
Journal of Frontiers of Computer Science and Technology ›› 2022, Vol. 16 ›› Issue (5): 1025-1042.DOI: 10.3778/j.issn.1673-9418.2111063
• Surveys and Frontiers • Previous Articles Next Articles
DONG Wenxuan, LIANG Hongtao( ), LIU Guozhu, HU Qiang, YU Xu
), LIU Guozhu, HU Qiang, YU Xu
Received:2021-11-11
Revised:2022-01-24
Online:2022-05-01
Published:2022-05-19
About author:DONG Wenxuan, born in 1997, M.S. candidate, student member of CCF. His research interests include machine learning, computer vision, etc.Supported by:
董文轩, 梁宏涛(), 刘国柱, 胡强, 于旭
通讯作者:
+ E-mail: lht@qust.edu.cn作者简介:董文轩(1997—),男,山东德州人,硕士研究生,CCF学生会员,主要研究方向为机器学习、计算机视觉等。基金资助:CLC Number:
DONG Wenxuan, LIANG Hongtao, LIU Guozhu, HU Qiang, YU Xu. Review of Deep Convolution Applied to Target Detection Algorithms[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(5): 1025-1042.
董文轩, 梁宏涛, 刘国柱, 胡强, 于旭. 深度卷积应用于目标检测算法综述[J]. 计算机科学与探索, 2022, 16(5): 1025-1042.
Add to citation manager EndNote|Ris|BibTeX
URL: http://fcst.ceaj.org/EN/10.3778/j.issn.1673-9418.2111063
| Vehicles | Household | Animals | Other |
|---|---|---|---|
| Aeroplane | Bottle | Bird | Person |
| Bicycle | Chair | Cat | |
| Boat | Dining table | Cow | |
| Bus | Potted plant | Dog | |
| Car | Sofa | Horse | |
| Motorbike | TV/Monitor | Sheep | |
| Train |
Table 1 VOC2012 categories
| Vehicles | Household | Animals | Other |
|---|---|---|---|
| Aeroplane | Bottle | Bird | Person |
| Bicycle | Chair | Cat | |
| Boat | Dining table | Cow | |
| Bus | Potted plant | Dog | |
| Car | Sofa | Horse | |
| Motorbike | TV/Monitor | Sheep | |
| Train |
| 预测值 | 真实值 | |
|---|---|---|
| 正例(Positive) | 负例(Negative) | |
| 正确(True) | TP | TN |
| 错误(False) | FP | FN |
Table 2 Confusion matrix
| 预测值 | 真实值 | |
|---|---|---|
| 正例(Positive) | 负例(Negative) | |
| 正确(True) | TP | TN |
| 错误(False) | FP | FN |
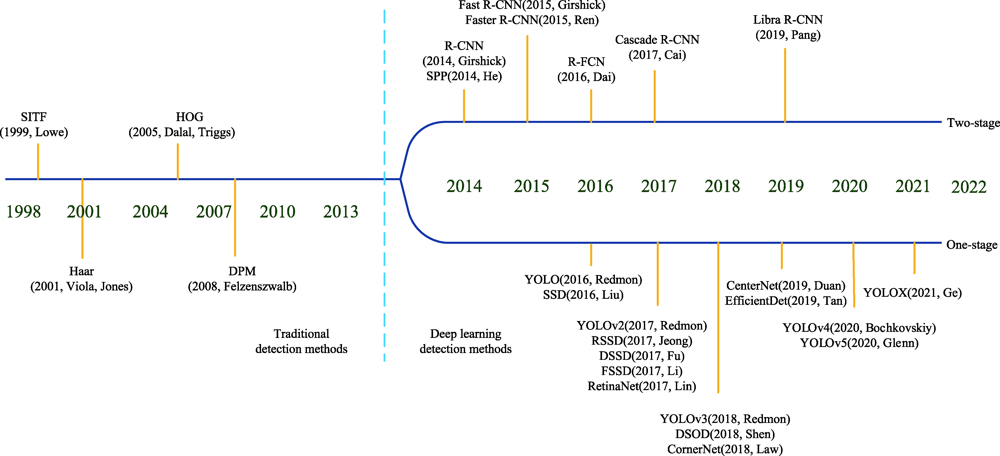
Fig.1 Timeline of target detection algorithm development

Fig.2 R-CNN model structure

Fig.3 Spatial pyramid pooling (SPP)

Fig.4 Fast R-CNN model structure
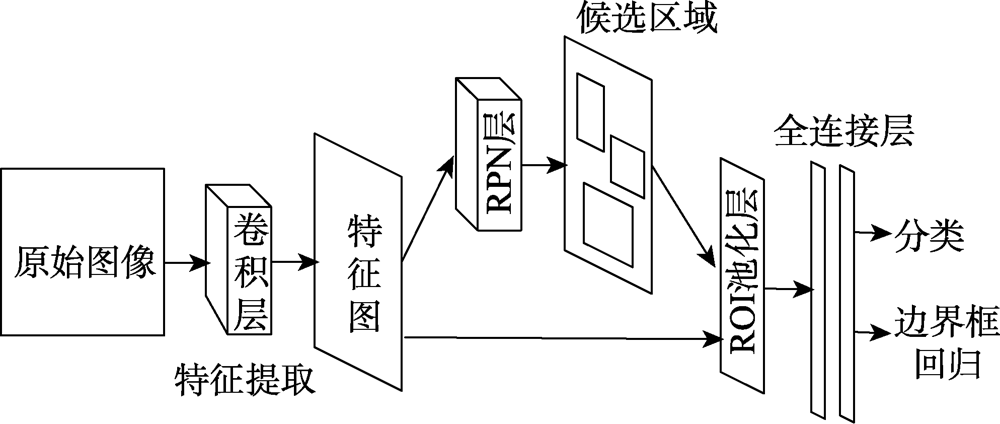
Fig.5 Faster R-CNN model structure

Fig.6 Position-sensitive score maps
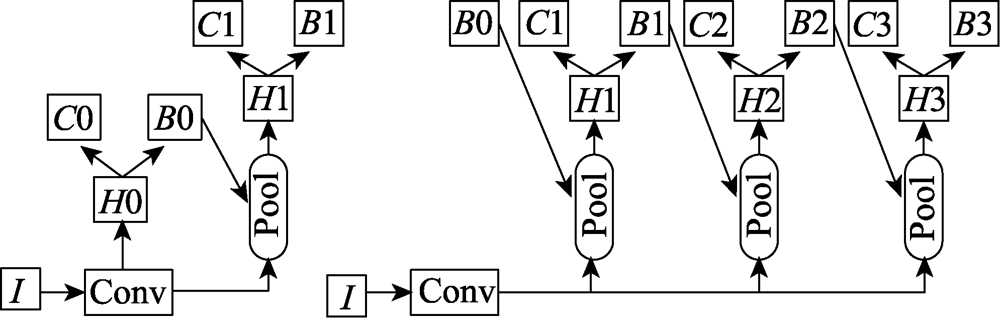
Fig.7 Faster R-CNN and Cascade R-CNN detection architecture

Fig.8 Balanced semantic pyramid
| 算法 | 主干网络 | 检测速率/(frame/s) | GPU | mAP/% | ||
|---|---|---|---|---|---|---|
| VOC2007 | VOC2012 | COCO(mAP@[0.50,0.95]) | ||||
| R-CNN | AlexNet | 0.03 | Titan X | 58.5 (ILSVRC2012[ | — | — |
| VGG16 | 0.50 | Titan X | 66.0 (ILSVRC2012+VOC2007) | — | — | |
| SPPNet | ZF-5 | 2.00 | Titan X | 59.2 (ImageNet2012) | — | — |
| Fast R-CNN | VGG16 | 3.00 | K40 | 70.0 (VOC2007+VOC2012) | 68.4 (VOC2007+VOC2012) | 19.7 (COCO) |
| Faster R-CNN | VGG16 | 7.00 | Titan X | 73.2 (VOC2007+VOC2012) | 70.4 (VOC2007+VOC2012) | 21.9 (COCO) |
| R-FCN | ResNet101 | 5.80 | K40 | 79.5 (VOC2007+VOC2012) | 77.6 (VOC2007+VOC2012) | 29.9 (COCO) |
| Cascade R-CNN | ResNet101 | 7.00 | Titan Xp | — | — | 42.8 (COCO) |
| Libra R-CNN | ResNeXt101[ | — | — | — | — | 43.0(COCO) |
Table 3 Performance comparison of two-stage target detection algorithms
