
Journal of Frontiers of Computer Science and Technology ›› 2022, Vol. 16 ›› Issue (4): 775-790.DOI: 10.3778/j.issn.1673-9418.2108079
• Surveys and Frontiers • Previous Articles Next Articles
PEI Lishen1, ZHAO Xuezhuan2,+( )
)
Received:2021-08-23
Revised:2021-11-03
Online:2022-04-01
Published:2021-11-08
About author:PEI Lishen, born in 1988, Ph.D., lecturer, M.S. supervisor, member of CCF. Her research interests include action recognition, image processing, computer vision and machine learning.Supported by:
裴利沈1, 赵雪专2,+()
通讯作者:
+ E-mail: xuezhuansci@126.com作者简介:裴利沈(1988—),女,河南郑州人,博士,讲师,硕士生导师,CCF会员,主要研究方向为行为识别、图像处理、计算机视觉、机器学习。基金资助:CLC Number:
PEI Lishen, ZHAO Xuezhuan. Survey of Collective Activity Recognition Based on Deep Learning[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(4): 775-790.
裴利沈, 赵雪专. 群体行为识别深度学习方法研究综述[J]. 计算机科学与探索, 2022, 16(4): 775-790.
Add to citation manager EndNote|Ris|BibTeX
URL: http://fcst.ceaj.org/EN/10.3778/j.issn.1673-9418.2108079

Fig.1 Workflow of deep recognition of collective activity

Fig.2 Comparison of 2D and 3D convolutions
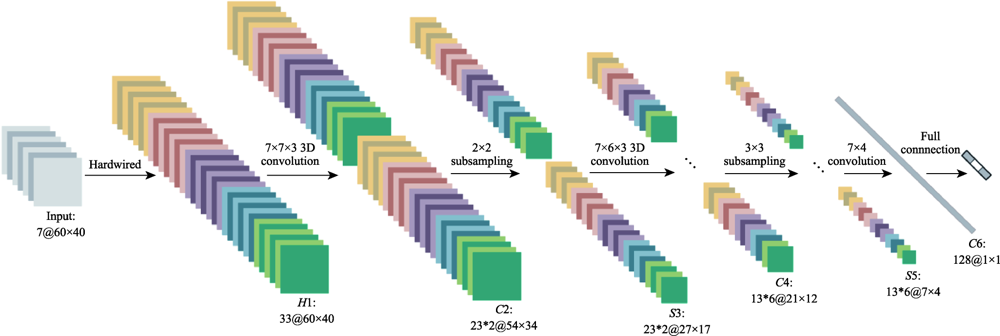
Fig.3 3DCNN architecture for activity recognition
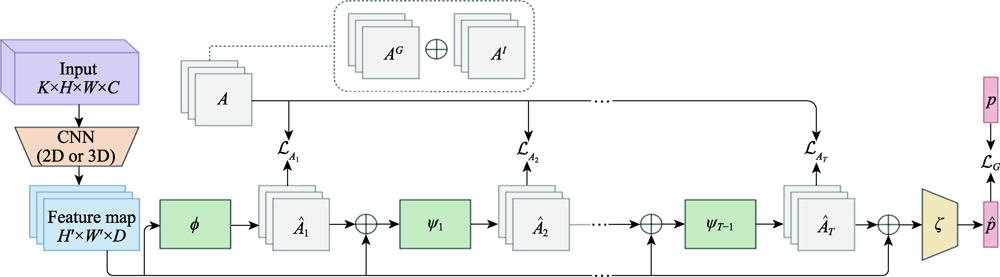
Fig.4 CRM architecture for group activity recognition

Fig.5 Two-stream network architecture

Fig.6 Temporal segment network

Fig.7 Hierarchical recurrent interactional context encoding framework
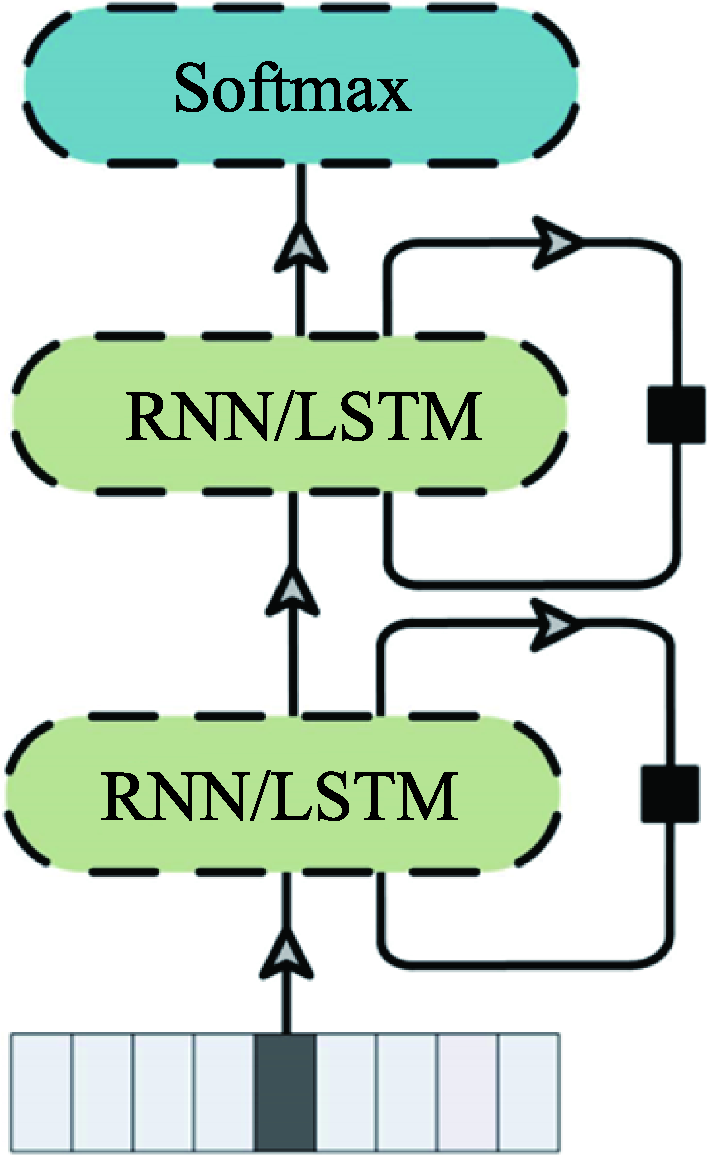
Fig.8 Recurrent neural network architecture of action recognition

Fig.9 Collective activity recognition framework based on temporal consistency detection

Fig.10 Hierarchical recurrent interactional context modeling framework

Fig.11 Architecture of Transformer model
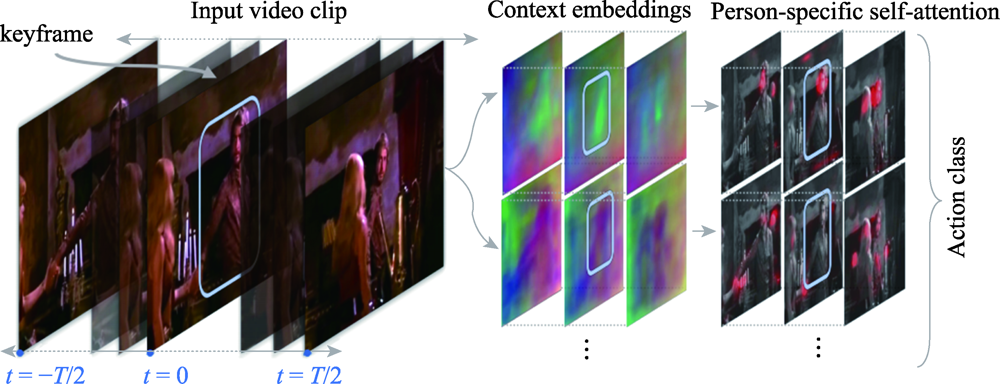
Fig.12 Action Transformer in action recognition

Fig.13 Actor Transformers architecture in group activity recognition
| Architecture | Advantages | Disadvantages |
|---|---|---|
| CNN/3DCNN | 1. 擅于空间域/时空域特征表征 2. 通用、紧凑、易于实现 3. 高效 | 1. 视频数据计算开销大 2. 特征表征能力低于双流网络 |
| Two-Stream Network | 1. 空间域与时间域信息全面表征 2. 识别率效果好 | 1. 分别对RGB和光流数据处理,计算量大 2. 两网络分别训练,时间开销大 |
