 | 0.767 0 | 0.844 4 | 0.70 | 0.497 8 | 0.446 5 | 0.577 5 | 0.40 |
| DBSCAN | 0.591 2 | 0.529 1 | 0.671 1 | 0.24/16 | 0.516 9 | 0.536 7 | 0.669 2 | 0.20/22 |
| Clustering algorithm | Libras | Dermatology | ||||||
| AMI | ARI | FMI | Arg- | AMI | ARI | FMI | Arg- | |
| WKMM-DPC | 0.676 7 | 0.411 4 | 0.458 6 | 8 | 0.902 3 | 0.841 6 | 0.880 8 | 61 |
| FKNN-DPC | 0.555 4 | 0.345 9 | 0.404 4 | 10 | 0.806 6 | 0.836 1 | 0.870 9 | 35 |
| DPCSA | 0.538 8 | 0.309 5 | 0.379 1 | — | 0.745 1 | 0.606 2 | 0.689 6 | — |
| FNDPC | 0.549 4 | 0.329 0 | 0.386 9 | 0.17 | 0.789 8 | 0.799 5 | 0.841 8 | 0.17 |
| DPC | 0.535 8 | 0.319 3 | 0.371 7 | 0.30 | 0.608 6 | 0.611 0 | 0.705 6 | 1.50 |
| DBSCAN | 0.591 2 | 0.196 5 | 0.257 0 | 0.90/2 | 0.625 0 | 0.415 2 | 0.538 5 | 0.99/3 |
| Clustering algorithm | Iris | Glass | ||||||
| AMI | ARI | FMI | Arg- | AMI | ARI | FMI | Arg- | |
| WKMM-DPC | 0.883 1 | 0.903 8 | 0.935 5 | 11 | 0.699 3 | 0.668 9 | 0.758 3 | 12 |
| FKNN-DPC | 0.883 1 | 0.903 8 | 0.935 5 | 22 | 0.489 6 | 0.510 6 | 0.654 1 | 9 |
| DPCSA | 0.883 1 | 0.903 8 | 0.935 5 | — | 0.237 5 | 0.198 6 | 0.545 6 | — |
| FNDPC | 0.883 1 | 0.903 8 | 0.935 5 | 0.11 | 0.563 5 | 0.576 4 | 0.687 7 | 0.09 |
| DPC | 0.724 7 | 0.703 7 | 0.803 2 | 0.20 | 0.556 5 | 0.533 5 | 0.655 9 | 0.90 |
| DBSCAN | 0.640 1 | 0.612 0 | 0.729 1 | 0.12/5 | 0.504 0 | 0.110 6 | 0.278 4 | 0.1/1 |
| Clustering algorithm | Wine | Waveform | ||||||
| AMI | ARI | FMI | Arg- | AMI | ARI | FMI | Arg- | |
| WKMM-DPC | 0.772 9 | 0.771 3 | 0.848 0 | 14 | 0.299 1 | 0.282 7 | 0.582 5 | 8 |
| FKNN-DPC | 0.848 1 | 0.883 9 | 0.922 9 | 8 | 0.323 9 | 0.267 1 | 0.524 4 | 2 |
| DPCSA | 0.748 0 | 0.741 4 | 0.828 3 | — | 0.251 0 | 0.223 6 | 0.532 7 | — |
| FNDPC | 0.789 8 | 0.802 5 | 0.868 6 | 0.26 | 0.329 3 | 0.283 0 | 0.544 2 | 0.34 |
| DPC | 0.706 5 | 0.672 4 | 0.783 5 | 2.00 | 0.326 1 | 0.269 8 | 0.529 2 | 0.10 |
| DBSCAN | 0.590 5 | 0.529 2 | 0.712 1 | 0.50/21 | 0.104 9 | 0.009 4 | 0.481 1 | 0.38/5 |
表5 6种聚类算法在8个UCI数据集上的聚类性能
Table 5 Performance of 6 clustering algorithms on 8 UCI datasets
| Clustering algorithm | Seeds | Ecoli | ||||||
|---|---|---|---|---|---|---|---|---|
| AMI | ARI | FMI | Arg- | AMI | ARI | FMI | Arg- | |
| WKMM-DPC | 0.705 4 | 0.730 6 | 0.820 7 | 5 | 0.716 2 | 0.747 9 | 0.824 4 | 25 |
| FKNN-DPC | 0.775 7 | 0.802 4 | 0.868 2 | 9 | 0.587 8 | 0.589 4 | 0.702 7 | 2 |
| DPCSA | 0.660 9 | 0.687 3 | 0.791 8 | — | 0.440 6 | 0.459 3 | 0.646 7 | — |
