
Journal of Frontiers of Computer Science and Technology ›› 2022, Vol. 16 ›› Issue (9): 1990-2010.DOI: 10.3778/j.issn.1673-9418.2202063
• Surveys and Frontiers • Previous Articles Next Articles
YANG Caidong1, LI Chengyang1,2, LI Zhongbo1,+( ), XIE Yongqiang1, SUN Fangwei1, QI Jin1
), XIE Yongqiang1, SUN Fangwei1, QI Jin1
Received:2022-02-23
Revised:2022-05-26
Online:2022-09-01
Published:2022-09-15
About author:YANG Caidong, born in 1996, M.S. candidate. His research interests include super-resolution reconstruction and object detection.
杨才东1, 李承阳1,2, 李忠博1,+(), 谢永强1, 孙方伟1, 齐锦1
通讯作者:
+ E-mail: zbli2021@163.com作者简介:杨才东(1996—),男,贵州六盘水人,硕士研究生,主要研究方向为超分辨率重建、目标检测。CLC Number:
YANG Caidong, LI Chengyang, LI Zhongbo, XIE Yongqiang, SUN Fangwei, QI Jin. Review of Image Super-resolution Reconstruction Algorithms Based on Deep Learning[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(9): 1990-2010.
杨才东, 李承阳, 李忠博, 谢永强, 孙方伟, 齐锦. 深度学习的图像超分辨率重建技术综述[J]. 计算机科学与探索, 2022, 16(9): 1990-2010.
Add to citation manager EndNote|Ris|BibTeX
URL: http://fcst.ceaj.org/EN/10.3778/j.issn.1673-9418.2202063

Fig.1 Typical SISR model

Fig.2 Pre-upsampling framework
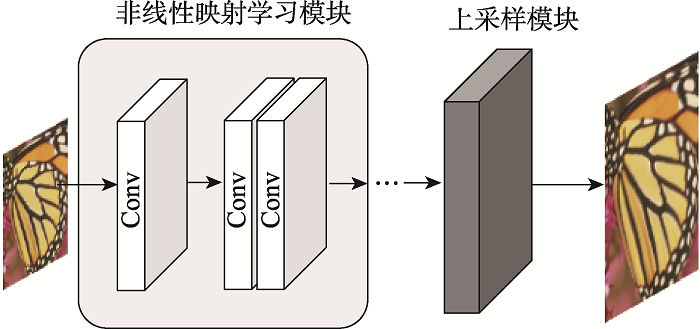
Fig.3 Post-upsampling framework

Fig.4 Progressive upsampling framework

Fig.5 Iterative up-and-down sampling framework

Fig.6 Four different network structures
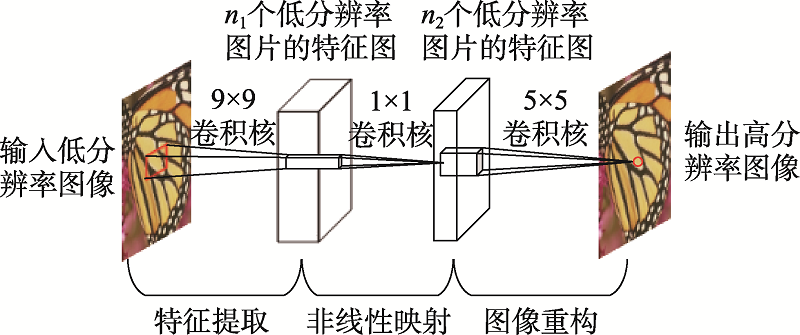
Fig.7 SRCNN structure

Fig.8 Typical RefSR model

Fig.9 Landmark structure

Fig.10 CrossNet structure

Fig.11 SRNTT structure

Fig.12 TTSR structure
| 数据集名称 | 数据集介绍 | 年份 | 期刊 | 图像数量 |
|---|---|---|---|---|
| Set5[ | 5张低复杂度测试图片,常用验证集 | 2014 | ACCV | 5张 |
| Set14[ | 14张测试图片 | 2014 | ACCV | 14张 |
| BSD100[ | 包含植物、人和食物等100张测试图像的经典数据集,是BSD300中的测试集,来源于Berkeley segmentation数据集 | 2002 | IEEE | 100张 |
| Urban100[ | 100张具有各种真实结构的HR图像,具有自相似性,常用验证集 | 2015 | IEEE | 100张 |
| DIV2K[ | 总共1 000张2K高清图片,按照8∶1∶1的比例分成训练、验证和测试图像,涵盖范围广 | 2017 | IEEE | 1 000张 |
| Flickr2K[ | 2 650张图片,包含人物、动物和风景等 | 2017 | CVPR | 2 650张 |
| RealSR[ | 同一场景不同焦距下的LR-HR图像对,并且具有不同的缩放尺度,完成了精准对齐 | 2019 | IEEE | 595对 |
| City100[ | 模拟相机镜头的真实数据集,具有100对LR-HR数据对 | 2020 | IEEE | 100对 |
| DRealSR[ | 具有LR-HR图像对的真实数据集,比RealSR具有更强的多样性、更多的数据 | 2020 | ECCV | 884对×2;783对×3;840对×4 |
Table 1 Introduction to benchmark datasets
| 数据集名称 | 数据集介绍 | 年份 | 期刊 | 图像数量 |
|---|---|---|---|---|
| Set5[ | 5张低复杂度测试图片,常用验证集 | 2014 | ACCV | 5张 |
| Set14[ | 14张测试图片 | 2014 | ACCV | 14张 |
| BSD100[ | 包含植物、人和食物等100张测试图像的经典数据集,是BSD300中的测试集,来源于Berkeley segmentation数据集 | 2002 | IEEE | 100张 |
| Urban100[ | 100张具有各种真实结构的HR图像,具有自相似性,常用验证集 | 2015 | IEEE | 100张 |
| DIV2K[ | 总共1 000张2K高清图片,按照8∶1∶1的比例分成训练、验证和测试图像,涵盖范围广 | 2017 | IEEE | 1 000张 |
| Flickr2K[ | 2 650张图片,包含人物、动物和风景等 | 2017 | CVPR | 2 650张 |
| RealSR[ | 同一场景不同焦距下的LR-HR图像对,并且具有不同的缩放尺度,完成了精准对齐 | 2019 | IEEE | 595对 |
| City100[ | 模拟相机镜头的真实数据集,具有100对LR-HR数据对 | 2020 | IEEE | 100对 |
| DRealSR[ | 具有LR-HR图像对的真实数据集,比RealSR具有更强的多样性、更多的数据 | 2020 | ECCV | 884对×2;783对×3;840对×4 |
| 模型算法 | 超分框架 | 上采样方式 | 网络模型 | 损失函数 | 优点 | 局限性 |
|---|---|---|---|---|---|---|
| SRCNN[ | 前采样 | 三立方插值 | 卷积直连 | MSE损失 | 首次将深度学习引入超分领域,重建效果超过传统算法 | 训练收敛慢,只能完成单一尺度放大,重建图像平滑 |
| FSRCNN[ | 后采样 | 转置卷积 | 卷积直连 | MSE损失 | 速度较SRCNN提高,实时性得到提高 | 依赖于局部的像素信息进行重建,有伪影产生 |
| VDSR[ | 后采样 | 三立方插值 | 残差网络 | MSE损失 | 实现多尺度超分放大 | 对图像进行插值放大再计算,导致巨大的计算量 |
| ESPCN[ | 前采样 | 亚像素卷积 | 卷积直连 | MSE损失 | 网络效率提高,提出了亚像素卷积放大方法,灵活解决了多尺度放大问题 | 重建图像有伪影 |
| SRResNet[ | 后采样 | 亚像素卷积 | 残差网络 | MSE损失 | 解决深层网络难训练问题 | 重建图像光滑 |
| SRGAN[ | 后采样 | 亚像素卷积 | 残差网络 | 感知损失 | 提高图像感知质量 | 模型设计复杂,训练困难 |
| LapSRN[ | 渐进式 | 三立方插值 | 残差网络 | L1损失 | 产生多尺度超分图像,网络拥有更大的感受野 | 重建质量不佳 |
| EDSR[ | 后采样 | 亚像素卷积 | 残差网络 | L1损失 | 增大模型尺寸,降低训练难度 | 推理时间长,实时性差 |
