
Journal of Frontiers of Computer Science and Technology ›› 2022, Vol. 16 ›› Issue (2): 305-322.DOI: 10.3778/j.issn.1673-9418.2106055
• Surveys and Frontiers • Previous Articles Next Articles
PEI Lishen1, LIU Shaobo1,+( ), ZHAO Xuezhuan2
), ZHAO Xuezhuan2
Received:2021-05-19
Revised:2021-07-26
Online:2022-02-01
Published:2021-08-04
About author:PEI Lishen, born in 1988, Ph.D., lecturer, M.S. supervisor, member of CCF. Her research interests include action recognition, image processing, computer vision, machine learning, etc.Supported by:
裴利沈1, 刘少博1,+(), 赵雪专2
通讯作者:
+ E-mail: 2559113707@qq.com作者简介:裴利沈(1988—),女,河南郑州人,博士,讲师,硕士生导师,CCF会员,主要研究方向为行为识别、图像处理、计算机视觉、机器学习等。基金资助:CLC Number:
PEI Lishen, LIU Shaobo, ZHAO Xuezhuan. Review of Human Behavior Recognition Research[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(2): 305-322.
裴利沈, 刘少博, 赵雪专. 人体行为识别研究综述[J]. 计算机科学与探索, 2022, 16(2): 305-322.
Add to citation manager EndNote|Ris|BibTeX
URL: http://fcst.ceaj.org/EN/10.3778/j.issn.1673-9418.2106055

Fig.1 Process comparison between traditional methods and deep learning methods

Fig.2 Action recognition classification
| 方法 | 优点 | 缺点 | 应用场景 |
|---|---|---|---|
| 轮廓剪影[ | 1. 关键区域简单 2. 信息量丰富 3. 描述能力强 | 1. 灵活性低 2. 对噪声和拍摄角度敏感 3. 物体遮挡时效果大大降低 4. 轮廓细节难以捕捉 | 背景简单,人体遮挡程度低 |
| 人体关节点[ | 1. 不需要提取人体模型 2. 不需要大量像素 3. 价格便宜 | 1. 对光线和拍摄角度敏感 2. 物体遮挡时效果降低 3. 计算相对复杂 | 目标较小,人体遮挡程度低 |
| 时空兴趣点[ | 1. 不需要背景剪除 2. 对场景适应性增强 3. 自动化程度增强 | 1. 对拍摄光线和人体遮挡敏感 2. 不同兴趣点提取方法密集度和时空复杂度不可兼得 | 背景相对复杂的场景 |
| 运动轨迹[ | 1. 鲁棒性强 2. 表征能力强 3. 无视背景干扰 4. 运动信息保留完整 | 1. 分类器训练计算复杂度高 2. 速度慢 3. 计算复杂度高 | 应用场景丰富,没有太大拘束 |
Table 1 Comparison of action recognition based on traditional methods
| 方法 | 优点 | 缺点 | 应用场景 |
|---|---|---|---|
| 轮廓剪影[ | 1. 关键区域简单 2. 信息量丰富 3. 描述能力强 | 1. 灵活性低 2. 对噪声和拍摄角度敏感 3. 物体遮挡时效果大大降低 4. 轮廓细节难以捕捉 | 背景简单,人体遮挡程度低 |
| 人体关节点[ | 1. 不需要提取人体模型 2. 不需要大量像素 3. 价格便宜 | 1. 对光线和拍摄角度敏感 2. 物体遮挡时效果降低 3. 计算相对复杂 | 目标较小,人体遮挡程度低 |
| 时空兴趣点[ | 1. 不需要背景剪除 2. 对场景适应性增强 3. 自动化程度增强 | 1. 对拍摄光线和人体遮挡敏感 2. 不同兴趣点提取方法密集度和时空复杂度不可兼得 | 背景相对复杂的场景 |
| 运动轨迹[ | 1. 鲁棒性强 2. 表征能力强 3. 无视背景干扰 4. 运动信息保留完整 | 1. 分类器训练计算复杂度高 2. 速度慢 3. 计算复杂度高 | 应用场景丰富,没有太大拘束 |

Fig.3 Structure framework of two-stream

Fig.4 Structure framework of spatiotemporal fusion

Fig.5 Comparison of 2D-CNN and 3D-CNN

Fig.6 Structural differences between RNN and LSTM

Fig.7 LRCN structure diagram
| 模型架构 | 优点 | 缺点 |
|---|---|---|
| 双流网络架构[ | 1. 注重时空信息 2. 准确率高 3. 使用广泛 | 1. 依赖巨大的数据量输入 2. 硬件需求高 3. 分离训练网络,耗时 |
| 3D卷积神经网络架 构[ | 1. 速度更快 2. 注重运动信息 | 1. 计算开销大,硬件要求高 2. 识别准确率比双流网络低 |
