
Journal of Frontiers of Computer Science and Technology ›› 2022, Vol. 16 ›› Issue (6): 1291-1303.DOI: 10.3778/j.issn.1673-9418.2102046
• High Performance Computing • Previous Articles Next Articles
WEI Guang1, QIAN Depei1,2, YANG Hailong1,2, LUAN Zhongzhi1,2,+( )
)
Received:2021-02-22
Revised:2021-04-25
Online:2022-06-01
Published:2021-05-10
About author:WEI Guang, born in 1986, Ph.D. candidate. His research interests include high-performance com-puting, energy optimization, etc.Supported by:
魏光1, 钱德沛1,2, 杨海龙1,2, 栾钟治1,2,+()
通讯作者:
+ E-mail: luan.zhongzhi@buaa.edu.cn作者简介:魏光(1986—),男,博士研究生,主要研究方向为高性能计算、能耗优化等。基金资助:CLC Number:
WEI Guang, QIAN Depei, YANG Hailong, LUAN Zhongzhi. Practice on Program Energy Consumption Optimization by Energy Measurement and Analysis Using FPowerTool[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(6): 1291-1303.
魏光, 钱德沛, 杨海龙, 栾钟治. 程序能耗测量分析工具FPowerTool及其能耗优化实践[J]. 计算机科学与探索, 2022, 16(6): 1291-1303.
Add to citation manager EndNote|Ris|BibTeX
URL: http://fcst.ceaj.org/EN/10.3778/j.issn.1673-9418.2102046
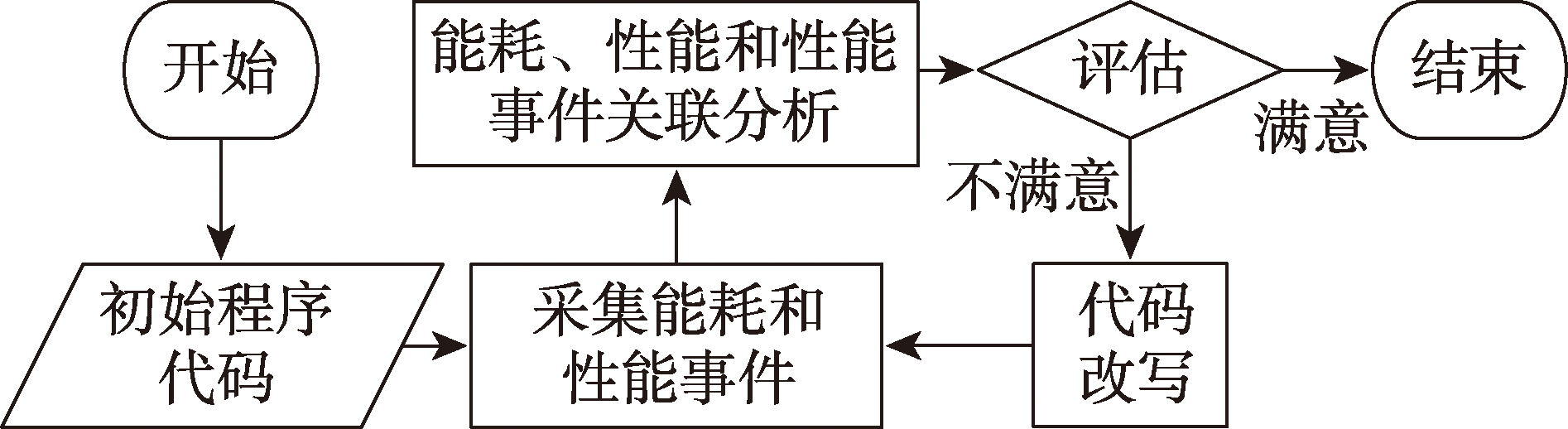
Fig.1 Workflow of energy-aware programming
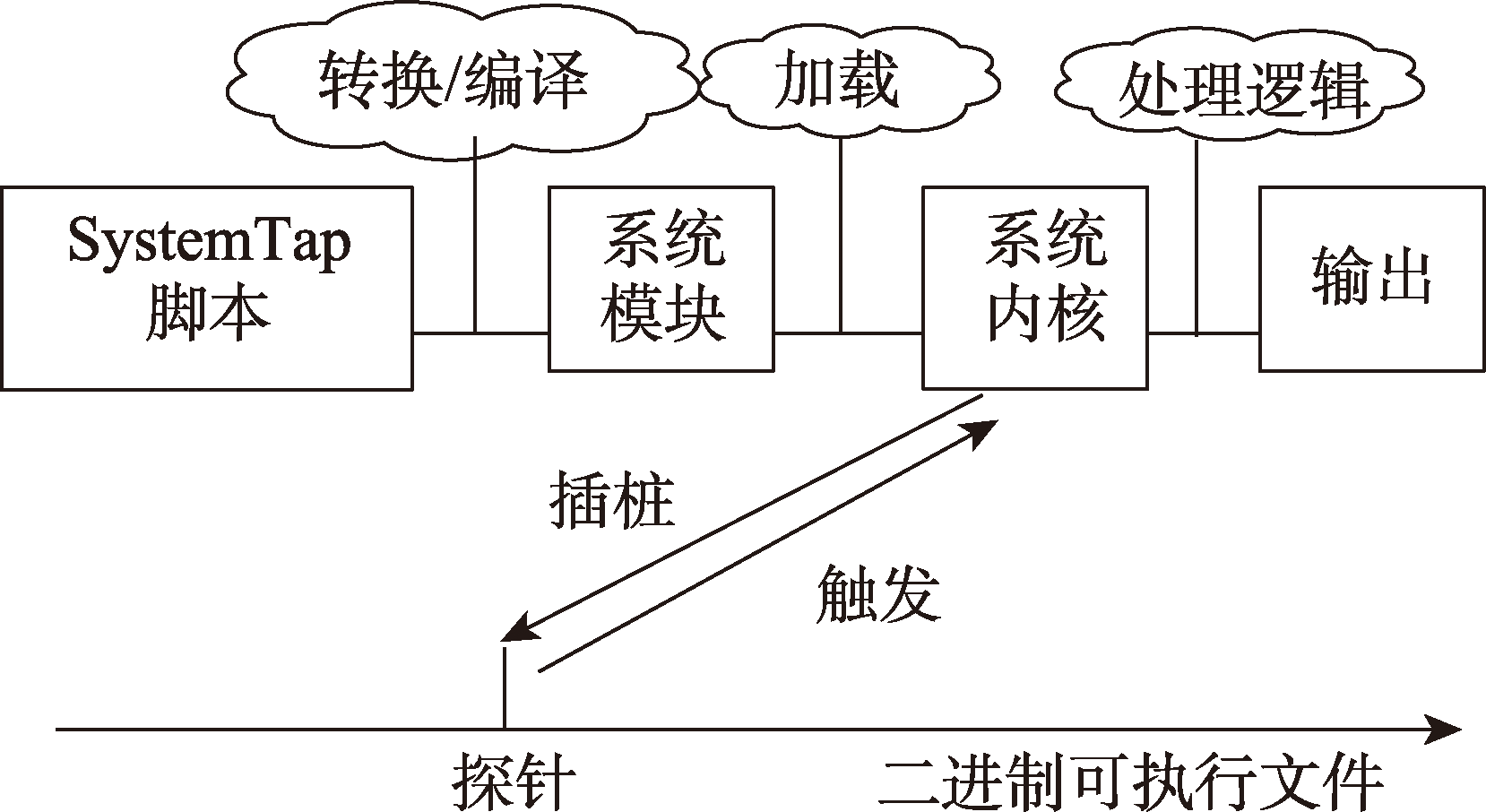
Fig.2 Workflow of dynamic instrument
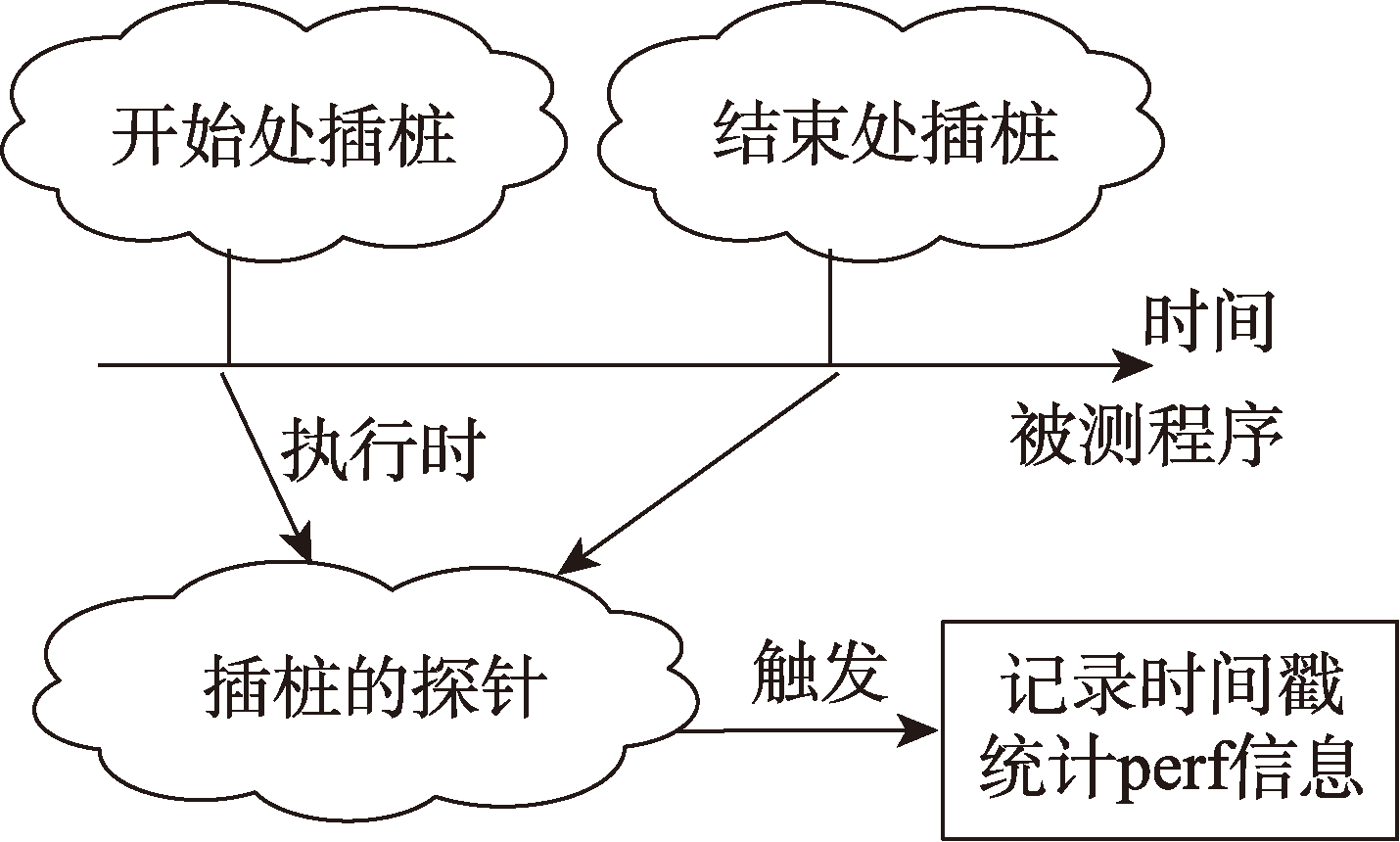
Fig.3 Schematic diagram of probe triggering
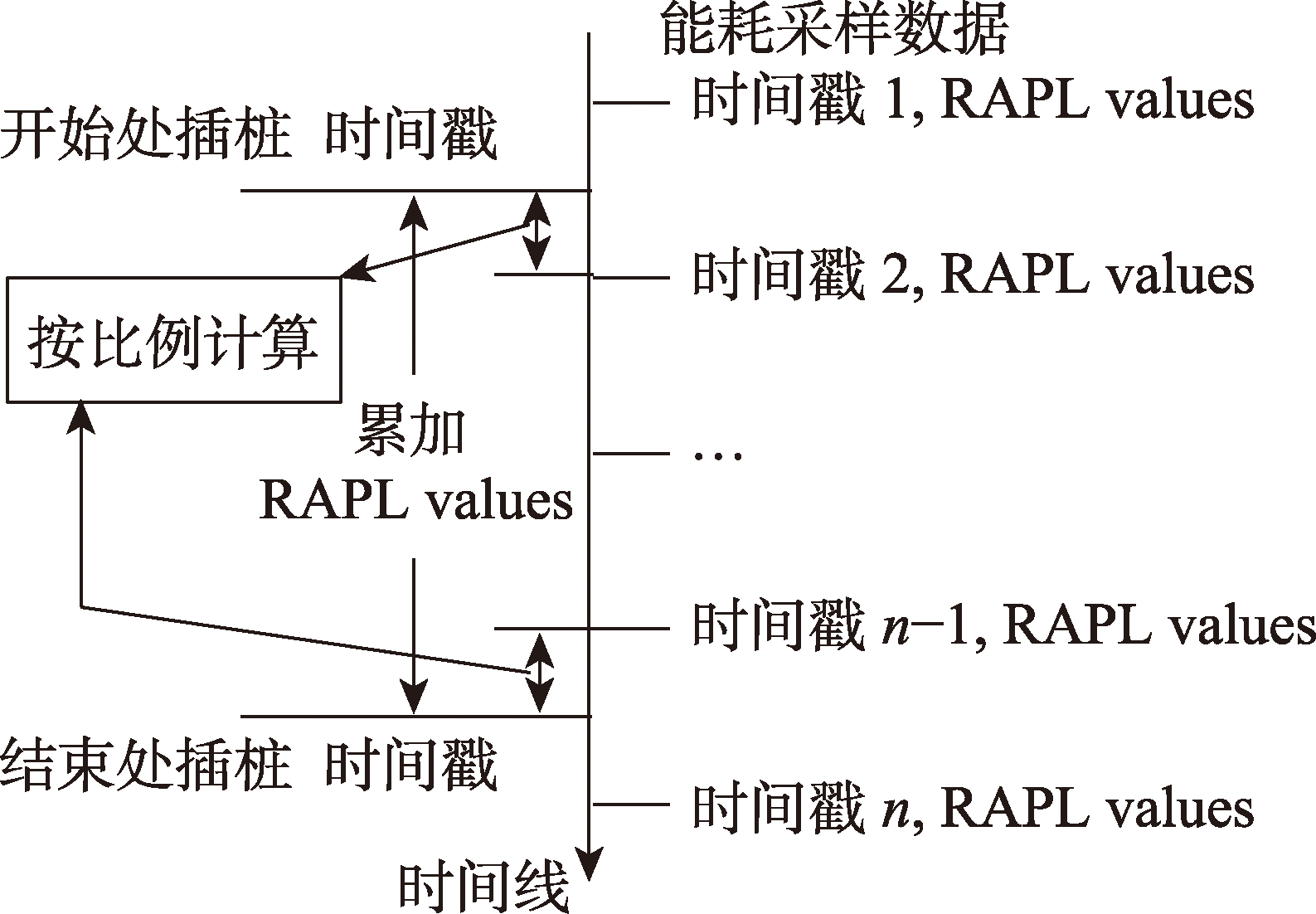
Fig.4 Computing energy consumption by a basic code block
| 类别 | 模型用到的性能事件 |
|---|---|
| 硬件事件 | buscycles, cachereferences, cpucycles, instructions, refcycles |
| 软件事件 | cpuclock, cpumigrations, minorfaults, taskclock |
| 硬件cache 事件 | L1dcacheloadmisses, L1dcachestores, L1icacheloadmisses, LLCloads, branchloads, dTLBloadmisses, dTLBstoremisses, iTLBloads, nodeloadmisses, nodeloads, nodestores |
Table 1 Performance events used in model
| 类别 | 模型用到的性能事件 |
|---|---|
| 硬件事件 | buscycles, cachereferences, cpucycles, instructions, refcycles |
| 软件事件 | cpuclock, cpumigrations, minorfaults, taskclock |
| 硬件cache 事件 | L1dcacheloadmisses, L1dcachestores, L1icacheloadmisses, LLCloads, branchloads, dTLBloadmisses, dTLBstoremisses, iTLBloads, nodeloadmisses, nodeloads, nodestores |
| 性能事件 | 相对重要性 | 性能事件 | 相对重要性 |
|---|---|---|---|
| cpucycles | 4.386 | nodeloads | 0.223 |
| cpuclock | 4.326 | dTLBloadmisses | 0.220 |
| taskclock | 3.855 | dTLBstoremisses | 0.216 |
| refcycles | 2.400 | L1dcacheloadmisses | 0.187 |
| buscycles | 2.161 | L1dcachestores | 0.151 |
| minorfaults | 0.864 | nodeloadmisses | 0.097 |
| iTLBloads | 0.773 | cachereferences | 0.090 |
| instructions | 0.715 | nodestores | 0.077 |
| L1icacheloadmisses | 0.481 | cpumigrations | 0.051 |
| LLCloads | 0.423 | branchloads | 0.019 |
Table 2 Relative importance of performance events in the first discriminant function
| 性能事件 | 相对重要性 | 性能事件 | 相对重要性 |
|---|---|---|---|
| cpucycles | 4.386 | nodeloads | 0.223 |
| cpuclock | 4.326 | dTLBloadmisses | 0.220 |
| taskclock | 3.855 | dTLBstoremisses | 0.216 |
| refcycles | 2.400 | L1dcacheloadmisses | 0.187 |
| buscycles | 2.161 | L1dcachestores | 0.151 |
| minorfaults | 0.864 | nodeloadmisses | 0.097 |