| SRDenseNet[ | 后采样 | 转置卷积 | 残差、稠密网络 | MSE损失 | 减轻梯度消失,增强特征传播能力 | 对所有层进行连接,计算量大 |
| RDN[ | 后采样 | 亚像素卷积 | 残差网络 | L1损失 | 增加网络复杂度,提高主观视觉质量效果 | 采用了稠密连接,计算量大 |
| RCAN[ | 后采样 | 亚像素卷积 | 残差、注意力机制网络 | L1损失 | 通过注意力网络使模型专注于对高频信息的学习 | 引入通道注意机制的同时,将各个卷积层视为单独的过程,忽略了不同层之间的联系 |
| ESRGAN[ | 后采样 | 亚像素卷积 | 残差、稠密网络 | L1损失 | 更稳定的GAN模型,重建高频纹理细节 | 模型设计复杂,训练困难 |
| SAN[ | 后采样 | 亚像素卷积 | 残差、注意力机制网络 | L1损失 | 提出了二阶通道注意力模块,增强了模型的特征表达和特征学习能力,利用非局部加强残差组捕捉长距离空间内容信息 | 计算成本高 |
| SRFBN[ | 后采样 | 转置卷积 | 递归、残差、稠密网络 | L1损失 | 引入反馈机制,前面层可以从后面层中受益 | 通过迭代的方式虽然减少了参数,但是每次迭代都会计算loss和重建图像,计算量大 |
| CDC[ | 渐进式 | 转置卷积 | 递归、残差、注意力机制网络 | 梯度加权损失 | 提高真实世界图像重建质量,对图像不同区域进行针对性训练 | 训练复杂,计算量大 |
| HAN[ | 后采样 | 亚像素卷积 | 残差、注意力机制网络 | L1损失 | 学习不同深度之间特征的关系,提高特征表达能力 | 对不同层、通道和位置之间的特征信息进行建模,参数量多,计算量大 |
| SRFlow[ | 后采样 | 亚像素卷积 | 残差网络 | 对抗损失 内容损失 | 克服了GAN模型易崩溃的问题 | 生成多张近似的图片,计算量大 |
| DFCAN[ | 后采样 | 亚像素卷积 | 残差、注意力机制网络 | 对抗损失 | 提升显微镜下超分重建图像质量 | 设计复杂,专用于显微镜超分 |
| LIIT[ | 后采样 | 亚像素卷积 | 残差网络 | L1损失 | 连续表达学习,实现30倍的放大图像 | 生成图像光滑 |
Table 2 SISR model statistics
| 模型算法 | 超分框架 | 上采样方式 | 网络模型 | 损失函数 | 优点 | 局限性 |
|---|---|---|---|---|---|---|
| SRCNN[ | 前采样 | 三立方插值 | 卷积直连 | MSE损失 | 首次将深度学习引入超分领域,重建效果超过传统算法 | 训练收敛慢,只能完成单一尺度放大,重建图像平滑 |
| FSRCNN[ | 后采样 | 转置卷积 | 卷积直连 | MSE损失 | 速度较SRCNN提高,实时性得到提高 | 依赖于局部的像素信息进行重建,有伪影产生 |
| VDSR[ | 后采样 | 三立方插值 | 残差网络 | MSE损失 | 实现多尺度超分放大 | 对图像进行插值放大再计算,导致巨大的计算量 |
| ESPCN[ | 前采样 | 亚像素卷积 | 卷积直连 | MSE损失 | 网络效率提高,提出了亚像素卷积放大方法,灵活解决了多尺度放大问题 | 重建图像有伪影 |
| SRResNet[ | 后采样 | 亚像素卷积 | 残差网络 | MSE损失 | 解决深层网络难训练问题 | 重建图像光滑 |
| SRGAN[ | 后采样 | 亚像素卷积 | 残差网络 | 感知损失 | 提高图像感知质量 | 模型设计复杂,训练困难 |
| LapSRN[ | 渐进式 | 三立方插值 | 残差网络 | L1损失 | 产生多尺度超分图像,网络拥有更大的感受野 | 重建质量不佳 |
| EDSR[ | 后采样 | 亚像素卷积 | 残差网络 | L1损失 | 增大模型尺寸,降低训练难度 | 推理时间长,实时性差 |
| SRDenseNet[ | 后采样 | 转置卷积 | 残差、稠密网络 | MSE损失 | 减轻梯度消失,增强特征传播能力 | 对所有层进行连接,计算量大 |
| RDN[ | 后采样 | 亚像素卷积 | 残差网络 | L1损失 | 增加网络复杂度,提高主观视觉质量效果 | 采用了稠密连接,计算量大 |
| RCAN[ | 后采样 | 亚像素卷积 | 残差、注意力机制网络 | L1损失 | 通过注意力网络使模型专注于对高频信息的学习 | 引入通道注意机制的同时,将各个卷积层视为单独的过程,忽略了不同层之间的联系 |
| ESRGAN[ | 后采样 | 亚像素卷积 | 残差、稠密网络 | L1损失 | 更稳定的GAN模型,重建高频纹理细节 | 模型设计复杂,训练困难 |
| SAN[ | 后采样 | 亚像素卷积 | 残差、注意力机制网络 | L1损失 | 提出了二阶通道注意力模块,增强了模型的特征表达和特征学习能力,利用非局部加强残差组捕捉长距离空间内容信息 | 计算成本高 |
| SRFBN[ | 后采样 | 转置卷积 | 递归、残差、稠密网络 | L1损失 | 引入反馈机制,前面层可以从后面层中受益 | 通过迭代的方式虽然减少了参数,但是每次迭代都会计算loss和重建图像,计算量大 |
| CDC[ | 渐进式 | 转置卷积 | 递归、残差、注意力机制网络 | 梯度加权损失 | 提高真实世界图像重建质量,对图像不同区域进行针对性训练 | 训练复杂,计算量大 |
| HAN[ | 后采样 | 亚像素卷积 | 残差、注意力机制网络 | L1损失 | 学习不同深度之间特征的关系,提高特征表达能力 | 对不同层、通道和位置之间的特征信息进行建模,参数量多,计算量大 |
| SRFlow[ | 后采样 | 亚像素卷积 | 残差网络 | 对抗损失 内容损失 | 克服了GAN模型易崩溃的问题 | 生成多张近似的图片,计算量大 |
| DFCAN[ | 后采样 | 亚像素卷积 | 残差、注意力机制网络 | 对抗损失 | 提升显微镜下超分重建图像质量 | 设计复杂,专用于显微镜超分 |
| LIIT[ | 后采样 | 亚像素卷积 | 残差网络 | L1损失 | 连续表达学习,实现30倍的放大图像 | 生成图像光滑 |
| 模型算法 | 对齐方法 | 匹配方法 | 融合方法 | 损失函数 | 优点 | 局限性 |
|---|---|---|---|---|---|---|
| Landmark[ | 全局配准 | — | 求解能量最小化 | — | 利用全局匹配,解决了图像内容相似但照明、焦距、镜头透视图等不同造成关联细节不确定性问题 | 参考图像与输入图像分辨率差距过大,影响了模型的学习能力 |
| CrossNet[ | 光流法 | — | 融合解码层 | L1损失 | 解决了Ref图像与LR图像分辨率差距大带来的图像对齐困难的问题 | 仅限于小视差的条件,在光场数据集上可以达到很高的精度,但在处理大视差的情况下效果迅速下降 |
| HCSR[ | 光流法 | — | 混合策略融合 | 重构损失 对抗损失 | 引入SISR方法生成的中间视图,解决跨尺度输入之间的显著分辨率之差引起的变换问题 | 依赖LR于HR之间的对准质量,计算多个视图差会带来巨大的计算量 |
| SSEN[ | 可变性 卷积 | — | RCAN基础网络 | 重构损失 感知损失 对抗损失 | 使用非局部块作为偏移量估计来积极地搜索相似度,可以以多尺度的方式执行像素对齐,并且提出的相似性搜索与提取模块可以插入到现有任何超分网络中 | 利用非局部块来辅助相似度搜索,全局计算意味着巨大的参数量 |
| SS-Net[ | — | 跨尺度对应网络 | 构建一个预测模块,从尺度3到尺度1进行融合 | 交叉熵 损失 | 设计了一个跨尺度对应网络来表示图像之间的匹配,在多个尺度下进行特征融合 | 参考图像与输入图像的相似度直接影响生成图像的质量 |
| SRNTT[ | — | 在自然空间中进行多级匹配 | 结合多级残差网络和亚像素卷积层构成神经结构转移模块 | 重构损失 感知损失 对抗损失 | 根据参考图像的纹理相似度自适应地转换纹理,丰富了HR纹理细节;并且在特征空间进行多级匹配,促进了多尺度神经传输,使得模型即使在参考图像极不相关的情况下性能也只会降低到SISR的级别 | 当相似纹理较少或者图像区域重复时,不能很好地处理,计算成本高 |