| 算法 | 主干网络 | 检测速率/(frame/s) | GPU | mAP/% | ||
|---|---|---|---|---|---|---|
| VOC2007 | VOC2012 | COCO(mAP@[0.50,0.95]) | ||||
| R-CNN | AlexNet | 0.03 | Titan X | 58.5 (ILSVRC2012[ | — | — |
| VGG16 | 0.50 | Titan X | 66.0 (ILSVRC2012+VOC2007) | — | — | |
| SPPNet | ZF-5 | 2.00 | Titan X | 59.2 (ImageNet2012) | — | — |
| Fast R-CNN | VGG16 | 3.00 | K40 | 70.0 (VOC2007+VOC2012) | 68.4 (VOC2007+VOC2012) | 19.7 (COCO) |
| Faster R-CNN | VGG16 | 7.00 | Titan X | 73.2 (VOC2007+VOC2012) | 70.4 (VOC2007+VOC2012) | 21.9 (COCO) |
| R-FCN | ResNet101 | 5.80 | K40 | 79.5 (VOC2007+VOC2012) | 77.6 (VOC2007+VOC2012) | 29.9 (COCO) |
| Cascade R-CNN | ResNet101 | 7.00 | Titan Xp | — | — | 42.8 (COCO) |
| Libra R-CNN | ResNeXt101[ | — | — | — | — | 43.0(COCO) |
| 算法 | 改进方式 | 优势 | 局限 |
|---|---|---|---|
| R-CNN | CNN应用于目标检测,选择性搜索算法,SVM分类,NMS筛选 | 开辟深度学习在目标检测方面的应用,性能优于传统目标检测算法 | 效率低,存储空间需求大,各个模块之间独立,丢失原图信息 |
| SPPNet | 提出空间金字塔 | 减少计算量,检测速度提高,移除对网络固定尺寸的限制 | 存储空间需求大,训练繁琐,改进局限于全连接层 |
| Fast R-CNN | 引入ROI Pooling,softmax替代SVM | 减少存储空间占用,降低计算复杂度,提高了检测精度 | 耗时耗空间,候选框模块独立 |
| Faster R-CNN | 引入区域建议网络,共享卷积层的特征图,提出了锚框 | 实现端到端的目标检测模型,减少候选框数,减少模型计算量 | 丧失网络平移不变性,对小目标检测较差 |
| R-FCN | 引入位置敏感分数图,对感兴趣区域进行了编码处理 | 使网络具有平移不变性,进一步提高检测精度 | 主干网络模型加深,检测速度慢 |
| Cascade R-CNN | 引入级联架构 | 缓解过拟合,IoU相匹配,减少网络检测噪声,提高检测准确度 | 增加了网络模型的复杂度,延长了网络训练和预测的时间 |
| Libra R-CNN | 引入平衡特征金字塔,采用分桶策略进行平衡采样,Balance L1替代Smooth L1 | 减轻模型因样本数据、特征不平衡而造成的影响,平滑训练时的梯度 | 网络模型更为复杂,无法满足实时的要求 |
Table 4 Overall analysis of two-stage target detection algorithms
| 算法 | 改进方式 | 优势 | 局限 |
|---|---|---|---|
| R-CNN | CNN应用于目标检测,选择性搜索算法,SVM分类,NMS筛选 | 开辟深度学习在目标检测方面的应用,性能优于传统目标检测算法 | 效率低,存储空间需求大,各个模块之间独立,丢失原图信息 |
| SPPNet | 提出空间金字塔 | 减少计算量,检测速度提高,移除对网络固定尺寸的限制 | 存储空间需求大,训练繁琐,改进局限于全连接层 |
| Fast R-CNN | 引入ROI Pooling,softmax替代SVM | 减少存储空间占用,降低计算复杂度,提高了检测精度 | 耗时耗空间,候选框模块独立 |
| Faster R-CNN | 引入区域建议网络,共享卷积层的特征图,提出了锚框 | 实现端到端的目标检测模型,减少候选框数,减少模型计算量 | 丧失网络平移不变性,对小目标检测较差 |
| R-FCN | 引入位置敏感分数图,对感兴趣区域进行了编码处理 | 使网络具有平移不变性,进一步提高检测精度 | 主干网络模型加深,检测速度慢 |
| Cascade R-CNN | 引入级联架构 | 缓解过拟合,IoU相匹配,减少网络检测噪声,提高检测准确度 | 增加了网络模型的复杂度,延长了网络训练和预测的时间 |
| Libra R-CNN | 引入平衡特征金字塔,采用分桶策略进行平衡采样,Balance L1替代Smooth L1 | 减轻模型因样本数据、特征不平衡而造成的影响,平滑训练时的梯度 | 网络模型更为复杂,无法满足实时的要求 |

Fig.9 YOLOv1 model structure

Fig.10 YOLOv3 model structure

Fig.11 YOLOv5 model structure
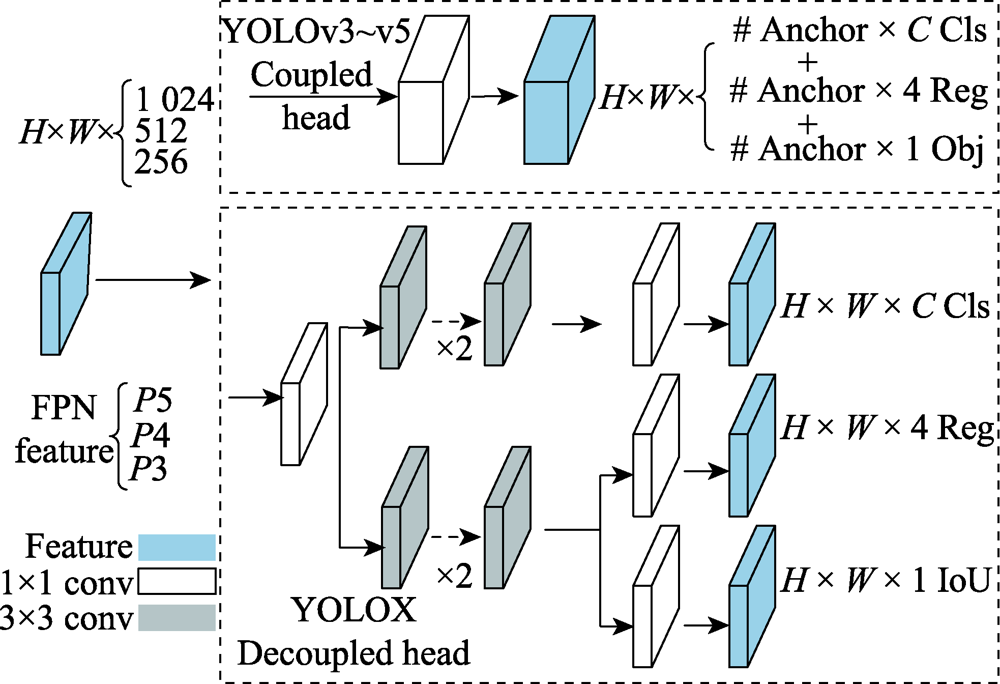
Fig.12 Comparison of structure of YOLO serieshead detection

Fig.13 SSD model structure

Fig.14 DSSD model structure

Fig.15 FSSD model structure
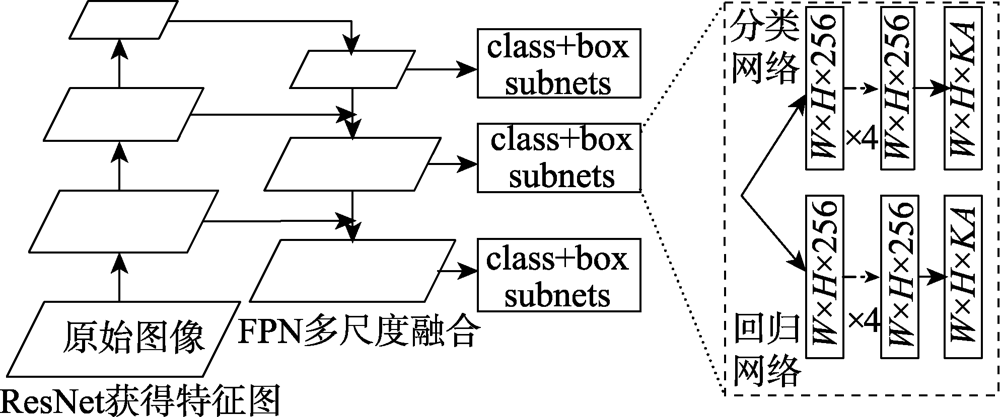
Fig.16 RetinaNet model structure

Fig.17 CornerNet model structure
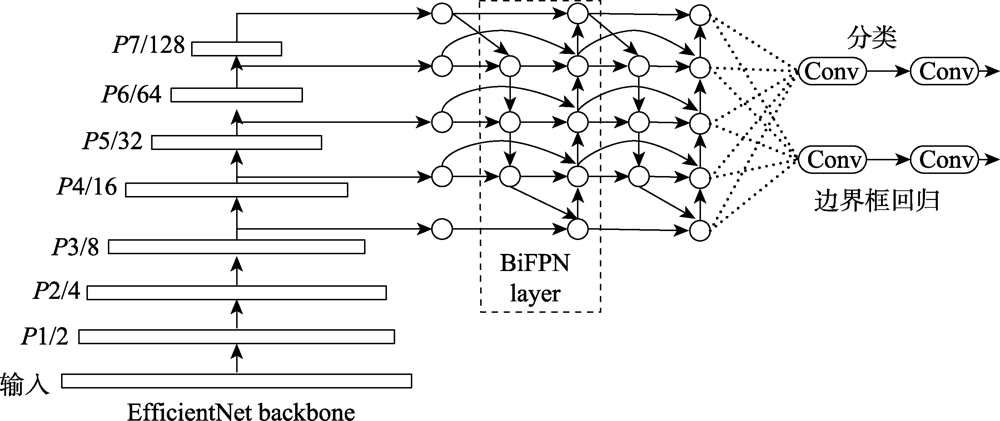
Fig.18 EfficientDet model structure
| 算法 | 主干网络 | 检测速率/(frame/s) | GPU | mAP/% | ||
|---|---|---|---|---|---|---|
| VOC2007 | VOC2012 | COCO(mAP@[0.50,0.95]) | ||||
| YOLOv1 | VGG16 | 45.0 | Titan X | 66.4 (VOC2007+VOC2012) | 57.9 (VOC2007+VOC2012) | — |
| YOLOv2 | DarkNet19 | 40.0 | Titan X | 78.6 (VOC2007+VOC2012) | 73.4 (VOC2007+VOC2012) | 21.6 (COCO) |
| YOLOv3 | DarkNet53 | 78.0 | Titan X | — | — | 33.0 (COCO) |
| YOLOv4 | CSPDarkNet53 | 66.0 | RTX 2070 | — | — | 43.5 (COCO) |