| 混合网络架构[ | 1. 速度快,准确性高 2. 组合多样 | 1. 组合困难 2. 组合复杂度高 |
Table 2 Comparison of deep learning based behavior recognition algorithms
| 模型架构 | 优点 | 缺点 |
|---|---|---|
| 双流网络架构[ | 1. 注重时空信息 2. 准确率高 3. 使用广泛 | 1. 依赖巨大的数据量输入 2. 硬件需求高 3. 分离训练网络,耗时 |
| 3D卷积神经网络架 构[ | 1. 速度更快 2. 注重运动信息 | 1. 计算开销大,硬件要求高 2. 识别准确率比双流网络低 |
| 混合网络架构[ | 1. 速度快,准确性高 2. 组合多样 | 1. 组合困难 2. 组合复杂度高 |
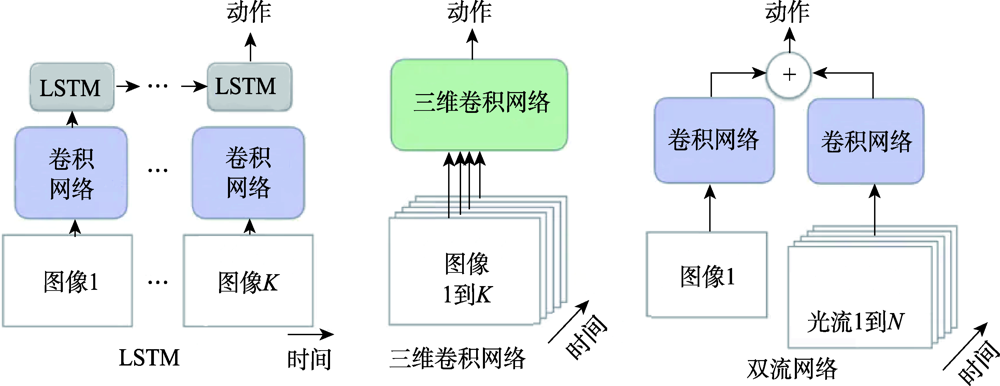
Fig.8 Comparison of classical network model framework diagrams
| 方法 | 关键点 | 数据量 | 研究热度 | 配置要求 | 效果 |
|---|---|---|---|---|---|
| 传统方式 | 特征提取 | 少 | 中 | 低 | 良 |
| 深度学习 | 数据量支撑 | 多 | 高 | 高 | 优 |
Table 3 Comparison of action recognition methods
| 方法 | 关键点 | 数据量 | 研究热度 | 配置要求 | 效果 |
|---|---|---|---|---|---|
| 传统方式 | 特征提取 | 少 | 中 | 低 | 良 |
| 深度学习 | 数据量支撑 | 多 | 高 | 高 | 优 |

Fig.9 HMDB51 and UCF101 datasets
| 数据集 | 年份 | 来源 | 样本数量 | 类数 | 平均时长/s | 实例类/行为类别 |
|---|---|---|---|---|---|---|
| KTH[ | 2004 | 志愿者拍摄 | 600 | 6 | 4.00 | 走路、慢跑、跑步、拳击、鼓掌、挥手 |
| UCF-Sports[ | 2008 | 体育电视 | 150 | 10 | 6.39 | 体育运动:潜水、高尔夫运动、踢 |
| Hollywood2[ | 2009 | 好莱坞电影 | 3 669 | 12 | 19.00 | 日常生活:吃饭、打电话、握手 |
| HMDB51[ | 2011 | 互联网、电影 | 6 849 | 51 | 2.00~5.00 | 一般面部动作、交互面部动作、一般身体动作、物体交互动作、人体交互动作 |
| UCF101[ | 2012 | 视频网站 | 13 320 | 101 | 5.00 | 人与物体交互动作、身体动作、人体交互动作、乐器演奏、运动 |
| Sports-1M[ | 2015 | 视频网站 | 1 133 158 | 487 | 336.00 | 水上运动、团队运动、冬季运动、球类运动、对抗运动、动物交互运动 |
| ActivityNet200 | 2016 | 视频网站 | 19 994 | 200 | 109.00 | 日常生活:跳远、遛狗、擦地板 |
| Kinetics[ | 2017 | 视频网站 | 306 245 | 400 | 10.00 | 弹奏乐器、日常生活:握手 |
| Epic-Kitchens[ | 2018 | 实验拍摄 | 432 | 149 | 10.00 | 厨房日常:做饭、打扫、准备食物、洗 |
| AVA[ | 2018 | 电影 | 57 600 | 80 | 3.00 | 日常生活:行走、踢、握手 |
| COIN[ | 2019 | 视频网站 | 11 827 | 180 | 14.19 | 日常生活:接发、刮胡、熨衣、抽血 |
| HACS[ | 2019 | 视频网站 | 504 000 | 200 | 2.00 | 运动:跳绳、撑杆跳高、铲雪 |
| AVA-Kinetics[ | 2020 | 视频网站 | 57 600 | 80 | 3.00 | 日常生活:拥抱、饮酒 |
Table 4 Comparison of behavior recognition datasets
| 数据集 | 年份 | 来源 | 样本数量 | 类数 | 平均时长/s | 实例类/行为类别 |
|---|---|---|---|---|---|---|
| KTH[ | 2004 | 志愿者拍摄 | 600 | 6 | 4.00 | 走路、慢跑、跑步、拳击、鼓掌、挥手 |
| UCF-Sports[ | 2008 | 体育电视 | 150 | 10 | 6.39 | 体育运动:潜水、高尔夫运动、踢 |
| Hollywood2[ | 2009 | 好莱坞电影 | 3 669 | 12 | 19.00 | 日常生活:吃饭、打电话、握手 |
| HMDB51[ | 2011 | 互联网、电影 | 6 849 | 51 | 2.00~5.00 | 一般面部动作、交互面部动作、一般身体动作、物体交互动作、人体交互动作 |
| UCF101[ | 2012 | 视频网站 | 13 320 | 101 | 5.00 | 人与物体交互动作、身体动作、人体交互动作、乐器演奏、运动 |
| Sports-1M[ | 2015 | 视频网站 | 1 133 158 | 487 | 336.00 | 水上运动、团队运动、冬季运动、球类运动、对抗运动、动物交互运动 |
| ActivityNet200 | 2016 | 视频网站 | 19 994 | 200 | 109.00 | 日常生活:跳远、遛狗、擦地板 |