| iTLBloads | 0.773 | cachereferences | 0.090 |
| instructions | 0.715 | nodestores | 0.077 |
| L1icacheloadmisses | 0.481 | cpumigrations | 0.051 |
| LLCloads | 0.423 | branchloads | 0.019 |
| 服务器 | 配置 |
|---|---|
| CPU | Intel® Xeon® CPU E5-2680 v3 2 sockets, 12 cores per socket, 2.50 GHz |
| 操作系统 | CentOS 7.3.1611 |
| 内存 | 125 GB |
| 编译器 | gcc 4.8.5 |
| Cache信息 | L1d cache: 32 KB L1i cache: 32 KB L2 cache: 256 KB L3 cache: 30 720 KB |
Table 3 Experiment platform configuration
| 服务器 | 配置 |
|---|---|
| CPU | Intel® Xeon® CPU E5-2680 v3 2 sockets, 12 cores per socket, 2.50 GHz |
| 操作系统 | CentOS 7.3.1611 |
| 内存 | 125 GB |
| 编译器 | gcc 4.8.5 |
| Cache信息 | L1d cache: 32 KB L1i cache: 32 KB L2 cache: 256 KB L3 cache: 30 720 KB |

Fig.5 Energy consumption of original LavaMD program
| 类别 | 原生程序 | 优化后 | 差值 | 差值百分比/% | |
|---|---|---|---|---|---|
| 时间/μs | 5.58E+06 | 4.91E+06 | -6.70E+05 | -12.0 | |
| 能量/J | PACKAGE0 | 175.2 | 158.2 | -17.0 | -9.7 |
| PACKAGE1 | 207.7 | 188.7 | -19.0 | -9.1 | |
| DRAM0 | 17.4 | 14.9 | -2.5 | -14.4 | |
| DRAM1 | 34.2 | 31.7 | -2.5 | -7.3 |
Table 4 Energy consumed by kernel_cpu before and after optimization
| 类别 | 原生程序 | 优化后 | 差值 | 差值百分比/% | |
|---|---|---|---|---|---|
| 时间/μs | 5.58E+06 | 4.91E+06 | -6.70E+05 | -12.0 | |
| 能量/J | PACKAGE0 | 175.2 | 158.2 | -17.0 | -9.7 |
| PACKAGE1 | 207.7 | 188.7 | -19.0 | -9.1 | |
| DRAM0 | 17.4 | 14.9 | -2.5 | -14.4 | |
| DRAM1 | 34.2 | 31.7 | -2.5 | -7.3 |
| 性能事件 | 原生程序 | 优化后 | 差值 | 差值百分比/% |
|---|---|---|---|---|
| branch_instructions | 4.50E+09 | 4.23E+09 | -2.70E+08 | -6.0 |
| branch_misses | 4.29E+07 | 4.35E+07 | 6.00E+05 | 1.4 |
| bus_cycles | 6.12E+08 | 5.64E+08 | -4.80E+07 | -7.8 |
| cache_misses | 2.83E+04 | 2.11E+04 | -7.20E+03 | -25.4 |
| cache_references | 8.84E+04 | 8.61E+04 | -2.30E+03 | -2.6 |
| cpu_cycles | 1.77E+10 | 1.61E+10 | -1.60E+09 | -9.0 |
| instructions | 4.11E+10 | 3.80E+10 | -3.10E+09 | -7.5 |
| ref_cpu_cycles | 1.53E+10 | 1.41E+10 | -1.20E+09 | -7.8 |
| cpu_clock | 6.14E+09 | 5.65E+09 | -4.90E+08 | -8.0 |
| page_faults_min | 5.03E+02 | 4.76E+02 | -2.70E+01 | -5.4 |
| task_clock | 6.14E+09 | 5.65E+09 | -4.90E+08 | -8.0 |
Table 5 Performance events of kernel_cpu before and after optimization
| 性能事件 | 原生程序 | 优化后 | 差值 | 差值百分比/% |
|---|---|---|---|---|
| branch_instructions | 4.50E+09 | 4.23E+09 | -2.70E+08 | -6.0 |
| branch_misses | 4.29E+07 | 4.35E+07 | 6.00E+05 | 1.4 |
| bus_cycles | 6.12E+08 | 5.64E+08 | -4.80E+07 | -7.8 |
| cache_misses | 2.83E+04 | 2.11E+04 | -7.20E+03 | -25.4 |
| cache_references | 8.84E+04 | 8.61E+04 | -2.30E+03 | -2.6 |
| cpu_cycles | 1.77E+10 | 1.61E+10 | -1.60E+09 | -9.0 |
| instructions | 4.11E+10 | 3.80E+10 | -3.10E+09 | -7.5 |
| ref_cpu_cycles | 1.53E+10 | 1.41E+10 | -1.20E+09 | -7.8 |
| cpu_clock | 6.14E+09 | 5.65E+09 | -4.90E+08 | -8.0 |
| page_faults_min | 5.03E+02 | 4.76E+02 | -2.70E+01 | -5.4 |
| task_clock | 6.14E+09 | 5.65E+09 | -4.90E+08 | -8.0 |
| 类别 | 程序1 | 程序2 | |
|---|---|---|---|
| 时间/μs | 7.60E+04 | 3.67E+04 | |
| 能量/J | PACKAGE0 | 1.54 | 0.70 |
