
Journal of Frontiers of Computer Science and Technology ›› 2022, Vol. 16 ›› Issue (7): 1439-1461.DOI: 10.3778/j.issn.1673-9418.2108105
• Surveys and Frontiers • Previous Articles Next Articles
HAN Yi1, QIAO Linbo2, LI Dongsheng2, LIAO Xiangke2,+( )
)
Received:2021-08-30
Revised:2022-03-22
Online:2022-07-01
Published:2022-07-25
Supported by:
韩毅1, 乔林波2, 李东升2, 廖湘科2,+()
作者简介:韩毅(1993—),男,山东青岛人,博士,讲师,主要研究方向为自然语言处理、知识图谱等。 基金资助:CLC Number:
HAN Yi, QIAO Linbo, LI Dongsheng, LIAO Xiangke. Review of Knowledge-Enhanced Pre-trained Language Models[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(7): 1439-1461.
韩毅, 乔林波, 李东升, 廖湘科. 知识增强型预训练语言模型综述[J]. 计算机科学与探索, 2022, 16(7): 1439-1461.
Add to citation manager EndNote|Ris|BibTeX
URL: http://fcst.ceaj.org/EN/10.3778/j.issn.1673-9418.2108105

Fig.1 Pre-trained language model combined with knowledge graph to solve practical problems
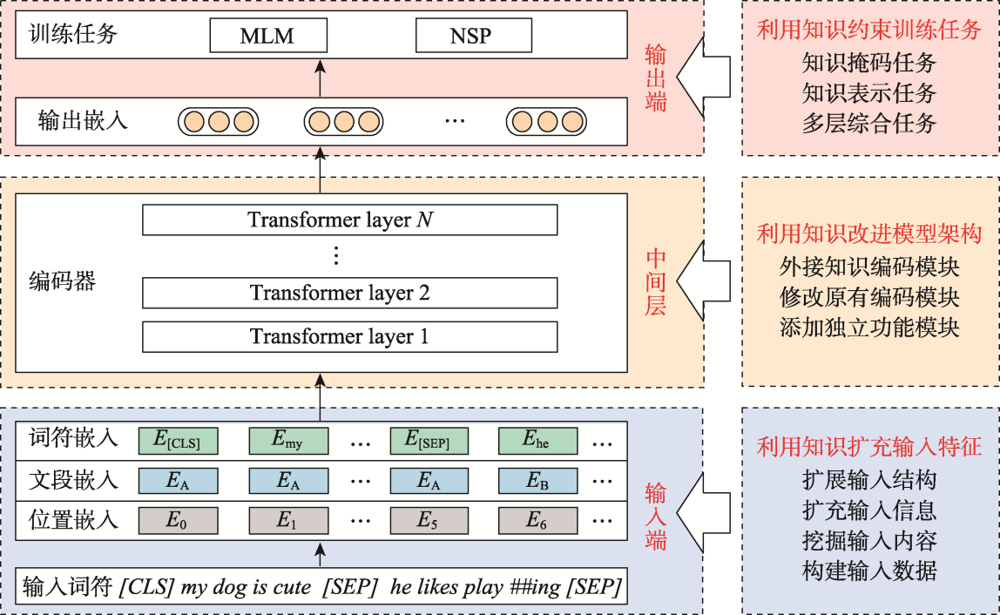
Fig.2 Three kinds of knowledge-enhanced methods divided by structure

Fig.3 Structures of word-knowledge tree and word-knowledge graph

Fig.4 Instances of combining entity embeddings and text embeddings on input side

Fig.5 Three methods of using knowledge to improve model architecture
| 增强模型 | 基线模型 | 单句分类 | 自然语言推理任务 | 语义相似度任务 | 基线分数 | 模型分数 | 差值 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CoLA (Mc) | SST-2 (Ac) | MNLI(m/mm) | QNLI (Ac) | RTE (Ac) | WNLI (Ac) | MRPC (Ac/F1) | STS-B (Pc/Sc) | QQP (Ac/F1) | |||||
| ERNIE 2.0BASE | BERTBASE | 55.2 | 95.0 | 86.1/85.5 | 92.9 | 74.8 | 65.1 | 86.1/89.9 | 87.6/86.5 | 89.8/73.2 | 79.6 | 82.1 | +2.5 |
| ERNIE 2.0LARGE | BERTLARGE | 63.5 | 95.6 | 88.7/88.8 | 94.6 | 80.2 | 67.8 | 87.4/90.2 | 91.2/90.6 | 90.1/73.8 | 82.1 | 84.8 | +2.7 |
| BERT-CSbase | BERTBASE | 54.3 | 93.6 | 84.7/83.9 | 91.2 | 69.5 | — | —/95.9 | —/86.4 | —/72.1 | 79.6 | 81.3 | +1.7 |
| BERT-CSlarge | BERTLARGE | 60.7 | 94.1 | 86.7/85.8 | 92.6 | 70.7 | — | —/89.0 | —/86.6 | —/72.1 | 82.1 | 82.0 | -0.1 |
| SemBERTBASE | BERTBASE | 57.8 | 93.5 | 84.4/84.0 | 90.9 | 69.3 | 90.9 | —/88.2 | 71.8/— | —/87.3 | 79.6 | 81.8 | +2.2 |
| SemBERTLARGE | BERTLARGE | 62.3 | 94.6 | 87.6/86.3 | 94.6 | 84.5 | 94.6 | —/91.2 | 72.8/— | —/87.8 | 82.1 | 85.6 | +3.5 |
| CorefBERTBASE | BERTBASE | 51.5 | 93.7 | 84.2/83.5 | 90.5 | 67.2 | — | —/89.1 | —/85.8 | —/71.3 | 79.6 | 79.6 | 0 |
| CorefBERTLARGE | BERTLARGE | 62.0 | 94.7 | 86.9/85.7 | 92.9 | 70.0 | — | —/89.3 | —/86.3 | —/71.7 | 82.1 | 82.2 | +0.1 |
| Thu-ERNIE | BERTBASE | 52.3 | 93.5 | 84.0/83.2 | 91.3 | 68.8 | — | —/88.2 | —/83.2 | —/71.2 | 79.6 | 79.5 | -0.1 |
| LIBERT(2M) | BERTBASE | 35.3 | 90.8 | 79.9/78.8 | 87.2 | 63.6 | — | 86.6/81.7 | 82.6/— | 69.3/88.2 | 75.3 | 76.7 | +1.4 |
| OM-ADAPT | BERTBASE | 53.5 | 93.4 | 84.2/83.7 | 90.6 | 68.2 | — | —/87.9 | —/85.9 | —/71.1 | 79.6 | 79.8 | +0.2 |
| CN-ADAPT | BERTBASE | 49.8 | 93.9 | 84.2/83.3 | 90.6 | 69.7 | — | —/88.9 | —/85.8 | —/71.6 | 79.6 | 79.8 | +0.2 |