| RNN/LSTM | 1. 擅长处理长度不一的序列数据 2. 易于与其他架构结合 | 1. 数据需求量大,训练困难 2. 计算费时,对硬件要求高 |
| Transformer | 1. 擅长时序数据处理,可并行计算 2. 不必依赖CNN,可直接对图像块序列分类 | 1. 不能利用序列顺序信息,引入位置嵌入 2. 在群体行为识别领域的应用尚不成熟 |
Table 1 Comparison of deep learning architectures
| Architecture | Advantages | Disadvantages |
|---|---|---|
| CNN/3DCNN | 1. 擅于空间域/时空域特征表征 2. 通用、紧凑、易于实现 3. 高效 | 1. 视频数据计算开销大 2. 特征表征能力低于双流网络 |
| Two-Stream Network | 1. 空间域与时间域信息全面表征 2. 识别率效果好 | 1. 分别对RGB和光流数据处理,计算量大 2. 两网络分别训练,时间开销大 |
| RNN/LSTM | 1. 擅长处理长度不一的序列数据 2. 易于与其他架构结合 | 1. 数据需求量大,训练困难 2. 计算费时,对硬件要求高 |
| Transformer | 1. 擅长时序数据处理,可并行计算 2. 不必依赖CNN,可直接对图像块序列分类 | 1. 不能利用序列顺序信息,引入位置嵌入 2. 在群体行为识别领域的应用尚不成熟 |
| Method | Module | Architecture | Average recognition accuracy/% | |
|---|---|---|---|---|
| Volleyball | Collective Activity | |||
| Ibrahim et al[ | CNN、LSTM | CNN/3DCNN+LSTM | 51.1 | 81.5 |
| Bagautdinov et al[ | FCN、RNN | CNN/3DCNN+RNN | 89.9 | — |
| Hu et al[ | SRG、FD、RG | — | — | 91.4 |
| Wu et al[ | CNN、GCN | CNN/3DCNN | 91.5 | 90.2 |
| Gavrilyuk et al[ | CNN、3DCNN、I3D、Transformer | CNN+Transformer | 94.4 | 92.8 |
| Ibrahim et al[ | CNN、HRN、RCRG | CNN/3DCNN | 89.5 | — |
| Azar et al[ | CNN、CRM | CNN/3DCNN | 93.0 | 85.8 |
| Wang et al[ | SCNN、MCNN、LSTM | Two-Stream Network+LSTM | — | 89.4 |
| Zalluhoglu et al[ | SCNN、SRCNN、TCNN、TRCNN | Two-Stream Network | 72.4 | 88.9 |
| Shu et al[ | CNN、LSTM | CNN/3DCNN+LSTM | 83.6 | 88.3 |
| Qi et al[ | RPN、RNN | RNN/LSTM | 89.3 | 89.1 |
| Deng et al[ | CNN、RNN | CNN/3DCNN+RNN/LSTM | — | 81.2 |
Table 2 Average recognition accuracy comparison of algorithms
| Method | Module | Architecture | Average recognition accuracy/% | |
|---|---|---|---|---|
| Volleyball | Collective Activity | |||
| Ibrahim et al[ | CNN、LSTM | CNN/3DCNN+LSTM | 51.1 | 81.5 |
| Bagautdinov et al[ | FCN、RNN | CNN/3DCNN+RNN | 89.9 | — |
| Hu et al[ | SRG、FD、RG | — | — | 91.4 |
| Wu et al[ | CNN、GCN | CNN/3DCNN | 91.5 | 90.2 |
| Gavrilyuk et al[ | CNN、3DCNN、I3D、Transformer | CNN+Transformer | 94.4 | 92.8 |
| Ibrahim et al[ | CNN、HRN、RCRG | CNN/3DCNN | 89.5 | — |
| Azar et al[ | CNN、CRM | CNN/3DCNN | 93.0 | 85.8 |
| Wang et al[ | SCNN、MCNN、LSTM | Two-Stream Network+LSTM | — | 89.4 |