| TTSR[ | — | 利用Transformer架构中的注意力结构来完成特征的匹配 | 利用软注意力模块完成特征融合 | 重构损失 感知损失 对抗损失 | 引入了Transformer架构,利用Transformer的注意力机制发现更深层的特征对应,从而可以传递准确的纹理特性 | 当相似纹理较少或者图像区域重复时,不能很好地处理,计算成本高 |
| Cross-MPI[ | — | 平面感知MPI机制 | 对不同深度平面通道进行汇总 | 重构损失 感知损失 内部监督 损失 | 平面感知MPI机制充分利用了场景结构进行有效的基于注意的对应搜索,不需要进行跨尺度立体图像之间的直接匹配或穷举匹配 | 虽然解决了图像之间较大分辨率差异时的高保真超分辨率重建,但是忽略了图像之间在分布上存在的差异产生的影响 |
| MASA[ | — | 利用自然图像局部相关性,由粗到精进行匹配 | 利用双残差聚合模块(DRAM) | 重构损失 感知损失 对抗损失 | 在保持高质量匹配的同时,利用图像的局部相关性,缩小特征空间搜索范围。同时提出了空间自适应模块,使得Ref图像中的有效信息可以更充分地利用 | 基于图像的内容和外观相似度来进行计算,忽略了HR与LR图像之间的底层转换关系 |
| C2-Matching[ | — | 利用图像的增强视图来学习经过底层变换之后的对应关系 | 动态融合模块完成特征融合 | 重构损失 感知损失 对抗损失 | 不仅考虑了图像分辨率差距上带来的影响,还考虑了图像在底层变换过程中导致图像外观发生变换带来的影响,使得模型对大尺度下以及旋转变换等情况都具有较强的鲁棒性 | 模型结构较为复杂,计算量大 |
Table 3 RefSR model statistics
| 模型算法 | 对齐方法 | 匹配方法 | 融合方法 | 损失函数 | 优点 | 局限性 |
|---|---|---|---|---|---|---|
| Landmark[ | 全局配准 | — | 求解能量最小化 | — | 利用全局匹配,解决了图像内容相似但照明、焦距、镜头透视图等不同造成关联细节不确定性问题 | 参考图像与输入图像分辨率差距过大,影响了模型的学习能力 |
| CrossNet[ | 光流法 | — | 融合解码层 | L1损失 | 解决了Ref图像与LR图像分辨率差距大带来的图像对齐困难的问题 | 仅限于小视差的条件,在光场数据集上可以达到很高的精度,但在处理大视差的情况下效果迅速下降 |
| HCSR[ | 光流法 | — | 混合策略融合 | 重构损失 对抗损失 | 引入SISR方法生成的中间视图,解决跨尺度输入之间的显著分辨率之差引起的变换问题 | 依赖LR于HR之间的对准质量,计算多个视图差会带来巨大的计算量 |
| SSEN[ | 可变性 卷积 | — | RCAN基础网络 | 重构损失 感知损失 对抗损失 | 使用非局部块作为偏移量估计来积极地搜索相似度,可以以多尺度的方式执行像素对齐,并且提出的相似性搜索与提取模块可以插入到现有任何超分网络中 | 利用非局部块来辅助相似度搜索,全局计算意味着巨大的参数量 |
| SS-Net[ | — | 跨尺度对应网络 | 构建一个预测模块,从尺度3到尺度1进行融合 | 交叉熵 损失 | 设计了一个跨尺度对应网络来表示图像之间的匹配,在多个尺度下进行特征融合 | 参考图像与输入图像的相似度直接影响生成图像的质量 |
| SRNTT[ | — | 在自然空间中进行多级匹配 | 结合多级残差网络和亚像素卷积层构成神经结构转移模块 | 重构损失 感知损失 对抗损失 | 根据参考图像的纹理相似度自适应地转换纹理,丰富了HR纹理细节;并且在特征空间进行多级匹配,促进了多尺度神经传输,使得模型即使在参考图像极不相关的情况下性能也只会降低到SISR的级别 | 当相似纹理较少或者图像区域重复时,不能很好地处理,计算成本高 |
| TTSR[ | — | 利用Transformer架构中的注意力结构来完成特征的匹配 | 利用软注意力模块完成特征融合 | 重构损失 感知损失 对抗损失 | 引入了Transformer架构,利用Transformer的注意力机制发现更深层的特征对应,从而可以传递准确的纹理特性 | 当相似纹理较少或者图像区域重复时,不能很好地处理,计算成本高 |
| Cross-MPI[ | — | 平面感知MPI机制 | 对不同深度平面通道进行汇总 | 重构损失 感知损失 内部监督 损失 | 平面感知MPI机制充分利用了场景结构进行有效的基于注意的对应搜索,不需要进行跨尺度立体图像之间的直接匹配或穷举匹配 | 虽然解决了图像之间较大分辨率差异时的高保真超分辨率重建,但是忽略了图像之间在分布上存在的差异产生的影响 |
| MASA[ | — | 利用自然图像局部相关性,由粗到精进行匹配 | 利用双残差聚合模块(DRAM) | 重构损失 感知损失 对抗损失 | 在保持高质量匹配的同时,利用图像的局部相关性,缩小特征空间搜索范围。同时提出了空间自适应模块,使得Ref图像中的有效信息可以更充分地利用 | 基于图像的内容和外观相似度来进行计算,忽略了HR与LR图像之间的底层转换关系 |
| C2-Matching[ | — | 利用图像的增强视图来学习经过底层变换之后的对应关系 | 动态融合模块完成特征融合 | 重构损失 感知损失 对抗损失 | 不仅考虑了图像分辨率差距上带来的影响,还考虑了图像在底层变换过程中导致图像外观发生变换带来的影响,使得模型对大尺度下以及旋转变换等情况都具有较强的鲁棒性 | 模型结构较为复杂,计算量大 |
| 算法名称 | 放大倍数 | Set5 | Set14 | BSD100 | Urban100 | ||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | ||
| SRCNN[ | ×2 | 33.66 | 0.954 2 | 32.45 | 0.906 7 | 31.36 | 0.887 9 | 29.50 | 0.894 6 |
| ×3 | 32.75 | 0.909 0 | 29.30 | 0.821 5 | 28.41 | 0.786 3 | 26.24 | 0.798 9 | |
| ×4 | 30.09 | 0.862 7 | 27.18 | 0.786 1 | 26.68 | 0.729 1 | 24.52 | 0.722 1 | |
| FSRCNN[ | ×2 | 37.05 | 0.956 0 | 32.66 | 0.909 0 | 31.53 | 0.892 0 | 29.88 | 0.902 0 |
| ×3 | 33.18 | 0.914 0 | 29.37 | 0.824 0 | 28.53 | 0.791 0 | 26.43 | 0.808 0 | |
| ×4 | 30.71 | 0.865 7 | 27.59 | 0.753 5 | 26.98 | 0.739 8 | 24.62 | 0.728 0 | |
| ESPCN[ | ×2 | 37.00 | 0.955 9 | 32.75 | 0.909 8 | 31.51 | 0.893 9 | 29.87 | 0.906 5 |
| ×3 | 33.02 | 0.913 5 | 29.49 | 0.827 1 | 28.50 | 0.793 7 | 26.41 | 0.816 1 | |
| ×4 | 30.76 | 0.878 4 | 27.66 | 0.800 4 | 27.02 | 0.744 2 | 24.60 | 0.736 0 | |
| VDSR[ | ×2 | 37.53 | 0.958 8 | 33.03 | 0.912 4 | 31.90 | 0.896 0 | 30.76 | 0.914 0 |
| ×3 | 33.68 | 0.920 1 | 29.86 | 0.831 2 | 28.83 | 0.796 6 | 27.15 | 0.831 5 | |
| ×4 | 31.35 | 0.883 8 | 28.01 | 0.767 4 | 27.29 | 0.725 1 | 25.18 | 0.752 4 | |
| SRResNet[ | ×4 | 32.05 | 0.901 9 | 28.49 | 0.818 4 | 27.58 | 0.762 0 | 26.07 | 0.783 9 |
| SRGAN[ | ×4 | 29.40 | 0.847 2 | 26.02 | 0.739 7 | 25.16 | 0.668 8 | — | — |
