
Journal of Frontiers of Computer Science and Technology ›› 2022, Vol. 16 ›› Issue (6): 1354-1361.DOI: 10.3778/j.issn.1673-9418.2012054
• Artificial Intelligence • Previous Articles Next Articles
WANG Baoliang1,+( ), PAN Wencai2
), PAN Wencai2
Received:2020-12-15
Revised:2021-04-02
Online:2022-06-01
Published:2021-04-15
About author:WANG Baoliang, born in 1971, Ph.D., senior engineer, M.S. supervisor. His research interests include data mining, mobile Internet, image processing, etc.Supported by:
王宝亮1,+(), 潘文采2
通讯作者:
+ E-mail: wbl@tju.edu.cn作者简介:王宝亮(1971—),男,山东潍坊人,博士,高级工程师,硕士生导师,主要研究方向为数据挖掘、移动互联、图像处理等。基金资助:CLC Number:
WANG Baoliang, PAN Wencai. Two-Terminal Neighbor Information Fusion Recommendation Algorithm Based on Knowledge Graph[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(6): 1354-1361.
王宝亮, 潘文采. 基于知识图谱的双端邻居信息融合推荐算法[J]. 计算机科学与探索, 2022, 16(6): 1354-1361.
Add to citation manager EndNote|Ris|BibTeX
URL: http://fcst.ceaj.org/EN/10.3778/j.issn.1673-9418.2012054
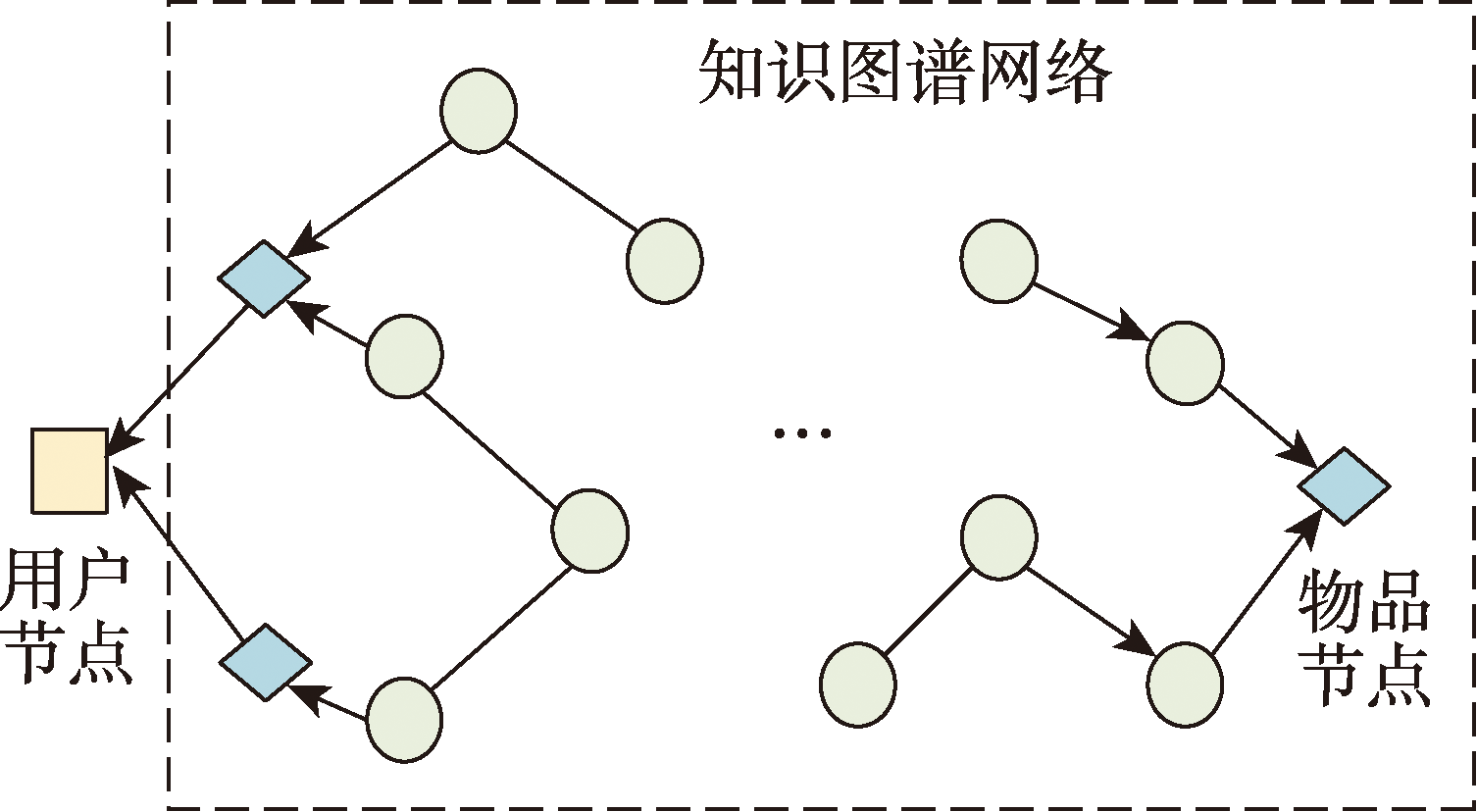
Fig.1 Overall framework

Fig.2 User node information aggregation
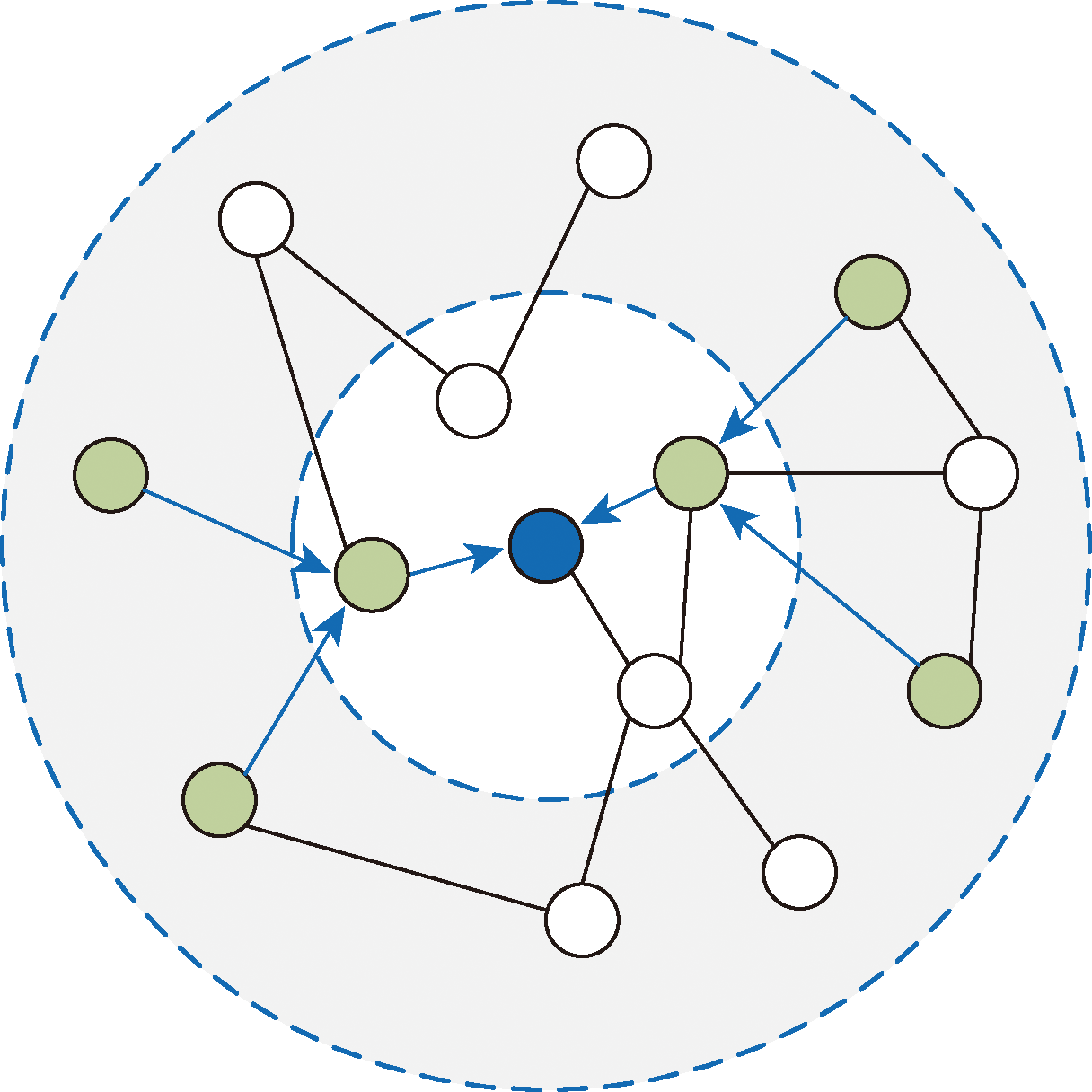
Fig.3 KGCN model
| 统计项目 | Book-Crossing | Last.FM |
|---|---|---|
| users | 19 676 | 1 872 |
| items | 20 003 | 3 846 |
| interactions | 172 576 | 42 346 |
| entities | 25 787 | 9 366 |
| relations | 18 | 60 |
| KG triples | 60 787 | 15 518 |
Table 1 Statistics for two datasets
