
计算机科学与探索 ›› 2022, Vol. 16 ›› Issue (1): 217-230.DOI: 10.3778/j.issn.1673-9418.2007059
李志欣1,+( ), 陈圣嘉1, 周韬1, 马慧芳2
), 陈圣嘉1, 周韬1, 马慧芳2
收稿日期:2020-07-03
修回日期:2020-09-09
出版日期:2022-01-01
发布日期:2020-09-25
通讯作者:
+ E-mail: lizx@gxnu.edu.cn作者简介:李志欣(1971—),男,博士,教授,博士生导师,CCF高级会员,主要研究方向为图像理解、机器学习、自然语言处理、跨媒体计算。基金资助:
LI Zhixin1,+(), CHEN Shengjia1, ZHOU Tao1, MA Huifang2
Received:2020-07-03
Revised:2020-09-09
Online:2022-01-01
Published:2020-09-25
About author:LI Zhixin, born in 1971, Ph.D., professor, Ph.D. supervisor, senior member of CCF. His research interests include image understanding, machine learning, natural language processing and cross-media computing.Supported by:摘要:
识别多尺度目标和遮挡目标是目标检测中的重点和难点。为了检测不同大小的目标,目标检测器通常利用卷积神经网络(CNN)的多尺度特征图层次结构,然而这种自顶向下的结构由于底层特征图的卷积层较小,缺乏获取小目标特征所需的细节信息,这些目标检测器的性能受到了限制。为此,结合Faster R-CNN框架提出Collaborative R-CNN,设计了一种级联网络结构,可以融合多尺度特征图,以生成深度融合的特征信息来增强小目标所需的细节特征,从而提高检测小目标的能力。此外,由于使用RoIPooling过程中的量化会对小目标检测造成极大的限制,为进一步提高方法的鲁棒性,设计了多尺度RoIAlign来消除这种量化,并通过多尺度的池化来提高网络检测不同尺度目标的能力。最后,将对抗网络与所提出的级联网络相结合,生成包含遮挡目标的训练样本,可显著提高模型的分类能力和识别遮挡目标的鲁棒性。在PASCAL VOC 2012和PASCAL VOC 2007数据集上的实验结果表明,提出的方法优于许多先进的方法。
中图分类号:
李志欣, 陈圣嘉, 周韬, 马慧芳. 协同级联网络和对抗网络的目标检测[J]. 计算机科学与探索, 2022, 16(1): 217-230.
LI Zhixin, CHEN Shengjia, ZHOU Tao, MA Huifang. Combining Cascaded Network and Adversarial Network for Object Detection[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(1): 217-230.

图1 一些典型的Faster R-CNN检测缺陷
Fig.1 Some typical detection defects of Faster R-CNN
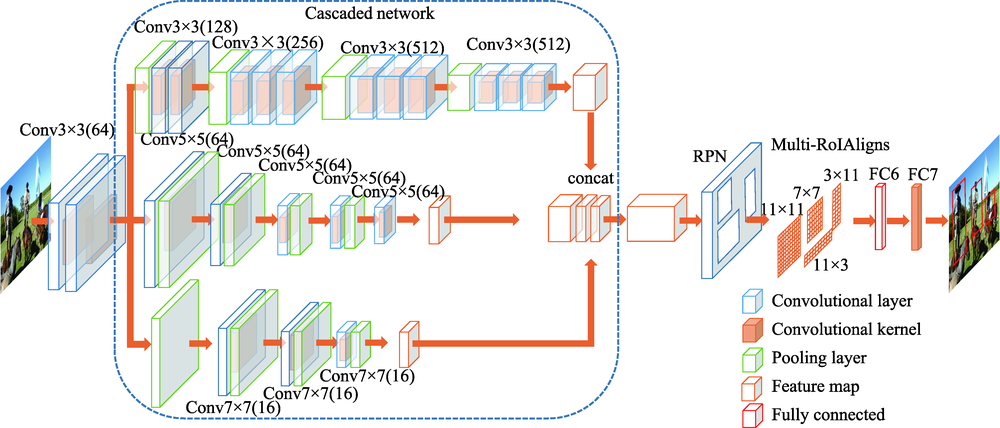
图2 Improved R-CNN模型的网络结构
Fig.2 Network structure of Improved R-CNN model
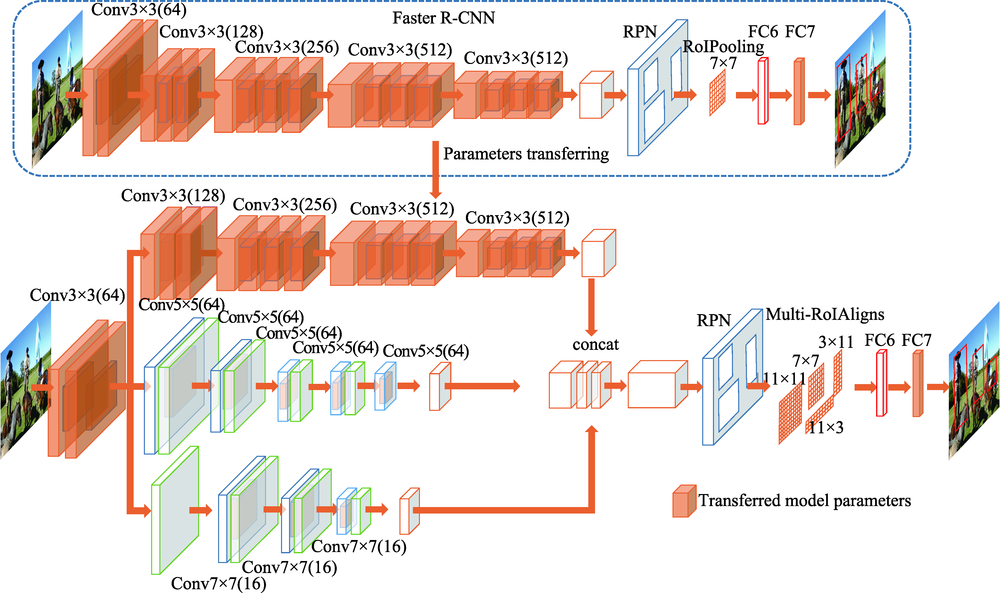
图3 Faster R-CNN参数迁移到Improved R-CNN