| EDSR[ | ×2 | 38.11 | 0.960 2 | 33.92 | 0.919 5 | 32.32 | 0.901 3 | 32.93 | 0.935 1 |
| ×3 | 34.65 | 0.928 0 | 30.52 | 0.846 2 | 29.25 | 0.809 3 | 28.80 | 0.865 3 | |
| ×4 | 32.46 | 0.896 8 | 28.80 | 0.787 6 | 27.71 | 0.742 0 | 26.64 | 0.803 3 | |
| SRDenseNet[ | ×4 | 32.02 | 0.893 4 | 28.50 | 0.778 2 | 27.53 | 0.733 7 | 26.05 | 0.781 9 |
| RDN[ | ×2 | 38.24 | 0.961 4 | 34.01 | 0.921 2 | 32.34 | 0.901 7 | 32.89 | 0.935 3 |
| ×3 | 34.71 | 0.929 6 | 30.57 | 0.846 8 | 29.26 | 0.809 3 | 28.80 | 0.865 3 | |
| ×4 | 32.63 | 0.900 2 | 28.87 | 0.788 9 | 27.77 | 0.743 6 | 26.82 | 0.808 7 | |
| RCAN[ | ×2 | 38.27 | 0.961 4 | 34.12 | 0.921 6 | 32.41 | 0.902 7 | 33.34 | 0.938 4 |
| ×3 | 34.74 | 0.929 9 | 30.51 | 0.846 1 | 29.32 | 0.811 1 | 29.09 | 0.870 2 | |
| ×4 | 32.63 | 0.900 2 | 28.87 | 0.788 9 | 27.77 | 0.743 6 | 26.82 | 0.808 7 | |
| ESRGAN[ | ×4 | 32.73 | 0.901 1 | 28.99 | 0.791 7 | 27.85 | 0.745 5 | 27.03 | 0.815 3 |
| SAN[ | ×2 | 38.31 | 0.962 0 | 34.07 | 0.921 3 | 32.42 | 0.902 8 | 33.10 | 0.937 0 |
| ×3 | 34.75 | 0.930 0 | 30.59 | 0.847 6 | 29.33 | 0.811 2 | 28.93 | 0.867 1 | |
| ×4 | 32.64 | 0.900 3 | 28.92 | 0.788 8 | 27.78 | 0.743 6 | 26.79 | 0.806 8 | |
| SRFBN[ | ×2 | 38.11 | 0.960 9 | 33.82 | 0.919 6 | 32.29 | 0.901 0 | 32.62 | 0.932 8 |
| ×3 | 34.70 | 0.929 2 | 30.51 | 0.846 1 | 29.24 | 0.808 4 | 28.73 | 0.864 1 | |
| ×4 | 32.47 | 0.898 3 | 28.81 | 0.786 8 | 27.72 | 0.740 9 | 26.60 | 0.801 5 | |
| HAN[ | ×2 | 38.33 | 0.961 7 | 34.24 | 0.922 4 | 32.45 | 0.903 0 | 33.53 | 0.939 8 |
| ×3 | 34.75 | 0.929 9 | 30.67 | 0.848 3 | 29.32 | 0.811 0 | 29.10 | 0.870 5 | |
| ×4 | 32.64 | 0.900 2 | 28.90 | 0.789 0 | 27.80 | 0.744 2 | 26.85 | 0.809 4 | |
Table 4 Algorithm performance evaluation of SISR
| 算法名称 | 放大倍数 | Set5 | Set14 | BSD100 | Urban100 | ||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | ||
| SRCNN[ | ×2 | 33.66 | 0.954 2 | 32.45 | 0.906 7 | 31.36 | 0.887 9 | 29.50 | 0.894 6 |
| ×3 | 32.75 | 0.909 0 | 29.30 | 0.821 5 | 28.41 | 0.786 3 | 26.24 | 0.798 9 | |
| ×4 | 30.09 | 0.862 7 | 27.18 | 0.786 1 | 26.68 | 0.729 1 | 24.52 | 0.722 1 | |
| FSRCNN[ | ×2 | 37.05 | 0.956 0 | 32.66 | 0.909 0 | 31.53 | 0.892 0 | 29.88 | 0.902 0 |
| ×3 | 33.18 | 0.914 0 | 29.37 | 0.824 0 | 28.53 | 0.791 0 | 26.43 | 0.808 0 | |
| ×4 | 30.71 | 0.865 7 | 27.59 | 0.753 5 | 26.98 | 0.739 8 | 24.62 | 0.728 0 | |
| ESPCN[ | ×2 | 37.00 | 0.955 9 | 32.75 | 0.909 8 | 31.51 | 0.893 9 | 29.87 | 0.906 5 |
| ×3 | 33.02 | 0.913 5 | 29.49 | 0.827 1 | 28.50 | 0.793 7 | 26.41 | 0.816 1 | |
| ×4 | 30.76 | 0.878 4 | 27.66 | 0.800 4 | 27.02 | 0.744 2 | 24.60 | 0.736 0 | |
| VDSR[ | ×2 | 37.53 | 0.958 8 | 33.03 | 0.912 4 | 31.90 | 0.896 0 | 30.76 | 0.914 0 |
| ×3 | 33.68 | 0.920 1 | 29.86 | 0.831 2 | 28.83 | 0.796 6 | 27.15 | 0.831 5 | |
| ×4 | 31.35 | 0.883 8 | 28.01 | 0.767 4 | 27.29 | 0.725 1 | 25.18 | 0.752 4 | |
| SRResNet[ | ×4 | 32.05 | 0.901 9 | 28.49 | 0.818 4 | 27.58 | 0.762 0 | 26.07 | 0.783 9 |
| SRGAN[ | ×4 | 29.40 | 0.847 2 | 26.02 | 0.739 7 | 25.16 | 0.668 8 | — | — |
| EDSR[ | ×2 | 38.11 | 0.960 2 | 33.92 | 0.919 5 | 32.32 | 0.901 3 | 32.93 | 0.935 1 |
| ×3 | 34.65 | 0.928 0 | 30.52 | 0.846 2 | 29.25 | 0.809 3 | 28.80 | 0.865 3 | |
| ×4 | 32.46 | 0.896 8 | 28.80 | 0.787 6 | 27.71 | 0.742 0 | 26.64 | 0.803 3 | |
| SRDenseNet[ | ×4 | 32.02 | 0.893 4 | 28.50 | 0.778 2 | 27.53 | 0.733 7 | 26.05 | 0.781 9 |
| RDN[ | ×2 | 38.24 | 0.961 4 | 34.01 | 0.921 2 | 32.34 | 0.901 7 | 32.89 | 0.935 3 |
| ×3 | 34.71 | 0.929 6 | 30.57 | 0.846 8 | 29.26 | 0.809 3 | 28.80 | 0.865 3 | |
| ×4 | 32.63 | 0.900 2 | 28.87 | 0.788 9 | 27.77 | 0.743 6 | 26.82 | 0.808 7 | |