| PACKAGE1 | 1.63 | 0.83 | |
| DRAM0 | 0.22 | 0.10 | |
| DRAM1 | 0.42 | 0.21 |
Table 6 Energy consumed by program 1 and program 2
| 类别 | 程序1 | 程序2 | |
|---|---|---|---|
| 时间/μs | 7.60E+04 | 3.67E+04 | |
| 能量/J | PACKAGE0 | 1.54 | 0.70 |
| PACKAGE1 | 1.63 | 0.83 | |
| DRAM0 | 0.22 | 0.10 | |
| DRAM1 | 0.42 | 0.21 |
| 硬件事件和软件事件 | 程序1 | 程序2 | 硬件cache事件 | 程序1 | 程序2 |
|---|---|---|---|---|---|
| branch_instructions | 1.14E+07 | 1.11E+07 | dtlbreadaccess | 2.23E+06 | 2.23E+06 |
| branch_misses | 4.38E+03 | 1.50E+03 | dtlbreadmiss | 1.38E+02 | 2.06E+02 |
| bus_cycles | 7.60E+06 | 4.37E+06 | dtlbwriteaccess | 5.48E+06 | 4.49E+06 |
| cache_misses | 9.93E+04 | 5.03E+04 | dtlbwritemiss | 3.41E+02 | 9.80E+01 |
| cache_references | 1.47E+06 | 4.09E+05 | itlbreadaccess | 4.15E+02 | 9.90E+01 |
| cpu_cycles | 1.17E+08 | 6.02E+07 | itlbreadmiss | 1.49E+02 | 7.40E+01 |
| instructions | 5.68E+07 | 5.54E+07 | L1dreadaccess | 6.64E+06 | 5.72E+06 |
| ref_cpu_cycles | 1.90E+08 | 1.09E+08 | L1dreadmiss | 3.15E+06 | 1.47E+06 |
| cpu_clock | 7.63E+07 | 4.39E+07 | L1dwriteaccess | 1.00E+07 | 7.40E+06 |
| page_faults_min | 1.21E+03 | 1.10E+03 | L1ireadmiss | 1.95E+04 | 9.15E+03 |
| task_clock | 7.63E+07 | 4.39E+07 | LLreadaccess | 8.19E+05 | 2.09E+05 |
| LLreadmiss | 8.85E+03 | 4.59E+03 | |||
| LLwriteaccess | 1.14E+04 | 6.43E+03 | |||
| LLwritemiss | 1.11E+04 | 5.80E+03 |
Table 7 Performance events statistics of program 1 and program 2
| 硬件事件和软件事件 | 程序1 | 程序2 | 硬件cache事件 | 程序1 | 程序2 |
|---|---|---|---|---|---|
| branch_instructions | 1.14E+07 | 1.11E+07 | dtlbreadaccess | 2.23E+06 | 2.23E+06 |
| branch_misses | 4.38E+03 | 1.50E+03 | dtlbreadmiss | 1.38E+02 | 2.06E+02 |
| bus_cycles | 7.60E+06 | 4.37E+06 | dtlbwriteaccess | 5.48E+06 | 4.49E+06 |
| cache_misses | 9.93E+04 | 5.03E+04 | dtlbwritemiss | 3.41E+02 | 9.80E+01 |
| cache_references | 1.47E+06 | 4.09E+05 | itlbreadaccess | 4.15E+02 | 9.90E+01 |
| cpu_cycles | 1.17E+08 | 6.02E+07 | itlbreadmiss | 1.49E+02 | 7.40E+01 |
| instructions | 5.68E+07 | 5.54E+07 | L1dreadaccess | 6.64E+06 | 5.72E+06 |
| ref_cpu_cycles | 1.90E+08 | 1.09E+08 | L1dreadmiss | 3.15E+06 | 1.47E+06 |
| cpu_clock | 7.63E+07 | 4.39E+07 | L1dwriteaccess | 1.00E+07 | 7.40E+06 |
| page_faults_min | 1.21E+03 | 1.10E+03 | L1ireadmiss | 1.95E+04 | 9.15E+03 |
| task_clock | 7.63E+07 | 4.39E+07 | LLreadaccess | 8.19E+05 | 2.09E+05 |
| LLreadmiss | 8.85E+03 | 4.59E+03 | |||
| LLwriteaccess | 1.14E+04 | 6.43E+03 | |||
| LLwritemiss | 1.11E+04 | 5.80E+03 |
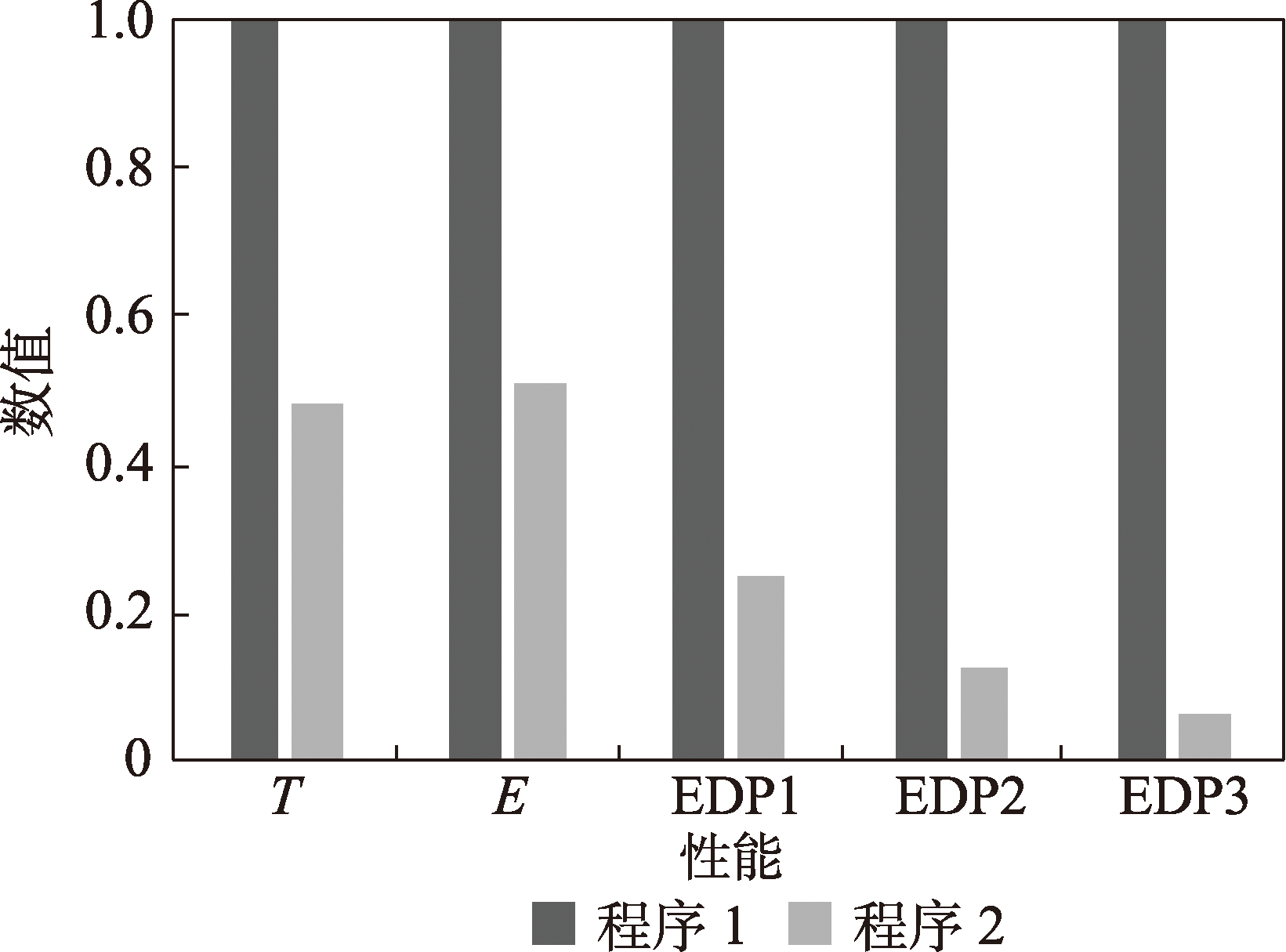
Fig.6 Normalized execution time, energy and EDP of program 1 and program 2
| 类别 | 程序3 | 程序4 | |
|---|---|---|---|
| 时间/μs | 1.76E+05 | 1.30E+05 | |
| 能量/J | PACKAGE0 | 3.58 | 2.75 |
| PACKAGE1 | 4.17 | 2.88 | |
| DRAM0 | 0.50 | 0.42 | |
| DRAM1 | 1.07 | 0.77 |
Table 8 Energy consumed by program 3 and program 4
| 类别 | 程序3 | 程序4 | |
|---|---|---|---|
| 时间/μs | 1.76E+05 | 1.30E+05 | |
| 能量/J | PACKAGE0 | 3.58 | 2.75 |
| PACKAGE1 | 4.17 | 2.88 | |
| DRAM0 | 0.50 | 0.42 | |
| DRAM1 | 1.07 | 0.77 |
| 硬件事件和软件事件 | 程序3 | 程序4 | 硬件cache事件 | 程序3 | 程序4 |