| Kinetics[ | 2017 | 视频网站 | 306 245 | 400 | 10.00 | 弹奏乐器、日常生活:握手 |
| Epic-Kitchens[ | 2018 | 实验拍摄 | 432 | 149 | 10.00 | 厨房日常:做饭、打扫、准备食物、洗 |
| AVA[ | 2018 | 电影 | 57 600 | 80 | 3.00 | 日常生活:行走、踢、握手 |
| COIN[ | 2019 | 视频网站 | 11 827 | 180 | 14.19 | 日常生活:接发、刮胡、熨衣、抽血 |
| HACS[ | 2019 | 视频网站 | 504 000 | 200 | 2.00 | 运动:跳绳、撑杆跳高、铲雪 |
| AVA-Kinetics[ | 2020 | 视频网站 | 57 600 | 80 | 3.00 | 日常生活:拥抱、饮酒 |
| 文献 | 定性分析 | 识别率/% | 相关分析 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 输入 | 机制 | 网络框架/特征 | Holly-wood2 | Olympic Sports* | Sports-1M | 优势 | 局限 | 适用场景 | |
| T:DT[ | RGB OF | Trajectories | HOG、HOF、MBH | 58.3 | — | — | 表征强 | 相机运动 | 视频监控 |
| T:IDT[ | HOG、HOF、MBH | 64.3 | 91.1 | — | 稳定、可靠 | 耗时 | 运动员训练 | ||
| T:IDT[ | MBH、SIHFMFCC | 63.5 | 82.1 | — | 鲁棒性强 | 环境影响 | 运动员训练 | ||
| T:MIFS[ | HOG、HOF、PCA | 68.0 | 91.4 | — | 计算成本小 | 跟踪质量偏低 | 体育赛事 | ||
| T:Video-Darwin[ | RGB | temporal pooling | HOF、MBH Comb | 73.7 | — | — | 简单、速度快 | 机器普适性差 | 厨房日常 |
| D:ELS Fusion[ | RGB | CNN | slow fusion | — | — | 60.9 | 速度快、通用 | 相机运动影响 | 球类运动识别 |
| D:HRP+RP | VGG-16 | 74.1 | — | — | 高容量编码 | 参数较多 | 日常监控 | ||
| D:LSTM[ | RGB OF | CNN-LSTM | Two-stream 3D ConvNet | — | — | 73.1 | 长视频、低计算 | 过程复杂 | 运动识别 |
Table 5 Performance comparison of different algorithms
| 文献 | 定性分析 | 识别率/% | 相关分析 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 输入 | 机制 | 网络框架/特征 | Holly-wood2 | Olympic Sports* | Sports-1M | 优势 | 局限 | 适用场景 | |
| T:DT[ | RGB OF | Trajectories | HOG、HOF、MBH | 58.3 | — | — | 表征强 | 相机运动 | 视频监控 |
| T:IDT[ | HOG、HOF、MBH | 64.3 | 91.1 | — | 稳定、可靠 | 耗时 | 运动员训练 | ||
| T:IDT[ | MBH、SIHFMFCC | 63.5 | 82.1 | — | 鲁棒性强 | 环境影响 | 运动员训练 | ||
| T:MIFS[ | HOG、HOF、PCA | 68.0 | 91.4 | — | 计算成本小 | 跟踪质量偏低 | 体育赛事 | ||
| T:Video-Darwin[ | RGB | temporal pooling | HOF、MBH Comb | 73.7 | — | — | 简单、速度快 | 机器普适性差 | 厨房日常 |
| D:ELS Fusion[ | RGB | CNN | slow fusion | — | — | 60.9 | 速度快、通用 | 相机运动影响 | 球类运动识别 |
| D:HRP+RP | VGG-16 | 74.1 | — | — | 高容量编码 | 参数较多 | 日常监控 | ||
| D:LSTM[ | RGB OF | CNN-LSTM | Two-stream 3D ConvNet | — | — | 73.1 | 长视频、低计算 | 过程复杂 | 运动识别 |
| 文献 | 定性分析 | 识别率/% | 相关分析 | |||||
|---|---|---|---|---|---|---|---|---|
| 输入 | 机制 | 网络框架/特征 | HMDB51 | UCF101 | 优势 | 局限 | 适用场景 | |
| T:Part Model[ | RGB、OF | Multiscale local model | GBH、PCA | 61.0 | 86.6 | 实时计算较好 | 复杂 | 视频监控 |
| T+D:TDD[ | Trajectories、 Two-stream | TDD+IDT | 65.9 | 91.5 | 避免手工 | 识别精度有限 | 人体交互 | |
| TDD | 63.2 | 90.3 | ||||||
| D:Segmentation[ | RGB、OF | Two-stream | BN-Inception Inception-v3 | 71.7 72.3 | 95.2 95.5 | 加强网络泛化 | 识别速度 | 日常生活 |