| 统计项目 | Book-Crossing | Last.FM |
|---|---|---|
| users | 19 676 | 1 872 |
| items | 20 003 | 3 846 |
| interactions | 172 576 | 42 346 |
| entities | 25 787 | 9 366 |
| relations | 18 | 60 |
| KG triples | 60 787 | 15 518 |
| Parameter | Book-Crossing | Last.FM |
|---|---|---|
| | 16 | 64 |
| | 3 | 3 |
| | 3 | 3 |
| | 1 | 1 |
| | 32 | 16 |
| | 1×10-6 | 1×10-6 |
| | 1×10-4 | 5×10-3 |
| | 0.1 | 0.1 |
| Batch size | 256 | 128 |
Table 2 Parameter setting
| Parameter | Book-Crossing | Last.FM |
|---|---|---|
| | 16 | 64 |
| | 3 | 3 |
| | 3 | 3 |
| | 1 | 1 |
| | 32 | 16 |
| | 1×10-6 | 1×10-6 |
| | 1×10-4 | 5×10-3 |
| | 0.1 | 0.1 |
| Batch size | 256 | 128 |
| 模型 | Book-Crossing | Last.FM | ||
|---|---|---|---|---|
| AUC | ACC | AUC | ACC | |
| LibFM | 0.685 0 | 0.640 0 | 0.777 0 | 0.709 0 |
| Wide&Deep | 0.712 0 | 0.624 0 | 0.756 0 | 0.688 0 |
| RippleNet | 0.724 9 | 0.662 0 | 0.813 2 | 0.746 0 |
| KGCN | 0.691 7 | 0.631 8 | 0.803 5 | 0.732 2 |
| KGNN-LS | 0.687 3 | 0.632 0 | 0.802 3 | 0.728 2 |
| 本文模型 | 0.737 4 | 0.690 1 | 0.821 9 | 0.754 5 |
| 本文模型-u | 0.728 0 | 0.664 1 | 0.817 6 | 0.743 9 |
| 本文模型-i | 0.673 8 | 0.619 9 | 0.773 0 | 0.700 8 |
| 不同预测函数 | 0.733 0 | 0.693 9 | 0.792 0 | 0.753 6 |
Table 3 Results of AUC and ACC in CTR prediction
| 模型 | Book-Crossing | Last.FM | ||
|---|---|---|---|---|
| AUC | ACC | AUC | ACC | |
| LibFM | 0.685 0 | 0.640 0 | 0.777 0 | 0.709 0 |
| Wide&Deep | 0.712 0 | 0.624 0 | 0.756 0 | 0.688 0 |