|---|---|---|---|---|---|
| branch_instructions | 3.95E+07 | 3.90E+07 | dtlbreadaccess | 9.00E+06 | 7.95E+06 |
| branch_misses | 3.00E+03 | 2.36E+03 | dtlbreadmiss | 2.39E+03 | 7.28E+02 |
| bus_cycles | 1.71E+07 | 1.31E+07 | dtlbwriteaccess | 1.98E+07 | 1.68E+07 |
| cache_misses | 2.54E+05 | 1.70E+05 | dtlbwritemiss | 1.23E+03 | 3.01E+02 |
| cache_references | 2.85E+06 | 1.31E+06 | itlbreadaccess | 9.00E+00 | 8.00E+00 |
| cpu_cycles | 3.32E+08 | 2.33E+08 | itlbreadmiss | 4.10E+01 | 1.70E+01 |
| instructions | 1.59E+08 | 1.57E+08 | L1dreadaccess | 2.31E+07 | 2.26E+07 |
| ref_cpu_cycles | 4.27E+08 | 3.27E+08 | L1dreadmiss | 8.05E+06 | 5.61E+06 |
| cpu_clock | 1.71E+08 | 1.31E+08 | L1dwriteaccess | 3.04E+07 | 2.87E+07 |
| page_faults_min | 7.28E+02 | 6.56E+02 | L1ireadmiss | 2.75E+04 | 2.40E+04 |
| task_clock | 1.71E+08 | 1.31E+08 | LLreadaccess | 1.45E+06 | 6.49E+05 |
| LLreadmiss | 1.35E+04 | 9.83E+03 | |||
| LLwriteaccess | 3.38E+04 | 2.07E+04 | |||
| LLwritemiss | 3.39E+04 | 1.99E+04 |
Table 9 Performance events statistics of program 3 and program 4
| 硬件事件和软件事件 | 程序3 | 程序4 | 硬件cache事件 | 程序3 | 程序4 |
|---|---|---|---|---|---|
| branch_instructions | 3.95E+07 | 3.90E+07 | dtlbreadaccess | 9.00E+06 | 7.95E+06 |
| branch_misses | 3.00E+03 | 2.36E+03 | dtlbreadmiss | 2.39E+03 | 7.28E+02 |
| bus_cycles | 1.71E+07 | 1.31E+07 | dtlbwriteaccess | 1.98E+07 | 1.68E+07 |
| cache_misses | 2.54E+05 | 1.70E+05 | dtlbwritemiss | 1.23E+03 | 3.01E+02 |
| cache_references | 2.85E+06 | 1.31E+06 | itlbreadaccess | 9.00E+00 | 8.00E+00 |
| cpu_cycles | 3.32E+08 | 2.33E+08 | itlbreadmiss | 4.10E+01 | 1.70E+01 |
| instructions | 1.59E+08 | 1.57E+08 | L1dreadaccess | 2.31E+07 | 2.26E+07 |
| ref_cpu_cycles | 4.27E+08 | 3.27E+08 | L1dreadmiss | 8.05E+06 | 5.61E+06 |
| cpu_clock | 1.71E+08 | 1.31E+08 | L1dwriteaccess | 3.04E+07 | 2.87E+07 |
| page_faults_min | 7.28E+02 | 6.56E+02 | L1ireadmiss | 2.75E+04 | 2.40E+04 |
| task_clock | 1.71E+08 | 1.31E+08 | LLreadaccess | 1.45E+06 | 6.49E+05 |
| LLreadmiss | 1.35E+04 | 9.83E+03 | |||
| LLwriteaccess | 3.38E+04 | 2.07E+04 | |||
| LLwritemiss | 3.39E+04 | 1.99E+04 |
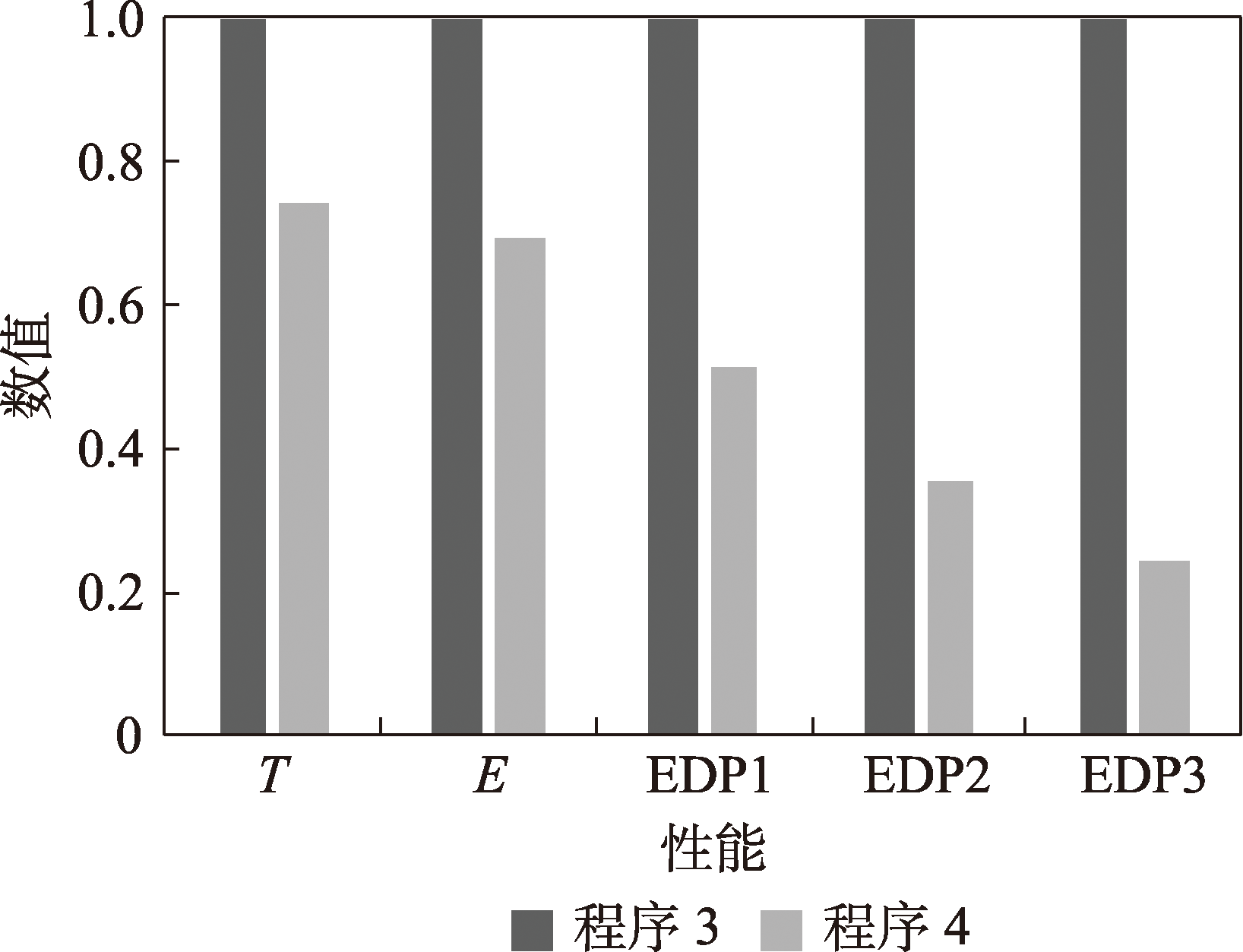
Fig.7 Normalized execution time, energy and EDP of program 3 and program 4

Fig.8 Comparison of per-column access and per-row access
| 类别 | 程序5 | 程序6 | |
|---|---|---|---|
| 时间/μs | 6.85E+04 | 1.97E+04 | |
| 能量/J | PACKAGE0 | 1.49 | 0.42 |
| PACKAGE1 | 1.49 | 0.41 | |
| DRAM0 | 0.24 | 0.08 | |
| DRAM1 | 0.31 | 0.11 |
Table 10 Energy consumed by program 5 and program 6
| 类别 | 程序5 | 程序6 | |
|---|---|---|---|
| 时间/μs | 6.85E+04 | 1.97E+04 | |
| 能量/J | PACKAGE0 | 1.49 | 0.42 |
| PACKAGE1 | 1.49 | 0.41 | |
| DRAM0 | 0.24 | 0.08 | |
| DRAM1 | 0.31 | 0.11 |
| 硬件事件和软件事件 | 程序5 | 程序6 | 硬件cache事件 | 程序5 | 程序6 |
|---|---|---|---|---|---|
| branch_instructions | 3.09E+06 | 3.07E+06 | dtlbreadaccess | 6.77E+05 | 7.93E+05 |
| branch_misses | 4.62E+03 | 3.00E+03 | dtlbreadmiss | 1.26E+03 | 5.40E+01 |
| bus_cycles | 6.86E+06 | 2.19E+06 | dtlbwriteaccess | 1.52E+06 | 1.95E+06 |