Fig.3 Faster R-CNN parameters transferred to Improved R-CNN
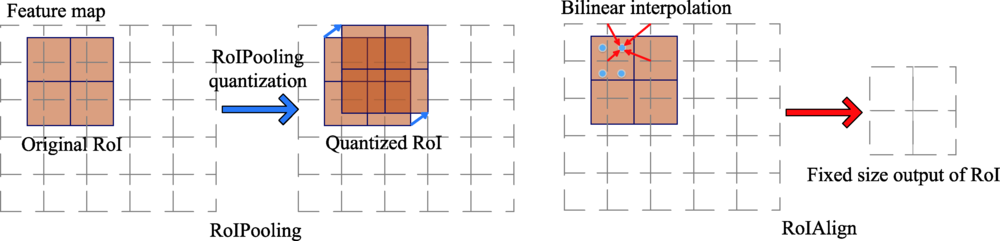
图4 RoIPooling和RoIAlign的操作过程
Fig.4 Operation process of RoIPooling and RoIAlign
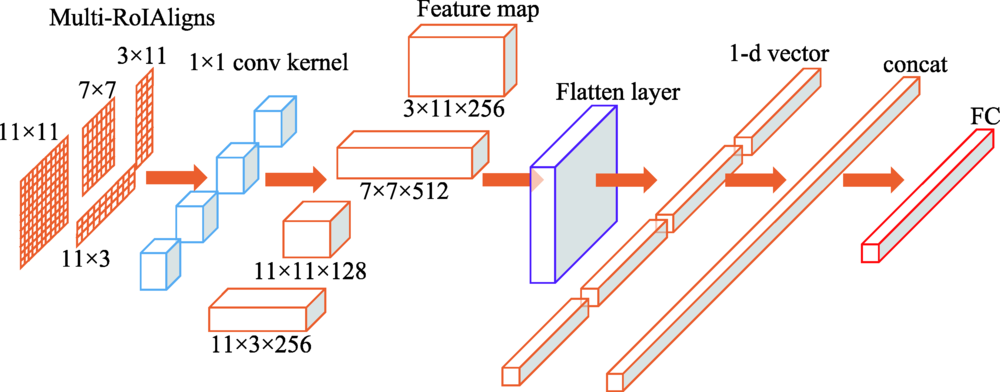
图5 特征过滤结构
Fig.5 Feature filtering structure
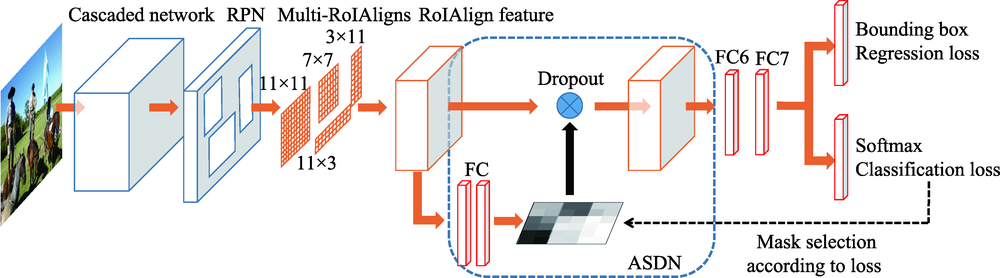
图6 与Improved R-CNN相结合的ASDN框架
Fig.6 Framework of ASDN combined with Improved R-CNN

图7 ASDN训练中选择和生成样本的实例
Fig.7 Instances of selecting and generating samples in ASDN training
| Method | Anchor | Pooling sizes | mAP/% |
|---|---|---|---|
| Faster R-CNN | (128,256,512) | 7×7 | 73.2 |
| Faster R-CNN | (64,128,256,512) | 7×7 | 73.3 |
| Cascaded network | (64,128,256,512) | 7×7 | 73.9 |
| Cascaded network+RoIAligns | (64,128,256,512) | 3×11、11×3、7×7 | 74.5 |
| Cascaded network+RoIAligns (Improved R-CNN) | (64,128,256,512) | 3×11、11×3、7×7、11×11 | 74.8 |
| Improved R-CNN+FT | (64,128,256,512) | 3×11、11×3、7×7、11×11 | 75.2 |
| Improved R-CNN+FT+ASDN (Collaborative R-CNN) | (64,128,256,512) | 3×11、11×3、7×7、11×11 | 77.5 |
表1 在PASCAL VOC 2007数据集上的消融实验结果
Table 1 Results of ablation experiments on PASCAL VOC 2007 dataset
| Method | Anchor | Pooling sizes | mAP/% |
|---|---|---|---|
| Faster R-CNN | (128,256,512) | 7×7 | 73.2 |
| Faster R-CNN | (64,128,256,512) | 7×7 | 73.3 |
| Cascaded network | (64,128,256,512) | 7×7 | 73.9 |
| Cascaded network+RoIAligns | (64,128,256,512) | 3×11、11×3、7×7 | 74.5 |
| Cascaded network+RoIAligns (Improved R-CNN) | (64,128,256,512) | 3×11、11×3、7×7、11×11 | 74.8 |
| Improved R-CNN+FT | (64,128,256,512) | 3×11、11×3、7×7、11×11 | 75.2 |
| Improved R-CNN+FT+ASDN (Collaborative R-CNN) | (64,128,256,512) | 3×11、11×3、7×7、11×11 | 77.5 |