| ERICABERT | BERTBASE | 57.9 | 92.8 | 84.5/84.7 | 90.7 | 69.6 | — | —/89.5 | —/89.5 | —/88.3 | 83.0 | 83.1 | +0.1 |
| ERICARoBERTa | RoBERTaBASE | 63.5 | 95.0 | 87.5/87.5 | 92.6 | 78.5 | — | —/91.5 | —/90.7 | —/91.6 | 86.4 | 86.5 | +0.1 |
| KEPLER-Wiki* | RoBERTaBASE | 63.6 | 94.5 | 87.2/86.5 | 92.4 | 85.2 | — | —/89.3 | —/91.2 | —/91.7 | 86.4 | 86.8 | +0.4 |
| CoLAKE* | RoBERTaBASE | 63.4 | 94.6 | 87.4/87.2 | 92.4 | 77.9 | — | —/90.9 | —/90.8 | —/92.0 | 86.4 | 86.3 | -0.1 |
Table 1 Score statistics of GLUE task %
| 增强模型 | 基线模型 | 单句分类 | 自然语言推理任务 | 语义相似度任务 | 基线分数 | 模型分数 | 差值 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CoLA (Mc) | SST-2 (Ac) | MNLI(m/mm) | QNLI (Ac) | RTE (Ac) | WNLI (Ac) | MRPC (Ac/F1) | STS-B (Pc/Sc) | QQP (Ac/F1) | |||||
| ERNIE 2.0BASE | BERTBASE | 55.2 | 95.0 | 86.1/85.5 | 92.9 | 74.8 | 65.1 | 86.1/89.9 | 87.6/86.5 | 89.8/73.2 | 79.6 | 82.1 | +2.5 |
| ERNIE 2.0LARGE | BERTLARGE | 63.5 | 95.6 | 88.7/88.8 | 94.6 | 80.2 | 67.8 | 87.4/90.2 | 91.2/90.6 | 90.1/73.8 | 82.1 | 84.8 | +2.7 |
| BERT-CSbase | BERTBASE | 54.3 | 93.6 | 84.7/83.9 | 91.2 | 69.5 | — | —/95.9 | —/86.4 | —/72.1 | 79.6 | 81.3 | +1.7 |
| BERT-CSlarge | BERTLARGE | 60.7 | 94.1 | 86.7/85.8 | 92.6 | 70.7 | — | —/89.0 | —/86.6 | —/72.1 | 82.1 | 82.0 | -0.1 |
| SemBERTBASE | BERTBASE | 57.8 | 93.5 | 84.4/84.0 | 90.9 | 69.3 | 90.9 | —/88.2 | 71.8/— | —/87.3 | 79.6 | 81.8 | +2.2 |
| SemBERTLARGE | BERTLARGE | 62.3 | 94.6 | 87.6/86.3 | 94.6 | 84.5 | 94.6 | —/91.2 | 72.8/— | —/87.8 | 82.1 | 85.6 | +3.5 |
| CorefBERTBASE | BERTBASE | 51.5 | 93.7 | 84.2/83.5 | 90.5 | 67.2 | — | —/89.1 | —/85.8 | —/71.3 | 79.6 | 79.6 | 0 |
| CorefBERTLARGE | BERTLARGE | 62.0 | 94.7 | 86.9/85.7 | 92.9 | 70.0 | — | —/89.3 | —/86.3 | —/71.7 | 82.1 | 82.2 | +0.1 |
| Thu-ERNIE | BERTBASE | 52.3 | 93.5 | 84.0/83.2 | 91.3 | 68.8 | — | —/88.2 | —/83.2 | —/71.2 | 79.6 | 79.5 | -0.1 |
| LIBERT(2M) | BERTBASE | 35.3 | 90.8 | 79.9/78.8 | 87.2 | 63.6 | — | 86.6/81.7 | 82.6/— | 69.3/88.2 | 75.3 | 76.7 | +1.4 |
| OM-ADAPT | BERTBASE | 53.5 | 93.4 | 84.2/83.7 | 90.6 | 68.2 | — | —/87.9 | —/85.9 | —/71.1 | 79.6 | 79.8 | +0.2 |
| CN-ADAPT | BERTBASE | 49.8 | 93.9 | 84.2/83.3 | 90.6 | 69.7 | — | —/88.9 | —/85.8 | —/71.6 | 79.6 | 79.8 | +0.2 |
| ERICABERT | BERTBASE | 57.9 | 92.8 | 84.5/84.7 | 90.7 | 69.6 | — | —/89.5 | —/89.5 | —/88.3 | 83.0 | 83.1 | +0.1 |
| ERICARoBERTa | RoBERTaBASE | 63.5 | 95.0 | 87.5/87.5 | 92.6 | 78.5 | — | —/91.5 | —/90.7 | —/91.6 | 86.4 | 86.5 | +0.1 |
| KEPLER-Wiki* | RoBERTaBASE | 63.6 | 94.5 | 87.2/86.5 | 92.4 | 85.2 | — | —/89.3 | —/91.2 | —/91.7 | 86.4 | 86.8 | +0.4 |
| CoLAKE* | RoBERTaBASE | 63.4 | 94.6 | 87.4/87.2 | 92.4 | 77.9 | — | —/90.9 | —/90.8 | —/92.0 | 86.4 | 86.3 | -0.1 |
| 增强模型 | 基线模型 | 数据集 | 评测指标 | 基线得分/% | 模型得分/% | 差值/% |
|---|---|---|---|---|---|---|
| K-APDATER | RoBERTaLARGE | LAMA-Google-RE | P@1 | 4.8 | 7.0 | +2.2 |
| K-APDATER | RoBERTaLARGE | LAMA-UHN-Google-RE | P@1 | 2.5 | 3.7 | +1.2 |
| K-APDATER | RoBERTaLARGE | LAMA-T-REx | P@1 | 27.1 | 29.1 | +2.0 |