| YOLOv5 | Focus+CSP | 140.0 | Tesla P100 | — | — | — |
| YOLOX-X | Modified CSPv5 | 57.8 | Tesla V100 | — | — | 51.2 (COCO) |
| SSD300 | VGG16 | 46.0 | Titan X | 74.3 (VOC2007+VOC2012) | 72.4 (VOC2007+VOC2012) | 23.2 (COCO) |
| SSD512 | VGG16 | 19.0 | Titan X | 76.8 (VOC2007+VOC2012) | 74.9 (VOC2007+VOC2012) | 26.8 (COCO) |
| RSSD300 | VGG16 | 35.0 | Titan X | 78.5 (VOC2007+VOC2012) | 76.4 (VOC2007+VOC2012) | — |
| RSSD512 | VGG16 | 16.6 | Titan X | 80.8 (VOC2007+VOC2012) | — | — |
| DSSD321 | ResNet101 | 9.5 | Titan X | 78.6 (VOC2007+VOC2012) | 76.3 (VOC2007+VOC2012) | 28.0 (COCO) |
| DSSD513 | ResNet101 | 5.5 | Titan X | 81.5 (VOC2007+VOC2012) | 80.0 (VOC2007+VOC2012) | 33.2 (COCO) |
| FSSD300 | VGGNet | 65.8 | 1080Ti | 82.7 (VOC2007+VOC2012+ COCO) | 82.0 (VOC2007+VOC2012+ COCO) | 27.1 (COCO) |
| FSSD512 | VGGNet | 35.7 | 1080Ti | 84.5 (VOC2007+VOC2012+ COCO) | 84.2 (VOC2007+VOC2012+ COCO) | 31.8 (COCO) |
| DSOD300 | DS/64-192-48-1 | 17.4 | Titan X | 77.7 (VOC2007+VOC2012) | 76.3 (VOC2007+VOC2012) | 29.3 (COCO) |
| RetinaNet | ResNet101+FPN | — | — | — | — | 39.1 (COCO) |
| ResNeXt101+FPN | 5.4 | Titan Xp | — | — | 40.8 (COCO) | |
| CornerNet | Hourglass104 | 4.1 | Titan Xp | — | — | 42.2 (COCO) |
| CenterNet | Hourglass104 | 7.8 | Titan Xp | — | — | 45.1 (COCO) |
| EfficientDet-D7 | EfficientNet | 8.2 | Tesla V100 | — | — | 53.7 (COCO) |
Table 5 Performance comparison of one-stage target detection algorithms
| 算法 | 主干网络 | 检测速率/(frame/s) | GPU | mAP/% | ||
|---|---|---|---|---|---|---|
| VOC2007 | VOC2012 | COCO(mAP@[0.50,0.95]) | ||||
| YOLOv1 | VGG16 | 45.0 | Titan X | 66.4 (VOC2007+VOC2012) | 57.9 (VOC2007+VOC2012) | — |
| YOLOv2 | DarkNet19 | 40.0 | Titan X | 78.6 (VOC2007+VOC2012) | 73.4 (VOC2007+VOC2012) | 21.6 (COCO) |
| YOLOv3 | DarkNet53 | 78.0 | Titan X | — | — | 33.0 (COCO) |
| YOLOv4 | CSPDarkNet53 | 66.0 | RTX 2070 | — | — | 43.5 (COCO) |
| YOLOv5 | Focus+CSP | 140.0 | Tesla P100 | — | — | — |
| YOLOX-X | Modified CSPv5 | 57.8 | Tesla V100 | — | — | 51.2 (COCO) |
| SSD300 | VGG16 | 46.0 | Titan X | 74.3 (VOC2007+VOC2012) | 72.4 (VOC2007+VOC2012) | 23.2 (COCO) |
| SSD512 | VGG16 | 19.0 | Titan X | 76.8 (VOC2007+VOC2012) | 74.9 (VOC2007+VOC2012) | 26.8 (COCO) |
| RSSD300 | VGG16 | 35.0 | Titan X | 78.5 (VOC2007+VOC2012) | 76.4 (VOC2007+VOC2012) | — |
| RSSD512 | VGG16 | 16.6 | Titan X | 80.8 (VOC2007+VOC2012) | — | — |
| DSSD321 | ResNet101 | 9.5 | Titan X | 78.6 (VOC2007+VOC2012) | 76.3 (VOC2007+VOC2012) | 28.0 (COCO) |
| DSSD513 | ResNet101 | 5.5 | Titan X | 81.5 (VOC2007+VOC2012) | 80.0 (VOC2007+VOC2012) | 33.2 (COCO) |
| FSSD300 | VGGNet | 65.8 | 1080Ti | 82.7 (VOC2007+VOC2012+ COCO) | 82.0 (VOC2007+VOC2012+ COCO) | 27.1 (COCO) |
| FSSD512 | VGGNet | 35.7 | 1080Ti | 84.5 (VOC2007+VOC2012+ COCO) | 84.2 (VOC2007+VOC2012+ COCO) | 31.8 (COCO) |
| DSOD300 | DS/64-192-48-1 | 17.4 | Titan X | 77.7 (VOC2007+VOC2012) | 76.3 (VOC2007+VOC2012) | 29.3 (COCO) |
| RetinaNet | ResNet101+FPN | — | — | — | — | 39.1 (COCO) |
| ResNeXt101+FPN | 5.4 | Titan Xp | — | — | 40.8 (COCO) | |
| CornerNet | Hourglass104 | 4.1 | Titan Xp | — | — | 42.2 (COCO) |