| Zalluhoglu et al[ | SCNN、SRCNN、TCNN、TRCNN | Two-Stream Network | 72.4 | 88.9 |
| Shu et al[ | CNN、LSTM | CNN/3DCNN+LSTM | 83.6 | 88.3 |
| Qi et al[ | RPN、RNN | RNN/LSTM | 89.3 | 89.1 |
| Deng et al[ | CNN、RNN | CNN/3DCNN+RNN/LSTM | — | 81.2 |
| Dataset | Video number | Collective activity number | Person-level activity number | Activity description |
|---|---|---|---|---|
| The Volleyball Dataset | 55 | 8 | 9 | Sports activity |
| The Collective Activity Dataset | 44 | 5 | 8 | Daily activity |
| The Collective Activity Extended Dataset | 75 | 6 | 8 | Daily activity |
| The Choi’s New Dataset | 32 | 6 | 3 | Daily activity |
| The Nursing Home Dataset | 80 | 2 | 6 | Daily activity |
| UCLA Courtyard Dataset | 106 min | 6 | 10 | Daily activity |
| Broadcast Field Hockey Dataset | 58 | 3 | 11 | Sports activity |
Table 3 Public dataset description
| Dataset | Video number | Collective activity number | Person-level activity number | Activity description |
|---|---|---|---|---|
| The Volleyball Dataset | 55 | 8 | 9 | Sports activity |
| The Collective Activity Dataset | 44 | 5 | 8 | Daily activity |
| The Collective Activity Extended Dataset | 75 | 6 | 8 | Daily activity |
| The Choi’s New Dataset | 32 | 6 | 3 | Daily activity |
| The Nursing Home Dataset | 80 | 2 | 6 | Daily activity |
| UCLA Courtyard Dataset | 106 min | 6 | 10 | Daily activity |
| Broadcast Field Hockey Dataset | 58 | 3 | 11 | Sports activity |
| Dataset | Year | Best average accuracy/% | Corresponding algorithm |
|---|---|---|---|
| The Collective Activity Dataset | 2009 | 92.8 | Gavrilyuk et al[ |
| The Collective Activity Extended Dataset | 2011 | 91.2 | Lu et al[ |
| The Choi’s New Dataset | 2012 | 89.2 | Lu et al[ |
| UCLA Courtyard Dataset | 2012 | 86.9 | Qi et al[ |
| The Nursing Home Dataset | 2012 | 85.5 | Deng et al[ |
| Broadcast Field Hockey Dataset | 2012 | 62.9 | Lan et al[ |
| The Volleyball Dataset | 2016 | 94.4 | Gavrilyuk et al[ |
Table 4 Datasets of collective activity analysis and recognition
| Dataset | Year | Best average accuracy/% | Corresponding algorithm |
|---|---|---|---|