| D:Attention- ConvLSTM[ | RGB、OF | VGG-16 | 69.8 | 94.6 | 强化帧间依赖 | 参数较多 | 运动场景 | |
| D:Fusion[ | RGB、OF | VGG-16、DT | 69.2 | 93.5 | 时空融合 | 计算复杂性 | 日常生活 | |
| D:TSN[ | RGB、OF、WF | BN-Inception | 69.4 | 94.2 | 高效学习整个视频 | 初始化复杂 | 长镜头场景 | |
| D:Sparse+TSN[ | RGB、OF Sparse | Inception | 76.4 | 96.9 | 特征利用率提高 | 特征交互弱 | 体育运动 | |
| D:I3D[ | RGB、OF | 3D-CNN | BN-Inception | 80.7 | 98.0 | 感受野更大 | 相机移动影响 | 日常监控 |
| D:LTC[ | depth-d | 67.2 | 92.7 | 长序列探索 | 时间复杂度 | 体育运动 | ||
| D:P3D+IDT[ | RGB、OF | 2D+1D CNN | ResNet | — | 93.7 | 参数量降低 | 识别效果 | 运动场景 |
| D:R(2+1)D[ | RGB | Mixed convolution | 78.7 | 97.3 | 参数易优化 | 空间分辨率 | 日常生活 | |
| D:CNN+LSTM[ | RGB、OF | CNN+LSTM | AlexNet、GoogleLeNet | — | 88.6 | 降低噪声影响 | 参数复杂 | 体育运动 |
Table 6 Performance comparison of different algorithms on HMDB51 and UCF101
| 文献 | 定性分析 | 识别率/% | 相关分析 | |||||
|---|---|---|---|---|---|---|---|---|
| 输入 | 机制 | 网络框架/特征 | HMDB51 | UCF101 | 优势 | 局限 | 适用场景 | |
| T:Part Model[ | RGB、OF | Multiscale local model | GBH、PCA | 61.0 | 86.6 | 实时计算较好 | 复杂 | 视频监控 |
| T+D:TDD[ | Trajectories、 Two-stream | TDD+IDT | 65.9 | 91.5 | 避免手工 | 识别精度有限 | 人体交互 | |
| TDD | 63.2 | 90.3 | ||||||
| D:Segmentation[ | RGB、OF | Two-stream | BN-Inception Inception-v3 | 71.7 72.3 | 95.2 95.5 | 加强网络泛化 | 识别速度 | 日常生活 |
| D:Attention- ConvLSTM[ | RGB、OF | VGG-16 | 69.8 | 94.6 | 强化帧间依赖 | 参数较多 | 运动场景 | |
| D:Fusion[ | RGB、OF | VGG-16、DT | 69.2 | 93.5 | 时空融合 | 计算复杂性 | 日常生活 | |
| D:TSN[ | RGB、OF、WF | BN-Inception | 69.4 | 94.2 | 高效学习整个视频 | 初始化复杂 | 长镜头场景 | |
| D:Sparse+TSN[ | RGB、OF Sparse | Inception | 76.4 | 96.9 | 特征利用率提高 | 特征交互弱 | 体育运动 | |
| D:I3D[ | RGB、OF | 3D-CNN | BN-Inception | 80.7 | 98.0 | 感受野更大 | 相机移动影响 | 日常监控 |
| D:LTC[ | depth-d | 67.2 | 92.7 | 长序列探索 | 时间复杂度 | 体育运动 | ||
| D:P3D+IDT[ | RGB、OF | 2D+1D CNN | ResNet | — | 93.7 | 参数量降低 | 识别效果 | 运动场景 |
| D:R(2+1)D[ | RGB | Mixed convolution | 78.7 | 97.3 | 参数易优化 | 空间分辨率 | 日常生活 | |
| D:CNN+LSTM[ | RGB、OF | CNN+LSTM | AlexNet、GoogleLeNet | — | 88.6 | 降低噪声影响 | 参数复杂 | 体育运动 |
| [1] |
TAKANO W, NAKAMURA Y. Statistical mutual conversion between whole body motion primitives and linguistic sentences for human motions[J]. The International Journal of Robotics Research, 2015, 34(10):1314-1328.
DOI URL |
| [2] |
ZHANG W H, SMITH M L, SMITH L N, et al. Gender and gaze gesture recognition for human-computer interaction[J]. Computer Vision and Image Understanding, 2016, 149:32-50.
DOI URL |
| [3] |
WANG X G. Intelligent multi-camera video surveillance: a review[J]. Pattern Recognition Letters, 2013, 34(1):3-19.