| CenterNet | Hourglass104 | 7.8 | Titan Xp | — | — | 45.1 (COCO) |
| EfficientDet-D7 | EfficientNet | 8.2 | Tesla V100 | — | — | 53.7 (COCO) |
| 算法 | 改进方式 | 优势 | 局限 |
|---|---|---|---|
| YOLOv1 | 移除候选区域操作,通过 | 提出首个基于回归分析的目标检测算法,大幅度提高检测速率 | 存在漏检问题,对小目标检测效果不佳,绝对位置训练困难 |
| YOLOv2 | 引入BN操作,通过 | 模型训练更为稳定,获取大多数锚框长宽比,特征融合,避免损失细粒度特征,提高模型鲁棒性 | 小目标检测召回率不高,密集群体目标检测效果差 |
| YOLOv3 | 引入残差操作,进行多尺度预测,跨尺度特征融合 | 获取更深层次的图像特征,提高了对小目标的检测效果 | 检测召回率低,定位精度不佳,密集物体检测效果差 |
| YOLOv4 | 引入SPP+PAN结构,提出一系列调优技巧 | 模型具有更大的感受野,检测精度达到同时期最优 | 模型的锚框长宽比只能适应大部分目标,缺少泛化性 |
| YOLOv5 | 自适应的锚框计算和图片放缩,引入Focus结构和FPN+PAN+CSP结构 | 减少模型计算量和信息损失,提高小目标的检测效果,多模型结构,灵活性高,检测速度快 | 延用锚框的策略,模型计算量增加和正负样本不平衡,检测精度还有待提高 |
| YOLOX | 锚框的操作,引入预测分支解耦结构,引入SimOTA操作 | 降低模型计算量,缓解正负样本不平衡,改善模型的收敛速度,获得最优样本匹配方案 | — |
| SSD | 多层次特征图融合 | 解决了小目标难以检测的问题 | 特征图检测独立,计算量大 |
| RSSD | 分类网络增加不同层之间的特征图联系,网络间参数共享 | 改进特征融合方式,检测更多的小尺寸目标,参数共享减少计算量 | 模型相较复杂,计算效率较低 |
| DSSD | 引入反卷积和残差单元 | 对小目标检测的效果显著提升 | 训练时间变长,检测速度变慢 |
| FSSD | 借鉴了FPN特征融合思想 | 将浅层的细节特征和高层的语义特征进行融合,提高了检测精度 | 检测精度还有提升空间,检测速度变慢 |
| DSOD | 引入Dense Prediction结构 | 避免梯度消失,减少了参数数量 | 获取的特征冗余,增加模型的计算量 |
| RetinaNet | ResNet和FPN相结合,应用focal loss | 平衡正负样本比例,取图像多尺度特征图,使模型更注重困难样本 | 模型设计复杂,检测速度变慢 |
| CornerNet | 采用预测角点对边界框进行定位,移除锚框操作 | 缓解正负样本不均衡,减少超参数计算,对边界框定位更准确 | 角点分组匹配耗时较长,存在角点匹配错误 |
| CenterNet | 采用中心点对边界框进行定位,移除NMS后处理方式 | 计算相对简单,提高检测速度 | 对于目标中心重叠时,模型只能检测出单个目标 |
| EfficientDet | 提出加权双向特征金字塔网络(BiFPN) | 更深层次的特征融合,BiFPN的通道数、重复层数可控,模型更灵活 | 模型预训练成本过高 |
Table 6 Overall analysis of one-stage target detection algorithms
| 算法 | 改进方式 | 优势 | 局限 |
|---|---|---|---|
| YOLOv1 | 移除候选区域操作,通过 | 提出首个基于回归分析的目标检测算法,大幅度提高检测速率 | 存在漏检问题,对小目标检测效果不佳,绝对位置训练困难 |
| YOLOv2 | 引入BN操作,通过 | 模型训练更为稳定,获取大多数锚框长宽比,特征融合,避免损失细粒度特征,提高模型鲁棒性 | 小目标检测召回率不高,密集群体目标检测效果差 |
| YOLOv3 | 引入残差操作,进行多尺度预测,跨尺度特征融合 | 获取更深层次的图像特征,提高了对小目标的检测效果 | 检测召回率低,定位精度不佳,密集物体检测效果差 |
| YOLOv4 | 引入SPP+PAN结构,提出一系列调优技巧 | 模型具有更大的感受野,检测精度达到同时期最优 | 模型的锚框长宽比只能适应大部分目标,缺少泛化性 |
| YOLOv5 | 自适应的锚框计算和图片放缩,引入Focus结构和FPN+PAN+CSP结构 | 减少模型计算量和信息损失,提高小目标的检测效果,多模型结构,灵活性高,检测速度快 | 延用锚框的策略,模型计算量增加和正负样本不平衡,检测精度还有待提高 |
| YOLOX | 锚框的操作,引入预测分支解耦结构,引入SimOTA操作 | 降低模型计算量,缓解正负样本不平衡,改善模型的收敛速度,获得最优样本匹配方案 | — |
| SSD | 多层次特征图融合 | 解决了小目标难以检测的问题 | 特征图检测独立,计算量大 |
| RSSD | 分类网络增加不同层之间的特征图联系,网络间参数共享 | 改进特征融合方式,检测更多的小尺寸目标,参数共享减少计算量 | 模型相较复杂,计算效率较低 |
| DSSD | 引入反卷积和残差单元 | 对小目标检测的效果显著提升 | 训练时间变长,检测速度变慢 |
| FSSD | 借鉴了FPN特征融合思想 | 将浅层的细节特征和高层的语义特征进行融合,提高了检测精度 | 检测精度还有提升空间,检测速度变慢 |
| DSOD | 引入Dense Prediction结构 | 避免梯度消失,减少了参数数量 | 获取的特征冗余,增加模型的计算量 |
| RetinaNet | ResNet和FPN相结合,应用focal loss | 平衡正负样本比例,取图像多尺度特征图,使模型更注重困难样本 | 模型设计复杂,检测速度变慢 |
| CornerNet | 采用预测角点对边界框进行定位,移除锚框操作 | 缓解正负样本不均衡,减少超参数计算,对边界框定位更准确 | 角点分组匹配耗时较长,存在角点匹配错误 |
| CenterNet | 采用中心点对边界框进行定位,移除NMS后处理方式 | 计算相对简单,提高检测速度 | 对于目标中心重叠时,模型只能检测出单个目标 |
| EfficientDet | 提出加权双向特征金字塔网络(BiFPN) | 更深层次的特征融合,BiFPN的通道数、重复层数可控,模型更灵活 | 模型预训练成本过高 |
| [1] | 史彩娟, 张卫明, 陈厚儒, 等. 基于深度学习的显著性目标检测综述[J]. 计算机科学与探索, 2021, 15(2): 219-232. |
| SHI C J, ZHANG W M, CHEN H R, et al. Survey of salient object detection based on deep learning[J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(2): 219-232. | |
| [2] |