| RCAN[ | ×2 | 38.27 | 0.961 4 | 34.12 | 0.921 6 | 32.41 | 0.902 7 | 33.34 | 0.938 4 |
| ×3 | 34.74 | 0.929 9 | 30.51 | 0.846 1 | 29.32 | 0.811 1 | 29.09 | 0.870 2 | |
| ×4 | 32.63 | 0.900 2 | 28.87 | 0.788 9 | 27.77 | 0.743 6 | 26.82 | 0.808 7 | |
| ESRGAN[ | ×4 | 32.73 | 0.901 1 | 28.99 | 0.791 7 | 27.85 | 0.745 5 | 27.03 | 0.815 3 |
| SAN[ | ×2 | 38.31 | 0.962 0 | 34.07 | 0.921 3 | 32.42 | 0.902 8 | 33.10 | 0.937 0 |
| ×3 | 34.75 | 0.930 0 | 30.59 | 0.847 6 | 29.33 | 0.811 2 | 28.93 | 0.867 1 | |
| ×4 | 32.64 | 0.900 3 | 28.92 | 0.788 8 | 27.78 | 0.743 6 | 26.79 | 0.806 8 | |
| SRFBN[ | ×2 | 38.11 | 0.960 9 | 33.82 | 0.919 6 | 32.29 | 0.901 0 | 32.62 | 0.932 8 |
| ×3 | 34.70 | 0.929 2 | 30.51 | 0.846 1 | 29.24 | 0.808 4 | 28.73 | 0.864 1 | |
| ×4 | 32.47 | 0.898 3 | 28.81 | 0.786 8 | 27.72 | 0.740 9 | 26.60 | 0.801 5 | |
| HAN[ | ×2 | 38.33 | 0.961 7 | 34.24 | 0.922 4 | 32.45 | 0.903 0 | 33.53 | 0.939 8 |
| ×3 | 34.75 | 0.929 9 | 30.67 | 0.848 3 | 29.32 | 0.811 0 | 29.10 | 0.870 5 | |
| ×4 | 32.64 | 0.900 2 | 28.90 | 0.789 0 | 27.80 | 0.744 2 | 26.85 | 0.809 4 | |
| 算法名称 | CUFED5 | Sun80 | Urban100 | Manga109 | WR-SR | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | |
| CrossNet[ | 25.48 | 0.764 | 28.52 | 0.793 | 25.11 | 0.764 | 23.36 | 0.741 | — | — |
| SRNTT[ | 26.24 | 0.784 | 28.54 | 0.793 | 25.50 | 0.783 | 28.95 | 0.885 | 27.59 | 0.780 |
| TTSR[ | 27.09 | 0.804 | 30.02 | 0.814 | 25.87 | 0.784 | 30.09 | 0.907 | 27.97 | 0.792 |
| MASA[ | 27.54 | 0.814 | 30.15 | 0.815 | 26.09 | 0.786 | — | — | — | — |
| C2-Matching[ | 28.24 | 0.841 | 30.18 | 0.817 | 26.03 | 0.785 | 30.47 | 0.911 | 28.32 | 0.801 |
Table 5 Algorithm performance evaluation of RefSR (×4)
| 算法名称 | CUFED5 | Sun80 | Urban100 | Manga109 | WR-SR | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | |
| CrossNet[ | 25.48 | 0.764 | 28.52 | 0.793 | 25.11 | 0.764 | 23.36 | 0.741 | — | — |
| SRNTT[ | 26.24 | 0.784 | 28.54 | 0.793 | 25.50 | 0.783 | 28.95 | 0.885 | 27.59 | 0.780 |
| TTSR[ | 27.09 | 0.804 | 30.02 | 0.814 | 25.87 | 0.784 | 30.09 | 0.907 | 27.97 | 0.792 |
| MASA[ | 27.54 | 0.814 | 30.15 | 0.815 | 26.09 | 0.786 | — | — | — | — |
| C2-Matching[ | 28.24 | 0.841 | 30.18 | 0.817 | 26.03 | 0.785 | 30.47 | 0.911 | 28.32 | 0.801 |

Fig.13 Comparison of two methods
| [1] | SAJJADI M M, SCHÖLKOPF B, HIRSCH M. EnhanceNet: single image super-resolution through automated texture synt-hesis[C]// Proceedings of the 2017 IEEE International Confe-rence on Computer Vision, Venice, Oct 22-29, 2017. Washin-gton: IEEE Computer Society, 2017: 4501-4510. |
| [2] | DAI D X, WANG Y J, CHEN Y H, et al. Is image super-resolution helpful for other vision tasks?[C]// Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision, Lake Placid, Mar 10, 2016. Washington: IEEE Computer Society, 2016: 1-9. |
| [3] | ISAAC J S, KULKARNI R. Super resolution techniques for medical image processing[C]// Proceedings of the 2015 Inter-national Conference on Technologies for Sustainable Develo-pment, Mumbai, Feb 4-6, 2015. Piscataway: IEEE, 2015: 1-6. |
| [4] |
GREENSPAN H. Super-resolution in medical imaging[J]. The Computer Journal, 2009, 52(1): 43-63.
DOI URL |
| [5] |
ZHANG L P, ZHANG H Y, SHEN H F, et al. A super-reso-lution reconstruction algorithm for surveillance images[J]. Signal Processing, 2010, 90(3): 848-859.
DOI URL |
| [6] |
KEYS R. Cubic convolution interpolation for digital image processing[J]. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1981, 29(6): 1153-1160.
DOI URL |
| [7] |
PARKER J A, KENYON R V, TROXEL D E. Comparison of interpolating methods for image resampling[J]. IEEE Transactions on Medical Imaging, 1983, 2(1): 31-39.