| Method | Backbone | Train data | Input resolution/pixel | mAP/% |
|---|---|---|---|---|
| Faster R-CNN[ | VGG16 | 07+12 | 600×1 000 | 73.2 |
| A-Fast-RCNN[ | VGG16 | 07+12 | 600×1 000 | 71.4 |
| NOC[ | VGG16 | 07+12 | 600×1 000 | 73.3 |
| SSD[ | VGG16 | 07+12 | — | 75.1 |
| RON[ | VGG16 | 07+12 | 384×384 | 77.6 |
| ION[ | VGG16 | 07+12 | 600×1 000 | 75.6 |
| SIN[ | VGG16 | 07+12 | 600×1 000 | 76.0 |
| RGC[ | VGG16 | 07+12 | 600×1 000 | 76.1 |
| SSD321[ | VGG16 | 07+12 | 321×321 | 77.1 |
| YOLOv3[ | DarkNet | 07+12 | 320×320 | 78.6 |
| CenterNet[ | ResNet101 | 07+12 | 384×384 | 78.7 |
| Collaborative R-CNN | VGG16 | 07+12 | 600×1 000 | 77.5 |
表2 在PASCAL VOC 2007数据集上的目标检测实验结果
Table 2 Experimental results of object detection on PASCAL VOC 2007 dataset
| Method | Backbone | Train data | Input resolution/pixel | mAP/% |
|---|---|---|---|---|
| Faster R-CNN[ | VGG16 | 07+12 | 600×1 000 | 73.2 |
| A-Fast-RCNN[ | VGG16 | 07+12 | 600×1 000 | 71.4 |
| NOC[ | VGG16 | 07+12 | 600×1 000 | 73.3 |
| SSD[ | VGG16 | 07+12 | — | 75.1 |
| RON[ | VGG16 | 07+12 | 384×384 | 77.6 |
| ION[ | VGG16 | 07+12 | 600×1 000 | 75.6 |
| SIN[ | VGG16 | 07+12 | 600×1 000 | 76.0 |
| RGC[ | VGG16 | 07+12 | 600×1 000 | 76.1 |
| SSD321[ | VGG16 | 07+12 | 321×321 | 77.1 |
| YOLOv3[ | DarkNet | 07+12 | 320×320 | 78.6 |
| CenterNet[ | ResNet101 | 07+12 | 384×384 | 78.7 |
| Collaborative R-CNN | VGG16 | 07+12 | 600×1 000 | 77.5 |
| Object | AP | ||||
|---|---|---|---|---|---|
| Faster R-CNN[ | A-Fast-RCNN[ | SSD[ | RON[ | CollaborativeR-CNN | |
| aero | 84.9 | 82.2 | 84.9 | 86.5 | 87.0 |
| bike | 79.8 | 75.6 | 82.6 | 82.9 | 83.5 |
| bird | 74.3 | 69.2 | 74.4 | 76.6 | 78.9 |