| FNDPC | 0.713 6 | 0.754 5 | 0.836 1 | 0.07 | 0.483 3 | 0.561 8 | 0.717 8 | 0.35 |
| DPC | 0.729 8 | 0.767 0 | 0.844 4 | 0.70 | 0.497 8 | 0.446 5 | 0.577 5 | 0.40 |
| DBSCAN | 0.591 2 | 0.529 1 | 0.671 1 | 0.24/16 | 0.516 9 | 0.536 7 | 0.669 2 | 0.20/22 |
| Clustering algorithm | Libras | Dermatology | ||||||
| AMI | ARI | FMI | Arg- | AMI | ARI | FMI | Arg- | |
| WKMM-DPC | 0.676 7 | 0.411 4 | 0.458 6 | 8 | 0.902 3 | 0.841 6 | 0.880 8 | 61 |
| FKNN-DPC | 0.555 4 | 0.345 9 | 0.404 4 | 10 | 0.806 6 | 0.836 1 | 0.870 9 | 35 |
| DPCSA | 0.538 8 | 0.309 5 | 0.379 1 | — | 0.745 1 | 0.606 2 | 0.689 6 | — |
| FNDPC | 0.549 4 | 0.329 0 | 0.386 9 | 0.17 | 0.789 8 | 0.799 5 | 0.841 8 | 0.17 |
| DPC | 0.535 8 | 0.319 3 | 0.371 7 | 0.30 | 0.608 6 | 0.611 0 | 0.705 6 | 1.50 |
| DBSCAN | 0.591 2 | 0.196 5 | 0.257 0 | 0.90/2 | 0.625 0 | 0.415 2 | 0.538 5 | 0.99/3 |
| Clustering algorithm | Iris | Glass | ||||||
| AMI | ARI | FMI | Arg- | AMI | ARI | FMI | Arg- | |
| WKMM-DPC | 0.883 1 | 0.903 8 | 0.935 5 | 11 | 0.699 3 | 0.668 9 | 0.758 3 | 12 |
| FKNN-DPC | 0.883 1 | 0.903 8 | 0.935 5 | 22 | 0.489 6 | 0.510 6 | 0.654 1 | 9 |
| DPCSA | 0.883 1 | 0.903 8 | 0.935 5 | — | 0.237 5 | 0.198 6 | 0.545 6 | — |
| FNDPC | 0.883 1 | 0.903 8 | 0.935 5 | 0.11 | 0.563 5 | 0.576 4 | 0.687 7 | 0.09 |
| DPC | 0.724 7 | 0.703 7 | 0.803 2 | 0.20 | 0.556 5 | 0.533 5 | 0.655 9 | 0.90 |
| DBSCAN | 0.640 1 | 0.612 0 | 0.729 1 | 0.12/5 | 0.504 0 | 0.110 6 | 0.278 4 | 0.1/1 |
| Clustering algorithm | Wine | Waveform | ||||||
| AMI | ARI | FMI | Arg- | AMI | ARI | FMI | Arg- | |
| WKMM-DPC | 0.772 9 | 0.771 3 | 0.848 0 | 14 | 0.299 1 | 0.282 7 | 0.582 5 | 8 |
| FKNN-DPC | 0.848 1 | 0.883 9 | 0.922 9 | 8 | 0.323 9 | 0.267 1 | 0.524 4 | 2 |
| DPCSA | 0.748 0 | 0.741 4 | 0.828 3 | — | 0.251 0 | 0.223 6 | 0.532 7 | — |
| FNDPC | 0.789 8 | 0.802 5 | 0.868 6 | 0.26 | 0.329 3 | 0.283 0 | 0.544 2 | 0.34 |
| DPC | 0.706 5 | 0.672 4 | 0.783 5 | 2.00 | 0.326 1 | 0.269 8 | 0.529 2 | 0.10 |
| DBSCAN | 0.590 5 | 0.529 2 | 0.712 1 | 0.50/21 | 0.104 9 | 0.009 4 | 0.481 1 | 0.38/5 |
| 算法 | 秩均值 | ||
|---|---|---|---|
| AMI | ARI | FMI | |
| WKMM-DPC | 4.81 | 5.06 | 5.19 |
| FKNN-DPC | 4.56 | 4.69 | 4.44 |
| DPCSA | 2.31 | 2.44 | 2.81 |
| FNDPC | 4.19 | 4.56 | 4.56 |
| DPC | 2.88 | 3.00 | 2.75 |
| DBSCAN | 2.25 | 1.25 | 1.25 |
表6 3种评价指标在UCI数据集上的Friedman检验值
Table 6 Friedman test value of 3 evaluation indices on UCI datasets
| 算法 | 秩均值 | ||
|---|---|---|---|