DOI URL |
| [8] | JIANG M, WANG G. Development of iterative algorithms for image reconstruction[J]. Journal of X-ray Science and Technology, 2002, 10(1/2): 77-86. |
| [9] | ZHANG L, YANG J F, XUE B, et al. Improved maximum a posteriori probability estimation method for single image super-resolution reconstruction[J]. Progress in Laser and Optoelectro-nics, 2011, 48(1): 78-85. |
| [10] | 王靖. 流形学习的理论与方法研究[D]. 杭州: 浙江大学, 2006. |
| WANG J. Research on theory and method of manifold lear-ning[D]. Hangzhou: Zhejiang University, 2006. | |
| [11] | WANG Z W, LIU D, YANG J C, et al. Deep networks for image super-resolution with sparse prior[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Dec 7-13, 2015. Washington: IEEE Computer Society, 2015: 370-378. |
| [12] | CHAO D, CHEN C L, HE K M, et al. Learning a deep convo-lutional network for image super-resolution[C]// LNCS 8692: Proceedings of the 13th European Conference on Computer Vision, Zurich, Sep 6-12, 2014. Cham: Springer, 2014: 184-199. |
| [13] | KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[C]// Proceedings of the 26th Annual Conference on Neural Infor-mation Processing Systems, Lake Tahoe, Dec 3-6, 2012. Red Hook: Curran Associates, 2012: 1097-1105. |
| [14] | LEDIG C, THEIS L, HUSZAR F, et al. Photo-realistic single image super-resolution using a generative adversarial network[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 105-114. |
| [15] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st Annual Confe-rence on Neural Information Processing Systems, Long Beach, Dec 4-9, 2017. Red Hook: Curran Associates, 2017: 5998-6008. |
| [16] | YANG F Z, YANG H, FU J L, et al. Learning texture trans-former network for image super-resolution[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 5790-5799. |
| [17] |
WANG Z H, CHEN J, HOI S C H. Deep learning for image super-resolution: a survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(10): 3365-3387.
DOI URL |
| [18] | ZEILER M D, KRISHNAN D, TAYLOR G W, et al. Decon-volutional networks[C]// Proceedings of the 23rd IEEE Confe-rence on Computer Vision and Pattern Recognition, San Fran-cisco, Jun 13-18, 2010. Washington: IEEE Computer Society, 2010: 2528-2535. |
| [19] | SHI W Z, CABALLERO J, HUSZÁR F, et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 1874-1883. |
| [20] | TIMOFTE R, ROTHE R, GOOL L V. Seven ways to improve example-based single image super resolution[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 1865-1873. |
| [21] | ZEYDE R, ELAD M, PROTTER M. On single image scale-up using sparse-representations[C]// LNCS 6920: Proceedings of the 7th International Conference on Curves and Surfaces, Avignon, Jun 24-30, 2010. Berlin, Heidelberg: Springer, 2010: 711-730. |
| [22] | THAPA D, RAAHEMIFAR K, BOBIER W R, et al. A per-formance comparison among different super-resolution tech-niques[J]. Computers & Electrical Engineering, 2016, 54: 313-329. |
| [23] |
YANG J C, WRIGHT J, HUANG T S, et al. Image super-resolution via sparse representation[J]. IEEE Transactions on Image Processing, 2010, 19(11): 2861-2873.
DOI URL |
| [24] | YANG J C, WRIGHT J, HUANG T S, et al. Image super-resolution as sparse representation of raw image patches[C]// Proceedings of the 2008 IEEE Computer Society Con-ference on Computer Vision and Pattern Recognition, Ancho-rage, Jun 24-26, 2008. Washington: IEEE Computer Society, 2008: 1-8. |
| [25] | TIMOFTE R, DE SMET V, VAN GOOL L. A+: adjusted anchored neighborhood regression for fast super-resolution[C]// LNCS 9006: Proceedings of the 12th Asian Conference on Computer Vision, Singapore, Nov 1-5, 2014. Cham: Spri-nger, 2014: 111-126. |
| [26] | 党向盈. 基于传统插值的最佳插值算法分析[J]. 黑龙江科技信息, 2008, 31: 4. |
| DANG X Y. Analysis of optimal interpolation algorithm based on traditional interpolation[J]. Heilongjiang Science and Technology Information, 2008, 31: 4. | |
| [27] | HARIS M, SHAKHNAROVICH G, UKITA N. Deep back-projection networks for super-resolution[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-22, 2018. Piscataway: IEEE, 2018: 1664-1673. |
| [28] | MAO X J, SHEN C H, YANG Y B. Image restoration using very deep convolutional encoder-decoder networks with sym-metric skip connections[C]// Proceedings of the Annual Confe-rence on Neural Information Processing Systems 2016, Bar-celona, Dec 5-10, 2016. Red Hook: Curran Associates, 2016: 2810-2818. |
| [29] | TONG T, LI G, LIU X J, et al. Image super-resolution using dense skip connections[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Oct 22-29, 2017. Washington: IEEE Computer Society, 2017: 4809-4817. |
| [30] | LECUN Y, BOSER B, DENKER J, et al. Backpropagation applied to handwritten zip code recognition[J]. Neural Com-putation, 1989, 1(4): 541-551. |
| [31] | CHAO D, CHEN C L, TANG X. Accelerating the super-resolution convolutional neural network[C]// LNCS 9906: Proceedings of the 14th European Conference on Computer Vision, Amsterdam, Oct 11-14, 2016. Cham: Springer, 2016: 391-407. |
| [32] | SIMONYAN K, ZISSERMAN A. Very deep convolutional net-works for large-scale image recognition[J]. arXiv:1409.1556, 2014. |
| [33] | HE K M, ZHANG X Y, REN S Q, et al. Deep residual lear-ning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 770-778. |
| [34] | KIM J, LEE J K, LEE K M. Accurate image super-reso-lution using very deep convolutional networks[C]// Procee-dings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washin-gton: IEEE Computer Society, 2016: 1646-1654. |
| [35] | LIM B, SON S, KIM H, et al. Enhanced deep residual net-works for single image super-resolution[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, Jul 21-26, 2017. Washing-ton: IEEE Computer Society, 2017: 1132-1140. |
| [36] | HARIS M, SHAKHNAROVICH G, UKITA N. Deep back-projection networks for super-resolution[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-22, 2018. Piscataway: IEEE, 2018: 1664-1673. |
| [37] | ZHANG Y L, LI K P, LI K, et al. Image super-resolution using very deep residual channel attention networks[C]// LNCS 11211: Proceedings of the 15th European Conference on Com-puter Vision, Munich, Sep 8-14, 2018. Cham: Springer, 2018: 286-301. |
| [38] | GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]// Proceedings of the 27th Inter-national Conference on Neural Information Processing System, Dec 8, 2014. Cambridge: MIT Press, 2014: 2672-2680. |
| [39] | MNIH V, KAVUKCUOGLU K, SILVER D, et al. Playing Atari with deep reinforcement learning[J]. arXiv:1312.5602, 2013. |
| [40] |
SILVER, HUANG A, MADDISON C J, et al. Mastering the game of go with deep neural networks and tree search[J]. Nature, 2016, 529(7587): 484-489.