| RippleNet | 0.724 9 | 0.662 0 | 0.813 2 | 0.746 0 |
| KGCN | 0.691 7 | 0.631 8 | 0.803 5 | 0.732 2 |
| KGNN-LS | 0.687 3 | 0.632 0 | 0.802 3 | 0.728 2 |
| 本文模型 | 0.737 4 | 0.690 1 | 0.821 9 | 0.754 5 |
| 本文模型-u | 0.728 0 | 0.664 1 | 0.817 6 | 0.743 9 |
| 本文模型-i | 0.673 8 | 0.619 9 | 0.773 0 | 0.700 8 |
| 不同预测函数 | 0.733 0 | 0.693 9 | 0.792 0 | 0.753 6 |
| | Book-Crossing | Last.FM |
|---|---|---|
| 100 | 0.734 9 | 0.814 1 |
| 10 | 0.737 1 | 0.820 6 |
| 1 | 0.736 1 | 0.820 4 |
| 0.1 | 0.737 4 | 0.821 9 |
| 0.01 | 0.735 8 | 0.821 1 |
| 直接累加 | 0.737 2 | 0.818 5 |
Table 4 Influence of parameter γ on AUC value
| | Book-Crossing | Last.FM |
|---|---|---|
| 100 | 0.734 9 | 0.814 1 |
| 10 | 0.737 1 | 0.820 6 |
| 1 | 0.736 1 | 0.820 4 |
| 0.1 | 0.737 4 | 0.821 9 |
| 0.01 | 0.735 8 | 0.821 1 |
| 直接累加 | 0.737 2 | 0.818 5 |
| | Book-Crossing | Last.FM |
|---|---|---|
| 2 | 0.725 5 | 0.806 3 |
| 4 | 0.729 7 | 0.807 2 |
| 8 | 0.735 4 | 0.813 5 |
| 16 | 0.737 4 | 0.819 0 |
| 32 | 0.736 4 | 0.819 6 |
| 64 | 0.735 5 | 0.821 9 |
Table 5 Impact of K - u sampled value per hop on AUC value at user end
| | Book-Crossing | Last.FM |
|---|---|---|
| 2 | 0.725 5 | 0.806 3 |
| 4 | 0.729 7 | 0.807 2 |
| 8 | 0.735 4 | 0.813 5 |
| 16 | 0.737 4 | 0.819 0 |
| 32 | 0.736 4 | 0.819 6 |
| 64 | 0.735 5 | 0.821 9 |
| | Book-Crossing | Last.FM |
|---|---|---|
| 1 | 0.670 2 | 0.749 2 |
| 2 | 0.680 0 | 0.741 6 |