| The Collective Activity Dataset | 2009 | 92.8 | Gavrilyuk et al[ |
| The Collective Activity Extended Dataset | 2011 | 91.2 | Lu et al[ |
| The Choi’s New Dataset | 2012 | 89.2 | Lu et al[ |
| UCLA Courtyard Dataset | 2012 | 86.9 | Qi et al[ |
| The Nursing Home Dataset | 2012 | 85.5 | Deng et al[ |
| Broadcast Field Hockey Dataset | 2012 | 62.9 | Lan et al[ |
| The Volleyball Dataset | 2016 | 94.4 | Gavrilyuk et al[ |
| [1] | 国家自然科学基金委员会. 国家自然科学基金“十三五”发展规划[EB/OL]. (2016-06-14)[2021-05-06]. https://www.nsfc.gov.cn/publish/portal0/xxgk/043/info72249.htm. |
| National Natural Science Foundation. The 13th five-year plan of national natural science foundation of China[EB/OL]. (2016-06-14)[2021-05-06]. https://www.nsfc.gov.cn/publish/portal0/xxgk/043/info72249.htm. | |
| [2] | 中国国务院. 国家中长期科学和技术发展规划纲要[EB/OL]. (2006-02-09)[2021-05-06]. http://www.gov.cn/jrzg/2006-02/09/content_183787.htm. |
| China State Council. Outline of the national program for long- and medium-term scientific and technological development[EB/OL]. (2006-02-09)[2021-05-06]. http://www.gov.cn/jrzg/2006-02/09/content_183787.htm. | |
| [3] | 中华人民共和国国民经济和社会发展第十三个五年规划纲要[EB/OL]. 中国工业和信息化部(2016-03-17)[2021-05-06]. http://www.gov.cn/xinwen/2016-03/17/content_5054992.htm. |
| Outline of the 13th five-year plan for National Economic and Social Development of the People’s Republic of China[EB/OL]. Ministry of Industry and Information Technology of China (2016-03-17)[2021-05-06]. http://www.gov.cn/xinwen/2016-03/17/content_5054992.htm. | |
| [4] | TANG J H, SHU X B, YAN R, et al. Coherence constrained graph LSTM for group activity recognition[J]. IEEE Trans-actions on Pattern Analysis and Machine Intelligence, 2022, 44(2):636-647. |
| [5] | IBRAHIM M S, MURALIDHARAN S, DENG Z W, et al. A hierarchical deep temporal model for group activity reco-gnition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 26-Jul 1, 2016. Washington: IEEE Computer Society, 2016: 1971-1980. |
| [6] |
QI M S, WANG Y H, QIN J, et al. stagNet: an attentive semantic RNN for group activity and individual action reco-gnition[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2020, 30(2):549-565.