DOI URL |
| [4] | CAMPORESI C, KALLMANN M, HAN J J, et al. VR solutions for improving physical therapy[C]//Proceedings of the 2013 IEEE Virtual Reality, Lake Buena Vista, Mar 18-20, 2013. Washington: IEEE Computer Society, 2013: 77-78. |
| [5] | WANG L M, XIONG Y J, WANG Z, et al. Temporal segment networks: towards good practices for deep action recognition[C]//LNCS 9912: Proceedings of the 14th European Conference on Computer Vision, Amsterdam, Oct 11-14, 2016. Cham: Springer, 2016: 20-36. |
| [6] | ZHOU B L, ANDONIAN A, Oliva A, et al. Temporal relational reasoning in videos[C]//LNCS 11205: Proceedings of the 15th European Conference on Computer Vision, Munich, Sep 8-14, 2018. Cham: Springer, 2018: 831-846. |
| [7] | FEICHTENHORFER C, FAN H Q, MALIK J, et al. SlowFast networks for video recognition[C]//Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Oct 27-Nov 2, 2019. Piscataway: IEEE, 2019: 6201-6210. |
| [8] | TRAN D, BOURDEV L D, FERGUS R, et al. Learning spatiotemporal features with 3D convolutional networks[C]//Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Dec 7-12, 2015. Washington: IEEE Computer Society, 2015: 4489-4497. |
| [9] | QIU Z F, YAO T, TAO M. Learning spatio-temporal representation with pseudo-3D residual networks[C]//Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Oct 22-29, 2017. Washington: IEEE Computer Society, 2017: 5533-5541. |
| [10] | DONAHUE J, HENDRICKS L A, ROHRBACH M, et al. Long-term recurrent convolutional networks for visual recognition and description[C]//Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, Jun 7-12, 2015. Washington: IEEE Computer Society, 2015: 2625-2634. |
| [11] |
LI Z Y, GAVRILYUK K, GAVVES E, et al. VideoLSTM convolves, attends and flows for action recognition[J]. Computer Vision and Image Understanding, 2018, 166:41-50.
DOI URL |
| [12] |
BOBICK A F, DAVIS J W. The recognition of human movement using temporal templates[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2001, 23(3):257-267.
DOI URL |
| [13] | YILMAZ A, SHAH M. Actions sketch: a novel action representation[C]//Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, Jun 20-26, 2005. Washington: IEEE Computer Society, 2005: 984-989. |
| [14] | MATIKAINEN P, HEBERT M, SUKTHANKAR R. Trajectons: action recognition through the motion analysis of tracked features[C]//Proceedings of the 12th IEEE International Conference on Computer Vision Workshops, Kyoto, Sep 27-Oct 4, 2009. Washington: IEEE Computer Society, 2009: 514-521. |
| [15] | FUJIYOSHI H, LIPTON A J, KANADE T. Real-time human motion analysis by image skeletonization[J]. IEICE Transactions on Information and Systems, 2004, E87-D(1):113-120. |
| [16] |
YANG X D, TIAN Y L. Effective 3D action recognition using eigenjoints[J]. Journal of Visual Communication and Image Representation, 2014, 25(1):2-11.
DOI URL |
| [17] | 张恒鑫, 叶颖诗, 蔡贤资, 等. 基于人体关节点的高效动作识别算法[J]. 计算机工程与设计, 2020, 41(11):3168-3174. |
| ZHANG H X, YE Y S, CAI X Z, et al. Efficient algorithm of action recognition based on joint points[J]. Computer Engineering and Design, 2020, 41(11):3168-3174. | |
| [18] | LAPTEV I. On space-time interest points[J]. International JournaI of Computer Vision, 2005, 64(2/3):107-123. |
| [19] | DOLLAR P, RABAUD V, COTTRELL G W, et al. Behavior recognition via sparse spatio-temporal features[C]//Proceedings of the 2005 IEEE International Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance, Beijing, Oct 15-16, 2005. Piscataway: IEEE, 2005: 65-72. |
| [20] | WANG H, ULLAH M M, KLÄSER A, et al. Evaluation of local spatio-temporal features for action recognition[C]//Proceedings of the British Machine Vision Conference, London, Sep 7-10, 2009. Durham: BMVA Press, 2009: 1-11. |
| [21] | WILLEMS G, TUYTELAARS T, VAN GOOL L. An efficient dense and scale-invariant spatio-temporal interest point detector[C]//LNCS 5303: Proceedings of the 10th European Conference on Computer Vision, Marseille, Oct 12-18, 2008. Berlin, Heidelberg: Springer, 2008: 650-663. |
| [22] | 陈艳, 胡荣, 李升健, 等. 基于组合特征和SVM的视频中人体行为识别算法[J]. 沈阳工业大学学报, 2020, 42(6):665-669. |
| CHEN Y, HU R, LI S J, et al. Recognition algorithm for human behavior in video based on combined features and SVM[J]. Journal of Shenyang University of Technology, 2020, 42(6):665-669. | |
| [23] | WANG H, KLÄSER A, SCHMID C, et al. Action recognition by dense trajectories[C]//Proceedings of the 24th IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, Jun 20-25, 2011. Washington: IEEE Com-puter Society, 2011: 3169-3176. |
| [24] | WANG H, SCHMID C. Action recognition with improved trajectories[C]//Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Dec 1-8, 2013. Washington: IEEE Computer Society, 2014: 3551-3558. |
| [25] | 李元祥, 谢林柏. 基于深度运动图和密集轨迹的行为识别算法[J]. 计算机工程与应用, 2020, 56(3):194-200. |
| LI Y X, XIE L B. Human action recognition based on depth motion map and dense trajectory[J]. Computer Engineering and Applications, 2020, 56(3):194-200. | |
| [26] | SIMONYAN K, ZISSERMAN A. Two-stream convolutional networks for action recognition in videos[C]//Proceedings of the Annual Conference on Neural Information Processing Systems, Montreal, Dec 8-13, 2014. Red Hook: Curran Associates, 2014: 568-576. |