| AMI | ARI | FMI | |
| WKMM-DPC | 4.81 | 5.06 | 5.19 |
| FKNN-DPC | 4.56 | 4.69 | 4.44 |
| DPCSA | 2.31 | 2.44 | 2.81 |
| FNDPC | 4.19 | 4.56 | 4.56 |
| DPC | 2.88 | 3.00 | 2.75 |
| DBSCAN | 2.25 | 1.25 | 1.25 |
| [1] |
SRIVASTAVA A N. Data mining: concepts, models, methods, and algorithms[J]. Journal of Computing and Information Science and Engineering, 2005, 5(4): 394-395.
DOI URL |
| [2] |
JAIN A K. Data clustering: 50 years beyond K-means[J]. Pattern Recognition Letters, 2010, 31(8): 651-666.
DOI URL |
| [3] |
ZHANG T, RAMAKRISHNAN R, LIVNY M. BIRCH: a new data clustering algorithm and its applications[J]. Data Mining and Knowledge Discovery, 1997, 1(2): 141-182.
DOI URL |
| [4] | ESTER M, KRIEGEL H P, SANDER J, et al. A density-based algorithm for discovering clusters in large spatial databases with noise[C]// Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining, Portland, 1996. Menlo Park: AAAI, 1996: 226-231. |
| [5] | WEI W, YANG J, MUNTZ R R. STING: a statistical informa-tion grid approach to spatial data mining[C]// Proceedings of the 23rd International Conference on Very Large Data Bases, Los Angeles, Aug 25-29, 1997. San Francisco: Morgan Kaufmann, 1997: 186-195. |
| [6] |
XU X, DING S, DU M, et al. DPCG: an efficient density peaks clustering algorithm based on grid[J]. International Journal of Machine Learning and Cybernetics, 2018, 9(5): 743-754.
DOI URL |
| [7] |
RODRIGUEZ A, LAIO A. Clustering by fast search and find of density peaks[J]. Science, 2014, 344(6191): 1492-1496.
DOI URL |
| [8] |
高诗莹, 周晓锋, 李帅. 基于密度比例的密度峰值聚类算法[J]. 计算机工程与应用, 2017, 53(16): 10-17.
DOI |
| GAO S Y, ZHOU X F, LI S. Clustering by fast search and find of density peaks based on density-raito[J]. Computer Engineering and Applications, 2017, 53(16): 10-17. | |
| [9] |
ZHAO J, TANG J J, SHI A Y, et al. Improved density peaks clustering based on firefly algorithm[J]. International Journal of Bio-Inspired Computation, 2020, 15(1): 24-42.
DOI URL |
| [10] |
SUN L, LIU R N, XU J C, et al. An adaptive density peaks clustering method with fisher linear discriminant[J]. IEEE Access, 2019, 7: 72936-72955.
DOI URL |
| [11] | 纪霞, 姚晟, 赵鹏. 相对邻域与剪枝策略优化的密度峰值聚类算法[J]. 自动化学报, 2020, 46(3): 562-575. |
| JI X, YAO S, ZHAO P. Relative neighborhood and pruning strategy optimized density peaks clustering algorithm[J]. Acta Automatica Sinica, 2020, 46(3): 562-575. | |
| [12] |
薛小娜, 高淑萍, 彭弘铭, 等. 结合K近邻的改进密度峰值聚类算法[J]. 计算机工程与应用, 2018, 54(7): 36-43.