| blt | 53.9 | 52.0 | 55.8 | 60.9 | 60.1 |
| boat | 49.8 | 47.2 | 50.0 | 55.8 | 57.6 |
| bus | 77.5 | 76.3 | 80.3 | 81.7 | 83.2 |
| car | 75.9 | 71.2 | 78.9 | 80.2 | 80.5 |
| cat | 88.5 | 88.5 | 88.8 | 91.1 | 90.2 |
| chair | 45.6 | 46.8 | 53.7 | 57.3 | 51.6 |
| cow | 77.1 | 74.0 | 76.8 | 81.1 | 82.4 |
| dog | 55.3 | 58.1 | 59.4 | 60.4 | 61.6 |
| hrs | 86.9 | 85.6 | 87.6 | 87.2 | 89.9 |
| mbk | 81.7 | 80.3 | 83.7 | 84.8 | 89.8 |
| per | 80.9 | 80.5 | 82.6 | 84.9 | 82.8 |
| plant | 79.6 | 74.7 | 81.4 | 81.7 | 86.6 |
| shp | 40.1 | 41.5 | 47.2 | 51.9 | 47.4 |
| sofa | 72.6 | 70.4 | 75.5 | 79.1 | 74.2 |
| table | 60.9 | 62.2 | 65.6 | 68.6 | 70.0 |
| train | 81.2 | 77.4 | 84.3 | 84.1 | 86.6 |
| tv | 61.5 | 67.0 | 68.1 | 70.3 | 69.9 |
| mAP | 70.4 | 69.0 | 73.1 | 75.4 | 75.7 |
表3 在PASCAL VOC 2012数据集上的目标检测实验结果
Table 3 Experimental results of object detection on PASCAL VOC 2012 dataset %
| Object | AP | ||||
|---|---|---|---|---|---|
| Faster R-CNN[ | A-Fast-RCNN[ | SSD[ | RON[ | CollaborativeR-CNN | |
| aero | 84.9 | 82.2 | 84.9 | 86.5 | 87.0 |
| bike | 79.8 | 75.6 | 82.6 | 82.9 | 83.5 |
| bird | 74.3 | 69.2 | 74.4 | 76.6 | 78.9 |
| blt | 53.9 | 52.0 | 55.8 | 60.9 | 60.1 |
| boat | 49.8 | 47.2 | 50.0 | 55.8 | 57.6 |
| bus | 77.5 | 76.3 | 80.3 | 81.7 | 83.2 |
| car | 75.9 | 71.2 | 78.9 | 80.2 | 80.5 |
| cat | 88.5 | 88.5 | 88.8 | 91.1 | 90.2 |
| chair | 45.6 | 46.8 | 53.7 | 57.3 | 51.6 |
| cow | 77.1 | 74.0 | 76.8 | 81.1 | 82.4 |
| dog | 55.3 | 58.1 | 59.4 | 60.4 | 61.6 |
| hrs | 86.9 | 85.6 | 87.6 | 87.2 | 89.9 |
| mbk | 81.7 | 80.3 | 83.7 | 84.8 | 89.8 |
| per | 80.9 | 80.5 | 82.6 | 84.9 | 82.8 |
| plant | 79.6 | 74.7 | 81.4 | 81.7 | 86.6 |