DOI URL |
| [7] | TANG Y S, LU J W, WANG Z A, et al. Learning semantics-preserving attention and contextual interaction for group activity recognition[J]. IEEE Transactions on Image Pro-cessing, 2019, 28(10):4997-5012. |
| [8] | ZHOU B L, WANG X G, TANG X O. Random field topic model for semantic region analysis in crowded scenes from tracklets[C]// Proceedings of the 24th IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, Jun 21-23, 2011. Washington: IEEE Computer Society, 2011: 3441-3448. |
| [9] | CHOI W, SAVARESE S. Understanding collective activities of people from videos[J]. IEEE Transactions on Pattern Ana-lysis and Machine Intelligence, 2014, 36(6):1242-1257. |
| [10] | RAMANATHAN V, YAO B P, LI F F. Social role discovery in human events[C]// Proceedings of the 2013 IEEE Confer-ence on Computer Vision and Pattern Recognition, Portland, Jun 23-28, 2013. Washington: IEEE Computer Society, 2013: 2475-2482. |
| [11] | CHEN L C, SCHWING A G, YUILLE A L, et al. Learning deep structured models[C]// Proceedings of the 2015 Inter-national Conference on Machine Learning, Lille, Jul 6-11, 2015. New York: ACM, 2015: 1-8. |
| [12] | WU Z R, LIN D H, TANG X O. Deep Markov random field for image modeling[C]// LNCS 9912: Proceedings of the 14th European Conference on Computer Vision, Amsterdam, Oct 11-14, 2016. Cham: Springer, 2016: 295-312. |
| [13] | AMER M R, XIE D, ZHAO M T, et al. Cost-sensitive top-down/bottom-up inference for multiscale activity recognition[C]// LNCS 7575: Proceedings of the 12th European Confer-ence on Computer Vision, Florence, Oct 7-13, 2012. Berlin, Heidelberg: Springer, 2012: 187-200. |
| [14] | SHU T M, XIE D, ROTHROCK B, et al. Joint inference of groups, events and human roles in aerial videos[C]// Pro-ceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, Jun 7-12, 2015. Washington: IEEE Computer Society, 2015: 4576-4584. |
| [15] | BAGAUTDINOV T, ALAHI A, FLEURET F, et al. Social scene understanding: end-to-end multi-person action localiza-tion and collective activity recognition[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 3425-3434. |
| [16] | SIMONYAN K, ZISSERMAN A. Two-stream convolutional networks for action recognition in videos[C]// Proceedings of the Annual Conference on Neural Information Processing Sys-tems, Montreal, Dec 8-13, 2014. Red Hook: Curran Asso-ciates, 2014: 568-576. |
| [17] | FEICHTENHOFER C, PINZ A, ZISSERMAN A, et al. Convolutional two-stream network fusion for video action recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 1933-1941. |
| [18] | WANG M S, NI B B, YANG X K. Recurrent modeling of interaction context for collective activity recognition[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 7408-7416. |
| [19] | HU G Y, CUI B, HE Y, et al. Progressive relation learning for group activity recognition[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 977-986. |
| [20] | BORJA-BORJA L F, LOPEZ J A, SAVAL-CALVO M, et al. Deep learning architecture for group activity recognition using description of local motions[C]// Proceedings of the 2020 International Joint Conference on Neural Networks, Glasgow, Jul 19-24, 2020. Piscataway: IEEE, 2020: 1-8. |
| [21] | SHU X B, ZHANG L Y, SUN Y L, et al. Host-parasite: graph LSTM-in-LSTM for group activity recognition[J]. IEEE Transactions on Neural Networks and Learning Sys-tems, 2021, 32(2):663-674. |
| [22] |
CAO Y, LIU C, HUANG Z, et al. Skeleton-based action recognition with temporal action graph and temporal ada-ptive graph convolution structure[J]. Multimedia Tools and Applications, 2021, 80(19):29139-29162.
DOI URL |
| [23] | JAIN A, ZAMIR A R, SAVARESE S, et al. Structural-RNN: deep learning on spatio-temporal graphs[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 5308-5317. |
| [24] | LIANG X D, SHEN X H, FENG J S, et al. Semantic object parsing with graph LSTM[C]// LNCS 9905: Proceedings of the 14th European Conference on Computer Vision, Amster-dam, Oct 11-14, 2016. Cham: Springer, 2016: 125-143. |
| [25] |
MOESLUND T B, HILTON A, KRÜGER V. A survey of advances in vision-based human motion capture and ana-lysis[J]. Computer Vision and Image Understanding, 2006, 104(2/3):90-126.