DOI |
| XUE X N, GAO S P, PENG H M, et al. Improved density peaks clustering algorithm combining K-nearest neighbors[J]. Computer Engineering and Applications, 2018, 54(7): 36-43. | |
| [13] |
DU M J, DING S F, JIA H J. Study on density peaks clustering based on k-nearest neighbors and principal component analysis[J]. Knowledge-Based Systems, 2016, 99: 135-145.
DOI URL |
| [14] |
XIE J Y, GAO H C, XIE W X, et al. Robust clustering by detecting density peaks and assigning points based on fuzzy weighted K-nearest neighbors[J]. Information Sciences, 2016, 354: 19-40.
DOI URL |
| [15] |
贾露, 张德生, 吕端端. 物理学优化的密度峰值聚类算法[J]. 计算机工程与应用, 2020, 56(13): 47-53.
DOI |
|
JIA L, ZHANG D S, LV D D. Optimized density peak clustering algorithm in physics[J]. Computer Engineering and Applications, 2020, 56(13): 47-53.
DOI |
|
| [16] |
王芙银, 张德生, 张晓. 结合鲸鱼优化算法的自适应密度峰值聚类算法[J]. 计算机工程与应用, 2021, 57(3): 94-102.
DOI |
| WANG F Y, ZHANG D S, ZHANG X. Adaptive density peaks clustering algorithm combining with whale optimization algorithm[J]. Computer Engineering and Applications, 2021, 57(3): 94-102. | |
| [17] | 赵嘉, 姚占峰, 吕莉, 等. 基于相互邻近度的密度峰值聚类算法[J]. 控制与决策, 2021, 36(3): 543-552. |
| ZHAO J, YAO Z F, LV L, et al. Density peaks clustering based on mutual neighbor degree[J]. Control and Decision, 2021, 36(3): 543-552. | |
| [18] | ZHAO J, TANG J J, FAN T H, et al. Density peaks clustering based on circular partition and grid similarity[J]. Concurrency and Computation: Practice and Experience, 2020, 32(7): e5567. |
| [19] |
CHEN H, YANG B, WANG G, et al. A novel bankruptcy prediction model based on an adaptive fuzzy-nearest neighbor method[J]. Knowledge-Based Systems, 2011, 24(8): 1348-1359.
DOI URL |
| [20] |
LV L, WANG J Y, WU R X, et al. Density peaks clustering based on geodetic distance and dynamic neighborhood[J]. International Journal of Bio-Inspired Computation, 2021, 17(1): 24-33.
DOI URL |
| [21] |
YU D H, LIU G J, GUO M Z, et al. Density peaks clustering based on weighted local density sequence and nearest neighbor assignment[J]. IEEE Access, 2019, 7: 34301-34317.
DOI URL |
| [22] |
DU M J, DING S F, XUE Y. A robust density peaks clustering algorithm using fuzzy neighborhood[J]. International Journal of Machine Learning and Cybernetics, 2018, 9(7): 1131-1140.
DOI URL |
| [23] | DIAS D B, MADEO R C B, ROCHA T, et al. Hand movement recognition for Brazilian sign language: a study using distance-based neural networks[C]// Proceedings of the 2009 International Joint Conference on Neural Networks, Atlanta, Jun 14-19,2009. Washington: IEEE Computer Society, 2009: 697-704. |
| [24] |
FU L M, MEDICO E. FLAME, a novel fuzzy clustering method for the analysis of DNA microarray data[J]. BMC Bioinformatics, 2007, 8(1): 3.
DOI URL |
| [25] | JAIN A K, LAW M H C. Data clustering: user's dilemma[C]// LNCS 3776: Proceedings of the 1st International Conference on Pattern Recognition and Machine Intelligence, Koikata,Dec 20-22, 2005. Berlin, Heidelberg: Springer, 2005: 1-10. |
| [26] |
CHANG H, YEUNG D Y. Robust path-based spectral clustering[J]. Pattern Recognition, 2008, 41(1): 191-203.