| cache_misses | 4.22E+05 | 2.74E+04 | dtlbwritemiss | 5.14E+02 | 3.11E+02 |
| cache_references | 5.19E+06 | 2.69E+05 | itlbreadaccess | 6.56E+02 | 1.25E+03 |
| cpu_cycles | 1.03E+08 | 2.79E+07 | itlbreadmiss | 2.20E+01 | 6.60E+01 |
| instructions | 1.82E+07 | 2.07E+07 | L1dreadaccess | 1.85E+06 | 2.12E+06 |
| ref_cpu_cycles | 1.72E+08 | 5.49E+07 | L1dreadmiss | 4.44E+06 | 7.54E+05 |
| cpu_clock | 6.89E+07 | 2.20E+07 | L1dwriteaccess | 2.48E+06 | 2.43E+06 |
| page_faults_min | 1.06E+03 | 1.06E+03 | L1ireadmiss | 5.31E+03 | 4.59E+03 |
| task_clock | 6.89E+07 | 2.20E+07 | LLreadaccess | 1.54E+06 | 1.07E+05 |
| LLreadmiss | 2.44E+05 | 2.19E+03 | |||
| LLwriteaccess | 3.53E+05 | 4.17E+03 | |||
| LLwritemiss | 2.73E+03 | 4.00E+03 |
Table 11 Performance events statistics of program 5 and program 6
| 硬件事件和软件事件 | 程序5 | 程序6 | 硬件cache事件 | 程序5 | 程序6 |
|---|---|---|---|---|---|
| branch_instructions | 3.09E+06 | 3.07E+06 | dtlbreadaccess | 6.77E+05 | 7.93E+05 |
| branch_misses | 4.62E+03 | 3.00E+03 | dtlbreadmiss | 1.26E+03 | 5.40E+01 |
| bus_cycles | 6.86E+06 | 2.19E+06 | dtlbwriteaccess | 1.52E+06 | 1.95E+06 |
| cache_misses | 4.22E+05 | 2.74E+04 | dtlbwritemiss | 5.14E+02 | 3.11E+02 |
| cache_references | 5.19E+06 | 2.69E+05 | itlbreadaccess | 6.56E+02 | 1.25E+03 |
| cpu_cycles | 1.03E+08 | 2.79E+07 | itlbreadmiss | 2.20E+01 | 6.60E+01 |
| instructions | 1.82E+07 | 2.07E+07 | L1dreadaccess | 1.85E+06 | 2.12E+06 |
| ref_cpu_cycles | 1.72E+08 | 5.49E+07 | L1dreadmiss | 4.44E+06 | 7.54E+05 |
| cpu_clock | 6.89E+07 | 2.20E+07 | L1dwriteaccess | 2.48E+06 | 2.43E+06 |
| page_faults_min | 1.06E+03 | 1.06E+03 | L1ireadmiss | 5.31E+03 | 4.59E+03 |
| task_clock | 6.89E+07 | 2.20E+07 | LLreadaccess | 1.54E+06 | 1.07E+05 |
| LLreadmiss | 2.44E+05 | 2.19E+03 | |||
| LLwriteaccess | 3.53E+05 | 4.17E+03 | |||
| LLwritemiss | 2.73E+03 | 4.00E+03 |

Fig.9 Normalized execution time, energy and EDP of program 5 and program 6
| [1] |
WEI G, QIAN D, YANG H, et al. FPowerTool: a function-level power profiling tool[J]. IEEE Access, 2019, 7: 185710-185719.
DOI URL |
| [2] | DAVID H, GORBATOV E, HANEBUTTE U R, et al. RAPL: memory power estimation and capping[C]// Proceedings of the 2010 ACM/IEEE International Symposium on Low-Power Electronics and Design, Austin, Aug 18-20, 2010. New York: ACM, 2010: 189-194. |
| [3] | Intel. Intel® 64 and IA-32 architectures software developer’s manual, volume 3b: system programming guide[R]. 2016: 33. |
| [4] | WEAVER V M, JOHNSON M, KASICHAYANULA K, et al. Measuring energy and power with PAPI[C]// Proceedings of the 41st International Conference on Parallel Processing Workshops, Pittsburgh, Sep 10-13, 2012. Washington: IEEE Computer Society, 2012: 262-268. |
| [5] | MCCRAW H, RALPH J, DANALIS A, et al. Power moni-toring with PAPI for extreme scale architectures and dataflow-based programming models[C]// Proceedings of the 2014 IEEE International Conference on Cluster Computing, Ma-drid, Sep 22-26, 2014. Washington: IEEE Computer Society, 2014: 385-391. |