DOI URL |
| [41] | CAO Q X, LIN L, SHI Y K, et al. Attention-aware face hallu-cination via deep reinforcement learning[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 1656-1664. |
| [42] | GOODRICH B, AREL I. Reinforcement learning based visual attention with application to face detection[C]// Proceedings of the 2012 IEEE Computer Society Conference on Com-puter Vision and Pattern Recognition Workshops, Providence, Jun 16-21, 2012. Washington: IEEE Computer Society, 2012: 19-24. |
| [43] | ZAREMBA W, SUTSKEVER I, VINYALS O. Recurrent neural network regularization[J]. arXiv:1409.2329, 2014. |
| [44] | DOSOVITSKIY A, BROX T. Generating images with percep-tual similarity metrics based on deep networks[C]// Procee-dings of the Annual Conference on Neural Information Proce-ssing Systems, Barcelona, Dec 5-10, 2016. Red Hook: Curran Associates, 2016: 658-666. |
| [45] | CABALLERO J, LEDIG C, AITKEN A, et al. Real-time video super-resolution with spatio-temporal networks and motion compensation[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 2848-2857. |
| [46] | YUE H J, SUN X Y, YANG J Y, et al. Landmark image super-resolution by retrieving web images[J]. IEEE Transac-tions on Image Processing, 2013, 22(12): 4865-4878. |
| [47] | ZHU Y, ZHANG Y N, YUILLE A L. Single image super-resolution using deformable patches[C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recog-nition, Columbus, Jun 23-28, 2014. Washington: IEEE Com-puter Society, 2014: 2917-2924. |
| [48] | ZHENG H T, JI M Q, WANG H Q, et al. CrossNet: an end-to-end reference-based super resolution network using cross-scale warping[C]// LNCS 11210: Proceedings of the 15th Euro-pean Conference on Computer Vision, Munich, Sep 8-14, 2018. Cham: Springer, 2018: 87-104. |
| [49] |
ZHAO M D, WU G C, LI Y P, et al. Cross-scale reference-based light field super-resolution[J]. IEEE Transactions on Computational Imaging, 2018, 4(3): 406-418.
DOI URL |
| [50] | SHIM G, PARK J, KWEON I S. Robust reference-based super-resolution with similarity-aware deformable convolu-tion[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 8422-8431. |
| [51] | DAI J F, QI H Z, XIONG Y W, et al. Deformable convo-lutional networks[C]// Proceedings of the 2017 IEEE Interna-tional Conference on Computer Vision, Venice, Oct 22-29, 2017. Washington: IEEE Computer Society, 2017: 764-773. |
| [52] | BARNES C, SHECHTMAN E, FINKELSTEIN A, et al. PatchMatch: a randomized correspondence algorithm for struc-tural image editing[J]. ACM Transactions on Graphics, 2009, 28(3): 24. |
| [53] | ZHENG H T, JI M Q, HAN L, et al. Learning cross-scale correspondence and patch-based synthesis for reference-based super-resolution[C]// Proceedings of the British Machine Vision Conference 2017, Sep 4-7, 2017. Durham: BMVA Press, 2017: 2. |
| [54] | ZHANG Z F, WANG Z W, LIN Z L, et al. Image super-resolution by neural texture transfer[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Reco-gnition, Long Beach, Jun 16-20, 2019. Piscataway: IEEE, 2019: 7982-7991. |
| [55] | ZHOU Y M, WU G C, FU Y, et al. Cross-MPI: cross-scale stereo for image super-resolution using multiplane images[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun 19-25, 2021. Piscataway: IEEE, 2021: 14842-14851. |
| [56] | LU L Y, LI W B, TAO X, et al. MASA-SR: matching accele-ration and spatial adaptation for reference-based image super-resolution[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun 19-25, 2021. Piscataway: IEEE, 2021: 6368-6377. |
| [57] | JIANG Y M, CHAN K C K, WANG X T, et al. Robust refe-rence-based super-resolution via C2-Matching[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun 19-25, 2021. Piscataway: IEEE, 2021: 2103-2112. |
| [58] |
LIU J Y, YANG W H, ZHANG X F, et al. Retrieval com-pensated group structured sparsity for image super-resolution[J]. IEEE Transactions on Multimedia, 2017, 19(2): 302-316.
DOI URL |
| [59] | TIMOFTE R, DESMET VINCENT, VAN GOOLL. Anc-hored neighborhood regression for fast example-based super-resolution[C]// Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Dec 1-8, 2013. Was-hington: IEEE Computer Society, 2013: 1920-1927. |
| [60] | SUN L B, HAYS J. Super-resolution from internet-scale scene matching[C]// Proceedings of the 2012 IEEE International Conference on Computational Photography, Seattle, Apr 28-29, 2012. Washington: IEEE Computer Society, 2012: 1-12. |
| [61] | FREEMAN W T, JONES T R, PASZTOR E C. Example-based super-resolution[J]. IEEE Computer Graphics and Appli-cations, 2002, 22(2): 56-65. |
| [62] | CHANG H, YEUNG D Y, XIONG Y. Super-resolution through neighbor embedding[C]// Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, with CD-ROM, Washington, Jun 27-Jul 2, 2004. Washington: IEEE Computer Society, 2004: 275-282. |
| [63] | MARTIN D R, FOWLKES C C, TAL D, et al. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics[C]// Proceedings of the 8th International Conference on Computer Vision, Vancouver, Jul 7-14, 2001. Washington: IEEE Computer Society, 2001: 416-423. |
| [64] | HUANG J B, SINGH A, AHUJA N. Single image super-resolution from transformed self-exemplars[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, Jun 7-12, 2015. Washington: IEEE Computer Society, 2015: 5197-5206. |
| [65] | AGUSTSSON E, TIMOFTE R. NTIRE 2017 challenge on single image super-resolution: dataset and study[C]// Procee-dings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 1122-1131. |
| [66] | CAI J R, GU S H, TIMOFTE R, et al. NTIRE 2019 chal-lenge on real image super-resolution: methods and results[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, Jun 16-20, 2019. Piscataway: IEEE, 2019: 2211-2223. |
| [67] | CHEN C, XIONG Z, TIAN X, et al. Camera lens super-resolution[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, Jun 16-20, 2019. Piscataway: IEEE, 2019: 1652-1660. |
| [68] | WEI P X, XIE Z W, LU H N, et al. Component divide-and-conquer for real-world image super-resolution[C]// LNCS 12353: Proceedings of the 16th European Conference on Computer Vision, Glasgow, Aug 23-28, 2020. Cham: Springer, 2020: 101-117. |
| [69] |
WANG Z, BOVIK A C, SHEIKH H R, et al. Image quality assessment: from error visibility to structural similarity[J]. IEEE Transactions on Image Processing, 2004, 13(4): 600-612.
DOI URL |
| [70] | XU X Y, SUN D Q, PAN J S, et al. Learning to super-resolve blurry face and text images[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Oct 22-29, 2017. Washington: IEEE Computer Society, 2017: 251-260. |
| [71] | LAI W S, HUANG J B, AHUJA N, et al. Deep Laplacian pyramid networks for fast and accurate super-resolution[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washin-gton: IEEE Computer Society, 2017: 5835-5843. |
| [72] | ZHANG Y L, TIAN Y P, KONG Y, et al. Residual dense network for image super-resolution[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Reco-gnition, Salt Lake City, Jun 18-22, 2018. Washington: IEEE Computer Society, 2018: 2472-2481. |
| [73] | WANG X T, YU K, WU S X, et al. ESRGAN: enhanced super-resolution generative adversarial networks[C]// LNCS 11133: Proceedings of the 15th European Conference on Computer Vision Workshops, Munich, Sep 8-14, 2018. Cham: Springer, 2018: 63-79. |
| [74] | DAI T, CAI J R, ZHANG Y B, et al. Second-order attention network for single image super-resolution[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, Jun 16-20, 2019. Piscataway: IEEE, 2019: 11065-11074. |
| [75] | LI Z, YANG J L, LIU Z, et al. Feedback network for image super-resolution[C]// Proceedings of the 2019 IEEE/CVF Con-ference on Computer Vision and Pattern Recognition, Long Beach, Jun 16-20, 2019. Piscataway: IEEE, 2019: 3867-3876. |
| [76] | NIU B, WEN W L, REN W Q, et al. Single image super-resolution via a holistic attention network[C]// LNCS 12357: Proceedings of the 16th European Conference on Computer Vision, Glasgow, Aug 23-28, 2020. Cham: Springer, 2020: 191-207. |
| [77] | LUGMAYR A, DANELLJAN M, VAN GOOL L, et al. SRFlow: learning the super-resolution space with normali-zing flow[C]// LNCS 12350: Proceedings of the 16th Euro-pean Conference on Computer Vision, Glasgow, Aug 23-28, 2020. Cham: Springer, 2020: 715-732. |
| [78] |
QIAO C, LI D, GUO Y, et al. Evaluation and development of deep neural networks for image super-resolution in optical microscopy[J]. Nature Methods, 2021, 18(2): 194-202.