| K-APDATER | RoBERTaLARGE | LAMA-UHN-T-REx | P@1 | 20.1 | 23.0 | +2.9 |
| E-BERT-concat | BERTBASE | LAMA-Google-RE+LAMA-T-REx | Hits@1 | 22.3 | 32.6 | +10.3 |
| E-BERT-concat | BERTBASE | LAMA-UHN | Hits@1 | 20.2 | 31.1 | +10.9 |
| CoLAKE | RoBERTaBASE | LAMA-Google-RE | P@1 | 5.3 | 9.5 | +4.2 |
| CoLAKE | RoBERTaBASE | LAMA-UHN-Google-RE | P@1 | 2.2 | 4.9 | +2.7 |
| CoLAKE | RoBERTaBASE | LAMA-T-REx | P@1 | 24.7 | 28.8 | +4.1 |
| CoLAKE | RoBERTaBASE | LAMA-UHN-T-REx | P@1 | 17.0 | 20.4 | +3.4 |
| CALM | T5Base | LAMA-ConceptNet | MRR | 11.5 | 12.1 | +0.6 |
| CALM | T5Base | LAMA-ConceptNet | P@1 | 5.9 | 6.5 | +0.6 |
| CALM | T5Base | LAMA-ConceptNet | P@10 | 21.6 | 22.5 | +0.9 |
| KEPLER-Wiki | RoBERTaBASE | LAMA-Google-RE | P@1 | 5.3 | 7.3 | +2.0 |
| KEPLER-Wiki | RoBERTaBASE | LAMA-SQuAD | P@1 | 9.1 | 14.3 | +5.2 |
| KEPLER-W+W | RoBERTaBASE | LAMA-ConceptNet | P@1 | 17.6 | 19.5 | -1.9 |
| KEPLER-W+W | RoBERTaBASE | LAMA-UHN-Google-RE | P@1 | 2.2 | 4.1 | +1.9 |
| KALM | GPT-2 | LAMA-Google-RE | P@1 | 4.9 | 5.4 | +0.5 |
| KALM | GPT-2 | LAMA-T-REx | P@1 | 15.7 | 26.0 | +10.3 |
| KALM | GPT-2 | LAMA-ConceptNet | P@1 | 9.7 | 10.7 | +1.0 |
| KALM | GPT-2 | LAMA-SQuAD | P@1 | 5.9 | 11.9 | +6.0 |
| EaE | BERTBASE | LAMA-ConceptNet | P@1 | 15.6 | 10.7 | -4.9 |
| EaE | BERTBASE | LAMA-Google-RE | P@1 | 9.8 | 9.4 | -0.4 |
| EaE | BERTBASE | LAMA-T-REx | P@1 | 31.1 | 37.4 | +6.3 |
| EaE | BERTBASE | LAMA-SQuAD | P@1 | 14.1 | 22.4 | +8.3 |
Table 2 Score statistics of LAMA task
| 增强模型 | 基线模型 | 数据集 | 评测指标 | 基线得分/% | 模型得分/% | 差值/% |
|---|---|---|---|---|---|---|
| K-APDATER | RoBERTaLARGE | LAMA-Google-RE | P@1 | 4.8 | 7.0 | +2.2 |
| K-APDATER | RoBERTaLARGE | LAMA-UHN-Google-RE | P@1 | 2.5 | 3.7 | +1.2 |
| K-APDATER | RoBERTaLARGE | LAMA-T-REx | P@1 | 27.1 | 29.1 | +2.0 |
| K-APDATER | RoBERTaLARGE | LAMA-UHN-T-REx | P@1 | 20.1 | 23.0 | +2.9 |
| E-BERT-concat | BERTBASE | LAMA-Google-RE+LAMA-T-REx | Hits@1 | 22.3 | 32.6 | +10.3 |
| E-BERT-concat | BERTBASE | LAMA-UHN | Hits@1 | 20.2 | 31.1 | +10.9 |
| CoLAKE | RoBERTaBASE | LAMA-Google-RE | P@1 | 5.3 | 9.5 | +4.2 |
| CoLAKE | RoBERTaBASE | LAMA-UHN-Google-RE | P@1 | 2.2 | 4.9 | +2.7 |
| CoLAKE | RoBERTaBASE | LAMA-T-REx | P@1 | 24.7 | 28.8 | +4.1 |
| CoLAKE | RoBERTaBASE | LAMA-UHN-T-REx | P@1 | 17.0 | 20.4 | +3.4 |
| CALM | T5Base | LAMA-ConceptNet | MRR | 11.5 | 12.1 | +0.6 |
| CALM | T5Base | LAMA-ConceptNet | P@1 | 5.9 | 6.5 | +0.6 |
| CALM | T5Base | LAMA-ConceptNet | P@10 | 21.6 | 22.5 | +0.9 |
| KEPLER-Wiki | RoBERTaBASE | LAMA-Google-RE | P@1 | 5.3 | 7.3 | +2.0 |
| KEPLER-Wiki | RoBERTaBASE | LAMA-SQuAD | P@1 | 9.1 | 14.3 | +5.2 |
| KEPLER-W+W | RoBERTaBASE | LAMA-ConceptNet | P@1 | 17.6 | 19.5 | -1.9 |
| KEPLER-W+W | RoBERTaBASE | LAMA-UHN-Google-RE | P@1 | 2.2 | 4.1 | +1.9 |
| KALM | GPT-2 | LAMA-Google-RE | P@1 | 4.9 | 5.4 | +0.5 |
| KALM | GPT-2 | LAMA-T-REx | P@1 | 15.7 | 26.0 | +10.3 |
| KALM | GPT-2 | LAMA-ConceptNet | P@1 | 9.7 | 10.7 | +1.0 |
| KALM | GPT-2 | LAMA-SQuAD | P@1 | 5.9 | 11.9 | +6.0 |