| [6] | KUFRIN R. PerfSuite: an accessible, open source, performance analysis environment for Linux[C]// Proceedings of the 6th International Conference on Linux Clusters, Chapel Hill, 2005. |
| [7] | KUFRIN R. Measuring and improving application performance with perfsuite[J]. Linux Journal, 2005(135): 4. |
| [8] | ENBODY R. Perfmon: performance monitoring tool[D]. Lan-sing: Michigan State University, 1999. |
| [9] | ERANIAN S. Perfmon: Linux performance monitoring for IA-64[EB/OL]. [2020-12-14]. http://www.hpl.hp.com/research/linux/perfmon . |
| [10] | ERANIAN S. Perfmon2: a flexible performance monitoring interface for Linux[C]// Proceedings of the 2006 Ottawa Linux Symposium, Ottawa, Jul 2006: 269-288. |
| [11] | DE MELO A C. The new Linux “perf” tools[R]. Brazil: Red Hat Inc., 2010. |
| [12] | TREIBIG J, HAGER G, WELLEIN G. LIKWID:a light-weight performance-oriented tool suite for x86 multicore environments[C]// Proceedings of the 39th International Con-ference on Parallel Processing, San Diego, Sep 13-16, 2010. Washington: IEEE Computer Society, 2010: 207-216. |
| [13] | EULISSE G, TUURA L A. IgProf profiling tool[R]. Bosto: Northeastern University, 2005: 1-4. |
| [14] | KHAN K N, NYBACK F, OU Z H, et al. Energy profiling using IgProf[C]// Proceedings of the 15th IEEE/ACM Inter-national Symposium on Cluster, Cloud and Grid Compu-ting, Shenzhen, May 4-7, 2015. Washington: IEEE Computer Society, 2015: 1115-1118. |
| [15] | MANOUSAKIS I, ZAKKAK F S, PRATIKAKIS P, et al. TProf: an energy profiler for task-parallel programs[J]. Sus-tainable Computing: Informatics and Systems, 2015, 5: 1-13. |
| [16] | MUKHANOV L, PARASYRIS N, WANG Z, et al. ALEA: a fine-grained energy profiling tool[J]. ACM Transactions on Architecture and Code Optimization, 2017, 14(1): 1-25. |
| [17] | MUKHANOV L, NIKOLOPOULOS D S, DE SUPINSKI B R. ALEA: fine-grain energy profiling with basic block sampling[C]// Proceedings of the 2015 International Confe-rence on Parallel Architectures and Compilation, San Fran-cisco, Oct 18-21, 2015. Washington: IEEE Computer Society, 2015: 87-98. |
| [18] | SMEJKAL T, HÄHNEL M, ILSCHE T, et al. E-Team: prac-tical energy accounting for multi-core systems[C]// Procee-dings of the 2017 USENIX Annual Technical Conference, Santa Clara, Jul 12-14, 2017: 589-601. |
| [19] | 宋杰, 孙宗哲, 李甜甜, 等. 面向代码的软件能耗优化研究进展[J]. 计算机学报, 2016, 39(11): 2270-2290. |
| SONG J, SUN Z Z, LI T T, et al. Research advance on code oriented optimization of software energy consumption[J]. Chinese Journal of Computers, 2016, 39(11): 2270-2290. | |
| [20] | KANDEMIR M T, KOLCU I, KADAYIF I. Influence of loop optimizations on energy consumption of multi-bank memory systems[C]// LNCS 2304: Proceedings of the 11th International Conference on Compiler Construction, Grenoble, Apr 8-12, 2002. Berlin, Heidelberg: Springer, 2002: 276-292. |
| [21] | BUNSE C, HÖPFNER H, MANSOUR E, et al. Exploring the energy consumption of data sorting algorithms in em-bedded and mobile environments[C]// Proceedings of the 2009 10th International Conference on Mobile Data Mana-gement: Systems, Services and Middleware, Taipei, China, May 18-20, 2009. Washington: IEEE Computer Society, 2009: 600-607. |