DOI URL |
| [27] |
VEENMAN C J, REINDERS M J T, BACKER E. A maximum variance cluster algorithm[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(9): 1273-1280.
DOI URL |
| [28] |
FRNTI P, VIRMAJOKI O. Iterative shrinking method for clustering problems[J]. Pattern Recognition, 2006, 39(5): 761-775.
DOI URL |
| [29] | CHARYTANOWICZ M, NIEWCZAS J, KULCZYCKI P, et al. Complete gradient clustering algorithm for features analysis of X-ray images[J]. Information Technologies in Biomedicine, 2010, 69: 15-24. |
| [30] | BLAKE C L, MERZ C J. UCI repository of machine learning database[EB/OL]. [2020-12-28]. http://archive.ics.uci.edu/ml/index.html. |
| [31] |
WU C R, JIA L, YAO J, et al. Efficient clustering method based on density peaks with symmetric neighborhood relationship[J]. IEEE Access, 2019, 7: 60684-60696.
DOI URL |
| [32] | BREIMAN L, FRIEDMAN J H, OLSHENR A, et al. Classificationand regression trees(CART)[J]. Biometrics, 1984, 40(3): 358. |
| [1] | 刘学文, 王继奎, 杨正国, 李冰, 聂飞平. 密度峰值隶属度优化的半监督Self-Training算法[J]. 计算机科学与探索, 2022, 16(9): 2078-2088. |
| [2] | 何云斌, 刘婉旭, 万静. 障碍空间中Voronoi图优化的反向近邻数聚类算法[J]. 计算机科学与探索, 2022, 16(9): 2041-2049. |
| [3] | 许嘉, 莫晓琨, 于戈, 吕品, 韦婷婷. SQL-Detector:基于编码特征的SQL习题抄袭检测技术[J]. 计算机科学与探索, 2022, 16(9): 2030-2040. |
| [4] | 赵力衡, 王建, 陈虹君. 去中心化加权簇归并的密度峰值聚类算法[J]. 计算机科学与探索, 2022, 16(8): 1910-1922. |
| [5] | 叶廷宇, 叶军, 王晖, 王磊. 结合人工蜂群优化的粗糙K-means聚类算法[J]. 计算机科学与探索, 2022, 16(8): 1923-1932. |
| [6] | 张祥平, 刘建勋, 肖巧翔, 曹步清. 融合多维信息的Web服务表征方法[J]. 计算机科学与探索, 2022, 16(7): 1561-1569. |
| [7] | 陈俊芬, 张明, 赵佳成, 谢博鋆, 李艳. 结合降噪和自注意力的深度聚类算法[J]. 计算机科学与探索, 2021, 15(9): 1717-1727. |
| [8] | 王大刚, 丁世飞, 钟锦. 基于二阶[k]近邻的密度峰值聚类算法研究[J]. 计算机科学与探索, 2021, 15(8): 1490-1500. |
| [9] | 沈学利, 秦鑫宇. 密度Canopy的增强聚类与深度特征的KNN算法[J]. 计算机科学与探索, 2021, 15(7): 1289-1301. |
| [10] | 范瑞东, 侯臣平. 鲁棒自加权的多视图子空间聚类[J]. 计算机科学与探索, 2021, 15(6): 1062-1073. |
| [11] | 柏锷湘, 罗可, 罗潇. 结合自然和共享最近邻的密度峰值聚类算法[J]. 计算机科学与探索, 2021, 15(5): 931-940. |
| [12] | 张倪妮, 葛洪伟. 稳定的K-多均值聚类算法[J]. 计算机科学与探索, 2021, 15(5): 941-948. |
| [13] | 马瑞强, 宋宝燕, 丁琳琳, 王俊陆. 面向时间序列事件的动态矩阵聚类方法[J]. 计算机科学与探索, 2021, 15(3): 468-477. |
| [14] | 薛红艳, 钱雪忠, 周世兵. 超簇加权的集成聚类算法[J]. 计算机科学与探索, 2021, 15(12): 2362-2373. |
| [15] | 张培, 祝恩, 蔡志平. 单步划分融合多视图子空间聚类算法[J]. 计算机科学与探索, 2021, 15(12): 2413-2420. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||