| EaE | BERTBASE | LAMA-ConceptNet | P@1 | 15.6 | 10.7 | -4.9 |
| EaE | BERTBASE | LAMA-Google-RE | P@1 | 9.8 | 9.4 | -0.4 |
| EaE | BERTBASE | LAMA-T-REx | P@1 | 31.1 | 37.4 | +6.3 |
| EaE | BERTBASE | LAMA-SQuAD | P@1 | 14.1 | 22.4 | +8.3 |
| [1] | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies, Minneapolis, Jun 2-7, 2019. Stroudsburg: ACL, 2019: 4171-4186. |
| [2] | BIANCHI F, HOVY D. On the gap between adoption and understanding in NLP[C]// Findings of the Association for Computational Linguistics, Aug 1-6, 2021. Stroudsburg: ACL, 2021: 3895-3901. |
| [3] | 索传军. 网络信息资源组织研究的新视角[J]. 图书馆情报工作, 2013, 57(7): 5-12. |
| SUO C J. A new perspective for web resource organization research[J]. Library and Information Service, 2013, 57(7): 5-12. | |
| [4] | LOGAN IV R L, LIU N F, PETERS M E, et al. Barack’s wife Hillary: using knowledge graphs for fact-aware language modeling[C]// Proceedings of the 57th Conference of the Association for Computational Linguistics, Florence, Jul 28- Aug 2, 2019. Stroudsburg: ACL, 2019: 5962-5971. |
| [5] |
JI S X, PAN S R, CAMBRIA E, et al. A survey on knowledge graphs: representation, acquisition, and applications[J]. IEEE Transactions on Neural Networks and Learning Systems, 2022, 33(2): 494-514.
DOI URL |
| [6] | ZHANG Z Y, HAN X, LIU Z Y, et al. ERNIE: enhanced language representation with informative entities[C]// Proceedings of the 57th Conference of the Association for Computational Linguistics, Florence, Jul 28-Aug 2, 2019. Stroudsburg: ACL, 2019: 1441-1451. |
| [7] |
SU Y S, HAN X, ZHANG Z Y, et al. CokeBERT: contextual knowledge selection and embedding towards enhanced pre-trained language models[J]. AI Open, 2021, 2: 127-134.
DOI URL |
| [8] | MCCLOSKEY M, COHEN N J. Catastrophic interference in connectionist networks: the sequential learning problem[J]. Psychology of Learning and Motivation, 1989, 24: 109-165. |
| [9] | 刘峤, 李杨, 段宏, 等. 知识图谱构建技术综述[J]. 计算机研究与发展, 2016, 53(3): 582-600. |
| LIU Q, LI Y, DUAN H, et al. Knowledge graph construction techniques[J]. Journal of Computer Research and Development, 2016, 53(3): 582-600. | |
| [10] | AMIT S. Introducing the knowledge graph[R]. America: Official Blog of Google, 2012. |
| [11] | MAHDISOLTANI F, BIEGA J, SUCHANEK F M. YAGO3: a knowledge base from multilingual wikipedias[C]// Procee-dings of the 7th Biennial Conference on Innovative Data Systems Research, Asilomar, Jan 4-7, 2015: 1-11. |
| [12] | VRANDEČIĆ D, KRÖTZSCH M. Wikidata: a free collaborative knowledgebase[J]. Communications of the ACM, 2014, 57(10): 78-85. |
| [13] | BOLLACKER K D, COOK R P, TUFTS P. Freebase: a shared database of structured general human knowledge[C]// Proceedings of the 22nd AAAI Conference on A.pngicial Intelligence, Vancouver, Jul 22-26, 2007. Menlo Park: AAAI, 2007: 1962-1963. |
| [14] |
BIZER C, LEHMANN J, KOBILAROV G, et al. DBpedia—a crystallization point for the web of data[J]. Journal of Web Semantics, 2009, 7(3): 154-165.