| [22] | DAYARATHNA M, WEN Y, MEMBER S, et al. Data center energy consumption modeling: a survey[J]. IEEE Com-munications Surveys & Tutorials, 2016, 18(1): 732-794. |
| [23] | O’BRIEN K, PIETRI I, REDDY R, et al. A survey of power and energy predictive models in HPC systems and appli-cations[J]. ACM Computing Surveys, 2017, 50(3): 37. |
| [24] | ZANG W, GORDON-ROSS A. A survey on cache tuning from a power/energy perspective[J]. ACM Computing Sur-veys, 2013, 45(3): 32. |
| [25] | MONCHIERO M, CANAL R, GONZÁLEZ A. Design space exploration for multicore architectures: a power/performance/thermal view[C]// Proceedings of the 20th Annual Interna-tional Conference on Supercomputing, Cairns, Jun 28-Jul 1, 2006. New York: ACM, 2006: 177-186. |
| [26] | KOWARSCHIK M, WEISS C. An overview of cache opti-mization techniques and cache-aware numerical algorithms[C]// LNCS 2625: Proceedings of the Algorithms for Memory Hierarchies, Mar 10-14, 2002. Berlin, Heidelberg: Springer, 2003: 213-232. |
| [27] | WEI G, QIAN D P, YANG H L, et al. Modeling power con-sumption of the code execution using performance counters statistics[C]// Proceedings of the 20th International Confe-rence on Parallel and Distributed Computing, Applications and Technologies, Gold Coast, Dec 5-7, 2019. Piscataway: IEEE, 2019: 381-385. |
| [28] | BIENIA C, KUMAR S, SINGH J P, et al. The PARSEC ben-chmark suite: characterization and architectural implications[C]// Proceedings of the 17th International Conference on Parallel Architectures and Compilation Techniques, Toronto, Oct 25-29, 2008. New York: ACM, 2008: 72-81. |
| [29] | BAILEY D H, BARSZCZ E, BARTON J T, et al. The NAS parallel benchmarks[J]. The International Journal of Super-computing Applications, 1991, 5(3): 63-73. |
| [30] | IZENMAN A J. Linear discriminant analysis[M]// Modern Multivariate Statistical Techniques. Berlin, Heidelberg: Sp-ringer, 2013: 237-280. |
| [31] | CHE S, BOYER M, MENG J Y, et al. Rodinia: a bench-mark suite for heterogeneous computing[C]// Proceedings of the 2009 IEEE International Symposium on Workload Cha-racterization, Austin, Oct 4-6, 2009. Washington: IEEE Com-puter Society, 2009: 44-54. |
| [32] | Rogue Wave Software. CPU cache optimization: does it matter? Should I worry? Why? An exploration of the world of CPU cache performance[R/OL]. [2020-12-14]. https://studylib.net/doc/18141740/cpu-cache-optimization--does-it-matter . |
| [33] | LAROS III J H, PEDRETTI K T, KELLY S M, et al. Energy-efficient high performance computing: measurement and tuning[M]. Berlin, Heidelberg: Springer, 2012. |
| [34] | HOROWITZ M, INDERMAUR T, GONZALEZ R. Low-power digital design[C]// Proceedings of the 1994 IEEE Symposium on Low Power Electronics, San Diego, Oct 10-12, 1994. Piscataway: IEEE, 1994: 8-11. |
| [1] | ZHAO Xuewu, WANG Hongmei, LIU Chaohui, LI Lingling, BO Shukui, JI Junzhong. Artificial Jellyfish Search Optimization Algorithm for Human Brain Functional Parcellation [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(8): 1829-1841. |