| 3 | 0.690 1 | 0.754 5 |
| 4 | 0.689 4 | 0.739 7 |
| 5 | 0.691 3 | 0.752 6 |
| 6 | 0.691 4 | 0.746 8 |
| 8 | 0.689 6 | 0.745 6 |
Table 6 Impact of K - i sampled value per hop on ACC value at item end
| | Book-Crossing | Last.FM |
|---|---|---|
| 1 | 0.670 2 | 0.749 2 |
| 2 | 0.680 0 | 0.741 6 |
| 3 | 0.690 1 | 0.754 5 |
| 4 | 0.689 4 | 0.739 7 |
| 5 | 0.691 3 | 0.752 6 |
| 6 | 0.691 4 | 0.746 8 |
| 8 | 0.689 6 | 0.745 6 |
| | Book-Crossing | Last.FM |
|---|---|---|
| 1 | 0.733 3 | 0.806 2 |
| 2 | 0.734 1 | 0.808 0 |
| 3 | 0.737 4 | 0.821 9 |
| 4 | 0.735 7 | 0.811 4 |
Table 7 Impact of user end aggregation hops H - u on AUC value
| | Book-Crossing | Last.FM |
|---|---|---|
| 1 | 0.733 3 | 0.806 2 |
| 2 | 0.734 1 | 0.808 0 |
| 3 | 0.737 4 | 0.821 9 |
| 4 | 0.735 7 | 0.811 4 |
| | Book-Crossing | Last.FM |
|---|---|---|
| 1 | 0.690 1 | 0.754 5 |
| 2 | 0.444 1 | 0.733 3 |
| 3 | 0.445 0 | 0.734 3 |
| 4 | 0.447 2 | 0.732 8 |
Table 8 Impact of item end aggregation hops H - i on ACC value
| | Book-Crossing | Last.FM |
|---|---|---|
| 1 | 0.690 1 | 0.754 5 |
| 2 | 0.444 1 | 0.733 3 |
| 3 | 0.445 0 | 0.734 3 |
| 4 | 0.447 2 | 0.732 8 |
| | Book-Crossing | Last.FM |
|---|---|---|
| 4 | 0.739 1 | 0.806 2 |
| 8 | 0.736 7 | 0.819 5 |
| 16 | 0.735 5 | 0.821 9 |
| 32 | 0.737 4 | 0.820 6 |
| 64 | 0.736 3 | 0.814 5 |
| 128 | 0.734 4 | 0.815 9 |
Table 9 Influence of vector dimension value d on AUC value