LOWE D G. Distinctive image features from scale-invariant keypoints[J]. International Journal of Computer Vision, 2004, 60(2): 91-110.
DOI URL |
| [3] | DALAL N, TRIGGS B. Histograms of oriented gradients for human detection[C]// Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, Jun 20-26, 2005. Piscataway: IEEE, 2005: 886-893. |
| [4] | LIENHART R, MAYDT J. An extended set of haar-like features for rapid object detection[C]// Proceedings of the 2002 International Conference on Image Processing, Rochester, Sep 22-25, 2002. Piscataway: IEEE, 2002: 900-903. |
| [5] |
OJALA T, PIETIKAINEN M, MAENPAA T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(7): 971-987.
DOI URL |
| [6] |
FELZENSZWALB P F, GIRSHICK R B, MCALLESTER D, et al. Object detection with discriminatively trained part-based models[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 32(9): 1627-1645.
DOI URL |
| [7] | WANG P, SHEN C, BARNES N, et al. Fast and robust object detection using asymmetric totally corrective Boosting[J]. IEEE Transactions on Neural Networks & Learning Systems, 2012, 23(1): 33-46. |
| [8] | BALCAZAR J L, DAI Y, WATANABE O. Provably fast training algorithms for support vector machines[C]// Proceedings of the 2001 IEEE International Conference on Data Mining, San Jose, Nov 29-Dec 2, 2001. Piscataway: IEEE, 2001: 43-50. |
| [9] | 王迪聪, 白晨帅, 邬开俊. 基于深度学习的视频目标检测综述[J]. 计算机科学与探索, 2021, 15(9): 1563-1577. |
| WANG D C, BAI C S, WU K J. Survey of video object detection based on deep learning[J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(9): 1563-1577. | |
| [10] |
LECUN Y, BENGIO Y, HINTON G. Deep learning[J]. Nature, 2015, 521(7553): 436-444.
DOI URL |
| [11] | KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[C]// Advances in Neural Information Processing Systems 25, 2012: 1106-1114. |
| [12] | DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database[C]// Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, Jun 20-25, 2009. Piscataway: IEEE, 2009: 248-255. |
| [13] | SHETTY S. Application of convolutional neural network for image classification on Pascal VOC challenge 2012 dataset[J]. arXiv:1607.03785, 2016. |
| [14] | LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context[C]// LNCS 8693: Proceedings of the 13th European Conference on Computer Vision, Zurich, Sep 5-12, 2014. Cham: Springer, 2014: 740-755. |
| [15] | EVERINGHAM M, VAN G L, WILLIAMS C K I, et al. The PASCAL visual object classes challenge 2007[EB/OL]. [2021-10-15]. http://host.robots.ox.ac.uk/pascal/VOC/voc2007/. |
| [16] | EVERINGHAM M, VAN GOOL L, WILLIAMS C K I, et al. Visual object classes challenge 2012[EB/OL]. [2021-10-14]. http://www.image-net.org/challenges/LSVRC/2012/. |
| [17] | GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmen-tation[C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, Jun 23-28, 2014. Piscataway: IEEE, 2014: 580-587. |
| [18] |
SHIN H C, ROTH H R, GAO M, et al. Deep convolutional neural networks for computer-aided detection: CNN archite-ctures, dataset characteristics and transfer learning[J]. IEEE Transactions on Medical Imaging, 2016, 35(5): 1285-1298.