| shp | 40.1 | 41.5 | 47.2 | 51.9 | 47.4 |
| sofa | 72.6 | 70.4 | 75.5 | 79.1 | 74.2 |
| table | 60.9 | 62.2 | 65.6 | 68.6 | 70.0 |
| train | 81.2 | 77.4 | 84.3 | 84.1 | 86.6 |
| tv | 61.5 | 67.0 | 68.1 | 70.3 | 69.9 |
| mAP | 70.4 | 69.0 | 73.1 | 75.4 | 75.7 |

图8 在PASCAL VOC 2007和PASCAL VOC 2012数据集上的实验结果
Fig.8 Experimental results on PASCAL VOC 2007 and PASCAL VOC 2012 datasets

图9 Faster R-CNN和Collaborative R-CNN的实验结果
Fig.9 Experimental results of Faster R-CNN and Collaborative R-CNN
| Type | Method | Test time/(ms/image) | mAP/% |
|---|---|---|---|
| One-stage | SSD | 46 | 73.1 |
| RON | 67 | 75.4 | |
| Two-stage | Faster R-CNN | 200 | 70.4 |
| Collaborative R-CNN | 234 | 75.7 |
表4 在PASCAL VOC 2012数据集上的实验结果
Table 4 Experimental results on PASCAL VOC 2012 dataset
| Type | Method | Test time/(ms/image) | mAP/% |
|---|---|---|---|
| One-stage | SSD | 46 | 73.1 |
| RON | 67 | 75.4 | |
| Two-stage | Faster R-CNN | 200 | 70.4 |
| Collaborative R-CNN | 234 | 75.7 |
| [1] | GIRSHICK R B, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, Jun 23-28, 2014. Washington: IEEE Computer Society, 2014: 580-587. |
| [2] | GIRSHICK R B. Fast R-CNN[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Dec 7-13, 2015. Washington: IEEE Computer Society, 2015: 1440-1448. |
| [3] | REN S Q, HE K M, GIRSHICK R B, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]// Proceedings of the Annual Conference on Neural In-formation Processing Systems, Montreal, Dec 7-12, 2015. Red Hook: Curran Associates, 2015: 91-99. |
| [4] |
RUSSAKOVSKY O, DENG J, SU H, et al. ImageNet large scale visual recognition challenge[J]. International Journal of Computer Vision, 2015, 115(3):211-252.