DOI URL |
| [15] | SWARTZ A. MusicBrainz: a semantic web service[J]. IEEE Intelligent Systems, 2002, 17(1): 76-77. |
| [16] | AHLERS D. Assessment of the accuracy of GeoNames gazetteer data[C]// Proceedings of the 7th Workshop on Geographic Information Retrieval, Orlando, Nov 5, 2013. New York: ACM, 2013: 74-81. |
| [17] | WISHART D S, KNOX C, GUO A C, et al. DrugBank: a comprehensive resource for in silico drug discovery and exploration[J]. Nucleic Acids Research, 2006, 34: 668-672. |
| [18] |
WANG X Z, GAO T Y, ZHU Z C, et al. KEPLER: a unified model for knowledge embedding and pre-trained language representation[J]. Transactions of the Association for Computational Linguistics, 2021, 9: 176-194.
DOI URL |
| [19] | HAO J, CHEN M, YU W, et al. Universal representation learning of knowledge bases by jointly embedding instances and ontological concepts[C]// Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, Aug 4-8, 2019. New York: ACM, 2019: 1709-1719. |
| [20] | CAMBRIA E, SONG Y Q, WANG H X, et al. Semantic multidimensional scaling for open-domain sentiment analysis[J]. IEEE Intelligent Systems, 2014, 29(2): 44-51. |
| [21] | 徐增林, 盛泳潘, 贺丽荣, 等. 知识图谱技术综述[J]. 电子科技大学学报, 2016, 45(4): 589-606. |
| XU Z L, SHENG Y P, HE L R, et al. Review on knowledge graph techniques[J]. Journal of University of Electronic Science and Technology of China, 2016, 45(4): 589-606. | |
| [22] | XIONG C Y, POWER R, CALLAN J. Explicit semantic ranking for academic search via knowledge graph embedding[C]// Proceedings of the 26th International Conference on World Wide Web, Perth, Apr 3-7, 2017. New York: ACM, 2017: 1271-1279. |
| [23] | DAI Z H, LI L, XU W. CFO: conditional focused neural question answering with large-scale knowledge bases[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Aug 7-12, 2016. Stroudsburg: ACL, 2016: 800-810. |
| [24] | ZHANG F Z, YUAN N J, LIAN D F, et al. Collaborative knowledge base embedding for recommender systems[C]// Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, Aug 13-17, 2016. New York: ACM, 2016: 353-362. |
| [25] | LIU Z B, NIU Z Y, WU H, et al. Knowledge aware conversation generation with explainable reasoning over augmented graphs[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, Nov 3-7, 2019. Stroudsburg: ACL, 2019: 1782-1792. |
| [26] | SPEER R, HAVASI C. ConceptNet 5: a large semantic network for relational knowledge[M]// GUREVYCHI, KIMJ. The People’s Web Meets NLP. Berlin, Heidelberg: Springer, 2013. |
| [27] | MILLER G A. WordNet: an electronic lexical database[M]. Cambridge: MIT Press, 1998. |
| [28] |
QIU X P, SUN T X, XU Y G, et al. Pre-trained models for natural language processing: a survey[J]. Science China Technological Sciences, 2020, 63: 1872-1897.
DOI URL |
| [29] | TURIAN J P, RATINOV L A, BENGIO Y. Word representations: a simple and general method for semi-supervised lear-ning[C]// Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, Uppsala, Jul 11-16, 2010. Stroudsburg: ACL, 2010: 384-394. |
| [30] | MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality[C]// Advances in Neural Information Processing Systems 26, Lake Tahoe, Dec 5-8, 2013. Red Hook: Curran Associates, 2013: 3111-3119. |
| [31] | PENNINGTON J, SOCHER R, MANNING C D. Glove: global vectors for word representation[C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Oct 25-29, 2014. Stroudsburg: ACL, 2014: 1532-1543. |
| [32] | PETERS M E, NEUMANN M, LYYER M, et al. Deep contextualized word representations[C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies, New Orleans, Jun 1-6, 2018. Stroudsburg: ACL, 2018: 2227-2237. |
| [33] | RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving language understanding by generative pre-training[EB/OL]. [2020-09-26]. https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf. |
| [34] | VASWANI A, SHAZEER N, PARMARN, et al. Attention is all you need[C]// Advances in Neural Information Processing Systems 30, Long Beach, Dec 4-9, 2017. Red Hook: Curran Associates, 2017: 5998-6008. |
| [35] | KURSUNCU U, GAUR M, SHETH A. Knowledge infused learning (K-IL): towards deep incorporation of knowledge in deep learning[J]. arXiv: 1912. 00512, 2019. |
| [36] | QIN Y, LIN Y, TAKANOBU R, et al. ERICA: improving entity and relation understanding for pre-trained language models via contrastive learning[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Aug 1-6, 2021. Stroudsburg: ACL, 2021: 3350-3363. |
| [37] | XIONG W H, DU J F, WANG W Y, et al. Pretrained encyclopedia: weakly supervised knowledge-pretrained language model[C]// Proceedings of the 8th International Conference on Learning Representations, Addis Ababa, Apl 26-30, 2020: 1-22. |
| [38] | ROSSET C, XIONG C, PHAN M, et al. Knowledge-aware language model pretraining[J]. arXiv: 2007. 00655, 2020. |
| [39] | XU S, LI H R, YUAN P, et al. K-PLUG: knowledge-injected pre-trained language model for natural language understanding and generation in E-commerce[C]// Findings of the Association for Computational Linguistics, Punta Cana, Nov 16-20, 2021. Stroudsburg: ACL, 2021: 1-17. |
| [40] | LIU W J, ZHOU P, ZHAO Z, et al. K-BERT: enabling language representation with knowledge graph[C]// Proceedings of the 2020 AAAI Conference on A.pngicial Intelligence, New York, Feb 7-12, 2020. Menlo Park: AAAI, 2020: 2901-2908. |
| [41] | SUN T, SHAO Y, QIU X, et al. CoLAKE: contextualized language and knowledge embedding[C]// Proceedings of the 34th AAAI Conference on A.pngicial Intelligence, the 32nd Innovative Applications of A.pngicial Intelligence Conference, the 10th AAAI Symposium on Educational Advances in A.pngicial Intelligence, New York, Feb 7-12, 2020. Menlo Park: AAAI, 2020: 3660-3670. |
| [42] | YAMADA I, ASAI A, SHINDO H, et al. LUKE: deep contextualized entity representations with entity-aware self-attention[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, Nov 16-20, 2020. Stroudsburg: ACL, 2020: 6442-6454. |