DOI URL |
| [26] | POPPE R. A survey on vision-based human action recogni-tion[J]. Image & Vision Computing, 2010, 28(6):976-990. |
| [27] |
TURAGA P, CHELLAPPA R, SUBRAHMANIAN V S, et al. Machine recognition of human activities: a survey[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2008, 18(11):1473-1488.
DOI URL |
| [28] |
JI S, XU W, YANG M, et al. 3D convolutional neural networks for human action recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(1):221-231.
DOI URL |
| [29] | TRAN D, BOURDEV L, FERGUS R, et al. Learning spatio-temporal features with 3D convolutional networks[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Dec 7-13, 2015. Washington: IEEE Computer Society, 2015: 4489-4497. |
| [30] | DONAHUE J, HENDRICKS L A, GUADARRAMA S, et al. Long-term recurrent convolutional networks for visual recognition and description[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, Jun 7-12, 2015. Washington: IEEE Computer Society, 2015: 2625-2634. |
| [31] | GAVRILYUK K, SANFORD R, JAVAN M, et al. Actor-transformers for group activity recognition[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 836-845. |
| [32] | 刘锁兰, 顾嘉晖, 王洪元, 等. 基于关联分区和ST-GCN的人体行为识别[J]. 计算机工程与应用, 2021, 57(13):168-175. |
| LIU S L, GU J H, WANG H Y, et al. Human behavior reco-gnition based on associative partition and ST-GCN[J]. Com-puter Engineering and Applications, 2021, 57(13):168-175. | |
| [33] | 胡根生, 张乐军, 张艳. 结合张量特征和孪生支持向量机的群体行为识别[J]. 北京理工大学学报, 2019, 39(10):1063-1068. |
| HU G S, ZHANG L J, ZHANG Y. Group activity recog-nition based on tensor features and twin support vector machines[J]. Transactions of Beijing Institute of Technology, 2019, 39(10):1063-1068. | |
| [34] |
NÚÑEZ J C, PANTRIGO J J, MONTEMAYOR A S, et al. Convolutional neural networks and long short-term memory for skeleton-based human activity and hand gesture recog-nition[J]. Pattern Recognition, 2018, 76:80-94.
DOI URL |
| [35] | SAHBI H. Learning Chebyshev basis in graph convolu-tional networks for skeleton-based action recognition[J]. arXiv: 2104. 05482, 2021. |
| [36] | KETKAR N, MOOLAYIL J. Convolutional neural networks. In deep learning with Python[EB/OL]. (2021-03-04) [2021-05-06]. https://doi.org/10.1007/978-1-4842-5364-9_6. |
| [37] | WU J C, WANG L M, WANG L, et al. Learning actor rela-tion graphs for group activity recognition[C]// Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, Jun 16-20, 2019. Pisca-taway: IEEE, 2019: 9964-9974. |
| [38] | IBRAHIM M S, MORI G. Hierarchical relational networks for group activity recognition and retrieval[C]// LNCS 11207: Proceedings of the 15th European Conference on Computer Vision, Munich, Sep 8-14, 2018. Cham: Springer, 2018: 742-758. |
| [39] | AZAR S M, ATIGH M G, NICKABADI A, et al. Convo-lutional relational machine for group activity recognition[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 7884-7893. |
| [40] | 李洪均, 丁宇鹏, 李超波, 等. 基于特征融合时序分割网络的行为识别研究[J]. 计算机研究与发展, 2020, 57(1):145-158. |
| LI H J, DING Y P, LI C B, et al. Action recognition of temporal segment network based on feature fusion[J]. Journal of Computer Research and Development, 2020, 57(1):145-158. | |
| [41] | ASAD M, JIANG H, YANG J, et al. Multi-level two-stream fusion-based spatio-temporal attention model for violence detection and localization[J]. International Journal of Pattern Recognition and Artificial Intelligence, 2022, 36(1):1-25. |
| [42] | CHOI W, SHAHID K, SAVARESE S. What are they doing?: Collective activity classification using spatio-temporal rela-tionship among people[C]// Proceedings of the 12th IEEE International Conference on Computer Vision Workshops, Kyoto, Sep 27-Oct 4, 2009. Washington: IEEE Computer Society, 2009: 1282-1289. |
| [43] | KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[C]// Proceedings of the 26th Annual Conference on Neural Infor-mation Processing Systems, Lake Tahoe, Dec 3-6, 2012. Red Hook: Curran Associates, 2012: 1106-1114. |
| [44] | SZEGEDY C, LIU W, JIA Y Q, et al. Going deeper with convolutions[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, Jun 7-12, 2015. Washington: IEEE Computer Society, 2015: 1-9. |
| [45] |
ZALLUHOGLU C, IKIZLER-CINBIS N. Region based multi-stream convolutional neural networks for collective activity recognition[J]. Journal of Visual Communication and Image Representation, 2019, 60:170-179.