| [2] | GUO Jinxin, ZHANG Guangting, ZHANG Yunquan, CHEN Zehua, JIA Haipeng. High-Performance Implementation and Optimization of Cooley-Tukey FFT Algorithm [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(6): 1304-1315. |
| [3] | MAO Yimin, GENG Junhao. Improved Parallel Random Forest Algorithm Combining Information Theory and Norm [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(5): 1064-1075. |
| [4] | LI Jinhong, WANG Lizhen, ZHOU Lihua. Top-k Average Utility Co-location Pattern Mining of Fuzzy Features [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(5): 1053-1063. |
| [5] | CHEN Liyue, CHAI Di, WANG Leye. UCTB: Spatiotemporal Crowd Flow Prediction Toolbox [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(4): 835-843. |
| [6] | ZHANG Shaowei, WANG Xin, CHEN Zirui, WANG Lin, XU Dawei, JIA Yongzhe. Survey of Supervised Joint Entity Relation Extraction Methods [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(4): 713-733. |
| [7] | JIANG Yiying, ZHANG Liping, JIN Feihu, HAO Xiaohong. Groups Nearest Neighbor Query of Mixed Data in Spatial Database [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(2): 348-358. |
| [8] | LI Zhaoyang, LI Lin, TAO Xiaohui. Two-Stream Graph Convolutional Neural Network for Dynamic Traffic Flow Fore-casting [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(2): 384-394. |
| [9] | ZHAO Hengtai, ZHAO Yuhai, YUAN Ye, JI Hangxu, QIAO Baiyou, WANG Guoren. Optimization for Large-Scale Dimension Table Connection Technology in Distributed Environment [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(2): 337-347. |
| [10] | LIU Weiming, ZHANG Chi, MAO Yimin. Hybrid Parallel Frequent Itemsets Mining Algorithm by Using N-List Structure [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(1): 120-136. |
| [11] | ZONG Fengbo, ZHAO Yuhai, WANG Guoren, JI Hangxu. Optimization Method of Projection and Order for Multiple Tables Join [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(1): 106-119. |
| [12] | LIN Hongwu1,2, YOU Chao1,2, ZHOU Minghui1,2+, MEI Hong1,2. Proxy Centric Approach for Component Resource Monitoring on OSGi Platform [J]. Journal of Frontiers of Computer Science and Technology, 2011, 5(1): 23-31. |
| [13] | ZHU Xiaohu1,2, SONG Wenjun1,2, WANG Chongjun1,2+, XIE Junyuan1,2. Improved Algorithm Based on Girvan-Newman Algorithm for Community Detection [J]. Journal of Frontiers of Computer Science and Technology, 2010, 4(12): 1101-1108. |
| [14] | ZENG Hongwei+; MIAO Huaikou. Applying Model Checking to Data Flow Testing of Components [J]. Journal of Frontiers of Computer Science and Technology, 2010, 4(12): 1121-1130. |
| [15] | YUAN Chongyi1,2, HUANG Yu1,2,3+, ZHAO Wen1,2,3, HUANG Shuzhi2. O_expressions: A Petri Net Representation* [J]. Journal of Frontiers of Computer Science and Technology, 2010, 4(11): 961-976. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
/D:/magtech/JO/Jwk3_kxyts/WEB-INF/classes/