| | Book-Crossing | Last.FM |
|---|---|---|
| 4 | 0.739 1 | 0.806 2 |
| 8 | 0.736 7 | 0.819 5 |
| 16 | 0.735 5 | 0.821 9 |
| 32 | 0.737 4 | 0.820 6 |
| 64 | 0.736 3 | 0.814 5 |
| 128 | 0.734 4 | 0.815 9 |
| [1] | KOREN Y, BELL R, VOLINSKY C. Matrix factorization techniques for recommender systems[J]. Computer, 2009, 42(8): 30-37. |
| [2] | SHI Y, LARSON M, HANJALIC A. Collaborative filtering beyond the user-item matrix[J]. ACM Computing Surveys, 2014, 47(1): 1-45. |
| [3] | MOHSEN J, MARTIN E. A matrix factorization technique with trust propagation for recommendation in social networks[C]// Proceedings of the 4th ACM Conference on Recom-mender Systems, Barcelona, Spain, Sep 26-30, 2010. New York: ACM, 2010: 135-142. |
| [4] | WANG H, WANG J, ZHAO M, et al. Joint topic-semantic-aware social recommendation for online voting[C]// Procee-dings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, Nov 6-10, 2017. New York: ACM, 2017: 347-356. |
| [5] | WANG H, ZHANG F, HOU M, et al. Shine: signed hetero-geneous information network embedding for sentiment link prediction[C]// Proceedings of the 11th ACM International Conference on Web Search and Data Mining, Los Angeles, Feb 5-9, 2018. New York: ACM, 2018: 592-600. |
| [6] |
WANG Q, MAO Z, WANG B, et al. Knowledge graph em-bedding: a survey of approaches and applications[J]. IEEE Transactions on Knowledge and Data Engineering, 2017, 29(12): 2724-2743.