DOI URL |
| [46] | GRAVES A, MOHAMED A, HINTON G E. Speech recog-nition with deep recurrent neural networks[C]// Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, May 26-31, 2013. Piscataway: IEEE, 2013: 6645-6649. |
| [47] |
HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8):1735-1780.
DOI URL |
| [48] | GRAVES A, JAITLY N. Towards end-to-end speech reco-gnition with recurrent neural networks[C]// Proceedings of the 31st International Conference on Machine Learning, Beijing, Jun 21-26, 2014. New York: ACM, 2014: 1764-1772. |
| [49] | DAS S, KOPERSKI M, BREMOND F, et al. A fusion of appearance based CNNs and temporal evolution of skeleton with LSTM for daily living action recognition[J]. arXiv: 1802. 00421v1, 2018. |
| [50] |
HERATH S, HARANDI M, PORIKLI F. Going deeper into action recognition: a survey[J]. Image and Vision Computing, 2017, 60:4-21.
DOI URL |
| [51] | RAMANATHAN V, HUANG J, ABU-El-HAIJA S, et al. Detecting events and key actors in multi-person videos[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 3043-3053. |
| [52] | SHU T M, TODOROVIC S, ZHU S C. CERN: confidence-energy recurrent network for group activity recognition[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 4255-4263. |
| [53] | QI M, QIN J, LI A, et al. stagNet: an attentive semantic RNN for group activity recognition[C]// LNCS 11214: Proceedings of the 15th European Conference on Computer Vision, Munich, Sep 8-14, 2018. Cham: Springer, 2018: 101-117. |
| [54] | DENG Z W, VAHDAT A, HU H X, et al. Structure inference machines: recurrent neural networks for analyzing relations in group activity recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Reco-gnition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 4772-4781. |
| [55] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the Annual Conference on Neural Information Processing Systems 2017, Long Beach, Dec 4-9, 2017. Red Hook: Curran Associates, 2017: 5998-6008. |
| [56] | DOERSCH C, GUPTA A, ZISSERMAN A. CrossTrans-formers:spatially-aware few-shot transfer[C]// Proceedings of the 35th Annual Conference on Neural Information Pro-cessing Systems, Dec 6-12, 2020. Montreal: MIT Press, 2020: 1-10. |
| [57] | TAN H, BANSAL M. LXMERT: learning cross-modality encoder representations from transformers[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Con-ference on Natural Language Processing, Hong Kong, China, Nov 3-7, 2019. Stroudsburg: ACL, 2019: 5099-5110. |
| [58] | KUMAR M, WEISSENBORN D, KALCHBRENNER N. Colorization transformer[C]// Proceedings of the 9th Interna-tional Conference on Learning Representations, Sydney, Aug 30-31, 2021: 1-8. |
| [59] | YANG F Z, YANG H, FU J L, et al. Learning texture trans-former network for image super-resolution[C]// Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 5790-5799. |
| [60] | DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: transformers for image reco-gnition at scale[J]. arXiv: 2010. 11929, 2020. |
| [61] | KHAN S, NASEER M, HAYAT M, et al. Transformers in vision: a survey[J]. arXiv: 2101. 01169, 2021. |
| [62] | CHEN H, WANG Y, GUO T, et al. Pre-trained image pro-cessing transformer[J]. arXiv: 2012. 00364, 2020. |
| [63] | WANG X, YESHWANTH C, NIEBNER M. Scene former: indoor scene generation with transformers[J]. arXiv: 2012. 09793, 2020. |
| [64] | LI R, YANG S, ROSS D A, et al. Learn to dance with AIST++: music conditioned 3D dance generation[J]. arXiv: 2101. 08779, 2021. |
| [65] | NEIMARK D, BAR O, ZOHAR M, et al. Video transformer network[J]. arXiv: 2102. 00719, 2021. |
| [66] | GIRDHAR R, CARREIRA J J, DOERSCH C, et al. Video action transformer network[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, Jun 15-20, 2019. Piscataway: IEEE, 2019: 244-253. |
| [67] | CHOI W, SHAHID K, SAVARESE S. Learning context for collective activity recognition[C]// Proceedings of the 24th IEEE Conference on Computer Vision and Pattern Reco-gnition, Colorado Springs, Jun 20-25, 2011. Washington: IEEE Computer Society, 2011: 3273-3280. |