DOI URL |
| [5] |
WEI S T, LI Z X, ZHANG C L. Combined constraint-based with metric-based in semi-supervised clustering ensemble[J]. International Journal of Machine Learning and Cybernetics, 2018, 9(7):1085-1100.
DOI URL |
| [6] | WEI Y C, XIA W, LIN M, et al. HCP: a flexible CNN frame-work for multi-label image classification[J]. IEEE Transac-tions on Pattern Analysis and Machine Intelligence, 2015, 38(9):1901-1907. |
| [7] |
ZHENG Y Z, LI Z X, ZHANG C L. A hybrid architecture based on CNN for cross-modal semantic instance annotation[J]. Multimedia Tools and Applications, 2018, 77(7):8695-8710.
DOI URL |
| [8] | DAI J F, LI Y, HE K M, et al. R-FCN: object detection via region-based fully convolutional networks[C]// Proceedings of the Annual Conference on Neural Information Processing Systems, Barcelona, Dec 5-10, 2016. Red Hook: Curran Associates, 2016: 379-387. |
| [9] | KONG T, YAO A B, CHEN Y R, et al. HyperNet: towards accurate region proposal generation and joint object detection[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 845-853. |
| [10] | SERMANET P, EIGEN D, ZHANG X, et al. OverFeat: integrated recognition, localization and detection using con-volutional networks[J]. arXiv:1312.6229, 2013. |
| [11] | LIN T Y. DOLLÁR P, GIRSHICK R B, et al. Feature pyramid networks for object detection[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recogni-tion, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 936-944. |
| [12] |
HE K M, ZHANG X Y, REN S Q, et al. Spatial pyramid pooling in deep convolutional networks for visual recogni-tion[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9):1904-1916.
DOI URL |
| [13] | EVERINGHAM M, VAN GOOL L, WILLIAMS C I, et al. The PASCAL visual object classes (VOC) challenge[J]. Inter-national Journal of Computer Vision, 2010, 88(2):303-338. |
| [14] |
UIJLINGS J R R, VAN DE SANDE K E A, GEVERS T, et al. Selective search for object recognition[J]. International Journal of Computer Vision, 2013, 104(2):154-171.