DOI URL |
| [19] |
LI Y, STEVENSON R L. Multimodal image registration with line segments by selective search[J]. IEEE Transactions on Cybernetics, 2016, 47(5): 1285-1298.
DOI URL |
| [20] | NEUBECK A, VAN GOOL L. Efficient non-maximum suppre-ssion[C]// Proceedings of the 18th International Conference on Pattern Recognition, Hong Kong, China, Aug 20-24, 2006. Piscataway: IEEE, 2006: 850-855. |
| [21] | HE K, ZHANG X, REN S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Iintelligence, 2015, 37(9): 1904-1916. |
| [22] | JEON J, JEONG B, BACK S, et al. Hybrid malware detection based on Bi-LSTM and SPP-Net for smart IoT[J]. IEEE Tran-sactions on Industrial Informatics, 2021. |
| [23] | GIRSHICK R. Fast R-CNN[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Dec 7-13, 2015. Piscataway: IEEE, 2015: 1440-1448. |
| [24] | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[J]. arXiv:1409.1556, 2014. |
| [25] | QASSIM H, VERMA A, FEINZIMER D. Compressed residual-VGG16 CNN model for big data places image recognition[C]// Proceedings of the 2018 IEEE 8th Annual Computing and Communication Workshop and Conference, Las Vegas, Jan 8-10, 2018. Piscataway: IEEE, 2018: 169-175. |
| [26] | QIN Y, HE S, ZHAO Y, et al. RoI pooling based fast multi-domain convolutional neural networks for visual tracking[C]// Proceedings of the 2016 International Conference on Artificial Intelligence and Industrial Engineering, Beijing, Nov 20-21, 2016: 198-202. |
| [27] |
WANG F, CHENG J, LIU W, et al. Additive margin softmax for face verification[J]. IEEE Signal Processing Letters, 2018, 25(7): 926-930.
DOI URL |
| [28] |
AHMADI-ASL S, CICHOCKI A, PHAN A H, et al. Randomized algorithms for computation of Tucker decomposition and higher order SVD (HOSVD)[J]. IEEE Access, 2021, 9: 28684-28706.
DOI URL |
| [29] | REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Inte-lligence, 2016, 39(6): 1137-1149. |
| [30] | SHAHIN S, SADEGHIAN R, SAREH S. Faster R-CNN-based decision making in a novel adaptive dual-mode robotic anchoring system[C]// Proceedings of the 2021 IEEE Inter-national Conference on Robotics and Automation, Xi’an, May 30-Jun 5, 2021. Piscataway: IEEE, 2021: 11010-11016. |
| [31] | JIANG H, LEARNED M E. Face detection with the faster R-CNN[C]// Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition, Washington, Dec 15-18, 2021. Piscataway: IEEE, 2017: 650-657. |
| [32] | CHEN Y, LI W, SAKARIDIS C, et al. Domain adaptive faster R-CNN for object detection in the wild[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake, Jun 18-23, 2018. Piscataway: IEEE, 2018: 3339-3348. |
| [33] | DAI J, LI Y, HE K, et al. R-FCN: object detection via region-based fully convolutional networks[C]// Advances in Neural Information Processing Systems 29, Barcelona, Dec 5-10, 2016. Red Hook: Curran Associates, 2016: 379-387. |
| [34] | SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, Jun 7-12, 2015. Piscataway: IEEE, 2015: 1-9. |
| [35] | 黄致君, 桑庆兵. 改进R-FCN的船舶识别方法[J]. 计算机科学与探索, 2020, 14(6): 1045-1053. |
| HUANG Z J, SANG Q B. ship detection based on improved R-FCN[J]. Journal of Frontiers of Computer Science and Technology, 2020, 14(6): 1045-1053. | |
| [36] | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Con-ference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Piscataway: IEEE, 2016: 770-778. |
| [37] | CAI Z, VASCONCELOS N. Cascade R-CNN: delving into high quality object detection[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake, Jun 18-23, 2018. Piscataway: IEEE, 2018: 6154-6162. |
| [38] | 方钧婷, 谭晓阳. 注意力级联网络的金属表面缺陷检测算法[J]. 计算机科学与探索, 2021, 15(7): 1245-1254. |
| FANG J T, TAN X Y. Defect detection of metal surface based on attention cascade R-CNN[J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(7): 1245-1254. | |
| [39] | WANG N, LIU H, XU C. Deep learning for the detection of COVID-19 using transfer learning and model integration[C]// Proceedings of the 2020 IEEE 10th International Conference on Electronics Information and Emergency Communication, Beijing, Jul 17-19, 2020. Piscataway: IEEE, 2020: 281-284. |
| [40] | PANG J, CHEN K, SHI J, et al. Libra R-CNN: towards balanced learning for object detection[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, Jun 15-20, 2019. Piscataway: IEEE, 2019: 821-830. |
| [41] |
GUO H, YANG X, WANG N, et al. A rotational libra R-CNN method for ship detection[J]. IEEE Transactions on Geoscience and Remote Sensing, 2020, 58(8): 5772-5781.
DOI URL |
| [42] | WANG X, GIRSHICK R, GUPAT A, et al. Nonlocal neural networks[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake, Jun 18-23, 2018. Piscataway: IEEE, 2018: 7794-7803. |
| [43] | DENG J, BERG A, SATHEESH S, et al. ImageNet large scale visual recognition competiton 2013[EB/OL]. [2021-10-14]. http://www.image-net.org/challenges/LSVRC/2013/. |
| [44] | XIE S, GIRSHICK R, DOLLAR P, et al. Aggregated residual transformations for deep neural networks[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Piscataway: IEEE, 2017: 1492-1500. |
| [45] | REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Piscataway: IEEE, 2016: 779-788. |
| [46] | LI G, SONG Z, FU Q. A new method of image detection for small datasets under the framework of YOLO network[C]// Proceedings of the 2018 IEEE 3rd Advanced Information Technology, Electronic and Automation Control Conference, Chongqing, Oct 12-14, 2018. Piscataway: IEEE, 2018: 1031-1035. |
| [47] | REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Piscataway: IEEE, 2017: 7263-7271. |
| [48] | ALHAIJA Q A, SMADI M, ALBATAINEH O M. Identifying phasic dopamine releases using DarkNet-19 convolutional neural network[C]// Proceedings of the 2021 IEEE International IOT, Electronics and Mechatronics Conference, Toronto, Apr 21-24, 2021. Piscataway: IEEE, 2021: 1-5. |
| [49] | GOPALAKRISHNA M T, ANUJ L. ResNet50 YOLOv2 convolutional neural network based hybrid deep structural learning for moving vehicle tracking under occlusion[J]. Solid State Technology, 2020, 63(6): 3237-3258. |
| [50] | COATES A, NG A Y. Learning feature representations with k-means[M]// MONTAVON G, ORR G B, MÜLLER K R. Neural Networks:Tricks of the Trade-Second Edition. Berlin, Heidelberg: Springer, 2012. |
| [51] | 洪敏, 贾彩燕, 王晓阳. K-means型多视图聚类中的初始化问题研究[J]. 计算机科学与探索, 2019, 13(4): 574-585. |
| HONG M, JIA C Y, WANG X Y. Research on initialization of K-means type multi-view clustering[J]. Journal of Frontiers of Computer Science and Technology, 2019, 13(4): 574-585. | |
| [52] | REDMON J, FARHADI A. YOLOv3: an incremental improve-ment[J]. arXiv:1804.02767, 2018. |
| [53] | 宋艳艳, 谭励, 马子豪, 等. 改进YOLOV3算法的视频目标检测[J]. 计算机科学与探索, 2021, 15(1): 163-172. |
| SONG Y Y, TAN L, MA Z H, et al. Video target detection based on improved YOLOV3 algorithm[J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(1): 163-172. | |
| [54] | KLEINBAUM D G, DIETZ K, GAIL M, et al. Logistic regression[M]. Berlin, Heidelberg: Springer, 2002. |
| [55] | BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: optimal speed and accuracy of object detection[J]. arXiv:2004.10934, 2020. |
| [56] | WANG C Y, BOCHKOVSKIY A, LIAO H Y M. Scaled-YOLOv4: scaling cross stage partial network[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, Jun 20-25, 2021. Piscat-away: IEEE, 2021: 13029-13038. |
| [57] |
ALBAHLI S, NIDA N, IRTAZA A, et al. Melanoma lesion detection and segmentation using YOLOv4-DarkNet and active contour[J]. IEEE Access, 2020, 8: 198403-198414.