| [43] | PÖRNER N, WALTINGER U, SCHÜTZE H. E-BERT: efficient-yet-effective entity embeddings for BERT[C]// Findings of the Association for Computational Linguistics, Nov 16-20, 2020. Stroudsburg: ACL, 2020: 803-818. |
| [44] | LIU A L, DU J F, STOYANOV V. Knowledge-augmented language model and its application to unsupervised named-entity recognition[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies, Minneapolis, Jun 2-7, 2019. Stroudsburg: ACL, 2019: 1142-1150. |
| [45] | LIU X, YIN D, ZHANG X, et al. OAG-BERT: pre-train heterogeneous entity-augmented academic language models[J]. arXiv: 2103. 02410, 2021. |
| [46] | ZHANG F J, LIU X, TANG J, et al. OAG: toward linking large-scale heterogeneous entity graphs[C]// Proceedings of the 25th ACM SIGKDD International Conference on Know-ledge Discovery and Data Mining, Anchorage, Aug 4-8, 2019. New York: ACM, 2019: 2585-2595. |
| [47] | LEE J, YOON W, KIM S, et al. BioBERT: a pre-trained biomedical language representation model for biomedical text mining[J]. Bioinformatics, 2020, 36(4): 1234-1240. |
| [48] | BELTAGY I, LO K, COHAN A. SciBERT: a pretrained language model for scie.pngic text[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, Nov 3-7, 2019. Stroudsburg: ACL, 2019: 3613-3618. |
| [49] | LO K, WANGL L L, NEUMANN M, et al. S2ORC: the semantic scholar open research corpus[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Jul 5-10, 2020. Stroudsburg: ACL, 2020: 4969-4983. |
| [50] | LAUSHER A, VULIC I, PONTI E M, et al. Specializing unsupervised pretraining models for word-level semantic similarity[C]// Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Dec 8-13, 2020: 1371-1383. |
| [51] | ZHANG Z S, WU Y W, ZHAO H, et al. Semantics-aware BERT for language understanding[C]// Proceedings of the 34th AAAI Conference on A.pngicial Intelligence, the 32nd Innovative Applications of A.pngicial Intelligence Conference, the 10th AAAI Symposium on Educational Advances in A.pngicial Intelligence, New York, Feb 7-12, 2020. Menlo Park: AAAI, 2020: 9628-9635. |
| [52] | YE Z X, CHEN Q, WANG W, et al. Align, mask and select: a simple method for incorporating commonsense knowledge into language representation models[J]. arXiv: 1908. 06725, 2019. |
| [53] | CHEN W, SU Y, YAN X, et al. KGPT: knowledge-grounded pre-training for data-to-text generation[J]. arXiv: 2010. 02307, 2020. |
| [54] | RASHKIN H, SAP M, ALLAWAYE, et al. Event2Mind:commonsense inference on events, intents, and reactions[C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Jul 15-20, 2020. Stroudsburg: ACL, 2020: 8635-8648. |
| [55] | SAP M, LE BRAS R, ALLAWAY E, et al. ATOMIC: an atlas of machine commonsense for if-then reasoning[C]// Proceedings of the 33rd AAAI Conference on A.pngicial Intelligence, the 31st Innovative Applications of A.pngicial Intelligence Conference, the 9th AAAI Symposium on Educational Advances in A.pngicial Intelligence, Honolulu, Jan 27-Feb 1, 2019. Menlo Park: AAAI, 2019: 3027-3035. |
| [56] | BOSSELUT A, RASHKIN H, SAP M, et al. COMET: commonsense transformers for automatic knowledge graph construction[C]// Proceedings of the 57th Conference of the Association for Computational Linguistics, Florence, Jul 28- Aug 2, 2019. Stroudsburg: ACL, 2019: 4762-4779. |
| [57] | BORDES A, USUNIER N, GARCÍA-DURÁN A, et al. Translating embeddings for modeling multi-relational data[C]// Advances in Neural Information Processing Systems 26, Lake Tahoe, Dec 5-8, 2013. Red Hook: Curran Associates, 2013: 2787-2795. |
| [58] | HE B, ZHOU D, XIAO J H, et al. Integrating graph contextualized knowledge into pre-trained language models[C]// Findings of the Association for Computational Linguistics, Nov 16-20, 2020. Stroudsburg: ACL, 2020: 2281-2290. |
| [59] | SUN Y, WANG S, FENG S, et al. ERNIE 3.0: large-scale knowledge enhanced pre-training for language understanding and generation[J]. arXiv: 2107. 02137, 2021. |
| [60] | PETERS M E, NEUMANN M, LOGAN IV R L, et al. Knowledge enhanced contextual word representations[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, Nov 3-7, 2019. Stroudsburg: ACL, 2019: 43-54. |
| [61] | YU D, ZHU C, YANG Y, et al. Jaket: joint pre-training of knowledge graph and language understanding[J]. arXiv: 2010. 00796, 2020. |
| [62] | WANG R, TANG D, DUAN N, et al. K-adapter: infusing knowledge into pre-trained models with adapters[J]. arXiv: 2002. 01808, 2020. |
| [63] | JAWAHAR G, SAGOT B, SEDDAH D. What does BERT learn about the structure of language?[C]// Proceedings of the 57th Conference of the Association for Computational Linguistics, Florence, Jul 28-Aug 2, 2019. Stroudsburg: ACL, 2019: 3651-3657. |
| [64] | LAUSCHER A, MAJEWSKA O, RIBEIRO F R, et al. Common sense or world knowledge? Investigating adapter-based knowledge injection into pretrained transformers[J]. arXiv: 2005. 11787, 2020. |
| [65] | GUU K, LEE K, TUNG Z, et al. Retrieval augmented language model pre-training[C]// Proceedings of the 37th International Conference on Machine Learning, Jul 13-18, 2020: 3929-3938. |
| [66] | YANG Z L, DAI Z H, YANG Y M, et al. XLNet: generalized autoregressive pretraining for language understanding[C]// Advances in Neural Information Processing Systems 32, Vancouver, Dec 8-14, 2019: 5754-5764. |
| [67] | LEWIS M, LIU Y H, GOYAL N, et al. BART:denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Jul 5-10, 2020. Stroudsburg: ACL, 2020: 7871-7880. |
| [68] | LIU Y, OTT M, GPYAL N, et al. RoBERTA: a robustly optimized BERT pretraining approach[J]. arXiv: 1907. 11692, 2019. |
| [69] |
JOSHI M, CHEN D Q, LIU Y H, et al. SpanBERT: improving pre-training by representing and predicting spans[J]. Transactions of Association for Computer Linguistics, 2020, 8: 64-77.