DOI URL |
| [15] | LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector[C]// LNCS 9905: Proceedings of the 14th European Conference on Computer Vision, Amsterdam, Oct 11-14, 2016. Cham: Springer, 2016: 21-37. |
| [16] | REDMON J, DIVVALA S K, GIRSHICK R B, et al. You only look once: unified, real-time object detection[C]// Pro-ceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Wash-ington: IEEE Computer Society, 2016: 779-788. |
| [17] | KONG T, SUN F C, YAO A B, et al. RON: reverse connec-tion with objectness prior networks for object detection[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 5244-5252. |
| [18] | 刘云, 钱美伊, 李辉, 等. 深度学习的多尺度多人目标检测方法研究[J]. 计算机工程与应用, 2020, 56(6):172-179. |
| LIU Y, QIAN M Y, LI H, et al. Research on multi-scale and multi-human detection method of deep learning[J]. Computer Engineering and Applications, 2020, 56(6):172-179. | |
| [19] | 杨雅茹, 邓红霞, 王哲, 等. 浅层特征融合引导的深层网络行人检测[J]. 计算机工程与应用, 2020, 56(2):196-200. |
| YANG Y R, DENG H X, WANG Z, et al. Deep network pedestrian detection guided by shallow feature fusion[J]. Computer Engineering and Applications, 2020, 56(2):196-200. | |
| [20] | 陈幻杰, 王琦琦, 杨国威, 等. 多尺度卷积特征融合的SSD目标检测算法[J]. 计算机科学与探索, 2019, 13(6):1049-1061. |
| CHEN H J, WANG Q Q, YANG G W, et al. SSD object detection algorithm with multi-scale convolution feature fusion[J]. Journal of Frontiers of Computer Science and Technology, 2019, 13(6):1049-1061. | |
| [21] | LIU Y, WANG R P, SHAN S G, et al. Structure inference net: object detection using scene-level context and instance-level relationships[C]// Proceedings of the 2018 IEEE Con-ference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-22, 2018. Washington: IEEE Computer Society, 2018: 6985-6994. |
| [22] | HE C H, LAI S C, LAM K M, et al. Improving object detection with relation graph inference[C]// Proceedings of the 2019 International Conference on Acoustics Speech and Signal Processing, Brighton, May 12-17, 2019. Piscataway: IEEE, 2019: 2537-2541. |
| [23] | REDMON J, FARHADI A. YOLOv3: an incremental improve- ment[J]. arXiv:1804.02767, 2018. |
| [24] | ZHOU X Y, WANG D Q, KRÄHENBÜHL P. Objects as points[J]. arXiv:1904.07850, 2019. |
| [25] | WANG X L, SHRIVASTAVA A, GUPTA A. A-Fast-RCNN: hard positive generation via adversary for object detection[C]// Proceedings of the 2017 IEEE Conference on Comp-uter Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 3039-3048. |
| [26] | ZHOU T, LI Z X, ZHANG C L, et al. An improved convo-lutional neural network model with adversarial net for multi-label image classification[C]// LNCS 11013: Proceedings of the 15th Pacific Rim International Conference on Artificial Intelligence, Nanjing, Aug 28-31, 2018. Cham: Springer, 2018: 38-46. |
| [27] | CHEN Y L, WANG Z C, PENG Y X, et al. Cascaded pyramid network for multi-person pose estimation[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-22, 2018. Washington: IEEE Computer Society, 2018: 7103-7112. |
| [28] | SZEGEDY C, IOFFE S, VANHOUCKE V, et al. Inception-v4, Inception-ResNet and the impact of residual connections on learning[J]. arXiv:1602.07261, 2016. |
| [29] | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[J]. arXiv:1409.1556, 2014 |
| [30] | KRIZHEVSKY A, SUTSKEVER I, HINTON G E. Image-Net classification with deep convolutional neural networks[C]// Proceedings of the Advances in Neural Information Processing Systems. Red Hook: Curran Associates, 2012: 1106-1114. |