| [27] | 周云, 陈淑荣. 基于双流非局部残差网络的行为识别方法[J]. 计算机应用, 2020, 40(8):2236-2240. |
| ZHOU Y, CHEN S R. Behavior recognition method based on two-stream non-local residual network[J]. Journal of Computer Applications, 2020, 40(8):2236-2240. | |
| [28] | 王增强, 张文强, 张良. 引入高阶注意力机制的人体行为识别[J]. 信号处理, 2020, 36(8):1272-1279. |
| WANG Z Q, ZHANG W Q, ZHANG L. Human behavior recognition with high-order attention mechanism[J]. Journal of Signal Processing, 2020, 36(8):1272-1279. | |
| [29] | FEICHTENHOFER C, PINZ A, ZISSERMAN A. Convolutional two-stream network fusion for video action recognition[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Jun 27-30, 2016. Washington: IEEE Computer Society, 2016: 1933-1941. |
| [30] | FEICHTENHOFER C, PINZ A, WILDES R P. Spatiotemporal residual networks for video action recognition[C]//Proceedings of the Annual Conference on Neural Information Processing Systems, Barcelona, Dec 5-10, 2016. Red Hook: Curran Associates, 2017: 3468-3476. |
| [31] | 潘娜, 蒋敏, 孔军. 基于时空交互注意力模型的人体行为识别算法[J]. 激光与光电子学展, 2020, 57(18):317-325. |
| PAN N, JIANG M, KONG J. Human action recognition algorithm based on spatial-temporal interactive attention model[J]. Laser & Optoelectronics Progress, 2020, 57(18):317-325. | |
| [32] |
WANG L L, GE L Z, LI R F, et al. Three-stream CNNs for action recognition[J]. Pattern Recognition Letters, 2017, 92:33-40.
DOI URL |
| [33] |
BILEN H, FERNANDO B, GAVVES E, et al. Action recognition with dynamic image networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(12):2799-2813.
DOI URL |
| [34] | BACCOUCHE M, MAMALET F, WOLF C, et al. Sequential deep learning for human action recognition[C]//LNCS 7065: Proceedings of the 2nd International Workshop on Human Behavior Understanding, Amsterdam, Nov 16, 2011. Berlin, Heidelberg: Springer, 2011: 29-39. |
| [35] |
JI S, XU W, YANG M, et al. 3D convolutional neural networks for human action recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(1):221-231.
DOI URL |
| [36] | SUN L, JIA K, YEUNG D Y, et al. Human action recognition using factorized spatio-temporal convolutional networks[C]//Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Dec 7-13, 2015. Washington: IEEE Computer Society, 2015: 4597-4605. |
| [37] | 李梁华, 王永雄 . 高效. 3D密集残差网络及其在人体行为识别中的应用[J]. 光电工程, 2020, 47(2):23-33. |
| LI L H, WANG Y X. Efficient 3D dense residual network and its application in human action recognition[J]. Opto-Electronic Engineering, 2020, 47(2):23-33. | |
| [38] | CARREIRA J, ZISSERMAN A. Quo vadis, action recognition? a new model and the kinetics dataset[C]//Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Jul 21-26, 2017. Washington: IEEE Computer Society, 2017: 4724-4733. |
| [39] | DIBA A, FAYYAZ M, SHARMA V, et al. Temporal 3D Convnets: new architecture and transfer learning for video classification[J]. arXiv:1711.08200, 2017. |
| [40] |
VAROL G, LAPTEV I, SHMID C. Long-term temporal convolutions for action recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(6):1510-1517.
DOI URL |
| [41] | 张小俊, 李辰政, 孙凌宇, 等. 基于改进3D卷积神经网络的行为识别[J]. 计算机集成制造系统, 2019, 25(8):2000-2006. |
| ZHANG X J, LI C Z, SUN L Y, et al. Behavior recognition method based on improved 3D convolutional neural network[J]. Computer Integrated Manufacturing Systems, 2019, 25(8):2000-2006. | |
| [42] |
HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8):1735-1780.
DOI URL |
| [43] | ANDREJ K, GEORGE T, SANKETH S, et al. Large-scale video classification with convolutional neural networks[C]//Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, Jun 23-28, 2014. Washington: IEEE Computer Society, 2014: 1725-1732. |
| [44] | 祁大健, 杜慧敏, 张霞, 等. 基于上下文特征融合的行为识别算法[J]. 计算机工程与应用, 2020, 56(2):171-175. |
| QI D J, DU H M, ZHANG X, et al. Behavior recognition algorithm based on context feature fusion[J]. Computer Engineering and Applications, 2020, 56(2):171-175. | |
| [45] | NG J Y H, HAUSKNECHT M J, VIJAYANARASIMHAN S, et al. Beyond short snippets: deep networks for video classification[C]//Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, Jun 7-12, 2015. Washington: IEEE Computer Society, 2015: 4694-4702. |
| [46] | 马翠红, 王毅, 毛志强. 基于注意力的双流CNN的行为识别[J]. 计算机工程与设计, 2020, 41(10):2903-2906. |
| MA C H, WANG Y, MAO Z Q. Action recognition of two-stream CNN based on attention[J]. Computer Engineering and Design, 2020, 40(10):2903-2906. | |
| [47] | 揭志浩, 曾明如, 周鑫恒, 等. 结合Attention-ConvLSTM的双流卷积行为识别[J]. 小型微型计算机系统, 2021, 42(2):405-408. |
| JIE Z H, ZENG M R, ZHOU X H, et al. Two stream CNN with Attention-ConvLSTM on human behavior recognition[J]. Journal of Chinese Computer Systems, 2021, 42(2):405-408. | |
| [48] | KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks[C]// Proceedings of the 5th International Conference on Learning Representations, Toulon, Apr 24-26, 2017: 1-14. |
| [49] | WANG P C, LI Z Y, HOU Y H, et al. Action recognition based on joint trajectory maps using convolutional neural networks[C]//Proceedings of the 2016 ACM Conference on Multimedia Conference, Amsterdam, Oct 15-19, 2016. New York: ACM, 2016: 102-106. |
| [50] |
SHAO Z P, LI Y F, GUO Y, et al. A hierarchical model for human action recognition from body-parts[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2019, 29(10):2986-3000.