DOI URL |
| [7] | WANG H, ZHANG F, XIE X, et al. DKN: deep knowledge-aware network for news recommendation[C]// Proceedings of the 2018 World Wide Web Conference, Lyon, Apr 23-27, 2018. New York: ACM, 2018: 1835-1844. |
| [8] | WANG H, ZHANG F, WANG J, et al. RippleNet: propagating user preferences on the knowledge graph for recommender systems[C]// Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Oct 22-26, 2018. New York: ACM, 2018: 417-426. |
| [9] | WANG H, ZHANG F, WANG J, et al. Exploring high-order user preference on the knowledge graph for recommender systems[J]. ACM Transactions on Information Systems, 2019, 37(3): 1-26. |
| [10] | WANG H, ZHAO M, XIE X, et al. Knowledge graph convo-lutional networks for recommender systems[C]// Proceedings of the 2019 World Wide Web Conference, San Francisco, May 13-17, 2019. New York: ACM, 2019: 3307-3313. |
| [11] | WANG H, ZHANG F, ZHANG M, et al. Knowledge-aware graph neural networks with label smoothness regularization for recommender systems[C]// Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, Aug 4-8, 2019. New York: ACM, 2019: 968-977. |
| [12] | WANG X, WANG D, XU C, et al. Explainable reasoning over knowledge graphs for recommendation[C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence, the 31st Innovative Applications of Artificial Intelligence Con-ference, the 9th AAAI Symposium on Educational Adv-ances in Artificial Intelligence, Honolulu, Jan 27-Feb 1, 2019. Menlo Park: AAAI, 2019: 5329-5336. |
| [13] | WANG X, HE X N, CAO Y X, et al. KGAT: knowledge graph attention network for recommendation[C]// Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, Aug 4-8, 2019. New York: ACM, 2019: 950-958. |
| [14] | RENDLE S. Factorization machines with LibFM[J]. ACM Transactions on Intelligent Systems and Technology, 2012, 3(3): 57. |
| [15] | CHENG H T, KOC L, HARMSEN J, et al. Wide & deep learning for recommender systems[C]// Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, Sep 15, 2016. New York: ACM, 2016: 7-10. |
| [1] | YU Huilin, CHEN Wei, WANG Qi, GAO Jianwei, WAN Huaiyu. Knowledge Graph Link Prediction Based on Subgraph Reasoning [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(8): 1800-1808. |
| [2] | SA Rina, LI Yanling, LIN Min. Survey of Question Answering Based on Knowledge Graph Reasoning [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(8): 1727-1741. |
| [3] | TIAN Xuan, CHEN Hangxue. Survey on Applications of Knowledge Graph Embedding in Recommendation Tasks [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(8): 1681-1705. |
| [4] | HAN Yi, QIAO Linbo, LI Dongsheng, LIAO Xiangke. Review of Knowledge-Enhanced Pre-trained Language Models [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(7): 1439-1461. |
| [5] | GUO Xiaowang, XIA Hongbin, LIU Yuan. Hybrid Recommendation Model of Knowledge Graph and Graph Convolutional Network [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(6): 1343-1353. |
| [6] | DONG Wenbo, SUN Shiliang, YIN Minzhi. Research and Development of Medical Knowledge Graph Reasoning [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(6): 1193-1213. |
| [7] | ZHANG Zichen, YUE Kun, QI Zhiwei, DUAN Liang. Incremental Construction of Time-Series Knowledge Graph [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(3): 598-607. |
| [8] | LI Xiang, YANG Xingyao, YU Jiong, QIAN Yurong, ZHENG Jie. Double End Knowledge Graph Convolutional Networks for Recommender Systems [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(1): 176-184. |
| [9] | WU Zhengyang, TANG Yong, LIU Hai. Survey of Personalized Learning Recommendation [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(1): 21-40. |
| [10] | WU Jiawei, SUN Yanchun. Recommendation System for Medical Consultation Integrating Knowledge Graph and Deep Learning Methods [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(8): 1432-1440. |
| [11] | GAO Yang, LIU Yuan. Recommendation Algorithm Combining Knowledge Graph and Short-Term Preferences [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(6): 1133-1144. |
| [12] | SHU Shitai, LI Song, HAO Xiaohong, ZHANG Liping. Knowledge Graph Embedding Technology: A Review [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(11): 2048-2062. |
| [13] | CHEN Zirui, WANG Xin, WANG Lin, XU Dawei, JIA Yongzhe. Survey of Open-Domain Knowledge Graph Question Answering [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(10): 1843-1869. |
| [14] | LIN Qika, ZHANG Lingling, LIU Jun, ZHAO Tianzhe. Question-aware Graph Convolutional Network for Educational Knowledge Base Question Answering [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(10): 1880-1887. |
| [15] | HAN Xinxin, BEN Kerong, ZHANG Xian. Research on Named Entity Recognition Technology in Military Software Testing [J]. Journal of Frontiers of Computer Science and Technology, 2020, 14(5): 740-748. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
/D:/magtech/JO/Jwk3_kxyts/WEB-INF/classes/