DOI URL |
| [70] | WANG W, BI B, YAN M, et al. StructBERT: incorporating language structures into pre-training for deep language understanding[C]// Proceedings of the 8th International Conference on Learning Representations, Addis Ababa, Apr 26-30, 2020: 1-10. |
| [71] | CLARK K, LUONG M T, LE Q V, et al. ELECTRA: pre-training text encoder as discriminators rather than generators[C]// Proceedings of the 8th International Conference on Learning Representations, Addis Ababa, Apr 26-30, 2020: 1-15. |
| [72] | SUN Y, WANG S, LI Y, et al. ERNIE: enhanced representation through knowledge integration[J]. arXiv: 1904. 09223, 2019. |
| [73] | LEVINE Y, LENZ B, DAGAN O, et al. SenseBERT: driving some sense into BERT[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Jul 5-10, 2020. Stroudsburg: ACL, 2020: 4656-4667. |
| [74] | YE D M, LIN Y K, DU J J, et al. Coreferential reasoning learning for language representation[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, Nov 16-20, 2020. Stroudsburg: ACL, 2020: 7170-7186. |
| [75] | MINTZ M, BILLS S, SNOW R, et al. Distant supervision for relation extraction without labeled data[C]// Proceedings of the 47th Annual Meeting of the Association for Computational Linguistics and the 4th International Joint Conference on Natural Language Processing of the AFNLP, Singapore, Aug 2-7, 2009. Stroudsburg: ACL, 2009: 1003-1011. |
| [76] | 李涓子, 侯磊. 知识图谱研究综述[J]. 山西大学学报(自然科学版), 2017, 40(3): 454-459. |
| LI J Z, HOU L. Reviews on knowledge graph research[J]. Journal of Shanxi University (Natural Science Edition), 2017, 40(3): 454-459. | |
| [77] | WANG Z, ZHANG J W, FENG J L, et al. Knowledge graph embedding by translating on hyperplanes[C]// Proceedings of the 28th AAAI Conference on A.pngicial Intelligence, Québec City, Jul 27-31, 2014. Menlo Park: AAAI, 2014: 1112-1119. |
| [78] | JI G L, HE S Z, XU L H, et al. Knowledge graph embedding via dynamic mapping matrix[C]// Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing of the Asian Federation of Natural Language Processing, Beijing, Jul 26-31, 2015. Stroudsburg: ACL, 2015: 687-696. |
| [79] | FÉVRY T, SOARES L B, FITZGERALD N, et al. Entities as experts: sparse memory access with entity supervision[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, Nov 16-20, 2020. Stroudsburg: ACL, 2020: 4937-4951. |
| [80] | VERGA P, SUN H, SOARES L B, et al. Facts as experts: adaptable and interpretable neural memory over symbolic knowledge[J]. arXiv: 2007. 00849, 2020. |
| [81] | SOARES L B, FITZGERALD N, LING J, et al. Matching the blanks: distributional similarity for relation learning[C]// Proceedings of the 57th Conference of the Association for Computational Linguistics, Florence, Jul 28- Aug 2, 2019. Stroudsburg: ACL, 2019: 2895-2905. |
| [82] | PENG H, GAO T Y, HAN X, et al. Learning from context or names? An empirical study on neural relation extraction[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, Nov 16-20, 2020. Stroudsburg: ACL, 2020: 3661-3672. |
| [83] | SUN Y, WANG S H, LI Y K, et al. ERNIE 2.0: a continual pre-training framework for language understanding[C]// Proceedings of the 34th AAAI Conference on A.pngicial Intelligence, the 32nd Innovative Applications of A.pngicial Intelligence Conference, the 10th AAAI Symposium on Educational Advances in A.pngicial Intelligence, New York, Feb 7-12, 2020. Menlo Park: AAAI, 2020: 8968-8975. |
| [84] | ZHOU W, LEE D H, SELVAM R K, et al. Pre-training text-to-text transformers for concept-centric common sense[C]// Proceedings of the 9th International Conference on Learning Representations, Austria, May 3-7, 2021: 1-15. |
| [85] | RAFFEL C, SHAZEER N, ROBERTS A, et al. Exploring the limits of transfer learning with a unified text-to-text transformer[J]. Journal of Machine Learning Research, 2020, 21: 140. |
| [86] | WANG A, SINGH A, MICHAEL J, et al. GLUE: a multi-task benchmark and analysis platform for natural language understanding[C]// Proceedings of the 7th International Conference on Learning Representations, New Orleans, May 6-9, 2019: 1-20. |
| [87] | PETRONI F, ROCKTASCHEL T, RIEDEL S, et al. Language models as knowledge bases?[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, Nov 3-7, 2019. Stroudsburg: ACL, 2019: 2463-2473. |
| [88] | ELSAHAR H, VOUGIOUSKLIS P, REMACI A, et al. T-REx: a large scale alignment of natural language with knowledge base triples[C]// Proceedings of the 11th International Conference on Language Resources and Evaluation, Miyazaki, May 7-12, 2018: 3448-3452. |