DOI URL |
| [51] | HINTON G. A practical guide to training restricted Boltzmann machines[J]. Momentum, 2010, 9(1):926-947. |
| [52] | TAYLOR G W, FERGUS R, LECUN Y, et al. Convolutional learning of spatio-temporal features[C]//LNCS 6316: Proceedings of the 11th European Conference on Computer Vision, Heraklion, Sep 5-11, 2010. Berlin, Heidelberg: Springer, 2010: 140-153. |
| [53] | TRAN S N, BENETOS E, D'AVILA G A S. Learning motion-difference features using Gaussian restricted Boltzmann machines for efficient human action recognition[C]//Proceedings of the 2014 International Joint Conference on Neural Networks, Beijing, Jul 6-11, 2014. Piscataway: IEEE, 2014: 2123-2129. |
| [54] | WANG X L, GIRSHICK R B, GUPTA A, et al. Non-local neural networks[C]//Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-22, 2018. Washington: IEEE Computer Society, 2018: 7794-7803. |
| [55] | CHI L, TIAN G Y, MU Y D, et al. Fast non-local neural networks with spectral residual learning[C]//Proceedings of the 27th ACM International Conference on Multimedia, Nice, Oct 21-25, 2019. New York: ACM, 2019: 2142-2151. |
| [56] | 叶丹, 李智, 王勇军. 基于SPLDA降维和XGBoost分类器的行为识别方法研究[J]. 微电子学与计算机, 2019, 36(6):35-39. |
| YE D, LI Z, WANG Y J. Research on behavior identification based on SPLDA dimensional reduction algorithm and XGBoost classifier[J]. Microelectronics & Computer, 2019, 36(6):35-39. | |
| [57] | SCHÜLDT C, LAPTEV I, CAPUTO B. Recognizing human actions: a local SVM approach[C]//Proceedings of the 17th International Conference on Pattern Recognition, Cambridge, Aug 23-26, 2004. Washington: IEEE Computer Society, 2004: 23-26. |
| [58] | MARSZALEK M, LAPTEV I, SCHMID C. Actions in context[C]//Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Miami, Jun 20-25, 2009. Washington: IEEE Computer Society, 2009: 2929-2936. |
| [59] | RODRIGUEZ M D, AHMED J, SHAH M. Action MACH a spatio-temporal maximum average correlation height filter for action recognition[C]//Proceedings of the 2008 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Anchorage, Jun 24-26, 2008. Washington: IEEE Computer Society, 2008: l-8. |
| [60] | SOOMRO K, ZAMIR A R, SHAH M. UCF101: a dataset of 101 human actions classes from videos in the wild[J]. arXiv:1212.0402, 2012. |
| [61] | NIEBLES J C, CHEN C W, LI F F. Modeling temporal structure of decomposable motion segments for activity classification[C]//LNCS 6312: Proceedings of the 11th European Conference on Computer Vision, Heraklion, Sep 5-11, 2010. Berlin, Heidelberg: Springer, 2010: 392-405. |
| [62] | KUEHNE H, JHUANG H, GARROTE E, et al. HMDB: a large video database for human motion recognition[C]//Proceedings of the 2011 IEEE International Conference on Computer Vision, Barcelona, Nov 6-13, 2011. Washington: IEEE Computer Society, 2011: 2556-2563. |
| [63] |
DAMEN D, DOUGHTY H, FARINELLA G M, et al. The EPIC-Kitchens dataset: collection, challenges and baselines[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(11):4125-4141.