| [31] | OQUAB M, BOTTOU L, LAPTEV I, et al. Learning and transferring mid-level image representations using convolu-tional neural networks[C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, Jun 23-28, 2014. Washington: IEEE Computer Society, 2014: 1717-1724. |
| [32] | ZEILER M D, FERGUS R. Visualizing and understanding convolutional networks[C]// LNCS 8689: Proceedings of the 13th European Conference on Computer Vision, Zurich, Sep 6-12, 2014. Cham: Springer, 2014: 818-833. |
| [33] | YOSINSKI J, CLUNE J, BENGIO Y, et al. How transfer-able are features in deep neural networks?[C]// Proceedings of the Annual Conference on Neural Information Processing Systems, Montreal, Dec 8-13, 2014. Red Hook: Curran Ass-ociates, 2014: 3320-3328. |
| [34] | ZHANG C L, LUO J H, WEI X S, et al. In defense of fully connected layers in visual representation transfer[C]// LNCS 10736: Proceedings of the 18th Pacific-Rim Conference on Multimedia Advances in Multimedia Information Processing, Harbin, Sep 28-29, 2017. Cham: Springer, 2017: 807-817. |
| [35] | HE K M, GKIOXARI G. DOLLÁR P, et al. Mask R-CNN[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Oct 22-29, 2017. Washington: IEEE Computer Society, 2017: 2961-2969. |
| [36] | JIANG Y, ZHU X, WANG X, et al. R2CNN: rotational region CNN for orientation robust scene text detection[J]. arXiv:1706.09579, 2017. |
| [37] | HUANG G, LIU Z, VAN DER MAATEN L, et al. Densely connected convolutional networks[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 2261-2269. |
| [38] | REN S Q, HE K M, GIRSHICK R B, et al. Object detection networks on convolutional feature maps[J]. IEEE Transac-tions on Pattern Analysis and Machine Intelligence, 2016, 39(7):1476-1481. |
| [39] | BELL S, ZITNICK C L, BALA K, et al. Inside-outside net: detecting objects in context with skip pooling and recurrent neural networks[C]// Proceedings of the 2016 IEEE Confer-ence on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 2874-2883. |
| [1] | 安凤平, 李晓薇, 曹翔. 权重初始化-滑动窗口CNN的医学图像分类[J]. 计算机科学与探索, 2022, 16(8): 1885-1897. |
| [2] | 夏鸿斌, 肖奕飞, 刘渊. 融合自注意力机制的长文本生成对抗网络模型[J]. 计算机科学与探索, 2022, 16(7): 1603-1610. |
| [3] | 彭豪, 李晓明. 多尺度选择金字塔网络的小样本目标检测算法[J]. 计算机科学与探索, 2022, 16(7): 1649-1660. |
| [4] | 孙方伟, 李承阳, 谢永强, 李忠博, 杨才东, 齐锦. 深度学习应用于遮挡目标检测算法综述[J]. 计算机科学与探索, 2022, 16(6): 1243-1259. |
| [5] | 赵运基, 范存良, 张新良. 融合多特征和通道感知的目标跟踪算法[J]. 计算机科学与探索, 2022, 16(6): 1417-1428. |
| [6] | 申瑞彩, 翟俊海, 侯璎真. 选择性集成学习多判别器生成对抗网络[J]. 计算机科学与探索, 2022, 16(6): 1429-1438. |
| [7] | 董文轩, 梁宏涛, 刘国柱, 胡强, 于旭. 深度卷积应用于目标检测算法综述[J]. 计算机科学与探索, 2022, 16(5): 1025-1042. |
| [8] | 林佳伟, 王士同. 用于无监督域适应的深度对抗重构分类网络[J]. 计算机科学与探索, 2022, 16(5): 1107-1116. |
| [9] | 程卫月, 张雪琴, 林克正, 李骜. 融合全局与局部特征的深度卷积神经网络算法[J]. 计算机科学与探索, 2022, 16(5): 1146-1154. |
| [10] | 童敢, 黄立波. Winograd快速卷积相关研究综述[J]. 计算机科学与探索, 2022, 16(5): 959-971. |
| [11] | 裴利沈, 赵雪专. 群体行为识别深度学习方法研究综述[J]. 计算机科学与探索, 2022, 16(4): 775-790. |
| [12] | 赵鹏飞, 谢林柏, 彭力. 融合注意力机制的深层次小目标检测算法[J]. 计算机科学与探索, 2022, 16(4): 927-937. |
| [13] | 伏轩仪, 张銮景, 梁文科, 毕方明, 房卫东. 锚点机制在目标检测领域的发展综述[J]. 计算机科学与探索, 2022, 16(4): 791-805. |
| [14] | 陆仲达, 张春达, 张佳奇, 王子菲, 许军华. 双分支网络的苹果叶部病害识别[J]. 计算机科学与探索, 2022, 16(4): 917-926. |
| [15] | 包广斌, 李港乐, 王国雄. 面向多模态情感分析的双模态交互注意力[J]. 计算机科学与探索, 2022, 16(4): 909-916. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||