DOI URL |
| [58] |
DU S, ZHANG P, ZHANG B, et al. Weak and occluded vehicle detection in complex infrared environment based on improved YOLOv4[J]. IEEE Access, 2021, 9: 25671-25680.
DOI URL |
| [59] |
MAHRISHI M, MORWAL S, MUZAFFAR A W, et al. Video index point detection and extraction framework using custom YOLOv4 Darknet object detection model[J]. IEEE Access, 2021, 9: 143378-143391.
DOI URL |
| [60] | JOCHER G. YOLOv5[EB/OL]. [2021-10-14]. https://github.com/ultralytics/yolov5. |
| [61] | 钱伍, 王国中, 李国平. 改进YOLOv5的交通灯实时检测鲁棒算法[J]. 计算机科学与探索, 2022, 16(1): 231-241. |
| QIAN W, WANG G Z, LI G P. Improved YOLOv5 traffic light real-time detection robust algorithm[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(1): 231-241. | |
| [62] | ZHOU F, ZHAO H, NIE Z. Safety Helmet detection based on YOLOv5[C]// Proceedings of the 2021 IEEE International Conference on Power Electronics, Computer Applications, Shenyang, Jan 22-24, 2021. Piscataway: IEEE, 2021: 6-11. |
| [63] | WANG C Y, LIAO H Y M, WU Y H, et al. CSPNet: a new backbone that can enhance learning capability of CNN[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 390-391. |
| [64] | GE Z, LIN S, WANG F, et al. YOLOX: exceeding YOLO series in 2021[J]. arXiv:2107.08430, 2021. |
| [65] | LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector[C]// LNCS 9905: Proceedings of the 14th European Conference on Computer Vision, Amsterdam, Oct 11-14, 2016. Cham: Springer, 2016: 21-37. |
| [66] | 陈幻杰, 王琦琦, 杨国威, 等. 多尺度卷积特征融合的SSD目标检测算法[J]. 计算机科学与探索, 2019, 13(6): 1049-1061. |
| CHEN H J, WANG Q Q, YANG G W, et al. SSD object detection algorithm with multi-scale convolution feature fusion[J]. Journal of Frontiers of Computer Science and Technology, 2019, 13(6): 1049-1061. | |
| [67] |
侯庆山, 邢进生. 基于Grad-CAM与KL损失的SSD目标检测算法[J]. 电子学报, 2020, 48(12): 2409-2416.
DOI |
| HOU Q S, XING J S. SSD object detection algorithm based on KL loss and Grad-CAM[J]. Acta Electronica Sinica, 2020, 48(12): 2409-2416. | |
| [68] | JEONG J, PARK H, KWAK N. Enhancement of SSD by concatenating feature maps for object detection[J]. arXiv:1705.09587, 2017. |
| [69] | 王殿伟, 赵梦影, 刘颖, 等. 改进的R-SSD全景视频图像车辆检测算法[J]. 计算机工程与应用, 2021, 57(3): 189-195. |
| WANG D W, ZHAO M Y, LIU Y, et al. Improved R-SSD panoramic video image vehicle detection algorithm[J]. Com-puter Engineering and Applications, 2021, 57(3): 189-195. | |
| [70] |
LU Y, DING E J, DU J, et al. Safety detection approach in industrial equipment based on RSSD with adaptive parameter optimization algorithm[J]. Safety Science, 2020, 125: 104605.
DOI URL |
| [71] | FU C Y, LIU W, RANGA A, et al. DSSD: deconvolutional single shot detector[J]. arXiv:1701.06659, 2017. |
| [72] |
JU M, LUO J, WANG Z, et al. Adaptive feature fusion with attention mechanism for multi-scale target detection[J]. Neural Computing and Applications, 2021, 33(7): 2769-2781.
DOI URL |
| [73] | WANG S, WU L, WU W, et al. Optical fiber defect detection method based on DSSD network[C]// Proceedings of the 2019 IEEE International Conference on Smart Internet of Things, Tianjin, Aug 9-11, 2019. Piscataway: IEEE, 2019: 422-426. |
| [74] | LI Z, ZHOU F. FSSD: feature fusion single shot multibox detector[J]. arXiv:1712.00960, 2017. |
| [75] | WANG Q, ZHANG H, HONG X, et al. Small object detection based on modified FSSD and model compression[J]. arXiv:2108.10503, 2021. |
| [76] |
SHEN Z, LIU Z, LI J, et al. Object detection from scratch with deep supervision[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 42(2): 398-412.
DOI URL |
| [77] | IANDOLA F, MOSKEWICZ M, KARAYEV S, et al. Dense-Net: implementing efficient ConvNet descriptor pyramids[J]. arXiv:1404.1869, 2014. |
| [78] | LIN T Y, GOYAL P, GIRSHICK R, et al. focal loss for dense object detection[J]. arXiv:1708.02002, 2017. |
| [79] | LIN T Y, GOYAL P, GIRSHICK R B, et al. Focal loss for dense object detection[C]// Proceedings of the 2017 IEEE Inter-national Conference on Computer Vision, Venice, Oct 22-29, 2017. Washington: IEEE Computer Society, 2017: 2999-3007. |
| [80] |
HO Y, WOOKEY S. The real-world-weight crossentropy loss function: modeling the costs of mislabeling[J]. IEEE Access, 2019, 8: 4806-4813.