DOI URL |
| [64] | KAY W, CARREIRA J, SIMONYAN K, et al. The Kinetics human action video dataset[J]. arXiv:1705.06950, 2017. |
| [65] | GU C H, SUN C, ROSS D A, et al. AVA: a video dataset of spatio-temporally localized atomic visual actions[C]//Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-22, 2018. Washington: IEEE Computer Society, 2018: 6047-6056. |
| [66] | TANG Y S, DING D J, RAO Y M, et al. COIN: a large-scale dataset for comprehensive instructional video analysis[C]//Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, Jun 16-20, 2019. Piscataway: IEEE, 2019: 1207-1216. |
| [67] | ZHAO H, TORRALBA A, TORRESANI L, et al. HACS: human action clips and segments dataset for recognition and temporal localization[C]//Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Oct 27-Nov 2, 2019. Piscataway: IEEE, 2019: 8667-8677. |
| [68] | LI A, THOTAKURI M, ROSS D A, et al. The AVA-Kinetics localized human actions video dataset[J]. arXiv:2005.00214, 2020. |
| [69] | SHAO D, ZHAO Y, DAI B, et al. FineGym: a hierarchical video dataset for fine-grained action understanding[C]//Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, Jun 13-19, 2020. Piscataway: IEEE, 2020: 2613-2622. |
| [70] | ONEATA D, VERBEEK J J, SCHMID C. Action and event recognition with fisher vectors on a compact feature set[C]//Proceedings of the 2013 International Conference on Computer Vision, Sydney, Dec 1-8, 2013. Washington: IEEE Computer Society, 2013: 1817-1824. |
| [71] | LAN Z Z, LIN M, LI X C, et al. Beyond Gaussian pyramid: multi-skip feature stacking for action recognition[C]//Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, Jun 7-12, 2015. Washington: IEEE Computer Society, 2015: 204-212. |
| [72] | FERNANDO B, GAVVES E, ORAMAS M J, et al. Modeling video evolution for action recognition[C]//Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, Jun 7-12, 2015. Washington: IEEE Computer Society, 2015: 5378-5387. |
| [73] | SHI F, LAGANIÈRE R, PETRIU E M. Local part model for action recognition[J]. Image and Vision Computing, 2016, 16(11):18-28. |
| [74] | WANG L M, QIAO Y, TANG X O. Action recognition with trajectory-pooled deep-convolutional descriptors[C]//Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, Jun 7-12, 2015. Washington: IEEE Computer Society, 2015: 4305-4314. |
| [75] | CHEN L, LIU Y G, MAN Y C. Two-stream CNN based on segmentation for action recognition[C]//Proceedings of the 39th China Control Conference, Liaoning, Jul 27-29, 2020. Piscataway: IEEE, 2020: 1160-1165. |
| [76] | 李洪均, 丁宇鹏, 李超波, 等. 基于特征融合时序分割网络的行为识别研究[J]. 计算机研究与发展, 2020, 57(1):145-158. |
| LI H J, DING Y P, LI C B, et al. Action recognition of temporal segment network based on feature fusion[J]. Journal of Computer Research and Development, 2020, 57(1):145-158. | |
| [77] | TRAN D, WANG H, TORRESANI L, et al. A closer look at spatiotemporal convolutions for action recognition[C]//Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Jun 18-22, 2018. Washington: IEEE Computer Society, 2018: 1010-1019. |
| [1] | AN Fengping, LI Xiaowei, CAO Xiang. Medical Image Classification Algorithm Based on Weight Initialization-Sliding Window CNN [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(8): 1885-1897. |
| [2] | HUANG Hao, GE Hongwei. Deep Residual Expression Recognition Network to Enhance Inter-class Discrimination [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(8): 1842-1849. |
| [3] | YU Huilin, CHEN Wei, WANG Qi, GAO Jianwei, WAN Huaiyu. Knowledge Graph Link Prediction Based on Subgraph Reasoning [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(8): 1800-1808. |
| [4] | ZENG Fanzhi, XU Luqian, ZHOU Yan, ZHOU Yuexia, LIAO Junwei. Review of Knowledge Tracing Model for Intelligent Education [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(8): 1742-1763. |
| [5] | LIU Yi, LI Mengmeng, ZHENG Qibin, QIN Wei, REN Xiaoguang. Survey on Video Object Tracking Algorithms [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(7): 1504-1515. |
| [6] | ZHAO Xiaoming, YANG Yijiao, ZHANG Shiqing. Survey of Deep Learning Based Multimodal Emotion Recognition [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(7): 1479-1503. |
| [7] | XIA Hongbin, XIAO Yifei, LIU Yuan. Long Text Generation Adversarial Network Model with Self-Attention Mechanism [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(7): 1603-1610. |
| [8] | LI Yuxuan, HONG Xuehai, WANG Yang, TANG Zhengzheng, BAN Yan. Groupwise Learning to Rank Algorithm with Introduction of Activated Weighting [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(7): 1594-1602. |
| [9] | SUN Fangwei, LI Chengyang, XIE Yongqiang, LI Zhongbo, YANG Caidong, QI Jin. Review of Deep Learning Applied to Occluded Object Detection [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(6): 1243-1259. |
| [10] | LIU Yafen, ZHENG Yifeng, JIANG Lingyi, LI Guohe, ZHANG Wenjie. Survey on Pseudo-Labeling Methods in Deep Semi-supervised Learning [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(6): 1279-1290. |
| [11] | ZHANG Yancao, ZHAO Yuhai, SHI Lan. Multi-feature Based Link Prediction Algorithm Fusing Graph Attention [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(5): 1096-1106. |
| [12] | OU Yangliu, HE Xi, QU Shaojun. Fully Convolutional Neural Network with Attention Module for Semantic Segmentation [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(5): 1136-1145. |
| [13] | CHENG Weiyue, ZHANG Xueqin, LIN Kezheng, LI Ao. Deep Convolutional Neural Network Algorithm Fusing Global and Local Features [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(5): 1146-1154. |
| [14] | TONG Gan, HUANG Libo. Review of Winograd Fast Convolution Technique Research [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(5): 959-971. |
| [15] | ZHONG Mengyuan, JIANG Lin. Review of Super-Resolution Image Reconstruction Algorithms [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(5): 972-990. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
/D:/magtech/JO/Jwk3_kxyts/WEB-INF/classes/