| [68] | CHOI W, SAVARESE S. A unified framework for multi-target tracking and collective activity recognition[C]// LNCS 7575: Proceedings of the 12th European Conference on Computer Vision, Florence, Oct 7-13, 2012. Berlin, Heidel-berg: Springer, 2012: 215-230. |
| [69] | DENG Z W, ZHAI M Y, CHEN L, et al. Deep structured models for group activity recognition[C]// Proceedings of the 2016 British Machine Vision Conference, Swansea, Sep 19-22, 2016. Durham: BMVA Press, 2016: 179. |
| [70] | LAN T, SIGAL L, MORI G. Social roles in hierarchical models for human activity recognition[C]// Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, Jun 16-21, 2012. Washington: IEEE Computer Society, 2012: 1354-1361. |
| [71] |
LU L H, LU Y, YU R Z, et al. GAIM: graph attention interaction model for collective activity recognition[J]. IEEE Transactions on Multimedia, 2020, 22(2):524-539.
DOI URL |
| [1] | AN Fengping, LI Xiaowei, CAO Xiang. Medical Image Classification Algorithm Based on Weight Initialization-Sliding Window CNN [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(8): 1885-1897. |
| [2] | ZENG Fanzhi, XU Luqian, ZHOU Yan, ZHOU Yuexia, LIAO Junwei. Review of Knowledge Tracing Model for Intelligent Education [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(8): 1742-1763. |
| [3] | LIU Yi, LI Mengmeng, ZHENG Qibin, QIN Wei, REN Xiaoguang. Survey on Video Object Tracking Algorithms [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(7): 1504-1515. |
| [4] | ZHAO Xiaoming, YANG Yijiao, ZHANG Shiqing. Survey of Deep Learning Based Multimodal Emotion Recognition [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(7): 1479-1503. |
| [5] | XIA Hongbin, XIAO Yifei, LIU Yuan. Long Text Generation Adversarial Network Model with Self-Attention Mechanism [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(7): 1603-1610. |
| [6] | SUN Fangwei, LI Chengyang, XIE Yongqiang, LI Zhongbo, YANG Caidong, QI Jin. Review of Deep Learning Applied to Occluded Object Detection [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(6): 1243-1259. |
| [7] | LIU Yafen, ZHENG Yifeng, JIANG Lingyi, LI Guohe, ZHANG Wenjie. Survey on Pseudo-Labeling Methods in Deep Semi-supervised Learning [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(6): 1279-1290. |
| [8] | CHENG Weiyue, ZHANG Xueqin, LIN Kezheng, LI Ao. Deep Convolutional Neural Network Algorithm Fusing Global and Local Features [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(5): 1146-1154. |
| [9] | TONG Gan, HUANG Libo. Review of Winograd Fast Convolution Technique Research [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(5): 959-971. |
| [10] | ZHONG Mengyuan, JIANG Lin. Review of Super-Resolution Image Reconstruction Algorithms [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(5): 972-990. |
| [11] | XU Jia, WEI Tingting, YU Ge, HUANG Xinyue, LYU Pin. Review of Question Difficulty Evaluation Approaches [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(4): 734-759. |
| [12] | LU Zhongda, ZHANG Chunda, ZHANG Jiaqi, WANG Zifei, XU Junhua. Identification of Apple Leaf Disease Based on Dual Branch Network [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(4): 917-926. |
| [13] | ZHU Weijie, CHEN Ying. Micro-expression Recognition Convolutional Network for Dual-stream Temporal-Domain Information Interaction [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(4): 950-958. |
| [14] | JIANG Yi, XU Jiajie, LIU Xu, ZHU Junwu. Research on Edge-Guided Image Repair Algorithm [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(3): 669-682. |
| [15] | ZHANG Quangui, HU Jiayan, WANG Li. One Class Collaborative Filtering Recommendation Algorithm Coupled with User Common Characteristics [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(3): 637-648. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
/D:/magtech/JO/Jwk3_kxyts/WEB-INF/classes/