DOI URL |
| [81] | LAW H, DENG J. CornerNet: detecting objects as paired keypoints[C]// LNCS 11218: Proceedings of the 15th European Conference on Computer vision, Munich, Sep 8-14, 2018. Cham: Springer, 2018: 765-781. |
| [82] | LAW H, TENG Y, RUSSAKOVSKY O, et al. CornerNet-Lite: efficient keypoint based object detection[J]. arXiv:1904.08900, 2019. |
| [83] | XIONG Q, TANG S, LI Y, et al. Research on surface quality monitoring of workpiece based on CornerNet[C]// Proceedings of the 2021 7th Annual International Conference on Net-work and Information Systems for Computers, Guiyang, Jul 23-25, 2021. Piscataway: IEEE, 2021: 430-438. |
| [84] | HAO L Y, LI J, GUO G. A multi-target corner pooling-based neural network for vehicle detection[J]. Neural Com-puting and Applications, 2020, 32(18): 14497-14506. |
| [85] | DUAN K, BAI S, XIE L, et al. CenterNet: keypoint triplets for object detection[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Oct 27-Nov 2, 2019. Piscataway: IEEE, 2019: 6569-6578. |
| [86] | AHMED I, AHMAD M, RODRIGUES J, et al. Edge computing-based person detection system for top view surveillance: using CenterNet with transfer learning[J]. Applied Soft Com-puting, 2021, 107(3): 107489. |
| [87] | 魏玮, 杨茹, 朱叶. 改进CenterNet的遥感图像目标检测[J]. 计算机工程与应用, 2021, 57(6): 191-199. |
| WEI W, YANG R, ZHU Y. Target detection of improved CenterNet to remote sensing images[J]. Computer Engineering and Applications, 2021, 57(6): 191-199. | |
| [88] | XU Z J, HRUSTIC E, VIVET D. CenterNet heatmap propaga-tion for real-time video object detection[C]// LNCS 12370: Proceedings of the 16th European Conference on Computer Vision, Glasgow, Aug 23-28, 2020. Cham: Springer, 2020: 220-234. |
| [89] | TAN M, PANG R, LE Q V. EfficientDet: scalable and efficient object detection[C]// Proceedings of the 2020 IEEE/CVF Con-ference on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 10781-10790. |
| [90] |
TRINH H C, LE D H, KWON Y K. PANet: a GPU-based tool for fast parallel analysis of robustness dynamics and feed-forward/feedback loop structures in large-scale biological networks[J]. PLoS One, 2014, 9(7): e103010.
DOI URL |
| [91] | CAO L, ZHANG X, PU J, et al. The field wheat count based on the EfficientDet algorithm[C]// Proceedings of the 2020 IEEE 3rd International Conference on Information Systems and Computer Aided Education, Dalian, Sep 27-29, 2020. Piscataway: IEEE, 2020: 557-561. |
| [92] | FA Z W, YAN W Y, SHUIYUAN D, et al. Research on location of chinese handwritten signature based on EfficientDet[C]// Proceedings of the 2021 IEEE 4th International Conference on Big Data and Artificial Intelligence, Qingdao, Jul 2-4, 2021. Piscataway: IEEE, 2021: 192-198. |
| [93] | MEKHALFI M L, NICOLÒ C, BAZI Y, et al. Contrasting YOLOv5, Transformer, and EfficientDet detectors for crop circle detection in desert[J]. IEEE Geoscience and Remote Sensing Letters, 2022, 19: 1-15. |
| [94] | FANG W. MOBILENET: US20120309352A1[P]. 2012. |
| [95] | SANDLER M, HOWARD A G, ZHU M L, et al. MobileNetv2: inverted residuals and linear bottlenecks[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake, Jun 18-22, 2018. Piscataway: IEEE, 2018: 4510-4520. |
| [96] | HOWARD A, SANDLER M, CHU G, et al. Searching for MobileNetv3[C]// Proceedings of the 2019 IEEE/CVF Interna-tional Conference on Computer Vision, Seoul, Oct 27-28, 2019. Piscataway: IEEE, 2019: 1314-1324. |
| [97] | HAN K, WANG Y, TIAN Q, et al. GhostNet: more features from cheap operations[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 1580-1589. |
| [1] | ZHANG Haocong, LI Tao, XING Lidong, PAN Fengrui. Parallel Implementation of OpenVX Feature Extraction Functions in Programmable Processing Architecture [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(7): 1583-1593. |
| [2] | PENG Hao, LI Xiaoming. Multi-scale Selection Pyramid Networks for Small-Sample Target Detection Algorithms [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(7): 1649-1660. |
| [3] | LIU Yi, LI Mengmeng, ZHENG Qibin, QIN Wei, REN Xiaoguang. Survey on Video Object Tracking Algorithms [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(7): 1504-1515. |
| [4] | MA Jinlin, ZHANG Yu, MA Ziping, MAO Kaiji. Research Progress of Lightweight Neural Network Convolution Design [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(3): 512-528. |
| [5] | RUAN Chenzhao, ZHANG Xiangsen, LIU Ke, ZHAO Zengshun. Progress on Human-Object Interaction Detection of Deep Learning [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(2): 323-336. |
| [6] | LI Kecen, WANG Xiaoqiang, LIN Hao, LI Leixiao, YANG Yanyan, MENG Chuang, GAO Jing. Survey of One-Stage Small Object Detection Methods in Deep Learning [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(1): 41-58. |
| [7] | ZHOU Weixiao, LAN Wenfei, XU Zhiming, ZHU Rongbo. SFExt-PGAbs: Two-Stage Summarization Model for Long Document [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(5): 907-921. |
| [8] | LIN Chengchuang, SHAN Chun, ZHAO Gansen, et al. Review of Image Data Augmentation in Computer Vision [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(4): 583-611. |
| [9] | CHEN Ruilong, LUO Lei, CAI Zhiping, MA Wentao. Algorithm for Real-Time Smoking Detection Based on Deep Learning [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(2): 327-337. |
| [10] | CHEN Haoran, PENG Li. Detection Algorithm of Small Target in Receptive Field Block [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(2): 346-353. |
| [11] | AN Ping, JI Zhong, LIU Xiyao. Task-Aware Dual Prototypical Network for Few-Shot Human-Object Interaction Recognition [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(11): 2184-2192. |
| [12] | JING Zhuangwei, GUAN Haiyan, ZANG Yufu, NI Huan, LI Dilong, YU Yongtao. Survey of Point Cloud Semantic Segmentation Based on Deep Learning [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(1): 1-26. |
| [13] | YAN Chunman, WANG Cheng. Development and Application of Convolutional Neural Network Model [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(1): 27-46. |
| [14] | XU Hui, ZHU Yuhua, ZHEN Tong, LI Zhihui. Survey of Image Semantic Segmentation Methods Based on Deep Neural Network [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(1): 47-59. |
| [15] | SONG Yanyan, TAN Li, MA Zihao, REN Xueping. Video Target Detection Based on Improved YOLOV3 Algorithm [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(1): 163-172. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
/D:/magtech/JO/Jwk3_kxyts/WEB-INF/classes/