DOI URL |
| [79] | CHEN Y B, LIU S F, WANG X L. Learning continuous image representation with local implicit image function[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun 19-25, 2021. Piscataway: IEEE, 2021: 8628-8638. |
| [80] | HAN W, CHANG S Y, LIU D, et al. Image super-resolution via dual-state recurrent networks[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recogni-tion, Salt Lake City, Jun 18-22, 2018. Piscataway: IEEE, 2018: 1654-1663. |
| [81] |
李现国, 冯欣欣, 李建雄. 多尺度残差网络的单幅图像超分辨率重建[J]. 计算机工程与应用, 2021, 57(7): 215-221.
DOI |
| LI X G, FENG X X, LI J X. Sigle image super-resolution reconstruction based on multi-scale residual network[J]. Com-puter Engineering and Applications, 2021, 57(7): 215-221. | |
| [82] | 吕佳, 许鹏程. 多尺度自适应上采样的图像超分辨率重建算法[J/OL]. 计算机科学与探索(2021-10-20)[2022-01-26].http://kns.cnki.net/kcms/detail/11.5602.TP.20211020.1013.002.html. |
| LYU J, XU P C. Image super-resolution reconstruction algo-rithm based on adaptive up-sampling of multi-scale[J]. Journal of Frontiers of Computer Science and Technology (2021-10-20)[2022-01-26].http://kns.cnki.net/kcms/detail/11.5602.TP.20211020.1013.002.html. | |
| [83] | KIM J, LEE J K, LEE K M. Deeply-recursive convolu-tional network for image super-resolution[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 1637-1645. |
| [84] | YING T, JIAN Y, LIU X M. Image super-resolution via deep recursive residual network[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 2790-2798. |
| [85] | RONG C, QU Y Y, ZENG K, et al. Persistent memory resi-dual network for single image super resolution[C]// Procee-dings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, Jun 18-22, 2018. Washington: IEEE Computer Society, 2018: 809-816. |
| [86] | 李灏, 杨志景, 王美林, 等. 噪声和U型判别网络的真实世界图像超分辨率[J/OL]. 计算机工程与应用(2022-01-25)[2022-02-11].https://kns.cnki.net/kcms/detail/11.2127.TP. 20220125.1616.008.html. |
| LI H, YANG Z J, WANG M L, et al. Real world image super-resolution based on noise and U-shaped discriminant network[J/OL]. Computer Engineering and Application (2022-01-25)[2022-02-11].https://kns.cnki.net/kcms/detail/11.2127.TP.20220125.1616.008.html. | |
| [87] | ZHANG X E, CHEN Q F, NG R, et al. Zoom to learn, learn to zoom[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, Jun 16-20, 2019. Piscataway: IEEE, 2019: 3762-3770. |
| [88] | LUO Z W, HUANG H B, YU L, et al. Deep constrained least squares for blind image super-resolution[J]. arXiv:2202.07508, 2022. |
| [89] | ZHANG K, LIANG J Y, VAN GOOL L, et al. Designing a practical degradation model for deep blind image super-resolution[C]// Proceedings of the 2021 IEEE/CVF Interna-tional Conference on Computer Vision, Montreal, Oct 10-17, 2021. Piscataway: IEEE, 2021: 4771-4780. |
| [90] | LIU A R, LIU Y H, GU J J, et al. Blind image super-resolution: a survey and beyond[J]. arXiv:2107.03055, 2021. |
| [91] |
夏皓, 吕宏峰, 罗军, 等. 图像超分辨率深度学习研究及应用进展[J]. 计算机工程与应用, 2021, 57(24): 51-60.
DOI |
|
XIA H, LYU H F, LUO J, et al. Survey on deep learning based image super-resolution[J]. Computer Engineering and Applications, 2021, 57(24): 51-60.
DOI |
|
| [92] | JIANG J J, WANG C Y, LIU X M, et al. Deep learning-based face super-resolution: a survey[J]. ACM Computing Surveys, 2021, 55(1): 1-36. |
| [93] |
LIU S, HOESS P, RIES J. Super-resolution microscopy for structural cell biology[J]. Annual Review of Biophysics, 2022, 51: 301-326.
DOI URL |
| [1] | LYU Xiaoqi, JI Ke, CHEN Zhenxiang, SUN Runyuan, MA Kun, WU Jun, LI Yidong. Expert Recommendation Algorithm Combining Attention and Recurrent Neural Network [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(9): 2068-2077. |
| [2] | ZHANG Xiangping, LIU Jianxun. Overview of Deep Learning-Based Code Representation and Its Applications [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(9): 2011-2029. |
| [3] | LI Dongmei, LUO Sisi, ZHANG Xiaoping, XU Fu. Review on Named Entity Recognition [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(9): 1954-1968. |
| [4] | REN Ning, FU Yan, WU Yanxia, LIANG Pengju, HAN Xi. Review of Research on Imbalance Problem in Deep Learning Applied to Object Detection [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(9): 1933-1953. |
| [5] | ZENG Fanzhi, XU Luqian, ZHOU Yan, ZHOU Yuexia, LIAO Junwei. Review of Knowledge Tracing Model for Intelligent Education [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(8): 1742-1763. |
| [6] | AN Fengping, LI Xiaowei, CAO Xiang. Medical Image Classification Algorithm Based on Weight Initialization-Sliding Window CNN [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(8): 1885-1897. |
| [7] | XIA Hongbin, XIAO Yifei, LIU Yuan. Long Text Generation Adversarial Network Model with Self-Attention Mechanism [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(7): 1603-1610. |
| [8] | LIU Yi, LI Mengmeng, ZHENG Qibin, QIN Wei, REN Xiaoguang. Survey on Video Object Tracking Algorithms [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(7): 1504-1515. |
| [9] | ZHAO Xiaoming, YANG Yijiao, ZHANG Shiqing. Survey of Deep Learning Based Multimodal Emotion Recognition [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(7): 1479-1503. |
| [10] | SUN Fangwei, LI Chengyang, XIE Yongqiang, LI Zhongbo, YANG Caidong, QI Jin. Review of Deep Learning Applied to Occluded Object Detection [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(6): 1243-1259. |
| [11] | LIU Yafen, ZHENG Yifeng, JIANG Lingyi, LI Guohe, ZHANG Wenjie. Survey on Pseudo-Labeling Methods in Deep Semi-supervised Learning [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(6): 1279-1290. |
| [12] | CHENG Weiyue, ZHANG Xueqin, LIN Kezheng, LI Ao. Deep Convolutional Neural Network Algorithm Fusing Global and Local Features [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(5): 1146-1154. |
| [13] | ZHONG Mengyuan, JIANG Lin. Review of Super-Resolution Image Reconstruction Algorithms [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(5): 972-990. |
| [14] | XU Jia, WEI Tingting, YU Ge, HUANG Xinyue, LYU Pin. Review of Question Difficulty Evaluation Approaches [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(4): 734-759. |
| [15] | PEI Lishen, ZHAO Xuezhuan. Survey of Collective Activity Recognition Based on Deep Learning [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(4): 775-790. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
/D:/magtech/JO/Jwk3_kxyts/WEB-INF/classes/