| [89] | RAJPURKAR P, ZHANG J, LOPYTEV K, et al. SQuAD:100, 000+ questions for machine comprehension of text[C]// Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, Nov 1-4, 2016. Stroudsburg: ACL, 2016: 2383-2392. |
| [90] | ROBERTS A, RAFFEL C, SHAZEER N. How much know-ledge can you pack into the parameters of a language model?[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, Nov 16-20, 2020. Stroudsburg: ACL, 2020: 5418-5426. |
| [91] | FERRADA S, BUSTOS B, HOGAN A. IMGpedia. a linked dataset with content-based analysis of Wikimedia images[C]// LNCS 10588: Proceedings of the 16th International Semantic Web Conference, Vienna, Oct 21-25, 2017. Cham: Springer, 2017: 84-93. |
| [92] |
WANG M, WANG H F, QI G L, et al. Richpedia: a large-scale, comprehensive multi-modal knowledge graph[J]. Big Data Research, 2020, 22: 100159.
DOI URL |
| [93] | 刘知远, 孙茂松, 林衍凯, 等. 知识表示学习研究进展[J]. 计算机研究与发展, 2016, 53(2): 247-261. |
| LIU Z Y, SUN M S, LIN Y K, et al. Knowledge representation learning: a review[J]. Journal of Computer Research and Development, 2016, 53(2): 247-261. | |
| [94] | 官赛萍, 靳小龙, 贾岩涛, 等. 面向知识图谱的知识推理研究进展[J]. 软件学报, 2018, 29(10): 2966-2994. |
| GUAN S P, JIN X L, JIA Y T, et al. Knowledge reasoning over knowledge graph: a survey[J]. Journal of Software, 2018, 29(10): 2966-2994. | |
| [95] | DING X, LI Z, LIU T, et al. ELG: an event logic graph[J]. arXiv: 1907. 08015, 2019. |
| [96] | HAYASHI K, SHIMBO M. On the equivalence of holographic and complex embeddings for link prediction[C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, Jul 30-Aug 4, 2017. Stroudsburg: ACL, 2017: 554-559. |
| [1] | YU Huilin, CHEN Wei, WANG Qi, GAO Jianwei, WAN Huaiyu. Knowledge Graph Link Prediction Based on Subgraph Reasoning [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(8): 1800-1808. |
| [2] | SA Rina, LI Yanling, LIN Min. Survey of Question Answering Based on Knowledge Graph Reasoning [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(8): 1727-1741. |
| [3] | TIAN Xuan, CHEN Hangxue. Survey on Applications of Knowledge Graph Embedding in Recommendation Tasks [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(8): 1681-1705. |
| [4] | XIA Hongbin, XIAO Yifei, LIU Yuan. Long Text Generation Adversarial Network Model with Self-Attention Mechanism [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(7): 1603-1610. |
| [5] | GUO Xiaowang, XIA Hongbin, LIU Yuan. Hybrid Recommendation Model of Knowledge Graph and Graph Convolutional Network [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(6): 1343-1353. |
| [6] | DONG Wenbo, SUN Shiliang, YIN Minzhi. Research and Development of Medical Knowledge Graph Reasoning [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(6): 1193-1213. |
| [7] | WANG Baoliang, PAN Wencai. Two-Terminal Neighbor Information Fusion Recommendation Algorithm Based on Knowledge Graph [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(6): 1354-1361. |
| [8] | ZHANG Zichen, YUE Kun, QI Zhiwei, DUAN Liang. Incremental Construction of Time-Series Knowledge Graph [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(3): 598-607. |
| [9] | CHEN Gongchi, RONG Huan, MA Tinghuai. Abstractive Text Summarization Model with Coherence Reinforcement and No Ground Truth Dependency [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(3): 621-636. |
| [10] | LI Xiang, YANG Xingyao, YU Jiong, QIAN Yurong, ZHENG Jie. Double End Knowledge Graph Convolutional Networks for Recommender Systems [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(1): 176-184. |
| [11] | ZHANG Chunpeng, GU Xiwu, LI Ruixuan, LI Yuhua, LIU Wei. Construction Method for Financial Personal Relationship Graphs Using BERT [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(1): 137-143. |
| [12] | CHEN Deguang, MA Jinlin, MA Ziping, ZHOU Jie. Review of Pre-training Techniques for Natural Language Processing [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(8): 1359-1389. |
| [13] | WU Jiawei, SUN Yanchun. Recommendation System for Medical Consultation Integrating Knowledge Graph and Deep Learning Methods [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(8): 1432-1440. |
| [14] | GAO Yang, LIU Yuan. Recommendation Algorithm Combining Knowledge Graph and Short-Term Preferences [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(6): 1133-1144. |
| [15] | REN Jianhua, LI Jing, MENG Xiangfu. Document Classification Method Based on Context Awareness and Hierarchical Attention Network [J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(2): 305-314. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
/D:/magtech/JO/Jwk3_kxyts/WEB-INF/classes/